AI Native 数据平台 · 数据智能系列
引言 :让所有 CTO 都头疼的真相
过去十年,企业累计投入大量资源建设数据仓库、数据湖与 BI 平台,但一个长期被低估的事实是:约 80% 的业务人员仍无法独立获得数据洞察,必须依赖数据团队编写 SQL 与生成报表,为此 Data Agent 应运而生。Data Agent 作为数据驱动决策的执行体,承担了数据翻译官、分析协作者甚至业务的自主执行者三重身份。
Data Agent 正在成为企业数据消费的下一代基础设施 ,然而在企业实际的落地过程中并不是一帆风顺。
Case Study
接下来,我们看一个虚拟但具备普适性意义的案例。某大型零售企业的数据团队投入三个月自研了一个 Data Agent,一开始 Agent 效果惊艳,业务人员用自然语言问"昨天的销售额是多少"等问题后,Agent 几秒钟返回结果,团队上下都兴奋了好一阵。然而好景不长。当业务部门尝试一些更复杂的需求,如"帮我分析上个月华南区某款新品销量下滑的原因,结合库存、天气和竞品动态,给出促销建议",Agent 彻底死机:要么出现严重的幻觉,要么卡在 SQL 里动弹不动。
这不是个例。Gartner 预言,超过 60% 的 AI 项目会因为数据问题而被放弃;MIT 的另一项研究也指出,95% 的企业 AI 部署项目没有产生可衡量的 ROI。Data Agent 究竟要具备什么能力,才能在企业真实业务场景里跑得起来?我们认为,答案并不在大模型本身------大模型已经足够聪明,问题出在企业工程体系:当 Agent 走出聊天窗口、进入生产系统,它要面对的是数据、语义、性能、安全、审计一整套工业级约束。
本文是腾讯云 AI Native 数据平台系列的第三篇。前两篇《计算智能》《存储智能》分别讲了如何让 Agent "跑得快"和"存得下、取得到",本篇聚焦数据智能------如何让 Agent 真正"替你分析",并且分析得可信、可控、可演进。
企业构建 Data Agent 的三大堵点
Data Agent 是面向数据分析的智能体系统,融合大模型推理、统一语义层、多智能体协同、Skill 沉淀与治理审计,让自然语言直接到数据洞察 成为可能。它不是"自然语言生成 SQL"的单点工具,而是分析型智能体系统 ------既能理解业务语言,也能规划任务、调用工具、验证结果、保留上下文。企业从"演示 Demo"到"生产系统"之间,隔着一整套工程体系。综合业界一线落地观察,核心堵点可归纳为三 大 新挑战 。
准确率 挑战:多步任务的失控
通常而言,对话式的Data Agent 复杂任务背后常触发几十到上百次数据交互。例如某金融客户一次"分析上季度风险敞口"的简单问句,背后可能触发涉及数百个数据表的复杂统计与交互,任何一步的失误都会让结果不可信。传统 BI 时代,一个 SQL 错了分析师肉眼就能看出,而在 Agent 时代,多步推理链中的错误会随上下文扩散,整个分析链路可能完全跑偏。
语义挑战:"同名不同义"的歧义
企业业务上下文是制约 Data Agent 准确率的关键挑战,即便大模型再聪明,缺乏企业上下文信息也很难理解企业业务语义。例如同样是"销售额",财务、运营、管理层可能指向不同口径、"客户数"在新增、活跃、有效、付费场景下各有定义。某企业 Data Agent 上线第一周就翻车了:业务部门拿 Agent 报告开会,财务总监拍桌子------Agent 从 CRM 拉的是"合同签订日期",而财务认的是"回款确认日期",同一个"销售额"差出 30%。模型没问题,数据口径错了 。
负载挑战:传统湖仓与 Agent 的错配
传统湖仓架构为大扫描设计,适合训练与批量 ETL,而 Agent 需要的是点查、过滤、聚合、向量检索的混合负载 。并发压力也骤升------以前是几十人用,未来是几百个 Agent 同时跑,每个持续检索、推理、调用。瓶颈从"模型算力"扩展到了**"数据算力"** 。
数据智能:围绕 Data Agent 生产级架构的系统工程
数据智能是一种能够自主执行数据相关任务的系统,具备知识理解、自动规划和自我反思三大核心能力 。为支撑这三大能力,数据智能具体需要具备六个关键要素:感知(Perception)、推理与规划(Reasoning & Planning)、工具调用(Tool Invocation)、记忆(Memory)、持续学习(Continuous Learning)、多智能体协作(Multi-Agent)。这六个要素回答的是 Agent应该具备什么,而要在企业生产环境中真正落地,还需要一套分层的工程架构来承载。
进一步从工程落地视角来看,成熟的企业级数据智能必须具备六大核心层 :上下文层(企业知识库)、推理层(大脑中枢)、执行层(手脚)、可观测层(确保可解释与安全合规)、评估层(持续准确率改进)、治理层(安全闸门)。这套分层解耦、可扩展、可管控的架构,正是 Data Agent 从玩具走向生产工具的工程基础。
- 上下文层(Context): 检索、组装、投影 schema、血缘、策略与观测事实,为推理提供必要且最小化的上下文窗口;
- 推理层(Reasoning): LLM 基于上下文规划行动、拆解任务、选择工具;承担多步推理与决策的"大脑";
- 执行层(Execution): 工具调用、副作用产生、失败回滚;将推理结果落地为可执行动作链;
- 可观测层(Observability): 记录每次运行的输入、工具调用、中间结果与输出;
- 评估层(Evaluation): Agent-as-Judge 打分、benchmark 套件、回归检测与版本 A/B Test,为模型升级提供质量门禁;
- 治理层(Governance): PII 检测、保留期执行、访问控制、Human-in-the-Loop 审批。
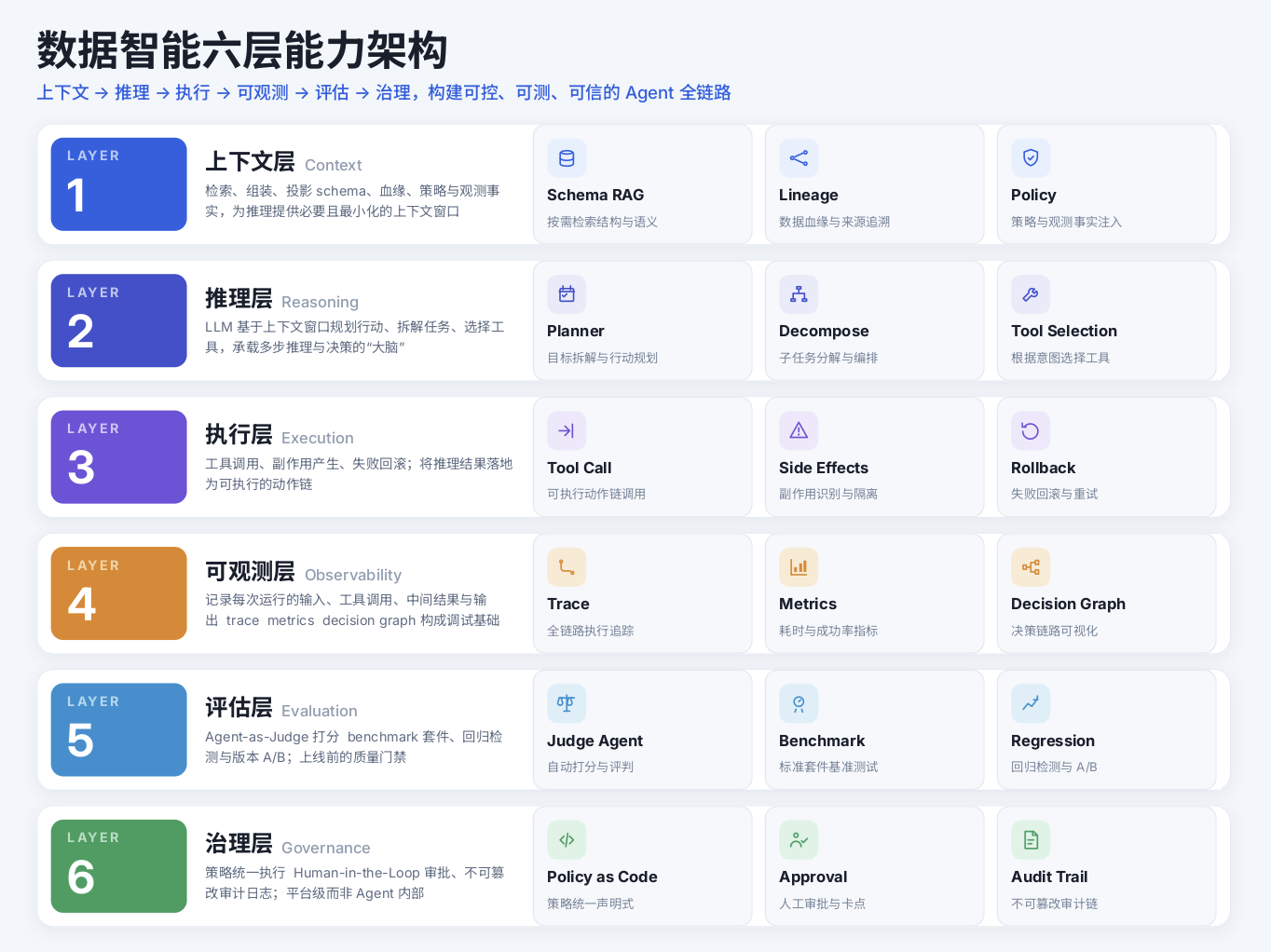
腾讯云数据智能整体介绍
腾讯云数据智能的核心载体是腾讯云数据分析智能体 TCDataAgent :一 个基于 1 年多来在众多企业真实业务场景中运行经验沉淀出的多 Data Agent 智能协作平台 。TCDataAgent 提供面向企业数据自主分析与洞察的智能体服务,通过检索和分析多模态数据,主动进行思考、洞察与行动决策,加速释放企业数据价值。具体而言,TCDataAgent 产品有三大差异化优势:
- Multi-Agent :从单 Agent 升级为 Agent 团队。用户下一个指令,系统自动组织 Agent 团队,有 Agent 负责清洗数据、有 Agent 分析趋势、有 Agent 做可视化报表;企业还可以自定义工作流和工作团队。
- Self-Evolution :Agent 自我进化。TCDataAgent 的多 Agent、Skill、memory 能根据历史执行经验、用户反馈和技能调用结果持续复盘和成长,像刚入职的实习生经过沉淀后可以自己避坑。
- Openness :内外部 Agent 统一集成。不管是自研的 Agent 还是第三方 Agent,都可以接入框架实现统一控制,做到"一键托管和无缝路由"。

TCDataAgent 采用五层技术架构 ,整套架构的设计哲学是让专家 Agent 各司其职、让中枢服务统一编排、让大数据引擎无缝对接、让基础底座提供 Agent-Ready 的算力与数据 。TCDataAgent 的能力覆盖数据全生命周期,落地为三大应用方向:
- 数据工程 :NL2SQL、CodeGen、智能选表------把数据接入、ETL 开发、工作流编排等繁重工程交给 Agent;
- 数据分析 :对话式问数、归因分析、报告生成------让业务人员零门槛完成从问数到洞察的全链路分析;
- 数据科学 :AutoPipeline、Notebook Agent、MLOps------支持数据科学家用自然语言驱动建模与流水线自动化。
下一节起,我们将逐一拆解 TCDataAgent 的三大关键能力:多 Agent 协作执行、增强语义的 SQL 生成、以及基于腾讯云 AI Native 平台的计算智能,看它们如何分别回应企业在准确度、语义、负载上的三大堵点。
关键能力一:多 Agent 协作执行
面对多步推理链失控的准确度挑战,多 Agent 协作 是当前最有效的解题思路。为什么多 Agent 能解决准确度问题?核心是多 Agent 架构下,专业化分工 + 流程化校验 :每个 Agent 只负责自己最擅长的子任务。而上一步的输出成为下一步的输入,下游 Agent 自然对上游形成校验,任何一个 Agent 失败都只影响一个环节,不会拖垮整个链路。这与人类组织里的"研发 + 测试 + 运维"分工异曲同工。
接下来,我们看一个生动的场景------慢 SQL 调优。在传统的运维模式下,通常 SRE 工程师需要数小时甚至数天,按照确认集群 → 找到慢查询 → 根据 Profile 定位 → 多轮调优这个路径完成具体慢查询任务的调优。而在 TCDataAgent 的多 Agent 模式 下,只需要数分钟的分析时间 :首席主 Agent 拆解任务 → 运维 Agent 分析集群负载、收集慢 SQL → 开发 Agent 自动 SQL 调优 → 运维 Agent 验证调优效果 → 分析 Agent 输出可视化报告。
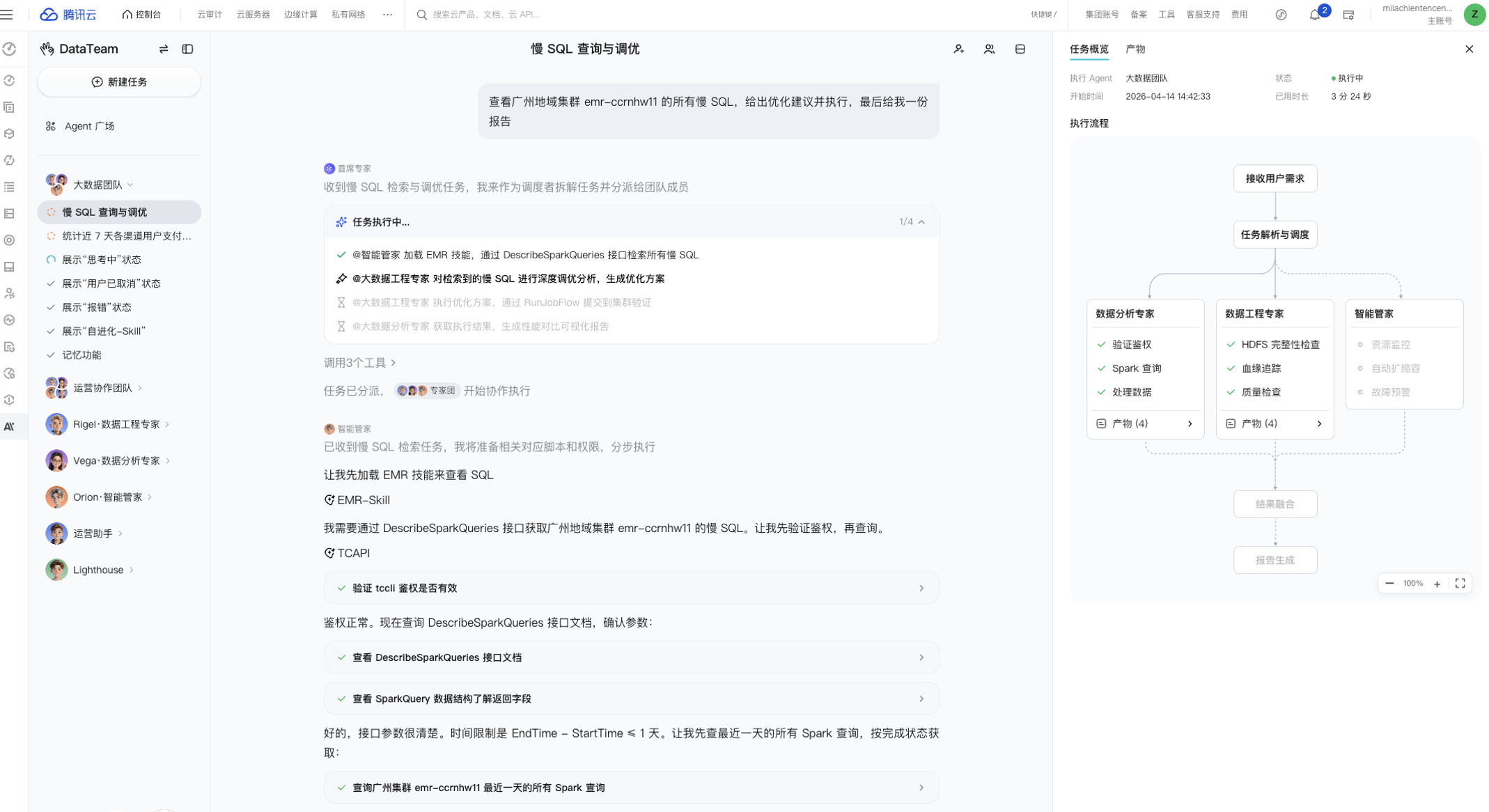
更进一步,TCDataAgent 把这种协作沉淀为可复用的 Team 模板 ------企业可以将慢 SQL 调优、周报生成、异常诊断等高频流程固化为内置 Skills,新任务到来时按模板自动组织 Agent。这种组织化复用比依赖模型临场发挥稳定得多。
关键能力二:增强语义的 SQL 生成
如果说多 Agent 解决流程准确度问题,那么理解准确度 即 Agent 对业务语义的理解能力,则由增强语义的 SQL 生成能力解决。传统 NL2SQL 行业平均水平约 70%,腾讯云 TCDataAgent 做到 90% 以上 。核心不是只依赖大模型写 SQL,而是打造了一套双引擎反馈链路 :
- 智能语义增强 :自动分析元数据,生成列注释,让 LLM 在生成 SQL 之前先"读懂"字段含义;
- 业务语义配置 :支持手工配置业务名词、接入外部语义指标平台,把企业专属术语沉淀为机器可读知识;
- 智能选表 :独立选表工具识别表与表之间复杂关联,避免"找表就找错"的第一步偏差;
- 语法智能匹配与生成优化 :自动识别底层是 Hive/TCHouse/DLC 并切换语法规则,执行报错后自我纠错;
- SQL 多轮优化 :执行后基于代价与执行计划多轮迭代,逼近最优解。
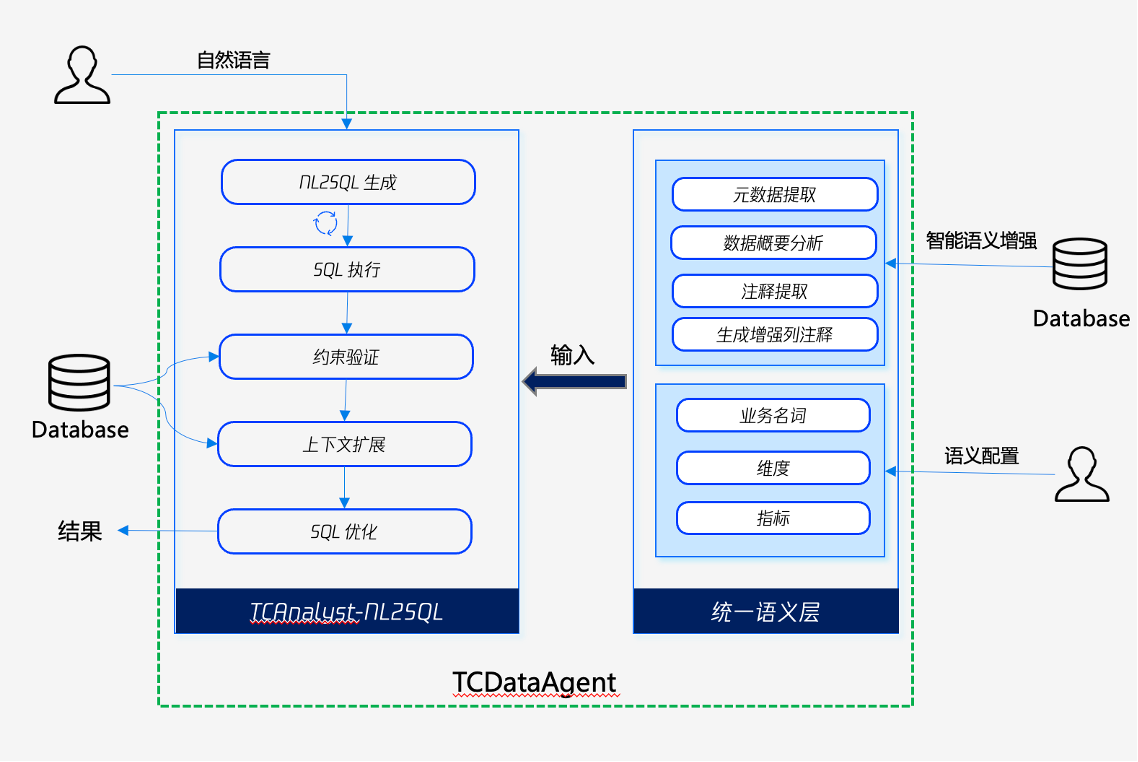
这套能力的本质是把理解意图和执行逻辑分离:让 LLM 专注于业务语言到指标/维度/过滤条件的映射(MQL),再由语义层自动翻译为 SQL。这与传统LLM 直接生成 SQL的路线相比,准确率的差距来自语义层而非模型 。
这套双引擎反馈链路的背后,是团队在 NL2SQL 方向持续的学术积累。腾讯云大数据团队从 2024 年起系统布局 NL2SQL、NL2Code、RAG 等方向,并连续两年入选数据与数据管理领域国际顶会:2025 年提出的"数据内容感知"设计被 VLDB 接收,可无缝集成到主流 NL2SQL 系统,最高将查询执行准确率提升 18.3%;2026 年与复旦大学联合提出的 CYANSQL,以"结构聚类 × 推理时扩展"的路线被 ICDE 收录。从"数据内容感知"到 CYANSQL,方法路线的持续演进,也印证了前面这套语义增强能力并非一次性调参,而是长期投入的结果。
国际权威评测同样给出了印证:TCDataAgent 在 BIRD 榜单位列全球第三、国内第一(2025 年 6 月),在 Spider 2.0-Snow 榜单位列全球第一(2026 年 2 月)。
关键能力三:腾讯云 AI Native 平台计算智能
如果把多 Agent 协作和语义层看作 Data Agent 的软件能力 ,那么计算智能 就是它的硬件效率 。这是本系列前两篇《计算智能》《存储智能》所展开的内容,这里只从 Data Agent 的视角做一次收口。
AI Native 大数据平台的"计算智能"维度,提供了 Agent-Ready 的原生计算平台,关键能力包括
- Meson 高性能计算引擎 :2026 年发布 Spark Rapids(GPU 加速)、增量计算、全面支持 Spark 4.0。TPC-DS 1TB 性能 3.6 倍 于社区版,计算密集型作业最高 5 倍以上,资源负载降低 50% 。
- Xpark 跨模态计算引擎 :全新发布 SQL-First AI Function------通过 SQL 调用多模态/LLM/ML 算子,支持 50+ AI Function;推理吞吐比开源方案提升 3 倍以上,GPU 利用率接近 100% (vs Spark GPU 约 50%)。
- TCRay 统一调度底座 :CPU+GPU 统一调度,对 Ray Core/Data/Train/Serve 四大块深度优化,让 Agent 工作负载在异构资源上弹性伸缩。
- 存储侧 TCLake AI 多模态 Lakehouse :结构化(TCIceberg,兼容 Iceberg/Hudi/Delta)+ 多模态(兼容 Lance 生态)融合成 Unified Table,一张表存数字、字符串、图片、音频、向量 Embedding。TCQA 原生加速引擎 让缓存命中率 +10%、计算耗时降低 22%。
Agent 需要的高并发点查、向量检索、跨模态计算,传统的湖仓架构跑不动也不经济,而在腾讯云 AI Native 平台下,Meson + Xpark + TCRay + TCLake 共同构成 Agent-Ready 的原生计算底座,让 Data Agent 真正"跑得起来也 用 得起 "。
结语
让我们回到开头的那个问题,Data Agent 究竟要具备什么能力,才能在企业真实业务场景里跑得起来?目前答案已经清晰:不是把 LLM 变得更聪明,而是把 LLM 放进由语义层、规则引擎、确定性工具、权限、评测、审计共同约束的工程体系 。这正是腾讯云数据智能的核心设计哲学:让 LLM 负责理解意图、编排任务、调用工具、生成解释,让企业的工程体系守住规则、口径、权限与可审计。
Data Agent 的进化本质上是一场关于企业如何分配认知权与决策权的深层革命,而当这场革命落在一套完整的 Agent-Ready 平台能力之上时,它就从概念走向了生产力。这或许才是数据智能作为新型基础设施 的真正含义。