文章目录
- indroduction
- [releted work](#releted work)
- preliminary
- [analysis and hypothesis](#analysis and hypothesis)
- method
- experiment
- idea
indroduction
怎么发现的问题?
For instance, DINO [43](https://arxiv.org/html/2602.22394?_immersive_translate_auto_translate=1#bib.bib43) demonstrates that label-supervised ViTs suffer from an attention deficit [26](https://arxiv.org/html/2602.22394?_immersive_translate_auto_translate=1#bib.bib26), while CLIPSelf [37](https://arxiv.org/html/2602.22394?_immersive_translate_auto_translate=1#bib.bib37) observes that text-supervised ViTs fail to produce dense image features that are accurately aligned with textual cues in open-vocabulary tasks. Meanwhile, Register [5](https://arxiv.org/html/2602.22394?_immersive_translate_auto_translate=1#bib.bib5) reveals that self-supervised ViTs generate artifacts in the attention maps, commonly referred to as high-norm tokens, which adversely affect object localization tasks [31](https://arxiv.org/html/2602.22394?_immersive_translate_auto_translate=1#bib.bib31).
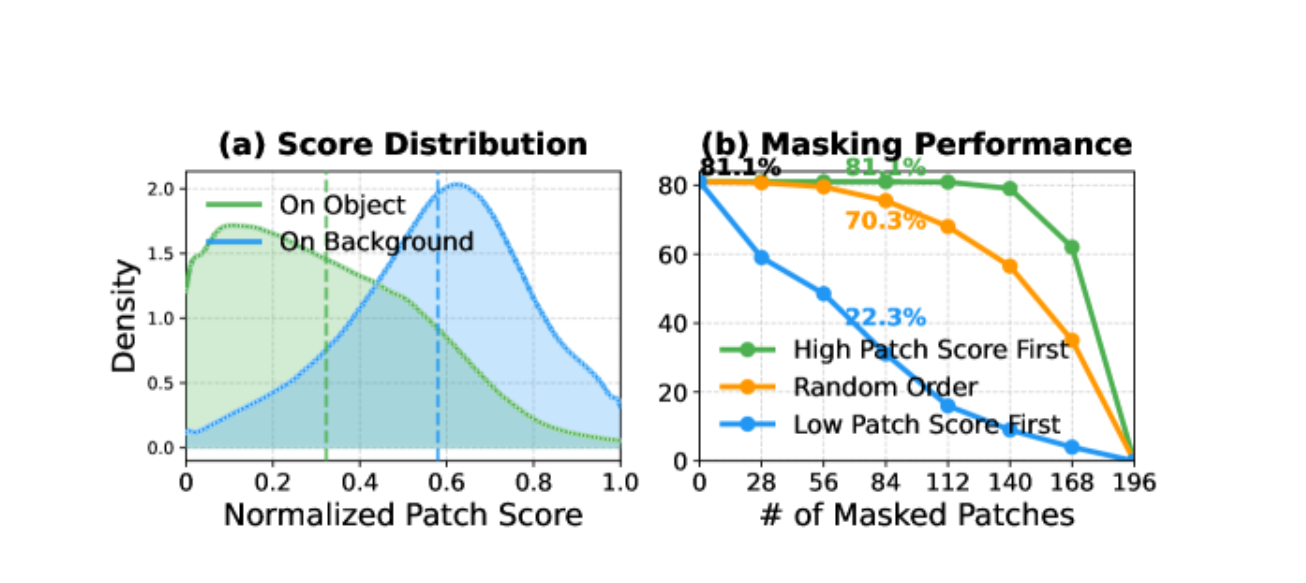
进而去做patch score和pib,即寻找cls token和各patch之间的相关度,理想情况下一张分类狗的图片,核心区域应该相关度最高,但实际发现背景区域的相关度更高
为了确认模型在偷懒,接下来做了1个验证
1:移除得分最高的50%背景元素,对识别率的影响微乎其微
探究为什么vit容易产生背景artifact
ViT 的全局 attention 太强了,导致前景物体的语义很容易被传播到背景 patch 上。
模型发现这样也能完成分类任务,于是就"偷懒"地用背景 patch 表示全局语义。所以模型只要最后分类正确就行。它不一定必须精确关注狗本身,也可以利用背景里的统计线索,比如草地、沙发、天空,甚至直接让背景 patch 吸收狗的语义。
减少全局依赖关系可以一定程度上缓解伪影的产生
怎么做的?
利用一种 frequency-aware selective aggregation,也就是"频率感知的选择性聚合"。作者认为:
-
前景物体区域语义更一致、更稳定;
-
背景区域内容更杂,语义变化更大;
-
所以可以通过低通滤波后的稳定性来判断哪些 patch 更像前景。
不要让所有 patch 都随便影响 CLS;
先判断哪些 patch 更有用,再选择性地聚合进 CLS。
做出的贡献:
(1) 我们通过 Patch Score 和 Point-in-Box 方法,系统地分析了 ViTs 中异常值产生的根本原因,发现了一个早期出现且持续存在的背景主导偏见现象。(2) 我们提出了一个假设,将粗粒度语义监督与全局依赖关系与懒惰聚合行为联系起来------这是一种快捷的聚合方式,即 ViTs 依靠背景 patch 来编码全局语义,而无需关注真正的前景区域。(3) 我们提出了 LaSt-ViT 这一简单的、基于频率选择性的聚合方案,该方案将 CLS 令牌与前景区域绑定在一起。(4) 我们在 12 个不同基准测试中的结果表明,该方案能够带来稳定的性能提升,包括物体检测、语义分割以及开放词汇检测等方面。
releted work
近年来,Vision Transformer 已成为视觉表征学习的重要基础模型。不同监督范式下的 ViT 都展现出较强的图像级识别能力,但在需要空间语义对齐的 dense prediction 任务中仍存在明显不足。
首先,CLIP 类文本监督 ViT 通过图文对比学习实现了强大的 zero-shot 分类能力。MaskCLIP 等工作进一步发现,CLIP 的 patch 特征可以与文本类别进行匹配,从而用于开放词汇语义分割。然而,后续研究表明,CLIP-ViT 的局部特征与文本语义经常存在错位,背景区域也可能被错误激活。为缓解这一问题,已有方法通常修改最后几层 attention、引入额外对齐训练,或在推理阶段进行激活修正。
其次,DINO / DINOv2 类自监督 ViT 在无标签训练下能够学习通用视觉特征,并自然涌现一定的目标发现和语义分割能力。但 Register 等研究发现,自监督 ViT 的特征图中会出现 high-norm tokens,这些异常 token 往往位于背景区域,却携带全局语义,从而破坏下游任务中的空间对齐。Register 方法通过引入额外 register tokens 存储全局信息来缓解这一现象。
不过,这些方法大多从特定现象出发进行修补:CLIP 相关工作关注文本-像素对齐,Register 关注 high-norm token。LaSt-ViT 则进一步提出,这些现象背后可能具有共同根源,即 ViT 在训练过程中形成了 lazy aggregation:由于缺少 patch 级空间监督,模型倾向于利用背景 patch 作为捷径来承载全局语义。
因此,LaSt-ViT 将问题重新定义为背景 patch 与全局 CLS 表征的错误对齐,并提出在预训练阶段调控 patch 对 CLS token 的贡献,引导模型更多聚合前景语义,从源头减少特征伪影,提升 ViT 在分割、检测等 dense prediction 任务中的空间语义对齐能力。
preliminary
这里说的是一般vit怎么生成cls token
一种是池化最后的token组,一种是加入一个cls token一起训练

前置知识
Pooling 可以先理解成一句很朴素的话:
把很多个 patch token 合并成一个 token。
在 ViT 里,encoder 输出后通常是这样:
x_patch ∈ R^{N × D}意思是有 N 个 patch,每个 patch 是一个 D 维向量:
patch_1 = [ ... D 个数 ... ]
patch_2 = [ ... D 个数 ... ]
patch_3 = [ ... D 个数 ... ]
...
patch_N = [ ... D 个数 ... ]但是分类、检索这类任务通常需要的是整张图的一个向量,比如:
Q_CLS ∈ R^D所以 Pooling 做的事情就是:
N 个 D 维向量 → 1 个 D 维向量最常见的是 mean pooling,也就是逐维求平均。
假设只有 3 个 patch,每个 patch 是 4 维:
patch_1 = [1, 2, 3, 4]
patch_2 = [3, 4, 5, 6]
patch_3 = [5, 6, 7, 8]对所有 patch token 做 mean pooling,就是每一维分别取平均:
第 1 维: (1 + 3 + 5) / 3 = 3
第 2 维: (2 + 4 + 6) / 3 = 4
第 3 维: (3 + 5 + 7) / 3 = 5
第 4 维: (4 + 6 + 8) / 3 = 6所以得到:
Q_CLS = [3, 4, 5, 6]这就是一个"整张图"的向量表示。
analysis and hypothesis
高 patch 相似性值主要集中在背景区域,这种偏差从训练开始就存在,并且持续保持不变。
ViT 的全局 attention 让任意 patch 都能直接看任意 patch。这个能力对分类很有用,因为分类经常需要整图上下文:
鸟的头 + 翅膀 + 天空背景
狗的脸 + 身体 + 草地/室内环境
车轮 + 车窗 + 道路如果改成 window attention,每个 patch 主要只能看局部窗口,远距离信息交换变弱。这样确实会减少"前景信息扩散到背景"的问题,但也削弱了模型整合全图证据的能力。所以论文里观察到:Point-in-Box 上升,说明高分 patch 更靠近前景;但 Top-1 accuracy 下降,说明整体分类能力受损。原文也把这解释成一个 trade-off:全局上下文有利于分类,但也方便语义扩散到背景。
两个评分机制
这两个评分是一前一后的关系:
Patch Score:给每个 patch 打分
它衡量的是:
某个 patch token 和整张图的全局表示有多像公式是余弦相似度:
s_p = (x_patch · Q_CLS) / (||x_patch||₂ ||Q_CLS||₂)其中:
x_patch:某一个 patch 的特征向量Q_CLS:整张图的全局表示,ViT 里通常是 CLS token·:点积- 分母:做归一化,变成 cosine similarity
所以 Patch Score 高,表示:
这个 patch 的特征方向和整张图的全局语义很接近比如一张狗图:
狗脸 patch 和 CLS 很像 → Patch Score 高
草地 patch 和 CLS 很像 → Patch Score 也可能高注意:Patch Score 不是在说"这个 patch 对分类因果贡献最大",而是在说:
这个 patch token 的最终特征和全局语义表示最对齐也就是"它像不像整张图的语义总结"。
Point-in-Box:看最高分 patch 有没有落在前景框里
Patch Score 是每张图、每个 patch 的分数。Point-in-Box 是进一步问:
分数最高的那个 patch,是在物体框里面,还是在背景里?流程大概是:
1. 对一张图的所有 patch 算 Patch Score
2. 找到分数最高的 patch
3. 看这个 patch 的位置是否落在人工标注的 foreground bounding box 里
4. 如果在框里,记为成功;不在框里,记为失败
5. 对很多张图求成功比例所以 Point-in-Box score 可以理解成:
最高语义对齐 patch 落在前景物体里的比例比如 1000 张图里,有 620 张图的最高 Patch Score patch 在物体框内:
Point-in-Box = 62%两者区别:
| 指标 | 衡量什么 | 粒度 |
|---|---|---|
| Patch Score | 每个 patch 和全局语义 CLS 有多相似 | 单张图里的每个 patch |
| Point-in-Box | 最高分 patch 是否落在前景物体框里 | 数据集级统计 |
论文用它们是为了判断:
ViT 的全局语义到底集中在前景 token,还是跑到了背景 token?如果 Patch Score 最高的 patch 经常在背景里,那么 Point-in-Box 就低,说明模型的全局语义表示和背景 token 高度对齐,存在背景 artifact / lazy aggregation 现象。
两个实验
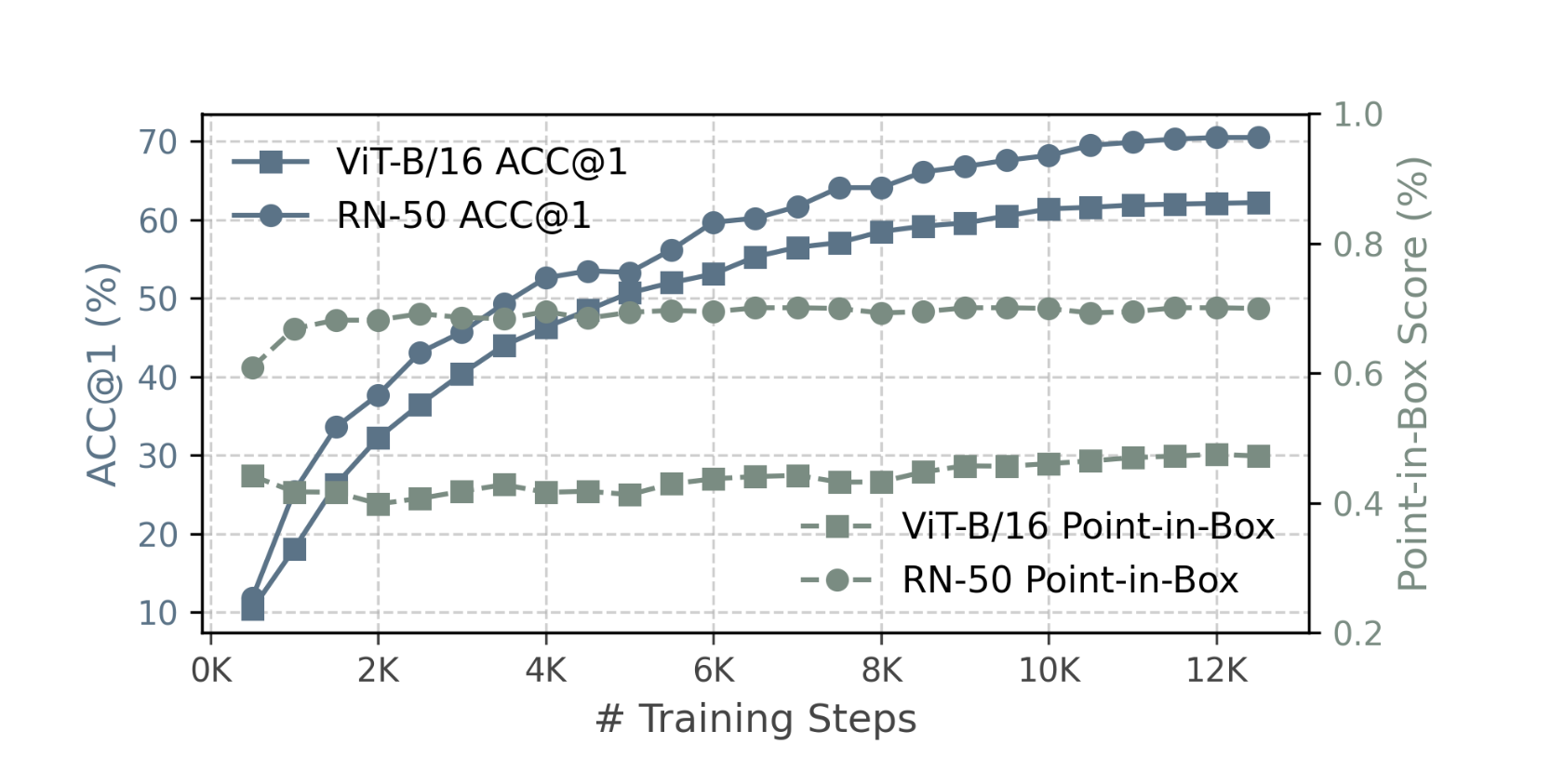
我们推测这种行为源自两个相互作用的因素:(1) 粗粒度语义监督,即图像级别的标签无法提供精确的 patch 级别监督;(2) 全局依赖性,即基于注意力的令牌混合使得背景令牌能够吸收前景信息。第 4.3 节和 4.4 节进一步分析了每个因素的作用及贡献。
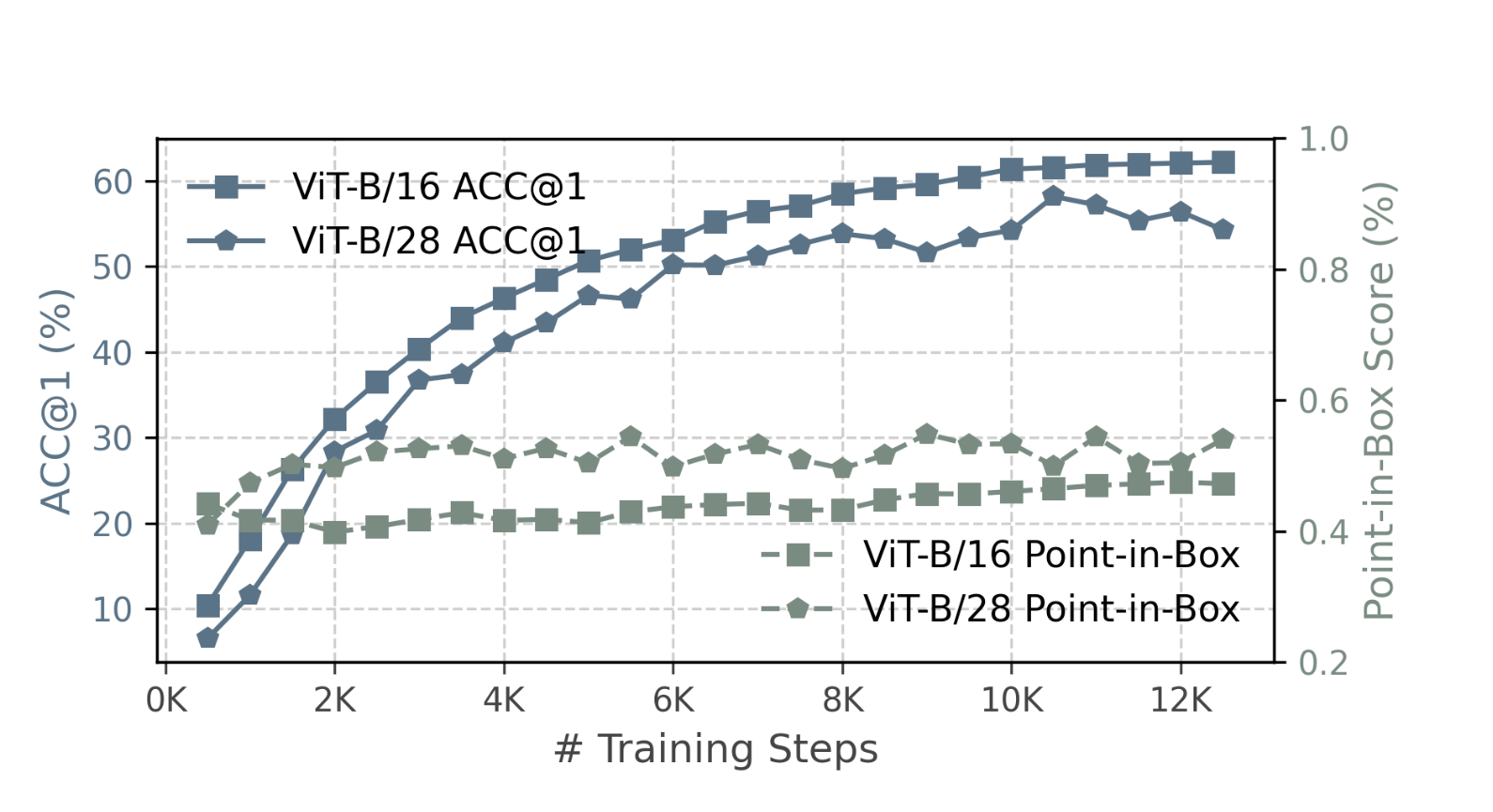
使用的块大小为 28×28 (默认值为 16×16 )当扩大补丁尺寸后,Point-in-Box 算法的效果从 0.44 提升到了 0.52 。这导致背景中的标记比例减少了约 10% 。补丁得分图显示,得分较高的区域从背景转移到了物体区域。不过,最高准确率从 62% 下降到了 55% ,这表明在分类准确性和定位准确性之间存在着权衡。

method

公式里的 channel j:
x_patch[i, j]这里的 j 是 ViT 特征里的第 j 个通道,比如第 1 维、第 2 维、第 768 维。
它不是傅里叶变换后的"频率编号"。
傅里叶变换只是中间用来做一次低通滤波:
原始 channel 向量
→ FFT 变到频率空间
→ 低通滤波,削掉高频
→ IFFT 变回原始 channel 空间
为什么要 每个 channel 单独选 Top-K patch?
因为不同 channel 可能代表不同类型的语义信息。
比如粗略地说:
channel 1:可能对狗毛纹理有响应
channel 2:可能对头部形状有响应
channel 3:可能对车轮形状有响应
...一个 patch 不一定在所有 channel 上都稳定。它可能是:
在 channel 1 很稳定
在 channel 2 不稳定
在 channel 3 又稳定如果只选"一批整体最稳定 patch",可能会丢掉某些 channel 上的重要信息。
转移到下游任务
LazyStrike 的意思是,不必非得靠 DINO,只要它把 CLS 拉回前景,普通 ViT 的 patch score 也能直接拿来做无监督物体定位。
原来可能是:
DINO 自监督 ViT
→ attention/patch feature 自然对齐前景
→ 可以做 object discovery而 LazyStrike 想做到:
有监督训练 ViT 也可以
CLIP/text-supervised ViT 也可以
其他训练目标也可以
→ 通过 LazyStrike 修正 CLS 聚合
→ patch score 更对齐前景
→ 做无监督 object discovery
experiment
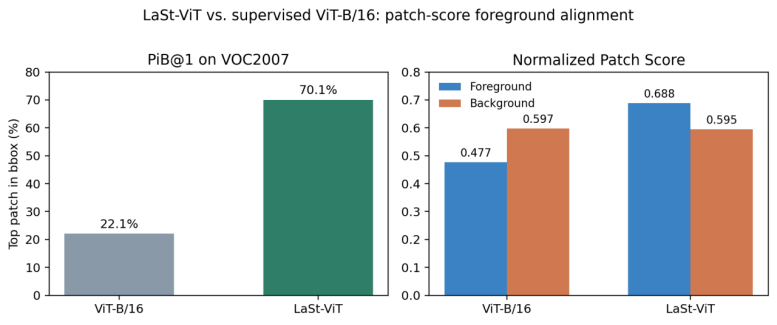
PiB 实验用于回答 LaSt-ViT 最核心的问题:最高 Patch Score 是否从背景转向前景。本报告用 VOC2007 bbox 作为前景标注。标准 ViT-B/16 的 PiB@1 为 22.09%,LaSt-ViT 提升至 70.06%。同时,标准 ViT 的背景平均 Patch Score 高于前景,LaSt-ViT 则前景平均 Patch Score 高于背景。这一结果与论文结论一致,说明 LaSt-ViT 的选择性聚合确实改善了 CLS 与前景 patch 的语义对齐。
| 模型 | PiB@1 | Hits | 前景平均 Patch Score | 背景平均 Patch Score |
|---|---|---|---|---|
| ViT-B/16 | 22.09% | 239 / 1082 | 0.477 | 0.597 |
| LaSt-ViT | 70.06% | 758 / 1082 | 0.688 | 0.595 |
idea
纵观整篇论文,简单而高效,其实就是改了一个生成CLS token的方式,让他更多的跟前景信息相关,那为什么要这么做呢。起因于发现了模型偷懒使用后景信息,怎么发现的,将传统的cls token跟所有的patch做了一个相关度的计算,发现相关度高的居然是毫不相干的后景,怎么判断模型是不是通过识别后景来猜测前景呢,将后景相关度最高的块遮挡,识别率没有变化,甚至还能提高,但是将前景遮挡,识别率大大下降,进而确定问题,把分块减少,后景减少了,确实和前景的相关度分数提高了,但是准确率也下降了,继续猜测是因为模型注意力机制把前景扩散到后景产生的原因,于是改成了窗口自注意力机制,产生了和前面一样的效果。到这里就可以定位问题了,那么怎么解决呢?很简单,做了一个低通滤波,认为变化小的稳定性好的就是前景。投票选出经过低通滤波后每个channle最稳定的几个patch,然后由这几个patch生成cls token。
接下来的事情:
第一个方向是搞清楚为什么模型会偏向于把前景信息扩散到后景里再用
第二个方向是怎么更好的做前景识别,一个低通滤波太简单了,举个例子,如果后景全是草地,那稳不稳定
模型要偷懒,直接从前景去识别不就行了,为什么还要把前景的信息扩散到后景再从后景拿
模型是直接根据后景信息猜的前景吗?但是移除得分最高的几个样本快并不会降低准确率,甚至可能会提高准确率
为什么偏偏是背景?
第一,背景 token 数量多。
一张 ImageNet 图里,前景可能只占一小部分,背景 patch 往往更多。假设:
前景 token: 20 个
背景 token: 176 个如果训练目标只是让 CLS 分类正确,那么把类别语义扩散到很多背景 token 上,比只依赖少数前景 token 更容易形成稳定的全局表示。论文也验证了这个点:增大 patch size、减少背景 token 后,Point-in-Box 会上升,高分 patch 更往前景移动,但分类精度下降。见 LaSt-ViT / Vision Transformers Need More Than Registers。
第二,背景 token 的"局部信息代价"低。
前景 token 本来要保留很多细节:
鸟嘴、翅膀、纹理、姿态、边界这些信息对识别和下游任务都有价值。如果把前景 token 过度改造成"整图语义 token",会破坏它自己的局部表示。
但很多背景 patch 比较冗余,比如天空、草地、墙面、水面。它们彼此相似,丢掉一部分局部细节对分类影响不大。于是模型会倾向于把这些低信息、冗余 token 当作临时存储区。之前的 Vision Transformers Need Registers 也有类似发现:高 norm/outlier token 常出现在冗余背景区域,局部信息少,但包含更多全局图像信息。