- 🍨 本文为 🔗365天深度学习训练营中的学习记录博客
- 🍖 原作者: K同学啊
ResNeXt 相比 ResNet50V2 / DenseNet 的优势
- vs ResNet50V2:在不增加参数复杂度的前提下,通过增加"基数"(并行路径数)提升模型容量,精度更高
- vs DenseNet:保留 ResNet 残差结构(训练稳定),同时引入分组卷积,比密集连接更易扩展、计算更高效
- 设计哲学:VGG 的简单拓扑 + Inception 的多分支 + ResNet 的残差连接,三者统一为"split-transform-merge"模式
|-----------------|------|---------------------------------------|---------------|
| 算法 | 核心思想 | 关键创新 | 参数量(ImageNet) |
| ResNet50V2 | 残差连接 | pre-activation(BN-ReLU-Conv),梯度流更顺畅 | ~25.6M |
| DenseNet121 | 密集连接 | 特征复用,每层连接所有前层,growth_rate 控制新特征 | ~8.0M |
| ResNeXt-50 | 聚合变换 | 基数(Cardinality) + 分组卷积,多路并行提取 | ~25.0M |
一、准备工作
1.1 设置 GPU
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchvision import transforms, datasets
import os, PIL, pathlib, copy, warnings
import numpy as np
warnings.filterwarnings("ignore")
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
device
device(type='cuda')1.2 导入数据(猴痘病识别 - 三分类:Measles/Monkeypox/Normal)
数据增强策略与 DenseNet 实战保持一致
data_dir = './data/day01'
# 训练集:增加数据增强
train_transforms = transforms.Compose([
transforms.Resize([224, 224]),
transforms.RandomHorizontalFlip(p=0.5), # 随机水平翻转
transforms.ColorJitter(brightness=0.2, # 颜色抖动
contrast=0.2,
saturation=0.1),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
# 测试集:仅做标准化
test_transforms = transforms.Compose([
transforms.Resize([224, 224]),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
])
# 先用统一 transform 加载全部数据(获取类别信息和总样本数)
total_data = datasets.ImageFolder(data_dir, transform=train_transforms)
total_data
Dataset ImageFolder
Number of datapoints: 1661
Root location: ./data/day01
StandardTransform
Transform: Compose(
Resize(size=[224, 224], interpolation=bilinear, max_size=None, antialias=True)
RandomHorizontalFlip(p=0.5)
ColorJitter(brightness=(0.8, 1.2), contrast=(0.8, 1.2), saturation=(0.9, 1.1), hue=None)
ToTensor()
Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
)
total_data.class_to_idx
{'0Normal': 0, '2Mild': 1, '4Severe': 2}1.3 划分数据集
train_size = int(0.8 * len(total_data))
test_size = len(total_data) - train_size
train_dataset, test_dataset = torch.utils.data.random_split(total_data, [train_size, test_size])
# 测试集使用无增强的 transform
test_dataset.dataset = datasets.ImageFolder(data_dir, transform=test_transforms)
# 保留训练集的增强
train_dataset.dataset = datasets.ImageFolder(data_dir, transform=train_transforms)
batch_size = 8
train_dl = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=0)
test_dl = torch.utils.data.DataLoader(test_dataset,
batch_size=batch_size,
num_workers=0)
for X, y in test_dl:
print("Shape of X [N, C, H, W]: ", X.shape)
print("Shape of y: ", y.shape, y.dtype)
break
vb
`Shape of X [N, C, H, W]: torch.Size([8, 3, 224, 224])
Shape of y: torch.Size([8]) torch.int64`二、搭建 ResNeXt-50 模型
ResNeXt 核心思想
- 聚合变换 (Aggregated Transformations):一个 block 由 C 条相同结构的并行分支组成,输出求和
- 基数 (Cardinality) C:并行路径数量(ResNeXt-50 默认 C=32),是除深度、宽度外的第三维度
- 分组卷积 :用
groups=cardinality高效实现多路并行,参数量与单路相当
- split-transform-merge 模式:1×1 降维 → 3×3 分组卷积 → 1×1 升维,最后 + 残差
ResNeXt-50 与 ResNet-50 结构对照
|--------|-----------------------|----------------------------|------|
| Stage | ResNet-50 层数 | ResNeXt-50 层数 | 输出通道 |
| conv1 | 7×7, 64, /2 + maxpool | 7×7, 64, /2 + maxpool | 64 |
| stage1 | 3 × Bottleneck(256) | 3 × Bottleneck(256, C=32) | 256 |
| stage2 | 4 × Bottleneck(512) | 4 × Bottleneck(512, C=32) | 512 |
| stage3 | 6 × Bottleneck(1024) | 6 × Bottleneck(1024, C=32) | 1024 |
| stage4 | 3 × Bottleneck(2048) | 3 × Bottleneck(2048, C=32) | 2048 |
2.1 模型ResNeXt搭建
class ResNeXtBottleneck(nn.Module):
"""
ResNeXt 瓶颈块:
1x1 Conv (降维) -> 3x3 Grouped Conv (分组卷积) -> 1x1 Conv (升维)
通过 groups=cardinality 实现多路并行特征提取
"""
expansion = 4 # 输出通道 = 基础通道 × 4
def __init__(self, in_channels, out_channels, stride=1,
cardinality=32, base_width=4, downsample=None):
super(ResNeXtBottleneck, self).__init__()
# 计算分组卷积的中间宽度
# base_width=4, cardinality=32 -> width=128 (当 out_channels=256 时比例缩放)
width = int(out_channels * (base_width / 64.0)) * cardinality
# 1x1 卷积:降维到 width
self.conv1 = nn.Conv2d(in_channels, width, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(width)
# 3x3 分组卷积:cardinality 条并行路径
self.conv2 = nn.Conv2d(width, width, kernel_size=3, stride=stride,
padding=1, groups=cardinality, bias=False)
self.bn2 = nn.BatchNorm2d(width)
# 1x1 卷积:升维到 out_channels * expansion
self.conv3 = nn.Conv2d(width, out_channels * self.expansion,
kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(out_channels * self.expansion)
self.downsample = downsample
self.stride = stride
def forward(self, x):
identity = x # 保存输入用于残差连接
out = F.relu(self.bn1(self.conv1(x)), inplace=True)
out = F.relu(self.bn2(self.conv2(out)), inplace=True)
out = self.bn3(self.conv3(out))
# 若通道数/尺寸不匹配,对输入做下采样
if self.downsample is not None:
identity = self.downsample(x)
out += identity # 残差连接
return F.relu(out, inplace=True)
class ResNeXt(nn.Module):
"""ResNeXt-50: layers=[3,4,6,3], cardinality=32"""
def __init__(self, block, layers, num_classes=1000,
cardinality=32, base_width=4):
super(ResNeXt, self).__init__()
self.in_channels = 64
self.cardinality = cardinality
self.base_width = base_width
# ===== Stem =====
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
# ===== 4 个 Stage =====
self.layer1 = self._make_layer(block, 64, layers[0], stride=1)
self.layer2 = self._make_layer(block, 128, layers[1], stride=2)
self.layer3 = self._make_layer(block, 256, layers[2], stride=2)
self.layer4 = self._make_layer(block, 512, layers[3], stride=2)
# ===== 分类头 =====
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.classifier = nn.Linear(512 * block.expansion, num_classes)
# ===== 权重初始化 =====
self._initialize_weights()
def _make_layer(self, block, out_channels, blocks, stride=1):
downsample = None
# 第一个 block 需要下采样以匹配维度
if stride != 1 or self.in_channels != out_channels * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.in_channels, out_channels * block.expansion,
kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(out_channels * block.expansion),
)
layers = [block(self.in_channels, out_channels, stride,
self.cardinality, self.base_width, downsample)]
self.in_channels = out_channels * block.expansion
for _ in range(1, blocks):
layers.append(block(self.in_channels, out_channels,
cardinality=self.cardinality,
base_width=self.base_width))
return nn.Sequential(*layers)
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)
def forward(self, x):
x = F.relu(self.bn1(self.conv1(x)), inplace=True)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x
def resnext50(num_classes=1000, cardinality=32, base_width=4):
"""构造 ResNeXt-50: layers=[3, 4, 6, 3]"""
return ResNeXt(ResNeXtBottleneck, [3, 4, 6, 3],
num_classes=num_classes,
cardinality=cardinality,
base_width=base_width)
model = resnext50(num_classes=len(total_data.classes)).to(device)
model
ResNeXt(
(conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(layer1): Sequential(
(0): ResNeXtBottleneck(
(conv1): Conv2d(64, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32, bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): ResNeXtBottleneck(
(conv1): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32, bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(2): ResNeXtBottleneck(
(conv1): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32, bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer2): Sequential(
(0): ResNeXtBottleneck(
(conv1): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), groups=32, bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): ResNeXtBottleneck(
(conv1): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32, bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(2): ResNeXtBottleneck(
(conv1): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32, bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(3): ResNeXtBottleneck(
(conv1): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32, bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer3): Sequential(
(0): ResNeXtBottleneck(
(conv1): Conv2d(512, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), groups=32, bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(512, 1024, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): ResNeXtBottleneck(
(conv1): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32, bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(2): ResNeXtBottleneck(
(conv1): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32, bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(3): ResNeXtBottleneck(
(conv1): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32, bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(4): ResNeXtBottleneck(
(conv1): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32, bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(5): ResNeXtBottleneck(
(conv1): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32, bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(layer4): Sequential(
(0): ResNeXtBottleneck(
(conv1): Conv2d(1024, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(1024, 1024, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), groups=32, bias=False)
(bn2): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(1024, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Sequential(
(0): Conv2d(1024, 2048, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): ResNeXtBottleneck(
(conv1): Conv2d(2048, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(1024, 1024, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32, bias=False)
(bn2): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(1024, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
(2): ResNeXtBottleneck(
(conv1): Conv2d(2048, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(1024, 1024, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32, bias=False)
(bn2): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(1024, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(avgpool): AdaptiveAvgPool2d(output_size=(1, 1))
(classifier): Linear(in_features=2048, out_features=3, bias=True)
)2.2 查看模型详情
import torchsummary as summary
summary.summary(model, (3, 224, 224))
----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 64, 112, 112] 9,408
BatchNorm2d-2 [-1, 64, 112, 112] 128
MaxPool2d-3 [-1, 64, 56, 56] 0
Conv2d-4 [-1, 128, 56, 56] 8,192
BatchNorm2d-5 [-1, 128, 56, 56] 256
Conv2d-6 [-1, 128, 56, 56] 4,608
BatchNorm2d-7 [-1, 128, 56, 56] 256
Conv2d-8 [-1, 256, 56, 56] 32,768
BatchNorm2d-9 [-1, 256, 56, 56] 512
Conv2d-10 [-1, 256, 56, 56] 16,384
BatchNorm2d-11 [-1, 256, 56, 56] 512
ResNeXtBottleneck-12 [-1, 256, 56, 56] 0
Conv2d-13 [-1, 128, 56, 56] 32,768
BatchNorm2d-14 [-1, 128, 56, 56] 256
Conv2d-15 [-1, 128, 56, 56] 4,608
BatchNorm2d-16 [-1, 128, 56, 56] 256
Conv2d-17 [-1, 256, 56, 56] 32,768
BatchNorm2d-18 [-1, 256, 56, 56] 512
ResNeXtBottleneck-19 [-1, 256, 56, 56] 0
Conv2d-20 [-1, 128, 56, 56] 32,768
BatchNorm2d-21 [-1, 128, 56, 56] 256
Conv2d-22 [-1, 128, 56, 56] 4,608
BatchNorm2d-23 [-1, 128, 56, 56] 256
Conv2d-24 [-1, 256, 56, 56] 32,768
BatchNorm2d-25 [-1, 256, 56, 56] 512
ResNeXtBottleneck-26 [-1, 256, 56, 56] 0
Conv2d-27 [-1, 256, 56, 56] 65,536
BatchNorm2d-28 [-1, 256, 56, 56] 512
Conv2d-29 [-1, 256, 28, 28] 18,432
BatchNorm2d-30 [-1, 256, 28, 28] 512
Conv2d-31 [-1, 512, 28, 28] 131,072
BatchNorm2d-32 [-1, 512, 28, 28] 1,024
Conv2d-33 [-1, 512, 28, 28] 131,072
BatchNorm2d-34 [-1, 512, 28, 28] 1,024
ResNeXtBottleneck-35 [-1, 512, 28, 28] 0
Conv2d-36 [-1, 256, 28, 28] 131,072
BatchNorm2d-37 [-1, 256, 28, 28] 512
Conv2d-38 [-1, 256, 28, 28] 18,432
BatchNorm2d-39 [-1, 256, 28, 28] 512
Conv2d-40 [-1, 512, 28, 28] 131,072
BatchNorm2d-41 [-1, 512, 28, 28] 1,024
ResNeXtBottleneck-42 [-1, 512, 28, 28] 0
Conv2d-43 [-1, 256, 28, 28] 131,072
BatchNorm2d-44 [-1, 256, 28, 28] 512
Conv2d-45 [-1, 256, 28, 28] 18,432
BatchNorm2d-46 [-1, 256, 28, 28] 512
Conv2d-47 [-1, 512, 28, 28] 131,072
BatchNorm2d-48 [-1, 512, 28, 28] 1,024
ResNeXtBottleneck-49 [-1, 512, 28, 28] 0
Conv2d-50 [-1, 256, 28, 28] 131,072
BatchNorm2d-51 [-1, 256, 28, 28] 512
Conv2d-52 [-1, 256, 28, 28] 18,432
BatchNorm2d-53 [-1, 256, 28, 28] 512
Conv2d-54 [-1, 512, 28, 28] 131,072
BatchNorm2d-55 [-1, 512, 28, 28] 1,024
ResNeXtBottleneck-56 [-1, 512, 28, 28] 0
Conv2d-57 [-1, 512, 28, 28] 262,144
BatchNorm2d-58 [-1, 512, 28, 28] 1,024
Conv2d-59 [-1, 512, 14, 14] 73,728
BatchNorm2d-60 [-1, 512, 14, 14] 1,024
Conv2d-61 [-1, 1024, 14, 14] 524,288
BatchNorm2d-62 [-1, 1024, 14, 14] 2,048
Conv2d-63 [-1, 1024, 14, 14] 524,288
BatchNorm2d-64 [-1, 1024, 14, 14] 2,048
ResNeXtBottleneck-65 [-1, 1024, 14, 14] 0
Conv2d-66 [-1, 512, 14, 14] 524,288
BatchNorm2d-67 [-1, 512, 14, 14] 1,024
Conv2d-68 [-1, 512, 14, 14] 73,728
BatchNorm2d-69 [-1, 512, 14, 14] 1,024
Conv2d-70 [-1, 1024, 14, 14] 524,288
BatchNorm2d-71 [-1, 1024, 14, 14] 2,048
ResNeXtBottleneck-72 [-1, 1024, 14, 14] 0
Conv2d-73 [-1, 512, 14, 14] 524,288
BatchNorm2d-74 [-1, 512, 14, 14] 1,024
Conv2d-75 [-1, 512, 14, 14] 73,728
BatchNorm2d-76 [-1, 512, 14, 14] 1,024
Conv2d-77 [-1, 1024, 14, 14] 524,288
BatchNorm2d-78 [-1, 1024, 14, 14] 2,048
ResNeXtBottleneck-79 [-1, 1024, 14, 14] 0
Conv2d-80 [-1, 512, 14, 14] 524,288
BatchNorm2d-81 [-1, 512, 14, 14] 1,024
Conv2d-82 [-1, 512, 14, 14] 73,728
BatchNorm2d-83 [-1, 512, 14, 14] 1,024
Conv2d-84 [-1, 1024, 14, 14] 524,288
BatchNorm2d-85 [-1, 1024, 14, 14] 2,048
ResNeXtBottleneck-86 [-1, 1024, 14, 14] 0
Conv2d-87 [-1, 512, 14, 14] 524,288
BatchNorm2d-88 [-1, 512, 14, 14] 1,024
Conv2d-89 [-1, 512, 14, 14] 73,728
BatchNorm2d-90 [-1, 512, 14, 14] 1,024
Conv2d-91 [-1, 1024, 14, 14] 524,288
BatchNorm2d-92 [-1, 1024, 14, 14] 2,048
ResNeXtBottleneck-93 [-1, 1024, 14, 14] 0
Conv2d-94 [-1, 512, 14, 14] 524,288
BatchNorm2d-95 [-1, 512, 14, 14] 1,024
Conv2d-96 [-1, 512, 14, 14] 73,728
BatchNorm2d-97 [-1, 512, 14, 14] 1,024
Conv2d-98 [-1, 1024, 14, 14] 524,288
BatchNorm2d-99 [-1, 1024, 14, 14] 2,048
ResNeXtBottleneck-100 [-1, 1024, 14, 14] 0
Conv2d-101 [-1, 1024, 14, 14] 1,048,576
BatchNorm2d-102 [-1, 1024, 14, 14] 2,048
Conv2d-103 [-1, 1024, 7, 7] 294,912
BatchNorm2d-104 [-1, 1024, 7, 7] 2,048
Conv2d-105 [-1, 2048, 7, 7] 2,097,152
BatchNorm2d-106 [-1, 2048, 7, 7] 4,096
Conv2d-107 [-1, 2048, 7, 7] 2,097,152
BatchNorm2d-108 [-1, 2048, 7, 7] 4,096
ResNeXtBottleneck-109 [-1, 2048, 7, 7] 0
Conv2d-110 [-1, 1024, 7, 7] 2,097,152
BatchNorm2d-111 [-1, 1024, 7, 7] 2,048
Conv2d-112 [-1, 1024, 7, 7] 294,912
BatchNorm2d-113 [-1, 1024, 7, 7] 2,048
Conv2d-114 [-1, 2048, 7, 7] 2,097,152
BatchNorm2d-115 [-1, 2048, 7, 7] 4,096
ResNeXtBottleneck-116 [-1, 2048, 7, 7] 0
Conv2d-117 [-1, 1024, 7, 7] 2,097,152
BatchNorm2d-118 [-1, 1024, 7, 7] 2,048
Conv2d-119 [-1, 1024, 7, 7] 294,912
BatchNorm2d-120 [-1, 1024, 7, 7] 2,048
Conv2d-121 [-1, 2048, 7, 7] 2,097,152
BatchNorm2d-122 [-1, 2048, 7, 7] 4,096
ResNeXtBottleneck-123 [-1, 2048, 7, 7] 0
AdaptiveAvgPool2d-124 [-1, 2048, 1, 1] 0
Linear-125 [-1, 3] 6,147
================================================================
Total params: 22,986,051
Trainable params: 22,986,051
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.57
Forward/backward pass size (MB): 263.39
Params size (MB): 87.68
Estimated Total Size (MB): 351.65
----------------------------------------------------------------三、训练模型
3.1 编写训练函数
def train(dataloader, model, loss_fn, optimizer):
size = len(dataloader.dataset)
num_batches = len(dataloader)
train_loss, train_acc = 0, 0
for X, y in dataloader:
X, y = X.to(device), y.to(device)
pred = model(X)
loss = loss_fn(pred, y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_acc += (pred.argmax(1) == y).type(torch.float).sum().item()
train_loss += loss.item()
train_acc /= size
train_loss /= num_batches
return train_acc, train_loss3.2 编写测试函数
def test(dataloader, model, loss_fn):
size = len(dataloader.dataset)
num_batches = len(dataloader)
test_loss, test_acc = 0, 0
with torch.no_grad():
for imgs, target in dataloader:
imgs, target = imgs.to(device), target.to(device)
target_pred = model(imgs)
loss = loss_fn(target_pred, target)
test_loss += loss.item()
test_acc += (target_pred.argmax(1) == target).type(torch.float).sum().item()
test_acc /= size
test_loss /= num_batches
return test_acc, test_loss3.3 正式训练
优化策略(沿用 DenseNet 实战中验证有效的方案):
- AdamW 优化器 + 标签平滑(label_smoothing=0.1)
- 余弦退火 学习率调度
-
batch_size=8
import copy
optimizer = torch.optim.AdamW(model.parameters(), lr=1e-3, weight_decay=1e-4)
标签平滑:防止过拟合
loss_fn = nn.CrossEntropyLoss(label_smoothing=0.1)
余弦退火学习率调度
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=10, eta_min=1e-6)
epochs = 10
train_loss = []
train_acc = []
test_loss = []
test_acc = []best_acc = 0
best_model = Nonefor epoch in range(epochs):
model.train() epoch_train_acc, epoch_train_loss = train(train_dl, model, loss_fn, optimizer) # 余弦退火:每个 epoch 后更新学习率 scheduler.step() model.eval() epoch_test_acc, epoch_test_loss = test(test_dl, model, loss_fn) train_acc.append(epoch_train_acc) train_loss.append(epoch_train_loss) test_acc.append(epoch_test_acc) test_loss.append(epoch_test_loss) # 保存最佳模型 if epoch_test_acc > best_acc: best_acc = epoch_test_acc best_model = copy.deepcopy(model) # 获取当前学习率 lr = optimizer.state_dict()['param_groups'][0]['lr'] template = ('Epoch:{:2d}, Train_acc:{:.1f}%, Train_loss:{:.3f}, ' 'Test_acc:{:.1f}%, Test_loss:{:.3f}, Lr:{:.2E}') print(template.format(epoch + 1, epoch_train_acc * 100, epoch_train_loss, epoch_test_acc * 100, epoch_test_loss, lr))保存最佳模型权重
PATH = './model/J8_best_model_resnext50.pth'
torch.save(best_model.state_dict(), PATH)
print('Done. Best Test Accuracy: {:.1f}%'.format(best_acc * 100))Epoch: 1, Train_acc:58.9%, Train_loss:1.115, Test_acc:64.3%, Test_loss:0.931, Lr:9.76E-04
Epoch: 2, Train_acc:65.5%, Train_loss:0.915, Test_acc:49.8%, Test_loss:1.086, Lr:9.05E-04
Epoch: 3, Train_acc:69.2%, Train_loss:0.881, Test_acc:57.4%, Test_loss:0.993, Lr:7.94E-04
Epoch: 4, Train_acc:68.9%, Train_loss:0.846, Test_acc:63.1%, Test_loss:0.955, Lr:6.55E-04
Epoch: 5, Train_acc:75.2%, Train_loss:0.777, Test_acc:72.4%, Test_loss:0.872, Lr:5.01E-04
Epoch: 6, Train_acc:76.4%, Train_loss:0.744, Test_acc:53.5%, Test_loss:1.115, Lr:3.46E-04
Epoch: 7, Train_acc:79.4%, Train_loss:0.670, Test_acc:82.6%, Test_loss:0.595, Lr:2.07E-04
Epoch: 8, Train_acc:82.1%, Train_loss:0.628, Test_acc:84.4%, Test_loss:0.562, Lr:9.64E-05
Epoch: 9, Train_acc:84.6%, Train_loss:0.590, Test_acc:88.3%, Test_loss:0.513, Lr:2.54E-05
Epoch:10, Train_acc:86.5%, Train_loss:0.546, Test_acc:87.4%, Test_loss:0.535, Lr:1.00E-06
Done. Best Test Accuracy: 88.3%
四、结果可视化
import matplotlib.pyplot as plt
from datetime import datetime
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['figure.dpi'] = 100
current_time = datetime.now()
epochs_range = range(epochs)
plt.figure(figsize=(12, 3))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, train_acc, label='Training Accuracy')
plt.plot(epochs_range, test_acc, label='Test Accuracy')
plt.legend(loc='lower right')
plt.title('ResNeXt-50 Training and Validation Accuracy')
plt.xlabel(current_time)
plt.subplot(1, 2, 2)
plt.plot(epochs_range, train_loss, label='Training Loss')
plt.plot(epochs_range, test_loss, label='Test Loss')
plt.legend(loc='upper right')
plt.title('ResNeXt-50 Training and Validation Loss')
plt.show()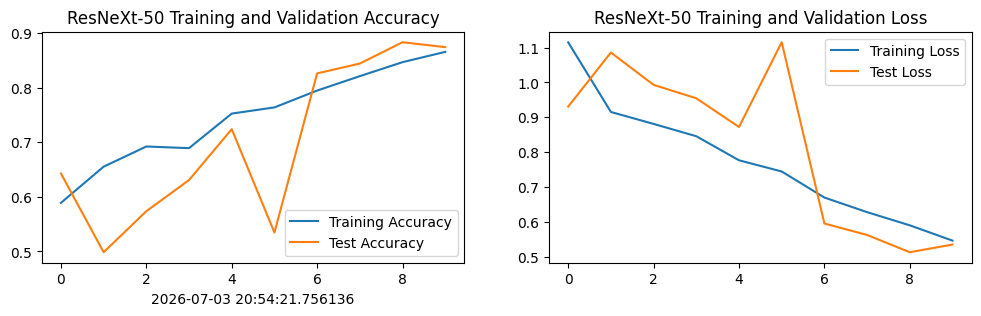
五、模型评估
best_model.load_state_dict(torch.load(PATH, map_location=device, weights_only=True))
epoch_test_acc, epoch_test_loss = test(test_dl, best_model, loss_fn)
print(f'ResNeXt-50 Best Test Accuracy: {epoch_test_acc*100:.1f}%')
print(f'ResNeXt-50 Best Test Loss: {epoch_test_loss:.4f}')
ResNeXt-50 Best Test Accuracy: 88.3%
ResNeXt-50 Best Test Loss: 0.5128六、三种算法总结
|-------------|---------------|------------------|------------------|
| 维度 | ResNet50V2 | DenseNet121 | ResNeXt-50 |
| 核心结构 | 残差块 (pre-act) | 密集块 + 过渡层 | 残差块 + 分组卷积 |
| 特征传递 | 跨层相加 | 跨层 concat | 跨层相加 (多路聚合) |
| 参数效率 | 中 | 高 (特征复用) | 中 |
| 训练稳定性 | 好 | 一般 (内存占用高) | 好 |
| 扩展维度 | 深度 / 宽度 | 深度 / growth_rate | 深度 / 宽度 / 基数 |
| ImageNet 精度 | 较好 | 好 | 更好 (同参数量) |
结论
- ResNeXt-50 通过引入"基数"这一新维度,在参数量与 ResNet-50 相当的情况下获得了更高的精度
- 其
split-transform-merge范式是后来 SENet、EfficientNet 等现代架构的设计基础
- 实战中可与迁移学习(
torchvision.models.resnext50_32x4d(pretrained=True))结合,进一步提升小数据集表现