前言
在 Kubernetes 中,Pod 是调度和运行的最小单元,但 Pod 本身具有" ephemeral"(短暂)的特性------它们可以被频繁地创建、销毁和重新调度。当容器崩溃或 Pod 被删除时,容器内部文件系统中的数据也会随之丢失。为了解决这一困境,Kubernetes 引入了 Volume(数据卷) 抽象。Volume 的生命周期独立于容器,即使容器被重建,Volume 中的数据也会保留,并可以被同一 Pod 中的其他容器共享。Kubernetes 支持多种类型的 Volume,包括 emptyDir、hostPath、NFS、Ceph、云存储等。本文将系统介绍几种常用的存储机制,并通过实际示例演示如何在不同场景下为 Pod 配置持久化存储,最后深入讲解 PV(PersistentVolume)和 PVC(PersistentVolumeClaim)的使用方法及回收策略。
一、K8s 中可用的数据卷概览
Kubernetes Volume 本质上就是一个目录,它与 Pod 绑定,Pod 中的所有容器都可以挂载并访问该目录。Volume 的生命周期与 Pod 相同,但内容是否持久取决于 Volume 的类型。
Kubernetes 支持以下主流 Volume 类型:
-
emptyDir:临时目录,Pod 删除时数据清除。
-
hostPath:宿主机节点上的目录,Pod 删除后数据保留,但节点故障则数据不可用。
-
NFS:网络文件系统,支持多节点同时挂载,数据持久化。
-
PVC/PV:通过 PersistentVolume 和 PersistentVolumeClaim 实现存储资源与存储消费的解耦。
-
其他:Ceph、GlusterFS、AWS EBS、GCE PD、Azure Disk 等。
二、emptyDir 类型存储
emptyDir 是最基础的 Volume 类型。当 Pod 被分配到节点时,会在该节点上创建一个空目录,Pod 中的所有容器都可以挂载该目录。注意 :emptyDir 的生命周期与 Pod 完全一致------Pod 从节点删除时,该目录及其内容会被永久清除;但如果只是容器被销毁而 Pod 还在,则 Volume 不受影响。
示例:同一个 Pod 内两个容器共享 Volume
下面的 YAML 文件描述了一个 Pod,其中包含两个容器 pods1 和 pods2,它们共享一个名为 share-vm 的 emptyDir Volume:
# pods.yml
apiVersion: v1
kind: Pod
metadata:
name: share-pods
spec:
containers:
- name: pods1
image: busybox
volumeMounts:
- name: share-vm
mountPath: /pods1
args:
- /bin/sh
- -c
- echo "hello k8s pods" > /pods1/hello ; sleep 3000
- name: pods2
image: busybox
volumeMounts:
- name: share-vm
mountPath: /pods2
args:
- /bin/sh
- -c
- cat /pods2/hello ; sleep 3000
volumes:
- name: share-vm
emptyDir: {}执行命令创建 Pod:
[root@master data]# kubectl apply -f pods.yml查看 pods2 容器的日志,确认它能读取到 pods1 写入的数据:
[root@master data]# kubectl logs share-pods pods2
hello k8s pods通过 docker inspect 可以在宿主机上看到两个容器挂载的正是同一个临时目录(路径类似 /var/lib/kubelet/pods/<pod-id>/volumes/kubernetes.io~empty-dir/share-vm)。
emptyDir 特别适合 Pod 内容器之间需要临时共享数据的场景,无需额外配置,但数据不持久化。
三、hostPath 存储类型
hostPath Volume 将宿主机节点文件系统中的已有目录挂载到 Pod 的容器中。一些系统级 Pod(如 kube-apiserver)就会使用 hostPath 挂载节点上的证书目录:
[root@master data]# kubectl edit --namespace=kube-system pod kube-apiserver-master可以看到类似下面的挂载配置:
volumes:
- hostPath:
path: /etc/ssl/certs
type: DirectoryOrCreate
name: ca-certs
- hostPath:
path: /etc/pki
type: DirectoryOrCreate
name: etc-pki
- hostPath:
path: /etc/kubernetes/pki
type: DirectoryOrCreate
name: k8s-certshostPath 的特点是:即使 Pod 被删除,宿主机上的目录依然保留,持久性比 emp``tyDir 强。但缺点也很明显------它增加了 Pod 与节点的耦合性(Pod 必须调度到存在特定目录的节点上),且节点故障时数据无法自动迁移。
示例:将宿主机 /tmp 目录挂载到 nginx 容器
# hostpath.yml
apiVersion: v1
kind: Pod
metadata:
name: myhostpath
spec:
containers:
- name: nginx
image: nginx
volumeMounts:
- name: hostpath
mountPath: /usr/share/nginx/html
volumes:
- name: hostpath
hostPath:
path: /tmp
type: Directory创建 Pod,找到其运行的节点(假设为 node1):
[root@master data]# kubectl apply -f hostpath.yml
[root@master data]# kubectl get pod -o wide
NAME READY STATUS RESTARTS AGE IP NODE
myhostpath 1/1 Running 0 7m 10.244.1.95 node1在 node1 上创建测试文件:
[root@node1 data]# echo "test hostpath" > /tmp/index.html通过 Pod IP 访问 nginx:
[root@master data]# curl 10.244.1.95
test hostpath四、使用 NFS 作为数据存储
NFS(Network File System)是一种成熟的网络文件共享协议,支持多个节点同时挂载,数据持久化且独立于节点。要在 Kubernetes 中使用 NFS,需要先搭建一台 NFS 服务器,并在所有节点上安装 nfs-utils 客户端。
步骤 1:搭建 NFS 服务器(IP 示例:172.16.213.230)
# 在 NFS 服务器上
[root@nfsserver ~]# yum install nfs-utils -y
[root@nfsserver ~]# mkdir -p /nfs
[root@nfsserver ~]# chown -R nfsnobody.nfsnobody /nfs
[root@nfsserver ~]# echo "/nfs *(rw,sync,no_root_squash)" > /etc/exports
[root@nfsserver ~]# systemctl start nfs步骤 2:在每个 K8s 节点安装客户端
[root@node1 ~]# yum install nfs-utils -y步骤 3:在 Pod 中挂载 NFS
# nfs-pod.yml
apiVersion: v1
kind: Pod
metadata:
name: nfs-pod
spec:
containers:
- name: nginx
image: nginx
volumeMounts:
- name: nfsdata
mountPath: /usr/share/nginx/html
volumes:
- name: nfsdata
nfs:
path: /nfs
server: 172.16.213.230创建 Pod 并测试:
[root@master data]# kubectl apply -f nfs-pod.yml
[root@nfsserver ~]# echo "nfs test" > /nfs/index.html
[root@master data]# curl $(kubectl get pod nfs-pod -o jsonpath='{.status.podIP}')
nfs test五、使用 NFS PV 存储数据
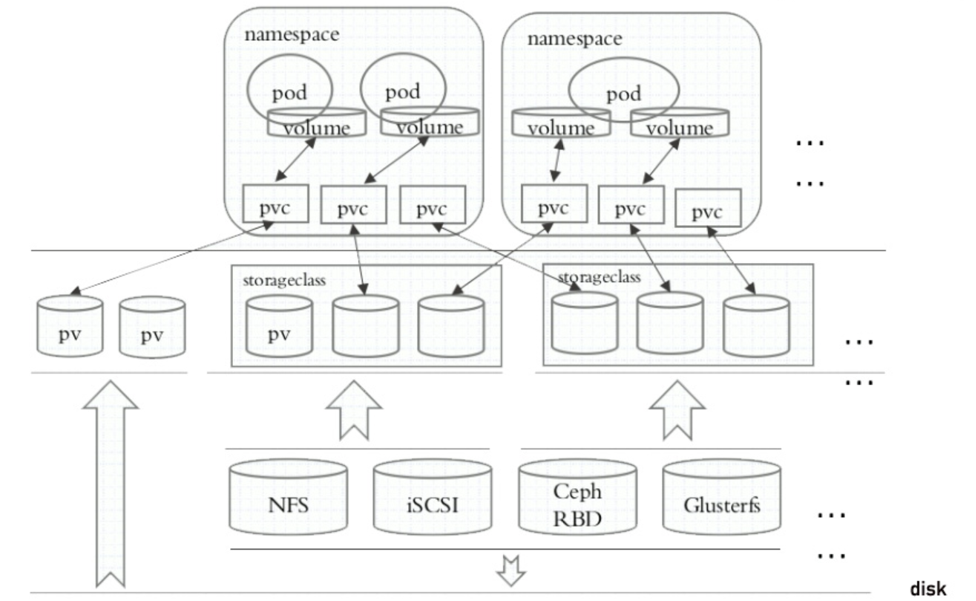
5.1 PV 和 PVC 概念
-
PersistentVolume(PV):由管理员预先创建的存储资源,是集群中的一块存储"存货",独立于任何 Pod。PV 具有持久性,生命周期与集群相当。
-
PersistentVolumeClaim(PVC):由用户(开发者)创建的存储请求,指明所需存储的大小和访问模式。Kubernetes 会根据 PVC 的要求自动匹配并绑定合适的 PV。
通过 PV/PVC,用户只需要关心"我需要多大的存储",而不用关心底层是 NFS、Ceph 还是云硬盘;管理员则负责管理真实的存储后端。
5.2 创建 PV
编写 nfs-pv1.yml,定义一个容量为 1Gi、访问模式为 ReadWriteMany 的 PV,存储后端为 NFS:
apiVersion: v1
kind: PersistentVolume
metadata:
name: mypv1
spec:
capacity:
storage: 1Gi
accessModes:
- ReadWriteMany
persistentVolumeReclaimPolicy: Recycle
storageClassName: nfs1
nfs:
path: /nfs/pv1
server: 172.16.213.230关键字段说明:
-
accessModes:支持ReadWriteOnce(单节点读写)、ReadOnlyMany(多节点只读)、ReadWriteMany(多节点读写)。 -
persistentVolumeReclaimPolicy:PV 回收策略,可选Retain(保留数据,需管理员手动处理)、Recycle(自动清理数据,即rm -rf)、Delete(删除云存储资源)。 -
storageClassName:存储类名称,用于 PVC 匹配 PV。 -
nfs:指定 NFS 服务器地址和共享路径。
创建 PV:
[root@master data]# kubectl apply -f nfs-pv1.yml5.3 创建 PVC
编写 nfs-pvc1.yml,申请 1Gi 存储空间,并使用相同的 storageClassName:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: mypvc1
spec:
accessModes:
- ReadWriteMany
storageClassName: nfs1
resources:
requests:
storage: 1Gi
volumeName: mypv1 # 可选,直接指定绑定的 PV创建 PVC 并查看绑定状态:
[root@master data]# kubectl apply -f nfs-pvc1.yml
[root@master data]# kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
mypvc1 Bound mypv1 1Gi RWX nfs1 10s
[root@master data]# kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS AGE
mypv1 1Gi RWX Recycle Bound default/mypvc1 nfs1 30s5.4 在 Pod 中使用 PVC
创建一个 Deployment,通过 persistentVolumeClaim 引用 mypvc1:
# deploy-pod2-nginx.yml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginxserver-deployment
spec:
replicas: 3
selector:
matchLabels:
app: nginxserver
template:
metadata:
labels:
app: nginxserver
spec:
containers:
- name: nginx-pod
image: nginx
volumeMounts:
- name: mynfsdata
mountPath: /usr/share/nginx/html
volumes:
- name: mynfsdata
persistentVolumeClaim:
claimName: mypvc1为方便外部访问,创建一个 NodePort Service:
# nfs-service-nginx.yml
apiVersion: v1
kind: Service
metadata:
name: service-nginx
spec:
type: NodePort
selector:
app: nginxserver
ports:
- protocol: TCP
nodePort: 31000
port: 80
targetPort: 80应用并测试:
[root@master data]# kubectl apply -f deploy-pod2-nginx.yml
[root@master data]# kubectl apply -f nfs-service-nginx.yml
[root@master data]# kubectl get svc
NAME TYPE CLUSTER-IP PORT(S) AGE
service-nginx NodePort 10.106.0.151 80:31000/TCP 55m现在,可以通过 http://<任意节点IP>:31000 访问 nginx。将文件放入 NFS 服务器的 /nfs/pv1/index.html,即可看到内容。
5.5 PV 回收策略实战
Recycle 策略示例
当 PVC 被删除时,Kubernetes 会启动一个 recycler Pod 清理 PV 中的数据,然后将 PV 状态重置为 Available:
[root@master data]# kubectl delete pvc mypvc1
[root@master data]# kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS AGE
mypv1 1Gi RWX Recycle Available nfs1 4h注意:Recycle 策略已被标记为废弃,推荐使用动态 PV 供给或 Retain。
Retain 策略示例
如果希望删除 PVC 后保留数据,可以将 PV 的回收策略设置为 Retain(创建 PV 时指定或通过 patch 修改):
persistentVolumeReclaimPolicy: Retain删除 PVC 后,PV 状态变为 Released,但数据依然保留在 NFS 服务器上。此时该 PV 不能被新的 PVC 绑定,需要管理员手动删除并重新创建 PV(删除 PV 对象不会删除后端数据):
[root@master data]# kubectl delete pv mypv2
[root@master data]# kubectl apply -f nfs-pv2.yml # 重新创建新创建的 PV 状态为 Available,可供后续 PVC 使用。
结尾
Kubernetes 的数据存储机制为容器化应用提供了灵活、持久的存储方案。从基础的 emptyDir、hostPath,到网络存储 NFS,再到解耦存储供给与消费的 PV/PVC,K8s 覆盖了从开发测试到生产环境的多种存储需求。本文通过丰富的示例,演示了每种存储类型的使用场景和配置方法,并深入讲解了 PV 的回收策略(Recycle 与 Retain)对数据生命周期的影响。
在实际生产环境中,建议:
-
对于临时、非关键的共享数据,使用
emptyDir。 -
仅当需要访问节点特定文件(如证书、设备文件)时使用
hostPath。 -
对于多节点共享的持久化数据,优先使用 NFS、Ceph 或云存储,并结合 PV/PVC 进行资源管理。
-
合理设置回收策略,避免误删重要数据;对于生产数据,推荐使用
Retain策略。
理解并熟练运用这些存储机制,将使你在 Kubernetes 中构建有状态应用时更加得心应手。