一、前置基础:从提示词工程到 Harness 工程
在讲解具体设计前,先明确两个底层认知,建立清晰的概念边界:
- 单次工具调用 ≠ 智能体(Agent)原生 Function Calling只能完成单次工具调用决策,而跨文件重构、项目级调试、长周期调研等复杂任务,需要多轮迭代、状态留存、环境交互、异常处理。仅靠提示词和单次工具调用无法支撑这类任务,这是 Harness 工程诞生的核心背景。
- Harness 的定位:Agent 的运行时控制容器Harness(直译为 "控制框架 / 挽具")是包裹在大模型外围的工程化运行框架,是「模型大脑」和「执行环境」之间的桥梁。提示词只是 Harness 中的一个组件,执行循环、工具调度、状态管理、安全沙箱、错误处理才是其核心组成部分。
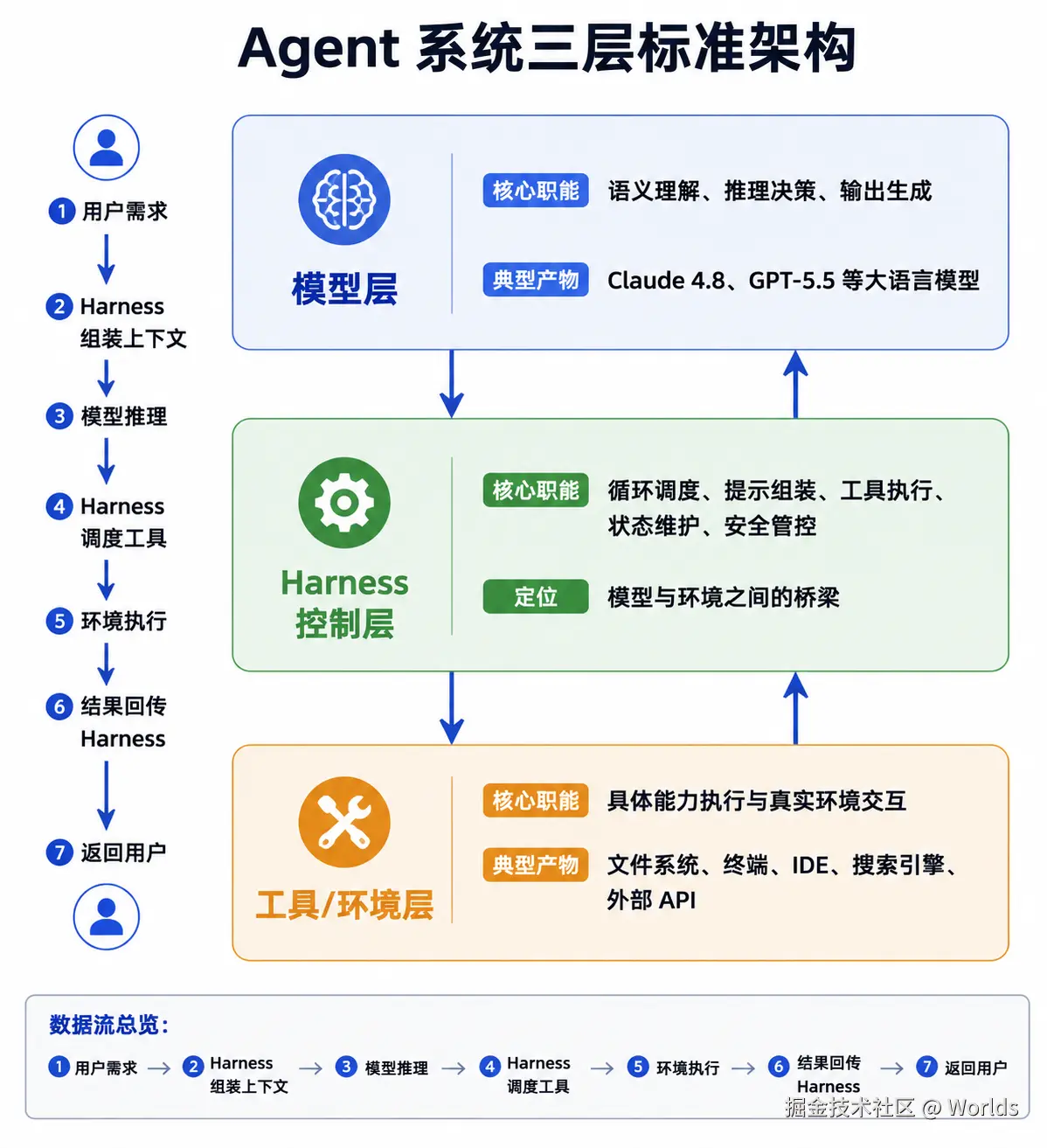
三层标准架构:
| 层级 | 核心职能 | 典型产物 |
|---|---|---|
| 模型层 | 语义理解、推理决策、输出生成 | Claude 4.8、GPT-5.5 等大语言模型 |
| Harness 控制层 | 循环调度、提示词组装、工具执行、状态维护、安全管控 | Claude Code、Codex 的核心运行框架 |
| 工具 / 环境层 | 具体能力执行与环境交互 | 文件系统、终端、IDE、搜索引擎、外部 API |
二、核心概念:什么是 Agent Harness,他与大模型的区别是什么。
2.1 定义
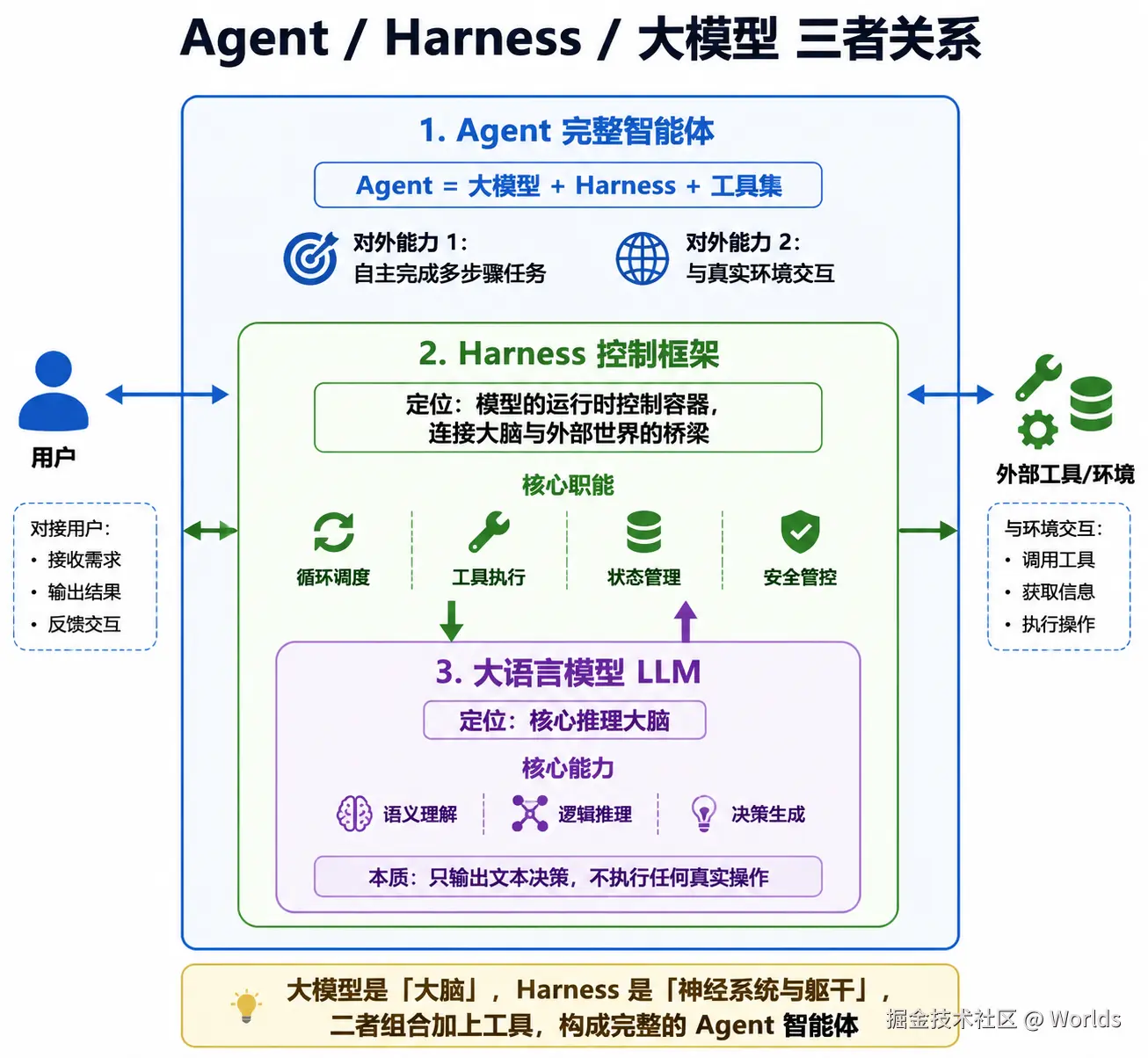
Agent Harness 是管理智能体完整执行生命周期的运行时控制框架。它通过标准化的执行循环串联模型推理、工具调用、结果反馈、状态流转,将大模型的开放式语义决策能力,转化为可预测、可控制、可落地的真实操作。
通俗理解:如果大模型是 Agent 的大脑,Harness 就是躯干与神经系统 ------ 负责接收大脑指令、调动手脚执行、回传感官信息、控制行为节奏、约束安全边界。
2.2 底层原理
Harness 的核心逻辑是状态机 + 执行闭环:
- 将 Agent 运行过程拆解为标准状态:思考、工具调用、等待结果、任务完成、异常中断
- 按照固定执行循环(如 ReAct 范式的思考 - 行动 - 观察)驱动状态流转
- 模型只负责输出决策内容,所有落地执行、异常处理、上下文维护都由 Harness 完成
本质是把模型的开放式生成,约束为工程化、可管控的流程,解决大模型随机性强、不可控、难落地的问题。
2.3 具象示例
以 Claude Code 重构项目代码为例,完整执行链路:
- 用户输入需求 → Harness 动态组装上下文:身份规则 + 工具说明 + 项目结构 + 用户需求,送入模型
- 模型输出读取目标文件的工具调用 → Harness 解析指令、校验路径权限、调用文件读取工具
- 读取完成后,Harness 将文件内容格式化后注入上下文,再次调用模型
- 模型输出修改文件的指令 → Harness 生成 diff 预览,判断是否需要用户确认
- 确认后执行修改,将执行结果回传模型,模型判断是否需要继续迭代
- 全部完成后,模型输出总结,Harness 终止循环并输出结果
整个过程中,模型只做推理决策,所有文件操作、权限校验、流程控制、状态留存都由 Harness 完成。
2.4 核心价值
- 稳定性:约束模型输出格式与执行流程,降低随机性带来的失败率
- 安全性:所有外部操作经过统一权限校验与沙箱隔离,规避误操作风险
- 可维护性:规则、工具、逻辑都在 Harness 层管理,无需频繁调整模型
- 可扩展性:新增工具、能力只需在 Harness 层接入,无需改动模型本身
三、Harness 的五大核心模块
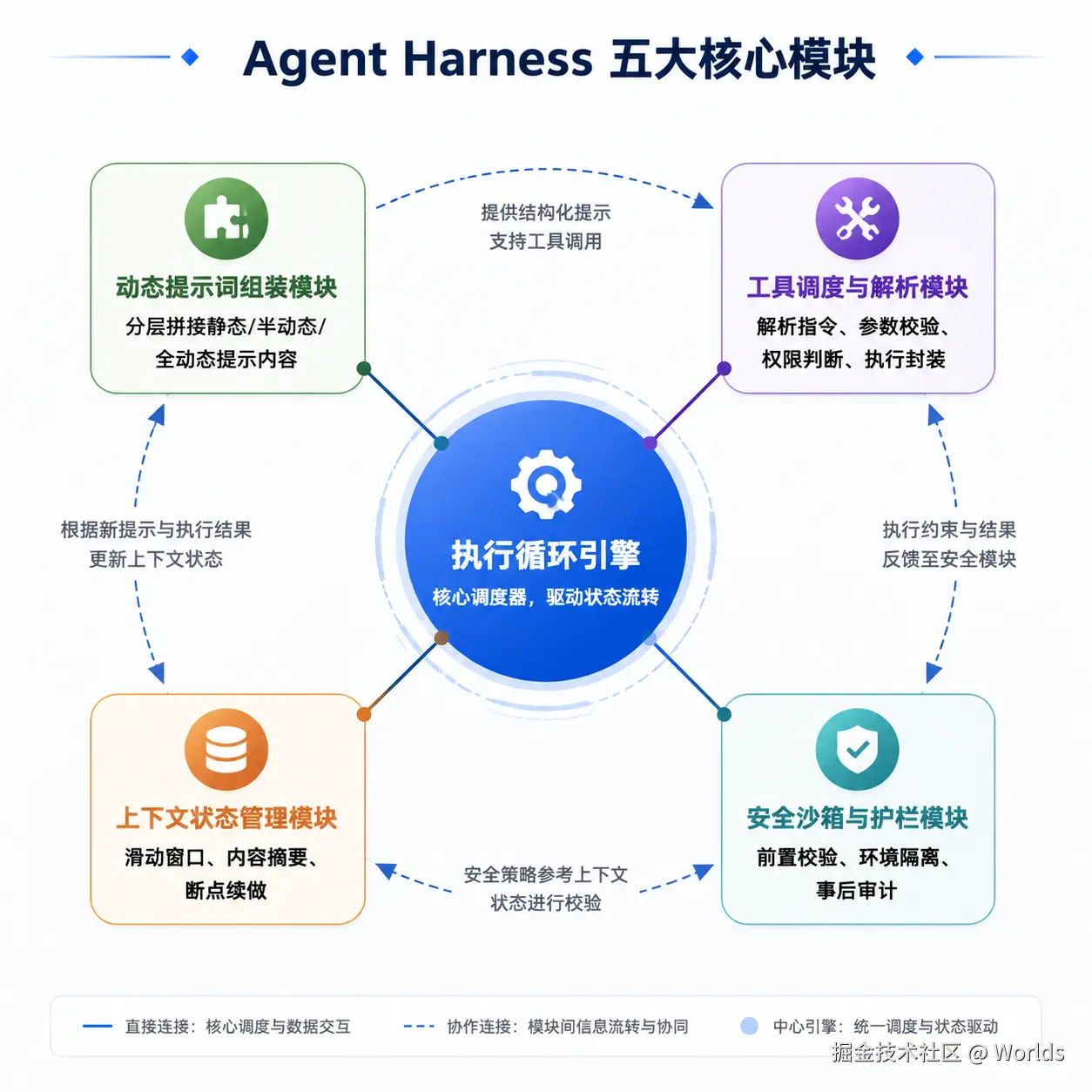
3.1 动态提示词组装模块
定义
负责根据当前场景,分层、动态拼接完整的提示词体系,而非使用固定单段系统提示,是 Harness 中直接影响模型行为的核心模块。
底层原理
采用分层拼接 + 分级缓存架构,不同层级的提示词生命周期、缓存策略不同:
- 静态全局层:身份定位、核心准则、安全边界,全程不变,可全局缓存复用
- 半动态场景层:可用工具列表、输出格式规范、领域规则,按场景加载
- 全动态环境层:当前环境状态、文件内容、执行结果、用户上下文,每轮更新
以 Claude Code 为例,其系统提示词本质是一个分段数组,通过边界标记区分静态与动态部分,静态部分支持全局缓存,大幅降低 Token 消耗。
具象示例
标准分层提示词结构:
plaintext
[静态身份层]
你是资深全栈工程师,擅长软件工程与代码重构,严格遵循工程最佳实践。
[半动态工具层]
你可以使用以下工具:
1. read_file:读取文件,参数 file_path
2. write_file:写入文件,参数 file_path, content
3. run_command:执行终端命令,参数 command, cwd
输出要求:工具调用必须包裹在<tool_call>标签中。
[全动态环境层]
工作目录:/project
当前文件:src/app.js
Git状态:2个文件未提交
历史执行结果:npm run build 执行失败,错误信息:xxx设计要点
- 工具按需加载,避免全量工具占用上下文窗口
- 环境信息精简,只保留与当前任务强相关的内容
- 静态内容前置,利用模型的提示词缓存机制降低成本
3.2 执行循环引擎
定义
Harness 的核心调度器,负责驱动 Agent 的多轮执行流程,控制状态流转、终止条件与异常处理。
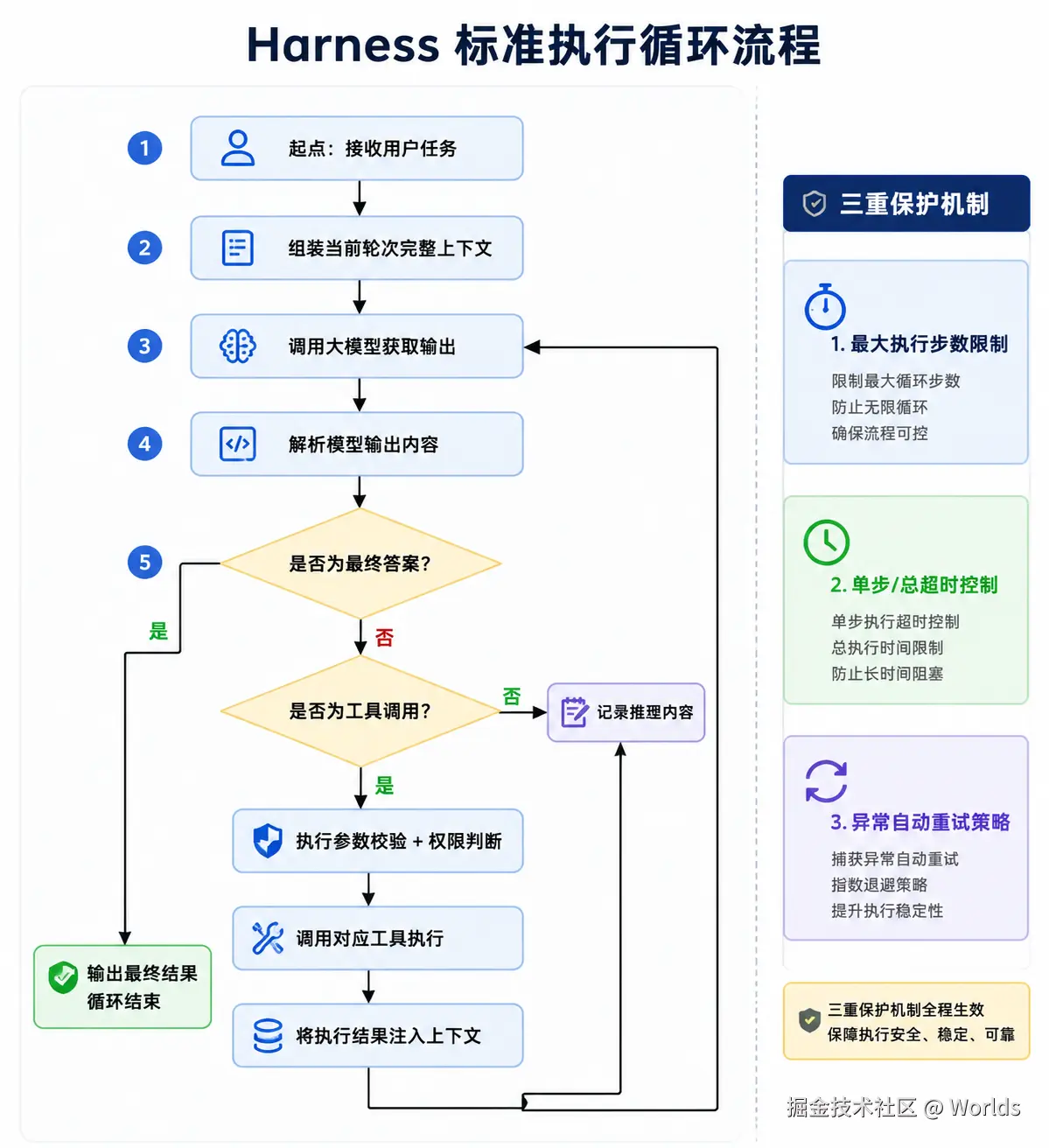
底层原理
基于扩展 ReAct 范式的状态机循环,标准执行流程:
- 组装当前轮次完整上下文,调用大模型
- 解析模型输出,判断状态:结束任务 / 调用工具 / 继续思考
- 若调用工具,执行后将结果注入上下文,回到第 1 步
- 若结束任务,输出最终结果,终止循环
同时内置三重保护机制:
- 最大执行步数:防止无限循环消耗 Token
- 单步 / 总超时:防止工具卡死、任务超时
- 异常重试:瞬态错误自动重试,可恢复错误返回模型自行修正
具象示例
Codex CLI 的执行循环伪代码:
python
max_steps = 20
for step in range(max_steps):
# 组装上下文,调用模型
response = llm.responses.create(context)
# 解析输出项
for item in response.output_items:
if item.type == "reasoning":
context.add_reasoning(item.content)
elif item.type == "tool_call":
# 路由到工具执行器,校验权限
result = tool_router.execute(item.tool, item.params)
context.add_observation(result)
elif item.type == "final_answer":
return item.content应用场景
所有长周期、多步骤的 Agent 任务,如代码重构、问题排查、自动化调研等。
3.3 工具调度与解析模块
定义
负责解析模型的工具调用指令,完成参数校验、权限判断、工具执行与结果格式化。
底层原理
模型只输出语义化的调用指令,Harness 负责工程化落地,流程分为四步:
- 格式解析:从模型输出中提取结构化的工具名与参数(XML/JSON 标签)
- 参数校验:校验参数类型、取值范围、路径合法性,拦截非法输入
- 权限分级:按工具风险等级执行不同审批策略:无风险自动执行、低风险静默执行、高风险用户确认
- 执行封装:调用对应工具,统一格式化输出结果与错误信息,注入上下文
以 Codex 为例,其 ToolRouter 模块内置三级审批模式:自动模式(读写本地文件自动执行)、只读模式、全确认模式,适配不同安全等级场景。
具象示例
模型输出:
xml
<tool_call>
{"name": "run_command", "params": {"command": "npm run build"}}
</tool_call>Harness 处理流程:
- 解析出工具
run_command,参数npm run build - 校验命令在白名单内,判断属于工作目录内操作,自动执行
- 沙箱环境执行命令,捕获标准输出与错误,记录执行时长
- 格式化后注入上下文:
xml
<observation status="success">
命令执行完成,输出:
> build success, 120 modules compiled
</observation>设计要点
- 所有工具执行必须设置超时,避免卡死
- 错误信息要清晰可定位,方便模型自我修正
- 危险操作必须留痕,支持审计与回滚
3.4 上下文状态管理模块
定义
负责维护 Agent 全生命周期的所有状态信息,动态管理上下文窗口,避免溢出并保障关键信息不丢失。
底层原理
分类管理信息,采用差异化保留策略:
- 永久保留:系统规则、工具定义、核心任务目标
- 优先保留:最近 3-5 轮的工具调用与结果
- 可压缩:更早的历史、大段文件内容,做摘要压缩
- 实时更新:环境状态、文件快照,每轮同步最新值
进阶方案:当上下文接近上限时,调用模型压缩接口生成加密的隐状态摘要,替代原始文本,既节省窗口又保留语义信息(如 Codex 的 /responses/compact 端点)。
核心能力
- 滑动窗口裁剪:自动裁剪久远的非关键信息
- 大内容摘要:长文件、长输出自动提取关键信息
- 断点续做:支持任务中断后恢复,基于检查点继续执行
应用场景
跨文件重构、复杂问题排查、长周期调研等需要长上下文的任务。
3.5 安全沙箱与护栏模块
定义
负责所有外部操作的安全管控,隔离执行环境,从机制上规避风险。
底层原理
采用「前置校验 + 环境隔离 + 事后审计」三层防护:
- 前置校验:参数合法性、操作权限、危险指令拦截
- 环境隔离:代码、命令在沙箱中运行,限制文件访问范围、网络权限
- 事后审计:所有工具操作全量日志记录,可追溯、可回滚
OpenAI 在 Codex 中进一步分为两层质量控制:
- 计算层控制:Linter、类型检查、结构测试,确定性快速校验
- 推理层控制:LLM 代码评审、语义验证,深度质量把控
具象示例
Claude Code 的安全机制:
- 文件操作限制在指定工作目录,禁止访问上级目录
- 删除文件、执行高危终端命令前,强制用户二次确认
- 自动拒绝权限外的操作,并不机械重试被驳回的指令
四、典型产品 Harness 设计案例

4.1 Claude Code:强约束分层式代码 Agent Harness
设计定位
面向终端与编辑器的代码智能体,主打深度工程化操作与稳定可控的执行体验。
核心 Harness 设计
-
分层提示词架构
- 静态层:身份定义、行为准则、安全规则,全局缓存复用
- 动态层:环境信息、MCP 工具、会话偏好,每轮动态组装
- 采用 XML 标签强约束输出格式,解析准确率极高
-
循环执行引擎
- 基于 while-loop 的无限步迭代,内置步数提醒与成本预估
- 支持用户中途打断、插入新指令,动态调整任务目标
- 以 Git 提交作为检查点,支持回滚与进度恢复
-
分级工具体系
- 覆盖文件读写、终端执行、Git 操作、搜索预览等全链路开发工具
- 按风险等级分级审批,低风险操作自动执行,高风险强制确认
差异化特点
- 提示词向精简化演进:新版已精简 80% 系统提示词,依赖模型原生能力而非冗余规则
- 环境感知能力强,自动同步项目结构与状态,按需加载相关上下文
4.2 OpenAI Codex:多端统一的生产级 Harness
设计定位
多端共享的代码智能体核心框架,支撑 CLI、Web、VS Code、桌面端等所有产品形态,一次开发多端生效。
核心 Harness 设计
-
统一共享 Harness
- 所有端复用同一套核心逻辑:Agent 循环、工具执行、权限、认证
- 通过 JSON-RPC 协议对外暴露能力,各端只需实现客户端 UI
- 功能迭代一次发布,全端同步生效
-
高效的上下文与缓存设计
- 静态内容(规则、工具)固定放在提示词最前端,最大化缓存命中率
- 工具顺序严格固定,避免顺序变动导致缓存失效
- 上下文溢出时调用压缩接口生成隐状态摘要,兼顾隐私与效率
-
双层质量护栏
- 计算层:Linter、类型检查、结构测试,确定性快速校验
- 推理层:LLM 代码评审、语义合规检查,深度质量把控
- 三级审批模式:自动、只读、全确认,适配不同安全场景
差异化特点
- 架构上优先考虑多端复用与工程效率,是大规模落地的生产级方案
- 深度结合 Responses API,执行循环与模型输出事件深度联动,流式体验流畅
五、常见认知误区
-
误区一:Harness 就是写一段高质量的 System Prompt
纠正:提示词组装只是 Harness 五大核心模块之一,占工程复杂度不到 20%。执行循环、工具调度、状态管理、安全沙箱才是 Harness 的核心,决定了 Agent 的稳定性、安全性与可用性。很多 Agent 效果不好,问题不在提示词,而在执行与状态管理的缺失。
-
误区二:系统提示词越长、规则越细,效果越好
纠正:新一代强模型的趋势恰恰相反。Claude Code 新版已将系统提示词精简 80%,冗余的规则和示例反而会限制模型能力、引入噪声。提示词的核心是清晰的边界与格式约束,而非事无巨细的规定。
-
误区三:模型自带工具调用,不需要 Harness
纠正:模型原生的 Function Calling 只是输出结构化调用指令,没有执行循环、没有参数校验、没有异常处理、没有安全控制、没有状态管理。没有 Harness 的封装,工具调用只能完成单次简单操作,无法支撑复杂多轮的 Agent 任务。
-
误区四:一套 Harness 可以适配所有 Agent 场景
纠正:不同领域的 Harness 设计差异极大。代码 Agent 的 Harness 侧重文件管理、沙箱执行;客服 Agent 侧重知识库对接、工单系统集成;数据 Agent 侧重数据库查询、图表生成。核心模块的逻辑、工具体系、安全规则完全不同,无法通用。
六、实操设计建议
6.1 提示词设计原则
- 分层组装:固定规则层、动态工具层、实时环境层分离,不要写死在单段文本
- 强格式约束:用 XML 或 JSON 标签强制结构化输出,降低解析错误率
- 静态前置:不变内容放在提示词最前端,最大化利用模型缓存能力
- 精简克制:规则清晰即可,不要堆砌冗余约束,强模型更依赖引导而非限制
6.2 执行循环设计原则
- 设置硬上限:必须配置最大执行步数、单步超时、总任务超时,避免无限消耗 Token
- 分级错误处理:瞬态错误自动重试,可恢复错误返回模型自行修正,严重错误中断并告知用户
- 支持人工介入:允许用户随时打断、修改需求、确认高危操作
6.3 工具设计原则
- 粒度适中:单一工具完成单一独立动作,不要过碎也不要过于笼统
- 错误友好:工具返回的错误信息要清晰、可定位,方便模型自我修正
- 安全分级:按风险等级分为无风险、低风险、高风险,对应不同确认机制
- 按需加载:根据当前场景动态加载相关工具,不要一次性全量塞入上下文
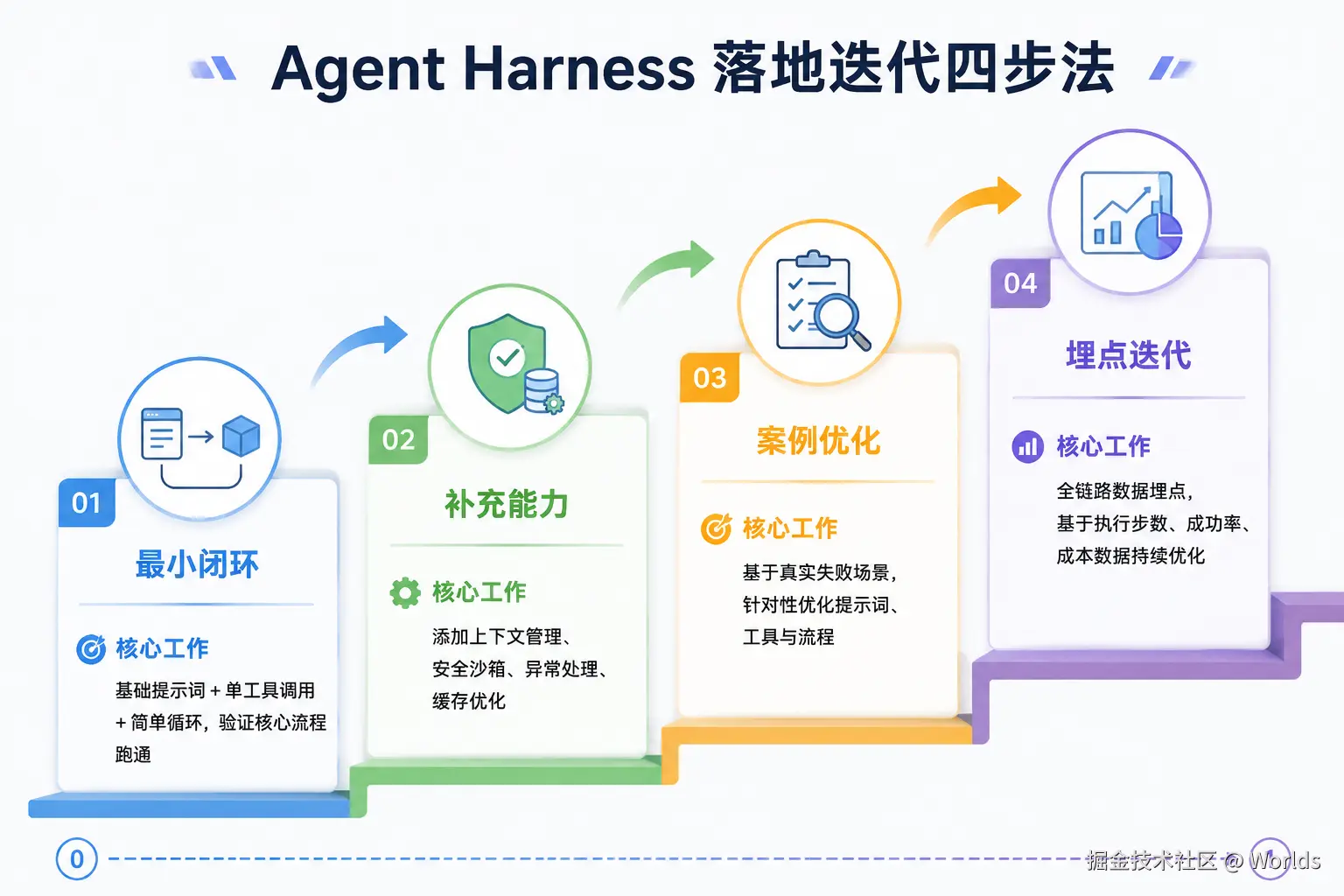
6.4 落地迭代路径
- 最小闭环先行:先实现基础提示词 + 单工具调用 + 简单循环,验证核心流程跑通
- 逐步补充能力:依次添加上下文管理、安全沙箱、异常处理、缓存优化
- 基于真实失败案例优化:根据实际使用中的失败场景,针对性优化提示词与工具设计
- 埋点监控:记录执行步数、Token 消耗、成功率、错误类型,数据驱动持续迭代