一个函数最会骗人的时刻,往往不是它报错的时候。
而是它看起来完全正确的时候。
变量名清楚,逻辑顺滑,样例也能跑通。你把它贴进项目里,心里甚至会冒出一点轻松感:这次模型写得还不错。直到一个空列表、一个重复元素、一个边界阈值突然出现,代码才露出真正的裂缝。
这就是代码生成和自然语言生成最大的不同。
一段回答写得像人话,不代表它有事实;一段代码写得像工程师,不代表它能通过执行。代码世界里,漂亮不是证据,测试才是证据。
AgentCoder 这篇 2023 年的工作,放到今天看反而更有意思。它没有把编程 Agent 想象成一个更会聊天的"超级程序员",而是回到软件工程里最朴素的一条纪律------写完代码,先过测试。
一个 Agent 写代码,一个 Agent 专门设计测试,一个执行器负责跑测试并把错误反馈回去。
这不是让 Agent 更多嘴。
这是让 Agent 先学会交作业。
1.代码生成最大的问题,不是不会写,而是不会验
大模型写代码的能力已经相当惊人。
你给它一个函数说明,它能很快吐出 Python 代码;你让它解释算法,它也能把思路拆得像模像样。HumanEval、MBPP 这类基准,过去几年几乎成了代码模型的"高考卷"。
但真实开发里,写出第一版代码只占一半。
另一半是验证。
为什么?因为代码的错误经常藏在正常样例之外。空列表、重复元素、极大输入、边界阈值、类型异常,这些东西不会主动跳出来提醒你。它们更像地板下面的裂缝,平时看不见,一踩重就塌。
单智能体自我修正路线,比如 Self-Edit、Self-Debugging、Reflexion,已经意识到这个问题。它们会让模型看错误、改代码、再尝试。问题在于,很多方法依赖已有测试或模型自己临时想几个样例,反馈质量并不稳定。
如果测试本身很弱,修正就会变成"对着假靶子练枪"。
多智能体路线看起来更像软件公司。MetaGPT、ChatDev、AgentVerse 这类框架会安排多个角色,让它们模拟需求分析、架构设计、编码、评审等流程。这个方向很有想象力,但也带来另一个代价------角色一多,沟通 token 就会膨胀。
团队越大,不一定越会写代码。
它的定位很清楚。
不是模拟一个完整软件公司,而是用最少角色抓住代码生成的关键瓶颈:测试反馈。
2.AgentCoder的结构:三个角色,一条闭环
AgentCoder 的系统设计非常克制。
它只有三个角色:Programmer agent、Test designer agent、Test executor agent。翻译成人话,就是写代码的人、出测试题的人、监考并判卷的人。
这套三角关系在图1里画得很直观:需求先进入程序员 Agent,同时测试设计 Agent 独立生成测试,最后由执行器把代码和测试放进真实环境里跑一遍。
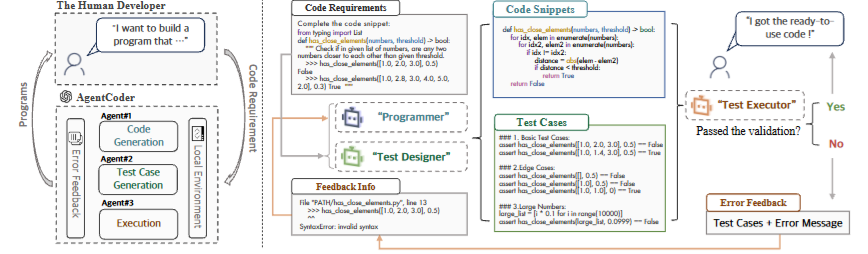
图1
图1:AgentCoder 的整体流程。它展示的不是"多个 Agent 聊天",而是"代码生成-测试设计-执行反馈"的闭环。
这个结构看似朴素,但关键点在"独立"两个字。
Programmer agent 负责根据自然语言需求生成代码。它被提示按照 Chain-of-Thought 的方式模拟正常编程流程:先理解问题,再选择算法,再写伪代码,最后生成代码。
这像一个程序员先在脑子里打草稿。
Test designer agent 不看完整代码,而是根据任务需求设计测试。论文要求它覆盖三类场景:basic tests(基本功能测试)、edge tests(边界场景测试)、large scale tests(大规模输入测试)。
这像考试出题人先看教学大纲,而不是看学生答案。
Test executor agent 更特殊。它不是大模型,而是一个 Python 脚本。它把代码和测试拿到本地环境里执行,观察终端返回的信息。如果全部通过,就把代码交给用户;如果失败,就把错误信息返回给 Programmer agent,让它继续修。
这一步把"语言判断"变成了"执行判断"。
为什么这很重要?因为大模型很擅长解释,也很擅长自信地解释错。执行器不跟你辩论。能跑就是能跑,报错就是报错。
一句大白话总结就是------AgentCoder 把代码生成从"口头承诺"拉回了"现场验收"。
3.测试设计Agent,才是这套系统的灵魂
很多人看到 AgentCoder,第一反应可能是:不就是写代码、写测试、跑测试吗?
没错,但难点恰恰在这里。
如果测试写得太简单,模型只要通过几个普通样例,就会以为代码已经正确。比如一个排序函数,只测 [3, 1, 2],确实能抓到一部分问题。但空列表呢?重复元素呢?已经有序的列表呢?超大输入呢?
测试不是装饰品。
测试是给模型设下的"现实摩擦"。
AgentCoder 的 Test designer agent 被明确要求生成三类测试。第一类是基本测试,确保功能在正常条件下可用。第二类是边界测试,专门挑战不常见输入。第三类是大规模测试,用来观察代码在更大输入下是否还能保持正确性和性能。
这就像你训练一个厨师,不能只让他炒一盘标准分量的菜。你还要看他处理少盐、多人份、临时缺材料、火候变化时会不会乱。
更关键的是,AgentCoder 不让测试设计 Agent 看完整代码。
为什么?因为看了代码,测试就可能被代码带偏。
如果程序员 Agent 忽略了某个边界条件,同一个对话里的测试也可能顺着这个盲点走。模型会在自己的错误周围打转,像学生先写答案再给自己出题,最后出的题刚好避开自己不会的地方(这就很危险)。
论文在 RQ6 里专门验证了这一点。
这个判断不是作者拍脑袋。论文直接把"一个 Agent 同时写代码和测试"与"代码 Agent、测试 Agent 分开"做了对比。
单个 Agent 同时写代码和测试,在 HumanEval 上 pass@1 只有 71.3%,MBPP 上是 79.4%。把代码生成和测试生成拆成不同 Agent 后,HumanEval 提升到 79.9%,MBPP 提升到 89.9%。

表1
表1:单 Agent 与多 Agent 的代码生成效果对比。HumanEval 从 71.3% 提升到 79.9%,MBPP 从 79.4% 提升到 89.9%,说明角色拆分本身就带来了明显收益。
测试准确率的差距更刺眼。
更关键的是,拆分角色不只是让代码结果更好,也让测试本身更可靠。
单 Agent 生成的测试,在 HumanEval 和 MBPP 上准确率分别只有 61.0% 和 51.8%。多 Agent 设置下,这两个数字变成 87.8% 和 89.9%。
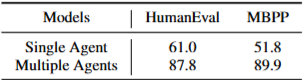
表2
表2:单 Agent 与多 Agent 生成测试的准确率对比。单 Agent 在 MBPP 上只有 51.8%,多 Agent 设置下提升到 89.9%。这说明"自己写代码、自己出题"确实会带来偏差。
这说明测试角色不是锦上添花。
它是系统能不能真正闭环的前提。
4.执行器的价值:把反馈从"感觉"变成"证据"
大模型编程里有一个很容易被低估的环节:执行。
人类程序员为什么离不开单元测试和 CI?因为代码审美不等于代码正确。你觉得这段逻辑合理,解释器未必买账;你觉得所有情况都考虑了,测试用例会把漏掉的角落拎出来。
AgentCoder 的 Test executor agent 就负责做这件事。
它拿到 Programmer agent 的代码和 Test designer agent 的测试,在本地终端运行。如果出现 syntax error、runtime error 或测试断言失败,它不会泛泛地说"请改进代码",而是把具体错误信息反馈给程序员 Agent。
这像医生看片子。
没有检查报告时,你只能说"可能哪里不舒服";有了报告,就能定位到具体指标。编程 Agent 也是一样。没有执行反馈,它只能靠语言自省;有了错误信息,它才知道该修哪一段。
论文的消融实验把这一点拆得很清楚。
如果只看最终效果,我们很难知道到底是谁在起作用。表3的价值就在这里:它把程序员、测试设计、执行反馈三个角色拆开看。
只用 programmer agent,在 HumanEval、HumanEval-ET、MBPP、MBPP-ET 上分别是 61.0%、52.4%、47.9%、35.0%。加上 test designer 但没有 executor,HumanEval 只到 64.0%,MBPP 到 62.3%。加上 executor 但没有新的测试设计,HumanEval 是 64.6%,MBPP 是 69.3%。
完整 AgentCoder 呢?
79.9%、77.4%、89.9%、89.1%。

表3
表3:不同 Agent 组合的贡献。只加测试设计或只加执行器都有提升,但完整 AgentCoder 才出现真正跃迁,说明高质量测试和真实执行反馈必须同时存在。
这组数字的意思很直接。
测试设计提供高质量题目,执行器提供真实判分,程序员 Agent 负责根据判分改答案。三者缺一个,闭环都会漏气。
旧路线常见的问题是,把"反馈"理解成模型的一段评论。AgentCoder 的反馈不只是评论,而是运行结果。它不是让模型多想一遍,而是让代码真的跑一遍。
这是一个重要区别。
5.迭代修正:代码不是一次生成,而是一轮轮过测试
AgentCoder 不是只跑一次。
它会进入迭代:生成代码,跑测试,失败就带着错误信息修复,再跑测试,直到通过测试或达到设定轮数。
这个过程很像真实开发。
没有哪个靠谱工程师会把第一版代码写完就直接上线。更常见的节奏是:写一点,跑一下;报错,改一下;边界不对,再补一下。代码质量不是凭空长出来的,而是在反馈里磨出来的。
论文在 RQ3 里测试了迭代次数的影响。
迭代的价值,可以直接从表4里看出来。随着测试-修复轮数增加,AgentCoder 不是原地打转,而是在四个数据集上持续变好。
在 GPT-3.5-turbo 上,当迭代次数从 1 增加到 5,HumanEval 的 pass@1 从 74.4% 提升到 79.9%;HumanEval-ET 从 73.2% 提升到 77.4%;MBPP 从 84.1% 提升到 89.9%;MBPP-ET 从 80.3% 提升到 89.1%。
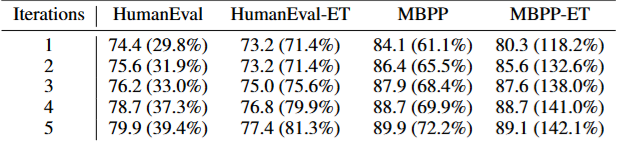
表4
表4:不同迭代次数下的 pass@1。尤其是 MBPP-ET,从 80.3% 提升到 89.1%,说明执行反馈能不断逼出更稳的代码。
这里最值得注意的是 MBPP-ET。
它是增强版测试集,比普通 MBPP 更难。一次迭代时是 80.3%,五次迭代后到 89.1%。这说明 AgentCoder 对更严苛测试不是完全失灵,反而能通过多轮修复逐步吃下复杂边界。
当然,迭代不是免费午餐。
每多一轮,都要多消耗 token 和执行时间。AgentCoder 的聪明之处在于,它没有用五个、七个、十几个 Agent 堆排场,而是把循环压在三个关键角色里。
多 Agent 的未来,不一定是角色越多越好。
更可能是角色越准越好。
6.实验结果:GPT-4拿到96.3% HumanEval,但成本反而更低
一句话概括实验结果:AgentCoder 在论文测试的 14 个 LLM 和 16 个优化基线上,整体表现非常强,尤其在 GPT-4 和 GPT-3.5-turbo 上拉开了明显差距。
先看 GPT-4。
论文最核心的结果集中在表5。它把 AgentCoder 和零样本模型、单 Agent 优化方法、多 Agent 框架放在同一张表里比较。
AgentCoder(GPT-4) 在 HumanEval 上达到 96.3% pass@1,在 MBPP 上达到 91.8%。对应的对比是,已有最强多智能体或优化方法在 HumanEval 上是 90.2%,在 MBPP 上是 78.9%。
这不是小修小补。
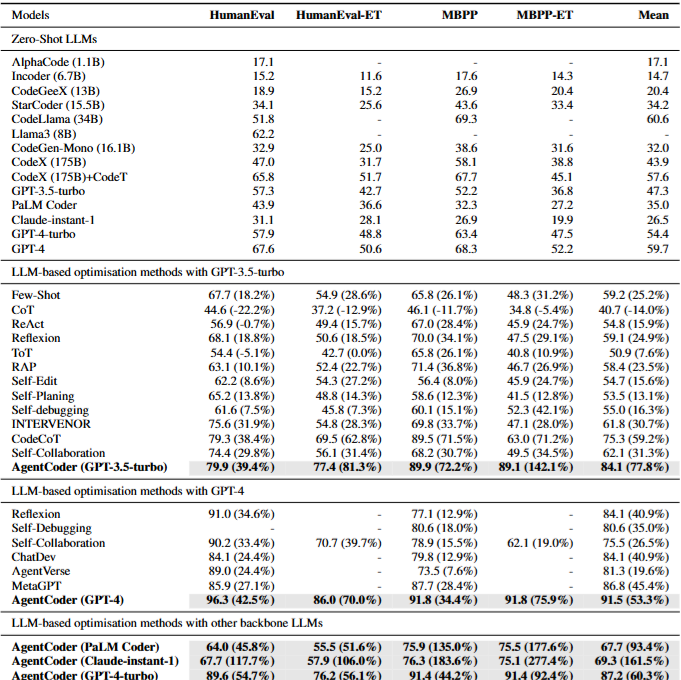
表5
表5:AgentCoder 与各类基线的端到端结果。AgentCoder(GPT-4) 在 HumanEval 上达到 96.3%,在 MBPP 上达到 91.8%;AgentCoder(GPT-3.5-turbo) 在 MBPP-ET 上达到 89.1%,明显高于 CodeCoT 的 63.0%。
再看 GPT-3.5-turbo。
零样本 GPT-3.5-turbo 在 HumanEval 上是 57.3%,AgentCoder 把它推到 79.9%。在 MBPP-ET 上,零样本是 36.8%,AgentCoder 是 89.1%。同一张表里,CodeCoT 在 MBPP-ET 上是 63.0%。
差距一下就有了直觉。
但 AgentCoder 更有意思的地方,是成本。
如果只看效果,AgentCoder 已经很强;但表6 进一步说明,它不是靠堆 Agent、堆 token 换来的。
很多多智能体系统效果提升后,token 账单也跟着暴涨。AgentVerse 在 HumanEval/MBPP 上使用 149.2K/193.6K tokens,ChatDev 是 183.7K/259.3K,MetaGPT 是 138.2K/206.5K。
AgentCoder 是 56.9K/66.3K。

表6
表6:GPT-4 下 AgentCoder 与多智能体基线的 token 和执行开销。AgentCoder 用 56.9K/66.3K tokens 达到 96.3%/91.8%,而 MetaGPT 使用 138.2K/206.5K tokens,效果反而更低。
这意味着什么?意味着 AgentCoder 的优势不只是"会做题",还包括"少开会"。
很多 Agent 框架的问题,是把协作做成了大量角色之间的文本沟通。看起来像公司,实际像会议。AgentCoder 则把沟通压缩到任务链条上:代码、测试、执行结果。
软件工程里,最有价值的沟通往往不是长篇讨论。
是失败的测试用例。
7.为什么测试能赢?因为它比自我解释更客观
把 AgentCoder 放到更大的研究版图里,它其实站在三条路线的中间。
第一条是单 Agent 自我修正。优势是简单、便宜、容易接入现有模型;缺陷是反馈容易停留在语言层面。模型说"我发现了问题",不代表问题真的被测试覆盖。
第二条是链式推理和规划路线,比如 CoT、ToT、RAP。优势是让模型更会分解问题;缺陷是分解得再漂亮,也不自动等于代码可运行。推理链能解释意图,不能替代执行。
第三条是大型多智能体软件公司路线。优势是角色丰富,能模拟复杂开发流程;缺陷是沟通成本高,测试反馈未必足够强。角色越多,越容易把工程问题变成聊天问题。
AgentCoder 的位置很微妙。
它没有否定多智能体,而是把多智能体收缩到最关键的三角形:生成、测试、执行。它没有否定推理,而是让推理必须接受测试校验。它也没有否定自我修正,而是把修正建立在真实错误信息上。
这就是它的平衡点。
测试准确率和覆盖率进一步解释了为什么这条路有效。AgentCoder(GPT-4) 的测试准确率在 HumanEval 和 MBPP 上分别是 89.6% 和 91.4%,高于 MetaGPT(GPT-4) 的 79.3% 和 84.4%。在线覆盖率上,AgentCoder(GPT-4) 达到 91.7% 和 92.3%,MetaGPT 是 81.7% 和 80.5%。
这里可以不急着再堆大表,但如果要把"测试质量"讲得更实,表7和表8是最好的证据。

表7

表8
表7:测试用例准确率对比。AgentCoder 的测试不是数量堆出来的,而是更可靠。
表8:测试代码行覆盖率对比。AgentCoder 更能覆盖真实解法里的代码路径。
准确率解决"测试别乱判"的问题。
覆盖率解决"测试别漏判"的问题。
这两个指标合在一起,才构成可靠反馈。只准确但覆盖窄,模型会漏掉边界;覆盖广但测试 oracle 错,模型会被带偏。AgentCoder 真正做对的,是把测试设计从代码生成里剥离出来,让测试更像外部审查。
这在代码 Agent 里非常关键。
因为编程不是让模型相信自己写对了,而是让环境无法反驳它。
8.编程Agent的下一步,不是更会说,而是更会被检验
AgentCoder 的贡献可以用一句话压缩:它把代码生成从"单次回答任务"改造成了"测试驱动的多智能体闭环"。
这件事的意义不在于三个 Agent 这个数字。
数字不重要,职责边界才重要。
Programmer agent 负责创造候选解,Test designer agent 负责制造压力,Test executor agent 负责把压力变成证据。三者组成的不是热闹的 Agent 社会,而是一条很工程化的验证流水线。
它也有边界。
AgentCoder 的实验主要围绕 Python 代码生成基准,离大型真实工程还有距离。真实仓库里有跨文件依赖、环境配置、隐藏状态、第三方库版本、长期维护成本,这些问题不会被几个函数级测试完全覆盖。
但方向已经很清楚。
未来的编程 Agent,很可能会沿着三条路继续演化:第一,测试设计会更贴近真实仓库,而不只是函数级样例;第二,执行器会接入更完整的 CI、静态分析、覆盖率和安全扫描;第三,Agent 之间的协作会从"聊天式分工"转向"证据式分工"。
也就是说,Agent 不只是要会写。
它要会被测、会被打回、会根据失败重新组织代码。
如果说过去的代码模型像一个很会答题的学生,AgentCoder 展示的就是另一种方向:让学生坐进真实考场,先写答案,再跑测试,错了就改,直到答案经得起执行环境的冷脸。
编程智能的成熟,不是模型终于敢说"我会了"。
而是测试终于点头说"它过了"。