最近有一点时间了,于是便开始做以前自己想做但是没有完成的事情。之前我其实就一直想写一个通用一点的告警推送组件,把项目里的异常信息、慢请求、状态码异常、JVM 指标,甚至数据库慢 SQL 这些内容统一收集起来,然后直接推送到飞书、钉钉、企业微信这类 IM 工具里。
这样做有两个好处,一个是出了问题能第一时间知道,另一个是后面如果再结合 Prometheus、Grafana,甚至再结合 OpenClaw 这类智能体去做自动处理,整个链路就能慢慢闭环起来。
所以这次我把它重新整理了一下,做成了一个可以直接接入 Spring Boot 项目的 starter,名字叫 pcm-prometheus-alert。
本文就来介绍一下这个项目是做什么的,有哪些功能,怎么使用,以及在业务里可以怎么落地。
项目地址:
先简单说下它解决的问题。
我们平时做项目,最怕的其实不是报错,而是报错了没人知道。很多时候服务已经异常了,接口已经慢了,线程已经堆起来了,但是如果没有专门去看日志、看监控,就很容易错过。
所以我做这个项目的目的很明确,就是让业务项目只需要引入一个 starter,再配一个 webhook 地址,就能具备基础的告警推送能力。
目前它主要支持下面这些能力:
- 自动捕获未处理异常并推送告警
- 统计慢请求并推送告警
- 监控 HTTP 状态码,比如 500、502、503、504
- 采集 JVM 内存、线程等指标
- 支持 Druid 慢 SQL 告警和连接池状态监控
- 支持飞书、钉钉、企业微信等 webhook 推送
- 支持告警去重,避免同一类问题反复刷屏
- 支持内置一个简单的仪表盘页面
- 可以继续扩展 Prometheus、SkyWalking、ELK
说白了,它不是想替代完整的监控平台,而是想先把最常用、最直接、最容易落地的告警能力沉淀成一个通用组件。
二、为什么我要做这个项目
这个项目其实不是为了炫技,而是因为业务里确实有这种需求。
以前碰到线上问题,很多时候还是靠人去盯日志、看群消息、查监控。项目一多之后,这种方式很容易漏。尤其是一些小问题,可能还没到系统彻底挂掉的程度,但是已经开始慢慢恶化了,比如:
- 某个接口偶发报错
- 某个请求耗时突然变长
- 某个机器内存使用率持续升高
- 某个 SQL 执行越来越慢
这些问题如果能在第一时间被推送出来,很多时候就能提前处理,不会等到影响面变大了再去救火。
我自己一直比较喜欢做一些实用型的东西,所以这个项目的思路也比较简单:
- 先把最核心的告警能力做出来;
- 尽量做到接入简单;
- 不强依赖太多外部系统;
- 后续有需要再往外扩展。
三、项目结构
整个项目采用的是 Maven 多模块结构,拆分得比较清晰。
pcm-prometheus-alert/
├── pcm-prometheus-alert-core
├── pcm-prometheus-alert-spring-boot-starter
├── pcm-prometheus-alert-sql-starter
├── pcm-prometheus-alert-extensions
└── pcm-prometheus-alert-demo各模块的作用大概如下:
pcm-prometheus-alert-core:核心模型和告警处理逻辑pcm-prometheus-alert-spring-boot-starter:Spring Boot 自动装配pcm-prometheus-alert-sql-starter:Druid 慢 SQL 和数据源监控pcm-prometheus-alert-extensions:Prometheus、SkyWalking、ELK 等扩展pcm-prometheus-alert-demo:本地测试示例
这样拆的好处也比较直接,就是业务项目按需引入,不需要的功能不用带上。
四、主要功能
这里把我目前已经做好的核心功能简单列一下。
1. 异常告警
这个是最基础的能力。
项目里如果出现没有处理的异常,会自动捕获并生成告警消息,然后推送到 webhook 对应的群里。这样做的好处是,不用等到用户反馈,自己就能先看到异常。
而且我这里还加了两个比较实用的小功能:
- 支持排除指定异常
- 支持堆栈截断
这样可以避免一些参数校验类异常也跟着一起刷屏。
2. 慢请求告警
这个也很实用。
很多线上问题不是直接报错,而是接口越来越慢。通过请求过滤器统计耗时后,只要超过阈值,就会自动触发告警。
同时也支持排除一些不需要监控的路径,比如:
/actuator/**/health/favicon.ico
这样就不会把一些无意义的请求也统计进去。
3. HTTP 状态码告警
有些问题不会抛异常,但是最后返回的是 500 或者 503,这种情况如果只看异常日志,未必第一时间能注意到。
所以这里也把状态码告警加进去了,默认会关注这些状态码:
- 500
- 502
- 503
- 504
4. JVM 指标告警
目前支持的主要是 JVM 堆内存、线程数这些比较常用的指标。
如果堆内存占用过高,或者线程数超过阈值,就会自动推送告警。对一些内存持续上涨、线程池堆积这类问题,还是比较有帮助的。
5. SQL 告警
如果项目里本身用的是 Druid,那么可以进一步把慢 SQL 和连接池状态也接进来。
这个场景在业务里也很常见,因为很多时候接口慢,根子其实不在 Java 代码本身,而是在 SQL 执行慢、连接池等待时间长。
6. 多平台 webhook 推送
目前支持:
- 默认 JSON
- 飞书
- 钉钉
- 企业微信
也就是说,不管你们团队平时主要用哪一种 IM 工具,基本都可以直接接入。
7. 告警去重
这个功能我觉得很重要。
如果一个异常在几秒钟之内连续触发很多次,而每一次都推送,很快群里就会被刷满,最后反而没人愿意看。
所以这里做了冷却窗口去重,同一类告警在一段时间内只会推送一次,尽量做到有用,而不是打扰。
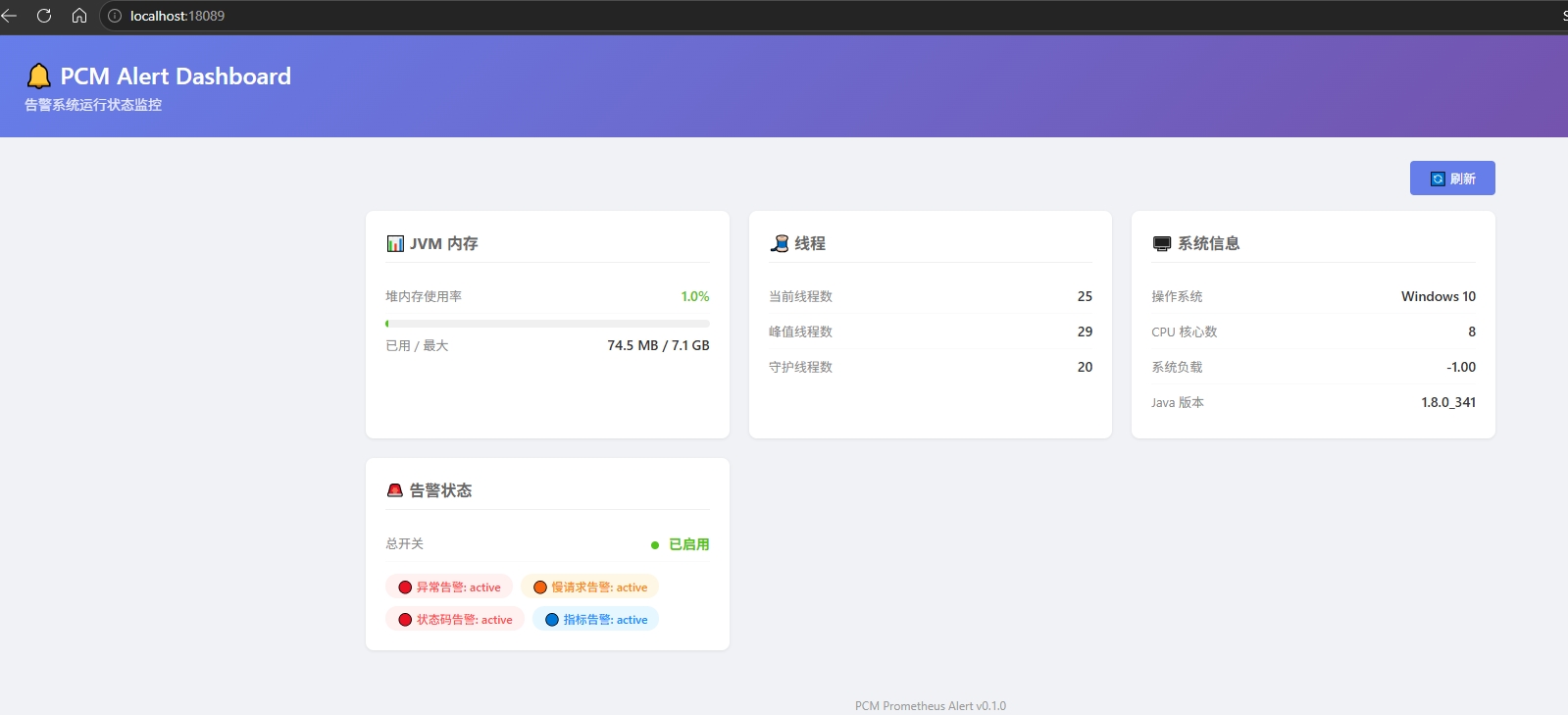
8. 内置仪表盘
这个我自己也比较喜欢。
为了方便本地测试和快速查看运行状态,starter 里内置了一个很轻量的页面,访问:
http://localhost:{port}/pcm-alert/
就可以看到当前服务的一些基础信息,比如 JVM 内存、线程信息、系统信息和告警状态。
效果图如下:
五、如何使用
这个部分我尽量写得直接一点。
1. 先把项目拉下来
git clone https://gitee.com/XuWuJing/pcm-prometheus-alert.git
cd pcm-prometheus-alert
mvn clean install -DskipTests因为现在项目代码已经完整了,所以你可以先在本地安装一遍,然后再在业务项目里引用对应的 starter。
2. 业务项目引入 starter
如果你只是想先用基础告警能力,那么直接引入下面这个依赖就可以了:
<dependency>
<groupId>com.pcm.alert</groupId>
<artifactId>pcm-prometheus-alert-spring-boot-starter</artifactId>
<version>0.1.0-SNAPSHOT</version>
</dependency>如果你还想接慢 SQL 和数据源告警,那么再额外引入:
<dependency>
<groupId>com.pcm.alert</groupId>
<artifactId>pcm-prometheus-alert-sql-starter</artifactId>
<version>0.1.0-SNAPSHOT</version>
</dependency>3. 配置 application.yml
最基础的配置其实很少,先把总开关和 webhook 配上就行。
pcm:
alert:
enabled: true
webhook: https://open.feishu.cn/open-apis/bot/v2/hook/xxxxxx
webhook-format: feishu
service-name: order-service
environment: prod如果想把常用能力都一起带上,可以参考下面这个配置:
pcm:
alert:
enabled: true
webhook: https://open.feishu.cn/open-apis/bot/v2/hook/xxxxxx
webhook-format: feishu
service-name: ${spring.application.name}
environment: ${spring.profiles.active}
publisher:
async: true
queue-size: 100
timeout-ms: 3000
dedupe:
enabled: true
cooldown-seconds: 300
exception:
enabled: true
stack-trace-max-lines: 20
exclude-exceptions:
- org.springframework.web.bind.MissingServletRequestParameterException
- org.springframework.web.method.annotation.MethodArgumentTypeMismatchException
request:
enabled: true
slow-threshold-ms: 1000
status-code-alert-enabled: true
status-code-alert-thresholds:
- 500
- 502
- 503
- 504
exclude-paths:
- /actuator/**
- /health
- /favicon.ico
metric:
enabled: true
interval-seconds: 30
jvm-memory-threshold: 0.8
thread-threshold: 500
cpu-enabled: false
recovery-enabled: false
dashboard:
enabled: true4. 启动后就能直接生效
这个项目的目标之一,就是尽量减少接入成本。
所以正常情况下,业务项目只要:
- 引入依赖;
- 配置 webhook;
- 启动服务;
基础告警能力就能直接生效,不需要你再写一堆额外代码。
六、在业务场景里可以怎么用
我觉得这个部分比单纯讲代码更重要,所以单独说一下。
1. 线上异常第一时间通知
这个是最直接的场景。
比如某个接口突然出现空指针、参数转换异常或者某个下游服务调用失败,系统就会自动把异常信息推送到群里。这样开发、测试、运维都能第一时间看到,不用再等别人截图或者口头反馈。
2. 慢接口预警
有些问题在最开始并不会报错,只是接口慢了。
比如原来 100ms 能返回的接口,突然开始稳定跑到 2 秒以上,这种时候虽然系统还没挂,但其实已经是风险信号了。这个 starter 可以先把这种问题暴露出来,让你在用户集中投诉前先看到。