本文对应的完整后端实现已经开源:
这是一个用 Go 写的 AI 助手平台后端,把流式对话、RAG、Agent、长期记忆和 MCP 工具调用整合在一个工程里。文章里会重点拆它的架构设计、RAG 管线和工程分层;如果你也在做 AI 应用后端、知识库问答或 Agent 平台,可以直接对照源码看完整实现。
引言
在 Agent 应用开发中,RAG(检索增强生成)几乎是标配能力------Agent 需要从外部知识库中检索相关信息来支撑推理和回答。但现实情况是,很多团队的 RAG 实现要么和业务逻辑强耦合难以复用,要么直接硬编码了特定模型 SDK 和存储后端,每次换模型、换向量库都伤筋动骨。
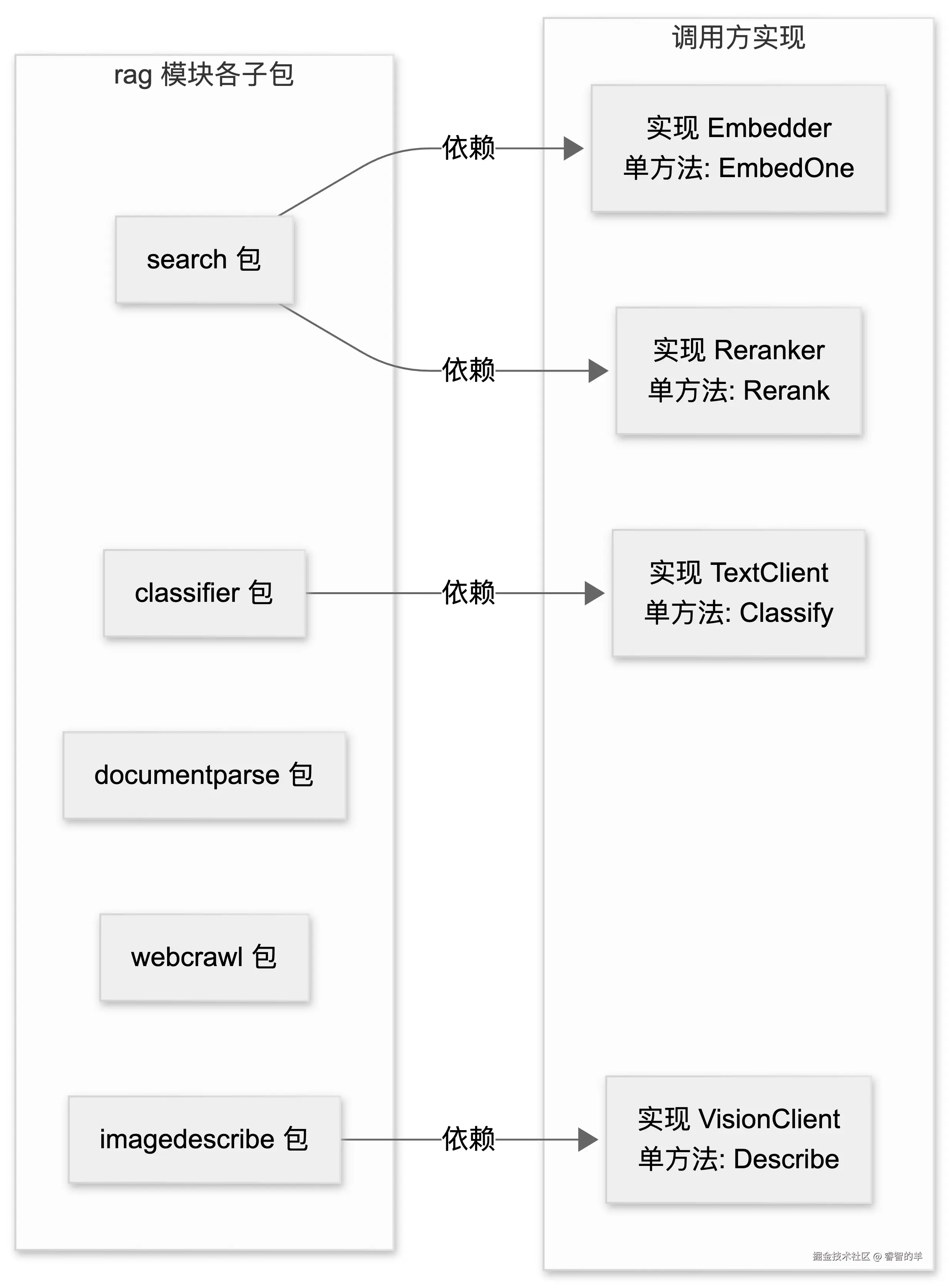
Cove API 的 internal/core/rag 模块提供了一个值得参考的方案:它把 RAG 全链路拆解为七个独立、可组合的子包,覆盖了从文档摄入到混合检索的完整流程,同时通过接口抽象和 Options 注入模式,将业务逻辑、模型适配和存储细节全部留给调用方。这种设计让 RAG 管道变成了一个可以按需组装的工具箱,而不是一套写死的框架。
本文将聚焦 rag 模块的整体架构、各子包的职责划分、核心接口设计以及围绕"封装与使用"的工程实践,帮助有 Agent 开发经验的读者理解这套模块的组织思路,并从中获得可迁移到自身项目的设计启发。
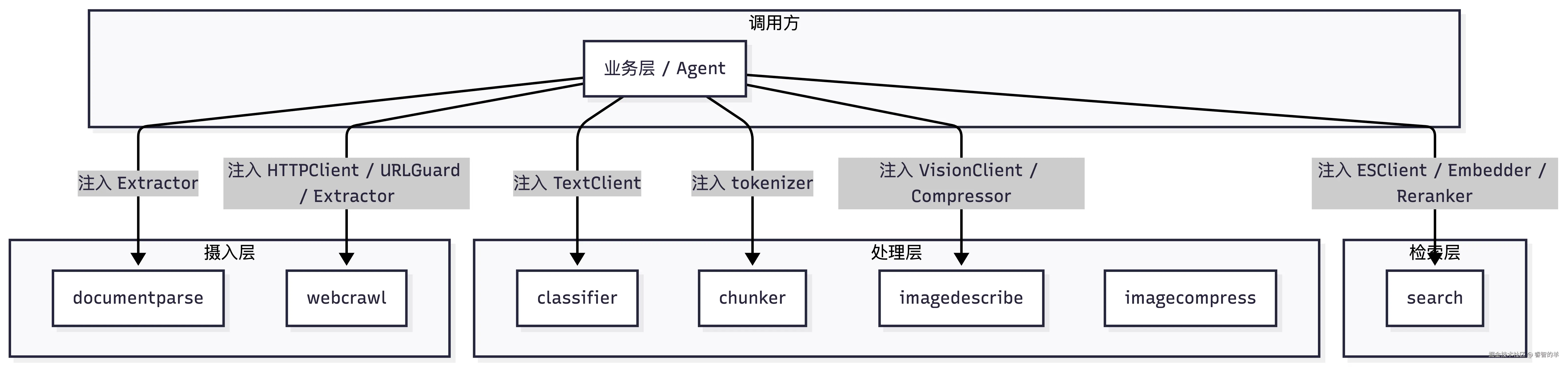
模块总览:七个子包的三层架构与职责边界
要设计一套可组合的 RAG 工具体系,第一个问题不是"每个环节怎么实现",而是"边界划在哪里"。Cove API 的 internal/core/rag 模块给出了一个清晰的回答:把 RAG 全链路拆成七个功能子包,外加一个模板资源包,按摄入 → 处理 → 检索三层组织,每一层只定义流程骨架,把具体能力交给调用方注入。
先建立心理模型:RAG 全链路
在深入子包之前,先用一张图建立 RAG 管道从数据到检索的完整链路。

这张图展示了核心数据流:文档和网页分别从 documentparse 和 webcrawl 进入管道,产出纯文本后交由 chunker 分块;同时文档中嵌入的图片经过 imagecompress → imagedescribe 两阶段处理生成结构化描述;classifier 为每个 chunk 打上可选标签;最终 search 负责混合检索并返回类型安全的结果。
prompt 子包不参与数据流------它只提供模板定义和参数结构体,是 classifier 和 imagedescribe 的共享资源。
三层架构:各司其职
按在链路中的位置,七个子包自然落入三个层次:
摄入层------把外部世界的数据变成纯文本流:
| 子包 | 入口 | 职责 |
|---|---|---|
documentparse |
Parser.Parse() |
按文件扩展名路由到对应 Extractor,输出 Output{Text, FileExt} |
webcrawl |
Crawler.Fetch() |
URL 校验 → HTTP 抓取 → Extractor 提取标题/正文,输出 Output{Title, Content, URL} |
两者的共性在于:核心流程(路由、重试、安全校验)由模块定义,具体能力(格式解析、HTTP 传输、正文提取)由接口注入。
处理层------对纯文本和关联图片做加工:
| 子包 | 入口 | 职责 |
|---|---|---|
imagecompress |
Compressor.Compress() |
尺寸判断 → 解码 → 贴白底 → 约束最长边 → JPEG 逐级编码 |
imagedescribe |
Describe() |
压缩 → base64 → VisionClient 调用 → JSON 解析为 Description |
chunker |
Chunk() |
句子级切分 → token 上限合并 → 产出父子块 Chunk{Content, Children} |
classifier |
Classify() |
构建 prompt → TextClient 调用 → 解析标签 → 失败时返回空切片 |
处理层的子包之间不存在硬依赖------imagedescribe 通过注入的 Compressor 接口调用压缩能力,而非直接依赖 imagecompress 包。classifier 的 TextClient 接口同样屏蔽了具体模型实现。
检索层------对已入库数据执行混合检索:
| 子包 | 入口 | 职责 |
|---|---|---|
search |
Searcher[T].Search() |
向量召回 → BM25 召回 → 分数融合 → 可选重排 → 结果组装 |
search 是整个模块中抽象密度最高的子包:ESClient、Embedder、Reranker、FilterBuilder、SourceDecoder[T] 五个接口全部由调用方注入,模块自身不绑定任何存储或模型。
为什么拆成七个子包?
如果用一个 monolithic RAG 包,调用方引入一个 parser 就得带上 search 的 ES 依赖链。这在 Agent 场景下尤其致命------不同的 Agent 运行时可能只需要其中两三个能力。
以 Cove API 的实际拆分来看,每个子包的 doc.go 都明确声明了自身不做什么:
documentparse:只处理文档二进制 → 纯文本,不涉及存储、索引、模型调用。webcrawl:只抓取网页并提取正文,不持久化 HTML,不管理 cookie/session。imagecompress:只处理图片字节,"不调用模型、不访问存储",压缩失败时返回原图而非阻断流程。imagedescribe:"不依赖具体大模型 SDK、数据库或业务对象"------VisionClient和Compressor都是接口。chunker:只做文本切分,不关心 chunk 之后存到哪里、怎么索引。classifier:"不访问数据库、不绑定业务标签体系"------标签体系完全由prompt模板参数注入。search:"业务过滤、索引字段含义和来源元数据解码均由调用方通过FilterBuilder、InputOption 和 SourceDecoder 注入"。
这种"不做什么"比"能做什么"更能定义模块边界。每个子包都是一个能力孤岛------它有自己完整的 Input/Output 类型、Options 配置、对外接口,但绝不对其它子包产生编译期依赖。
依赖方向:接口向下,实现向上
子包之间的协作不靠直接 import,而是靠接口注入:
每个子包都在自己的 types.go 中定义最小接口契约------比如 classifier 的 TextClient 只有一个方法:
go
type TextClient interface {
Classify(ctx context.Context, prompt string, temperature float64, maxTokens int64) (string, error)
}search 的 Embedder 同样只有一个方法:
go
type Embedder interface {
EmbedOne(ctx context.Context, text string, dimensions int) ([]float64, error)
}这不是巧合,而是一条贯穿全模块的设计准则:接口只定义模块真正需要的那个行为,不多不少。调用方可以用任何模型 SDK、任何存储引擎来适配这些接口,子包完全不感知具体实现。
数据流:从摄入到检索的类型演进
整个链路中数据的形态变化体现了各层的分工:
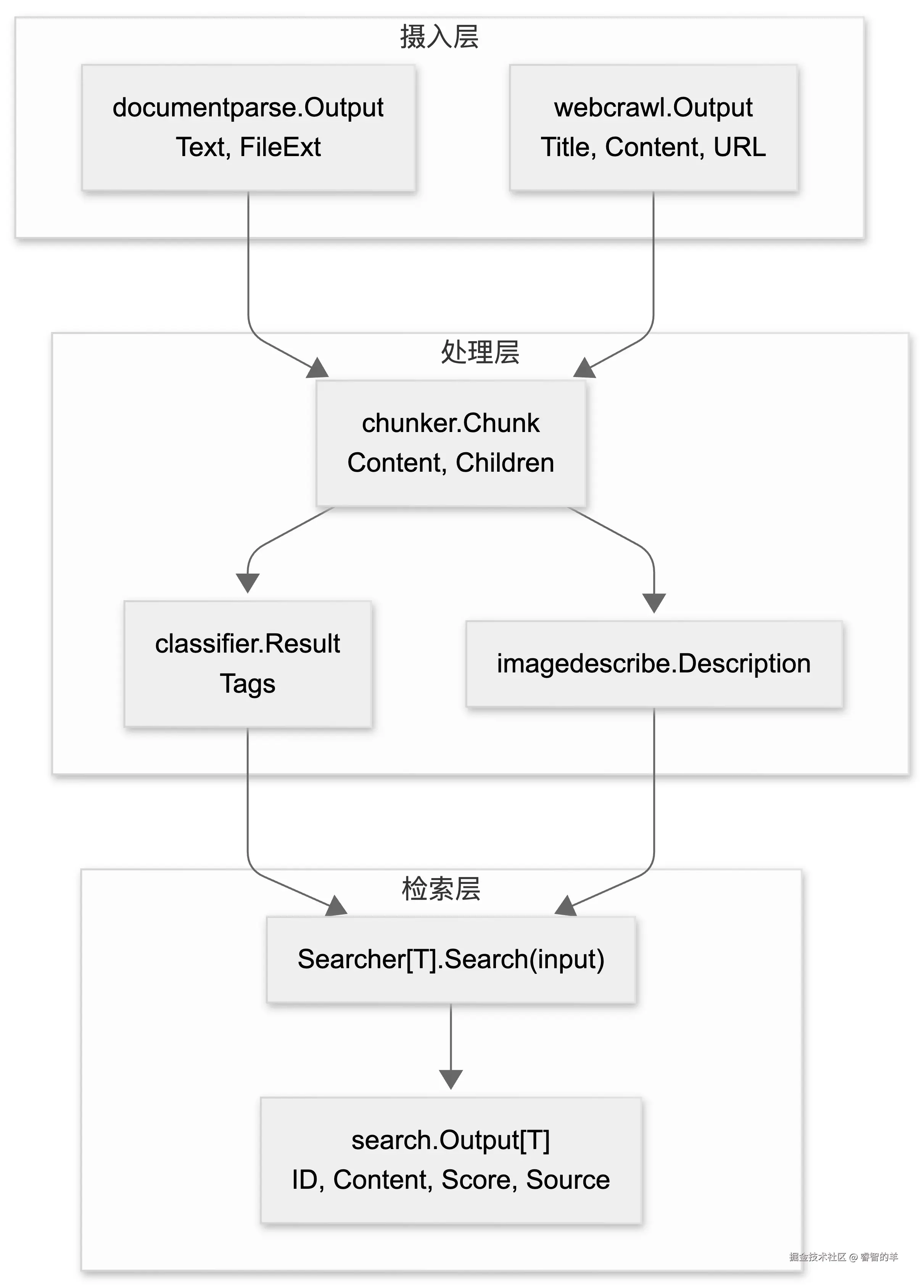
注意 search.Output[T] 中的泛型参数 T。通过 SourceDecoder[T],调用方可以将 ES 的 _source 解码为任意业务类型------比如 DocumentMeta、ArticleInfo 或自定义结构体。这意味着检索结果直接携带类型安全的业务元数据,调用方拿到 Output[T] 后不需要再做 interface{} 断言。
prompt:不参与数据流,但约束参数形态
prompt 子包是八个子包中唯一不暴露任何方法或结构体类型的包。它只做三件事:
- 用
//go:embed *.tmpl嵌入两个模板文件(content_classifier.tmpl和image_description.tmpl); - 暴露
Templates变量和模板文件名常量; - 声明
ContentClassifierData等参数结构体,约束模板可用的变量。
它不读取、不解析、不渲染模板------这些工作由外层的 core/prompt 包完成。这种"只定义不执行"的设计让模板成为纯粹的静态资源,调用方可以自由选择渲染引擎。
边界设计的工程价值
把所有子包的边界约束放在一起看,会发现一个清晰的模式:

这四条约定了 Cove API RAG 模块的设计底线:每个子包都是一个有明确输入输出的纯函数式能力单元。调用方拥有完整的控制权------选什么模型、用什么存储、定义什么标签体系、如何降级,全部由调用方决定。
理解了全局架构之后,接下来沿着数据流向,从摄入层开始逐一深入:先看 documentparse 和 webcrawl 如何通过接口抽象将文档和网页统一为纯文本流。
数据摄入层:documentparse 与 webcrawl 的接口设计
RAG 的第一步永远是拿到数据。在实际场景中,数据以两种典型形态进入系统:用户上传的文档文件(PDF、DOCX、Markdown 等),以及需要从外部抓取的网页链接。这两种入口表面上是完全不同的操作,但在设计层面面临同一个问题------如何让核心流程不绑定任何具体实现。
Cove API 的答案是把摄入层拆成两个子包:documentparse 处理文档二进制 → 纯文本,webcrawl 处理 URL → 标题+正文。两个包的共同设计原则很明确:模块定义流程骨架,调用方注入具体能力。
documentparse:格式无关的文档解析
documentparse 只做一件事:接收字节数组和文件扩展名,返回纯文本。它不关心文件从哪来、文本将去哪,也不绑定任何存储或模型 SDK。
核心抽象是两个极简接口:
go
// Extractor 定义单一文件格式的文本提取行为。
type Extractor interface {
Extract(ctx context.Context, input Input) (string, error)
}
// TextDecoder 定义纯文本字节到字符串的解码行为。
type TextDecoder interface {
Decode(data []byte) (string, error)
}Extractor 负责格式解析(PDF、DOCX、HTML 等),TextDecoder 负责字符编码(UTF-8 校验、非法字节替换)。两个接口各自只有一个方法,符合接口最小化原则------每个接口只定义模块真正需要的契约。
Parser 持有 Options,后者内部维护一个 map[string]Extractor。Parse 方法的流程非常直截:
go
func (p *Parser) Parse(ctx context.Context, input Input) (*Output, error) {
ext := normalizeExt(input.FileExt)
extractor, ok := p.Extractors[ext]
if ext == "" || !ok {
return nil, fmt.Errorf("%w: %s", errUnsupportedType, ext)
}
text, err := extractor.Extract(ctx, Input{Data: input.Data, FileExt: ext})
if err != nil {
return nil, err
}
text = normalizeText(text)
if text == "" {
return nil, errEmptyContent
}
return &Output{Text: text, FileExt: ext}, nil
}整个流程可以概括为三步:扩展名归一化 → 查表路由 → 提取 + 出口规整。

值得注意的一个设计细节是:extractor 只负责格式解析,空白规整(normalizeText)和空文本拦截统一在 Parse 的出口完成。这意味着任何一个自定义 Extractor 的实现者都不需要操心后处理------这是框架层的职责。
内置格式与自定义注册
NewParser 会先构造默认提取器集合,再用调用方传入的 WithExtractor 选项覆盖同扩展名的条目:
go
func NewParser(opts ...Option) *Parser {
decoder := utf8Decoder{}
parser := &Parser{
Options: Options{
TextDecoder: decoder,
Extractors: map[string]Extractor{},
},
}
for _, opt := range opts {
if opt != nil {
opt(&parser.Options)
}
}
customExtractors := parser.Extractors
parser.Extractors = defaultExtractors(parser.TextDecoder)
for ext, extractor := range customExtractors {
parser.Extractors[ext] = extractor
}
return parser
}默认支持的格式覆盖了常见的文档类型:.txt、.md/.markdown、.html/.htm、.docx、.pdf。如果调用方需要支持 .rst 或 .org 等自定义格式,只需实现 Extractor 接口并通过 WithExtractor 注册即可。如果想替换 PDF 的解析实现(比如换成更高精度的库),同样只需要覆盖 ".pdf" 对应的提取器。
TextDecoder 也同样可替换。默认的 utf8Decoder 会校验 UTF-8 合法性,对非法字节用空格替换------一个安全优先、静默修复的策略,而不是直接报错中断流程。
此外,extractorFunc 适配器提供了将普通函数转换为 Extractor 的便利方式:
go
type extractorFunc func(ctx context.Context, input Input) (string, error)
func (fn extractorFunc) Extract(ctx context.Context, input Input) (string, error) {
return fn(ctx, input)
}内置的 PDF、DOCX、HTML 提取器都通过这个适配器挂载,调用方同样可以用它来避免定义新的结构体类型。
webcrawl:安全抓取与正文提取
webcrawl 处理的是完全不同的场景:给定一个 URL,返回网页标题和正文。流程比 documentparse 更复杂,因为它涉及网络 I/O 和安全风险。
Crawler 的 Fetch 方法定义了一条严格的执行链路:
go
func (c *Crawler) Fetch(ctx context.Context, input Input) (*Output, error) {
// 前置校验:三个核心依赖必须存在
// ...
rawURL := strings.TrimSpace(input.URL)
if err := c.URLGuard.Validate(ctx, rawURL); err != nil {
return nil, err
}
for attempt := 0; attempt <= c.RetryCount; attempt++ {
page, err := c.fetchOnce(ctx, rawURL)
if err == nil {
return c.Extractor.Extract(ctx, page)
}
lastErr = err
}
return nil, lastErr
}
整个链路分为三个阶段:URL 安全校验 → HTTP 抓取(含重试)→ 正文提取。其中抓取阶段的错误会触发重试,但提取器错误直接返回------因为提取失败通常意味着页面格式问题,重试没有意义。
URLGuard:SSRF 防护的核心
URLGuard 接口定义了 URL 安全校验能力:
go
type URLGuard interface {
Validate(ctx context.Context, rawURL string) error
}默认实现 defaultURLGuard 的 Validate 方法做了三层检查:
- Scheme 白名单:只允许
http和https,拒绝file://、ftp://等协议。 - Host 解析:如果 host 本身是 IP 地址就直接校验,否则通过
Resolver进行 DNS 解析。 - IP 安全检查:对解析到的每个 IP 调用
isSafeIP:
go
func isSafeIP(ip net.IP) bool {
if ip == nil {
return false
}
return ip.IsGlobalUnicast() &&
!ip.IsPrivate() &&
!ip.IsLoopback() &&
!ip.IsLinkLocalUnicast() &&
!ip.IsLinkLocalMulticast() &&
!ip.IsMulticast() &&
!ip.IsUnspecified()
}这个函数排除了所有危险地址类型:内网地址(IsPrivate)、本地回环(IsLoopback)、链路本地(IsLinkLocalUnicast)、多播和未指定地址。攻击者无法通过构造指向 127.0.0.1 或 169.254.x.x 的 URL 来探测内部服务。
更关键的是,URLGuard 不仅作用于初始请求,还作用于重定向。defaultHTTPClient 在构造 http.Client 时通过 CheckRedirect 回调,让每次重定向都经过同样的安全校验:
go
CheckRedirect: func(req *http.Request, via []*http.Request) error {
if len(via) >= maxRedirects {
return http.ErrUseLastResponse
}
if guard != nil {
return guard.Validate(req.Context(), req.URL.String())
}
return nil
},这意味着即使攻击者从一个合法的外部 URL 重定向到内网地址,也会在校验环节被拦截。这是一种纵深防御------不在入口做一次检查就信任后续跳转。
Resolver 同样以接口形式暴露,调用方可以通过 WithResolver 注入自定义 DNS 解析器(例如接入内部 DNS 服务或缓存层),而不影响 URLGuard 的校验逻辑。
抓取与提取的分离
Crawler 的 Options 中包含 HTTPClient、Extractor 和 URLGuard 三个可替换接口。默认的 HTMLExtractor 使用 golang.org/x/net/html 进行 DOM 解析,会跳过 script、style、noscript 等标签,只收集文本节点。标题为空时会回退到页面 URL,避免输出缺失关键元数据。
fetchOnce 中还设置了浏览器风格的 User-Agent 和 Accept 头,减少被目标站点简单拦截的概率------这是工程实践中的细节,不影响接口抽象,但显著提高了抓取成功率。
两个子包的共同设计思路
回顾 documentparse 和 webcrawl,可以看到一套贯穿的设计模式:
| 维度 | documentparse | webcrawl |
|---|---|---|
| 核心流程 | normalizeExt → Extract → normalizeText |
Validate → fetchOnce → Extract |
| 能力注入接口 | Extractor、TextDecoder |
HTTPClient、Extractor、URLGuard、Resolver |
| 适配器模式 | extractorFunc |
extractorFunc |
| 配置方式 | Option 函数式选项 |
Option 函数式选项 |
| 默认实现 | txt/md/html/docx/pdf | HTMLExtractor + defaultURLGuard + 带重定向校验的 HTTP client |
核心思想是一致的:模块定义"做什么"和"按什么顺序做",调用方决定"用什么来做"。
Parser 定义了文档解析的骨架------扩展名路由、提取、空白规整、空文本拦截------但每个格式的提取逻辑和文本解码策略完全由调用方控制。Crawler 定义了安全抓取的骨架------校验、发起请求、重试、提取------但 HTTP 客户端、安全策略和正文提取算法都是可替换的。
这种设计的结果是:两个子包都不依赖数据库、不绑定模型 SDK、不涉及存储。它们只生产纯文本或结构化输出(Output{Title, Content, URL}),下游的 chunker、classifier 等处理层子包在此基础上继续加工。
纯文本拿到之后,新的问题随之而来:文档中嵌入的图片怎么办?架构图、流程图、截图往往承载了不亚于正文的关键信息,如果直接丢弃,检索质量会大打折扣。Cove API 的做法是为图片建立一条独立的两阶段处理管线------这正是下一环节要解决的问题。
图片处理管线:imagecompress 与 imagedescribe 的两阶段协作
假如一篇待入库的技术文档里嵌入了一张系统架构图。用户搜索「服务间通信方式」时,纯文本匹配只能命中正文中零散提到的「gRPC」「消息队列」,而架构图里清晰的箭头标注、模块关系、协议说明------这些对理解系统至关重要的信息,在纯文本索引中完全不可见。
这就是 RAG 管道必须处理图片的原因:图片承载的语义信息往往是文本无法替代的。但直接拿原始图片去调视觉模型也有问题------高分辨率 PNG 动辄 10MB+,视觉模型按 token 计费,输入成本会迅速失控。
Cove API 的解决方案是把图片处理拆成两个独立子包:imagecompress 负责把图片压缩到适合模型输入的大小,imagedescribe 负责调用视觉模型生成结构化描述。两者通过接口协作,各自可替换。
下面这张图概括了完整的数据流:
压缩阶段:逐级降质,保证有结果
Compressor 的核心设计思想是「尽最大努力压缩,但绝不阻断流程」。整个 Compress 方法遵循一条清晰的降级链路:
go
func (c *Compressor) Compress(input Input) (*Output, error) {
out := &Output{
Data: input.Data,
MIME: mime,
OriginalBytes: len(input.Data),
OutputBytes: len(input.Data),
}
// 第一步:小图直接放行
if len(input.Data) <= c.TargetBytes {
return out, nil
}
// 后续每一步失败都返回原图,error 为 nil
img, _, err := image.Decode(bytes.NewReader(input.Data))
if err != nil {
return out, nil
}
// ...
}值得注意的细节是,out 在函数开头就被初始化为携带原始数据的结构体。这意味着后续任何一步失败------解码、贴白底、缩放、编码------都只是 return out, nil。调用方始终能拿到可用的图片数据,压缩失败不会变成业务中断。
流程中的三个关键步骤各有其工程考量:
贴白底(flattenToRGB):透明 PNG 在转为 JPEG 时透明通道会被填充为黑色,这在视觉模型看来就是一团噪声。统一贴白底再编码,既避免了兼容性问题,也让模型看到的画面更接近人类预期。
约束最长边(resizeToMaxEdge):默认最长边为 1568px。这里使用 CatmullRom 算法做等比缩放,保持宽高比------宁可牺牲分辨率,也不破坏图片的语义结构。一张被压扁的架构图对模型来说是灾难。
逐级编码(encodeJPEGByQuality):这是压缩策略最精妙的部分。默认质量序列是 [85, 70, 55, 40],从高到低依次尝试:
go
for _, quality := range qualities {
jpeg.Encode(&buf, img, &jpeg.Options{Quality: quality})
last = buf.Bytes()
if targetBytes <= 0 || len(last) <= targetBytes {
return last, nil // 命中目标体积,立即返回
}
}
return last, nil // 所有质量档位都试完,返回最后一个(最低质量)它的逻辑是:尽可能保留视觉信息,只有在必要时才牺牲质量。而且即使所有档位都无法满足 3MB 目标,也返回最低质量的结果------永远不空手而归。
默认配置通过 Options 暴露了三个可调参数:MaxEdge(默认 1568)、TargetBytes(默认 3MB)、Qualities(默认 [85,70,55,40]),调用方可以根据模型的价格敏感度和精度要求自行调整。
描述阶段:Compressor 接口让压缩策略可替换
Describer 自身不实现压缩逻辑,而是依赖一个 Compressor 接口:
go
type Compressor interface {
Compress(input imagecompress.Input) (*imagecompress.Output, error)
}默认实现当然是 imagecompress.NewCompressor(),但接口的存在意味着调用方可以注入任何实现。比如,如果未来需要针对线框图使用不同的压缩策略(更高的对比度保留、更激进的分辨率压缩),只需实现同一个接口即可替换,Describer 的核心流程完全不受影响。
同样的模式也应用在 VisionClient 上:
go
type VisionClient interface {
Describe(ctx context.Context, prompt string, imageBase64 string,
mime string, maxTokens int64) (string, error)
}Describer 不绑定任何模型 SDK。它只知道:给我一个实现了 Describe 方法的东西,我就能工作。这让调用方可以自由选择 GPT-4V、Claude Vision、Gemini 或私有部署模型,模块本身不需要任何改动。
解析与兜底:fail-open 的两层体现
Describe 方法完成压缩和模型调用后,进入 parse 阶段。这里体现了 fail-open 设计在非核心路径上的两次运用。
第一层:JSON 解析失败时,原文兜底。 视觉模型不一定严格输出 JSON,prompt 里写了「只输出 JSON」但实际行为不可控。parse 的处理方式是不阻塞:
go
func (d *Describer) parse(answer string) *Description {
var raw rawDescription
if err := d.Parser.Unmarshal(answer, &raw); err != nil {
return &Description{
Description: truncate(answer, maxDescriptionRunes),
Objects: []string{},
}
}
// ...
}JSON 解析失败时,整个模型返回的原文直接塞进 Description 字段,Objects 给一个空数组。检索时至少能命中这段文本;OCR、场景标签等结构化字段虽然丢失了,但不影响最核心的语义检索能力。
第二层:字段类型不稳定时,安全规整。 即使 JSON 解析成功,模型输出的字段类型也可能不靠谱------description 可能是字符串也可能是数字,objects 可能是字符串数组也可能是单个字符串。为此,rawDescription 的所有字段都用了 any 类型,再通过 valuex 工具函数做安全转换:
go
return &Description{
Description: truncate(valuex.String(raw.Description), maxDescriptionRunes),
OCRText: truncate(valuex.String(raw.OCRText), maxOCRTextRunes),
Objects: valuex.StringList(raw.Objects),
Scene: truncate(valuex.String(raw.Scene), maxSceneRunes),
}valuex.String 只接受 string 和 json.Number,其他类型一律返回空字符串;valuex.StringList 则处理 []string 和 []any 两种情况,并过滤空字符串。再加上 truncate 按 rune 截断(描述和 OCR 各 2000 字符,场景标签 64 字符),确保下游拿到的永远是格式稳定的数据。
这两层兜底加起来的效果是:无论视觉模型返回什么奇怪的东西,Describe 都不会崩溃,调用方也总能拿到一个可用的 Description。
Description 结构体:为检索而设计
整个管线的最终产出是一个四字段的结构体:
go
type Description struct {
Description string `json:"description"` // 主描述,便于语义检索
OCRText string `json:"ocr_text"` // 图中文字,可做关键词匹配
Objects []string `json:"objects"` // 物体列表,支持标签过滤
Scene string `json:"scene"` // 场景类别,支持分类筛选
}Prompt 模板直接对应了这个结构:
- description: 对图片内容的详细描述(一段话,尽量具体,便于后续检索) - ocr_text: 图片中出现的所有文字(没有则空字符串) - objects: 图片中的主要物体列表(字符串数组) - scene: 图片的场景类别(如:办公室、户外、文档截图、人物 等,一个词)
这个设计刻意把图片信息拆成四个维度:Description 对应语义检索场景(用户用自然语言描述图片内容),OCRText 对应关键词精确匹配(用户搜索图中出现的某个术语或产品名),Objects 和 Scene 对应标签过滤(「只查包含架构图的文档」或「只查有代码截图的页面」)。四个字段各司其职,下游的检索系统可以根据自己的索引结构灵活选择使用哪些维度。
从数据摄入产出的纯文本,到图片被压缩和结构化描述,整个 RAG 上游的数据准备已经就绪。但此时每个文档还是一条完整的长文本------直接入库会遇到 token 上限问题,检索粒度也太粗。下一步自然就是分块。
文本分块策略:chunker 的父子块设计与 token 管理
假设你有一个 8000 字的 API 文档,其中既有接口声明,也有配置示例和排错说明。如果直接将全文作为一个向量存入知识库,检索时会出现两个典型问题:其一,查询"如何配置超时时间"命中的向量混杂了无关章节的噪声,语义被稀释;其二,返回给 LLM 的上下文是一个 8000 字的整块,远超模型的注意力窗口,处理成本极高且容易丢失关键细节。
这正是 chunker 子包要解决的核心问题:将长文本拆成合适粒度的片段,既保留足够上下文,又保证检索精度。
父子两级分块:一个结构,两个粒度
chunker 的答案是把分块设计成父子两级结构。Chunk 类型定义非常简洁:
go
type Chunk struct {
Content string
Children []string
}Content 是父块,代表一段较完整的上下文;Children 是同一父块内按更小 token 上限切出的子块列表。检索时用子块做向量匹配------粒度细、语义集中;但返回给 LLM 的是父块全文------上下文完整,不会因为切分丢失段落间的因果逻辑。
这种设计实际上解决了 RAG 中一个经典矛盾:召回需要小粒度以提升相关性,生成需要大粒度以保留上下文。父子块各自承担不同职责,互不妥协。
Chunk 主流程:从文本到父子块
Chunk 方法的处理流程可以用一张图概括:
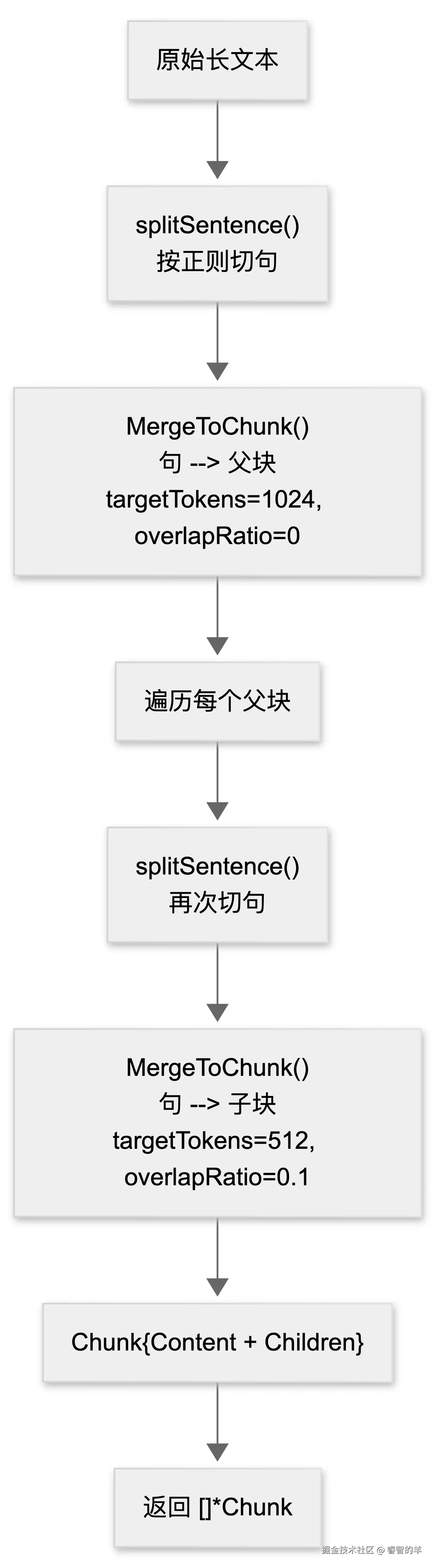
流程上分四步:
- 用正则将全文切分为句子列表;
- 以
ParentChunkTokens(默认 1024)为上限,将句子合并为父块,父块之间不做重叠; - 对每个父块,再次切句后以
ChildChunkTokens(默认 512)为上限合并为子块,子块之间按重叠比例保留尾部句子; - 将父块内容和子块列表封装为
Chunk返回。
关键约束在于:子块在父块内部切出,绝不跨父块边界。这保证了每个子块命中后回查到的父块上下文是语义自洽的,不会出现"前半段讲配置、后半段讲安全"的拼接错乱。
MergeToChunk:句子级的 token 管理
MergeToChunk 是整个分块策略的引擎。它接收句子列表和 token 上限,按贪婪方式合并,逻辑上有三条分支:
正常合并:当前句的 token 数加上已累积句子不超过目标上限时,直接追加到当前块。
超限 flush:新句子会导致当前块超出上限时,先输出当前块,再根据 overlapRatio 决定是否保留尾部若干句子作为下一个块的上下文起点。对于父块,overlapRatio 为 0,flush 后清空重新开始;对于子块,默认 0.1,即保留当前块尾部 10% 的句子带入下一块。
长句拆分:如果单个句子的 token 数本身就超过目标上限------比如一段没有标点的日志输出------则进入 splitLongSentence,在 token 级别按窗口滑动切分,同样支持重叠:
go
func (c *Chunker) splitLongSentence(sentence string, targetTokens int, overlapRatio float64) []string {
tokens := c.tkm.Encode(sentence, nil, nil)
step := targetTokens
if overlapRatio > 0 {
overlap := max(1, int(float64(targetTokens)*overlapRatio))
step = max(1, targetTokens-overlap)
}
for start := 0; start < len(tokens); start += step {
end := min(start+targetTokens, len(tokens))
chunks = append(chunks, c.tkm.Decode(tokens[start:end]))
}
return chunks
}这里直接操作 token 数组而非原始字符串,确保窗口大小精确匹配模型 tokenizer 的计算结果,避免编码差异导致的隐性超限。
子块重叠:召回连续性与存储成本的权衡
ChildOverlapRatio(默认 0.1)是子块之间重叠比例的控制器。它的工作原理是:当前子块 flush 后,不丢弃全部已累积句子,而是保留尾部 max(1, len(cur) * overlapRatio) 个句子作为下一个子块的起点。
为什么需要重叠?考虑一段跨越两个子块边界的论述------"如上所述,该配置项存在三种模式......第一种模式适用于......"。如果不重叠,检索"第一种模式"时可能只命中后半段,丢失了前置的"如上所述"和"三种模式"的总括信息。10% 的重叠让相邻子块共享边界附近的句子,有效缓解这种边界截断问题。
当然,重叠会增加存储成本。每个子块的尾部句子会在相邻子块中重复出现,向量索引也会存储重复的 embedding。默认 10% 是在召回连续性和存储开销之间的一个经验平衡点,调用方可以根据文档特征自行调整------知识库类文档可以设得更高,新闻类短平快内容可以设得更低甚至为 0。
Options 模式:一切可配置
chunker 不将任何分块策略写死。所有参数通过 Options 结构体和 With* 函数注入:
go
type Options struct {
ChildChunkTokens int
ParentChunkTokens int
ChildOverlapRatio float64
SentenceRegex *regexp.Regexp
TokenEncodingName string
}ChildChunkTokens/ParentChunkTokens:子块和父块的 token 上限,默认 512 / 1024。如果模型上下文窗口更大,可以调高父块上限以提供更完整上下文。ChildOverlapRatio:子块重叠比例,默认 0.1。SentenceRegex:句子切分正则,默认已覆盖中英文常见标点(。!?.!?)。对于代码、表格等非自然语言文本,调用方可以注入自定义正则。TokenEncodingName:tiktoken 编码名称,默认cl100k_base(与 GPT-4 / GPT-3.5 一致)。如果使用其他模型,更换编码名即可对齐 token 计数。
NewChunker 通过 Functional Options 模式组装配置:
go
chunker := chunker.NewChunker(
chunker.WithParentChunkTokens(2048),
chunker.WithChildChunkTokens(768),
chunker.WithChildOverlapRatio(0.15),
)编码名无法加载时直接 panic------这属于初始化阶段的配置错误,应该在启动或测试中暴露,而非在运行时静默降级。除此以外,Chunker 初始化后可安全复用,不在分块过程中修改公开配置。
与上下游的衔接
chunker 的输入是经过图片描述管线处理后的纯文本------此时文档中的图片已被替换为结构化的文字描述,整份文档就是一个待分块的文本流。chunker 不关心文本来源,也不关心下游存储方式;它只负责将文本拆成父子块并返回 []*Chunk。
分块完成后,每个子块就是一个检索单元。但即便粒度合适,检索精度仍然受限于"用户查询的用词"与"文档内容的用词"之间的语义鸿沟。一个自然的增强手段是为每个 chunk 打上分类标签------比如"配置说明""接口定义""排错指南"------让检索时可以在向量匹配之外叠加类别过滤。这正是 classifier 子包承担的角色:在分块产出 chunk 列表后,可选地为它们附加结构化标签,进一步提升检索精度。
轻量分类与降级保护:classifier 的 fail-open 实践
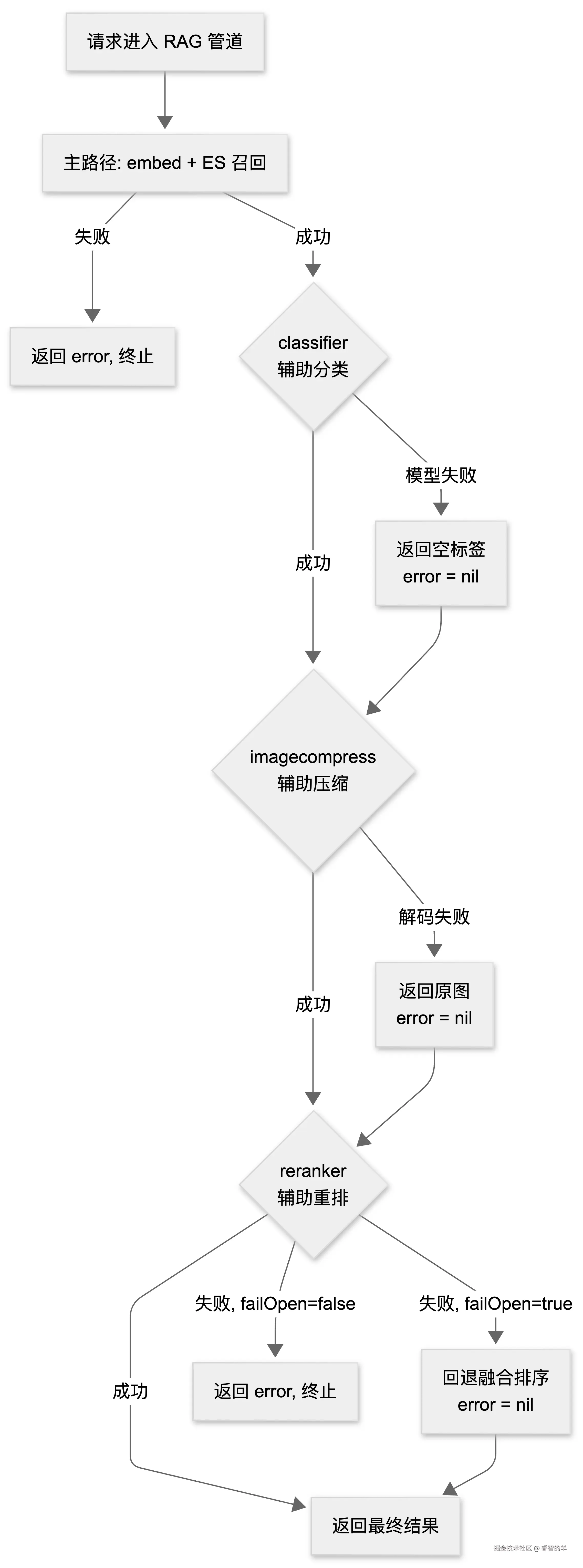
RAG 检索中,标签分类到底是锦上添花还是必需品?这个问题没有标准答案。在构建知识库时,给每个 chunk 打上主题标签确实能提升过滤效率------检索时先按标签缩小候选集,再交给向量模型做语义匹配,精度和延迟都会更好。但反过来看,如果标签打错了,反而可能把正确答案排除在召回范围之外。而如果分类本身依赖大模型调用,多出来的延迟和成本是否值得,也取决于场景。
Cove API 的 classifier 包对这个问题的回答是:分类是可选的增强能力,不是强制步骤。 它的设计哲学可以浓缩为一句话------做好该做的事,出错时安静退场,绝不拖累主流程。
整体流程:从文本到标签
classifier 的职责非常聚焦:接收一段文本和已有的标签池,调用文本模型输出最多两个宽泛主题标签。整个过程被封装在 Classify 这一个方法中。
三个核心步骤环环相扣,但每一步都埋着降级逻辑。
最小接口:TextClient 的一方法契约
classifier 不依赖任何具体的 LLM SDK。它定义的 TextClient 接口只有一个方法:
go
type TextClient interface {
Classify(ctx context.Context, prompt string, temperature float64, maxTokens int64) (string, error)
}这个接口的妙处在于:它对模型调用的抽象停留在"给一段 prompt,返回一段文本"的最原始粒度,不关心模型是 OpenAI、Claude 还是本地部署的开源模型。classifier 自身不知道也不关心消息格式、多轮对话、流式输出等概念------那些是调用方的事。
如果调用方使用的是 Cove API 内部的 core LLM 客户端,可以通过 WithClient 注入,classifier 内部会通过 llmTextClient 适配器自动完成转换:
go
type llmTextClient struct {
client corellm.Client
}
func (c llmTextClient) Classify(ctx context.Context, prompt string,
temperature float64, maxTokens int64) (string, error) {
return c.client.Invoke(ctx,
[]*corellm.Message{{Role: corellm.UserRole, Content: prompt}},
corellm.WithTemperature(temperature),
corellm.WithMaxTokens(maxTokens),
)
}而如果调用方使用的是外部模型或自定义客户端,只需实现 TextClient 接口即可,通过 WithTextClient 直接注入。两种注入方式同时存在时,后传的 option 生效,语义清晰。
这种设计让 classifier 可以独立于公司内部的基础设施演进------哪天换了模型供应商,classifier 一行代码都不用改。
模板注入:让标签体系由调用方定义
分类器的 prompt 同样不硬编码。默认模板 content_classifier.tmpl 使用了 Go template 语法:
text
你是一个内容分类助手。请阅读下面的文本,为它打 1 到 2 个宽泛的中文主题标签。
【已有标签】(请优先复用,只要语义吻合就直接选用,不要造近义词/同义词):
{{ .Existing }}
规则:
- 优先从【已有标签】中选择;只有当已有标签都明显不合适时,才创造 1 个新的宽泛标签。
...
文本内容:
{{ .Content }}模板参数由 ContentClassifierData 结构体约束:
go
type ContentClassifierData struct {
Existing string // 调用方已有标签列表拼接后的文本
Content string // 裁剪后的待分类正文
}这个设计的意义在于:业务标签体系完全由调用方控制。如果你是一家法律科技公司,希望标签在"合同法""劳动法""知识产权"等维度上分布,你只需要在 Input.ExistingTags 中传入这些候选标签,模型就会优先复用它们。如果你想完全替换 prompt------比如改用英文分类、调整标签粒度------直接调用 WithPrompt 传入自定义 prompt 即可,此时模板渲染会被关闭。
buildPrompt 还做了一个容易被忽略的工程处理:用 valuex.TruncateRunes 将正文截断到 1500 个 rune(可通过 WithSnippetRunes 调整)。这既控制了 prompt token 消耗,也避免了某些模型对过长输入的不稳定表现。
fail-open:静默降级比抛错更工程
classifier 最值得讲的设计,是它对失败的几乎"无所谓"态度。
看 Classify 的关键路径:
go
// 分类是辅助能力:模型调用失败不能阻断文档主流程。
answer, err := client.Classify(ctx, prompt, c.Temperature, c.MaxTokens)
if err != nil {
return &Result{Tags: []string{}}, nil
}
return &Result{Tags: c.parseTags(answer)}, nil模型调用失败时,返回的是 &Result{Tags: []string{}}, nil------空标签 + 无错误。parseTags 内部同理:JSON 数组提取失败、Unmarshal 失败、标签规整后全部为空------全部返回空切片,不产生 error。
整个 Classify 只在两种情况下返回 error:client 未配置,或 Parser 未配置。这两者都属于配置错误而非运行时故障------它们是调用方的 bug,应该在启动阶段就被发现并修复。运行时的一切异常------网络抖动、模型超时、输出格式异常、标签内容不符合预期------全部被静默吸收。
这种策略在工程上被称为 fail-open:失败时保持通路开放,让系统继续运行,而不是中断整条链路。与之相对的是 fail-closed------一遇到错误就返回 error,由上游决定如何处理。
在 RAG 管道中,classifier 处于非关键路径。chunk 有没有标签,不影响它能不能被检索到;向量召回和 BM25 召回都不依赖标签。如果因为分类失败而阻塞整个文档的入库流程,那就是为了一项辅助能力牺牲了核心能力------显然不划算。
换个角度看,fail-open 也让调用方的代码更干净:
go
result, _ := classifier.Classify(ctx, input)
// result.Tags 可能是 ["技术", "AI"] 也可能是 [],但代码不需要分支处理
chunk.Tags = result.Tags调用方不需要 try-catch、不需要判断 error、不需要考虑降级逻辑。分类成功就拿到标签,分类失败就拿到空切片,对下游的影响只是"标签字段为空"------这在检索时最多意味着标签过滤条件不生效,检索仍然可以走纯语义路径。
标签解析的防御性设计
parseTags 内部的防御层次也值得展开。模型输出天然不稳定------有时返回纯 JSON 数组,有时用 markdown 代码块包裹,有时在数组前后加解释文字。extractJSONArray 的处理策略很务实:
go
func extractJSONArray(answer string) string {
text := strings.TrimSpace(answer)
if strings.HasPrefix(text, "```") {
text = strings.Trim(text, "`")
text = strings.TrimSpace(strings.TrimPrefix(text, "json"))
}
start := strings.Index(text, "[")
end := strings.LastIndex(text, "]")
if start == -1 || end < start {
return ""
}
return text[start : end+1]
}先去除 markdown 包裹,再用 [ 和 ] 定位 JSON 数组。不要求模型输出严格 JSON,只要包含可识别的数组片段就能解析。
解析后的规整同样保守:每个标签截断到 16 个字符,非字符串元素(模型偶尔会输出数字或嵌套对象)被转换为字符串后过滤,最终只保留最多 2 个标签。这些限制不是随意的------它们对应了 prompt 模板中的约束("每个标签 2 到 16 个字符,最多输出 2 个"),形成了一层"即使模型不听话也不会把脏数据写入下游"的兜底。
Options 的双层配置
classifier 的 Options 设计延续了全模块的一致性模式,但多了一层值得注意的细节:构造级配置和请求级配置的分层。
构造级配置在 NewClassifier 时通过 Option 函数注入:
go
classifier := classifier.NewClassifier(
classifier.WithClient(llmClient),
classifier.WithTemperature(0.3),
classifier.WithMaxTokens(150),
)请求级配置在每次 Classify 时通过 InputOption 函数注入:
go
result, _ := classifier.Classify(ctx, input,
classifier.WithInputClient(anotherLLMClient),
)请求级 client 优先于构造级。这意味着同一个 Classifier 实例可以用默认模型处理大部分请求,而在特定场景(比如某些 chunk 需要更强模型)下临时切换。这种双层设计在不引入额外复杂度的情况下提供了足够的灵活性。
所有数据处理完毕、标签也打好了,chunk 现在可以写入向量数据库和全文索引。接下来就进入整个 RAG 管道真正对外产生价值的环节------检索。search 包如何把向量召回和 BM25 召回融合成统一的检索结果,如何通过重排进一步提升精度,正是下一部分的核心。
混合检索核心:search 包的双路召回、融合与重排
假设用户在某个 Agent 应用中输入:「如何配置 HTTPS 证书?」这条查询进入 Cove API 的 search 包后,将经历一条精心编排的多阶段检索流水线。下面以这次查询为例,完整追踪它从文本到最终结果的路径。
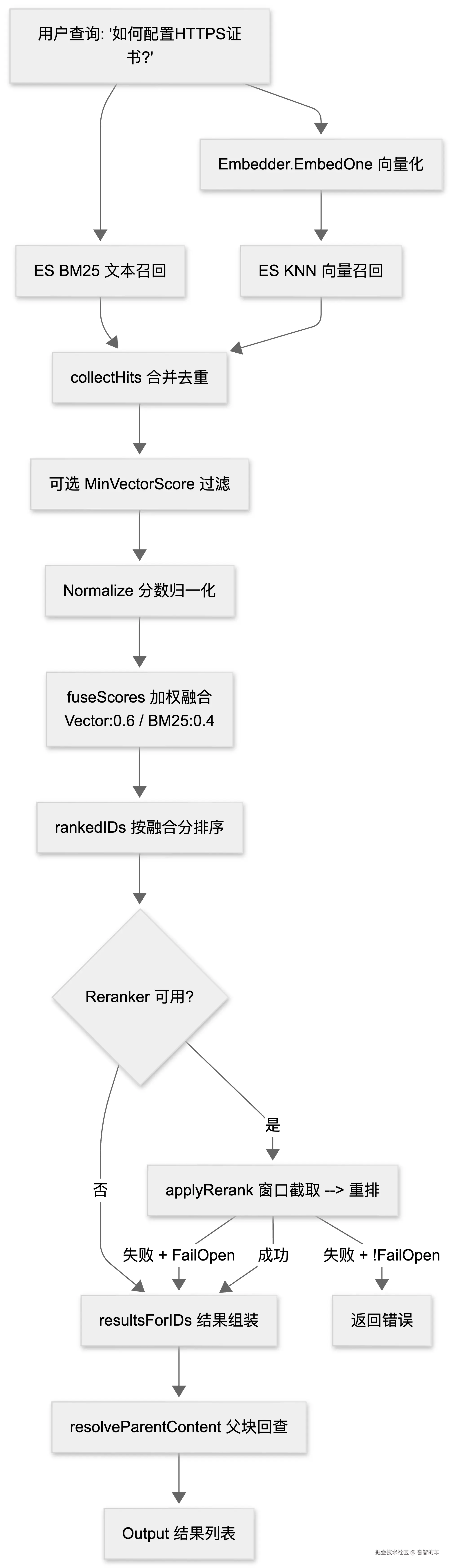
整个流程可以拆为四个阶段:双路召回、分数融合、可选重排、结果组装。每个阶段都承载了明确的工程考量。
双路召回:语义与关键词的互补
搜索的第一个关键决策是同时发起两路召回,而非二选一。
向量召回通过 Embedder.EmbedOne 将查询文本转为 1024 维向量,构造 ES knn 查询命中 vector 字段。它擅长捕捉「HTTPS 证书」与「TLS 配置」「SSL 证书安装」之间的语义关联,但也可能在查询包含精确术语时漏掉严格匹配的文档。
BM25 召回则直接对 content 字段执行 match 查询,基于词频和逆文档频率打分。「HTTPS」和「证书」作为关键词的精确命中能得到可靠的高分,不会因语义漂移被稀释。
两路召回共享同一组 filter------FilterBuilder 返回的过滤条件会同时注入 vectorQuery 和 bm25Query:
go
// vectorQuery 和 bm25Query 共享 baseFilter
knnResp, _ := s.es.Search(ctx, s.Index, vectorQuery(queryVector, recallSize, s.KnnOversample, baseFilter))
bm25Resp, _ := s.es.Search(ctx, s.Index, bm25Query(req.Query, recallSize, baseFilter))collectHits 将两路结果按 _id 合并到同一个 map,同时分别记录向量分数和 BM25 分数。同一文档在两侧都命中时,两套分数都被保留,留给后续融合阶段处理。
在融合之前,还有一个可选的门控步骤:MinVectorScore。当调用方设置该阈值时,只有 ES cosine 原始相关度达到门槛的候选才能进入融合。ES 的 cosine KNN 将分数映射为 (1 + cos) / 2,因此 filterByMinVectorScore 需要先还原真实 cosine 再比较:
go
cos := 2*score - 1
if cos < minScore {
continue
}这个门控适合精确搜索场景------用户想要与查询高度相关的文档,而非「大致相关」的内容。
分数归一化与加权融合
两路召回的分数尺度完全不同:向量分数是 cosine 相似度(映射后介于 0 到 1),BM25 分数则由词频统计决定,没有固定上界。直接相加毫无意义,必须先归一化。
Normalize 函数对每一路分数独立执行 min-max 归一化,将所有分数映射到 0, 1 区间:
go
for id, score := range scores {
out[id] = (score - lo) / (hi - lo)
}这里有一个细节:当一路中所有候选分数完全相同(hi - lo < 1e-9)时,每个条目直接返回 1,避免分母为零导致融合时全部塌缩为 0。
归一化完成后,fuseScores 执行加权线性组合:
go
fused[id] = vectorWeight*vecScores[id] + bm25Weight*bmScores[id]默认权重为 向量 0.6、BM25 0.4(defaultVectorWeight / defaultBM25Weight),偏向语义匹配但仍保留关键词匹配的影响力。这个比例由 WithVectorWeight 和 WithBM25Weight 在构造时配置,允许调用方按业务场景调整------例如法律文档检索可能调高 BM25 权重以保证术语精确匹配。
融合后的结果由 rankedIDs 按分数降序排列,分数相同时按 id 升序作为稳定 tie-break。排名列表的前 max(topK, recallSize) 个候选进入下一阶段。
重排阶段的 fail-open 设计
融合排序已经给出了一个可用结果,但 reranker(通常是一个更精准的 Cross-Encoder 模型)可以对顶部候选做二次精排。
applyRerank 的设计将 reranker 明确定位为可选增强而非必备组件。这体现在三个层面:
第一,配置可分两层。 构造级的 WithReranker 设置默认 reranker,请求级的 WithInputReranker 可在单次调用中覆盖。resolveRerankConfig 将两层配置合并,请求级优先级高于构造级:
go
config := rerankConfig{
enabled: true,
reranker: s.Reranker,
windowSize: s.RerankWindowSize,
...
}
if req.reranker != nil {
config.reranker = req.reranker
}WithInputRerankEnabled(false) 甚至可以在请求级完全关闭重排,即使构造级已配置 reranker。
第二,窗口截取控制成本。 只有融合排序后的前 windowSize 个候选被送入 reranker,默认窗口为 max(topK, recallSize)。调用方可以通过 WithRerankWindowSize 缩小窗口以降低延迟和模型调用成本。
第三,也是最重要的------fail-open。 当 config.reranker.Rerank() 返回错误时,applyRerank 不直接向上抛出:
go
reranked, err := config.reranker.Rerank(ctx, req.Query, documents, config.topK)
if err != nil {
if config.failOpen {
return candidateIDs, nil, nil // 回退到融合排序
}
return nil, nil, err
}defaultRerankFailOpen 为 true,意味着 reranker 挂掉时,系统静默退回到第一阶段的融合排序结果,检索本身不受影响。这个设计的工程含义很明确:reranker 是一个辅助服务,不应成为检索的硬依赖。调用方如果希望强制重排(例如在严格评测场景中),可以通过 WithRerankFailOpen(false) 关闭回退。
mapRerankResults 还做了额外的防御:越界下标、重复下标、低于 minScore 的结果都会被静默丢弃------外部 reranker 的行为不被完全信任,core 层自己做兜底校验。
子块命中与父块回查
检索结果进入 resultsForIDs 组装阶段。这里有一个容易被忽略但实际影响上下文完整性的机制:parent chunk 回查。
在 chunker 的父子块设计中,子块(child)被索引以支持细粒度召回,但子块内容往往是不完整的句子片段。resolveParentContent 在组装结果时检查每条命中的 parent_id 字段:
go
parentID := valuex.String(src["parent_id"])
if parentID == "" {
return valuex.String(src["content"]), nil
}
resp, err := s.es.Search(ctx, s.Index, map[string]any{
"size": 1,
"query": map[string]any{
"bool": map[string]any{
"filter": []any{
map[string]any{"term": map[string]any{"chunk_id": parentID}},
},
},
},
})如果当前命中是子块且存在父块,则通过 ES 的 term 查询回查父块,用父块的完整内容替换 Output.Content。如果父块查询失败或父块内容为空,则退回使用子块自身的 content 字段。
这意味着上层调用方拿到的 Output.Content 始终是完整上下文------即使命中发生在子块级别。对于 Agent 场景的下游 LLM 调用,这直接决定了生成回答的信息完整性。
贯穿全流程的配置分层
search 包的配置体系值得单独关注。Options(构造级)定义 Searcher 的长期配置------索引名、维度、权重、默认 reranker;InputOption(请求级)通过一系列 WithInput* 函数覆盖单次请求行为。这种双层设计让同一 Searcher 实例可以在不同请求中使用不同的 embedder、reranker 甚至完全关闭重排,而无需创建多个实例。
从 NewSearcher 的默认值可以看到包的保守设计哲学:默认 topK=5、recallSize=20、embeddingDim=1024、rerankFailOpen=true------所有参数都倾向于「先跑起来,再按需调优」。
整个 search 包大量运用了泛型 Searcher[T] 和 SourceDecoder[T] 来实现类型安全的业务元数据解码,Embedder、Reranker、ESClient 等核心接口则各只有一个方法------这些贯穿全模块的接口抽象和泛型设计模式,在后文将单独展开总结。
Mermaid 工具遇到环境限制,我将直接使用语法正确的 Mermaid 代码。现在开始编写章节。
贯通设计:Options 注入、接口抽象与泛型 SearcherT
如果让你设计一个 RAG 框架,你会怎么做?是在每个子模块里硬编码模型 SDK 调用、写死分块参数、用 interface{} 搬运检索结果------还是把这些选择权交还给调用方?Cove API 的 rag 模块选择了后者。当你横向看完七个 sub-package 的代码,会发现它们共享同一套设计基因:Options 注入控制行为、最小接口抽象解耦外部依赖、泛型承载类型安全、fail-open 保护非关键路径。这四个模式不是某个子包的局部选择,而是贯穿全模块的架构约定。
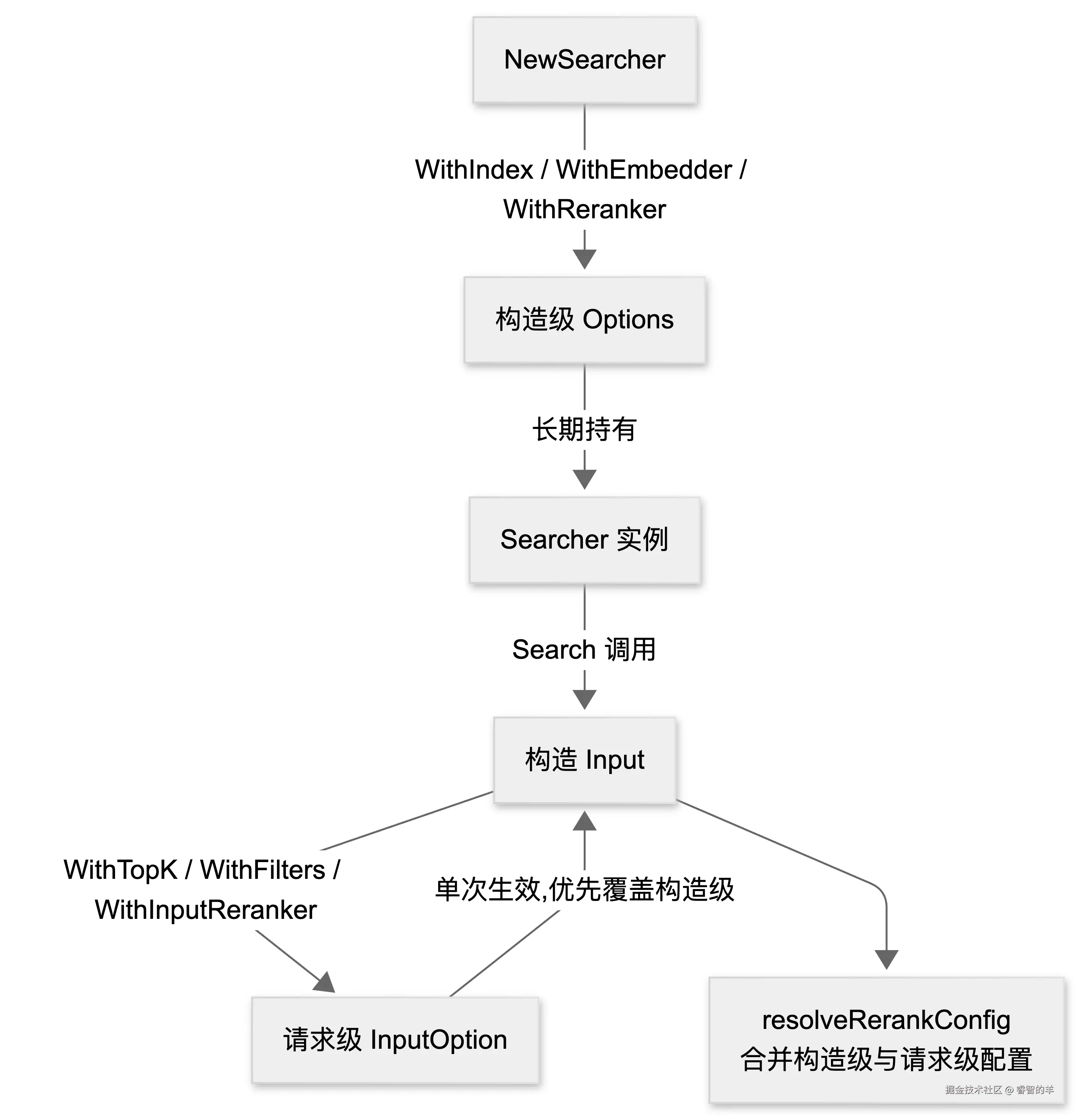
Options 模式:构造级配置与请求级配置的双层分离
所有子包无一例外地采用 type Options struct + type Option func(*Options) + With* 函数簇的模式。chunker 的 WithChildChunkTokens、classifier 的 WithTemperature、documentparse 的 WithExtractor、webcrawl 的 WithTimeout------命名不同,结构完全一致。这不是巧合,而是一种刻意的工程约束:调用方永远通过函数式 Option 注入配置,模块内部永远不假设配置来源。
但真正的设计亮点不在"都用 Options",而在 search 包对"构造级"和"请求级"的明确切分。
search 包有两套配置体系:Option 用于 NewSearcher 构造时注入,影响 Searcher 的整个生命周期;InputOption 用于每次 Search 调用时注入,只影响当次请求。
go
// 构造级:创建 Searcher 时通过 Option 注入,长期持有
searcher := search.NewSearcher[MySource](esClient,
search.WithIndex("my_cove_chunks"), // 索引名------构造级
search.WithEmbedder(myEmbedder), // 向量化客户端------构造级
search.WithReranker(myReranker), // 重排器------构造级
search.WithFilterBuilder(myFilter), // 过滤构造器------构造级(但延迟执行)
)
// 请求级:每次 Search 调用时通过 InputOption 注入,单次生效
results, _ := searcher.Search(ctx, "什么是 RAG?",
search.WithTopK(10), // 返回数量------请求级
search.WithFilters(tenantFilter), // 本次筛选条件------请求级
search.WithInputRerankEnabled(false), // 本次跳过重排------请求级
)为什么 WithIndex 是构造级而 WithTopK 是请求级?因为索引名是 Searcher 的物理锚点,一旦创建就不该在运行时切换;而返回数量、过滤条件、是否启用重排这些参数天然随查询语义变化。这个区分看似琐碎,实际上把"这个 Searcher 连到哪里"和"这次搜索要什么"两个关注点干净拆开了。
下面的流程图展示了双层 Options 的注入和决议路径:
classifier 也采用同样的双层设计:WithClient 设置长期 client,WithInputClient 在 Classify 时覆盖。不过 chunker、documentparse、webcrawl 只用了单层构造级 Options------因为它们的行为不随单次请求语义变化,强行拆分反而过度设计。
接口最小化:每个接口只定义一个方法
如果你打开各子包的 types.go,会发现一个规律:几乎每个接口只有一个方法。
| 子包 | 接口 | 唯一方法 |
|---|---|---|
| search | Embedder |
EmbedOne(ctx, text, dims) ([]float64, error) |
| search | Reranker |
Rerank(ctx, query, docs, topN) ([]RerankResult, error) |
| search | ESClient |
Search(ctx, index, query) (map[string]any, error) |
| classifier | TextClient |
Classify(ctx, prompt, temp, maxTokens) (string, error) |
| documentparse | Extractor |
Extract(ctx, input) (string, error) |
| documentparse | TextDecoder |
Decode(data) (string, error) |
| webcrawl | HTTPClient |
Do(req) (*http.Response, error) |
| webcrawl | Extractor |
Extract(ctx, page) (*Output, error) |
| webcrawl | URLGuard |
Validate(ctx, rawURL) error |
| webcrawl | Resolver |
LookupIP(ctx, host) ([]net.IP, error) |
| imagedescribe | VisionClient |
Describe(ctx, prompt, imgBase64, mime, maxTokens) (string, error) |
| imagedescribe | Compressor |
Compress(input) (*Output, error) |
这不是巧合,而是刻意的最小化设计。以 Embedder 为例:
go
type Embedder interface {
EmbedOne(ctx context.Context, text string, dimensions int) ([]float64, error)
}只定义 EmbedOne,不定义 EmbedBatch、不定义模型类型枚举、不定义 token 计数。因为 search 包只需要"把一条查询文本变成向量"这一个能力。批量向量化是下游业务的事,token 计数是 chunker 的事------模块不管不该管的事。
同样的,classifier 的 TextClient 只暴露 Classify 一个方法:
go
type TextClient interface {
Classify(ctx context.Context, prompt string, temperature float64, maxTokens int64) (string, error)
}classifier 不关心这个 client 背后是 OpenAI 还是本地模型、是否支持流式输出、conversation history 怎么管理。它只需要"给我一段 prompt,还我一段文本"。
这种最小接口的工程价值在于:调用方适配成本极低。想接入一个新的 embedding 服务?实现一个方法就行。想替换视觉模型?实现 VisionClient 的一个方法就行。模块不绑定任何 SDK,不引入任何第三方模型依赖。
泛型 SearcherT:类型安全的业务元数据解码
检索结果的 _source 是 ES 返回的 map[string]any。如果直接把 map[string]any 抛给调用方,业务代码就要到处做类型断言,既繁琐又危险。Cove API 的方案是:让 Searcher 本身泛型化,让调用方通过 SourceDecoder[T] 定义自己的解码逻辑。
go
// SourceDecoder 把 ES _source 解码成调用方需要的类型
type SourceDecoder[T any] func(src map[string]any) (T, error)
// Searcher 不理解业务字段,业务元数据通过 SourceDecoder 解码到 Output.Source
type Searcher[T any] struct {
Options
es ESClient
sourceDecoder SourceDecoder[T]
}
// Output 的 Source 字段直接是调用方定义的类型 T
type Output[T any] struct {
ID string
Content string
Score float64
RerankScore *float64
Source T // 不是 interface{},是 T
}这个设计的精妙之处在于 NewSearcher 中的类型恢复:
go
func NewSearcher[T any](esClient ESClient, opts ...Option) *Searcher[T] {
searcher := &Searcher[T]{...}
for _, opt := range opts {
opt(&searcher.Options)
}
// WithSourceDecoder 在 Options 中以 any 存储,这里通过类型断言恢复到具体类型
if decoder, ok := searcher.Options.sourceDecoder.(SourceDecoder[T]); ok {
searcher.sourceDecoder = decoder
}
return searcher
}由于 Go 泛型的限制,WithSourceDecoder[T] 的泛型参数无法直接传导到 Options.sourceDecoder 字段(Options 是非泛型结构体),因此采用了"存储为 any,构造时类型断言恢复"的桥接方式。调用方对此完全无感------只要 NewSearcher 的类型参数和 WithSourceDecoder 的类型参数一致,一切类型安全:
go
type MySource struct {
DocID string `json:"doc_id"`
Category string `json:"category"`
}
decoder := func(src map[string]any) (MySource, error) {
// 自定义解码逻辑
}
searcher := search.NewSearcher[MySource](esClient,
search.WithSourceDecoder(decoder),
)
results, _ := searcher.Search(ctx, "query")
// results[0].Source 的类型是 MySource,不是 interface{}
fmt.Println(results[0].Source.Category) // 类型安全,IDE 有补全resultsForIDs 方法在组装结果时调用 sourceDecoder,一旦解码失败会直接返回错误而不是静默丢弃------这意味着业务元数据的完整性是可验证的。
fail-open:非关键路径的统一降级哲学
RAG 管道中有些环节是"没它不行"的------比如向量化查询、ES 检索------这些环节失败必须返回错误。但更多环节属于"锦上添花":分类标签、图片压缩、重排。这些辅助能力失败时,管道应该继续运转还是整体报错?
Cove API 的选择是统一的 fail-open:辅助能力失败时静默降级,不阻断主流程。
classifier 最典型。在 Classify 方法中,模型调用失败直接返回空标签:
go
// 分类是辅助能力:模型调用失败不能阻断文档主流程。
answer, err := client.Classify(ctx, prompt, c.Temperature, c.MaxTokens)
if err != nil {
return &Result{Tags: []string{}}, nil // 空标签,error 为 nil
}不光是模型调用失败,JSON 解析失败同样降级------parseTags 在 extractJSONArray 返回空串或 Unmarshal 失败时返回空切片,不抛错误。
imagecompress 遵循同样的原则。Compress 方法中,解码失败或重编码失败都返回原图:
go
// 解码失败通常意味着格式暂不支持或数据损坏;压缩器降级返回原图,不把辅助失败升级为业务错误。
img, _, err := image.Decode(bytes.NewReader(input.Data))
if err != nil {
return out, nil // 返回原图,error 为 nil
}imagedescribe 的 parse 方法在 JSON 解析失败时,用模型原文作为兜底描述:
go
if err := d.Parser.Unmarshal(answer, &raw); err != nil {
// 模型没有按 JSON 返回时,将原文作为描述兜底,避免上层丢失可检索文本。
return &Description{
Description: truncate(answer, maxDescriptionRunes),
Objects: []string{},
}
}search/rerank 则更进一步------不仅默认 fail-open,还把选择权交给了调用方:
go
// rerank 是可选增强;fail-open 时保留第一阶段融合结果,避免辅助服务阻断检索。
if config.failOpen {
return candidateIDs, nil, nil // 回退到融合排序
}
return nil, nil, err // failOpen=false 才暴露错误RerankFailOpen 默认值为 true,调用方可以通过 WithRerankFailOpen(false) 显式关闭。这种设计在"安全默认"和"可观测性"之间找到了平衡:生产环境默认降级保可用,调试时可以关闭降级来排查 reranker 问题。
这四个模式不是独立存在的。把它们放在一起看:Options 模式让调用方控制所有行为参数,最小接口让调用方自由替换外部依赖,泛型 SearcherT 让调用方以类型安全的方式拿到业务数据,fail-open 让调用方可以安全地把辅助能力当作可选增强而非必需品。它们共同表达了一个设计立场------这套 RAG 模块不是黑盒引擎,而是一组调用方握有全部控制权的可组合工具。
正是这些设计模式------模块化拆解、接口抽象、Options 注入、fail-open 降级------共同构成了一套可组合的 RAG 工具体系,而非一个黑盒引擎。
结论
Cove API 的 rag 模块展示了一种将 RAG 能力模块化、可组合化的实践思路。它不试图提供"开箱即用的一体化 RAG 引擎",而是将管道中的每一步------文档解析、文本分块、图片处理、内容分类、网页抓取、混合检索------都封装为独立、低耦合的子包,每个子包通过接口契约与调用方交互,不绑定具体的模型 SDK、数据库或业务标签体系。
这种设计带来的好处是显而易见的:调用方可以按需选取子包,用 Options 模式注入自己的适配器,在保持核心流程不变的前提下灵活替换底层实现。同时,模块在辅助能力(如分类、重排)上采用了 fail-open 策略,确保非关键路径的失败不会中断主流程,体现了工程上对鲁棒性的重视。
对于有 Agent 开发经验的工程师来说,这套模块的最大启发或许在于:RAG 管道的"封装"不一定要封装成一个黑盒,把每个环节封成可替换的积木块,往往比一个精巧但难以修改的整体方案更有生命力。
项目地址
本文里的实现已经整理在 GitHub:
- GitHub:github.com/chenyang-zz...
- 技术栈:Go / Gin / PostgreSQL / Elasticsearch / Neo4j / Redis / asynq
- AI 能力:SSE 流式对话、RAG、Agent、长期记忆、MCP、Anthropic / OpenAI 多 Provider
- 工程能力:分层架构、异步任务、OpenAPI 生成、Repository 生成、Docker Compose 本地启动
如果你正在做 AI 应用后端、企业知识库、Agent 平台,或者想参考一套 Go 版本的 RAG + Agent 工程结构,可以直接 clone 跑起来看。项目还在持续迭代,欢迎 Star,也欢迎通过 Issue 交流真实使用场景。