通用大模型存在知识滞后、上下文容量有限、容易编造事实(幻觉)等固有缺陷,无法直接调用企业私有文档、实时互联网信息。RAG(检索增强生成)作为轻量化外部知识接入方案,无需重新训练模型,仅通过检索外部资料补充上下文,是当前 AI 应用落地的标配技术。本文简单介绍RAG:
一、RAG 诞生逻辑与标准系统架构
大模型的知识全部固化在训练权重中,一旦训练结束,无法获取新数据;同时模型上下文窗口存在上限,海量行业文档无法全部塞入对话。2017 年 "检索 + 生成" 的基础思路被提出,2020 年 RAG 正式被定义,核心思路为先检索、再生成,分为检索器、生成器两大核心组件。
完整运行流程分为四步:首先将 PDF、合同、网页等原始文档切分为固定长度文本块,避免单份文件过长占用上下文;其次通过索引机制存储文本与对应特征;用户发起提问时,检索器匹配与问题高度相关的文本片段;最后将检索结果和用户问题拼接为提示词送入大模型,限定 AI 仅依靠参考资料作答,从根源降低幻觉。
区别于全量微调,RAG 仅新增检索流程,文档更新时只需重新索引,不用改动大模型权重,适配企业文档频繁更新的场景,也是中小团队低成本搭建知识库问答的首选方案。
二、两类检索路线与工程优化方案
检索器的性能直接决定 RAG 回答准确度,行业主流分为基于词项、基于嵌入两条技术路线,生产环境多采用二者结合的混合检索。
基于词项检索以 BM25、TF-IDF 算法为代表,依靠关键词匹配文档,计算速度快、部署成本低,依靠倒排索引快速定位包含指定词汇的内容。但该方案只能识别字面文字,无法理解语义,搜索 "Transformer 架构" 时会同时返回电器变压器、电影《变形金刚》相关无关内容。
基于嵌入检索通过嵌入模型将文本转为多维向量,存入 Milvus、FAISS 等向量数据库,依靠语义相似度匹配内容,能区分一词多义。但向量生成、向量搜索会增加算力开销,大规模数据场景成本更高。
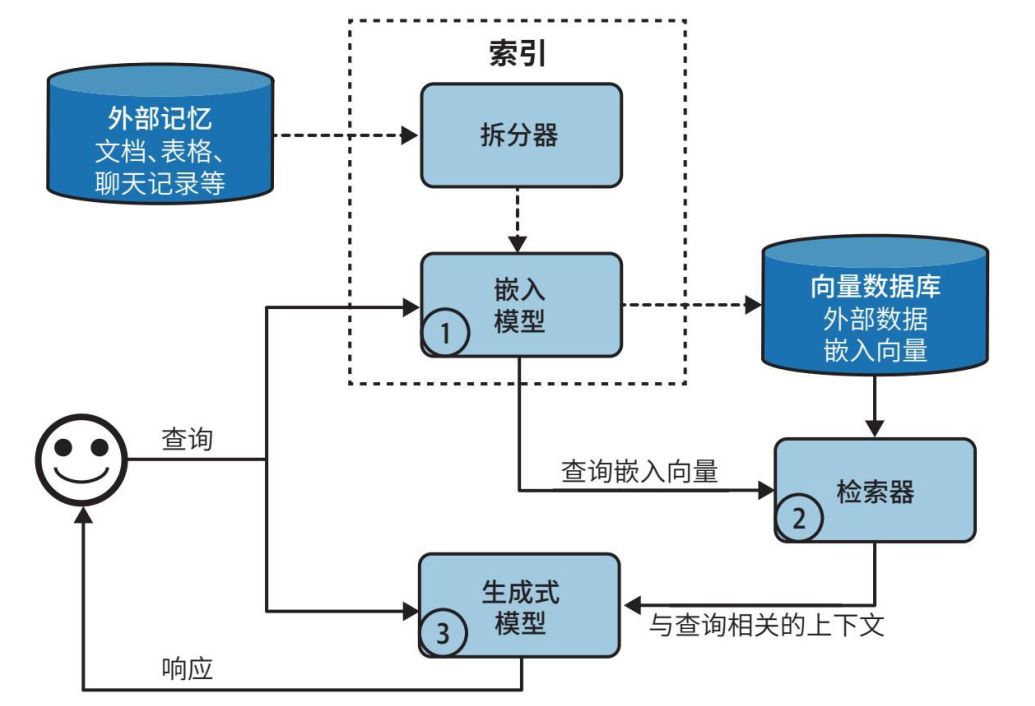
为平衡精度与开销,工业落地衍生多重优化手段:采用重叠分块避免关键信息被截断;使用重排序工具筛选初次检索结果;通过查询重写补全对话模糊提问;同时混合检索先用 BM25 粗筛,再用向量模型精细排序,兼顾速度与语义识别能力。
三、RAG 技术拓展:多模态与结构化表格落地
传统 RAG 仅支持纯文本检索,如今已拓展至多模态、结构化表格两大场景,覆盖更多企业业务需求。
多模态 RAG 依托 CLIP 等多模态嵌入模型,可同时处理文字、图片、音视频。电商智能客服场景中,用户上传产品故障图片提问,系统能同步检索产品图文说明书,图文结合给出维修方案;教育场景可检索课本配图与对应知识点文字,实现图文同步答疑。
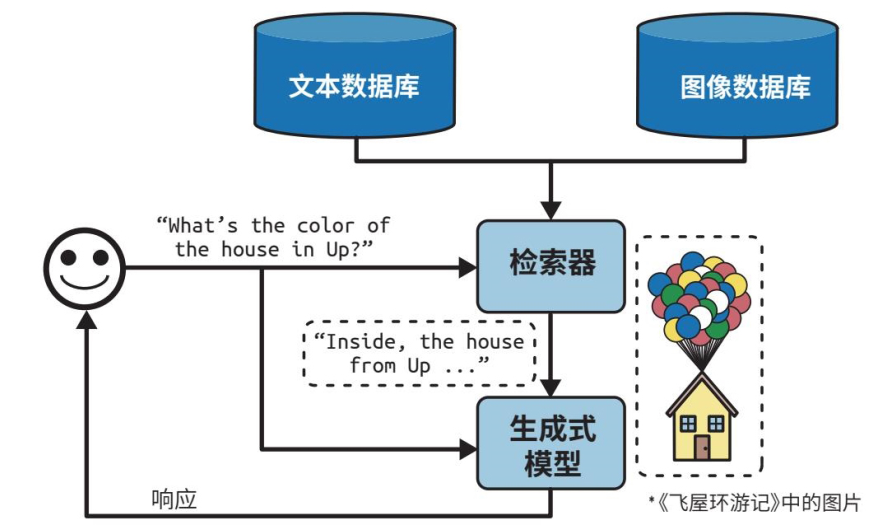
面向表格数据的 RAG 则新增文本转 SQL 能力,针对销售、财务数据表,AI 自动生成查询语句读取数值。例如电商运营提问近一周单品销量,系统生成 SQL 提取表格数据后再整理自然语言答案,解决大模型不擅长统计计算的问题。
两类拓展方案大幅拓宽 RAG 适用边界,智能客服、企业数字调研、本地文档助手等产品均以此为底层核心。
RAG 通过检索外部资料补充大模型上下文,低成本解决模型幻觉、知识滞后、私有数据无法读取的痛点。词项检索与向量检索各有优劣,混合检索、分块优化、重排序等工程手段可显著提升检索精度。随着多模态、表格检索技术成熟,RAG 不再局限于纯文本问答,成为企业 AI 落地的基础组件。同时 RAG 也是 AI 智能体的核心工具之一,为智能体提供长期外部记忆,是连接大模型与现实业务数据的关键桥梁。