nano-vllm 用千行代码拆解 vLLM 核心,是读懂大模型推理最快的捷径。
1. 介绍
上一篇把张量并行的三种切法(weight、vocab、head)讲完了。但 TP 这几篇的代码都在单进程里模拟两卡------把 tp_size、tp_rank 当参数手动传进去。
真实的多卡是多进程:每张卡一个进程,tp_size、tp_rank 从 dist 取。本篇看这套多进程怎么搭------进程怎么起、rank0 怎么把一次方法调用(比如每个 step 的 run)传给每张卡、跑完怎么收摊。
2. 总览
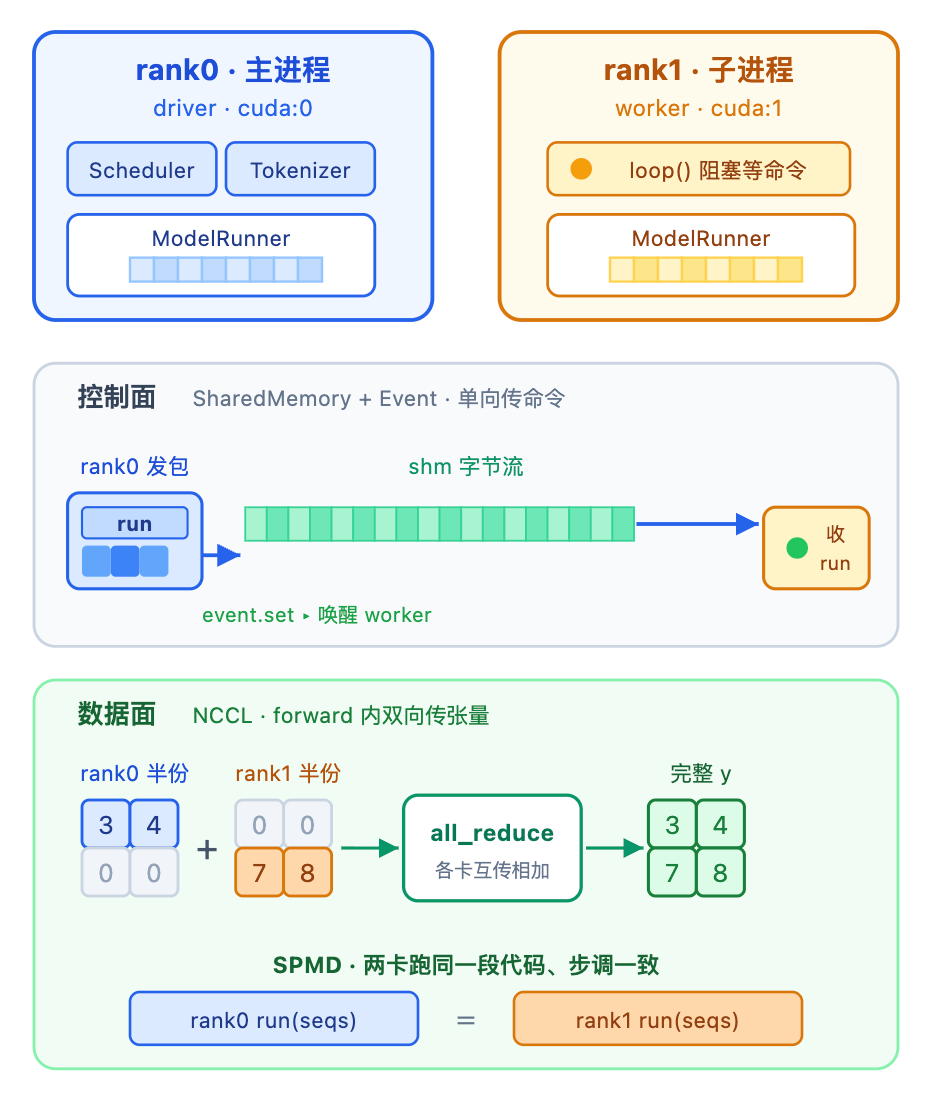
以 tp=2 为例。LLMEngine 在主进程里起 1 个子进程,连自己共 2 个进程,每进程占一张卡、各跑一个 ModelRunner。
- rank0 在主进程 ,是 driver:握着
Scheduler、Tokenizer,跑generate主循环,自己也兼一个本卡ModelRunner。 - 其余 rank 在子进程 ,是 worker:只有一个
ModelRunner,平时阻塞在loop()里等命令。
两进程靠两条通道协作:
- 控制面 (
SharedMemory+Event):rank0 单向广播「该跑哪个方法」给 worker。 - 数据面 (NCCL):forward 内部的
all_reduce、gather走这条,前几篇的张量通信都在这里。
核心是 SPMD :所有卡跑同一段代码。rank0 通过控制面让每张卡都调用同一个方法、同一批参数,于是代码跑到 all_reduce 那行时所有卡正好都到齐------数据面的集合通信才对得上。
打个比方:rank0 像工头对着对讲机喊「现在都做 run」,每个工人(worker)听到同样的指令、对着自己那份料各做各的,做到要合料的工序(all_reduce)时正好都到齐。
3. 起进程
一个 Python 进程只有一个 GIL(全局解释器锁,同一时刻只准一个线程执行 Python 代码),CPU 端一次只能往一张卡发 kernel。要让多张卡真正并行,就得多进程------每进程一个 GIL、独占一张卡。
起子进程用 spawn 而非 fork:fork 会继承父进程已初始化的 CUDA 上下文,而 CUDA 不支持这样跨进程复用;spawn 起一个全新的 Python 解释器,各自干净地初始化 CUDA。
主进程循环起 tp_size - 1 个子进程(rank 1...tp-1),每个 target=ModelRunner、占一张卡;rank0 的 ModelRunner 留在主进程。每个子进程分一个 Event,rank0 收下全部 Event 的列表(广播时逐个 set)。
python
import torch.multiprocessing as mp
# LLMEngine.__init__(只留起进程部分)
def __init__(self, config):
self.ps, self.events = [], []
ctx = mp.get_context("spawn") # 全新解释器,CUDA 不能 fork
for i in range(1, config.tensor_parallel_size): # rank 1...tp-1
event = ctx.Event()
p = ctx.Process(target=ModelRunner, args=(config, i, event))
p.start() # 子进程跑 ModelRunner(config, i, event)
self.ps.append(p)
self.events.append(event)
# rank0 留主进程,拿到所有子进程的 event 列表
self.model_runner = ModelRunner(config, 0, self.events)进程起来后
每个 ModelRunner 一启动,先 dist.init_process_group("nccl", ...) 加入 NCCL 组------NCCL 是 NVIDIA 的多卡通信库,专管 GPU 之间传张量,这就是数据面,前几篇的 all_reduce、gather 都走它。接着各自 set_device(rank)、建模型、加载权重、warmup、分配 KV cache。
rank0 建好共享内存就返回、回 LLMEngine 干活;worker 打开同一块共享内存后,执行 loop() 阻塞等命令。
中间的 dist.barrier() 是一道栅栏:所有进程都到了才放行。rank0 先建好共享内存再过栅栏,worker 过栅栏后才去打开------保证它打开时共享内存已存在。
python
# ModelRunner.__init__
def __init__(self, config, rank, event):
dist.init_process_group("nccl", "tcp://localhost:2333",
world_size=self.world_size, rank=rank) # 加入数据面
# ... set_device、建模型、加载权重、warmup、分配 KV cache ...
if self.world_size > 1:
if rank == 0:
self.shm = SharedMemory(name="nanovllm", create=True, size=2**20)
dist.barrier() # 建好共享内存,等所有进程到齐
else:
dist.barrier()
self.shm = SharedMemory(name="nanovllm") # 打开同一块
self.loop() # 扎进 loop 阻塞等命令4. 一次 call 怎么传到每张卡
控制面用两个多进程原语搭起来:
SharedMemory:一块多个进程都能映射进各自地址空间、直接读写的内存,相当于一块公共白板。进程之间内存本来互相隔离,有了它 rank0 在白板上写、worker 在白板上读,不用拷贝、最快。Event:一个跨进程的信号灯,有wait/set/clear。光有白板,worker 不知道「写好了没」,只能空转干等;Event让 worker 先阻塞在wait()上,rank0 写完set()一下把它叫醒。
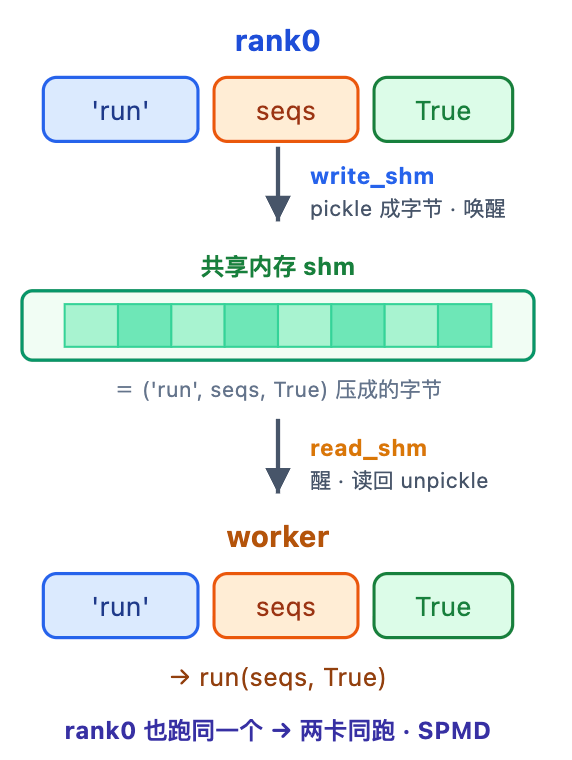
rank0 要让每张卡都跑某个方法(比如每个 step 的 run),入口是统一的 call:
- rank0 调
call:先write_shm把方法名和参数广播出去,再自己执行。 - worker 在
loop()里read_shm收到,再call执行(worker 不广播,否则会循环执行)。
python
import pickle
# ModelRunner 的控制面四个方法
def write_shm(self, method_name, *args): # 只有 rank0 调
data = pickle.dumps([method_name, *args])
n = len(data)
self.shm.buf[0:4] = n.to_bytes(4, "little") # 前 4 字节:长度 n
self.shm.buf[4:n+4] = data # 其后:pickle 字节流
for event in self.event: # 逐个唤醒 worker
event.set()
def read_shm(self): # 只有 worker 调
self.event.wait() # 阻塞,被 set 唤醒
n = int.from_bytes(self.shm.buf[0:4], "little")
method_name, *args = pickle.loads(self.shm.buf[4:n+4])
self.event.clear() # 复位,等下次
return method_name, args
def call(self, method_name, *args): # 两边共同入口
if self.world_size > 1 and self.rank == 0:
self.write_shm(method_name, *args) # 只有 rank0 广播
method = getattr(self, method_name, None)
return method(*args) # 各卡都执行
def loop(self): # worker 主循环
while True:
method_name, args = self.read_shm()
self.call(method_name, *args)
if method_name == "exit":
breakwrite_shm:先 pickle 成字节流(pickle 就是把 Python 对象和字节互相转换,即序列化),前 4 字节写长度 n (读时才知道截到哪),其后写数据,最后 event.set() 逐个唤醒 worker。
read_shm:event.wait() 一直阻塞,被唤醒后先读 4 字节拿 n、再按 n 截出字节流 unpickle,最后 event.clear() 复位,好等下一次。
call 是 rank0 和 worker 的共同入口,但只有 rank0 会 write_shm------worker 的 call 由 loop 调,再广播就死循环了。两边最后都 getattr 执行同一个方法,这就是 SPMD。
loop:worker 一辈子在这转------读一条、执行一条,直到读到 "exit" 才跳出。
为什么方法调用走共享内存、不走 NCCL?NCCL 只传张量,而这里要传的是方法名加 seqs 这种 Python 对象,pickle 进共享内存最直接(开 2²⁰ 字节够装一批请求的元数据)。
5. 退出清理
generate 跑完,LLMEngine 在 atexit 里调 call("exit")------和 run 同一条控制面,把 "exit" 广播给每个 worker。worker 的 loop 读到 "exit",执行完 exit 就 break 出循环、进程结束;主进程再 join 等它们退干净。
exit 做三件收尾:关掉共享内存(rank0 还要 unlink 真正删除)、销毁 NCCL 进程组、同步 CUDA。
python
import torch
# ModelRunner.exit
def exit(self):
if self.world_size > 1:
self.shm.close() # 关掉本进程的共享内存映射
dist.barrier() # 等所有进程都 close 完
if self.rank == 0:
self.shm.unlink() # rank0 真正删除共享内存
if not self.enforce_eager:
del self.graphs, self.graph_pool # 释放 CUDA Graph
torch.cuda.synchronize()
dist.destroy_process_group() # 拆掉 NCCL 组6. 小结
多卡的多进程架构到这里清楚了:
- 起进程 :每卡一进程(
spawn,CUDA 不能 fork),rank0 留主进程当 driver,其余 worker 进loop()阻塞等命令;dist.barrier握手保证共享内存建好再打开。 - 控制面 (
SharedMemory+Event):rank0write_shm广播方法名+参数、event.set()唤醒;workerread_shm收下执行。call是两边共同入口,只有 rank0 广播。 - 数据面 (NCCL):forward 里的
all_reduce、gather走这条。 - 两条通道合起来就是 SPMD:所有卡跑同一段代码、步调一致,集合通信才对得上。
- 退出 :
call("exit")广播,worker 跳出loop,各自关共享内存、拆 NCCL 组。
张量并行至此介绍完毕。下一篇端到端跑通整个推理引擎。