
💡 一句话:基于方舟 Agent Plan,结合最新大模型 + 全新 Harness 能力(专业数据集 + 豆包搜索 + Agent 记忆 + 火山引擎 Supabase) ,通过 Codex 把散落在飞书会话、纪要、云文档里的私域销售资料和外部专业信息,搭成一个能查公司、看档案、问历史的销售团队定制工作台。
更多 CookBook 可见:方舟 Agent Plan「CookBook」(公开版)
一、解决什么痛点
销售资料散在 5 个地方 ------ 飞书群、会议纪要、云文档、客户需求、上传材料。切窗口、找文件、问"上次他们说了啥"......全靠手。
目标: 一个工作台,围绕销售目标管理公司池、自动生成最近档案、对历史资料做问答。
🏆 本案例的目标是教用户如何通过 Codex 和 Agent Plan Harness,从零开发一个销售场景工作台,并将开发过程沉淀为可复用 Skill,方便后续继续迭代。
「核心使用能力」
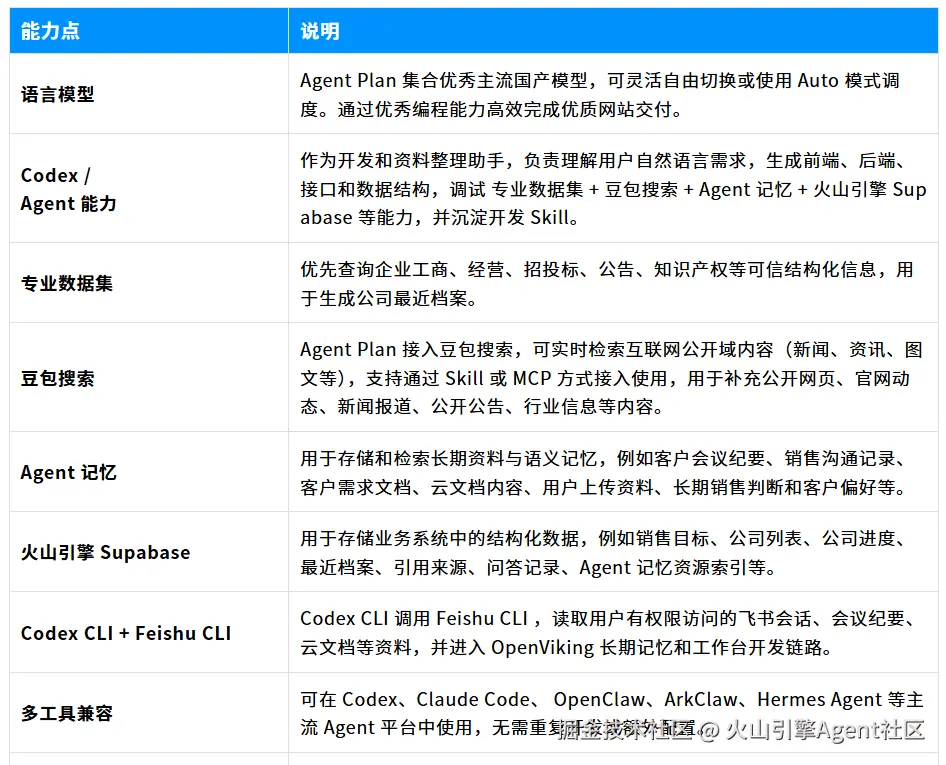
🏆 快速理解:
- Codex 负责开发和资料整理;
- Agent Plan 语言模型负责生成与总结;
- 专业数据集负责可信企业数据;
- 豆包搜索负责公开信息补充;
- Agent 记忆负责长期资料和语义检索;
- 火山引擎 Supabase 负责结构化业务状态和资料索引;
- Codex CLI + Feishu CLI 负责获取用户有权限访问的飞书资料。
二、前置准备
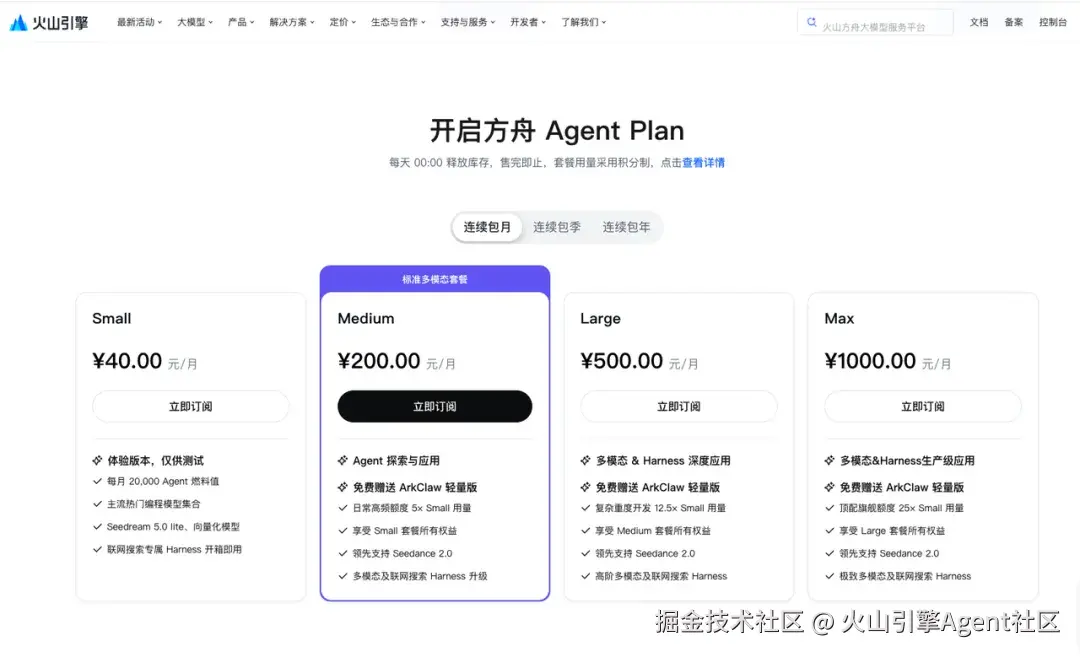
Step1 购买 Agent Plan 套餐
请登录「火山方舟」或「官网活动页」,购买 Agent Plan 套餐。
建议购买 Medium 及以上套餐,以获得更完整的 Agent 模型与 Harness 使用体验。Small 套餐更适合基础测试和体验。
Step2 快速配置
需要获取 Agent Plan 支持的专属 Base URL、专属 API Key 及模型配置,才能正常使用并抵扣套餐额度。
推荐使用 Ark Helper一键安装模型及 mcp。 以下为该项目所使用的配置信息,您可按需选择。
方式 1:自动化配置 (推荐)
配置项:Ark Helper
说明: Ark Helper 是一个编码工具助手,支持快速配置选择的工具接入 Agent Plan。

方式 2:手动配置
配置项:配置模型及专属 Base URL
说明: 获取 Agent Plan 的专属 Base URL、模型配置。套餐集合优秀主流国产模型,可灵活自由切换或使用 Auto 模式调度。详见快速开始
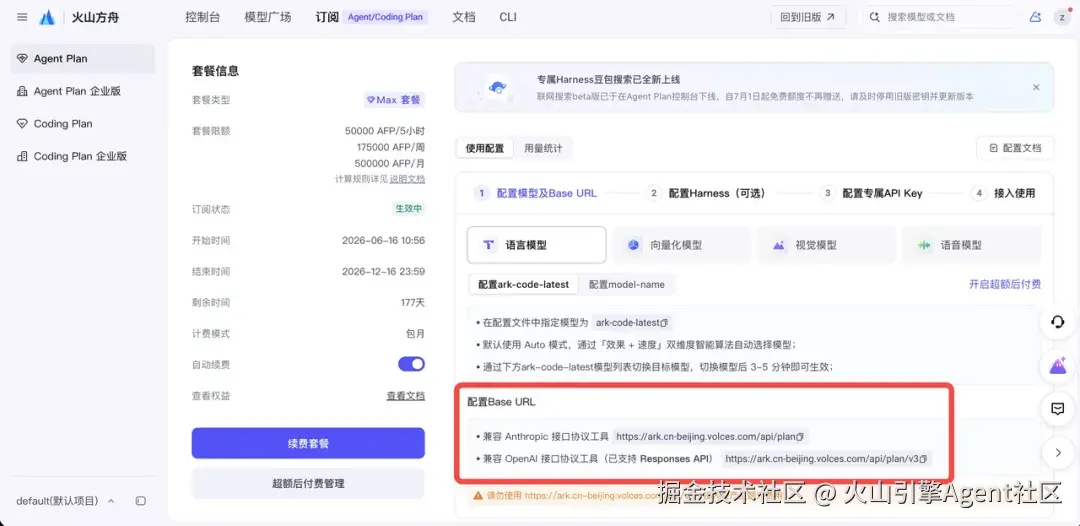
配置项:获取专属 API Key
说明: 请注意 Agent Plan 使用专属 API Key,请勿混用。
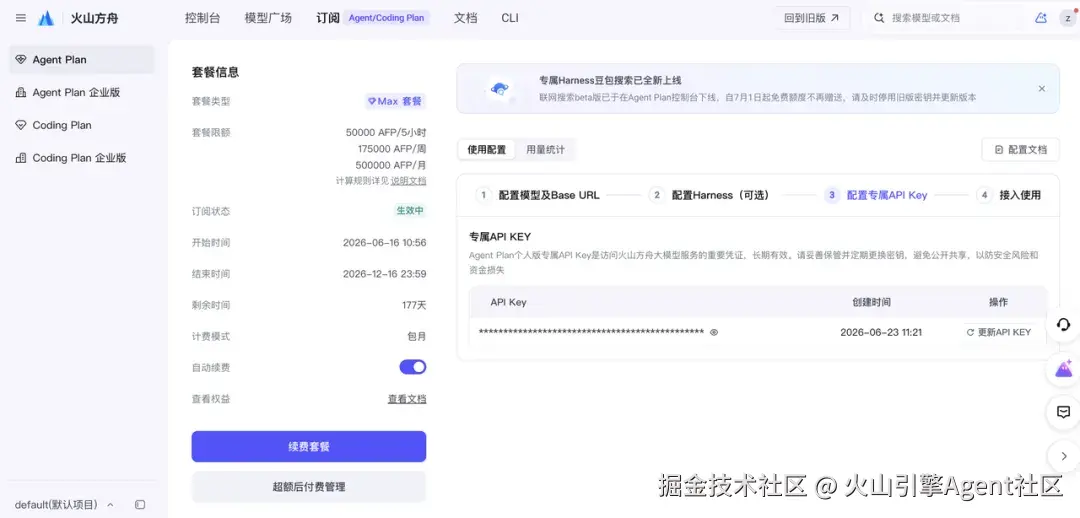
配置项:配置 DataPro / 专业数据集 MCP
说明: 可在控制台「配置 Harness」处开启抵扣。具体参照专业数据集配置文档
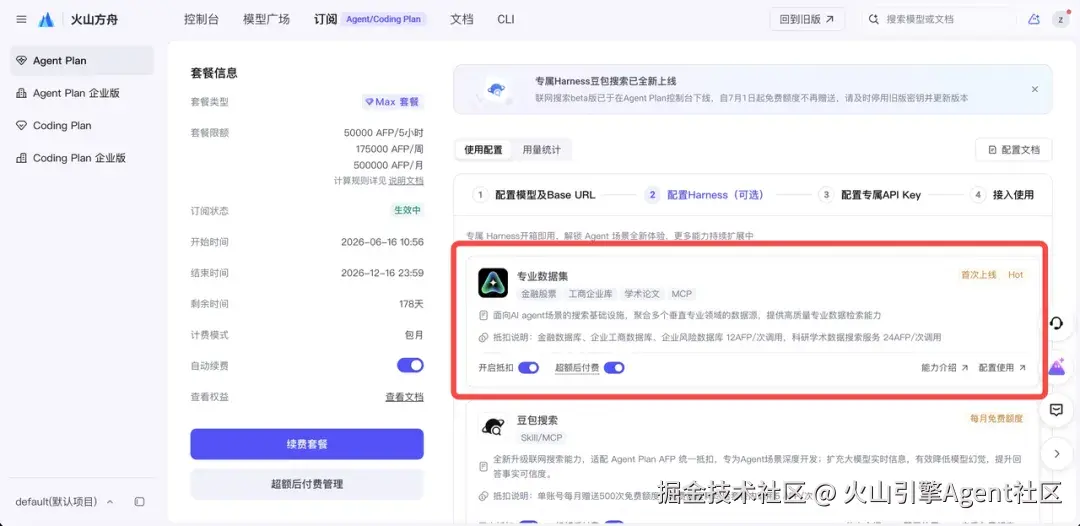
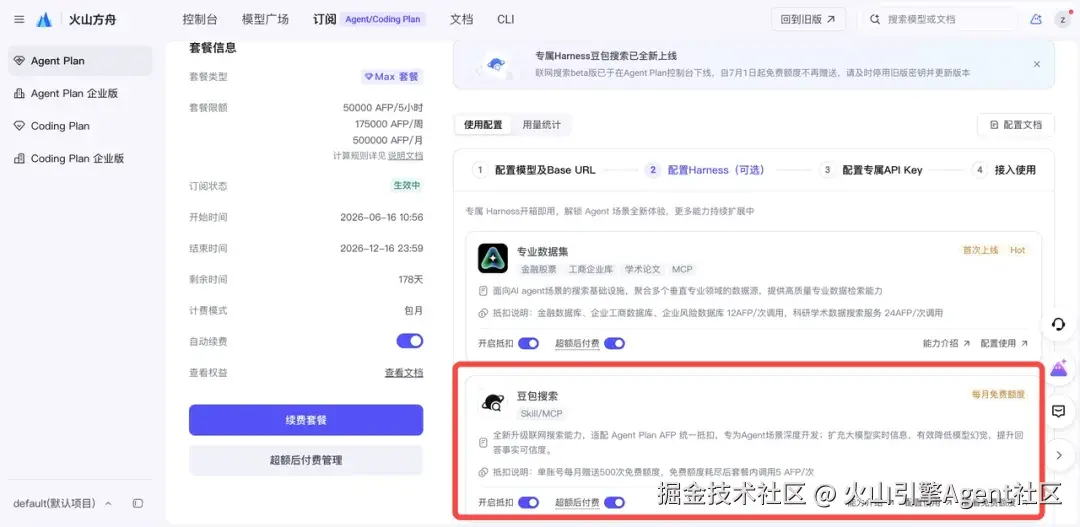
配置项:配置豆包搜索 Skil、MCP
说明: 可在控制台「配置 Harness」处领取豆包搜索权益,订阅套餐即可每月赠送一定免费额度。具体参照豆包搜索配置文档
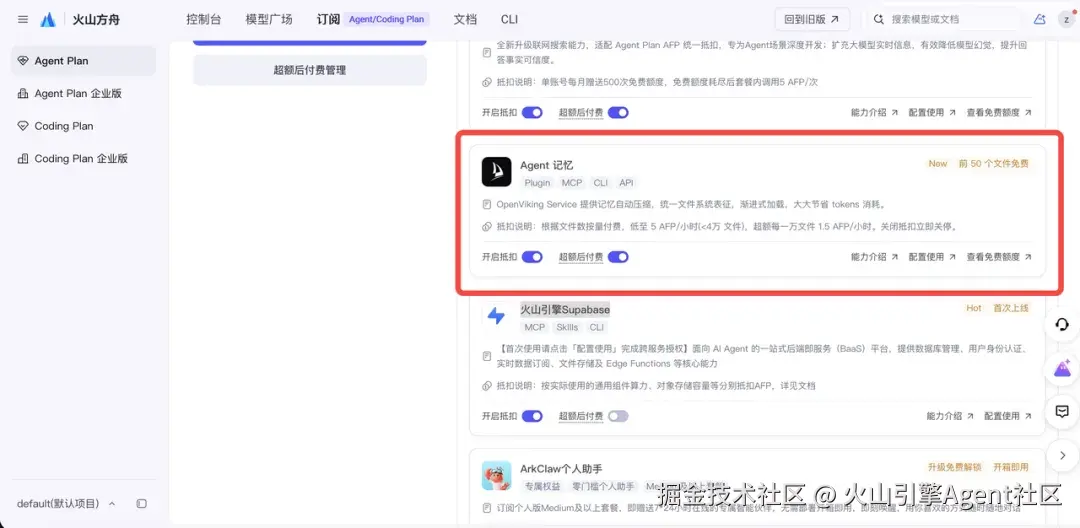
配置项:配置 Agent 记忆
说明: 可在控制台「配置 Harness」处开启抵扣。Agent 接入 OpenViking 时,必须使用 OpenViking 的 API Key 作为唯一认证,并关联到对应的数据。OpenViking API Key 可在 OpenViking Service 控制台 (console.volcengine.com/vikingdb/op...) 的用户管理页面查看与复制。具体参照 Agent 记忆配置文档
配置项:配置火山引擎 Supabase
说明: 可在控制台「配置 Harness」处开启抵扣。在 AI 原生 BaaS 平台 Supabase 版 (console.volcengine.com/aidap) 的 Workspace 详情页,可查看 Supabase URL、API Key 及数据库连接串。具体参照火山引擎 Supabase 配置文档
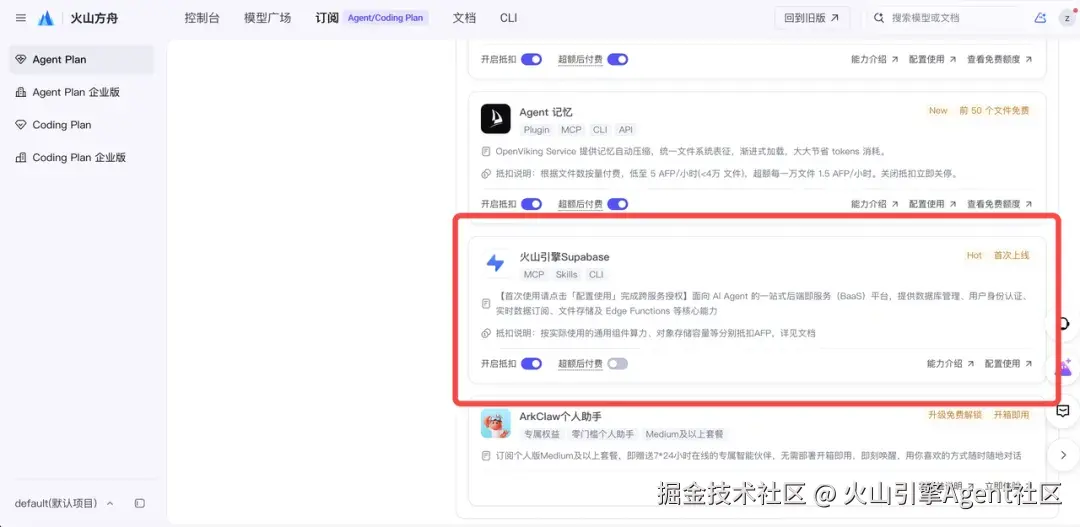
配置项:配置 Codex CLI + Feishu CLI
说明: 飞书 CLI 配置具体参照飞书 CLI 能力介绍与最佳实践
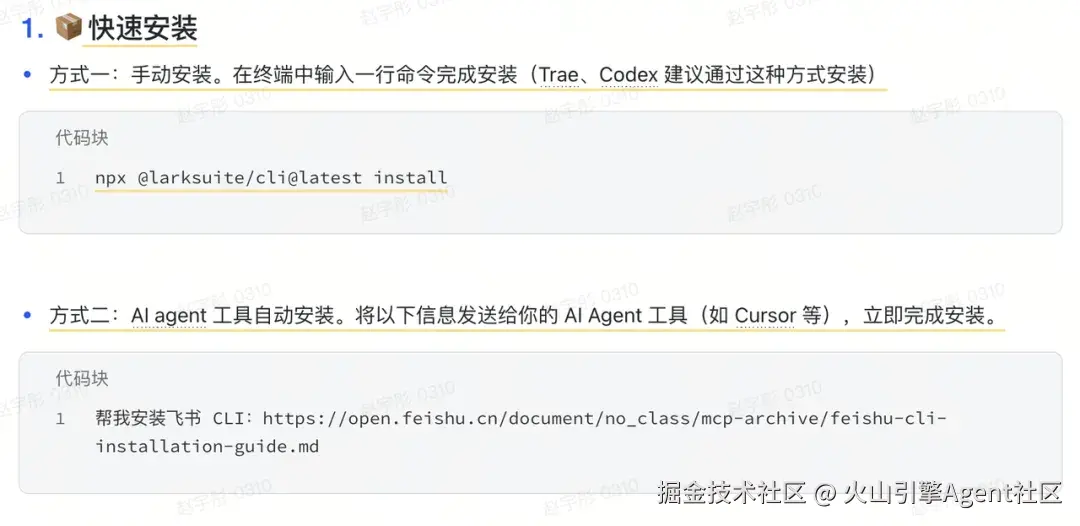
Step3 配置检查清单
正式开发前,建议先完成一次最小可用性检查。
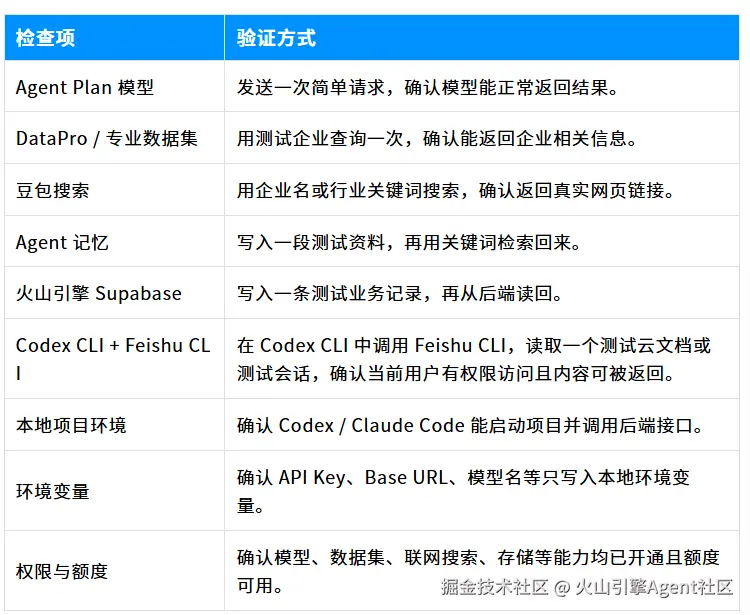
补充说明:如果任一配置未通过检查,建议先修复配置或权限问题,再进入正式开发。
Step4 接入 Codex 使用
完成配置和检查后,可在主流编程及 Agent 工具中接入 Agent Plan,使用语言模型、DataPro MCP、豆包搜索 、 Agent 记忆 和火山引擎 Supabase 完成平台开发。截图演示以 Codex 为例,接入方舟 Agent Plan 服务进行使用。
三、详细操作指南
1. 从销售资料整理到工作台开发流程
🍄 本节说明用户如何通过 Codex 开发销售场景工作台,并将开发过程沉淀为可复用 Skill。
Step1 用户表达销售资料整理和销售工作台需求
用户可以先说明自己的真实痛点和边界:
我想开发一个销售场景工作台。现在销售资料分散在飞书会话、会议纪要、云文档和客户资料里,希望用 Codex 帮我整理这些资料,并开发一个工作台,用于创建销售目标、查找公司、查看公司进度、生成最近档案和进行资料问答。
当前版本只做销售目标、关键词找公司、目标企业池、公司详情、最近档案、历史资料库和资料问答。Step2 通过 Codex CLI + Feishu CLI 导入飞书资料并写入 OpenViking
用户先在本机完成 Feishu CLI 登录与权限配置。随后在本地终端启动 Codex CLI,由 Codex CLI 调用 Feishu CLI,读取当前用户有权限访问的飞书云文档、会议纪要和会话资料。读取范围以 Feishu CLI 登录用户的飞书权限为准,读取到的资料由 Codex 整理后写入 OpenViking,形成后续可检索、可召回的长期销售资料。

Step3 设计销售场景工作台方案
在历史资料进入 OpenViking 后,让 Codex 设计销售场景工作台页面和后端接口。

后端应提供固定接口,负责连接 专业数据集 + 豆包搜索 + Agent 记忆 + 火山引擎 Supabase 和语言模型。
Step4 开发真实前后端
对 Codex 生成的方案进行约束和优化,用户可以这样告诉 Codex:
markdown
请开发真实可运行的前后端,不要只生成静态 Mock 页面。
前端只展示销售用户能理解的信息。
后端需要按固定业务流程接入各项能力:
1. 销售目标、公司列表、目标企业池、当前进度、最近档案、引用来源、问答记录等结构化业务数据,保存到 火山引擎Supabase。
2. 历史资料库需要读取前面已经导入 OpenViking 的飞书会话、会议纪要、云文档和客户资料。
3. 最近档案生成时,先调用 专业数据集,再调用豆包搜索补充公开信息,再从 OpenViking 召回历史销售资料,最后由模型整理成档案,并把档案和引用来源保存到 Supabase。
4. 资料问答时,只能基于 OpenViking 中的历史资料、当前公司最近档案和已保存引用来源回答,不在问答阶段自由联网。
5. Harness 失败时,页面不能崩溃,需要用业务语言提示或返回保守结果。2. 生成工作台能力介绍
🍄 本节说明销售场景工作台生成后,用户如何在页面中完成销售目标管理、公司跟进、最近档案查看、历史资料检索和资料问答。
创建销售目标并查找公司
可以点击「新增销售目标」创建新的销售目标。销售目标用于组织一批需要持续跟进的公司。
用户在「查找企业」输入框中输入关键词,例如行业、区域或公司名称。系统根据关键词返回相关公司。用户可以从搜索结果中选择合适的公司,并加入当前销售目标下的目标企业池。
查看客户进展
公司详情页中的「当前进度」用于展示该公司的当前跟进状态,进度由已有资料综合判断。

获取最近档案
用户点击右上角「获取最新档案」后,系统会更新当前公司的「最近档案」。最近档案用于帮助用户快速了解该公司的最新情况和销售推进判断。并展示数据来源。
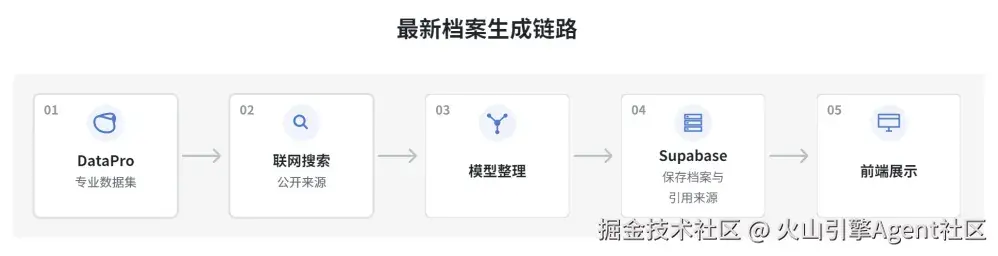
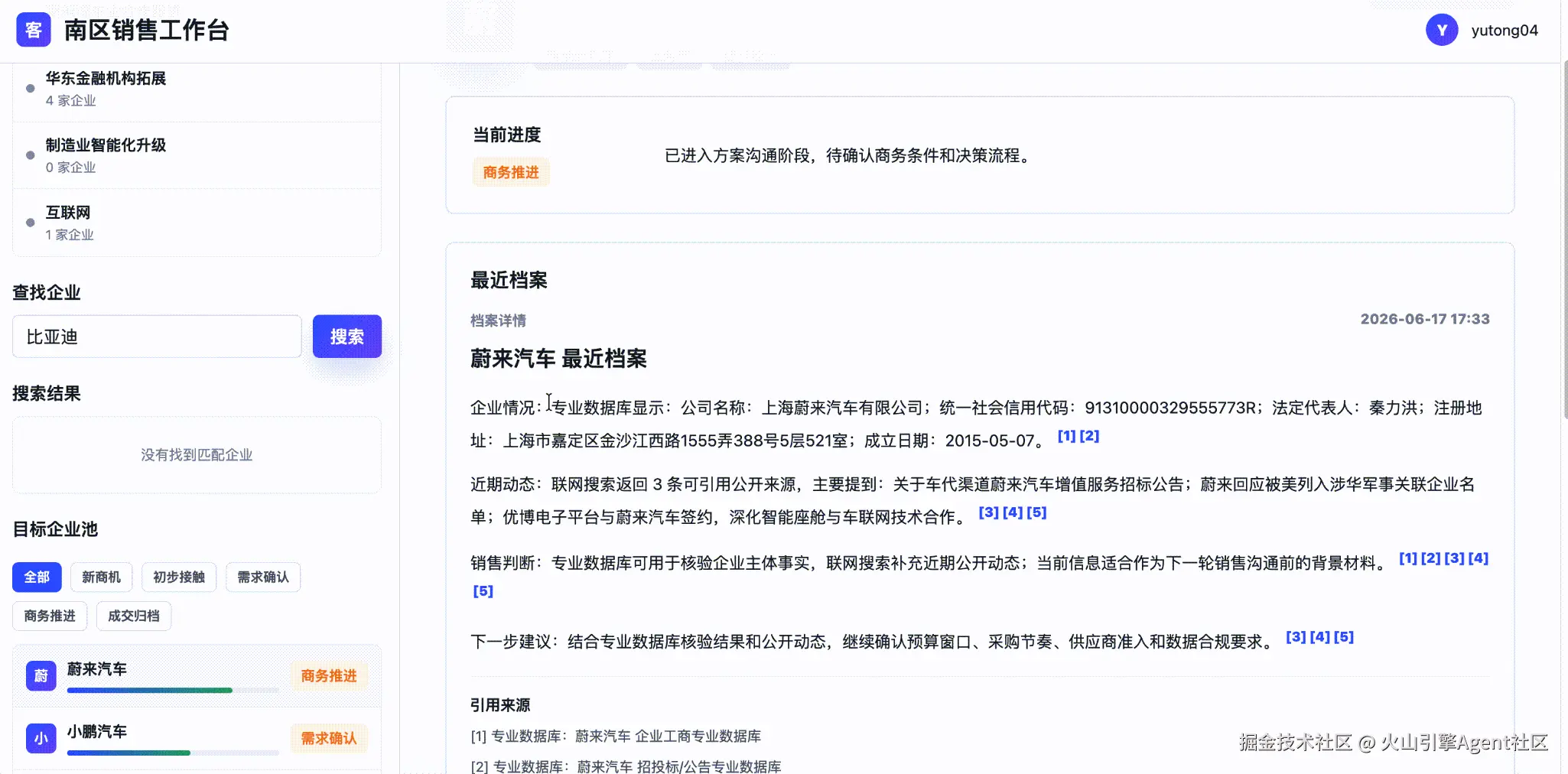
查看历史资料库
历史资料来自前面已经导入 OpenViking 的销售资料,例如:飞书会话;云文档;会议纪要;客户需求文档;内部方案材料。
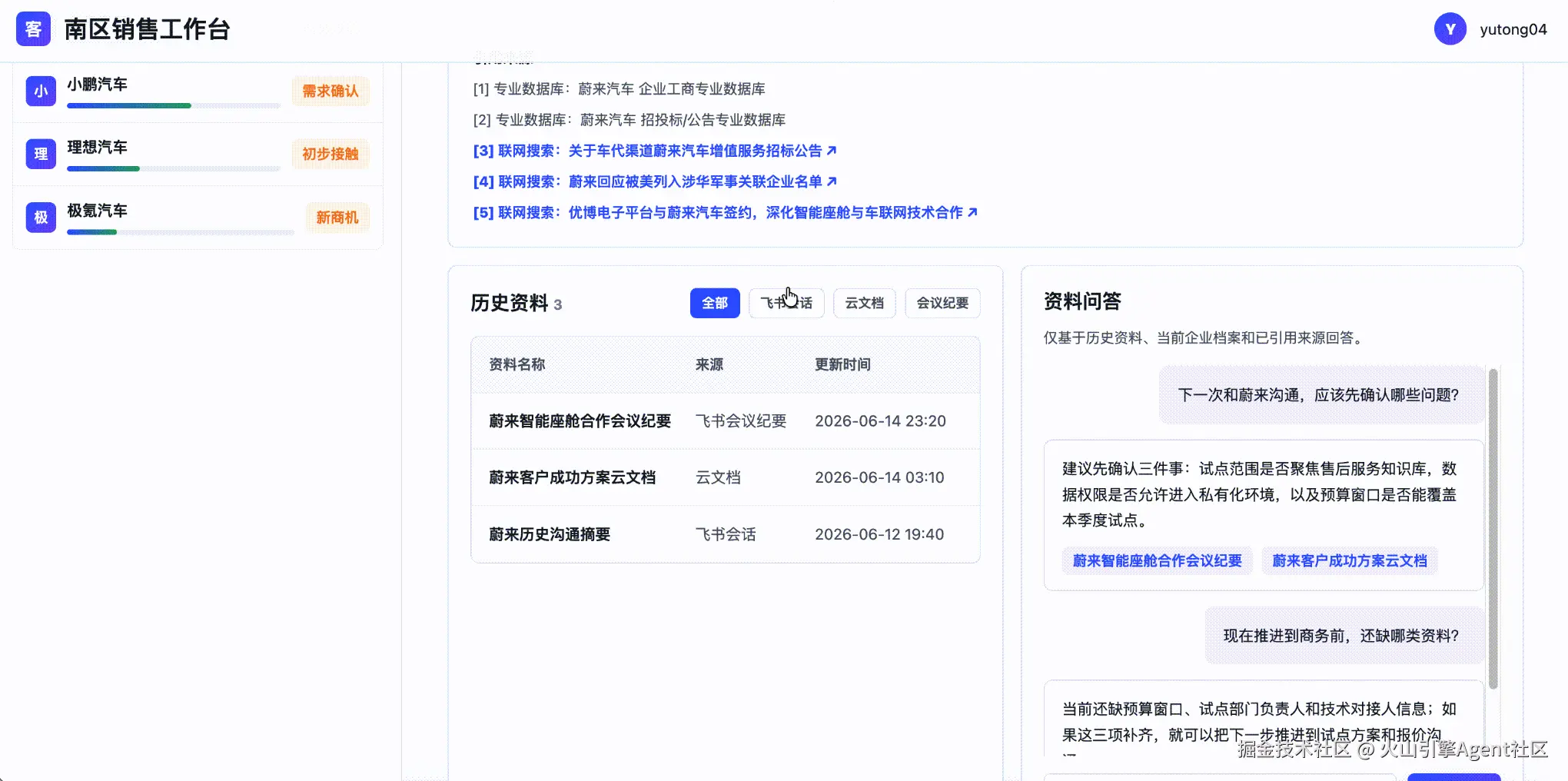
使用资料问答
用户可以在「资料问答」模块中,围绕当前公司提问。资料问答只基于以下内容回答:
- OpenViking 中已经导入的历史资料;
- 当前公司最近档案;
- 已保存的引用来源。
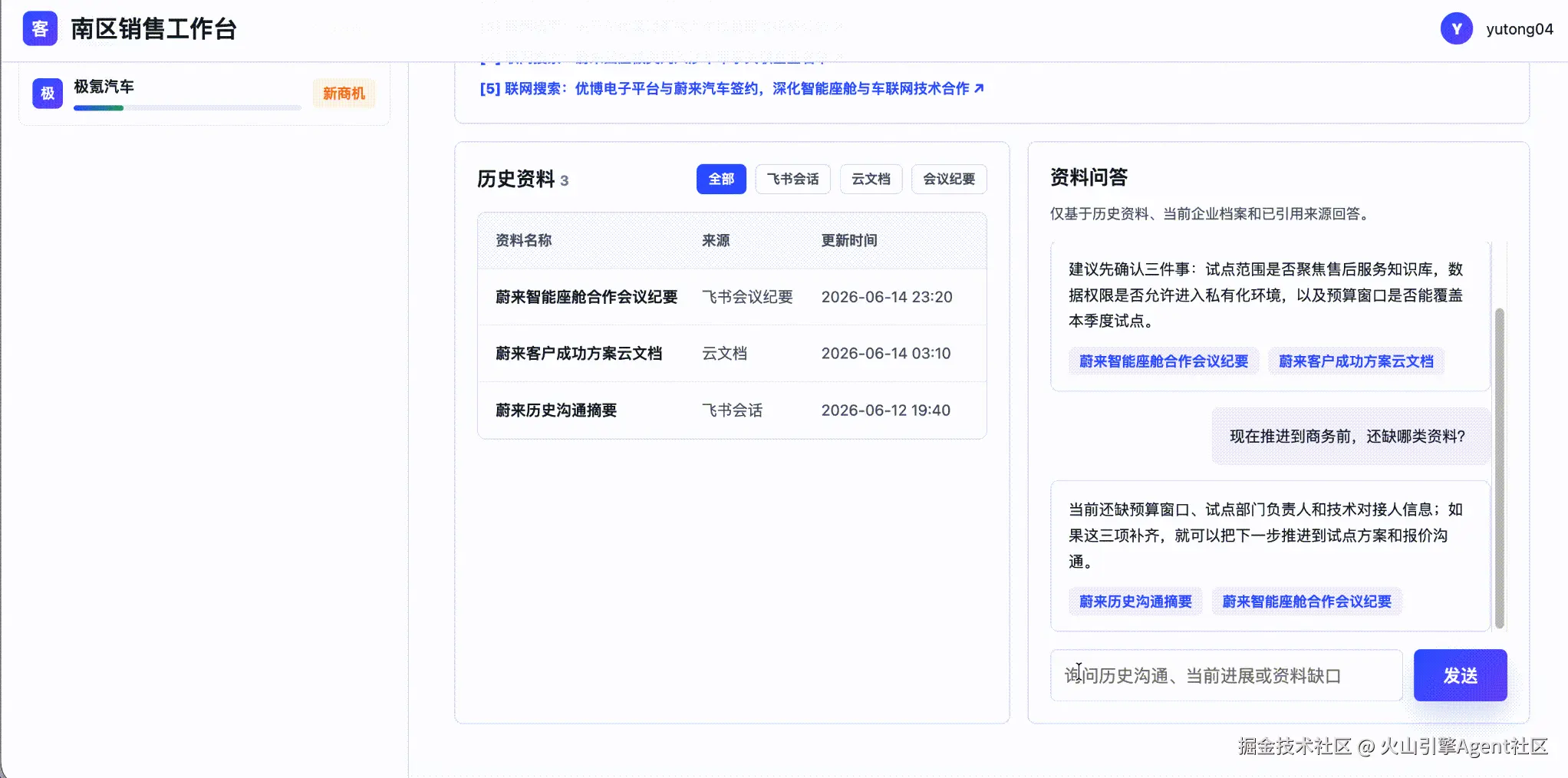
持续迭代和补充资料
用户后续可以继续补充新的会议纪要、飞书会话、云文档或客户资料。
补充资料后,系统可以将这些资料继续写入 OpenViking,并在工作台中更新历史资料库。后续查看进度、生成最近档案或进行资料问答时,都可以基于新的历史资料进行回答。
工作台不是一次性页面,而是一个可以持续沉淀销售资料、更新公司档案和辅助跟进判断的销售资料工作区。
开发完成并通过业务链路验证后,建议将本次工作沉淀为可复用 Skill 。后续用户说"继续优化销售场景工作台"时,Codex 可以基于 Skill 继续迭代,而不是重新生成一个全新项目。
3. 查询 AFP 用量消耗
用户可通过方舟控制台查询 Agent Plan 套餐 AFP 的实时用量,积分详情可见 AFP 积分机制
(www.volcengine.com/docs/82379/...%25E3%2580%2582%25E6%259C%25AC%25E6%25A1%2588%25E4%25BE%258B%25E5%258F%25AF%25E8%2583%25BD%25E4%25BA%25A7%25E7%2594%259F "https://www.volcengine.com/docs/82379/2366394?lang=zh[#c90d28c2]())%E3%80%82%E6%9C%AC%E6%A1%88%E4%BE%8B%E5%8F%AF%E8%83%BD%E4%BA%A7%E7%94%9F") AFP 或相关资源消耗,主要来自:
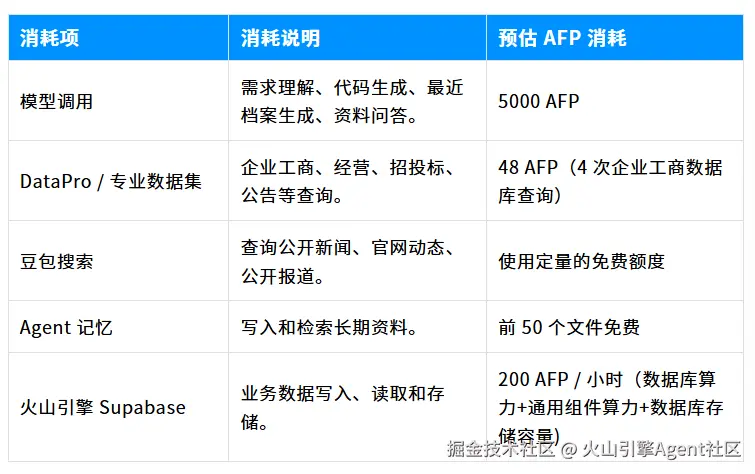
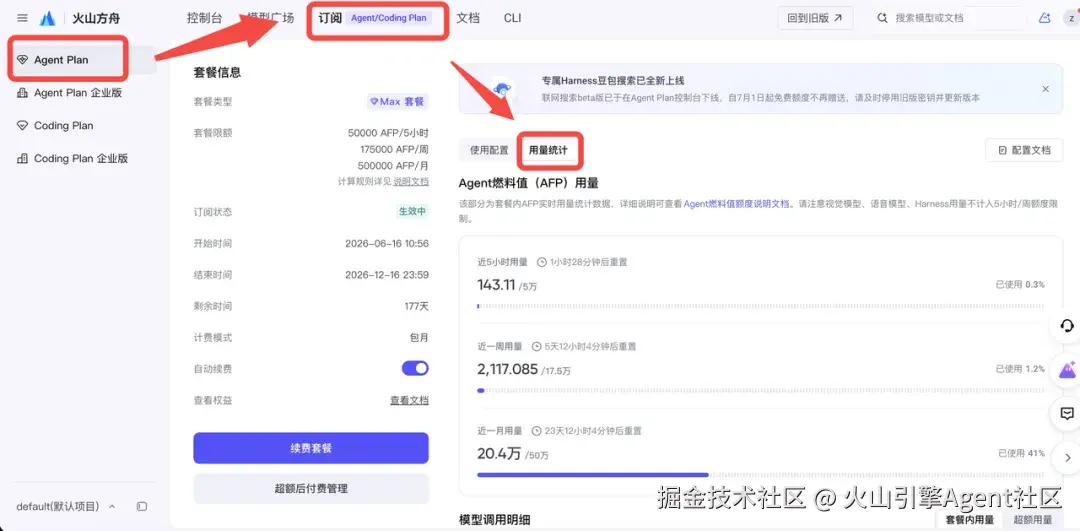
说明:
- 实际消耗以控制台展示为准
- 开发调试阶段的消耗通常高于稳定运行阶段
- 不同用户的模型选择、查询次数、资料规模和页面复杂度不同,最终消耗会不同
欢迎订阅火山方舟 Agent Plan,多模型随心用,养虾更划算。