线上接口超时,是 Spring Boot 项目里非常常见的问题。很多人第一反应是把超时时间调大,但这往往只是把问题藏起来。真正要解决接口超时,不能只盯着某一个接口的代码,而要把请求从进入应用到访问下游服务的完整链路看清楚。
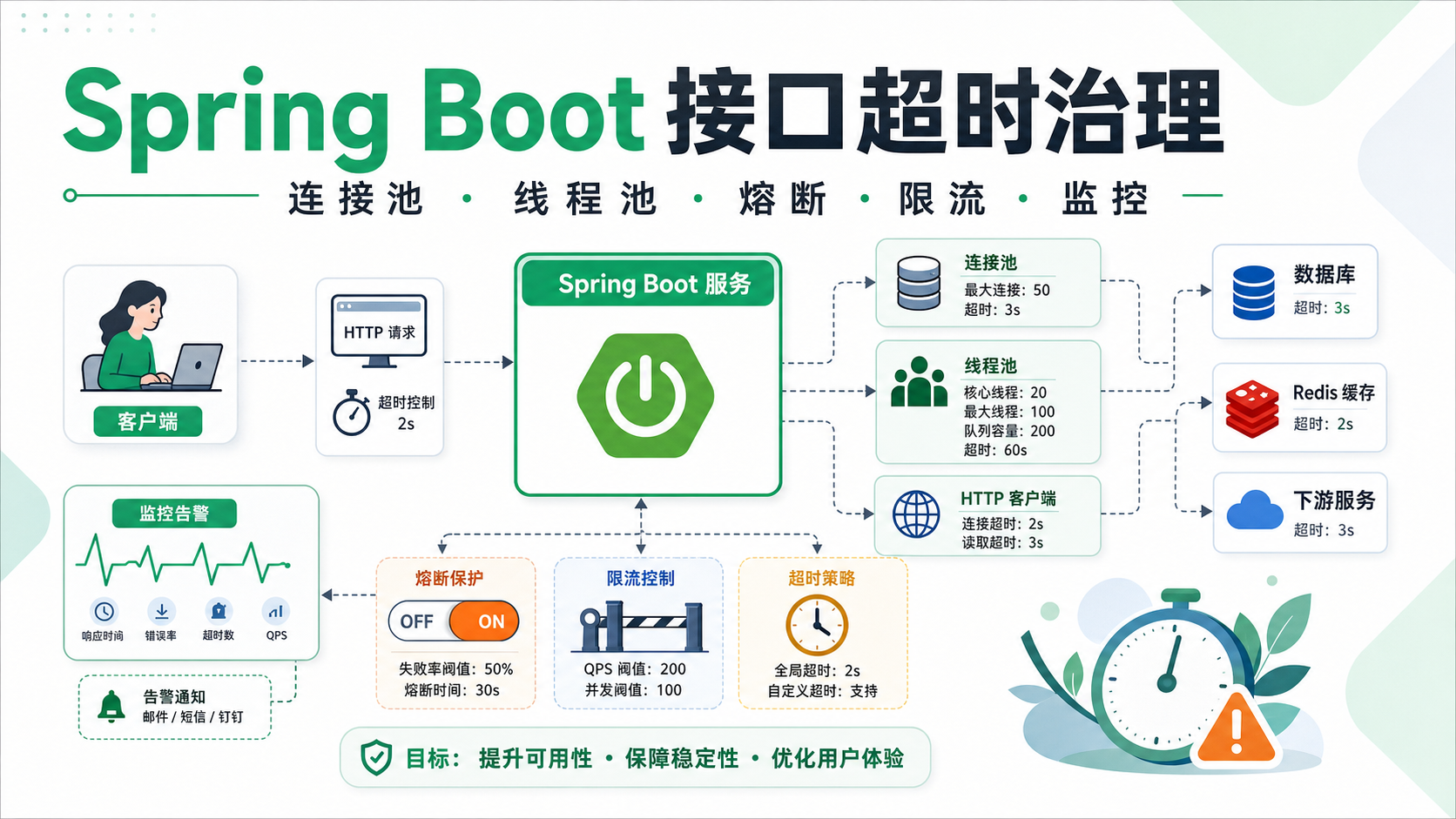
一个接口请求通常会经过这些环节:客户端请求进入 Web 容器,业务代码在线程池中执行,期间可能访问数据库、Redis、HTTP 下游服务、消息队列或文件系统。任何一个环节变慢,都可能表现为接口超时。
第一步,先区分是哪一种超时。
常见的超时包括连接超时、读取超时、线程等待超时、数据库查询超时、网关超时和客户端超时。
连接超时通常说明连接还没建立成功,可能是网络不通、服务不可达、连接池耗尽或目标服务压力过大。读取超时说明连接建立了,但对方迟迟没有返回数据。线程等待超时可能是应用内部线程池被打满,任务排队太久。数据库超时则可能是慢 SQL、锁等待、连接池不足或索引设计不合理。
如果不区分这些类型,只是笼统地说"接口超时",排查会非常低效。
第二步,检查 Web 容器线程池。
Spring Boot 默认常用 Tomcat 作为内嵌容器。请求进入应用后,会由 Tomcat 工作线程处理。如果这些线程被长时间占用,新请求就只能等待,最终表现为接口响应慢甚至超时。
需要关注几个指标:当前线程数、活跃线程数、最大线程数、请求排队数、接口响应耗时。如果活跃线程数长期接近最大值,说明应用入口层已经拥堵。
这时不要马上把最大线程数调得很大。线程数增加会带来更多上下文切换,也会把更大的压力传递给数据库和下游服务。正确做法是先找出线程为什么被占用:是业务代码慢,还是下游调用慢,还是锁竞争严重。
第三步,检查数据库连接池。
很多接口超时最终都和数据库有关。常见情况是接口本身逻辑不复杂,但等待数据库连接花了很久。
如果使用 HikariCP,需要重点关注活跃连接数、空闲连接数、等待连接数、连接获取耗时和连接超时次数。当连接池被打满时,请求线程会阻塞等待连接,进而拖慢整个接口。
连接池不是越大越好。连接数过大可能把数据库打满,导致所有 SQL 都变慢。更合理的做法是结合数据库承载能力、应用实例数量和接口并发量设置连接池大小。
如果连接池经常耗尽,应该继续排查慢 SQL、事务过长、连接未释放、批量任务抢占连接等问题。
第四步,外部 HTTP 调用必须设置超时。
很多接口不稳定,是因为调用下游服务时没有设置合理的 connectTimeout 和 readTimeout。一旦下游变慢,请求线程会长时间等待,最后把自己应用的线程池也拖死。
生产环境中,所有 HTTP 客户端都应该显式设置连接超时、读取超时、连接池大小、最大空闲连接数和重试策略。
重试也要谨慎。一次请求如果重试三次,每次都等待几秒,在下游故障时会迅速放大流量压力。对于核心链路,建议配合熔断和限流,避免故障扩散。
第五步,使用熔断保护下游和自身。
熔断的意义不是让系统不报错,而是在下游明显不可用时快速失败,避免大量请求继续堆积。
比如某个第三方接口失败率持续升高,应用可以短时间打开熔断,直接返回降级结果。等一段时间后再半开探测,如果下游恢复,再逐步放开请求。
熔断适合保护不稳定的外部依赖,尤其是支付、通知、推荐、风控、第三方数据接口等链路。
第六步,限流要放在入口和关键资源前。
限流的本质是承认系统容量有限。与其让所有请求一起挤进来导致整体雪崩,不如在入口处控制流量,把系统稳定性保住。
限流可以按接口、用户、IP、租户、业务类型等维度做。对于高成本接口,比如导出、复杂查询、批量计算,最好单独设置限流规则,避免它们影响普通接口。
第七步,监控要覆盖完整链路。
接口超时治理离不开监控。至少要有接口耗时分布、错误率、QPS、Tomcat 线程池、业务线程池、数据库连接池、Redis 连接池、HTTP 客户端耗时、下游服务耗时、慢 SQL 和 GC 指标。
其中耗时分布比平均耗时更重要。平均耗时看起来正常,不代表 P95、P99 没问题。用户真正感受到的,往往是尾部延迟。
总结一下,Spring Boot 接口超时不是单点问题,而是链路问题。排查时要先定位超时类型,再看入口线程池、业务线程池、连接池、下游调用和数据库。治理上要配置合理超时、控制重试、增加熔断、做好限流,并建立完整监控。只有这样,接口才能在高峰和异常场景下保持可控。