数据准备
python
import torch
# 固定随机种子,使得运行结果可以稳定复现
torch.manual_seed(1024)
# 产生训练用的数据
x_origin = torch.linspace(100, 300, 200)
# 将变量X归一化,否则梯度下降法很容易不稳定
x = (x_origin - torch.mean(x_origin)) / torch.std(x_origin)
epsilon = torch.randn(x.shape)
y = 10 * x + 5 + epsilontorch.linspace
使用 torch.linspace 函数时,需要指定三个主要参数:起始值(start)、结束值(end)和步数(steps)。步数决定了张量中将包含多少个元素。例如,创建一个从3到10的张量,包含5个元素,可以使用以下代码:
python
import torch
# 创建一个从3到10,包含5个元素的张量
tensor = torch.linspace(3, 10, steps=5)
print(tensor)
输出将是:
tensor([ 3.0000, 4.7500, 6.5000, 8.2500, 10.0000])参数解释
start:张量的起始值。
end:张量的结束值。
steps:张量中元素的数量。
dtype:可选参数,用于指定返回张量的数据类型。
device:可选参数,用于指定张量所在的设备(如CPU或GPU)。
requires_grad:可选参数,指定是否需要计算梯度。
torch.std
在PyTorch中,标准差是通过 torch.std 函数计算的,它可以计算张量(tensor)的标准差。标准差是衡量数据集中数值分散程度的统计量,它是方差的平方根。在PyTorch中,标准差的计算考虑了贝塞尔校正(Bessel's correction),这意味着在计算样本标准差时,默认会使用 n-1 而不是 n 作为分母。
python
import torch
# 创建一个张量
a = torch.tensor([[0.2035, 1.2959, 1.8101, -0.4644],
[1.5027, -0.3270, 0.5905, 0.6538],
[-1.5745, 1.3330, -0.5596, -0.6548],
[0.1264, -0.5080, 1.6420, 0.1992]])
# 计算每行的标准差,并保持维度
std_a = torch.std(a, dim=1, keepdim=True)
print(std_a)输出将是每行元素标准差的张量。
参数解释
input:输入张量。
dim:要减少的维度,可以是单个维度、维度列表或 None。
correction:样本大小与样本自由度之间的差异,默认为贝塞尔校正,即 correction=1。
keepdim:输出张量是否保留 dim 维度。
out:输出张量。
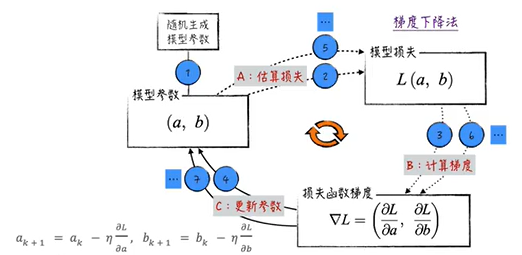
模型定义
python
# 为了使用PyTorch的高层封装函数,我们通过继承Module类来定义函数
class Linear(torch.nn.Module):
def __init__(self):
"""
定义线性回归模型的参数:a, b
"""
super().__init__()
self.a = torch.nn.Parameter(torch.zeros(()))
self.b = torch.nn.Parameter(torch.zeros(()))
def forward(self, x):
"""
根据当前的参数估计值,得到模型的预测结果
参数
----
x :torch.tensor,变量x
返回
----
y_pred :torch.tensor,模型预测值
"""
return self.a * x + self.b
def string(self):
"""
输出当前模型的结果
"""
return f'y = {self.a.item():.2f} * x + {self.b.item():.2f}'forward
我们在定义自已的网络的时候,需要继承nn.Module类,并重新实现构造函数__init__和forward这两个方法。但有一些注意技巧:
(1)一般把网络中具有可学习参数的层(如全连接层、卷积层等)放在构造函数__init__()中,当然我也可以吧不具有参数的层也放在里面;
(2)一般把不具有可学习参数的层(如ReLU、dropout、BatchNormanation层)可放在构造函数中,也可不放在构造函数中,如果不放在构造函数__init__里面,则在forward方法里面可以使用nn.functional来代替
(3)forward方法是必须要重写的,它是实现模型的功能,实现各个层之间的连接关系的核心。
super().init()
super().init() 是 Python 中用于调用父类初始化方法的语法,常用于继承场景,确保子类能够正确初始化父类的属性和方法。
python
class Parent:
def __init__(self):
print("Parent initialized")
class Child(Parent):
def __init__(self):
super().__init__() # 调用父类的 __init__ 方法
print("Child initialized")
child = Child()输出:
Parent initialized
Child initialized
继承父类初始化逻辑:通过 super().init(),子类可以调用父类的 init 方法,避免重复代码。
多继承支持:在多继承中,super() 遵循方法解析顺序(MRO),确保所有父类的初始化方法都被正确调用。
Python中的f字符串
f字符串(formatted string literals)是Python 3.6引入的一种字符串格式化方法,它使得字符串格式化更加简便和高效。
基本用法
在f字符串中,可以在大括号 {} 内放入任何有效的Python表达式,这些表达式会在运行时被求值并替换为其结果。
python
name = "Alice"
print(f"Hello, {name}!") # 输出:Hello, Alice!表达式求值与函数调用
f字符串的大括号内可以填入表达式或调用函数,Python会求出其结果并填入返回的字符串内。
python
import math
print(f"The value of pi is approximately {math.pi:.2f}.") # 输出:The value of pi is approximately 3.14多行f字符串
f字符串还可以用于多行字符串。
python
name = "Eric"
age = 27
msg = (
f"Hello!\n"
f"I'm {name}.\n"
f"I'm {age}."
)
print(msg)
# 输出:
# Hello!
# I'm Eric
# I'm 27自定义格式
可以使用格式说明符对数字进行格式化,例如对齐、宽度、符号、补零、精度等。
python
number = 1234.5678
print(f"{number:,.2f}") # 输出:1,234.57创建实例、参数设置与使用第三方库训练
python
# 定义模型
model = Linear()
# 确定最优化算法
learning_rate = 0.1
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
for t in range(20):
# 根据当前的参数估计值,得到模型的预测结果
# 也就是调用forward函数
y_pred = model(x)
# 计算损失函数
loss = (y - y_pred).pow(2).mean()
# 将上一次的梯度清零
optimizer.zero_grad()
# 计算损失函数的梯度
loss.backward()
# 迭代更新模型参数的估计值
optimizer.step()
print(f'Step {t + 1}, Loss: {loss: .2f}; Result: {model.string()}')SGD
torch.optim.SGD 是PyTorch中用于实现随机梯度下降(Stochastic Gradient Descent,SGD)的类,它是深度学习中常用的优化算法之一。SGD通过迭代更新模型参数来最小化目标函数,通常用于训练神经网络。
在PyTorch中,要使用SGD优化器,首先需要创建一个SGD对象,并将模型的参数传递给它。然后,在训练循环中,执行前向传播、计算损失、执行反向传播并调用优化器的step()方法来更新参数。例如:
python
import torch
import torch.optim as optim
# 定义模型和损失函数
model = torch.nn.Linear(10, 1)
criterion = torch.nn.MSELoss()
# 定义优化器
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.9, weight_decay=0.0001)
# 在训练循环中使用优化器
for epoch in range(epochs):
# 前向传播
output = model(input_data)
loss = criterion(output, target)
# 反向传播和优化
optimizer.zero_grad()
loss.backward()
optimizer.step()SGD的参数解释
params(必须参数):需要优化的参数(张量)的迭代器,例如模型的参数model.parameters()。
lr(必须参数):学习率,控制每次参数更新的步长。
momentum(默认值为0):动量,用于加速SGD收敛,引入了上一步梯度的指数加权平均。
dampening(默认值为0):阻尼项,用于减缓动量的速度。
weight_decay(默认值为0):权重衰减,也称为L2正则化项,用于防止过拟合。
nesterov(默认值为False):Nesterov动量,采用Nesterov动量更新规则。
自定义训练
python
# 利用代码实现PyTorch封装的梯度下降法
model = Linear()
for t in range(20):
# 根据当前的参数估计值,得到模型的预测结果
# 也就是调用forward函数
y_pred = model(x)
# 计算损失函数
loss = (y - y_pred).pow(2).mean()
# 计算损失函数的梯度
loss.backward()
with torch.no_grad():
for param in model.parameters():
# 迭代更新模型参数的估计值,等同于optimizer.step()
param -= learning_rate * param.grad
# 将梯度清零,等同于optimizer.zero_grad()
param.grad = None
print(f'Step {t + 1}, Loss: {loss: .2f}; Result: {model.string()}')loss是需要减小的,所以是减去梯度。
torch.no_grad()
在 PyTorch 中,with torch.no_grad 是一个上下文管理器,用于在特定代码块中禁用自动求导功能。这在模型评估或推断时非常有用,因为在这些情况下不需要计算梯度,从而可以提高代码执行效率。以下是一个简单的示例,展示了如何使用 with torch.no_grad:
python
import torch
# 创建一些张量并设置 requires_grad=True
x = torch.randn(10, 5, requires_grad=True)
y = torch.randn(10, 5, requires_grad=True)
z = torch.randn(10, 5, requires_grad=True)
# 在 with torch.no_grad 语句块中进行计算
with torch.no_grad():
w = x + y + z
print(w.requires_grad) # 输出: False
print(w.grad_fn) # 输出: None
print(w.requires_grad) # 输出: False在上述代码中,即使 x、y 和 z 的 requires_grad 属性为 True,在 with torch.no_grad 语句块中计算得到的新张量 w 的 requires_grad 属性也会被自动设置为 False,且 grad_fn 为 None。
代码跟踪与尝试
复现:
python
import torch
torch.manual_seed(1024)
x_ori=torch.linspace(100,300,200)
x=(x_ori-torch.mean(x_ori))/torch.std(x_ori)
e=torch.randn(x.shape)
y=10*x+5+e
class Linear(torch.nn.Module):
def __init__(self):
super().__init__()
self.a=torch.nn.Parameter(torch.zeros(()))
self.b=torch.nn.Parameter(torch.zeros(()))
def forward(self,x):
return self.a*x+self.b
def string(self):
return f'y={self.a.item():.2f}*x+{self.b.item():.2f}'
model=Linear()
lr=0.1
optimizer=torch.optim.SGD(model.parameters(),lr=lr)
for i in range(20):
y_p=model(x)
loss=(y-y_p).pow(2).mean()
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(f'Step {i + 1}, Loss: {loss: .2f}; Result: {model.string()}')
model=Linear()
for i in range(20):
y_p=model(x)
loss=(y-y_p).pow(2).mean()
loss.backward()
with torch.no_grad():
for param in model.parameters():
param-=lr*param.grad
param.grad=None
print(f'Step {i + 1}, Loss: {loss: .2f}; Result: {model.string()}')结果:
python
Step 1, Loss: 125.25; Result: y=1.98*x+1.02
Step 2, Loss: 80.72; Result: y=3.56*x+1.83
Step 3, Loss: 52.16; Result: y=4.83*x+2.49
Step 4, Loss: 33.84; Result: y=5.85*x+3.01
Step 5, Loss: 22.10; Result: y=6.66*x+3.42
Step 6, Loss: 14.57; Result: y=7.31*x+3.76
Step 7, Loss: 9.74; Result: y=7.83*x+4.03
Step 8, Loss: 6.64; Result: y=8.25*x+4.24
Step 9, Loss: 4.66; Result: y=8.59*x+4.41
Step 10, Loss: 3.38; Result: y=8.85*x+4.55
Step 11, Loss: 2.56; Result: y=9.07*x+4.66
Step 12, Loss: 2.04; Result: y=9.24*x+4.74
Step 13, Loss: 1.71; Result: y=9.38*x+4.81
Step 14, Loss: 1.49; Result: y=9.49*x+4.87
Step 15, Loss: 1.35; Result: y=9.58*x+4.91
Step 16, Loss: 1.26; Result: y=9.65*x+4.95
Step 17, Loss: 1.21; Result: y=9.71*x+4.98
Step 18, Loss: 1.17; Result: y=9.75*x+5.00
Step 19, Loss: 1.15; Result: y=9.79*x+5.02
Step 20, Loss: 1.13; Result: y=9.82*x+5.03
Step 1, Loss: 125.25; Result: y=1.98*x+1.02
Step 2, Loss: 80.72; Result: y=3.56*x+1.83
Step 3, Loss: 52.16; Result: y=4.83*x+2.49
Step 4, Loss: 33.84; Result: y=5.85*x+3.01
Step 5, Loss: 22.10; Result: y=6.66*x+3.42
Step 6, Loss: 14.57; Result: y=7.31*x+3.76
Step 7, Loss: 9.74; Result: y=7.83*x+4.03
Step 8, Loss: 6.64; Result: y=8.25*x+4.24
Step 9, Loss: 4.66; Result: y=8.59*x+4.41
Step 10, Loss: 3.38; Result: y=8.85*x+4.55
Step 11, Loss: 2.56; Result: y=9.07*x+4.66
Step 12, Loss: 2.04; Result: y=9.24*x+4.74
Step 13, Loss: 1.71; Result: y=9.38*x+4.81
Step 14, Loss: 1.49; Result: y=9.49*x+4.87
Step 15, Loss: 1.35; Result: y=9.58*x+4.91
Step 16, Loss: 1.26; Result: y=9.65*x+4.95
Step 17, Loss: 1.21; Result: y=9.71*x+4.98
Step 18, Loss: 1.17; Result: y=9.75*x+5.00
Step 19, Loss: 1.15; Result: y=9.79*x+5.02
Step 20, Loss: 1.13; Result: y=9.82*x+5.03拓展:广播机制
广播机制(Broadcasting)是指在进行运算时,自动扩展较小的张量以匹配较大的张量的尺寸,而不需要复制数据。这种机制可以提高运算效率,节省内存。
广播机制允许两个形状不同的张量进行运算。其基本规则如下:
每个张量至少有一个维度。
从末尾维度开始遍历,两个张量的每个对应维度需要满足以下条件之一: 维度相等。 其中一个维度为1。 其中一个维度不存在^3^。
如果两个张量是"可广播的",则计算过程遵循以下规则:
在较小张量前面增加维度,使其维度与较大张量相等。
计算结果的维度值取两个张量中较大的那个值。
扩展维度的过程是将数值进行复制。
以下是一些使用广播机制的示例代码:
import torch
# 示例1:两个张量的维度相同
a = torch.rand(4, 32, 14, 14)
b = torch.rand(4, 32, 14, 14)
print((a + b).shape) # 输出:torch.Size([4, 32, 14, 14])
# 示例2:一个张量的某些维度为1
a = torch.rand(4, 32, 14, 14)
b = torch.rand(1, 32, 1, 1)
print((a + b).shape) # 输出:torch.Size([4, 32, 14, 14])
# 示例3:一个张量的维度较小
a = torch.rand(4, 32, 14, 14)
c = torch.rand(32, 1, 1)
print((a + c).shape) # 输出:torch.Size([4, 32, 14, 14])注意事项
在使用广播机制时,需要注意以下几点:
确保张量的维度符合广播规则,否则会引发错误。
避免在原地操作中使用广播,因为原地操作不允许改变张量的形状。