前言
- 最近在总结传统方面的内容,准备收拾收拾尾部内容过渡到强化学习,刚好有一个项目需要用到卡尔曼滤波,刚好就半总结半实现的方式实现本文。
- 本文将尽可能以通俗易懂的方式介绍现代控制理论基础,同时介绍并简单推导卡尔曼滤波的公式,同时使用
python代码实现一个简单的卡尔曼滤波。
0 概率论基础
0-1 均值(Mean)
- 均值(Mean)表示随机变量的"中心位置":μ=Ex\mu = Exμ=Ex
- 均值 = "你最相信的那个值"
- 举个例子:
- 你同一时间测得传感器数据为
[9.8,10.1,10.0,10.2] - 平均值为
10.0,也就是"最佳猜测值"
- 你同一时间测得传感器数据为
0-2 协方差
- 协方差 = "两个变量"共同变化的程度""
- 协方差的本质是:Cov(x,y)=E(x−μx)(y−μy)\mathrm{Cov}(x,y)=E(x-\\mu_x)(y-\\mu_y)Cov(x,y)=E(x−μx)(y−μy)
- 单变量情况下,协方差就是方差:P=E(x−μ)2P = E(x - \\mu)\^2P=E(x−μ)2
- 协方差 = "你有多不确定",也就是"估计的可靠程度"
0-3 条件概率
- 条件概率描述的是: 在"已知某个事件发生"的前提下,另一个事件发生的概率P(A∣B)=P(A∩B)P(B)P(A|B) = \frac{P(A \cap B)}{P(B)}P(A∣B)=P(B)P(A∩B)
- P(A∣B)P(A∣B)P(A∣B):在B发生的前提下,A发生的概率
0-4 联合概率(Joint Probability)
- 联合概率指的是: 两个事件 A 和 B 同时发生的概率 P(A∩B)P(A \cap B)P(A∩B)
- 也就是说:A发生,同时B也发生的概率
0-5 后验概率(Posterior)
- 后验概率表示:在看到观测 zzz 之后,对状态 xxx 的更新认知p(x∣z)p(x∣z)p(x∣z)
0-6 先验概率(Prior)
- 先验概率表示:在没有看到观测之前,对状态的初始相信p(x)p(x)p(x)
0-7 似然函数(Likelihood)
- 似然函数表示:如果真实状态是 x,那么观测 z 出现的概率p(z∣x)p(z∣x)p(z∣x)
0-8 观测边缘概率(marginal likelihood / evidence)
- 观测边缘概率表示:观测到 z 的总概率p(z)p(z)p(z),对于不同的x,出现z的概率
0-9 贝叶斯公式
- 由于联合概率可以写成以下两种形式p(x,z)=p(z∣x)p(x)=p(x∣z)p(z)p(x,z)=p(z∣x)p(x)=p(x∣z)p(z)p(x,z)=p(z∣x)p(x)=p(x∣z)p(z)
- 所以我们可以得到贝叶斯公式:p(x∣z)=p(z∣x)p(x)p(z)p(x|z) = \frac{p(z|x)p(x)}{p(z)}p(x∣z)=p(z)p(z∣x)p(x)
- 也就是说
- 如何通过观测数据 z 对先验分布 p(x) 进行修正,从而得到后验分布 p(x|z)
1 现代控制理论
1-1 介绍
- 现代控制理论是研究动态系统建模、分析与控制的一类系统方法论,其核心基于
状态空间描述,用于统一刻画系统的内部动态行为与外部输入输出关系。 - 与经典控制理论(如传递函数方法)主要依赖频域分析不同,现代控制理论从系统内部结构出发,引入
状态变量(state variables)作为描述系统动态的基本元素,从而能够更完整地表达多输入多输出(MIMO)系统及其复杂耦合行为。 - 说人话:现代控制理论不再只关注
输入输出关系,而是引入:
"状态(State)"作为系统内部最小信息集合
1-2 三大核心支柱
- 其中,现代控制理论的基础可以概括为三大支柱:
状态空间表示(State-space representation)系统可控性 / 可观性(Controllability / Observability)最优控制与状态估计(Optimal control & state estimation)
1-3 状态空间表示(State-space representation)
状态(State)是:描述系统"当前完整信息"的最小变量集合- 例如:
- 小车的状态空间可以简单概述为:x=位置,速度Tx=位置,速度^Tx=位置,速度T
- 飞机的状态空间可以简单概述为:x=位置,速度,姿态,角速度Tx=位置,速度,姿态,角速度^Tx=位置,速度,姿态,角速度T
- 例如:
状态空间(State Space):就是用向量形式描述系统:xk=x1x2⋯x_k = \begin{bmatrix} x_1 \\ x_2 \\ \cdots \end{bmatrix}xk= x1x2⋯状态转移(State Transition):状态从一个状态转换为另一个状态的过程,一般用状态方程进行描述。- 即"当前状态如何变成下一时刻状态"
状态方程(State Equation):描述系统如何从上一时刻演化到下一时刻:xk=f(xk−1,uk,wk)x_k = f(x_{k-1}, u_k, w_k)xk=f(xk−1,uk,wk)其中:- xkxkxk:当前状态
- xk−1x_{k-1}xk−1:上一时刻状态
- uku_kuk:控制输入
- wkw_kwk:过程噪声
- f(⋅)f(\cdot)f(⋅):系统函数
1-4 系统可控性 / 可观性(Controllability / Observability)
- 在状态空间描述中,仅仅"写出系统方程"是不够的,还需要进一步回答两个本质问题:
系统能不能被我控制?系统内部状态我能不能看见?
- 这就引出了现代控制理论中的两个核心性质:
可控性与可观性。
1-4-1 系统可控性(Controllability)
可控性:描述系统是否可以通过控制输入 uku_kuk,在有限时间内将系统从任意初始状态驱动到任意目标状态。- 对于线性离散系统:xk+1=Axk+Bukx_{k+1} = Ax_k + Bu_kxk+1=Axk+Buk若存在合适的控制输入 uku_kuk,使得系统状态可以到达任意目标状态,则称该系统是可控的。
- 说人话:
- 可控性决定系统"能不能被
控制"
- 可控性决定系统"能不能被
1-4-2 系统可观性(Observability)
可观性:描述系统内部状态 xkx_kxk 是否可以通过输出 yky_kyk 在有限时间内唯一确定。- 系统输出通常表示为:yk=Cxky_k = Cx_kyk=Cxk若通过一段时间的输出序列,可以唯一恢复状态 xkx_kxk,则系统是可观的。(也就是我能不能通过观察 一段时间的yky_kyk来反推出xkx_kxk)
- 说人话:
- 可观性决定系统"能不能被
估计"
- 可观性决定系统"能不能被
1-5 最优控制与状态估计(Optimal control & state estimation)
- 在完成系统建模(状态空间)以及系统性质分析(可控性、可观性)之后,现代控制理论进一步关注两个实际问题:
如何"最优地控制系统"?
如何在噪声环境中"准确地估计系统状态"?
- 这就引出了现代控制理论的两个核心应用方向:最优控制与状态估计。
1-5-1 最优控制(Optimal Control)
最优控制:- 在满足系统动态约束的前提下,通过优化某个性能指标函数,求得最优控制输入 uku_kuk。
- 我们假设系统满足
动态约束(dynamics constraint):也就是系统的状态不能随便变,它必须按"物理规律"演化。xk+1=Axk+Bukx_{k+1} = Ax_k + Bu_kxk+1=Axk+Buk - 定义性能指标(代价函数J):J=∑k=0N(xkTQxk+ukTRuk)J = \sum_{k=0}^{N} (x_k^T Q x_k + u_k^T R u_k)J=k=0∑N(xkTQxk+ukTRuk)其中:
- xkx_kxk:状态
- QQQ :"权重矩阵",xkTQxkx_k^T Q x_kxkTQxk 表示"偏离目标的代价"
- uku_kuk:控制输入
- R:"权重矩阵",ukTRuku_k^T R u_kukTRuk表示"控制动作的消耗"
- 举个例子你就懂了:
- 我们假设是xk=位置速度x_k = \begin{bmatrix} 位置 \\ 速度 \end{bmatrix}xk=位置速度,且Q=q100q2Q = \begin{bmatrix} q_1 & 0 \\ 0 & q_2 \end{bmatrix}Q=q100q2,那么xkTQxkx_k^T Q x_kxkTQxk其实就是q1⋅位置2+q2⋅速度2q_1 \cdot 位置^2 + q_2 \cdot 速度^2q1⋅位置2+q2⋅速度2
- QQQ 惩罚"你偏离目标状态的程度"
- 位置2位置^2位置2 表示离目标远不远
- 速度2速度^2速度2 表示动得快不快
- RRR 惩罚"你用力太猛"(控制输入ukukuk是否过大)
- 常见的
最优控制(Optimal Control)算法有:LQR(Linear Quadratic Regulator): 在线性系统与二次型代价函数假设下的最优反馈控制方法,是最经典的解析解形式之一。MPC(Model Predictive Control):基于滚动时域优化的控制方法,在每个时刻求解有限时间优化问题,能够显式处理系统约束(如输入饱和、状态约束等)。- 考虑后面有一期我们来谈谈这两个算法的实现。
1-5-2 状态估计(State Estimation)
- 在实际系统中,一个关键现实是:
系统的真实状态 xkx_kxk 往往无法直接测量。
- 因此只能通过有噪声的观测yky_kyk来反向推断真实的状态xkx_kxkyk=Cxk+vky_k = Cx_k + v_kyk=Cxk+vk其中:
- yky_kyk:可测输出
- vkv_kvk:测量噪声
- 还是一样举个例子:
- 我们假设是xk=位置速度x_k = \begin{bmatrix} 位置 \\ 速度 \end{bmatrix}xk=位置速度,但是我们实际只能通过传感器来测得当前的数据,所以我们当前的观测是 yk=传感器信息+vky_k=传感器信息+v_kyk=传感器信息+vk
- 我们需要做的就是通过传感器的噪声数据反向估计真实的数据
- 常见的
状态估计(State Estimation)算法有:Kalman Filter(KF):在"线性系统 + 高斯噪声"假设下,通过"预测 + 更新"的递推结构,对系统状态进行最优估计,是现代状态估计理论的基础方法。
1-6 工程上的
-
在实际工程系统中,现代控制理论通常以一个完整闭环的形式落地,而不是孤立使用某个算法。
-
典型结构如下:
系统 → 状态估计器(KF) → 控制器(LQR / PID / MPC) → 系统
-
现代控制工程的核心,就是在"不完全可观测的动态系统"中,通过
状态估计与最优控制的协同,实现对真实物理系统的闭环调节与优化。
2 卡尔曼滤波
2-1 介绍
- 卡尔曼滤波(Kalman Filter, KF)是由 R. E. Kalman 在 1960 年提出的一种用于线性动态系统状态估计的最优递推算法。
- 在控制理论与信号处理领域中,卡尔曼滤波具有极其重要的地位,其核心意义在于:
在存在噪声干扰的情况下,对动态系统的"不可直接观测状态"进行最优估计。
2-2 卡尔曼滤波的前提
- 需要注意的是,卡尔曼滤波并不是对所有系统都成立,它建立在一组明确的数学假设之上:
2-2-1 线性系统(Linear System)
-
系统必须满足线性状态空间模型:xk=Fxk−1+Buk+wkx_k = F x_{k-1} + B u_k + w_kxk=Fxk−1+Buk+wkzk=Hxk+vkz_k = H x_k + v_kzk=Hxk+vk其中:
- xkx_kxk:系统状态
- uku_kuk:控制输入
- zkz_kzk:观测值
- wkwkwk:过程噪声("状态演化过程中"的不确定性或外部扰动。)
- vkv_kvk:观测噪声(传感器测量过程中引入的误差。)
- FFF:状态转移矩阵(系统如何自己演化)
- BBB:控制输入如何影响系统
- HHH:状态到观测的映射
-
说人话,线性系统必须满足
"线性可叠加"- 输入翻倍 → 输出也按比例变化
- 两个输入叠加 → 输出也是叠加
2-2-2 噪声为高斯白噪声
- 系统噪声满足:
- 过程噪声:wk∼N(0,Q)w_k \sim \mathcal{N}(0, Q)wk∼N(0,Q)
- 观测噪声:vk∼N(0,R)v_k \sim \mathcal{N}(0, R)vk∼N(0,R)
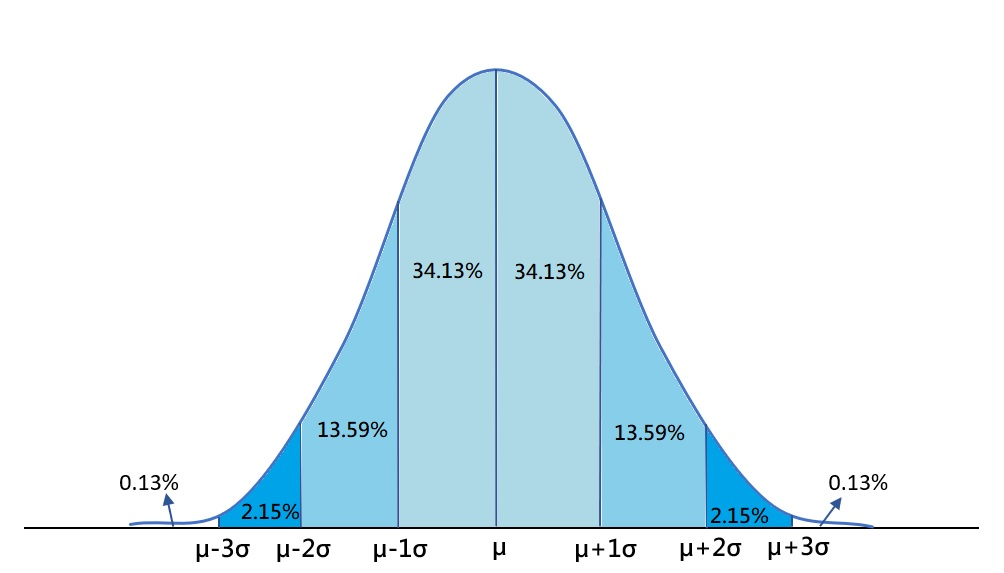
- 高斯白噪声分成三块理解,
- 高斯分布:按照上面高斯分布的图,也就是大部分误差很小,少量大误差很少出现
- 横轴我们理解为:误差大小(-∞ → +∞)
- 纵轴我们理解为:出现这个误差的概率
- 零均值Ewk=0,Evk=0Ewk=0,Evk=0Ewk=0,Evk=0说明没有系统性偏差,不会存在越估计越不准
- 白噪声(White Noise):每一时刻的噪声彼此独立
2-2-3 初始状态服从高斯分布
x0∼N(x^0,P0)x_0 \sim \mathcal{N}(\hat{x}_0, P_0)x0∼N(x^0,P0)
- x^0\hat{x}_0x^0:你认为的初始状态
- P0P_0P0:随机变量 x0x_0x0 的方差(variance)或协方差矩阵(covariance matrix)
2-2-4 马尔可夫性(Markov Property)
马尔可夫性(Markov Property):指系统的未来状态只依赖于当前状态,而与更早的历史状态无关。P(xk∣xk−1)P(xk∣xk−1,xk−2,... )=P(xk∣xk−1)P(xk∣xk−1)P(x_k | x_{k-1}, x_{k-2}, \dots) = P(x_k | x_{k-1})P(xk∣xk−1)P(xk∣xk−1,xk−2,...)=P(xk∣xk−1)- 说人话就是
- 系统"没有记忆",它只记得现在,不记得过去。
2-3 公式推导
- 那么我们就开始进行卡尔曼滤波的推导
2-3-1 状态预测(Prior)
-
已知上一时刻估计,也就是我们认为上一时刻的真实状态 xk−1x_{k-1}xk−1很可能在 x^k−1\hat{x}{k-1}x^k−1 附近,并且误差服从高斯分布,误差大小由 Pk−1P{k-1}Pk−1描述。xk−1∼N(x^k−1,Pk−1)x_{k-1} \sim \mathcal{N}(\hat{x}{k-1}, P{k-1})xk−1∼N(x^k−1,Pk−1)
-
那么我们就可以根据系统的状态方程xk=Fxk−1+wkx_k = F x_{k-1} + w_kxk=Fxk−1+wk直接得到我们的预测内容:
- 预测均值:(最佳观测值)x^k∣k−1=Fx^k−1+Buk\hat{x}{k|k-1} = F \hat{x}{k-1} + B u_kx^k∣k−1=Fx^k−1+Buk
- 预测协方差:(不确定性)Pk∣k−1=FPk−1FT+QP_{k|k-1} = F P_{k-1} F^T + QPk∣k−1=FPk−1FT+Q
-
以防你忘记:
- xkx_kxk:系统状态
- uku_kuk:控制输入
- wkwkwk:过程噪声("状态演化过程中"的不确定性或外部扰动。)
- FFF:状态转移矩阵(系统如何自己演化)
- BBB:控制输入如何影响系统
2-3-2 观测更新(Posterior)
-
先前我们提到的,我们假设观测模型:zk=Hxk+vkz_k = H x_k + v_kzk=Hxk+vk
-
以防你忘记:
- zkz_kzk:观测值
- vkv_kvk:观测噪声(传感器测量过程中引入的误差。)
- HHH:状态到观测的映射
2-3-3 贝叶斯更新
- 也就是我们当前已经有了先验分布p(xk)p(x_k )p(xk)、似然估计p(zk∣xk)p(z_k|x_k)p(zk∣xk)、观测边缘概率p(zk)p(z_k)p(zk),我们需要借助贝叶斯公式计算求后验分布p(xk∣zk)=p(zk∣xk)p(xk)p(zk)p(x_k|z_k) = \frac{p(z_k|x_k)p(x_k)}{p(z_k)}p(xk∣zk)=p(zk)p(zk∣xk)p(xk)
- 其中这里的
- 先验分布p(xk)p(x_k )p(xk):来自状态预测xk−1∼N(x^k−1,Pk−1)x_{k-1} \sim \mathcal{N}(\hat{x}{k-1}, P{k-1})xk−1∼N(x^k−1,Pk−1)
- 似然估计p(zk∣xk)p(z_k|x_k)p(zk∣xk):来自观测模型zk=Hxk+vkz_k = H x_k + v_kzk=Hxk+vk
- 观测边缘概率p(zk)p(z_k)p(zk):p(zk)=∫p(zk∣xk)p(xk) dxkp(z_k) = \int p(z_k|x_k)p(x_k)\,dx_kp(zk)=∫p(zk∣xk)p(xk)dxk,也就是"在所有可能的 xkx_kxk 下,观测 zkz_kzk 出现的总概率"
- 同时我们利用高斯分布性质:后验分布p(xk∣zk))p(x_k|z_k))p(xk∣zk))后验仍为高斯分布p(x∣z)∝p(z∣x)p(x)p(x|z) \propto p(z|x)p(x)p(x∣z)∝p(z∣x)p(x)
- 也就是说: xk∼N(x^k,Pk)x_{k} \sim \mathcal{N}(\hat{x}{k}, P{k})xk∼N(x^k,Pk)
- 因为先验和似然都是高斯分布,并且观测模型是线性的仿射变换,因此后验仍为高斯分布(高斯分布的共轭性),所以KF本质是"高斯分布在仿射变换下的闭式更新"
- 那么下面的
1-3-4(卡尔曼增益)+1-3-5(状态更新)+1-3-6(协方差更新)= 贝叶斯更新的"解析实现"
2-3-4 卡尔曼增益推导
- 也就是说我们目前已经得到了预测状态:x^k∣k−1=Fx^k−1+Buk\hat{x}{k|k-1} = F \hat{x}{k-1} + B u_kx^k∣k−1=Fx^k−1+Buk
2-3-4-1 残差(innovation)(观测空间下)
- 我们定义
残差(innovation)来表示我预测的差距:yk=zk−Hx^k∣k−1y_k = z_k - H \hat{x}_{k|k-1}yk=zk−Hx^k∣k−1其中:- zkz_kzk:观测值
- Hx^k∣k−1H \hat{x}_{k|k-1}Hx^k∣k−1:预测状态对应的观测值
2-3-4-2 协方差(观测空间下)
- 其协方差:Sk=HPk∣k−1HT+RS_k = H P_{k|k-1} H^T + RSk=HPk∣k−1HT+R其中:
- HPk∣k−1HTH P_{k|k-1} H^THPk∣k−1HT:预测不确定性,Pk∣k−1P_{k|k-1}Pk∣k−1是状态协方差,HHH:状态到观测的转移矩阵
- RRR:传感器本身噪声
- 值得说明的一点是,Pk∣k−1P_{k|k-1}Pk∣k−1是在状态空间下的协方差,而SkS_kSk则对应观测空间下的协方差,这二者需要进行映射变换,对应的规则是:
- z=Hxz=Hxz=Hx
- Cov(Hx)=H Cov(x) HT\mathrm{Cov}(Hx) = H \, \mathrm{Cov}(x) \, H^TCov(Hx)=HCov(x)HT
- 左边 HHH:把 x 映射到 z 空间
- 右边 HTH^THT:保持协方差结构(内积结构)
2-3-4-3 卡尔曼增益Kalman Gain(核心!!!!!!!!)
-
那么我们现在已经得到了观测空间下预测值的
残差(innovation)和协方差,我们需要定义一个自适应权重,用来根据"预测不确定性"和"观测不确定性"自动决定融合比例。 -
卡尔曼增益:Kk=Pk∣k−1HTSk−1K_k = P_{k|k-1} H^T S_k^{-1}Kk=Pk∣k−1HTSk−1其中:
- SkS_kSk:观测空间下的协方差,也就是不确定性
- Sk−1S_k^{-1}Sk−1:是观测不确定性的逆,表示观测的可信程度,用来控制卡尔曼增益中观测信息的权重。
- Pk∣k−1HTSk−1P_{k|k-1}H^T S_k^{-1}Pk∣k−1HTSk−1:用HTH^THT投影把观测空间下映射回回状态空间
| 对象 | 含义 |
|---|---|
| H | 状态 → 观测 |
| K | 观测 → 状态 |
- 注意:K 不是 H 的逆,而是"最优融合权重"
2-3-5 状态更新
- 那么现在我们已经有了
卡尔曼增益Kalman Gain,我们就可以对预测的数据进行修正x^k=x^k∣k−1+Kkyk\hat{x}k = \hat{x}{k|k-1} + K_k y_kx^k=x^k∣k−1+Kkyk其中:- x^k∣k−1\hat{x}_{k|k-1}x^k∣k−1:预测值
- yky_kyk: 残差
- 从这里我们不难看出KF 本质是在做"局部线性修正"
2-3-6 协方差更新
- 同时我们需要对协方差也进行更新Pk=(I−KkH)Pk∣k−1P_k = (I - K_k H) P_{k|k-1}Pk=(I−KkH)Pk∣k−1其中:
- Pk∣k−1P_{k|k-1}Pk∣k−1:预测协方差
- KkHK_k HKkH:观测对状态的影响程度
- I−KkHI - K_k HI−KkH:剩下的部分
- 也就是利用观测信息来修正不确定性。
3 卡尔曼滤波python实现
3-1 背景描述
- 我们来思考一个应用场景,我们假设一个有规则运动的小球在二维平面中运动,其真实状态包含位置与速度,但只能通过传感器获得带有噪声的位置观测,因此无法直接得到真实轨迹,也无法直接观测速度等隐含状态。
3-2 系统建模
- 对于上述背景,我们设定:
- 状态变量 xx=xyvxvyx = \begin{bmatrix} x \\ y \\ v_x \\ v_y \end{bmatrix}x= xyvxvy
- 观测变量zz=xyz = \begin{bmatrix} x \\ y \end{bmatrix}z=xy
- 状态转移矩阵 FF=10dt0010dt00100001F = \begin{bmatrix} 1 & 0 & dt & 0 \\ 0 & 1 & 0 & dt \\ 0 & 0 & 1 & 0 \\ 0 & 0 & 0 & 1 \end{bmatrix}F= 10000100dt0100dt01
- 原理就是假设物体在极短时间的运行模型是"局部可以近似匀速直线",满足:{xk+1=xk+vx⋅dtyk+1=yk+vy⋅dtvx,k+1=vx,kvy,k+1=vy,k\begin{cases} x_{k+1} = x_k + v_x \cdot dt \\ y_{k+1} = y_k + v_y \cdot dt \\ v_{x,k+1} = v_{x,k} \\ v_{y,k+1} = v_{y,k} \end{cases}⎩ ⎨ ⎧xk+1=xk+vx⋅dtyk+1=yk+vy⋅dtvx,k+1=vx,kvy,k+1=vy,k
- 这时候我们就可以根据xk+1=Fxkx_{k+1}=Fx_kxk+1=Fxk
- 观测矩阵HH=10000100H = \begin{bmatrix} 1 & 0 & 0 & 0 \\ 0 & 1 & 0 & 0\end{bmatrix}H=10010000
- 对于z=Hxz=Hxz=Hx
- 状态空间协方差P:P=1000010000100001⋅10 P=\begin{bmatrix} 1 & 0 & 0 & 0 \\ 0 & 1 & 0 & 0\\ 0&0&1&0\\ 0&0&0&1\end{bmatrix}\cdot10P= 1000010000100001 ⋅10其中:
- P0=10IP_0=10IP0=10I,也就是说初始不确定性为10(系数自己定)
- 过程噪声Q:Q=1000010000100001⋅0.2 Q=\begin{bmatrix} 1 & 0 & 0 & 0 \\ 0 & 1 & 0 & 0\\ 0&0&1&0\\ 0&0&0&1\end{bmatrix}\cdot0.2Q= 1000010000100001 ⋅0.2
- 观测噪声R:R=1001⋅3.0 R=\begin{bmatrix} 1 & 0 \\0&1\end{bmatrix}\cdot3.0R=1001⋅3.0
3-2 KF代码实现
- 我们实现KF的内容如下:
python
class KF:
def __init__(self):
self.dt = 1.0 # 时间间隔
self.x = np.zeros((4, 1)) # 状态变量
self.F = np.array([ # 状态转移矩阵
[1, 0, self.dt, 0],
[0, 1, 0, self.dt],
[0, 0, 1, 0],
[0, 0, 0, 1]
])
self.H = np.array([ # 观测矩阵
[1, 0, 0, 0],
[0, 1, 0, 0]
])
self.P = np.eye(4) * 10 # 状态空间协方差P
self.Q = np.eye(4) * 0.2 # 过程噪声
self.R = np.eye(2) * 3.0 # 观测噪声
def predict(self):
'''状态预测'''
# 更新状态
self.x = self.F @ self.x
# 更新协方差
self.P = self.F @ self.P @ self.F.T + self.Q
def update(self, z):
'''贝叶斯更新'''
# 观测更新
z = np.array(z).reshape(2, 1)
# 观测空间的残差
y = z - self.H @ self.x
# 观测空间的协方差
S = self.H @ self.P @ self.H.T + self.R
# 卡尔曼增益
K = self.P @ self.H.T @ np.linalg.inv(S)
# 修正状态
self.x = self.x + K @ y
# 修正协方差
self.P = (np.eye(4) - K @ self.H) @ self.P3-3 模型
- 我们分别实现以下两种模拟运动的物体
python
class BaseTarget:
def step(self):
raise NotImplementedError
class ConstantVelocityTarget(BaseTarget):
def __init__(self):
self.x = np.array([0.0, 0.0])
self.v = np.array([2.0, 1.0])
def step(self):
self.x = self.x + self.v
return self.x.copy()
class CircularTarget(BaseTarget):
def __init__(self):
self.t = 0.0
self.radius = 50.0
self.omega = 0.05
def step(self):
x = self.radius * np.cos(self.t)
y = self.radius * np.sin(self.t)
self.t += self.omega
return np.array([x, y])3-4 测试
- 我们实现如下代码:
cpp
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.animation as animation
from abc import ABC, abstractmethod
class KF:
def __init__(self):
self.dt = 1.0 # 时间间隔
self.x = np.zeros((4, 1)) # 状态变量
self.F = np.array([ # 状态转移矩阵
[1, 0, self.dt, 0],
[0, 1, 0, self.dt],
[0, 0, 1, 0],
[0, 0, 0, 1]
])
self.H = np.array([ # 观测矩阵
[1, 0, 0, 0],
[0, 1, 0, 0]
])
self.P = np.eye(4) * 10 # 状态空间协方差P
self.Q = np.eye(4) * 0.2 # 过程噪声
self.R = np.eye(2) * 3.0 # 观测噪声
def predict(self):
'''状态预测'''
# 更新状态
self.x = self.F @ self.x
# 更新协方差
self.P = self.F @ self.P @ self.F.T + self.Q
def update(self, z):
'''贝叶斯更新'''
# 观测更新
z = np.array(z).reshape(2, 1)
# 观测空间的残差
y = z - self.H @ self.x
# 观测空间的协方差
S = self.H @ self.P @ self.H.T + self.R
# 卡尔曼增益
K = self.P @ self.H.T @ np.linalg.inv(S)
# 修正状态
self.x = self.x + K @ y
# 修正协方差
self.P = (np.eye(4) - K @ self.H) @ self.P
# =========================
# Target
# =========================
class BaseTarget:
def step(self):
raise NotImplementedError
class ConstantVelocityTarget(BaseTarget):
def __init__(self):
self.x = np.array([0.0, 0.0])
self.v = np.array([2.0, 1.0])
def step(self):
self.x = self.x + self.v
return self.x.copy()
class CircularTarget(BaseTarget):
def __init__(self):
self.t = 0.0
self.radius = 50.0
self.omega = 0.05
def step(self):
x = self.radius * np.cos(self.t)
y = self.radius * np.sin(self.t)
self.t += self.omega
return np.array([x, y])
# =========================
# Init
# =========================
target = ConstantVelocityTarget()
filt = KF()
true_path = []
obs_path = []
est_path = []
rmse_history = []
# =========================
# Plot
# =========================
fig, (ax, ax2) = plt.subplots(1, 2, figsize=(12, 5))
true_line, = ax.plot([], [], 'g-', label="True")
obs_scatter, = ax.plot([], [], 'bo', markersize=3, label="Obs")
est_line, = ax.plot([], [], 'r-', label="Filter")
ax.legend()
ax.set_title("Tracking")
rmse_line, = ax2.plot([], [], 'r-', label="RMSE")
ax2.set_title("Running RMSE")
ax2.set_xlabel("Frame")
ax2.set_ylabel("RMSE")
ax2.grid(True)
ax2.legend()
# =========================
# Utils
# =========================
def follow_view(ax, tp, window=60):
cx, cy = tp[-1]
ax.set_xlim(cx - window, cx + window)
ax.set_ylim(cy - window, cy + window)
# =========================
# Update
# =========================
def update(frame):
global target, filt
true = target.step()
if np.random.rand() < 0.7:
obs = true + np.random.randn(2) * 0.8
else:
obs = None
filt.predict()
if obs is not None:
filt.update(obs)
est = filt.x[:2].flatten()
true_path.append(true)
est_path.append(est)
if obs is not None:
obs_path.append(obs)
else:
obs_path.append([np.nan, np.nan])
tp = np.array(true_path)
op = np.array(obs_path)
ep = np.array(est_path)
# =========================
# RMSE (running)
# =========================
err = np.linalg.norm(true - est)
rmse_history.append(err)
rmse_curve = np.sqrt(
np.cumsum(np.square(rmse_history)) /
np.arange(1, len(rmse_history) + 1)
)
# =========================
# plot update
# =========================
true_line.set_data(tp[:, 0], tp[:, 1])
obs_scatter.set_data(op[:, 0], op[:, 1])
est_line.set_data(ep[:, 0], ep[:, 1])
rmse_line.set_data(
np.arange(len(rmse_curve)),
rmse_curve
)
ax2.set_xlim(0, len(rmse_curve) + 1)
# 稳定y轴(用95分位避免爆炸)
ax2.set_ylim(0, np.percentile(rmse_curve, 95) + 1)
follow_view(ax, tp, window=70)
return true_line, obs_scatter, est_line, rmse_line
# =========================
# Animation
# =========================
ani = animation.FuncAnimation(
fig,
update,
interval=40,
blit=False,
cache_frame_data=False
)
plt.show()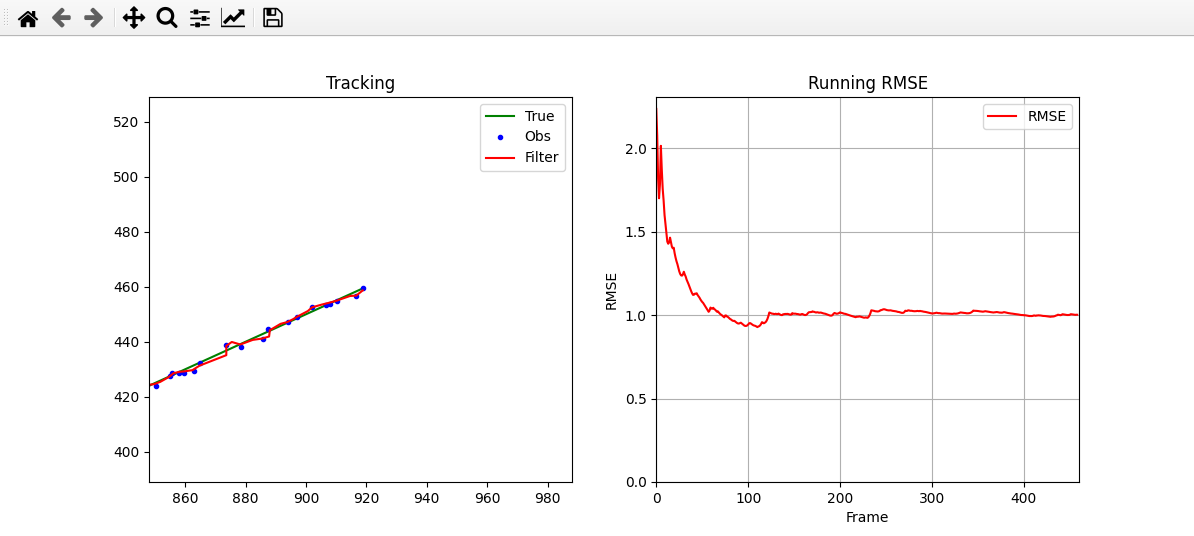
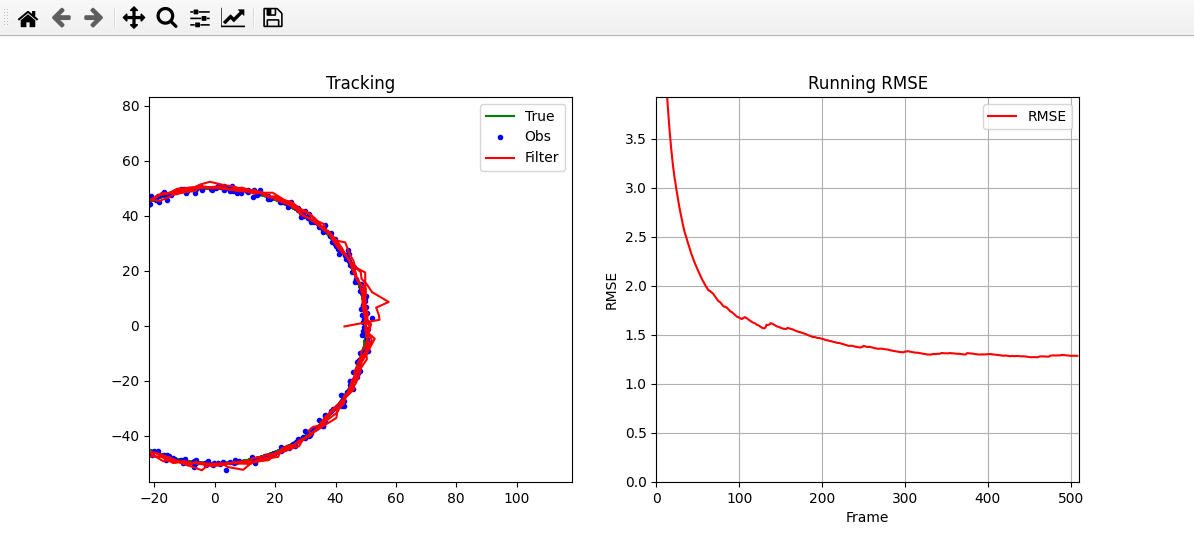
- 注意:这里 RMSE 为累计均方根误差
小节
- 本文以通俗易懂的方式介绍现代控制理论基础,同时介绍并简单推导卡尔曼滤波的公式,同时使用
python代码实现一个简单的卡尔曼滤波。 - 如有错误,欢迎指出!
- 感谢观看!