文章目录
- 1.RAG介绍
-
- [1.1 大模型的局限](#1.1 大模型的局限)
- [1.2 什么是RAG](#1.2 什么是RAG)
- [1.3 RAG优缺点](#1.3 RAG优缺点)
- [1.4 RAG流程](#1.4 RAG流程)
- 2.文档加载
-
- [2.1 加载 Markdown](#2.1 加载 Markdown)
- [2.2 加载Docx](#2.2 加载Docx)
- [2.3 加载 PDF](#2.3 加载 PDF)
1.RAG介绍
1.1 大模型的局限
1)知识滞后
LLM 因其具有海量参数,需要花费相当的物力与时间成本进行预训练和微调,同时商用 LLM 还需要进行各种安全测试与风险评估等。因此 LLM 会存在知识滞后的问题。
2)知识缺失
在专有领域,LLM 无法学习到所有的专业知识细节,因此在面向专业领域知识的提问时,无法给出可靠准确的回答。
3)幻觉
LLM 在生成回答时,可能会"胡言乱语",这种现象称之为 LLM 的"幻觉"。"幻觉"可以体现为错误陈述、编造事实、错误的复杂推理或者复杂语境下理解能力不足等。
"幻觉"产生的原因:
训练知识存在偏差,这些错误信息被 LLM 学习后在输出中复现
- LLM 训练时过度泛化,将普通的模式应用在特定场合导致不准确输出
- LLM 本身没有真正学习到训练数据中深层次的含义,导致在一些需要深入理解或复杂推理的任务中出错
- LLM 缺乏某些领域的相关知识,在面临这些领域的相关问题时编造不存在的信息
- 大模型生成内容的不可控,尤其是在金融和医疗领域等领域,一次金额评估的错误,一次医疗诊断的失误,哪怕只出现一次都是致命的。但这些错误对于非专业人士来说难以辨识。目前还没有能够百分之百解决这种情况的方案。
1.2 什么是RAG
为了改善大模型在时效性、可靠性与准确性方面的不足,各种针对 LLM 优化的方法应运而生。RAG(Retrieval-Augmented Generation,检索增强生成)就是其中一种被广泛研究和应用的优化架构。
RAG 的基本思想为:将传统的生成式大模型和实时信息检索技术相结合,为大模型补充来自外部的相关数据和上下文,来帮助大模型生成更加准确可靠的内容。这使得大模型在生成内容时可以依赖实时与个性化的数据和知识,而非仅仅依赖训练知识。就相当于在大模型回答时给它一本参考书。
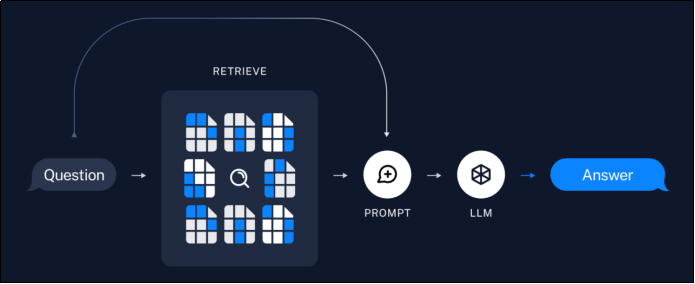
可以说,当应用需求集中在利用大模型去回答特定私有领域的知识,且知识库足够大时,那么除了微调大模型外,RAG 就是非常有效的一种解决方案。LangChain 对这一流程提供了解决方案。
1.3 RAG优缺点
1)RAG的优点
- 相比提示词工程,RAG 有更丰富的上下文和数据样本,可以不需要用户提供过多的背景描述,就能生成比较符合用户预期的答案。
- 相比于模型微调,RAG 可以提升问答内容的时效性和可靠性。
- 在一定程度上保护了业务数据的隐私性。
2)RAG的缺点
- 由于每次问答都涉及外部系统数据检索,因此 RAG 的响应时延相对较高。
- 引用的外部知识数据会消耗大量的模型 Token 资源。
1.4 RAG流程
1)典型的RAG有两个主要流程:
- 索引:从数据源提取数据,构建索引。
- 检索生成:接受用户查询并从索引中检索相关数据,然后将其传递给模型。
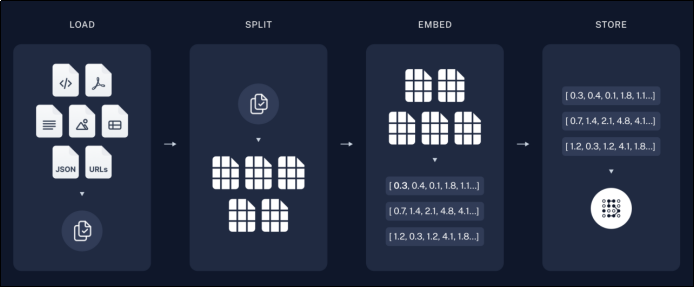
2)索引阶段整体流程如下:
- 从各种数据源加载数据;
- 将文档切分为小块;
- 对文本块进行嵌入;
- 存储嵌入向量。
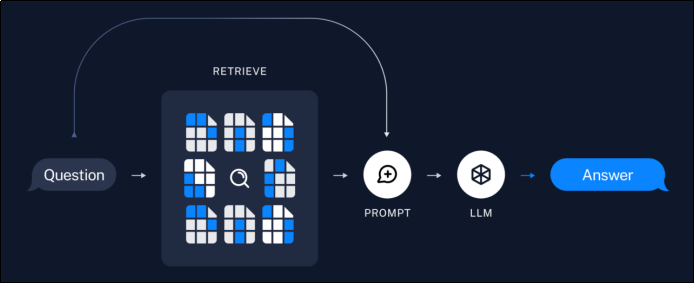
3)检索生成阶段:
- 根据用户输入,使用检索器从存储中检索相关文本块;
- 大模型使用包含问题和检索结果的提示生成回答。
2.文档加载
数据源可能包含多种格式的文件,如文本文档、Markdown,PDF 等。因此我们首先需要对各种格式的文件进行处理。LangChain 实现和集成了众多文档加载器,方便从不同格式的文件中加载数据。可在 https://docs.langchain.com/oss/python/integrations/document_loaders 查看所有集成的文档加载器。
LangChain 所有文档加载器都实现了 BaseLoader 接口,接口提供了通用的 load(一次加载所有文档) 与 lazy_load(以延迟方式加载文档) 方法,用于从数据源加载数据并处理为 Document 对象。
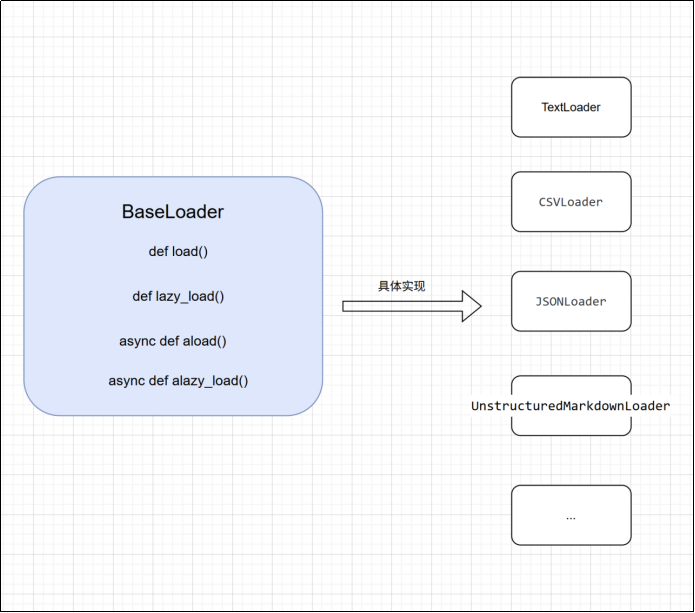
LangChain 实现了 Document 抽象,用于表示文本单元及其元数据,它包含三个属性:
- page_content:文本内容字符串。
- metadata:包含元数据的字典,如文档的来源等。
- id:可选,文档标识符。
下面通过Markdown和Docx以及PDF作为例子,来了解下如何对文件进行相关加载和解析。
2.1 加载 Markdown
MarkDown形式一种半结构化的数据,其原始文本,通过特定语法,标记出了标题、段落、有序列表、无序列表等相关信息,
如下所示,不同的层级的文本,在markdown当中表示的形式不一致:

可以使用 Unstructured 文档加载器来加载多种类型的文件,关于如何在 LangChain 中使用 unstructured 生态系统,可参考这里。
Unstructured.io对Markdown的解析流程,如下所示:
- 按照Markdown结构进行切分,标题等会被切分成单独的element
- 对于同一个标题下的文本,再按照段落进行切分,不同的段落(通过\n标识)会被切分成多个element。
可使用 langchain集成的UnstructuredMarkdownLoader 来加载 Markdown 文件。
2.2 加载Docx
现代的 Word 文档(.docx 格式)本质上也是一种半结构化(Semi-structured)且机器可读(Machine-readable)的文件。
.docx 的本质上是XML 的容器,XML 标签严格规定了文档的层级(比如 <w:p> 代表段落,<w:r> 代表文本运行块)。机器可以利用这些标签精确地提取信息。
但是,由于Word文档对于层级的定义相较于Markdown又更加灵活,我们可以自定义不同层级标题的样式,而这些样式通常只是正文样式,加了手动格式,使得解析库无法按照统一的标准格式将层级进行解析,这个特点给Word解析又带来了难点。
同样可以使用LangChain封装的Unstructured.io的Loader对.docx进行解析。在使用Unstructured.io对Word进行解析时,仅会按照换行对文件进行解析,无法识别出文档标题。
加载 Markdown、Docx示例代码
加载 Markdown、Docx示例代码
py
# 加载MarkDown文件的函数
from langchain_community.document_loaders import UnstructuredMarkdownLoader, UnstructuredWordDocumentLoader
# from langdetect import detect
def load_markdown():
# 创建非结构化的MarkDown的加载器,一次性加载整个文件
file_loader = UnstructuredMarkdownLoader("files/LangChain.md")
# 讲文件切分成多个文档
file_loader2 = UnstructuredMarkdownLoader(file_path="files/LangChain.md",mode="elements")
# 加载文件
docs = file_loader.load()
docs2 = file_loader2.load()
# 打印
print(type(docs)) # <class 'list'>
# 打印文档中的page_content
print(docs[0].page_content)
print("=" * 60)
print(type(docs2)) # <class 'list'>
# 遍历
for doc in docs2:
print(doc.page_content)
# 加载word文件的函数
def load_word():
# 创建加载器
file_load = UnstructuredWordDocumentLoader(file_path="files/LangChain.docx",mode="elements")
# 加载文件得到多个文档
docs = file_load.load()
# 遍历
for doc in docs:
print(doc.page_content)
if __name__ == "__main__":
# 调用加载md文件的函数
# load_markdown()
# 调用加载word文件的函数
load_word()这里需要自行创建LangChain.md和LangChain.docx
2.3 加载 PDF
PDF 存在多种来源格式,包括扫描版(图片 PDF)、电子文本版、混合版。并且布局格式也多种多样,包括单列布局、双列布局甚至竖排文本布局。并且包含段落、标题、页眉页脚、表格、数学公式、化学式、特殊符号、图片等各种元素。
因此,PDF 解析存在很多挑战。对于复杂 PDF,需要进行文本提取、布局检测、表格解析、公式识别等处理。
在此处,我们介绍一个开源的,专门用于解析PDF的工具:Mineru。
MinerU是一款将PDF转化为机器可读格式的工具(如markdown、json),可以很方便地抽取为任意格式。
Mineru可以配置使用VLM模型进行文档解析。其开源的opendatalab/MinerU2.5-2509-1.2B(https://huggingface.co/opendatalab/MinerU2.5-2509-1.2B))模型,在各项基础测试当中,都达到了SOTA水平
下图展示了MinerU2-VLM在多项基准测试当中得分排名:
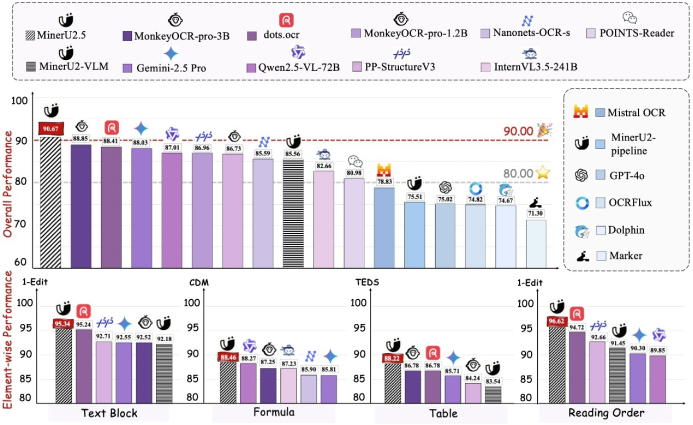
MinerU2.5采用两阶段解析策略:首先对下采样图像进行高效的全局布局分析,然后对文本、公式和表格的原生分辨率裁剪图像进行细粒度内容识别。在大规模、多样化的数据引擎支持下进行预训练和微调,MinerU2.5 在多个基准测试中始终优于通用模型和特定领域模型,同时保持较低的计算开销。MinerU 提供了 PDF、Word、PPT、图片等文件的解析,支持图像提取、OCR、公式、表格解析等功能。
另外,Mineru开源所有代码,支持本地通过Docker方式进行部署,其项目仓库链接:https://github.com/opendatalab/MinerU。Mineru官网也提供了直接调用API的方式,上传文件进行解析。首先需要在官网申请API_KEY,并将其放到环境变量当中
示例代码如下:
先去官网拿到免费使用的token:https://mineru.net/
py
# 测试使用MinerU解析PDF、图片等文件
# 上传文件的函数
def mineru_upload_file_demo():
import requests
token = "mineru_token"
url = "https://mineru.net/api/v4/file-urls/batch"
header = {
"Content-Type": "application/json",
"Authorization": f"Bearer {token}"
}
data = {
"files": [
{"name":"demo.pdf", "data_id": "abcd"}
],
"model_version":"vlm"
}
file_path = [r"files/img.png"]
try:
response = requests.post(url,headers=header,json=data)
if response.status_code == 200:
result = response.json()
print('上传成功:{}'.format(result))
batch_id = result['data']['batch_id']
if result["code"] == 0:
batch_id = result["data"]["batch_id"]
urls = result["data"]["file_urls"]
print('batch_id:{},urls:{}'.format(batch_id, urls))
for i in range(0, len(urls)):
with open(file_path[i], 'rb') as f:
res_upload = requests.put(urls[i], data=f)
if res_upload.status_code == 200:
print(f"{urls[i]} 上传成功")
else:
print(f"{urls[i]} 上传失败")
else:
print('apply upload url failed,reason:{}'.format(result.msg))
return batch_id
else:
print(f"请求失败,状态码:{response.status_code},响应内容:{response.text}")
except Exception as err:
print(err)
# 获取解析结果的函数
def mineru_check_result_demo(batch_id):
import requests
import time
token = "mineru_token"
url = f"https://mineru.net/api/v4/extract-results/batch/{batch_id}"
header = {
"Content-Type": "application/json",
"Authorization": f"Bearer {token}"
}
res = requests.get(url, headers=header)
while res.json()["data"]['extract_result'][0]['state'] != 'done':
print('当前状态为running,等待3秒后重试')
time.sleep(3)
res = requests.get(url, headers=header)
print(res.status_code)
print(res.json()["data"]['extract_result'][0]['state'],end="\n\n=========\n\n")
print('提取结果为:',res.json()["data"]['extract_result'][0]['full_zip_url'])
if __name__ == '__main__':
# 调用上传文件的函数
batch_id = mineru_upload_file_demo()
# 调用获取解析结果的函数
mineru_check_result_demo(batch_id)Mineru解析之后,有多种不同的输出格式,具体可参见Mineru官方文档:https://opendatalab.github.io/MinerU/zh/reference/output_files/。
要进行下一步处理,最简单的方式是通过解析之后得到的一个MarkDown文件,再利用MarkDown解析器,进行进一步的解析即可。
相关文章: