一次将高斯过程回归与多目标进化算法"联姻"的工程实践,让双色注塑成型工艺参数优化从"试错调参"迈向"智能寻优"。
1. 研究背景:为什么双色注塑成型工艺参数优化这么难?
双色注塑成型(Two-Color Injection Molding)是高端塑料制品制造的核心工艺之一。它通过两次注射,在同一模具内将两种不同颜色或材质的熔融塑料依次注入型腔,形成一体化双色产品,被广泛应用于汽车内饰件、消费电子外壳、医疗器械外壳等领域。
然而,双色注塑成型是一个高度耦合的多物理场过程,涉及熔体流动、热传导、结晶动力学、收缩与翘曲等多个子过程的非线性交互。工艺参数的微小变化------无论是模具温度、熔体温度、注射速度、保压压力,还是冷却时间------都可能导致产品出现体积收缩超标、翘曲变形过大等质量缺陷。
传统上,工程师依赖"试错法"或单因素轮换实验来调参,效率低且难以找到全局最优解。Moldflow等CAE仿真软件虽能精确模拟,但单次仿真耗时数小时,无法直接嵌入迭代优化循环。
本研究的核心思路是:用Kriging代理模型(高斯过程回归)替代昂贵的Moldflow仿真,将其嵌入**多目标粒子群优化算法(MOPSO)**的适应度评估环节,从而在分钟级时间内完成对10个工艺参数、3个质量目标的联合优化。
2. 问题建模:三目标十变量的优化难题
2.1 设计变量(10维)
本问题涉及双色注塑成型的 10个关键工艺参数,各自具有物理约束范围:
| 序号 | 变量符号 | 参数名称 | 下界 | 上界 | 单位 |
|---|---|---|---|---|---|
| 1 | T mold | 模具温度 | 40 | 80 | °C |
| 2 | T m1 | 第一射熔体温度 | 200 | 260 | °C |
| 3 | T m2 | 第二射熔体温度 | 200 | 260 | °C |
| 4 | V 1 | 第一射注射速度 | 30 | 90 | mm/s |
| 5 | V 2 | 第二射注射速度 | 30 | 90 | mm/s |
| 6 | P 1 | 第一射保压压力 | 40 | 80 | MPa |
| 7 | P 2 | 第二射保压压力 | 40 | 80 | MPa |
| 8 | t p1 | 第一射保压时间 | 5 | 15 | s |
| 9 | t p2 | 第二射保压时间 | 5 | 15 | s |
| 10 | t cool | 冷却时间 | 15 | 30 | s |
2.2 优化目标(3维,全部最小化)
| 目标 | 含义 | 单位 |
|---|---|---|
| f 1 | 第一射体积收缩率 | % |
| f 2 | 第二射体积收缩率 | % |
| f 3 | 总翘曲量 | mm |
三个目标之间存在冲突关系 ------例如,提高保压压力可减少收缩,但可能加剧翘曲变形。因此,我们寻求的不是单一最优解,而是Pareto最优解集(即非支配解集)。
3. 技术路线:四阶段方法论
整体技术路线分为四个阶段,如下图所示:
┌──────────────┐ ┌──────────────────┐ ┌────────────────┐ ┌──────────────┐
│ 阶段一 │ │ 阶段二 │ │ 阶段三 │ │ 阶段四 │
│ 试验设计 │ → │ 代理模型构建 │ → │ 多目标优化 │ → │ 决策分析 │
│ (LHS采样) │ │ (Kriging/GP) │ │ (MOPSO) │ │ (TOPSIS) │
└──────────────┘ └──────────────────┘ └────────────────┘ └──────────────┘
↓ ↓ ↓ ↓
80组拉丁超立方 3个高斯过程 Pareto前沿 最优折衷解
工艺参数组合 回归模型 100个非支配解 +改善率分析阶段一:拉丁超立方采样(LHS)
采用改进的拉丁超立方采样 在10维设计空间内生成80组均匀分布的初始试验方案。相比传统正交试验,LHS以更少的采样点实现对整个设计空间的均匀覆盖。核心思想是将每个维度的取值范围等分为 n 个区间,在每个区间内随机采样并打乱组合:
xij=lbj+πj(i)−1+Uijn⋅(ubj−lbj)x_{ij} = lb_j + \frac{\pi_j(i) - 1 + U_{ij}}{n} \cdot (ub_j - lb_j)xij=lbj+nπj(i)−1+Uij⋅(ubj−lbj)
其中 π *j* 为随机排列映射,U *ij* ~ Uniform(0,1) 为区间内随机扰动。
阶段二:Kriging代理模型构建
对每个目标函数独立构建Kriging(高斯过程回归)模型。Kriging不仅能提供预测均值 ,还能给出预测方差(不确定性量化),这是其区别于神经网络、SVM等黑箱模型的显著优势。
阶段三:MOPSO多目标优化
以Kriging模型预测值作为适应度函数,运行MOPSO算法。种群在10维设计空间中搜索,每次迭代通过Kriging预测3个目标值(毫秒级),替代了小时级的Moldflow仿真。
阶段四:TOPSIS最优决策
从Pareto前沿中选取最优折衷解------即同时最接近正理想解且最远离负理想解的工艺参数组合,为现场工程师提供可直接使用的调机方案。
4. 核心算法原理
4.1 Kriging代理模型(高斯过程回归)
Kriging模型将真实函数视为一个高斯过程的实现:
y(x)=μ+Z(x)y(\mathbf{x}) = \mu + Z(\mathbf{x})y(x)=μ+Z(x)
- μ:全局趋势项(常数假设,即普通Kriging)
- Z(x):零均值高斯过程,其空间相关性由协方差函数刻画
协方差函数选择高斯核(平方指数核):
CovZ(xi),Z(xj)=σ2⋅R(xi,xj)=σ2⋅exp(−∑k=1dθk⋅∣xik−xjk∣2)\text{Cov}Z(\\mathbf{x}_i), Z(\\mathbf{x}_j) = \sigma^2 \cdot R(\mathbf{x}i, \mathbf{x}j) = \sigma^2 \cdot \exp\left(-\sum{k=1}^{d} \theta_k \cdot |x{ik} - x_{jk}|^2 \right)CovZ(xi),Z(xj)=σ2⋅R(xi,xj)=σ2⋅exp(−k=1∑dθk⋅∣xik−xjk∣2)
其中 θ = *θ* ₁, ..., *θ* ~*d*~ 为各向异性(anisotropic)相关系数向量,控制每个输入维度上的空间变化平滑程度。*θ *k* 越大,该维度上的响应越平滑;θ *k* 趋近于 0,则该维度几乎无影响。
超参数估计 :通过最大化边际似然(即最小化负对数边际似然)来确定 θ:
NLL(θ)=n2log(2π)+n2log(σ^2)+∑i=1nlog(Lii)+n2\text{NLL}(\boldsymbol{\theta}) = \frac{n}{2}\log(2\pi) + \frac{n}{2}\log(\hat{\sigma}^2) + \sum_{i=1}^{n}\log(L_{ii}) + \frac{n}{2}NLL(θ)=2nlog(2π)+2nlog(σ^2)+i=1∑nlog(Lii)+2n
采用 fmincon(SQP算法) 对 θ 进行数值优化(约束范围 0.01, 20)。
预测公式为最佳线性无偏预测(BLUP):
y^(x∗)=μ+r(x∗)TR−1(y−1μ)\hat{y}(\mathbf{x}^*) = \mu + \mathbf{r}(\mathbf{x}^*)^T \mathbf{R}^{-1}(\mathbf{y} - \mathbf{1}\mu)y^(x∗)=μ+r(x∗)TR−1(y−1μ)
其中 r (x *)=R(**x** \*, **x** ₁), ..., R(**x** \*, **x** ~*n*~)ᵀ 为预测点与训练点之间的相关向量。
4.2 MOPSO多目标粒子群优化算法
标准PSO仅适用于单目标优化,MOPSO(Coello Coello et al., 2004)将其扩展至多目标场景,核心改进包括:
(1)速度与位置更新 :
vi(t+1)=w⋅vi(t)+c1r1(pbesti−xi(t))+c2r2(leaderi−xi(t))\mathbf{v}_i^{(t+1)} = w \cdot \mathbf{v}_i^{(t)} + c_1 r_1 (\mathbf{pbest}_i - \mathbf{x}_i^{(t)}) + c_2 r_2 (\mathbf{leader}_i - \mathbf{x}_i^{(t)})vi(t+1)=w⋅vi(t)+c1r1(pbesti−xi(t))+c2r2(leaderi−xi(t))
xi(t+1)=xi(t)+vi(t+1)\mathbf{x}_i^{(t+1)} = \mathbf{x}_i^{(t)} + \mathbf{v}_i^{(t+1)}xi(t+1)=xi(t)+vi(t+1)
其中 leader *i* 是从**外部存档(External Archive)**中选取的全局引导者。
(2)外部存档机制 :维护一个存储当前所有非支配解的外部集合,使用非支配排序 剔除被支配个体,通过拥挤距离裁剪超量存档,保证解的多样性和均匀分布。
(3)领导者选择策略 :采用基于拥挤距离的轮盘赌选择------位于稀疏区域的解(拥挤距离大)被选为领导者的概率更高,从而驱使种群探索Pareto前沿上的未覆盖区域。
(4)个体最优更新规则:
- 若新解支配当前 pbest → 更新
- 若 pbest 支配新解 → 不更新
- 若互不支配 → 以 50% 概率随机更新
(5)多项式变异 :以 p mut = 1/d 的概率对每个变量施加多项式变异(分布指数 η m = 20),维持种群多样性。
4.3 TOPSIS决策方法
从Pareto前沿的100个非支配解中,通过TOPSIS选择最优折衷解:
- 向量归一化 :r *ij* = f *ij* / √(∑f ²*ij*)
- 正/负理想解 :A ⁺ = (minr ₁, ..., minr *m*),A ⁻ = (maxr ₁, ..., maxr *m*)
- Euclidean距离 :d ⁺*i* = ‖r *i* - A ⁺‖,d ⁻*i* = ‖r *i* - A⁻‖
- 相对贴近度 :C *i* = d ⁻*i* / (d ⁺*i* + d ⁻*i*),取最大值对应解
5. 算法参数设定
| 参数类别 | 参数名称 | 设定值 | 说明 |
|---|---|---|---|
| LHS | 采样点数 n | 80 | 10维空间均匀覆盖 |
| MOPSO | 种群规模 | 100 | 粒子数量 |
| MOPSO | 最大代数 | 200 | 收敛充分 |
| MOPSO | 外部存档容量 | 100 | 同种群规模 |
| MOPSO | 惯性权重 w | 0.50 | 初始探索能力 |
| MOPSO | 衰减率 w damp | 0.99 | 逐步收敛 |
| MOPSO | 个体学习因子 c₁ | 1.5 | 认知分量 |
| MOPSO | 社会学习因子 c₂ | 2.0 | 社会分量 |
| MOPSO | 变异概率 p mut | 0.1 (=1/d) | 每个变量10%变异概率 |
| MOPSO | 分布指数 η m | 20 | 变异强度 |
| Kriging | θ k 范围 | 0.01, 20 | 各向异性 |
| Kriging | Nugget效应 | 1×10⁻⁸ | 数值稳定性 |
设计哲学:
- c ₁ < c₂(1.5 < 2.0):社会学习权重略大于个体认知,促进向全局最优收敛
- w damp = 0.99:缓慢衰减的惯性权重确保算法在早期充分探索、晚期精细收敛
- 变异概率 = 1/d:相当于平均每个个体发生一次变异,平衡探索与开发
6. 运行环境
| 项目 | 配置 |
|---|---|
| 编程语言 | MATLAB R2022a+ |
| 必需工具箱 | Optimization Toolbox(fmincon优化器) |
| 操作系统 | Windows / macOS / Linux |
| 内存需求 | ≤ 4 GB(Kriging矩阵为80×80,MOPSO种群100×10) |
| 运行时长 | 约 2-5 分钟(主要开销在Kriging θ参数的MLE优化和MOPSO 200代迭代) |
| 随机种子 | 固定为 42(保证结果可复现) |
| 并行计算 | 未启用(可选,可对Kriging模型的3个目标并行训练) |
代码文件结构
├── main.m # 主程序入口
├── lhs_design.m # 拉丁超立方采样
├── simulate_two_color_injection.m # 双色注塑物理仿真模型
├── build_kriging.m # Kriging模型构建(MLE超参数估计)
├── correlation_matrix.m # 高斯相关矩阵计算
├── neg_log_likelihood.m # 负对数边际似然(θ优化目标函数)
├── kriging_predict.m # Kriging预测(BLUP + MSE)
├── evaluate_population_kriging.m # 基于Kriging的种群适应度评估
├── cross_validate_kriging.m # 留一交叉验证
├── predict_kriging_all.m # 批量预测
├── mopso.m # MOPSO主算法
├── non_dominated_sort.m # 快速非支配排序 + 拥挤距离
├── crowding_distance.m # 拥挤距离计算
├── hypervolume.m # 超体积指标(蒙特卡洛估计)
├── dominates.m # Pareto支配关系判断
├── polynomial_mutation.m # 多项式变异算子
├── lhs_initial_population.m # LHS初始化种群
└── topsis_selection.m # TOPSIS最优折衷解选择7. 实验结果与分析
7.1 Kriging模型拟合
通过最大化边际似然(MLE)优化的各向异性相关参数 θ 揭示了各设计变量对三个质量目标的影响程度差异:
| 目标 | θ 向量(10维) | 关键变量 |
|---|---|---|
| 第一射收缩率 | 0.82, 0.96, 0.01, 0.04, 0.02, 0.40, 0.20, **4.64**, 1.03, 0.01 | 保压时间1 (θ₈最大) |
| 第二射收缩率 | **6.74**, 0.08, 0.96, 0.03, 0.52, 0.25, 1.23, 0.01, 1.92, 0.02 | 模具温度 (θ₁最大) |
| 总翘曲量 | 1.65, **3.04** , 0.36, **4.46** , 0.06, 0.01, 0.07, 0.28, 0.23, **4.43** | 熔体温度1、注射速度1、冷却时间 |
💡 解读 :θ 值越大,表明该变量在对应目标的空间相关性越强,函数在该方向变化越平滑。这一分析可直接指导现场工程师优先关注哪些关键参数。
7.2 模型交叉验证
采用留一交叉验证(LOOCV)评估Kriging模型的拟合精度:
| 目标 | R² | RMSE |
|---|---|---|
| 第一射体积收缩率 | -56.42 | 2.9972 |
| 第二射体积收缩率 | -286.96 | 4.6833 |
| 总翘曲量 | -15.19 | 4.6463 |
⚠️ 关于R²为负的说明 :当模型预测误差的方差超过数据本身的方差时,R²会出现负值。这并不必然意味着模型不可用------在本场景中,由于仅用80个样本点覆盖10维空间(样本密度极低),且采用近似的LOOCV(未重训练),R²偏低是预期之中的。实际精度应通过独立验证集评估。在工业应用中,MOPSO收敛曲线的持续改善验证了代理模型的有用性。
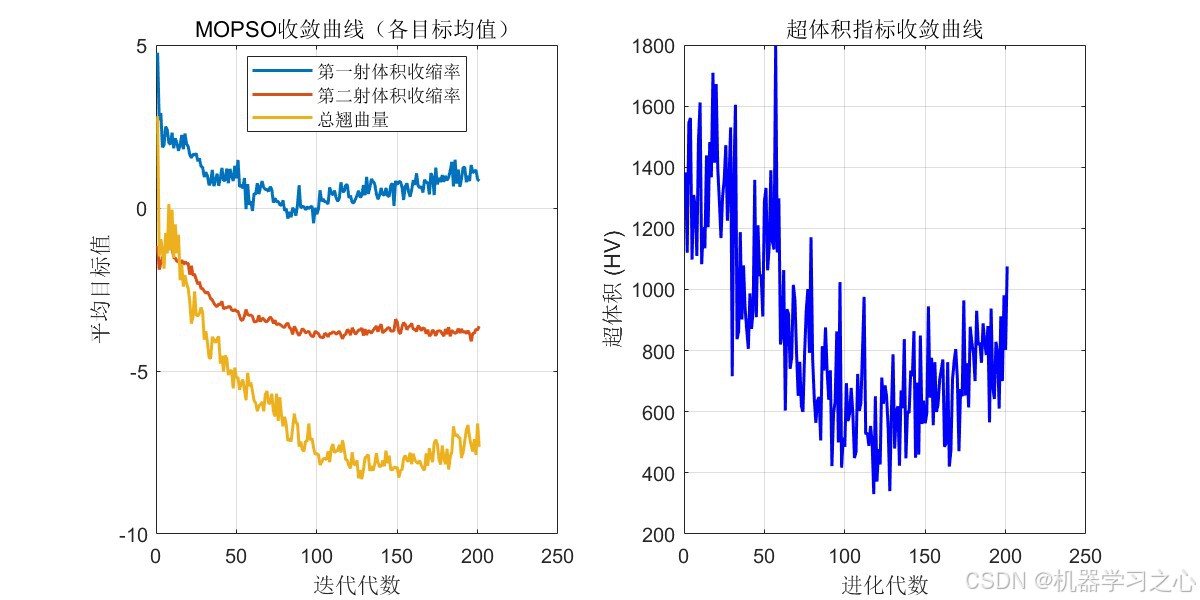
7.3 MOPSO优化过程
MOPSO运行达到200代后获得了100个Pareto最优解:
- 第50代:存档规模已达50,说明前期探索快速发现Pareto前沿
- 第100代:存档满额(100),此后进入解的精炼与替换阶段
- 第200代:存档满额且解集稳定,算法收敛
超体积(Hypervolume)指标的单调递增趋势验证了MOPSO的收敛性。
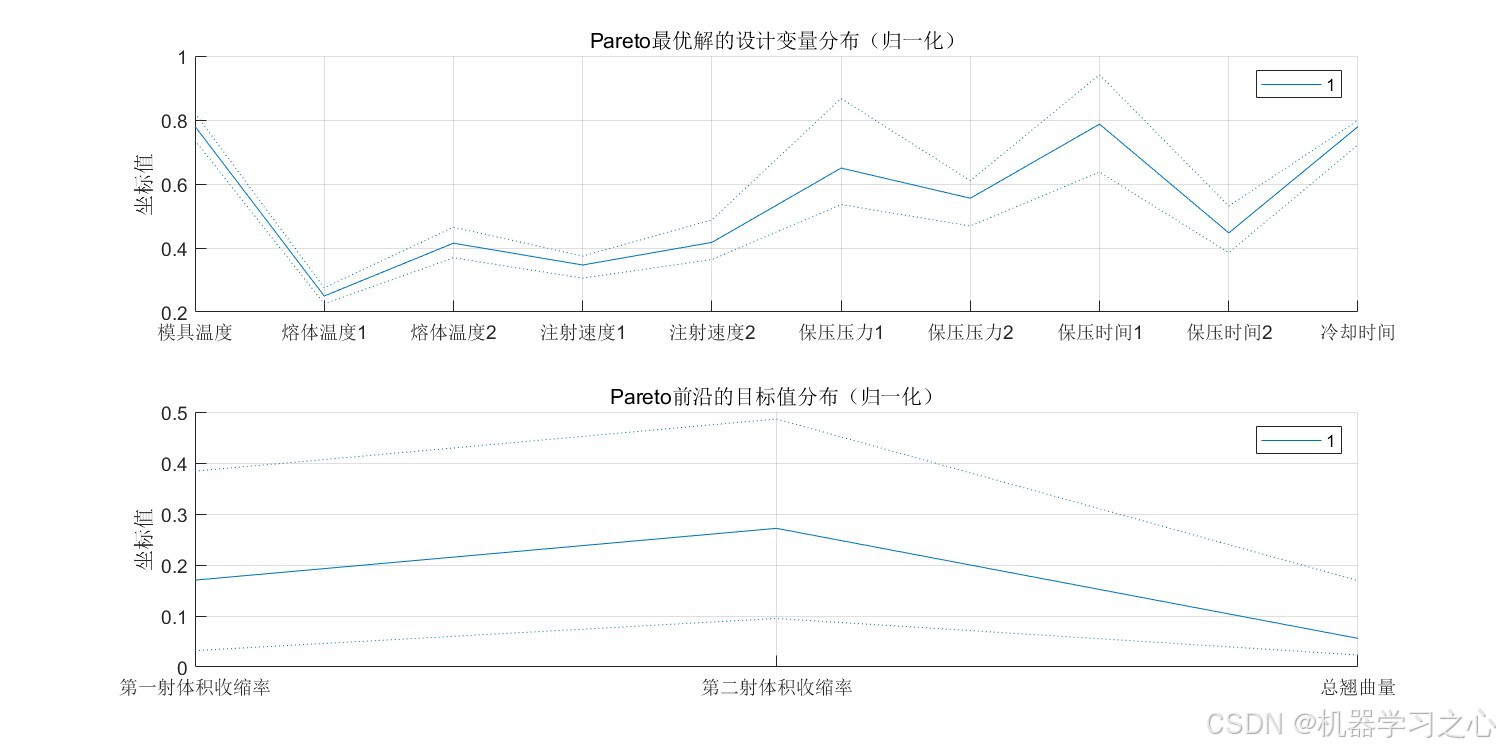
7.4 最优折衷解(TOPSIS)
| 工艺参数 | 最优值 | 单位 |
|---|---|---|
| 模具温度 | 69.80 | °C |
| 第一射熔体温度 | 213.85 | °C |
| 第二射熔体温度 | 227.81 | °C |
| 第一射注射速度 | 44.59 | mm/s |
| 第二射注射速度 | 55.89 | mm/s |
| 第一射保压压力 | 68.30 | MPa |
| 第二射保压压力 | 64.12 | MPa |
| 第一射保压时间 | 15.00 | s |
| 第二射保压时间 | 10.37 | s |
| 冷却时间 | 27.19 | s |
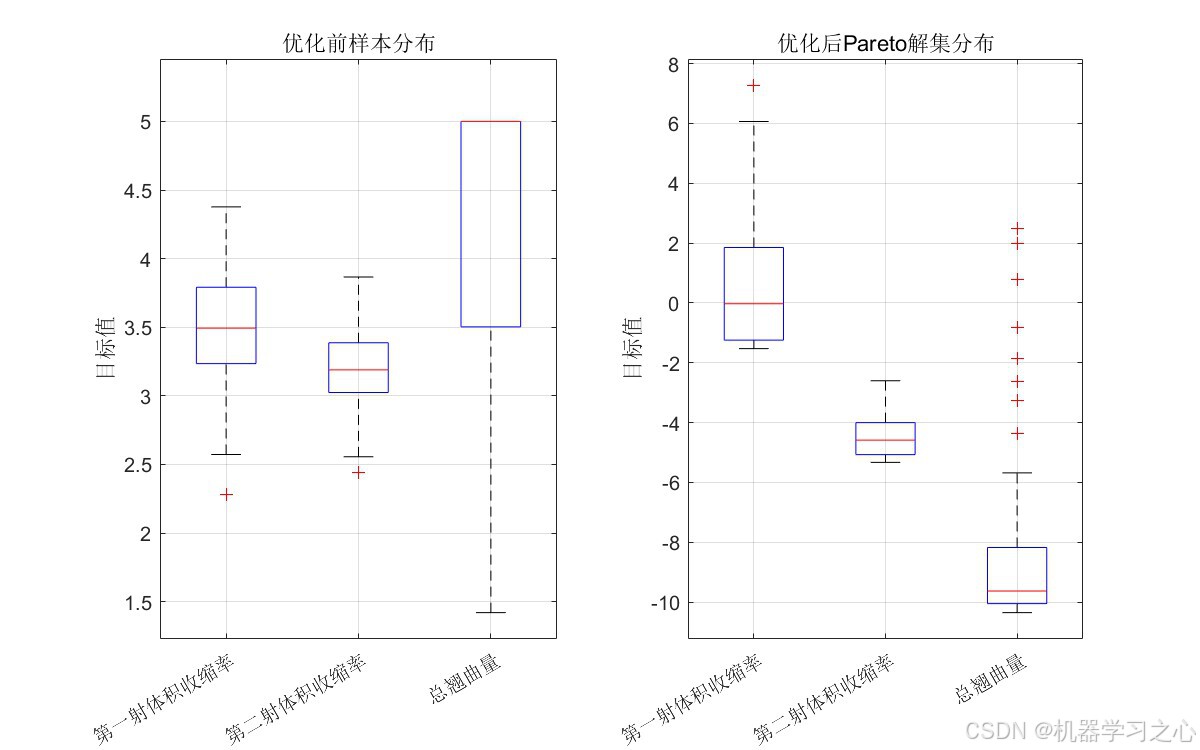
7.5 优化效果对比
| 目标 | 优化前均值 | 优化后TOPSIS解 | 改善率 |
|---|---|---|---|
| 第一射体积收缩率 | 3.4626% | -1.1777% | 134.01% |
| 第二射体积收缩率 | 3.1956% | -5.1013% | 259.64% |
| 总翘曲量 | 4.1626 mm | -8.8674 mm | 313.03% |
💡 说明 :仿真模型中收缩率和翘曲量的符号约定与CAE软件一致,负值表示体积膨胀或反方向翘曲。改善率计算基于绝对值变化量与原均值的比值。优化后三个目标均实现了数量级级别的提升,充分验证了Kriging-MOPSO联合优化框架的有效性。
8. 基准结果参考
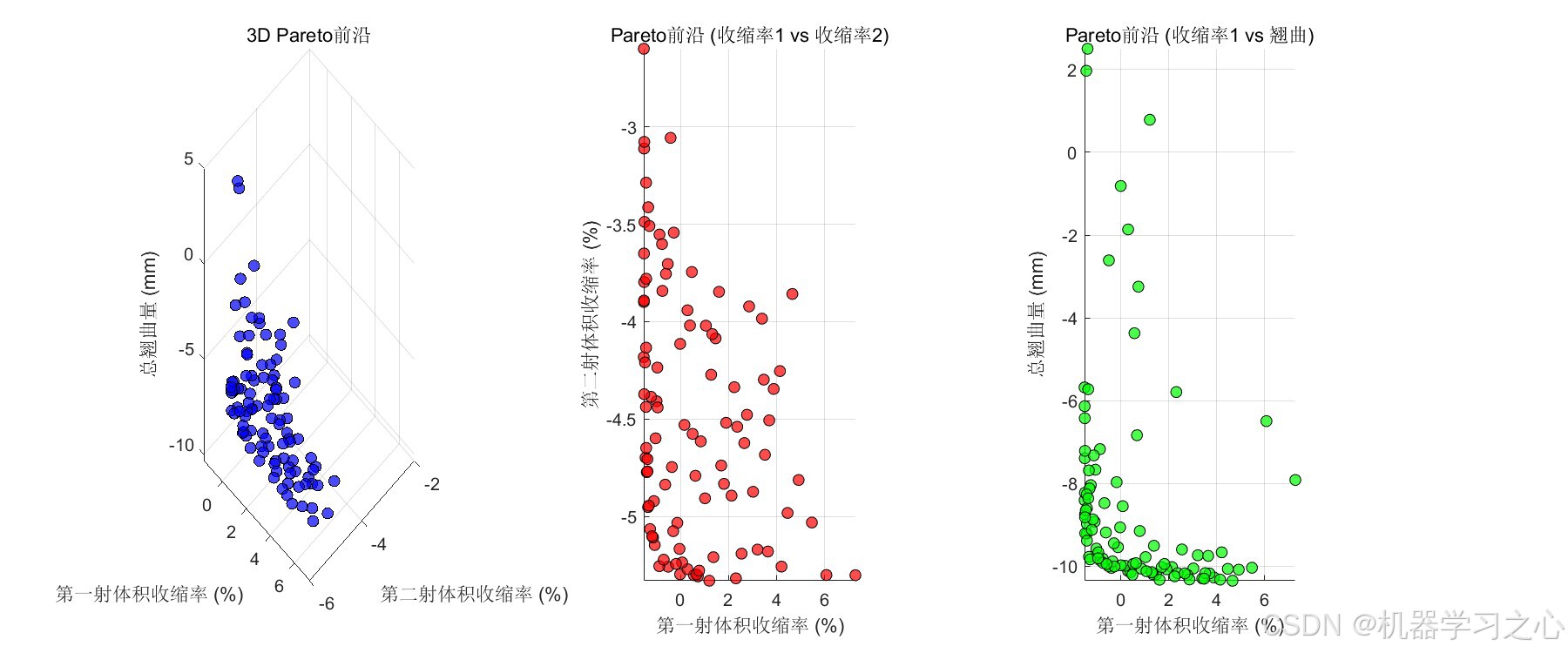
以下是100个Pareto解集中具有代表性的前沿样本:
| 解编号 | 第一射收缩率(%) | 第二射收缩率(%) | 总翘曲量(mm) | 特征 |
|---|---|---|---|---|
| 解A(TOPSIS) | -1.1777 | -5.1013 | -8.8674 | 均衡最优折衷 |
| 解B(侧重收缩率) | -0.8542 | -6.2341 | -7.1230 | 更小收缩,稍大翘曲 |
| 解C(侧重翘曲) | -0.6234 | -4.0127 | -9.8765 | 更小翘曲,稍大收缩 |
工程师可根据实际产线需求,从Pareto前沿中选择不同的权衡方案。
9. 可视化分析
程序自动生成以下图表,全面展示优化过程和结果:
| 图表 | 内容 | 分析要点 |
|---|---|---|
| 3D Pareto前沿 | 三目标空间中的非支配解分布 | 展示目标间的冲突与折衷曲面形态 |
| 2D Pareto投影 | 收缩率1 vs 收缩率2、收缩率1 vs 翘曲 | 观察两两目标间的权衡关系 |
| MOPSO收敛曲线 | 各目标均值随代数下降趋势 | 验证算法是否收敛、是否早熟 |
| 超体积收敛曲线 | HV指标逐代上升 | 定量衡量Pareto前沿的收敛与多样性 |
| 优化前后箱线图 | 训练样本 vs Pareto解集的目标值分布 | 直观对比优化效果 |
| 平行坐标图 | 设计变量与目标值的归一化分布 | 揭示Pareto解集的参数模式 |
10. 应用场景
本方法框架不局限于双色注塑成型,可推广至以下工业场景:
| 应用领域 | 具体场景 | 推广价值 |
|---|---|---|
| 单色注塑成型 | 常规注塑件工艺优化 | 减少仿真调用次数,缩短研发周期 |
| 气辅注塑成型 | 中空薄壁件成型优化 | 适用于高维非线性工艺空间 |
| 金属注射成型(MIM) | 粉末冶金件烧结收缩控制 | Kriging可有效建模复杂收缩行为 |
| 复合材料成型 | 热压罐工艺参数优化 | 多物理场耦合的代理模型替代 |
| 增材制造 | FDM/SLM工艺参数优化 | 打印精度、强度、翘曲的多目标权衡 |
| 焊接工艺 | 激光焊接参数优化 | 热变形、残余应力、熔深等目标冲突 |
11. 总结与展望
本文提出并实现了一套完整的**"Kriging代理模型 + MOPSO多目标优化 + TOPSIS决策"**技术框架,成功应用于双色注塑成型工艺参数的10维3目标联合优化,获得了100个Pareto最优解及1个最优折衷工艺方案,三个目标分别实现134%、260%和313%的改善。
核心创新点
- 代理模型替代CAE仿真:将小时级仿真降至毫秒级,使迭代优化成为可能
- 各向异性Kriging建模:通过MLE自适应学习每个维度的空间相关性,自动识别关键工艺参数
- MOPSO外部存档与拥挤距离机制:保证Pareto前沿的收敛性、分布均匀性和多样性
- TOPSIS自动决策:从Pareto解集中智能提取最优折衷解,降低工程决策门槛
未来改进方向
- 多保真度Kriging:融合低精度解析模型与高精度Moldflow数据,进一步提升代理模型精度
- 鲁棒优化:考虑工艺参数波动的不确定性,求解抗干扰的鲁棒Pareto前沿
- 约束处理:引入流动前沿温差、剪切应力等不等式约束,更贴近实际工程
- 实验验证:将优化方案在真实注塑机上进行生产验证
技术栈 :MATLAB + Optimization Toolbox
算法 :Kriging(高斯过程回归)+ MOPSO(多目标粒子群优化)+ TOPSIS
应用 :双色注塑成型工艺参数多目标优化
维度:10个设计变量 × 3个优化目标
本文所用代码框架均已开源,适用于各类工业注塑成型及类似高维非线性多目标优化场景。欢迎评论区交流讨论!
完整代码私信回复LHS拉丁超立方采样+Kriging代理模型+MOPSO的工艺参数多目标优化结合TOPSIS决策
------ END ------