第1章 RDD概述
1.1 什么是RDD
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象。代码中是一个抽象类,它代表一个弹性的、不可变、可分区、里面的元素可并行计算的集合。
RDD类比工厂生产。
dart
内容和长度都是不可变化的!要修改数据或者加数据进去只能创建新的RDD,RDD的数据是存储在不同计算机的内存中,而Kafka存储在同一计算机的磁盘不同分区。
*** RDD类比工厂生产 ***。
懒加载机制,就是厂长发话才可以运转开干,中间的流程可进行优化,上一个过程结束之后,不存储数据,下一个过程继续,中间车间可以多个,也可以车间合并。
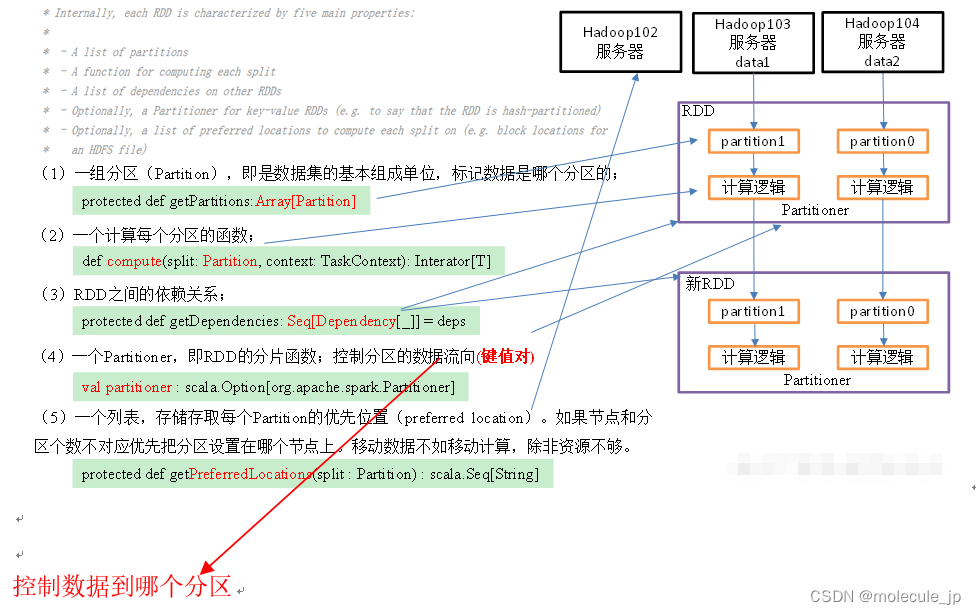
## 1.2 RDD五大特性
# 第2章 RDD编程
## 2.1 RDD的创建
在Spark中创建RDD的创建方式可以分为三种:从集合中创建RDD、从外部存储创建RDD、从其他RDD创建。
2.1.1 IDEA环境准备
1)创建一个maven工程,工程名称叫SparkCore
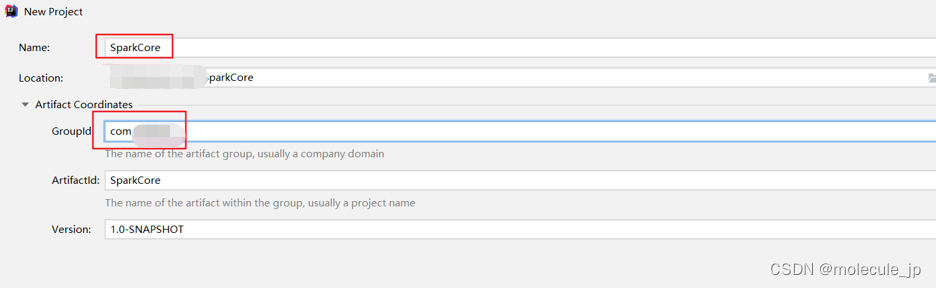
2)创建包名:com.aa.createrdd
3)在pom文件中添加spark-core的依赖
```dart
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.1.3</version>
</dependency>
</dependencies>4)如果不希望运行时打印大量日志,可以在resources文件夹中添加log4j.properties文件,并添加日志配置信息
dart
log4j.rootCategory=ERROR, console
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.target=System.err
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss} %p %c{1}: %m%n
# Set the default spark-shell log level to ERROR. When running the spark-shell, the
# log level for this class is used to overwrite the root logger's log level, so that
# the user can have different defaults for the shell and regular Spark apps.
log4j.logger.org.apache.spark.repl.Main=ERROR
# Settings to quiet third party logs that are too verbose
log4j.logger.org.spark_project.jetty=ERROR
log4j.logger.org.spark_project.jetty.util.component.AbstractLifeCycle=ERROR
log4j.logger.org.apache.spark.repl.SparkIMain$exprTyper=ERROR
log4j.logger.org.apache.spark.repl.SparkILoop$SparkILoopInterpreter=ERROR
log4j.logger.org.apache.parquet=ERROR
log4j.logger.parquet=ERROR
# SPARK-9183: Settings to avoid annoying messages when looking up nonexistent UDFs in SparkSQL with Hive support
log4j.logger.org.apache.hadoop.hive.metastore.RetryingHMSHandler=FATAL
log4j.logger.org.apache.hadoop.hive.ql.exec.FunctionRegistry=ERROR2.1.2 创建IDEA快捷键
1)点击File->Settings...->Editor->Live Templates->output->Live Template


2)点击左下角的Define->选择JAVA

3)在Abbreviation中输入快捷键名称sc,在Template text中填写,输入快捷键后生成的内容。

dart
// 1.创建配置对象
SparkConf conf = new SparkConf().setMaster("local[*]").setAppName("sparkCore");
// 2. 创建sparkContext
JavaSparkContext sc = new JavaSparkContext(conf);
// 3. 编写代码
// 4. 关闭sc
sc.stop();