课程链接:
在【计算机组成 课程笔记】7.1 存储层次结构概况_Elaine_Bao的博客-CSDN博客中提到,因为CPU和内存的速度差距越来越大,使得计算机的性能受到了影响,而高速缓存的出现则挽救了这一局面。这一节我们就来看一下高速缓存是如何工作的。
这是CPU的存储层次结构,高速缓存,也就是Cache,位于CPU和DRAM主存之间,相比于主存,它的容量要小得多,但速度要快得多。
但是为什么在CPU和主存之间增加这么一个速度更快但是容量很小的存储部件,就能提升整个计算机系统的性能呢?这就要得益于计算机中运行程序的一个特点,这个特点被称为程序的局部性原理。

程序的局部性原理
这是一个常见的程序,有两层循环,对一个二维数组进行累加。如果sum这个变量是保存在内存中的,那么这个存储单元就会被不断访问,这就称为时间局部性。类似地,这些对循环变量进行判断条件的指令,和对循环变量递增的指令,也会被反复执行。
另一点叫做空间局部性。指的是正在被访问的存储单元附近单元也很快会被访问。例如,a00附近的a01,a02也会很快被访问。

Cache的基本原理
Cache就是利用了程序的局部性原理设计出来的。
首先我们来看Cache对空间局部性的利用。当CPU要访问主存时,实际上是把地址发给了Cache,最开始Cache里是没有数据的,所以它会再把地址发给主存,再从主存中取得对应的数据。但Cache并不会只取回当前需要的数据,而是会把与这个数据相邻的主存单元的数据一并取回来,这些数据就被称为一个数据块(block)。Cache取回数据块以后存在自己内部,再选出CPU需要的那个数据传给CPU。那过一会CPU很可能就需要刚刚那个数据附近的其他数据,这时候Cache里面已经有了,就可以很快地返回,从而提升访存效率。
再来看一下Cache对时间局部性的利用。因为刚才这个数据块暂时会保存在Cache当中,那CPU如果要再次用到刚才用过的那个存储单元,Cache也可以很快地提供。

这就是Cache对程序局部性的利用。我们要注意,这些操作,都是由硬件完成的,对于软件编程人员来说,他编写的程序代码当中只是访问了主存当中的某个地址,而并不知道这个地址对应的存储单元到底是放在主存当中还是Cache当中。
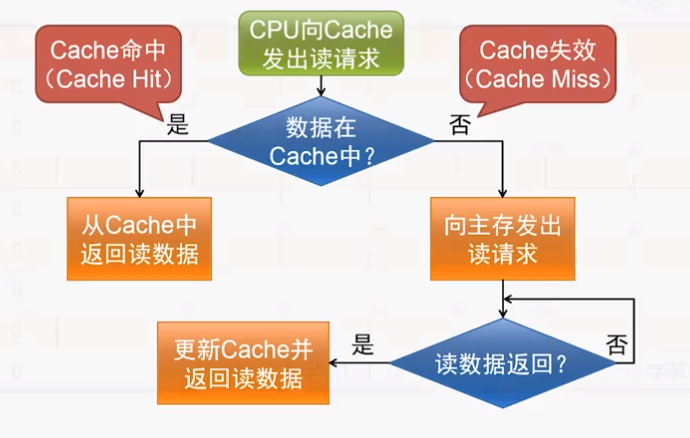
Cache的访问过程
现在CPU放松读请求都是直接发给Cache,Cache这个硬件部件会检查数据是否存在Cache当中,根据是否命中(hit/miss),来决定是否需要向主存发送读请求------这个过程是由Cache发起的,CPU是不知情的,它仍然在等待Cache返回数据。
Cache组织结构示例
Cache的主要组成部件是SRAM,SRAM的组织结构很像这个表格,会分为很多行,每行当中有一个bit是有效位,还有若干bit是标签,其他bit用于存储从主存取回的数据块,这个例子中数据块是16字节。

Cache的读操作
我们来看一个具体的读操作过程示例。假设一开始Cache全是空的,有效位为0代表对应行没有数据。现在我们要来执行这4条指令。

MOV AL, 2011H
第一步,我们要访问2011H这个地址,并取出对应的字节放在AL寄存器中。CPU把2011H这个地址发给Cache,而现在因为Cache全是空的,所以显然没有命中,那么Cache就会向内存发起一次读操作的请求。但我们要注意,因为Cache一次要从内存中读取一个数据块,而现在这个Cache的结构,一个数据块是16字节,所以它发出的地址都是16个字节对齐的,所以它向主存发出的地址是2010H。读回数据块后,分配的Cache Line是第一行(表项1),这时候表项1中的字节0存的是2010H的数据,字节1存的是2011H的数据,所以把字节1的A1H返回给CPU。
那么这里为什么分配的Cache Line是第一行呢?Cache从CPU收到的地址是2011H,而由于Cache是以块为单位进行存储的,所以2011H中的最后一位正好用来表示在这一行中的索引。剩下的倒数第二位则正好可以用于选取Cache Line,在这个例子中这个数是1,所以Cache决定放在表项1中。剩下的还有两位地址20H,则作为标签存储起来。

MOV BL, 4011H
Cache收到4011这个地址后,首先查看表项1是否有数据。有效位是1,说明是有数据的,但是标签对应的是20H,和当前需要的40H不同,所以还是未命中,Cache还是向主存发出访存请求,发出的访存地址是4010H。读回数据以后替换表项1,并将4011H对应的数据B1H返回给CPU,这条指令就完成了。

MOV CL, 3732H
这条指令会去查看Cache中的表项3是否有数据,发现没有数据。接下来的过程和第1条指令类似。

MOV DL, 401FH
Cache首先找到对应的表项1,有效位为1,说明有数据。下一步是比较标签,也是40H,说明是所需要的Cache Line,确认Cache hit。最后再根据最低位F找到对应数据BFH返回给CPU。

现在我们就了解了Cache读操作的几种典型情况:
-
没有命中,且对应表项是空的情况。
-
没有命中,但是对应表项已经被占用的情况。
-
命中了的情况。
那看完了读,我们再来看一下Cache的写操作。
Cache的写策略
当CPU要写一个数据的时候,也会先送到Cache,这时也会有命中和失效两种情况。
当Cache命中时,可以采取的一种写策略是写穿透,即同时写入Cache和主存中,这样能保证数据的一致性,但因为访问主存速度较慢,所以这种写策略效率较低。
所以还可以采用另一种写策略叫做写返回,即数据只写入Cache,只在该数据块被替换时才将数据写入主存。这样的性能显然会好些,因为有可能对同一个单元进行连续多次的写,这样只需要将最后一次写的结果在替换时写回主存就可以了,大大减少了访问主存的次数。但要完成这样的功能,Cache这个部件就会变得复杂得多。
同样的,在Cache失效时,也有两种写策略。一种叫做写不分配,因为Cache失效,要写的那个存储单元不在Cache当中,所以直接写入主存。
另一种策略叫做写分配,就是先将这个数据块读入Cache,然后将数据写入Cache中。写不分配的策略实现简单,但是性能不太好,而写分配的策略虽然第一次操作时复杂一些,要把数据先读到Cache里,但是根据局部性原理,这个数据块后面很可能还会被用到,所以会让后续的访存性能大大提升。

所以在现在Cache的设计中,写穿透和写不分配往往是配套使用的,用于那些对性能要求不高但设计简单的系统,对性能要求较高的,通常使用写返回和写分配这一套组合的策略。
Cache的设计要点
高速缓存是一个非常精细的部件,如果要达到很好的性能,需要在设计时进行仔细的权衡。想要设计出一个优秀的高速缓存,我们需要从几个基本概念入手。
平均访存时间
以下是Cache的访问过程,其中有几个性能指标:命中率,命中时间,失效率和失效代价。

要评价访存的性能,经常会用到平均访存时间这个指标。其计算公式如下:

那么要减少平均访存时间,就有三个途径:
-
降低Hit Time:要求Cache的容量小一点,Cache的结构简单一点
-
减少Miss Penalty:提升主存的性能,或者再增加一层cache
-
降低Miss Rate:增大Cache的容量
可以看出以上三个途径并不是完全独立的,我们先来看一下提高命中率,即降低失效率这个方面。根据上述假设,命中率提升2%可以带来访存效率提升一倍。所以对于Cache来说,能够提升一点点命中率,都能带来很大的性能提升。
Cache失效原因
那么哪些因素会影响命中率呢,或者Cache失效会有哪些原因?
一种原因是义务失效,这个无法避免。第二种是容量失效,可以通过增加Cache容量来缓解,但这一方面增加成本,另一方面也会影响到命中时间,所以也需要综合的考虑。第三种是冲突失效,也就是在Cache并没有满的情况下,由于将多个存储器的位置映射到了同一Cache Line,导致位置上的冲突而带来的失效,我们重点来看看如何解决这个问题。

Cache的映射策略
直接映射
例如,如果有一个8表项的cache,直接映射的情形如图,就相当于将内存中的数据块每8个分为一组,每一组当中的第0个数据块都会被放在Cache的表项0,第1个数据块都会被放在Cache的表项1。

直接映射的优点在于硬件结构简单,只要根据地址就能知道对应的数据块应该放在哪个表项。缺点是如果交替的访问两个数据a,b,而这两个数据对应的数据块恰好被映射到了同一个表项中,那就会一直cache miss,这样的访存性能还不如没有Cache,而这时候其实Cache中的其他表项都是空闲的。
N路组相联
为了解决直接映射的问题,我们可以做一些改进,在不增加cache总的容量的情况下,我们可以将这8个Cache行分为两组,这就是二路组相联的Cache。这样刚才那种交替访问a,b的情况,a可以被放在第一行第一个位置,然后b被放在第一行第二个,之后在访问a,b时都能cache hit。
当然如果CPU在交替访问a,b,c的话,二路组相联就不行了,又会出现连续不命中的情况,所以我们还可以对它进一步切分,如四路组相联。

那我们是不是可以无限切分下去呢?可以是可以,比如对于上述Cache的大小,全部展开可以得到八路组相联,也就是说内存当中任一个数据块都可以放到这个Cache当中的任何一个行中, 而不用通过地址的特征来约定固定放在哪一个行,那这样结构的Cache就叫做全相联的Cache。这样的设计灵活性显然是最高的,但它的控制逻辑也会变得非常复杂,比如假设CPU发来一个地址,Cache要判断这个地址是否在自己内部,对于直接映射的Cache,只需要比较一行的标签就可以了,那在全相联的情况下,它就需要比较所有Cache行的标签。这样的比较需要使用大量的硬件电路,既增加了延迟,又增加了功耗。所以如果划分的路数太多,虽然降低了失效率,但是增加了命中时间,这样就得不偿失了。而且话又说回来,增加了路数,还不一定能够降低失效率,还跟替换策略有关。
Cache替换算法
现在常见的Cache替换算法有这几种。在实际使用中,LRU的性能表现比较好,但其硬件设计也相当的复杂,所以映射策略和替换算法都需要在性能和代价之间进行权衡。

Cache设计实例


