batchsize:中文翻译为批大小(批尺寸)。
简单点说,批量大小将决定我们一次训练的样本数目。
batch_size将影响到模型的优化程度和速度。
为什么需要有 Batch_Size :
batchsize 的正确选择是为了在内存效率和内存容量之间寻找最佳平衡。
Batch_Size的取值:
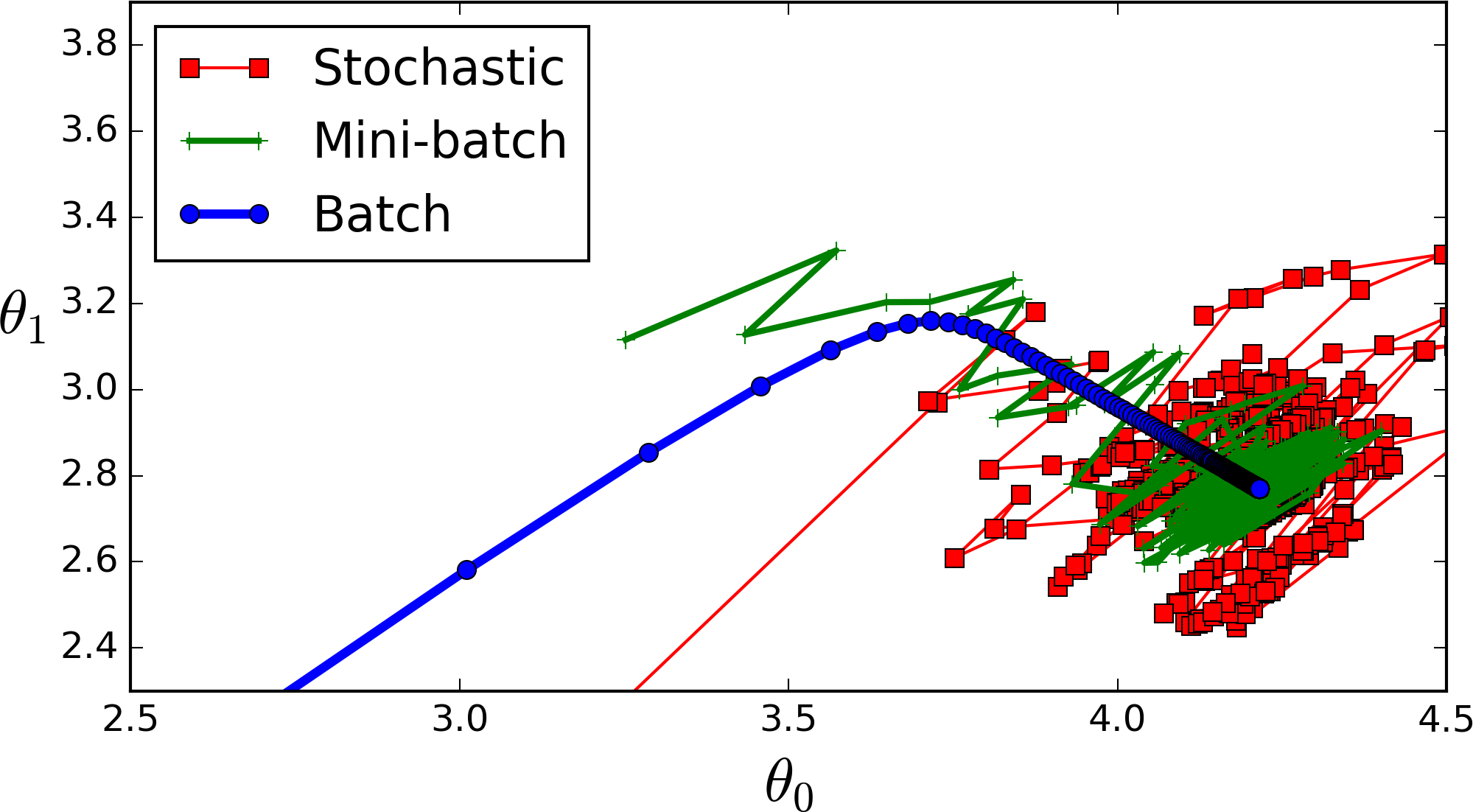
全批次(蓝色)
如果数据集比较小我们就采用全数据集。全数据集确定的方向能够更好地代表样本总体,从而更准确地朝向极值所在的方向。
注:对于大的数据集我们不能使用全批次,因为会得到更差的结果。
迷你批次(绿色)
选择一个适中的 Batch_Size 值。就是说我们选定一个batch的大小后,将会以batch的大小将数据输入深度学习的网络中,然后计算这个batch的所有样本的平均损失,即代价函数是所有样本的平均。
随机(batch_size等于1的情况)(红色)
每次修正方向以各自样本的梯度方向修正,横冲直撞各自为政,难以达到收敛。
适当的增加Batchsize 的优点:
1.通过并行化提高内存利用率。
2.单次epoch的迭代次数减少,提高运行速度。(单次epoch=(全部训练样本/batchsize) / iteration =1)
3.适当的增加Batch_Size,梯度下降方向准确度增加,训练震动的幅度减小。(看上图便可知晓)
经验总结:
相对于正常数据集,如果Batch_Size过小,训练数据就会非常难收敛,从而导致underfitting。
增大Batch_Size,相对处理速度加快。
增大Batch_Size,所需内存容量增加(epoch的次数需要增加以达到最好结果)。
这里我们发现上面两个矛盾的问题,因为当epoch增加以后同样也会导致耗时增加从而速度下降。因此我们需要寻找最好的batch_size。
再次重申:batchsize 的正确选择是为了在内存效率和内存容量之间寻找最佳平衡。
Iteration: 中文翻译为迭代。
迭代是重复 反馈的动作,神经网络中我们希望通过迭代进行多次的训练以到达所需的目标或结果。
++每一次迭代得到的结果都会被作为下一次迭代的初始值。++
一个迭代 = 一个正向通过+一个反向通过
epoch:中文翻译为时期。
一个时期 = 所有训练样本的一个正向传递和一个反向传递。