
著名: 本文是从 Michael Nielsen的电子书Neural Network and Deep Learning的深度学习那一章的卷积神经网络的参数优化方法的一些总结和摘录,并不是我自己的结论和做实验所得到的结果。我想Michael的实验结果更有说服力一些。本书在github上有中文翻译的版本,
前言
最近卷积神经网络(CNN)很火热,它在图像分类领域的卓越表现引起了大家的广泛关注。本文总结和摘录了Michael Nielsen的那本Neural Network and Deep Learning一书中关于深度学习一章中关于提高泛化能力的一些概述和实验结果。力争用数据给大家一个关于正则化,增加卷积层/全连接数,弃权技术,拓展训练集等参数优化方法的效果。
本文并不会介绍正则化,弃权(Dropout), 池化等方法的原理,只会介绍它们在实验中的应用或者起到的效果,更多的关于这些方法的解释请自行查询。
mnist数据集介绍
本文的实验是基于mnist数据集合的,mnist是一个从0到9的手写数字集合,共有60,000张训练图片,10,000张测试图片。每张图片大小是28*28大小。我们的实验就是构建一个神经网络来高精度的分类图片,也就是提高泛化能力。
 提高泛化能力的方法
提高泛化能力的方法
一般来说,提高泛化能力的方法主要有以下几个:
- 正则化
- 增加神经网络层数
- 使用正确的代价函数
- 使用好的权重初始化技术
- 人为拓展训练集
- 弃权技术
下面我们通过实验结果给这些参数优化理论一个直观的结果
1. 普通的全连接神经网络的效果
我们使用一个隐藏层,包含100个隐藏神经元,输入层是784,输出层是one-hot编码的形式,最后一层是Softmax层。训练过程采用对数似然代价函数,60次迭代,学习速率η=0.1,随机梯度下降的小批量数据大小为10,没有正则化。在测试集上得到的结果是97.8%,代码如下:
* >>> import network3
* >>> from network3 import Network
* >>> from network3 import ConvPoolLayer, FullyConnectedLayer, SoftmaxLayer
* >>> training_data, validation_data, test_data = network3.load_data_shared()
* >>> mini_batch_size = 10
* >>> net = Network([
* FullyConnectedLayer(n_in=784, n_out=100),
* SoftmaxLayer(n_in=100, n_out=10)], mini_batch_size)
* >>> net.SGD(training_data, 60, mini_batch_size, 0.1,
* validation_data, test_data)
2.使用卷积神经网络 --- 仅一个卷积层
输入层是卷积层,5*5的局部感受野,也就是一个5*5的卷积核,一共20个特征映射。最大池化层选用2*2的大小。后面是100个隐藏神经元的全连接层。结构如图所示
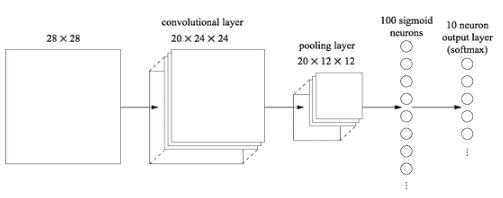 在这个架构中,我们把卷积层和chihua层看做是学习输入训练图像中的局部感受野,而后的全连接层则是一个更抽象层次的学习,从整个图像整合全局信息。也是60次迭代,批量数据大小是10,学习率是0.1.代码如下,
在这个架构中,我们把卷积层和chihua层看做是学习输入训练图像中的局部感受野,而后的全连接层则是一个更抽象层次的学习,从整个图像整合全局信息。也是60次迭代,批量数据大小是10,学习率是0.1.代码如下,
* >>> net = Network([
* ConvPoolLayer(image_shape=(mini_batch_size, 1, 28, 28),
* filter_shape=(20, 1, 5, 5),
* poolsize=(2, 2)),
* FullyConnectedLayer(n_in=20*12*12, n_out=100),
* SoftmaxLayer(n_in=100, n_out=10)], mini_batch_size)
* >>> net.SGD(training_data, 60, mini_batch_size, 0.1,
* validation_data, test_data)
经过三次运行取平均后,准确率是98.78%,这是相当大的改善。错误率降低了1/3,。卷积神经网络开始显现威力。
3.使用卷积神经网络 --- 两个卷积层
我们接着插入第二个卷积-混合层,把它插入在之前的卷积-混合层和全连接层之间,同样的5*5的局部感受野,2*2的池化层。
* >>> net = Network([
* ConvPoolLayer(image_shape=(mini_batch_size, 1, 28, 28),
* filter_shape=(20, 1, 5, 5),
* poolsize=(2, 2)),
* ConvPoolLayer(image_shape=(mini_batch_size, 20, 12, 12),
* filter_shape=(40, 20, 5, 5),
* poolsize=(2, 2)),
* FullyConnectedLayer(n_in=40*4*4, n_out=100),
* SoftmaxLayer(n_in=100, n_out=10)], mini_batch_size)
* >>> net.SGD(training_data, 60, mini_batch_size, 0.1,
* validation_data, test_data)
这一次,我们拥有了99.06%的准确率。
4.使用卷积神经网络 --- 两个卷积层+线性修正单元(ReLU)+正则化
上面我们使用的Sigmod激活函数,现在我们换成线性修正激活函数ReLU
f(z)=max(0,z),我们选择60个迭代期,学习速率η=0.03, ,使用L2正则化,正则化参数λ=0.1,代码如下
* >>> from network3 import ReLU
* >>> net = Network([
* ConvPoolLayer(image_shape=(mini_batch_size, 1, 28, 28),
* filter_shape=(20, 1, 5, 5),
* poolsize=(2, 2),
* activation_fn=ReLU),
* ConvPoolLayer(image_shape=(mini_batch_size, 20, 12, 12),
* filter_shape=(40, 20, 5, 5),
* poolsize=(2, 2),
* activation_fn=ReLU),
* FullyConnectedLayer(n_in=40*4*4, n_out=100, activation_fn=ReLU),
* SoftmaxLayer(n_in=100, n_out=10)], mini_batch_size)
* >>> net.SGD(training_data, 60, mini_batch_size, 0.03,
* validation_data, test_data, lmbda=0.1)
这一次,我们获得了99.23%的准确率,超过了S型激活函数的99.06%. ReLU的优势是max(0,z)中z取最大极限时不会饱和,不像是S函数,这有助于持续学习。
5.使用卷积神经网络 --- 两个卷基层+线性修正单元(ReLU)+正则化+拓展数据集
拓展训练集数据的一个简单方法是将每个训练图像由一个像素来代替,无论是上一个像素,下一个像素,或者左右的像素。其他的方法也有改变亮度,改变分辨率,图片旋转,扭曲,位移等。
我们把50,000幅图像人为拓展到250,000幅图像。使用第4节一样的网络,因为我们是在训练5倍的数据,所以减少了过拟合的风险。
* >>> expanded_training_data, _, _ = network3.load_data_shared(
* "../data/mnist_expanded.pkl.gz")
* >>> net = Network([
* ConvPoolLayer(image_shape=(mini_batch_size, 1, 28, 28),
* filter_shape=(20, 1, 5, 5),
* poolsize=(2, 2),
* activation_fn=ReLU),
* ConvPoolLayer(image_shape=(mini_batch_size, 20, 12, 12),
* filter_shape=(40, 20, 5, 5),
* poolsize=(2, 2),
* activation_fn=ReLU),
* FullyConnectedLayer(n_in=40*4*4, n_out=100, activation_fn=ReLU),
* SoftmaxLayer(n_in=100, n_out=10)], mini_batch_size)
* >>> net.SGD(expanded_training_data, 60, mini_batch_size, 0.03,
* validation_data, test_data, lmbda=0.1)
这次的到了99.37的训练正确率。
6.使用卷积神经网络 --- 两个卷基层+线性修正单元(ReLU)+正则化+拓展数据集+继续插入额外的全连接层
继续上面的网络,我们拓展全连接层的规模,300个隐藏神经元和1000个神经元的额精度分别是99.46%和99.43%.
我们插入一个额外的全连接层
* >>> net = Network([
* ConvPoolLayer(image_shape=(mini_batch_size, 1, 28, 28),
* filter_shape=(20, 1, 5, 5),
* poolsize=(2, 2),
* activation_fn=ReLU),
* ConvPoolLayer(image_shape=(mini_batch_size, 20, 12, 12),
* filter_shape=(40, 20, 5, 5),
* poolsize=(2, 2),
* activation_fn=ReLU),
* FullyConnectedLayer(n_in=40*4*4, n_out=100, activation_fn=ReLU),
* FullyConnectedLayer(n_in=100, n_out=100, activation_fn=ReLU),
* SoftmaxLayer(n_in=100, n_out=10)], mini_batch_size)
* >>> net.SGD(expanded_training_data, 60, mini_batch_size, 0.03,
* validation_data, test_data, lmbda=0.1)
这次取得了99.43%的精度。拓展后的网络并没有帮助太多。
7.使用卷积神经网络 --- 两个卷基层+线性修正单元(ReLU)+拓展数据集+继续插入额外的全连接层+弃权技术
弃权的基本思想就是在训练网络时随机的移除单独的激活值,使得模型对单独的依据丢失更为强劲,因此不太依赖于训练数据的特质。我们尝试应用弃权技术到最终的全连接层(不是在卷基层)。这里,减少了迭代期的数量为40个,全连接层使用1000个隐藏神经元,因为弃权技术会丢弃一些神经元。Dropout是一种非常有效有提高泛化能力,降低过拟合的方法!
* >>> net = Network([
* ConvPoolLayer(image_shape=(mini_batch_size, 1, 28, 28),
* filter_shape=(20, 1, 5, 5),
* poolsize=(2, 2),
* activation_fn=ReLU),
* ConvPoolLayer(image_shape=(mini_batch_size, 20, 12, 12),
* filter_shape=(40, 20, 5, 5),
* poolsize=(2, 2),
* activation_fn=ReLU),
* FullyConnectedLayer(
* n_in=40*4*4, n_out=1000, activation_fn=ReLU, p_dropout=0.5),
* FullyConnectedLayer(
* n_in=1000, n_out=1000, activation_fn=ReLU, p_dropout=0.5),
* SoftmaxLayer(n_in=1000, n_out=10, p_dropout=0.5)],
* mini_batch_size)
* >>> net.SGD(expanded_training_data, 40, mini_batch_size, 0.03,
* validation_data, test_data)
使用弃权技术,的到了99.60%的准确率。
8.使用卷积神经网络 --- 两个卷基层+线性修正单元(ReLU)+正则化+拓展数据集+继续插入额外的全连接层+弃权技术+组合网络
组合网络类似于随机森林或者adaboost的集成方法,创建几个神经网络,让他们投票来决定最好的分类。我们训练了5个不同的神经网络,每个都大到了99.60%的准去率,用这5个网络来进行投票表决一个图像的分类。
采用这个方法,达到了99.67%的准确率。
总结
卷积神经网络 的一些技巧总结如下:
-
使用卷积层极大地减小了全连接层中的参数的数目,使学习的问题更容易
-
使用更多强有力的规范化技术(尤其是弃权和卷积)来减小过度拟合,
-
使用修正线性单元而不是S型神经元,来加速训练-依据经验,通常是3-5倍,
-
使用GPU来计算
-
利用充分大的数据集,避免过拟合
-
使用正确的代价函数,避免学习减速
-
使用好的权重初始化,避免因为神经元饱和引起的学习减速