视频分类模型简介
X3D 系列模型
官方网站
https://github.com/facebookresearch/SlowFast
提出论文
Facebook Research 的《X3D: Expanding Architectures for Efficient Video Recognition》
https://arxiv.org/pdf/2004.04730
原理
X3D 的设计思路受到机器学习中特征选择方法的启发,它基于 X2D 图像分类模型,通过一种逐步扩展的方式,将 2D 空间建模拓展为 3D 时空建模。具体来说,X3D 在网络的宽度、深度、帧率、帧数和分辨率等维度上,依次只对单一维度进行扩展,并在每一步中综合考虑计算量与精度表现,从而选择最优的扩展策略。
X3D通过6个轴来对X2D进行拓展,X2D在这6个轴上都为1。
拓张维度
|------------------|------------------|--------------------------------|
| 维度 | 物理意义 | 优化影响 |
| X-Temporal | 采样帧数(视频片段长度) | 增强长时序上下文感知能力(如手势识别) |
| X-Fast | 帧率(采样间隔缩短) | 提升时间分辨率,优化快速捕捉(如体育动作分解) |
| X-Spatial | 输入空间分辨率(112→224) | 提升细节识别能力(需同步增加网络深度以扩大感受野) |
| X-Depth | 网络层数(ResNet阶段数) | 增强特征抽象能力,匹配高分辨率输入要求 |
| X-Width | 通道数 | 提升特征表达能力(计算量≈通道数²×分辨率²) |
| X-Bottleneck | Bottleneck层通道宽度 | 优化计算效率:扩展内部通道可平衡精度与计算量(优于全局加宽) |
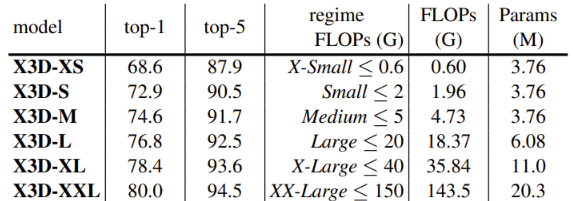
模型结果指标和参数量
数据准备
数据集根目录/
├── train/ # 训练集
│ ├── flow/ # 类别1(正常视频流)
│ │ ├── video1.mp4
│ │ └── video2.avi
│ └── freeze/ # 类别2(视频冻结)
│ ├── video3.mp4
│ └── video4.mov
└── val/ # 验证集
├── flow/
│ ├── video5.mp4
│ └── video6.avi
└── freeze/
├── video7.mp4
└── video8.mkv
训练代码
import os
import sys
import time
import copy
import argparse
import random
import warnings
from pathlib import Path
from typing import List, Tuple
import numpy as np
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader, WeightedRandomSampler
from torchvision.io import read_video
from torchvision.transforms import functional as TF
# --------------------------- 工具 ---------------------------
def set_seed(seed: int = 42):
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
def list_videos(root: Path, exts=(".mp4", ".avi", ".mov", ".mkv")) -> List[Path]:
files = []
for ext in exts:
files += list(root.rglob(f"*{ext}"))
return sorted(files)
def count_labels(samples: List[Tuple[Path, int]], num_classes: int = 2):
counts = [0] * num_classes
for _, y in samples:
counts[y] += 1
return counts
# --------------------------- 数据集 ---------------------------
class VideoFolderDataset(Dataset):
"""
读取 root/{split}/{class}/*.mp4
- 均匀采样 T 帧(不足补尾帧)
- 训练:随机短边缩放、随机裁剪、概率翻转
验证:短边定值、中心裁剪
- 输出 (C,T,H,W) float32,[0,1] 标准化(Kinetics 统计)
"""
def __init__(
self,
root: str,
split: str = "train",
classes: Tuple[str, str] = ("flow", "freeze"),
frames: int = 16,
short_side: int = 256,
crop_size: int = 224,
mean: Tuple[float, float, float] = (0.45, 0.45, 0.45),
std: Tuple[float, float, float] = (0.225, 0.225, 0.225),
allow_corrupt_skip: bool = True,
train_scale_jitter: Tuple[float, float] = (0.8, 1.2),
hflip_prob: float = 0.5,
):
super().__init__()
self.root = Path(root)
self.split = split
self.frames = frames
self.short_side = short_side
self.crop_size = crop_size
self.mean = torch.tensor(mean).view(3, 1, 1, 1)
self.std = torch.tensor(std).view(3, 1, 1, 1)
self.classes = tuple(sorted(classes))
self.class_to_idx = {c: i for i, c in enumerate(self.classes)}
self.allow_corrupt_skip = allow_corrupt_skip
self.train_scale_jitter = train_scale_jitter
self.hflip_prob = hflip_prob if split == "train" else 0.0
self.samples: List[Tuple[Path, int]] = []
for c in self.classes:
cdir = self.root / split / c
vids = list_videos(cdir)
for v in vids:
self.samples.append((v, self.class_to_idx[c]))
if len(self.samples) == 0:
raise FileNotFoundError(f"No videos found in {self.root}/{split}/({self.classes}).")
if self.allow_corrupt_skip:
keep = []
for p, y in self.samples:
try:
vframes, _, _ = read_video(str(p), pts_unit="sec", output_format="TCHW", start_pts=0, end_pts=0.1)
if vframes.numel() == 0:
continue
keep.append((p, y))
except Exception:
print(f"⚠️ 跳过无法读取的视频: {p}")
if keep:
self.samples = keep
self.label_counts = count_labels(self.samples, num_classes=len(self.classes))
def __len__(self):
return len(self.samples)
@staticmethod
def _uniform_indices(total: int, num: int) -> np.ndarray:
if total <= 0:
return np.zeros((num,), dtype=np.int64)
if total >= num:
idx = np.linspace(0, total - 1, num=num)
return np.round(idx).astype(np.int64)
else:
base = list(range(total))
base += [total - 1] * (num - total)
return np.array(base, dtype=np.int64)
def _load_video_tensor(self, path: Path) -> torch.Tensor:
vframes, _, _ = read_video(str(path), pts_unit="sec", output_format="TCHW")
if vframes.numel() == 0:
raise RuntimeError("Empty video tensor.")
if vframes.shape[1] == 1:
vframes = vframes.repeat(1, 3, 1, 1)
return vframes # (T,C,H,W)
def __getitem__(self, idx: int):
path, label = self.samples[idx]
try:
v = self._load_video_tensor(path)
except Exception:
if self.allow_corrupt_skip:
new_idx = random.randint(0, len(self.samples) - 1)
path, label = self.samples[new_idx]
v = self._load_video_tensor(path)
else:
raise
T, C, H, W = v.shape
# 均匀采样 frames 帧
idxs = self._uniform_indices(T, self.frames)
v = v[idxs]
if self.split == "train":
scale = random.uniform(self.train_scale_jitter[0], self.train_scale_jitter[1])
target_ss = max(64, int(self.short_side * scale))
v = TF.resize(v, target_ss, antialias=True)
_, _, H2, W2 = v.shape
if H2 < self.crop_size or W2 < self.crop_size:
min_ss = max(self.crop_size, min(H2, W2))
v = TF.resize(v, min_ss, antialias=True)
_, _, H2, W2 = v.shape
top = random.randint(0, H2 - self.crop_size)
left = random.randint(0, W2 - self.crop_size)
v = TF.crop(v, top, left, self.crop_size, self.crop_size)
if random.random() < self.hflip_prob:
v = torch.flip(v, dims=[-1])
else:
v = TF.resize(v, self.short_side, antialias=True)
v = TF.center_crop(v, [self.crop_size, self.crop_size])
v = v.permute(1, 0, 2, 3).contiguous() # (C,T,H,W)
v = v.float() / 255.0
v = (v - self.mean) / self.std
return v, torch.tensor(label, dtype=torch.long)
# --------------------------- 模型构建(含预训练) ---------------------------
def build_model(arch: str, frames: int, crop_size: int, num_classes: int = 2, pretrained: bool = True) -> nn.Module:
arch = arch.lower()
if arch in {"x3d_s", "x3d_m"}:
model = torch.hub.load('facebookresearch/pytorchvideo', arch, pretrained=pretrained)
if hasattr(model.blocks[-1], "proj") and isinstance(model.blocks[-1].proj, nn.Linear):
in_feats = model.blocks[-1].proj.in_features
model.blocks[-1].proj = nn.Linear(in_feats, num_classes)
else:
head = model.blocks[-1]
proj = None
for _, m in head.named_modules():
if isinstance(m, nn.Linear):
proj = m; break
if proj is None:
raise RuntimeError("未找到X3D分类头线性层,请升级 pytorchvideo 或改用 torchvision 模型。")
in_feats = proj.in_features
model.blocks[-1].proj = nn.Linear(in_feats, num_classes)
return model
elif arch in {"r2plus1d_18", "r3d_18"}:
from torchvision.models.video import r2plus1d_18, r3d_18
from torchvision.models.video import R2Plus1D_18_Weights, R3D_18_Weights
if arch == "r2plus1d_18":
weights = R2Plus1D_18_Weights.KINETICS400_V1 if pretrained else None
model = r2plus1d_18(weights=weights)
else:
weights = R3D_18_Weights.KINETICS400_V1 if pretrained else None
model = r3d_18(weights=weights)
in_feats = model.fc.in_features
model.fc = nn.Linear(in_feats, num_classes)
return model
else:
raise ValueError(f"未知 arch: {arch}. 可选: x3d_s, x3d_m, r2plus1d_18, r3d_18")
def set_backbone_trainable(model: nn.Module, trainable: bool, arch: str):
for p in model.parameters():
p.requires_grad = trainable
if arch.startswith("x3d"):
for p in model.blocks[-1].parameters():
p.requires_grad = True
else:
for p in model.fc.parameters():
p.requires_grad = True
def get_head_parameters(model: nn.Module, arch: str):
return list(model.blocks[-1].parameters()) if arch.startswith("x3d") else list(model.fc.parameters())
# --------------------------- EMA / TTA / Metrics ---------------------------
class ModelEMA:
"""Exponential Moving Average of model parameters."""
def __init__(self, model: nn.Module, decay: float = 0.999):
self.ema = copy.deepcopy(model).eval()
for p in self.ema.parameters():
p.requires_grad_(False)
self.decay = decay
@torch.no_grad()
def update(self, model: nn.Module):
d = self.decay
msd = model.state_dict()
esd = self.ema.state_dict()
for k in esd.keys():
v = esd[k]
mv = msd[k]
if isinstance(v, torch.Tensor) and v.dtype.is_floating_point:
esd[k].mul_(d).add_(mv.detach(), alpha=1 - d)
else:
esd[k].copy_(mv)
@torch.no_grad()
def _forward_with_tta(model: nn.Module, x: torch.Tensor, tta_flip: bool):
logits = model(x)
if tta_flip:
x_flip = torch.flip(x, dims=[-1])
logits = logits + model(x_flip)
logits = logits / 2.0
return logits
@torch.no_grad()
def evaluate(model: nn.Module, loader: DataLoader, device: str = "cuda", tta_flip: bool = False):
model.eval()
total, correct, loss_sum = 0, 0, 0.0
criterion = nn.CrossEntropyLoss()
amp_ctx = torch.amp.autocast(device_type='cuda', dtype=torch.float16, enabled=(device == "cuda"))
for x, y in loader:
x = x.to(device, non_blocking=True).float()
y = y.to(device, non_blocking=True)
with amp_ctx:
logits = _forward_with_tta(model, x, tta_flip)
loss = criterion(logits, y)
loss_sum += loss.item() * y.size(0)
pred = logits.argmax(dim=1)
correct += (pred == y).sum().item()
total += y.size(0)
return correct / max(1, total), loss_sum / max(1, total)
@torch.no_grad()
def evaluate_detailed(model: nn.Module, loader: DataLoader, device: str = "cuda", tta_flip: bool = False):
"""返回详细指标并打印:混淆矩阵/各类P/R/F1;扫描阈值优化freeze的F1与Balanced Acc。"""
model.eval()
all_probs1, all_labels = [], []
amp_ctx = torch.amp.autocast(device_type='cuda', dtype=torch.float16, enabled=(device == "cuda"))
for x, y in loader:
x = x.to(device, non_blocking=True).float()
with amp_ctx:
logits = _forward_with_tta(model, x, tta_flip)
probs = torch.softmax(logits.float(), dim=1)
all_probs1.append(probs[:, 1].cpu())
all_labels.append(y)
p1 = torch.cat(all_probs1).numpy()
y_true = torch.cat(all_labels).numpy().astype(int)
def metrics_at(th):
y_pred = (p1 >= th).astype(int)
tp = int(((y_true == 1) & (y_pred == 1)).sum())
tn = int(((y_true == 0) & (y_pred == 0)).sum())
fp = int(((y_true == 0) & (y_pred == 1)).sum())
fn = int(((y_true == 1) & (y_pred == 0)).sum())
acc = (tp + tn) / max(1, len(y_true))
prec1 = tp / max(1, tp + fp)
rec1 = tp / max(1, tp + fn)
f1_1 = 2 * prec1 * rec1 / max(1e-12, (prec1 + rec1))
prec0 = tn / max(1, tn + fn)
rec0 = tn / max(1, tn + fp)
f1_0 = 2 * prec0 * rec0 / max(1e-12, (prec0 + rec0))
bal_acc = 0.5 * (rec0 + rec1)
cm = np.array([[tn, fp],
[fn, tp]], dtype=int)
return acc, bal_acc, (prec0, rec0, f1_0), (prec1, rec1, f1_1), cm
# 0.5 默认与最佳阈值
acc50, bal50, cls0_50, cls1_50, cm50 = metrics_at(0.5)
best_f1_th, best_f1 = 0.5, -1
best_bal_th, best_bal = 0.5, -1
for th in np.linspace(0.05, 0.95, 91):
acc, bal, _, cls1, _ = metrics_at(th)
f1 = cls1[2]
if f1 > best_f1:
best_f1, best_f1_th = f1, th
if bal > best_bal:
best_bal, best_bal_th = bal, th
print("== Detailed Validation Metrics ==")
print(f"Default th=0.50 | Acc={acc50:.4f} | BalancedAcc={bal50:.4f} | "
f"Class0(P/R/F1)={cls0_50[0]:.3f}/{cls0_50[1]:.3f}/{cls0_50[2]:.3f} | "
f"Class1(P/R/F1)={cls1_50[0]:.3f}/{cls1_50[1]:.3f}/{cls1_50[2]:.3f}")
print(f"Confusion Matrix @0.50 (rows=true [0,1]; cols=pred [0,1]):\n{cm50}")
print(f"Best F1(freeze=1) th={best_f1_th:.2f} | F1={best_f1:.4f}")
print(f"Best Balanced Acc th={best_bal_th:.2f} | BalancedAcc={best_bal:.4f}")
return {
"acc@0.5": acc50,
"balanced@0.5": bal50,
"cm@0.5": cm50,
"best_f1_th": best_f1_th,
"best_bal_th": best_bal_th,
}
# --------------------------- 训练主函数 ---------------------------
def main():
warnings.filterwarnings("once", category=UserWarning)
parser = argparse.ArgumentParser()
parser.add_argument("--root", type=str, required=True, help="数据根目录,包含 train/ val/")
parser.add_argument("--epochs", type=int, default=30)
parser.add_argument("--freeze_epochs", type=int, default=3, help="线性探测epoch数,仅训分类头")
parser.add_argument("--batch", type=int, default=8)
parser.add_argument("--frames", type=int, default=16)
parser.add_argument("--size", type=int, default=224)
parser.add_argument("--short_side", type=int, default=256)
parser.add_argument("--arch", type=str, default="x3d_m", choices=["x3d_s","x3d_m","r2plus1d_18","r3d_18"])
parser.add_argument("--pretrained", type=int, default=1, help="是否使用预训练权重(1/0)")
parser.add_argument("--lr", type=float, default=3e-4)
parser.add_argument("--lr_head_mul", type=float, default=10.0, help="分类头学习率倍率")
parser.add_argument("--wd", type=float, default=1e-4)
parser.add_argument("--warmup", type=int, default=2, help="warmup的epoch数")
parser.add_argument("--clip_grad", type=float, default=1.0, help="梯度裁剪阈值;<=0则关闭")
parser.add_argument("--ls", type=float, default=0.05, help="Label smoothing")
parser.add_argument("--balance", type=str, default="auto", choices=["off","sampler","class_weight","auto"],
help="类别不均衡处理方式")
parser.add_argument("--workers", type=int, default=4)
parser.add_argument("--seed", type=int, default=42)
parser.add_argument("--ckpt", type=str, default="freeze_x3d.pth")
parser.add_argument("--device", type=str, default="cuda" if torch.cuda.is_available() else "cpu")
# 新增
parser.add_argument("--tta_flip", type=int, default=0, help="验证时水平翻转TTA")
parser.add_argument("--ema", type=int, default=0, help="是否启用EMA(1/0)")
parser.add_argument("--ema_decay", type=float, default=0.999, help="EMA 衰减")
args = parser.parse_args()
set_seed(args.seed)
device = args.device
print(f"Device: {device}")
print("Enabling TF32 for speed (if Ampere+ GPU).")
torch.backends.cuda.matmul.allow_tf32 = True
torch.backends.cudnn.allow_tf32 = True
torch.backends.cudnn.benchmark = True
# 数据集
classes = ("flow", "freeze")
train_set = VideoFolderDataset(root=args.root, split="train", classes=classes,
frames=args.frames, short_side=args.short_side, crop_size=args.size)
val_set = VideoFolderDataset(root=args.root, split="val", classes=classes,
frames=args.frames, short_side=args.short_side, crop_size=args.size)
print(f"[Data] train={len(train_set)} val={len(val_set)} label_counts(train)={train_set.label_counts}")
# 不均衡
sampler = None
class_weight_tensor = None
if args.balance in ("sampler", "auto"):
counts = np.array(train_set.label_counts, dtype=np.float64) + 1e-6
inv_freq = 1.0 / counts
sample_weights = [inv_freq[y] for _, y in train_set.samples]
sampler = WeightedRandomSampler(sample_weights, num_samples=len(sample_weights), replacement=True)
if args.balance in ("class_weight",):
counts = np.array(train_set.label_counts, dtype=np.float64) + 1e-6
class_weight_tensor = torch.tensor((counts.sum() / counts), dtype=torch.float32)
train_loader = DataLoader(
train_set, batch_size=args.batch, shuffle=(sampler is None), sampler=sampler,
num_workers=args.workers, pin_memory=True, drop_last=True,
persistent_workers=(args.workers > 0), prefetch_factor=2 if args.workers > 0 else None,
)
val_loader = DataLoader(
val_set, batch_size=max(1, args.batch // 2), shuffle=False,
num_workers=max(0, args.workers // 2), pin_memory=True, drop_last=False,
persistent_workers=False,
)
# 模型
model = build_model(args.arch, args.frames, args.size, num_classes=2, pretrained=bool(args.pretrained)).to(device)
# 线性探测
set_backbone_trainable(model, trainable=False, arch=args.arch)
head_params = get_head_parameters(model, args.arch)
head_ids = {id(p) for p in head_params}
backbone_params = [p for p in model.parameters() if p.requires_grad and id(p) not in head_ids]
param_groups = [{"params": head_params, "lr": args.lr * args.lr_head_mul}]
if backbone_params:
param_groups.append({"params": backbone_params, "lr": args.lr})
optimizer = torch.optim.AdamW(param_groups, lr=args.lr, weight_decay=args.wd)
# Scheduler
from torch.optim.lr_scheduler import LinearLR, CosineAnnealingLR, SequentialLR
warmup_epochs = max(0, min(args.warmup, args.epochs - 1))
sched_main = CosineAnnealingLR(optimizer, T_max=max(1, args.epochs - warmup_epochs))
scheduler = SequentialLR(optimizer, [LinearLR(optimizer, start_factor=0.1, total_iters=warmup_epochs),
sched_main], milestones=[warmup_epochs]) if warmup_epochs > 0 else sched_main
# Loss
criterion = nn.CrossEntropyLoss(
label_smoothing=args.ls,
weight=class_weight_tensor.to(device) if class_weight_tensor is not None else None
)
# AMP & EMA
scaler = torch.amp.GradScaler('cuda', enabled=(device == "cuda"))
amp_ctx = torch.amp.autocast(device_type='cuda', dtype=torch.float16, enabled=(device == "cuda"))
ema = ModelEMA(model, decay=args.ema_decay) if args.ema else None
best_acc = 0.0
os.makedirs(os.path.dirname(args.ckpt) if os.path.dirname(args.ckpt) else ".", exist_ok=True)
# 训练
for epoch in range(1, args.epochs + 1):
model.train()
t0 = time.time()
running_loss = running_acc = seen = 0
if epoch == args.freeze_epochs + 1:
print(f"===> Unfreezing backbone for finetuning from epoch {epoch}.")
set_backbone_trainable(model, trainable=True, arch=args.arch)
head_params = get_head_parameters(model, args.arch)
head_ids = {id(p) for p in head_params}
backbone_params = [p for p in model.parameters() if p.requires_grad and id(p) not in head_ids]
optimizer = torch.optim.AdamW(
[{"params": head_params, "lr": args.lr * args.lr_head_mul},
{"params": backbone_params, "lr": args.lr}],
lr=args.lr, weight_decay=args.wd
)
from torch.optim.lr_scheduler import CosineAnnealingLR
scheduler = CosineAnnealingLR(optimizer, T_max=max(1, args.epochs - epoch + 1))
for step, (x, y) in enumerate(train_loader, 1):
x = x.to(device, non_blocking=True).float()
y = y.to(device, non_blocking=True)
if step == 1 and epoch == 1:
print(f"[Sanity] x.dtype={x.dtype}, param.dtype={next(model.parameters()).dtype}, x.shape={x.shape}")
optimizer.zero_grad(set_to_none=True)
with amp_ctx:
logits = model(x)
loss = criterion(logits, y)
scaler.scale(loss).backward()
if args.clip_grad and args.clip_grad > 0:
scaler.unscale_(optimizer)
nn.utils.clip_grad_norm_(model.parameters(), max_norm=args.clip_grad)
scaler.step(optimizer)
scaler.update()
if ema:
ema.update(model)
bs = y.size(0)
running_loss += loss.item() * bs
running_acc += (logits.argmax(dim=1) == y).sum().item()
seen += bs
if step % 10 == 0 or step == len(train_loader):
lr0 = optimizer.param_groups[0]["lr"]
print(f"Epoch {epoch}/{args.epochs} | Step {step}/{len(train_loader)} | "
f"LR {lr0:.2e} | Loss {(running_loss/seen):.4f} | Acc {(running_acc/seen):.4f}")
scheduler.step()
train_loss = running_loss / max(1, seen)
train_acc = running_acc / max(1, seen)
# 验证(优先用EMA模型)
eval_model = ema.ema if ema else model
val_acc, val_loss = evaluate(eval_model, val_loader, device=device, tta_flip=bool(args.tta_flip))
dt = time.time() - t0
print(f"[Epoch {epoch}] train_loss={train_loss:.4f} acc={train_acc:.4f} | "
f"val_loss={val_loss:.4f} acc={val_acc:.4f} | time={dt:.1f}s {'(EMA+TTA)' if ema or args.tta_flip else ''}")
if val_acc > best_acc:
best_acc = val_acc
ckpt = {
"epoch": epoch,
"state_dict": eval_model.state_dict(), # 保存 EMA 权重更利于部署
"optimizer": optimizer.state_dict(),
"scaler": scaler.state_dict(),
"best_acc": best_acc,
"args": vars(args),
"classes": classes,
"arch": args.arch,
"is_ema": bool(ema)
}
torch.save(ckpt, args.ckpt)
print(f"✅ Saved best checkpoint to {args.ckpt} (acc={best_acc:.4f})")
print(f"Training done. Best val acc = {best_acc:.4f}")
# 结束时输出详细指标(基于 EMA+TTA 的模型)
eval_model = ema.ema if ema else model
evaluate_detailed(eval_model, val_loader, device=device, tta_flip=bool(args.tta_flip))
if __name__ == "__main__":
try:
main()
except KeyboardInterrupt:
sys.exit(1)启动命令:
python3 train_freeze.py --root /path/to/dataset --epochs 30 --freeze_epochs 3 \
--arch x3d_m --pretrained 1 --batch 8 --frames 32 --size 224 --short_side 256 \
--lr 3e-4 --lr_head_mul 10 --wd 1e-4 --warmup 2 \
--balance auto --ls 0.05 --clip_grad 1.0 --workers 8 \
--tta_flip 1 --ema 1 --ema_decay 0.999关键参数解释
| 参数 | 典型值 | 作用 |
|---|---|---|
--frames |
16/32 | 控制时间感受野大小 |
--short_side |
256 | 保持长宽比的缩放基准 |
--lr_head_mul |
10 | 分类头学习率是主干的10倍 |
--ema_decay |
0.999 | 模型权重指数移动平均系数 |
推理代码
import os
import sys
import argparse
from pathlib import Path
from typing import List, Tuple, Dict, Any
import numpy as np
import torch
import torch.nn as nn
from torchvision.io import read_video
from torchvision.transforms import functional as TF
# --------------------- 小工具 ---------------------
def list_videos(root: Path, exts=(".mp4", ".avi", ".mov", ".mkv")) -> List[Path]:
files = []
for ext in exts:
files += list(root.rglob(f"*{ext}"))
return sorted(files)
def uniform_indices(total: int, num: int) -> np.ndarray:
if total <= 0:
return np.zeros((num,), dtype=np.int64)
if total >= num:
idx = np.linspace(0, total - 1, num=num)
return np.round(idx).astype(np.int64)
else:
base = list(range(total))
base += [total - 1] * (num - total)
return np.array(base, dtype=np.int64)
def segment_indices(total: int, num_frames: int, clip_idx: int, num_clips: int) -> np.ndarray:
if num_clips <= 1:
return uniform_indices(total, num_frames)
start = int(np.floor(clip_idx * total / num_clips))
end = int(np.floor((clip_idx + 1) * total / num_clips)) - 1
end = max(start, end)
seg_len = end - start + 1
if seg_len >= num_frames:
idx = np.linspace(start, end, num=num_frames)
return np.round(idx).astype(np.int64)
else:
idx = list(range(start, end + 1))
idx += [end] * (num_frames - seg_len)
return np.array(idx, dtype=np.int64)
MEAN = torch.tensor((0.45, 0.45, 0.45)).view(3,1,1,1)
STD = torch.tensor((0.225, 0.225, 0.225)).view(3,1,1,1)
# --------------------- 模型构建(离线优先) ---------------------
def build_x3d_offline(variant: str, num_classes: int, pretrained: bool = False, repo_dir: str = "") -> nn.Module:
"""
优先走 pytorchvideo 本地 Python API(无需联网);
失败则从本地 hub 缓存目录加载(source='local'),也不会联网。
"""
variant = variant.lower()
assert variant in {"x3d_s", "x3d_m"}
# 1) 直接用 pytorchvideo 的 Python API(无需 torch.hub、可离线)
try:
from pytorchvideo.models import hub as pv_hub
builder = getattr(pv_hub, variant) # x3d_s / x3d_m
model = builder(pretrained=pretrained)
# 替换头
if hasattr(model.blocks[-1], "proj") and isinstance(model.blocks[-1].proj, nn.Linear):
in_feats = model.blocks[-1].proj.in_features
model.blocks[-1].proj = nn.Linear(in_feats, num_classes)
else:
# 兜底:遍历最后一块的线性层
head = model.blocks[-1]
proj = None
for _, m in head.named_modules():
if isinstance(m, nn.Linear):
proj = m; break
if proj is None:
raise RuntimeError("未找到X3D分类头线性层。")
in_feats = proj.in_features
model.blocks[-1].proj = nn.Linear(in_feats, num_classes)
return model
except Exception as e_api:
print(f"[Info] pytorchvideo.models.hub 离线构建失败,尝试本地 hub 缓存加载。原因: {e_api}")
# 2) 使用 torch.hub 的本地缓存(不联网)
try:
if not repo_dir:
repo_dir = os.path.join(torch.hub.get_dir(), "facebookresearch_pytorchvideo_main")
if not os.path.isdir(repo_dir):
raise FileNotFoundError(f"本地 hub 缓存不存在:{repo_dir}")
# 关键:source='local' 可确保不联网;trust_repo=True 跳过校验
model = torch.hub.load(repo_dir, variant, pretrained=pretrained, source='local', trust_repo=True)
# 替换头
if hasattr(model.blocks[-1], "proj") and isinstance(model.blocks[-1].proj, nn.Linear):
in_feats = model.blocks[-1].proj.in_features
model.blocks[-1].proj = nn.Linear(in_feats, num_classes)
else:
head = model.blocks[-1]
proj = None
for _, m in head.named_modules():
if isinstance(m, nn.Linear):
proj = m; break
if proj is None:
raise RuntimeError("未找到X3D分类头线性层。")
in_feats = proj.in_features
model.blocks[-1].proj = nn.Linear(in_feats, num_classes)
return model
except Exception as e_local:
raise RuntimeError(
"无法离线构建 X3D 模型。请确保已安装 pytorchvideo 或本地已有 hub 缓存。\n"
f"- pip 安装:pip install pytorchvideo\n"
f"- 本地缓存目录(示例):{os.path.join(torch.hub.get_dir(), 'facebookresearch_pytorchvideo_main')}\n"
f"原始错误:{e_local}"
)
def build_model(arch: str, num_classes: int, pretrained: bool = False, repo_dir: str = "") -> nn.Module:
arch = arch.lower()
if arch in {"x3d_s", "x3d_m"}:
return build_x3d_offline(arch, num_classes=num_classes, pretrained=pretrained, repo_dir=repo_dir)
elif arch in {"r2plus1d_18", "r3d_18"}:
from torchvision.models.video import r2plus1d_18, r3d_18
# 预训练与否不重要,稍后会 load_state_dict
m = r2plus1d_18(weights=None) if arch == "r2plus1d_18" else r3d_18(weights=None)
in_feats = m.fc.in_features
m.fc = nn.Linear(in_feats, num_classes)
return m
else:
raise ValueError(f"未知 arch: {arch}")
def load_ckpt_build_model(ckpt_path: str, device: str = "cuda", override: Dict[str, Any] = None, repo_dir: str = ""):
# 显式 weights_only=False,避免未来默认变更带来的困惑
ckpt = torch.load(ckpt_path, map_location="cpu", weights_only=False)
args = ckpt.get("args", {}) or {}
arch = (override or {}).get("arch", args.get("arch", "x3d_m"))
classes = ckpt.get("classes", ("flow","freeze"))
num_classes = len(classes)
model = build_model(arch, num_classes=num_classes, pretrained=False, repo_dir=repo_dir)
missing, unexpected = model.load_state_dict(ckpt["state_dict"], strict=False)
if missing or unexpected:
print(f"[load_state_dict] missing={missing} unexpected={unexpected}")
model.to(device).eval()
meta = {
"arch": arch,
"classes": classes,
"frames": int((override or {}).get("frames", args.get("frames", 16))),
"size": int((override or {}).get("size", args.get("size", 224))),
"short_side": int((override or {}).get("short_side", args.get("short_side", 256))),
}
return model, meta
# --------------------- 预处理 & 前向 ---------------------
@torch.no_grad()
def preprocess_clip(vframes: torch.Tensor, frames: int, short_side: int, crop_size: int, idxs: np.ndarray) -> torch.Tensor:
clip = vframes[idxs] # (frames,C,H,W)
if clip.shape[1] == 1:
clip = clip.repeat(1,3,1,1)
clip = TF.resize(clip, short_side, antialias=True)
clip = TF.center_crop(clip, [crop_size, crop_size])
clip = clip.permute(1,0,2,3).contiguous().float() / 255.0 # (C,T,H,W)
clip = (clip - MEAN) / STD
return clip.unsqueeze(0) # (1,3,T,H,W)
@torch.no_grad()
def _forward_with_tta(model: nn.Module, x: torch.Tensor, tta_flip: bool):
logits = model(x)
if tta_flip:
logits = (logits + model(torch.flip(x, dims=[-1]))) / 2.0
return logits
@torch.no_grad()
def infer_one_video(model: nn.Module, path: Path, frames: int, short_side: int, crop_size: int,
num_clips: int = 1, tta_flip: bool = False, device: str = "cuda") -> Tuple[int, np.ndarray]:
vframes, _, _ = read_video(str(path), pts_unit="sec", output_format="TCHW")
if vframes.numel() == 0:
raise RuntimeError(f"Empty video: {path}")
if vframes.shape[1] == 1:
vframes = vframes.repeat(1, 3, 1, 1)
T = vframes.shape[0]
logits_sum = torch.zeros((1, 2), dtype=torch.float32, device=device)
amp_ctx = torch.amp.autocast(device_type='cuda', dtype=torch.float16, enabled=(device == "cuda"))
for ci in range(max(1, num_clips)):
idxs = segment_indices(T, frames, ci, num_clips)
x = preprocess_clip(vframes, frames, short_side, crop_size, idxs).to(device, non_blocking=True)
with amp_ctx:
logits = _forward_with_tta(model, x, tta_flip)
logits_sum += logits.float()
probs = torch.softmax(logits_sum / max(1, num_clips), dim=1).squeeze(0).cpu().numpy()
pred = int(np.argmax(probs))
return pred, probs
# --------------------- 主流程 ---------------------
def main():
parser = argparse.ArgumentParser()
parser.add_argument("--ckpt", type=str, required=True, help="训练保存的 .pth")
parser.add_argument("--input", type=str, required=True, help="视频文件或目录")
parser.add_argument("--out", type=str, default="", help="可选:输出 CSV 路径")
parser.add_argument("--threshold", type=float, default=0.5, help="freeze(=1) 阈值")
parser.add_argument("--clips", type=int, default=1, help="多时间片数(Temporal TTA)")
parser.add_argument("--tta_flip", type=int, default=0, help="水平翻转 TTA (0/1)")
parser.add_argument("--device", type=str, default="cuda" if torch.cuda.is_available() else "cpu")
parser.add_argument("--frames", type=int, default=None, help="覆盖 ckpt 的 frames(可选)")
parser.add_argument("--size", type=int, default=None, help="覆盖 ckpt 的 crop size(可选)")
parser.add_argument("--short_side", type=int, default=None, help="覆盖 ckpt 的 short_side(可选)")
parser.add_argument("--arch", type=str, default=None, help="覆盖 arch(可选)")
parser.add_argument("--repo_dir", type=str, default="", help="pytorchvideo 本地 hub 缓存目录(可选)")
args = parser.parse_args()
if args.device.startswith("cuda"):
torch.backends.cuda.matmul.allow_tf32 = True
torch.backends.cudnn.allow_tf32 = True
torch.backends.cudnn.benchmark = True
override = {}
if args.arch: override["arch"] = args.arch
if args.frames is not None: override["frames"] = args.frames
if args.size is not None: override["size"] = args.size
if args.short_side is not None: override["short_side"] = args.short_side
model, meta = load_ckpt_build_model(args.ckpt, device=args.device, override=override, repo_dir=args.repo_dir)
classes = list(meta["classes"])
frames = int(meta["frames"])
crop = int(meta["size"])
short_side = int(meta["short_side"])
print(f"[Model] arch={meta['arch']} classes={classes}")
print(f"[Preprocess] frames={frames} size={crop} short_side={short_side}")
print(f"[TTA] clips={args.clips} flip={bool(args.tta_flip)} threshold={args.threshold:.2f}")
inp = Path(args.input)
paths: List[Path]
if inp.is_dir():
paths = list_videos(inp)
if not paths:
print(f"No videos found in {inp}")
sys.exit(1)
else:
if not inp.exists():
print(f"File not found: {inp}")
sys.exit(1)
paths = [inp]
rows = []
for p in paths:
try:
pred, probs = infer_one_video(model, p, frames, short_side, crop,
num_clips=args.clips, tta_flip=bool(args.tta_flip), device=args.device)
label = classes[pred] if pred < len(classes) else str(pred)
prob_freeze = float(probs[1]) if len(probs) > 1 else float('nan')
is_freeze = int(prob_freeze >= args.threshold)
print(f"{p.name:40s} -> pred={label:6s} probs(flow,freeze)={probs} freeze@{args.threshold:.2f}={is_freeze}")
rows.append((str(p), label, probs[0], probs[1] if len(probs)>1 else float('nan'), is_freeze))
except Exception as e:
print(f"[Error] {p}: {e}")
rows.append((str(p), "ERROR", float('nan'), float('nan'), -1))
if args.out:
import csv
with open(args.out, "w", newline="") as f:
writer = csv.writer(f)
writer.writerow(["path", "pred_label", "prob_flow", "prob_freeze", f"freeze@{args.threshold}"])
writer.writerows(rows)
print(f"Saved results to {args.out}")
if __name__ == "__main__":
main()启动命令
python3 inference_freeze.py --ckpt ./freeze_x3d.pth --input /path/to/video_or_dir \
--clips 3 --tta_flip 1关键参数解释
python3 inference_freeze.py \
--ckpt ./freeze_x3d.pth \ # 模型权重文件路径
--input /path/to/video_or_dir \ # 输入视频文件或目录
--clips 3 \ # 时间片段采样数
--tta_flip 1 # 水平翻转增强开关