本文较长,建议点赞收藏,以免遗失。更多AI大模型应用开发学习视频及资料,尽在聚客AI学院。
本文系统拆解深度学习中模型剪枝、量化、知识蒸馏三大核心压缩技术,帮助各位实现16倍模型压缩与4倍推理加速。如果对你有所帮助,记得点个小红心。
一、模型压缩的核心挑战
深度学习模型规模激增带来四大痛点:
- 存储膨胀:ResNet-50达98MB,GPT-3超百GB
- 内存瓶颈:推理中间结果占用数GB内存
- 计算延迟:实时场景要求<100ms推理速度
- 边缘限制:移动设备内存通常<8GB,算力<5TOPS
压缩目标:Smaller Size + Faster Inference + Edge Deployment
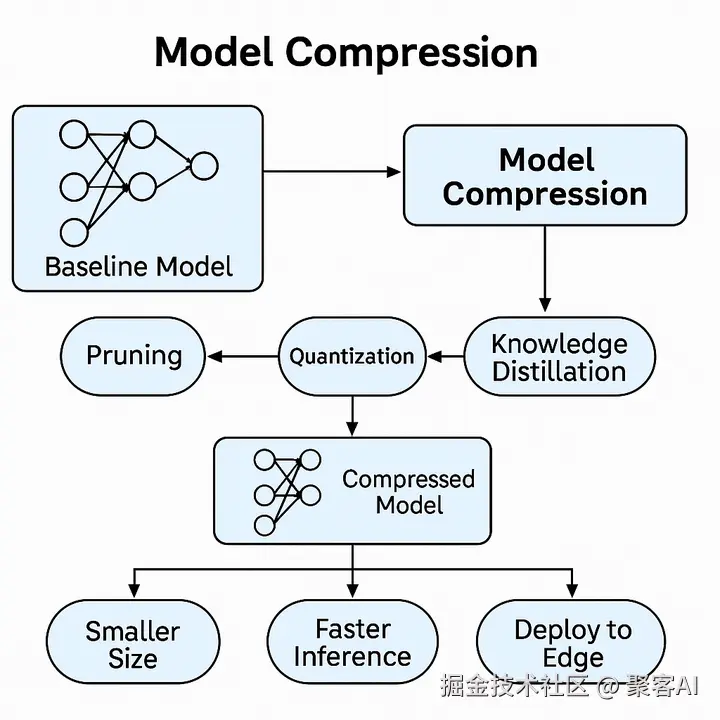
二、核心技术拆解与工程实践
1. 剪枝(Pruning):剔除冗余结构
核心原理:神经网络中60%以上连接权重接近0,移除后精度损失<3%
结构化剪枝:
ini
# PyTorch通道剪枝示例
prune.ln_structured(module, name="weight", amount=0.3, n=2, dim=0)- 优势:直接移除整层/通道,兼容通用硬件
- 劣势:压缩率通常<50%
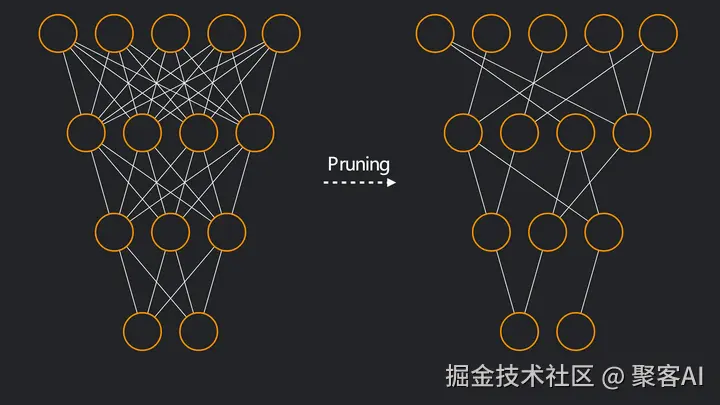
非结构化剪枝:
- 优势:压缩率可达90%(如LLM稀疏化)
- 挑战:需专用芯片支持稀疏矩阵运算
五步实施法:
- 重要性评估(L1/L2范数、泰勒展开)
- 制定逐层剪枝策略(敏感层保留更多参数)
- 执行剪枝生成稀疏模型
- 微调恢复(1%-5%训练数据,1-5个epoch)
- 迭代优化直至满足约束
2. 量化(Quantization):精度换效率
8bit量化收益:
- 存储降为1/4,内存带宽需求减少75%
- INT8计算速度比FP32快2-4倍
两大技术路线对比:
| 方法 | 精度损失 | 部署难度 | 适用场景 |
|---|---|---|---|
| 训练后量化(PTQ) | 0.5%-2% | ★☆☆☆☆ | 移动端图像分类 |
| 量化感知训练(QAT) | <0.5% | ★★★☆☆ | 自动驾驶/医疗诊断 |
实操建议:
使用TensorRT实现FP32→INT8自动转换:
ini
calibrator = trt.Int8EntropyCalibrator()
engine = builder.build_engine(network, config)3. 知识蒸馏(Knowledge Distillation):模型进化论
师生架构设计:
scss
Teacher Model(ResNet-50) → Soft Labels → Student Model(MobileNetV3)损失函数创新:
scss
Ltotal=α⋅KL(pt∣∣ps)+(1−α)⋅LCE(y,ps)其中 α=0.7时效果最佳,软标签传递类别关联信息(如猫与豹相似度)
蒸馏收益:
- 学生模型参数量降至教师1/10
- 推理速度提升3倍,精度损失<2%
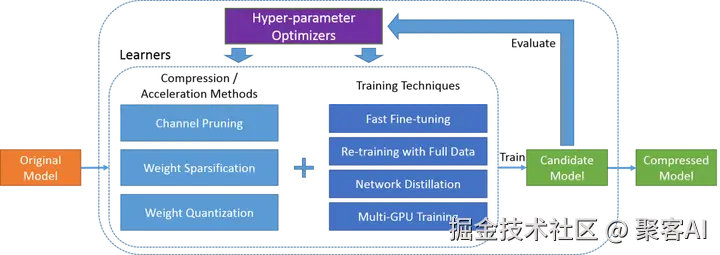
三、组合方案:蒸馏→剪枝→量化
最优级联顺序论证:
- 蒸馏先行:获取结构优化的轻量模型
- 剪枝跟进:移除蒸馏后剩余的冗余连接
- 量化收尾:实现最终存储计算优化
技术协同效应:单独使用剪枝/量化仅能获得2-4倍压缩,组合方案可达10-20倍
ps:这里还是想说一下,如果你想往AI大模型岗位去发展,或者企业有相关的AI项目需求,建议你还是系统的学习一下AI大模型应用开发,零零碎碎的知识会让你在实践中遇到很多的坑,这里为你整理了一套学习路径,粉丝朋友自行领取《如何更系统的学习AI大模型,挑战AI高薪岗位?》
四、实战案例:边缘场景性能对比
案例1:移动端图像分类(iOS/Android相册)
| 阶段 | 模型大小 | 准确率 | 推理延迟 |
|---|---|---|---|
| Baseline(ResNet-50) | 98MB | 95% | 150ms |
| +蒸馏(MobileNetV3) | 25MB | 93% | 65ms |
| +结构化剪枝(30%) | 18MB | 92.5% | 45ms |
| +INT8量化 | 6MB | 92% | 35ms |
案例2:智能音箱离线语音识别
原始模型:Transformer 12层/16头,200MB
优化路径:
- 蒸馏压缩至6层
- 注意力头剪枝至8头
- 混合精度量化(关键层INT8,其余INT4)
结果:
-
模型15MB,延迟80ms
-
94%准确率满足离线场景需求
最后再总结一下:
- 自动压缩框架:NNI/AutoCompress实现剪枝率自动搜索
- 稀疏计算硬件:NVIDIA A100支持2:4稀疏模式
- 量化感知架构:MobileNetV4原生支持INT8计算
洞见:没有最优的单一压缩技术,只有最适合业务场景的组合策略。边缘部署需在0.1%精度损失与10倍加速间寻找平衡点。好了,今天的分享就到这里,我们下期见。