|-------------------------|-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 1 2 3 4 5 6 7 8 | 英文名称: World Models 中文名称: 世界模型 链接: https://arxiv.org/abs/1803.10122 示例: https://worldmodels.github.io/ 作者: David Ha, J¨urgen Schmidhuber 机构: Google Brain, NNAISENSE, Swiss AI Lab, IDSIA (USI & SUPSI) 日期: 27 Mar 2018 引用次数: 1033 |
1 读后感
不同于之前简单的强化学习方法,这篇论文将模型分为三部分:视觉 V、记忆 M 和控制 C。视觉部分 V 将视觉信息压缩到潜空间,记忆部分 M 学习物理空间的变化规律,控制部分 C 则使用强化学习模型来学习智能体的最佳动作。
这相当于将模型拆分为大脑的不同功能区域。复杂的世界信息保留在 V 和 M 中,同时确保强化学习部分 C 足够小,以便快速训练。V 和 M 可以分别看作对空间和时间的建模。
文中还讨论了梦境和海马回放。由于有了时序预测模型 M,我们可以在没有现实输入的情况下通过 M 计算出后续状态,从而生成一个想象中的环境。还可以利用梦中产生的数据来训练控制模型,并通过调节梦的真实程度来构造更复杂的训练环境,以提升模型的性能。
文章发表于 2018 年,当时还没有太多可用的深度强化学习库。现在,我们可以利用更新的强化学习库和硬件以更快、更精确的方式建模。然而,我认为 V+M+C 的结构仍然适用。如果将智能体(Agent)视为一个人,他们的视觉能力 V 和对时间变化的预测能力 M 是通用的;而强化学习控制器 C 则针对具体目标,如赛车或打球。因此,在实际应用中,可能会采用一个 V、一个 M 和多个 C 的结构。这也要求 C 足够小,同时将通用知识提取到 V 和 M 中。
事实上,真实世界(模型输入)与我们理解的世界(M 输出)之间存在很大差异。
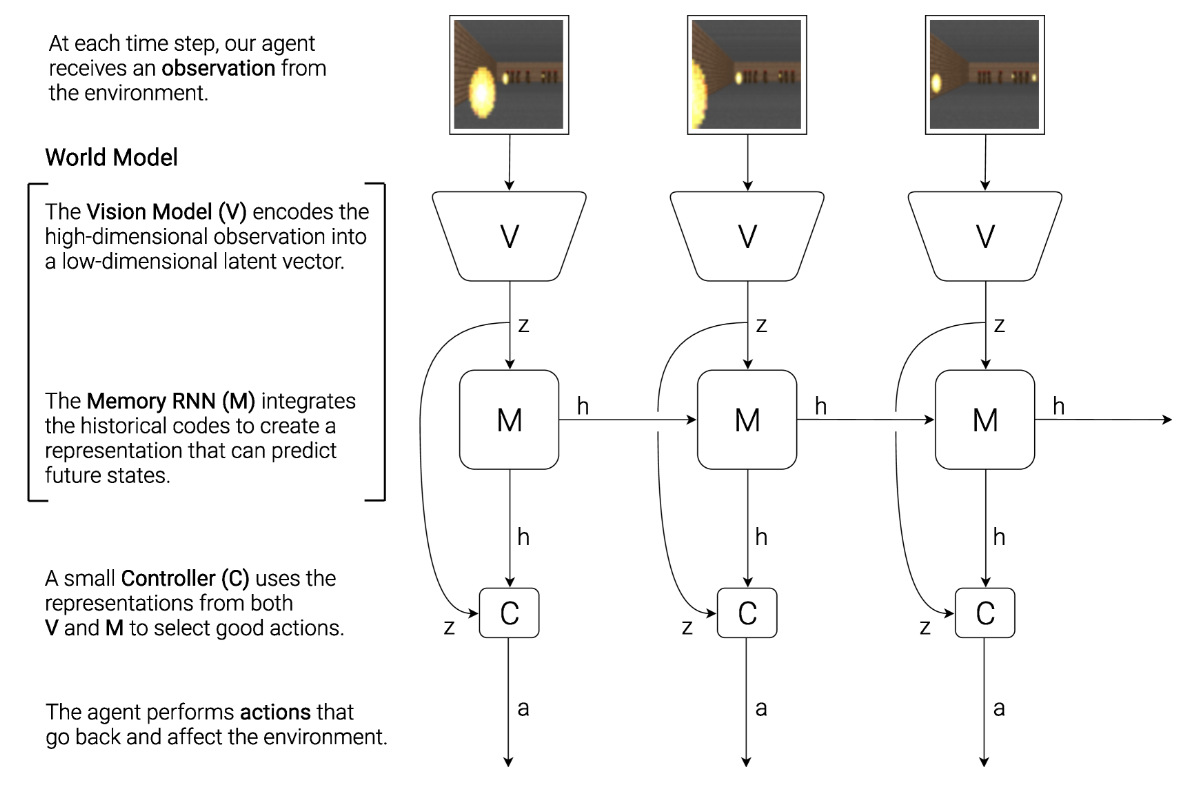
图 4:代理由三个紧密协作的组件组成:视觉(V)、内存(M)和控制器(C)
2 摘要
目标:建立世界模型,学习压缩空间内的时空表示。通过使用从世界模型中提取的特征作为智能体的输入,训练智能体完成具体任务。
方法:以无监督的方式快速训练一个非常紧凑和简单的策略,可以解决具体问题。甚至可以完全在它自己的幻觉梦境中训练智能体,并将其中产生的世界模型,应用到实际环境中。
结论:通过训练代理,表明使用文中的世界模型可以提高对世界的表征能力。
3 Agent 模型
文中提出了一个受自身认知系统启发的简单模型。该模型包括视觉感知组件 V,能够将所见内容压缩为较小的表征空间;记忆组件 M,能够根据历史信息预测未来行为;以及决策组件 C,根据视觉和记忆组件的表示来确定行动。这个模型通过将输入信息处理和决策制定进行分离,可以实现更高效的智能体行为。
3.1 VAE (V) 模型
变分自编码器 VAE 将每个时间步的视觉层面将图像压缩到隐空间 z。
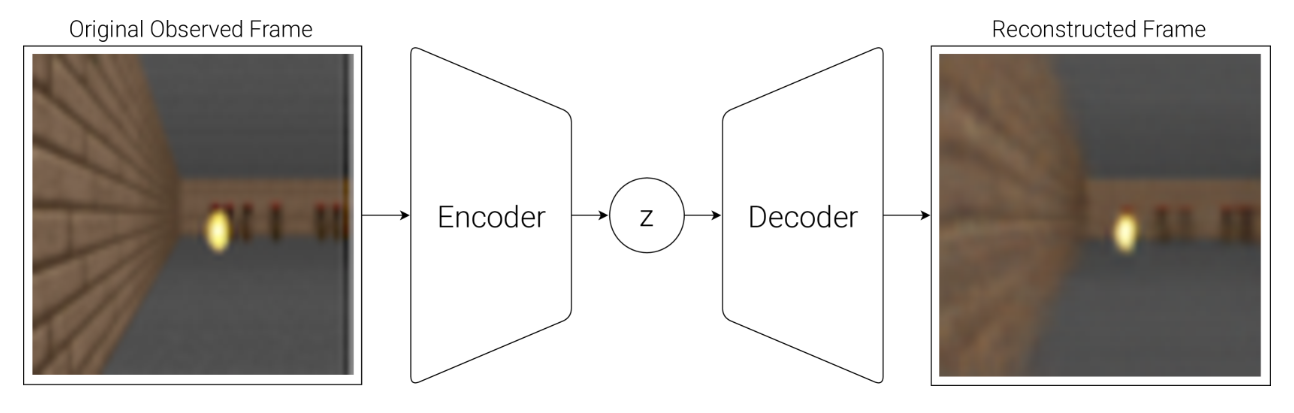
图 5:变分自编码器(VAE)的流程图。
3.2 MDN-RNN (M) 模型
在时序层面使用 RNN 来预测未来。由于许多复杂环境本质上是随机的,因此训练 RNN 输出概率密度函数 p(z),而不是确定性预测 z。简而言之,即预测下一步潜向量 z 的概率分布。
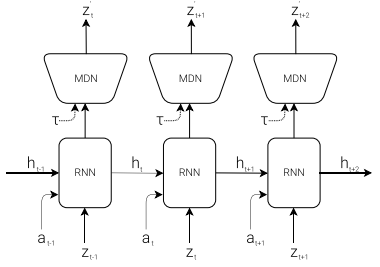
图 6:具有混合密度网络输出层的 RNN。MDN 输出高斯分布混合的参数 p(z),用于对下一个潜在向量的预测进行采样 z 。
P(zt+1|at,zt,ℎt) ,其中 at 是 time t 采取的动作, ℎt 是 RNN 在 time t 的隐藏状态。根据温度参数来控制模型的不确定性。
3.3 控制器 (C) 模型
控制器(C)模型负责确定在环境推进过程中代理能够获得的预期累积奖励最大化的行动过程。为了使 C 更简单且更小,它与 V 和 M 分开训练,因此智能体的大部分复杂性留在世界模型(V 和 M)中。
C 是一个简单的单层线性模型,它将 z 映射到每个时间步的操作 a。
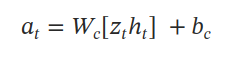
3.4 结合 V、M 和 C
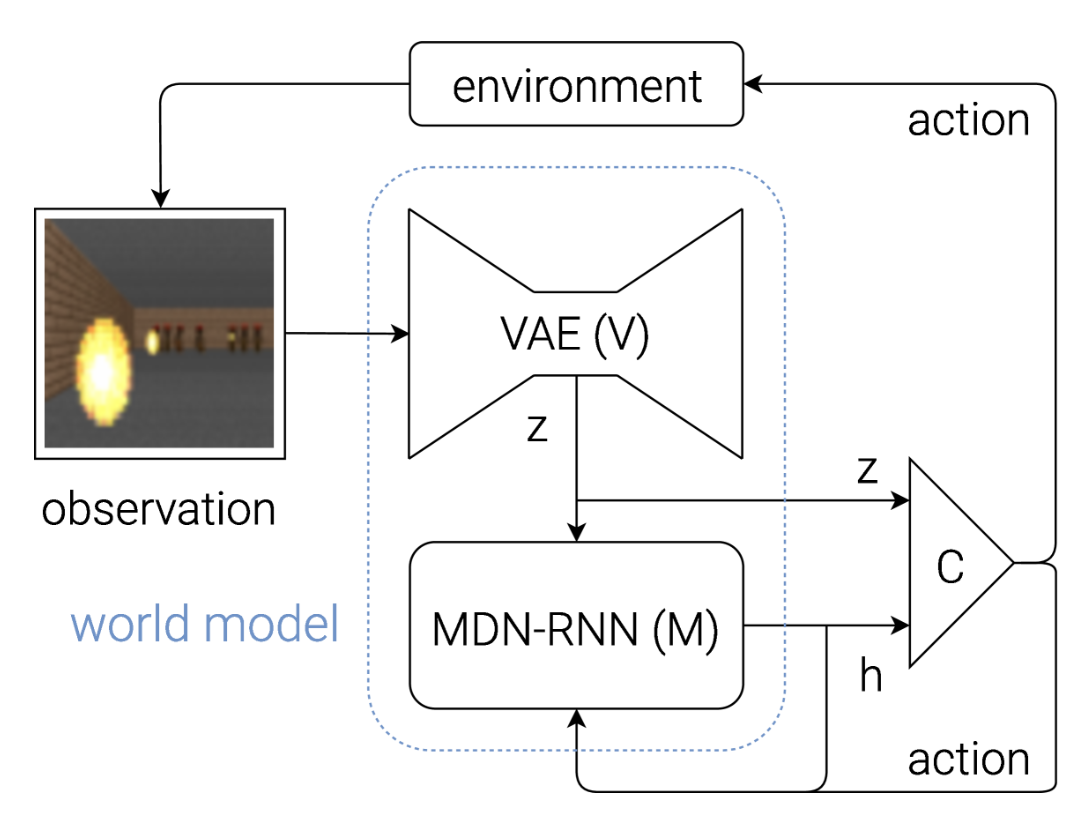
图 8:Agent 模型流程图。原始观测值经过 V 处理得到潜在向量 z。C 的输入是这个潜在向量 z,与 M 的隐藏状态 ℎ 在每个时间步长上连接。然后,C 使用输出 a 控制动作向量,并对环境产生影响。接着,M 使用当前的状态 z 和动作 a 更新自己的隐藏状态,生成下一个时间步 t+1 上要使用的 ℎ。
V 和 M 使用深度学习方法进行训练;并选择了协方差矩阵适应进化策略(CMA-ES)来优化 C 的参数,它适用于解空间中具有多达几千个参数的情况。通过在一台拥有多个 CPU 核心的单机上并行运行多个环境实例来训练模型 C 的参数。
4 赛车实验
4.1 用于特征提取的世界模型
预测世界模型可以帮助我们提取有用的空间和时间表示。通过将这些功能作为控制器的输入使用。
为了训练我们的 V 模型,首先收集了一个包含 10,000 个随机推出的环境的数据集。让一个智能体随机行动多次来探索环境,并记录所采取的随机行动 a 和由此产生的环境观察结果。使用这个数据集来训练 V 以学习每一帧观察到的潜在空间。
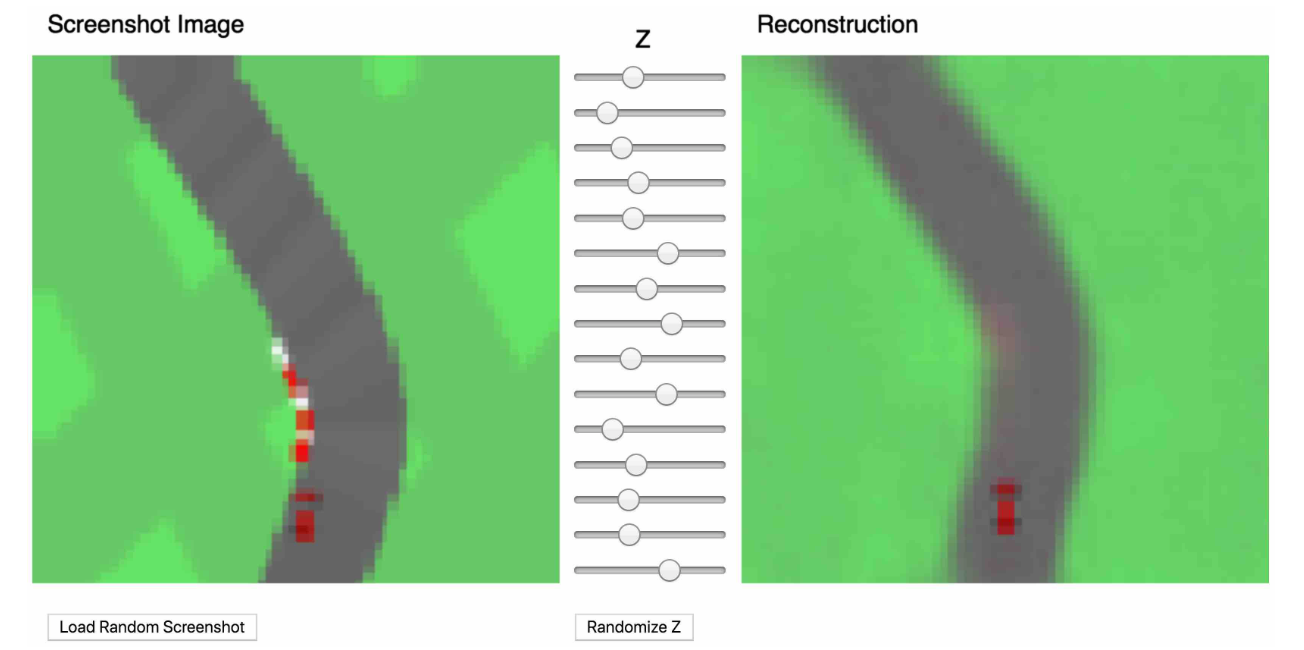
使用经过训练的 V 模型对每一帧进行预处理,生成 z,以便训练时序记忆 M 模型。
世界模型(V 和 M)任务的目标是压缩和预测观察到的图像帧序列,但并不了解来自环境的实际奖励信号。只有控制器(C)模型能够获取来自环境的奖励信息。线性控制器模型只有 867 个参数,因此 CMA-ES 等进化算法非常适合用于优化任务。
4.2 程序
具体步骤如下:
- 从随机策略中收集 10,000 轮数据。
- 使用 VAE(V)训练模型,用于将帧编码为 z。
- 使用 MDN-RNN(M)训练模型,对概率 P(z) 进行建模。
- 将控制器(C)定义为 a。
- 使用 CMA-ES 求解参数 w 和 b,以最大化预期的累积奖励。
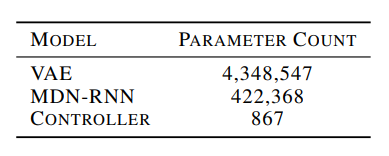
模型参数量如下:
4.3 结果
首先测试使只能访问 V 而不能访问 M 时,控制器的效果。实验证明,这会导致摇晃和不稳定的驾驶,并在更陡峭的弯道上错过赛道。在 100 次随机试验中,它获得了平均分数 632 ± 251。
M 用于预测环境的变化,因为ℎ包含有关未来概率分布的信息,所以 Agent 可以查询 RNN 以指导其行动决策。加入 M 后,在 100 次随机试验中获得了 906 ± 21 分。报告排行榜上最佳解决方案在 100 次随机试验中获得了平均分数 838 ± 11。

4.4 赛车之梦
世界模型可以用来对未来进行建模,因此我们可以让它自己计算假设的赛车场景。可以要求它生成给定当前状态的 zt+1 概率分布,并采样 a,zt+1 作为实际观察值。训练过的 C 可以应用于由 M 产生的虚拟环境中。
5 VizDoom 实验
5.1 在梦中学习
本部分研究了能否通过训练智能体在梦境中学习,并将其学到的策略应用于实际环境。
智能体并不直接观察现实,而只是通过世界模型看到世界的映像。在这个实验中训练了一个智能体,在由世界模型生成的幻觉中进行训练。
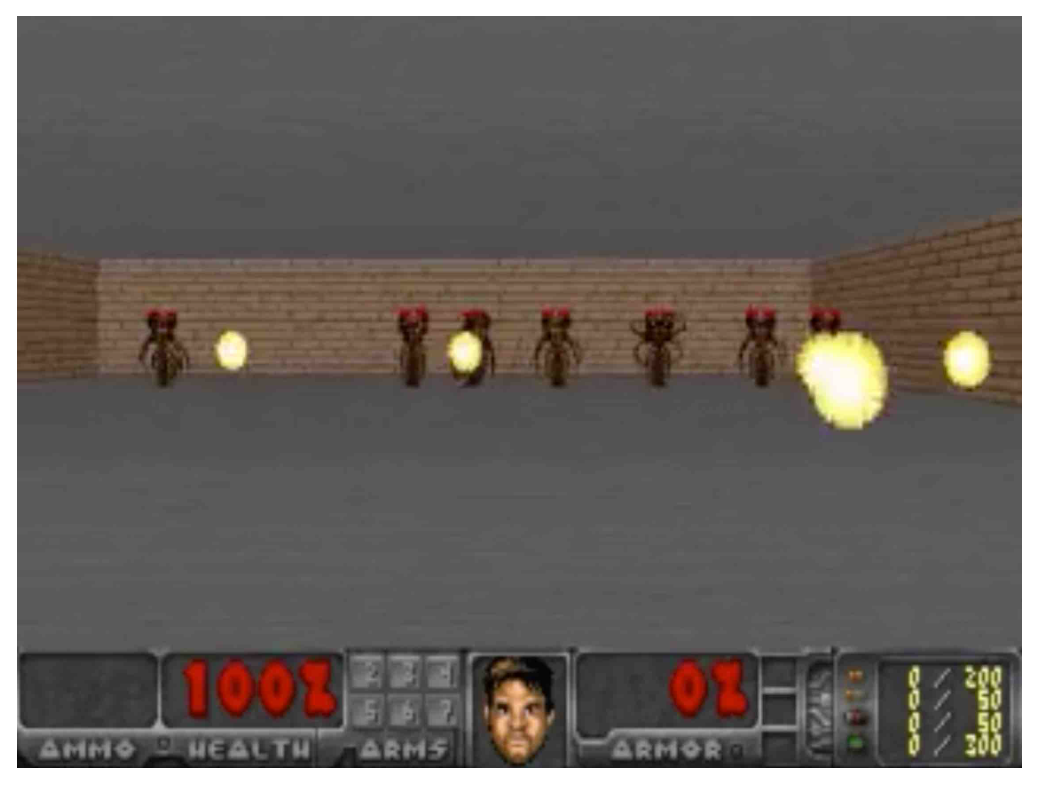
在这个游戏中,特工必须学会避开怪物从房间另一侧射出的火球。在这种环境中没有明确的奖励,累积奖励可以定义为代理保持存活的时间步数。环境的每次最多运行 2100 个时间步长,如果连续 100 轮的平均生存时间大于 750 个时间步长,则认为任务完成。
5.2 程序
在这个任务中,M 模型除了预测下一步的 z 外,还将预测智能体是否在下一帧中死亡。
在梦境模拟中,不需要 V 模型对任何真实像素帧进行编码,因此智能体将完全在潜在空间环境中进行训练。
- 收集 10,000 轮数据的随机策略。
- 使用 VAE(V)将每一帧编码为潜在向量 z,并使用 V 将从第一步收集的图像转换为潜在空间表示。
- 训练 MDN-RNN(M)进行时序建模。
- 定义控制器(C)生成动作 a。
- 使用 CMA-ES 求解生成动作 a 的参数 W,以最大化虚拟环境中的预期生存时间。
- 在实际环境中使用从虚拟环境中学到的策略。
5.3 在梦中训练
这里的 RNN 学习了完整的游戏环境,包括游戏逻辑、敌人行为、物理和 3D 图形渲染。
与实际游戏环境不同的是,虚拟环境中可能增加额外的不确定性,使得梦境环境中的游戏更加具有挑战性。
通过增加温度参数来增加不确定性,使得梦境变得更加困难。火球可能会在难以预测的路径上更随机地移动,代理可能因为纯粹的不幸而死亡。实验发现,在较高温度设置下表现良好的 Agent 通常在正常设置下也表现更好。
5.4 将策略转移到实际环境中
让代理在虚拟环境中接受训练,并在原始的 VizDoom 场景中测试其性能。经过超过 100 次随机连续试验,分数达到了约 1100 个时间步长,远远超出了要求分数 750 个时间步长,并且远高于在更困难的虚拟环境中获得的分数。
5.5 欺骗世界模式
在游戏过程中,智能体也会寻找游戏中的漏洞以进行作弊,以最大化其预期的累积奖励。然而,如果学习的虚拟环境存在问题(即 M 模型有缺陷),代理就会找到在虚拟环境中看起来不错但在实际环境中会失败的策略。
为了解决这个问题,可以通过调整温度参数来控制 M 模型中的随机性。实验结果显示训练 C 模型对具有不同不确定性水平的幻觉虚拟环境有影响。表 -2 展示了在给定温度下训练代理后,在实际环境中进行 100 次随机推演所得到的平均分数。
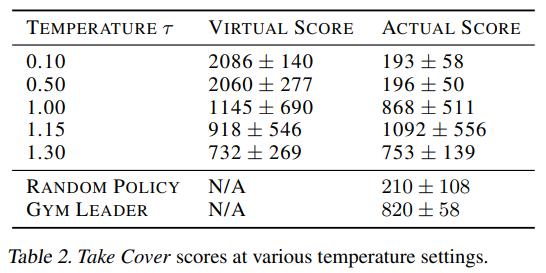
OpenAI Gym 排行榜(Paquette,2016 年)的最佳成绩是 820 ± 58。加大温度会增加难度,从而使模型的分数更高。但是如果难度过高,反而会产生相反的效果。
6 迭代训练程序
对于更复杂的任务,需要进行迭代训练过程。
- 使用随机模型参数初始化 M 和 C。
- 在实际环境中进行 N 次推演。将期间的所有操作 a 和观察结果 x 保存到存储器中。
- 训练模型 M 来建模 P(x),同时通过优化 C 来改进 M 的内部预期奖励。
- 如果任务尚未完成,返回第 2 步继续进行。
这类似于神经科学中的海马体回放,即:动物在休息或睡眠时如何回放最近的经历。回放最近的经历在记忆巩固中起着重要作用,它更像是思考而不是做梦。