Celery 的简单介绍
用 Celery 官方的介绍:它是一个分布式任务队列; 简单,灵活,可靠的处理大量消息的分布式系统; 它专注于实时处理,并支持任务调度。
Celery 如果使用 RabbitMQ 作为消息系统的话,整个应用体系就是下面这张图

Celery 官方给出的 Hello World, 对于未接触它的人来说根本就不知道是什么
|---------------|--------------------------------------------------------------------------------------------------------------------------------|
| 1 2 3 4 5 6 7 | from celery import Celery app = Celery('hello', broker='amqp://guest@localhost//') @app.task def hello(): return 'hello world' |
还是有必要按住上面那张图看 Celery 的组成部分
- Celery 自身实现的部分其实是 Producer 和 Consumer. Producer 创建任务,并发送消息到消息队列,我们称这个队列为 Broker。Consumer 从 Broker 中接收消息,完成计算任务,把结果存到 Backend
- Broker 就是那个消息队列,可选择的实现有 RabbitMQ, Redis, Amazon SQS
- 结果存储(Backend), 可选择 AMQP(像 RabbitMQ 就是它的一个实现), Redis, Memcached, Cassandra, Elasticsearch, MongoDB, CouchDB, DynamoDB, Amazon S3, File system 等等,看来它的定制性很强
- 消息和结果的存储还涉及到一个序列化的问题,可选择 pickle(Python 专用), json, yaml, msgpack. 消息可用 zlib, bzip2 进行压缩, 或加密存储
- Worker 的并发可采用 prefork(多进程), thread(多线程), Eventlet, gevent, solo(单线程)]
Celery 应用的基础选型
Celery 的 Broker 和 Backend 有非常多的选择组合,RabbitMQ 和 Redis 都是即可作为 Broker 又能用作 Backend。但 Celery 的推荐是用 RabbitMQ 作为 Broker, 小的结果这里选择用 Redis 作为 Backend, 所以这里的选型是
- Broker: RabbitMQ
- Backend: Redis
- 序列化:JSON -- 方便在学习中查到消息中的数据
准备 Redis
安装 Python 包
在需要运行 Producer 和 Consumer(worker) 的机器上创建一个 Python 虚拟环境,然后安装下面的包
$ pip install celery redis
实践中只需要安装 celery redis 就能运行后面的例子,没有安装 librabbitmq, "celerylibrabbitmq" 也行,安装了这两个库能使用更高效的 librabbitmq C 库。如果安装了 librabbitmq 库,broker='amqp://...' 默认使用 librabbitmq, 找不到 librabbitmq 的话就用 broker='pyamqp://...'
$ pip install librabbitmq
$ pip install "celerylibrabbitmq"
注:中括号中的是安装 Celery 提供的 bundle, 它定义在 setup.py 的 setup 函数中的 extras_require。
Celery 应用实战
我们不用 Celery 的 Hello World 实例,那不能帮助我们理解背后发生了什么。创建一个 tasks.py 文件
|-------------------------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 1 2 3 4 5 6 7 8 9 10 11 | from celery import Celery app = Celery('celery-demo', broker='amqp://celery:your-password@192.168.86.181:5672/', backend='redis://192.168.86.181:6379') @app.task def add(x, y): return x + y |
这里配置连接到 brocker 的 / vhost, 如果连接到别的 vhost, 如 celery 的话, url 写成 amqp://celery:your-passoword@192.168.86.181:5672/celery. backend 的 redis 如果要配置密码, 和 db 的话,写成 redis://:password@192.168.86.181:6379/2
暂且不在该脚本中直接执行 add.delay(15, 30), 而是放到 Python 控制台下方便测试
现在进到 Python 控制台
|-------------|-------------------------------------------------------------------------------------------------------------------------------------------------|
| 1 2 3 4 5 6 | >>> from tasks import add >>> task = add.delay(15, 30) >>> task.id 'c3552fa2-502a-450b-933b-19a1da65ba33' >>> task.status 'PENDING' |
由于 Worker 还没有启动,所以得到一个 task_id, 状态是 PENDING。趁这时候看看 Celery 目前做了什么,来查看到 RabbitMQ
|---|---------------|
| 7 | celery direct |
Celery 在 RabbitMQ 中创建了的资源有
- 一个 Exchange: celery direct
- 两个 binding: 送到
默认(空字符串)或celeryexchange 的, routing-key 为 celery 的消息会转发到队列celery中 - 一个队列
celery
查看队列 celery 中的消息
|-------------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 1 2 3 4 5 6 | vagrant@celery:~$ rabbitmqadmin get queue=celery ackmode=ack_requeue_true +-------------+----------+---------------+-------------------------------------------------------------------------------------+---------------+------------------+-------------+ | routing_key | exchange | message_count | payload | payload_bytes | payload_encoding | redelivered | +-------------+----------+---------------+-------------------------------------------------------------------------------------+---------------+------------------+-------------+ | celery | | 0 | \[15, 30, {}, {"callbacks": null, "errbacks": null, "chain": null, "chord": null}] | 83 | string | False | +-------------+----------+---------------+-------------------------------------------------------------------------------------+---------------+------------------+-------------+ |
ackmode=ack_requeue_true, 所以消息仍然在队列中, Redis 中什么也还没发生,接下来要
启动 Celery Worker
要用到 celery 命令,不过只要是 Python 的程序,命令行能做的事情总是能用 Python 代码来执行,用 celery --help 可看它的详细说明。
$ celery -A tasks worker -l INFO
tasks 是自己创建的模块文件 tasks.py
这时候显示出一条绿绿的芹菜出来了,所以得用屏幕截图来表现
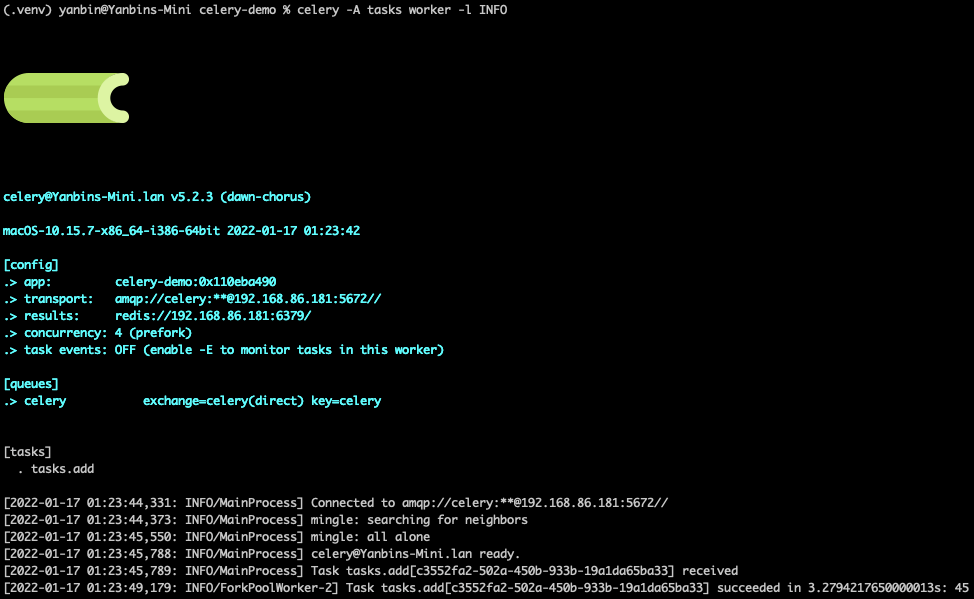
取出消息并显示任务执行完成,这时候去看 RabbitMQ 的队列 celery 中的消息不见了,启动 Worker 后也会在 RabbitMQ 中创建 queue, 及对应的 binding, exchange。
再回到提交任务的 Python 控制台
|---------|----------------------------------------------------|
| 1 2 3 4 | >>> task.status 'SUCCESS' >>> task.result 45 |
一个 Celery 全套服务圆满完成。结果存在了 Redis 中
192.168.86.181:6379> keys *
- "celery-task-meta-c3552fa2-502a-450b-933b-19a1da65ba33"
192.168.86.181:6379> TTL celery-task-meta-c3552fa2-502a-450b-933b-19a1da65ba33
(integer) 85840
192.168.86.181:6379> get celery-task-meta-c3552fa2-502a-450b-933b-19a1da65ba33
"{\"status\": \"SUCCESS\", \"result\": 45, \"traceback\": null, \"children\": \[\], \"date_done\": \"2022-01-17T07:23:48.901999\", \"task_id\": \"c3552fa2-502a-450b-933b-19a1da65ba33\"}"
Redis 中的结果保存时长为 24 小时,失败的任务会记录下异常信息。
关于 Worker 的控制查看帮助 celery worker --help, 比如
- -c, --concurrency: 并发数,默认为系统中 CPU 的内核数
- -P, --pool prefork\|eventlet\|gevent\|solo\|processes\|threads: worker 池的实现方式
- --max-tasks-per-child INTEGER: worker 执行的最大任务数,达到最大数目后便重启当前 worker
- -Q, --queues: 指定处理任务的队列名称,逗号分隔
任务的状态变迁是:PENDING -> STARTED -> RETRY -> STARTED -> RETRY -> STARTED -> SUCCESS
Celery 的配置
除了在声明 Celery 对象时可以指定 broker, backend 属性之外,我们可以用 py 配置文件的形式来配置更多的内容,配置文件 celeryconfig.py, 内容是 Configuration and defautls 中列出的项目
|---------------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 1 2 3 4 5 6 7 | broker_url = 'amqp://celery:your-password@192.168.86.181:5672/' result_backend = 'redis://192.168.86.181:6379' task_serializer = 'json' result_serializer = 'json' accept_content = 'json' timezone = 'America/Chicago' enable_utc = True |
新的格式是用小写的,旧格式用大写,如 BROKER_URL, 但是同一个配置文件中不能混合大小写,同时写 BROKER_URL 和 result_backend 就不行了。
然后在 tasks.py 中加载配置文件
|---------|----------------------------------------------------------------------------------------------------------------|
| 1 2 3 4 | from celery import Celery import celeryconfig app = Celery('celery-demo') app.config_from_object(celeryconfig) |
Celery 实时监控工具
Flower 是一个基于 Web 的监控 Celery 中任务的工具,安装和启动
$ pip install flower
$ celery -A tasks flower
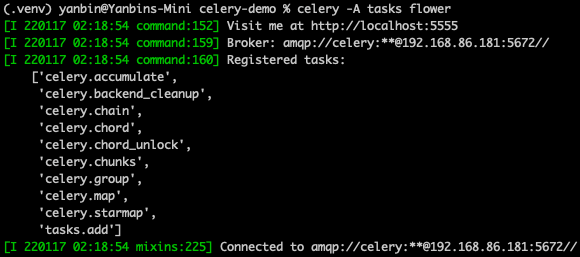
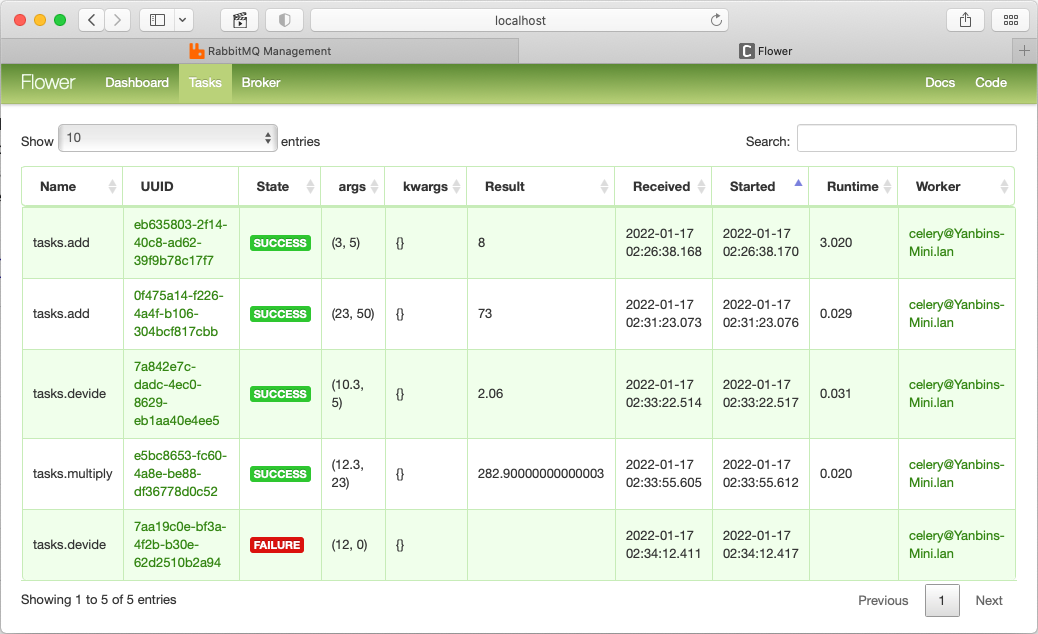
其他剩下的问题,应该就是如何安排 Worker(比如结合 AutoScaling),从 Python 代码中启动 Worker, 怎么做灵活的配置, 调度任务的执行,其他的 backend 选择等等。
其他补充
backend rpc:// 的组合
如果配置中用
|-----|-------------------------------------------------------------------------------------------|
| 1 2 | broker_url = 'amqp://celery:password@192.168.86.50:5672/celery' result_backend = 'rpc://' |
amqp 和 rpc:// 的组合,任务和结果都会存在 RabbitMQ 中
|-----|----------------------------------------------------------------|
| 1 2 | broker_url = 'redis://192.168.86.50' result_backend = 'rpc://' |
redis 和 rpc:// 的组合,任务和结果都保存在 Redis 中
为什么 Celery 推荐使用 RabbitMQ, 一说是它的一开发人员负责开发过 RabbitMQ, 所以即使使用 Redis 时,也会在 Redis 中写入有关 RabbitMQ 概念的数据,如 exchange, routing key 等。
常见问题
Celery ValueError: not enough values to unpack (expected 3, got 0)的解决方案
先安装eventlet
python
pip install eventlet然后,启动worker的时候加一个参数,如下:
python
celery -A <moduleName> worker -l info -P eventlet然后就可以正常运行worker执行任务了