往期我们测试了1 台 DGX Spark 运行 gps-oss-120b FP4 模型,近期我们的技术伙伴测试了3 台集群运行 Qwen3-235B-A22B-FP8 模型,现在来为大家带来第一手的实测性能分析。
实测视频
DGX Spark 三机互连跑 Qwen3-235B-FP8
上述视频中通过3 台 DGX Spark 互连形成环状网 ,已成功调用3台 DGX Spark 的算力,并且可以运行 Qwen3-235B-A22B-FP8 的模型。想要了解网络如何配置可私信,下面我们来看看实测数据。
测试数据(4k输入)
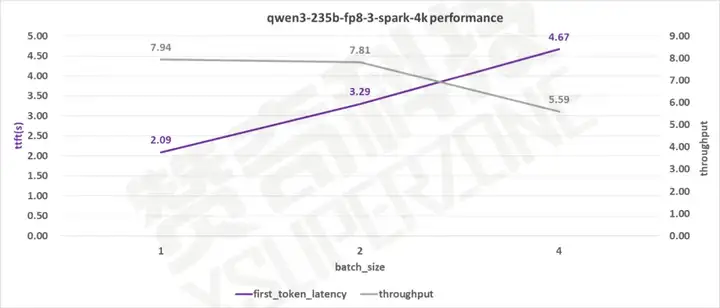
单用户的生成速度有8 tokens/s ,首字延迟在2s左右。
并发为2时,生成速度仍有 7.8 tokens/s ,首字延迟3.29s。
此外 DGX Spark 单用户的 Prefill 能达到2000 token/s 。多用户 Prefill 最高可达 3450 token/s。可以看出 DGX Spark 的表现不错。
为什么 Prefill 那么重要?
- 用户体验: 在交互式应用中(如聊天机器人),Prefill 直接决定了用户从按下"发送"到看到第一个字开始出现的等待时间。这个"首字延迟"对用户体验至关重要。
- 处理长上下文能力: Prefill 的计算复杂度与输入序列长度的平方(在原始注意力机制下)成正比。因此当处理非常长的文档或对话历史时,Prefill 延迟会急剧增加成为系统瓶颈。优化 Prefill 性能是让模型用好长上下文的关键。