最近进行的课程汇报,学习了2023年的CVPR文章《DreamBooth: Fine Tuning Text-to-Image Diffusion Models****for Subject-Driven Generation》,因此尝试使用了几种方法对这篇文章的工作进行了一定的复现。本文主要介绍Stable Diffusion Web UI(webui)的安装以及使用webui运行DreamBooth生成图片。
参考教程
一开始看的文字教程主要是有关DreamBooth的,没有看明白这个Stable Diffusion Web UI是怎么安装与使用的,于是我又在B站找了个视频教程,效果还不错,下面给出我观看的视频教程链接和作者id,避免侵权~~~
视频教程链接:stable diffusion 使用dream booth训练大模型入门教程_哔哩哔哩_bilibili
b站视频作者id:穆飞大神
接下来我将结合我在安装过程中遇到的一些问题,以图文形式对Stable Diffusion Web UI的安装过程进行讲解。
安装过程
step1 克隆webui的github仓库
webui的github仓库链接:AUTOMATIC1111/stable-diffusion-webui: Stable Diffusion web UI (github.com)![]() https://github.com/AUTOMATIC1111/stable-diffusion-webui通过命令将仓库克隆至本地:
https://github.com/AUTOMATIC1111/stable-diffusion-webui通过命令将仓库克隆至本地:
(在git bash中和在win cmd中运行效果似乎是一样的)
bash
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
(此时需要注意,存放路径中不能带有中文,否则后续运行会报错)
后面的run bat文件可以直接在资源管理器下双击运行。

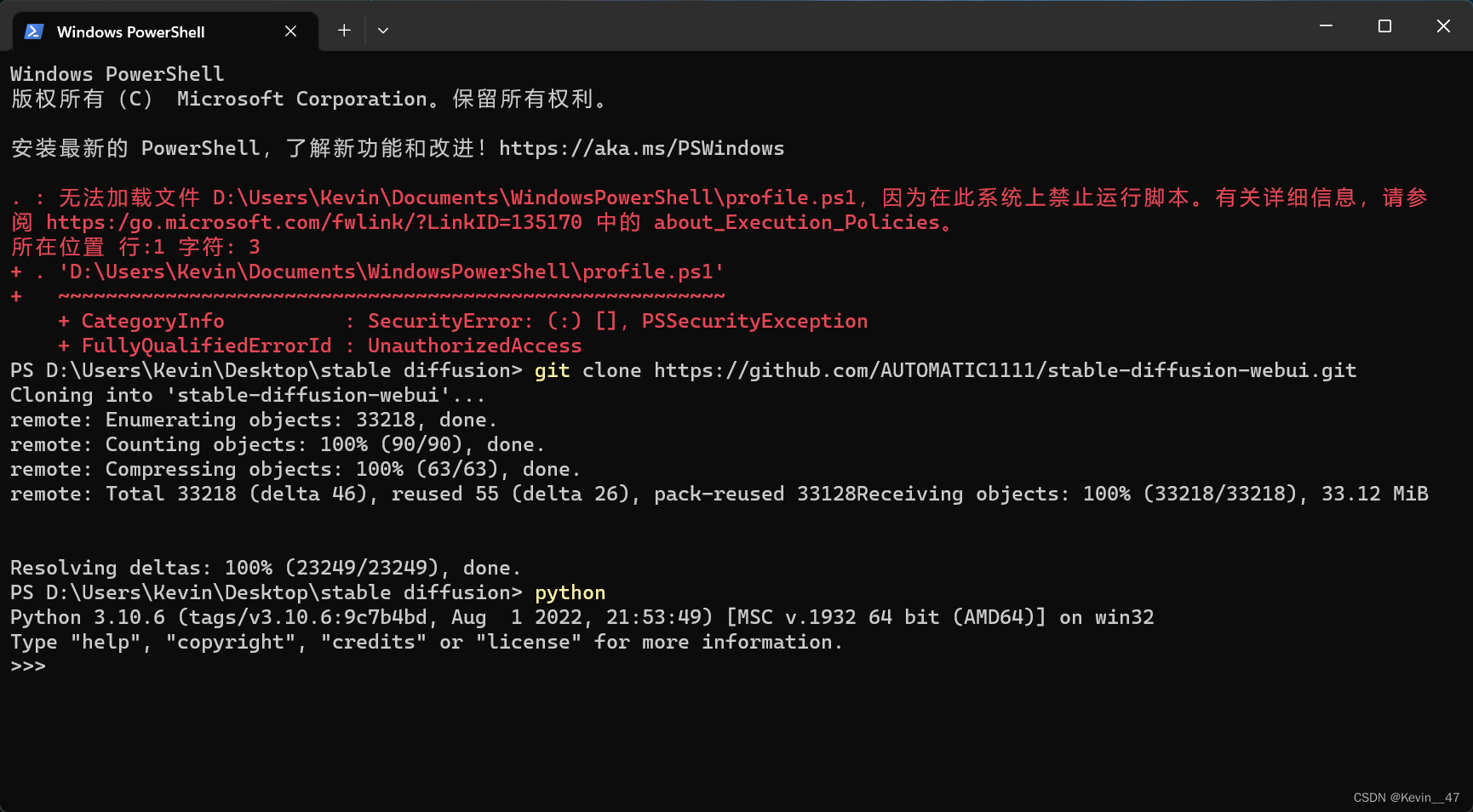
运行后提示could not launch python。
step2 安装python 3.10.6
Stable Diffusion Web UI本地运行需要安装python 3.10.6,目前看下来似乎必须是这个版本。
安装python时需要勾选,添加到环境变量add python to path,否则系统无法找到,在cmd中输入python会跳转microsoft store(至少在win11下会这样,但是以前确实从来没有遇到过这种情况,可能是以前安装的时候都装对了)。
安装完之后在命令行中输入python之后的结果如下图所示。
step3 运行webui
双击运行webui.bat文件,第一次运行会自动安装一些包,运行情况如下图所示。

在安装完包之后又遇到报错:

通过排查,这里的报错原因就是第一步路径中带有中文,重新在没有中文的路径下双击运行webui.bat文件,结果如下图所示。
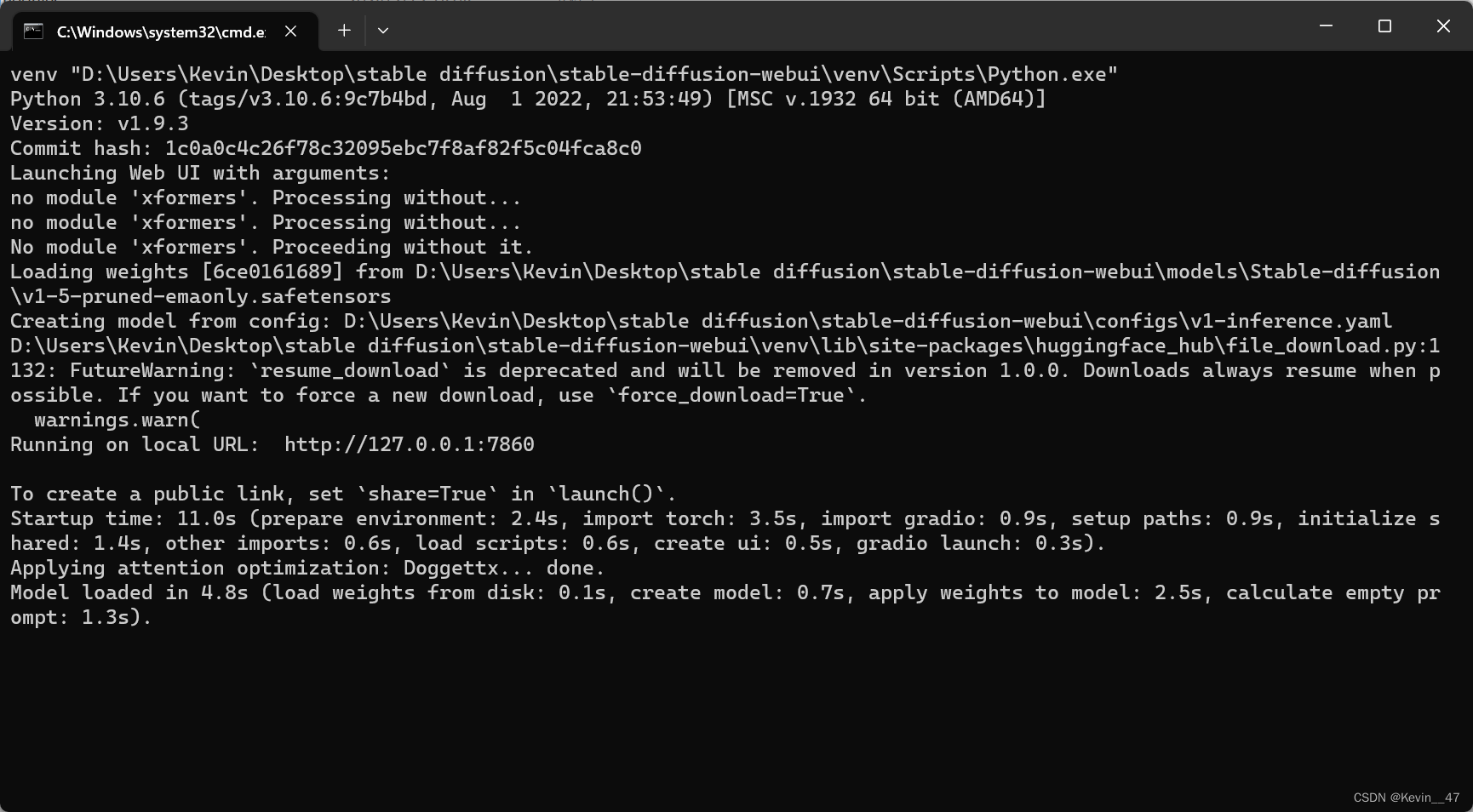
安装相关的包完成后,命令行出现上述结果,浏览器直接跳出stable diffusion界面。

我这里的webui也没有再另外进行汉化,所以界面都是英文的。
step4* 安装DreamBooth插件
*如果不用训练可以不做这一步。
插件的位置,在webui-Extension-Available-点击Load from,在下面出现的众多插件中找到DreamBooth(可以通过Ctrl+F直接在页面中进行查找),点击安装。
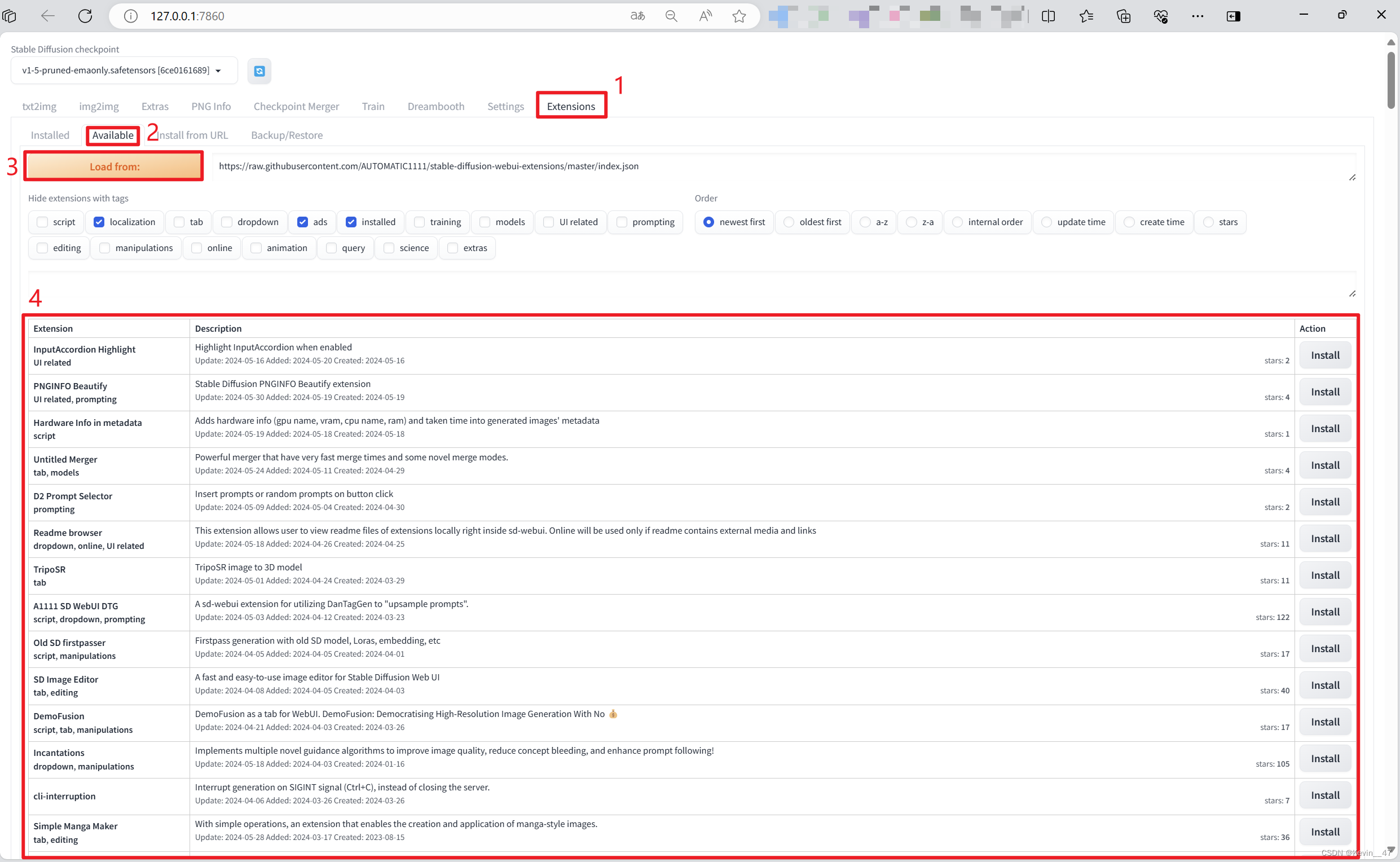
(安装过后,在这里就不会再出现了)
最终安装好之后的效果如下图所示。
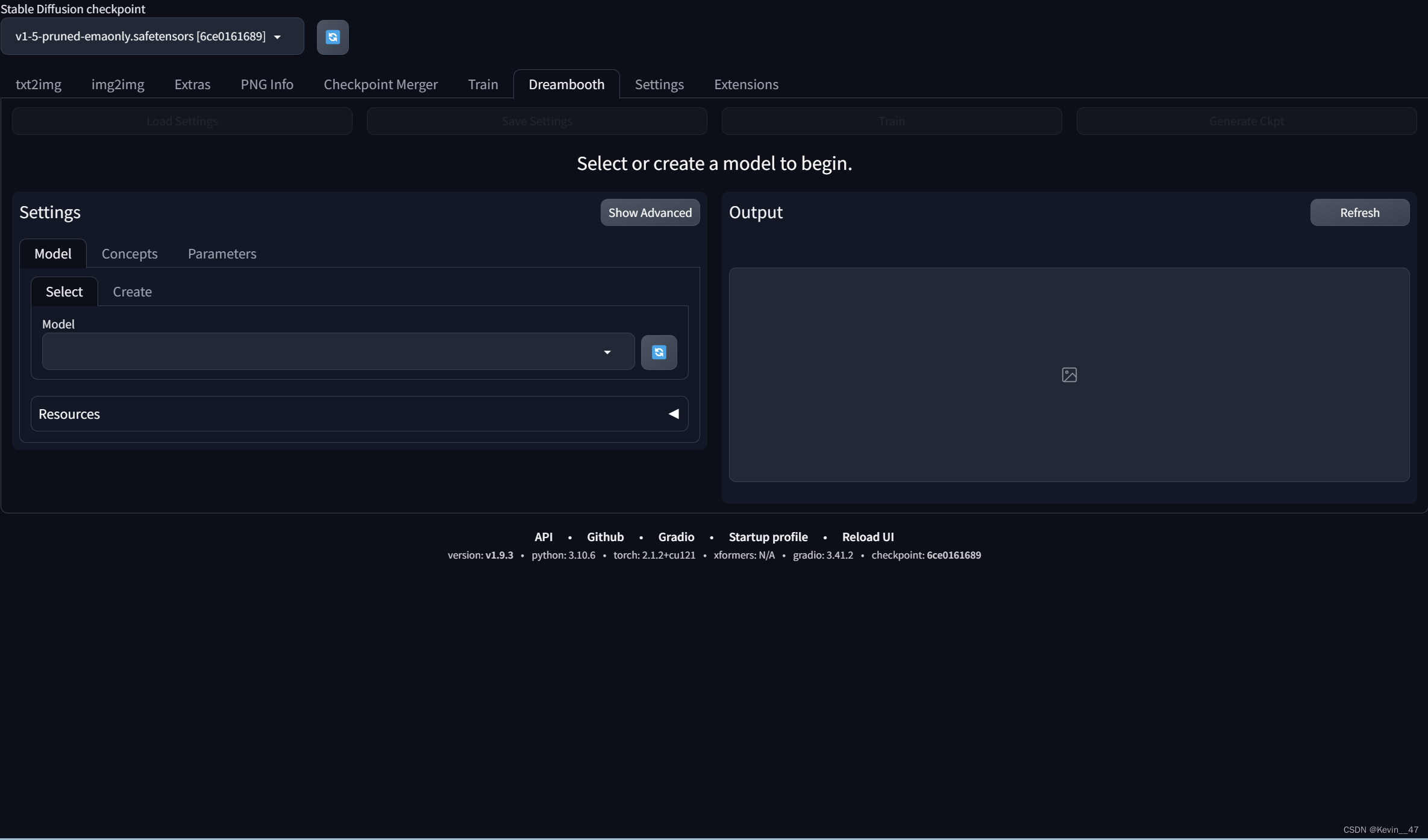
(由于我这里的界面和我所看的视频教程中不太一样,所以我没有使用这里的extension-dreambooth进行训练)
至此,安装过程就基本结束了。
上手使用
直接安装的webui似乎是没有模型的,在安装了上面所说的DreamBooth插件之后,会自动下载一个v1.5-pruned.ckpt的模型,此时加载该模型,进行文生图的测试。以ed sheeran为提示词,设置Sampling steps为150,点击generate进行生成,生成的图片结果如下图所示。

根据教程,我又在C站下载了作者发布的无聊猿模型,模型链接如下:
Apes - apes_v1.0 | Stable Diffusion Checkpoint | Civitai

将下载好的模型文件放到webui存储模型文件的路径下,具体位置如下图所示。
添加完模型文件后需要刷新webui(重新进入),然后在webui中加载这个模型,此时模型的下拉菜单中已经可以看到刚刚添加的模型文件。
以下是我的一些生成结果。




思考
目前的文生图技术感觉只是先把这项技术做出来,暂时还想象不到有什么具体的应用。比如平面设计,或是科研绘图,这些都需要很多细节、色彩的微调,而直接生成的图片是位图不是矢量图,无法满足这样的需求。文生图感觉还是用来预览想象力的一种手段,很多天马行空的想法但是可能实现、绘制一个像样的demo需要较长的时间,此时把想法描述给AI,来进行绘制与实现可以提高效率,为后期的制作提供一个具体的方向。