11. 常用的Web应用程序
Django为开发者提供了常见的Web应用程序,
如会话控制, 缓存机制, CSRF防护, 消息框架, 分页功能, 国际化和本地化, 单元测试和自定义中间件.
内置的Web应用程序大大优化了网站性能, 并且完善了安全防护机制, 同时也提高了开发者的开发效率.
11.1 会话控制
Django内置的会话控制简称为Session, 可以为用户提供基础的数据存储.
数据主要存储在服务器上, 并且网站的任意站点都能使用会话数据.
当用户第一次访问网站时, 网站的服务器将自动创建一个Session对象,
该Session对象相当于该用户在网站的一个身份凭证, 而且Session能存储该用户的数据信息.
当用户在网站的页面之间跳转时, 存储在Session对象中的数据不会丢失,
只有Session过期或被清理时, 服务器才将Session中存储的数据清空并终止该Session.
11.1.1 会话的配置与操作
在4.2.3小节已讲述过Session和Cookie的关系, 本节将简单回顾两者的关系, 说明如下:
● Session存储在服务器端, Cookie存储在客户端, 所以Session的安全性比Cookie高.
● 当获取某用户的Session数据时, 首先从用户传递的Cookie里获取sessionid, 然后根据sessionid在网站服务器找到相应的Session.
● Session存放在服务器的内存中, Session的数据不断增加会造成服务器的负担, 因此存放在Session中的数据不能过于庞大.
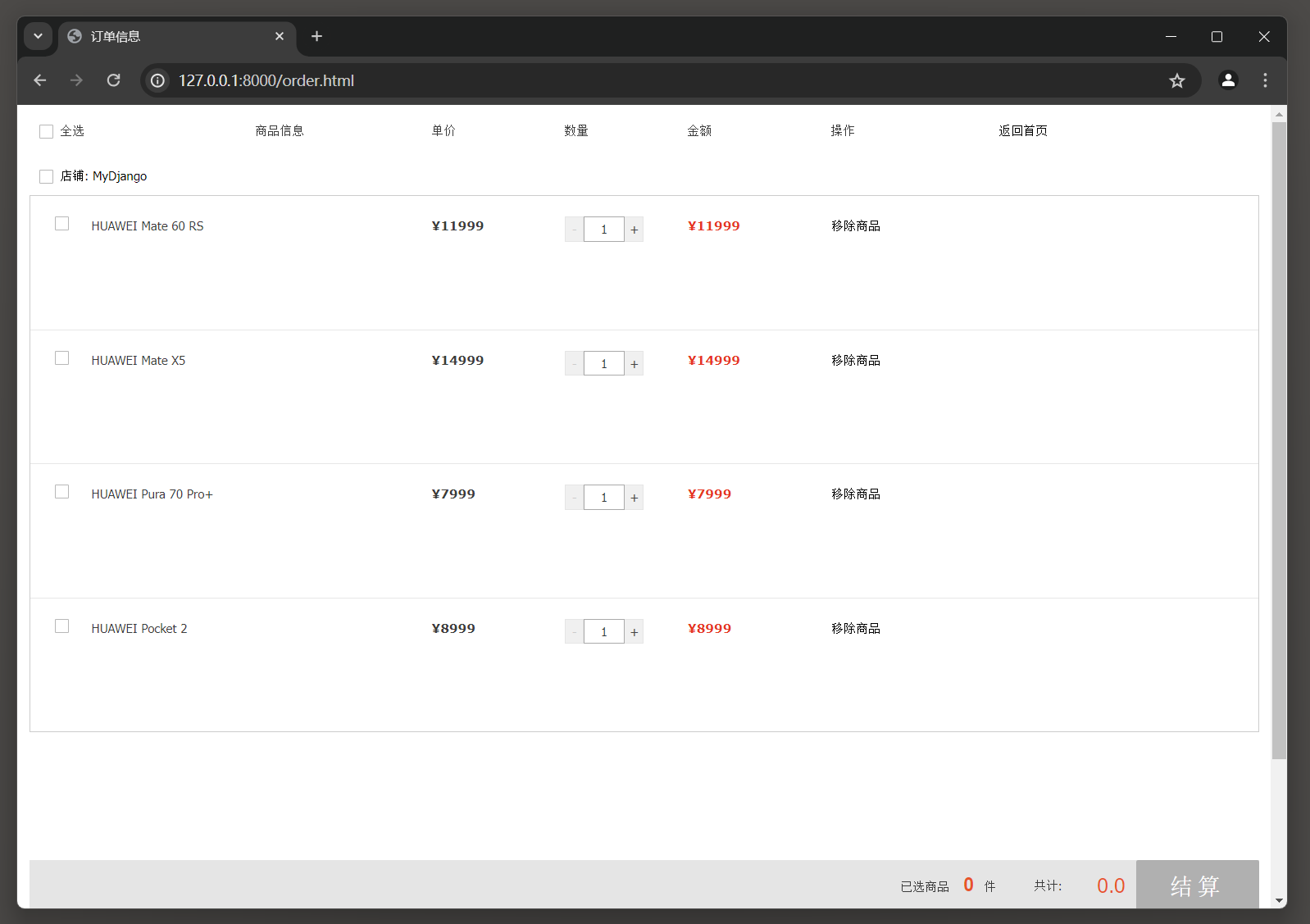
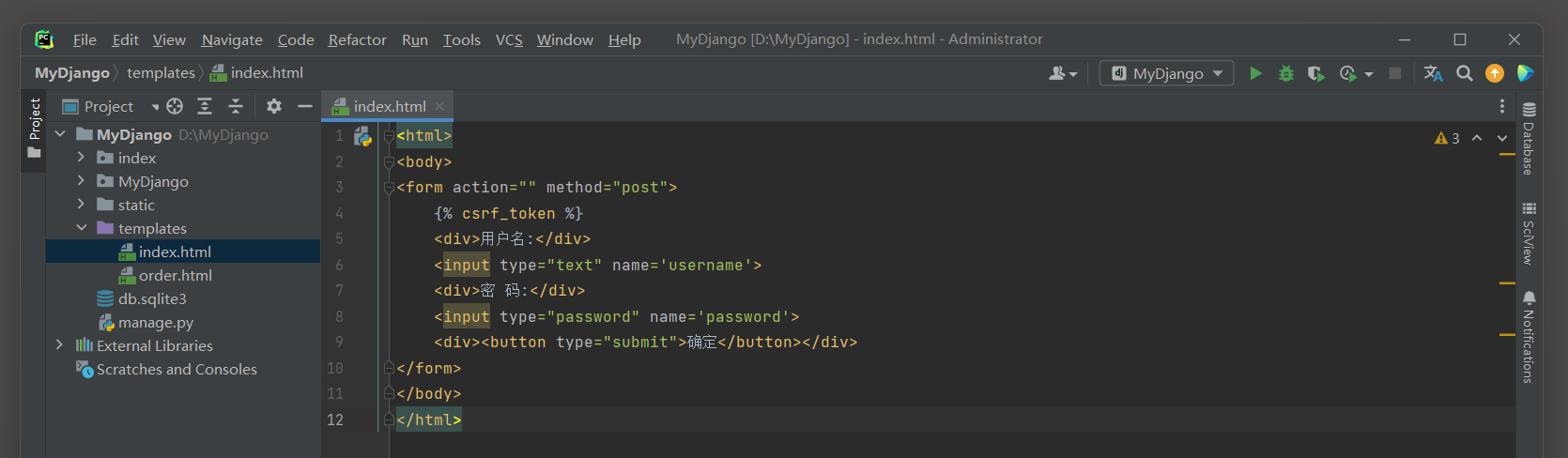
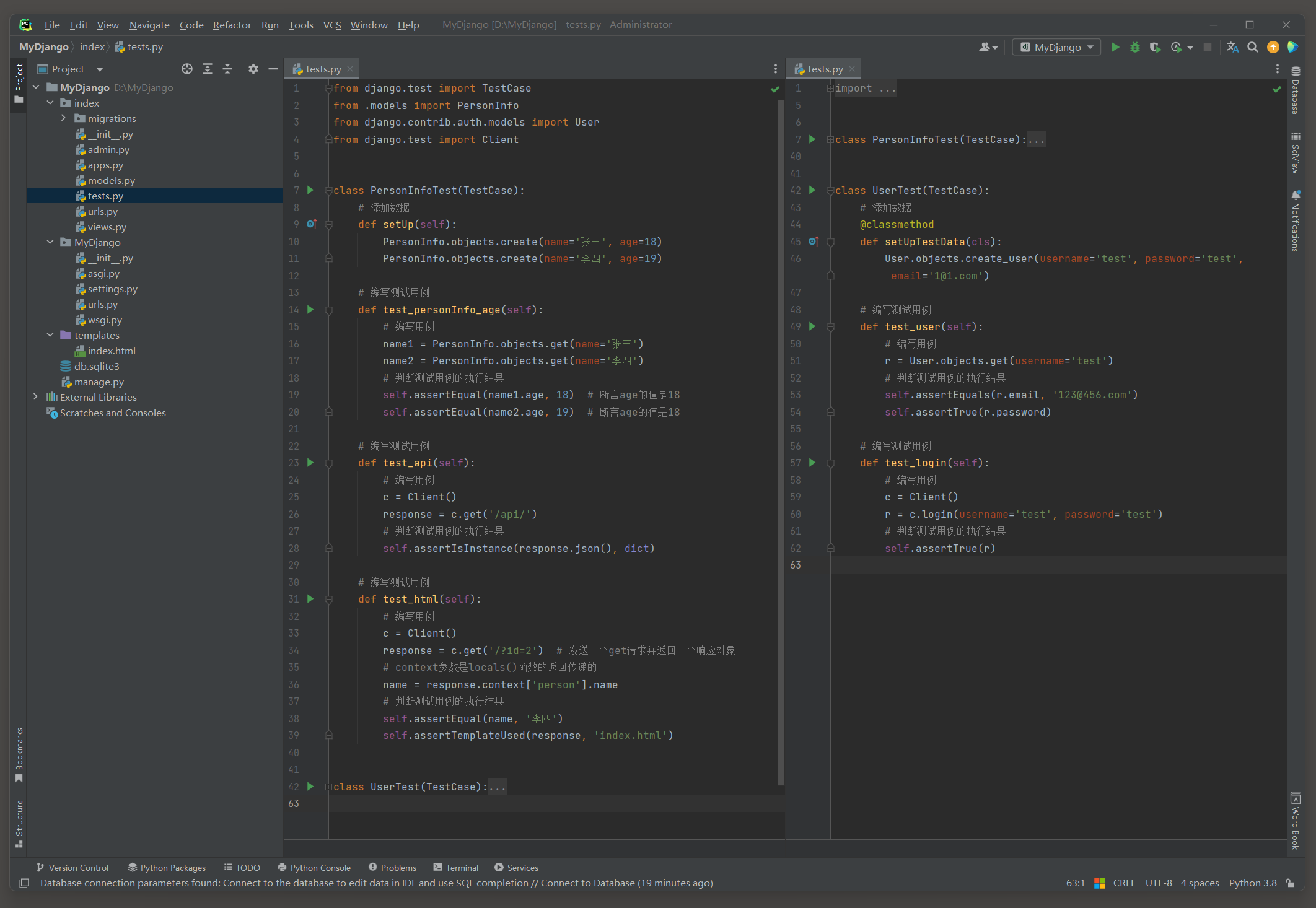
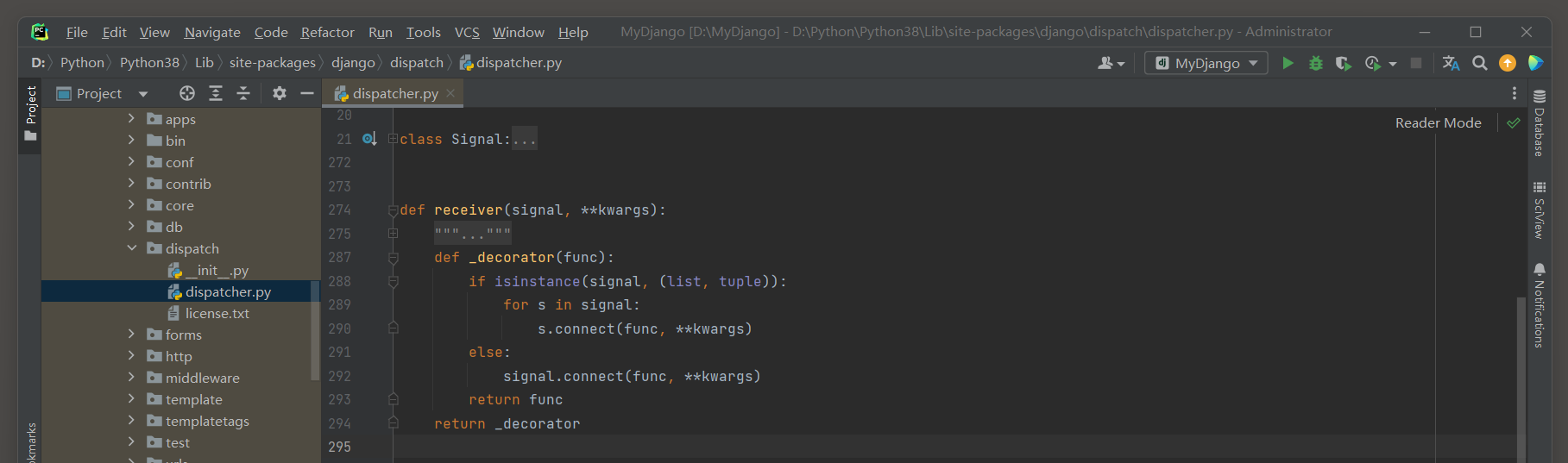
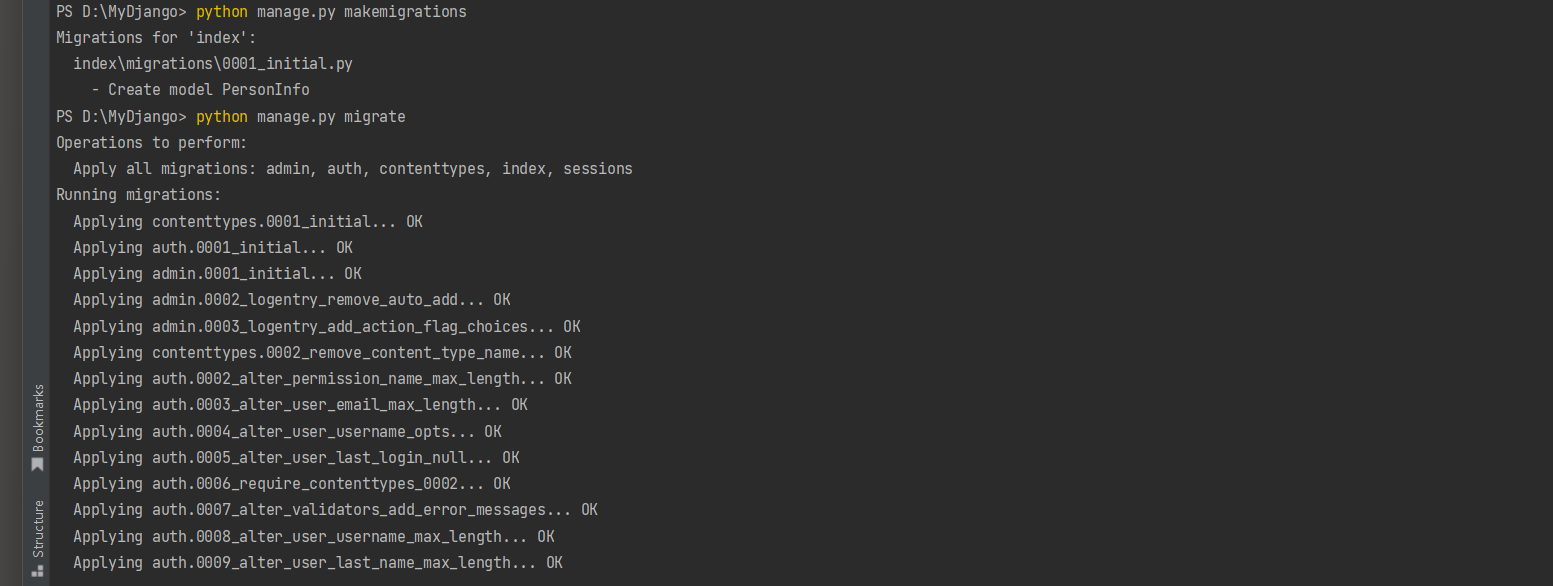
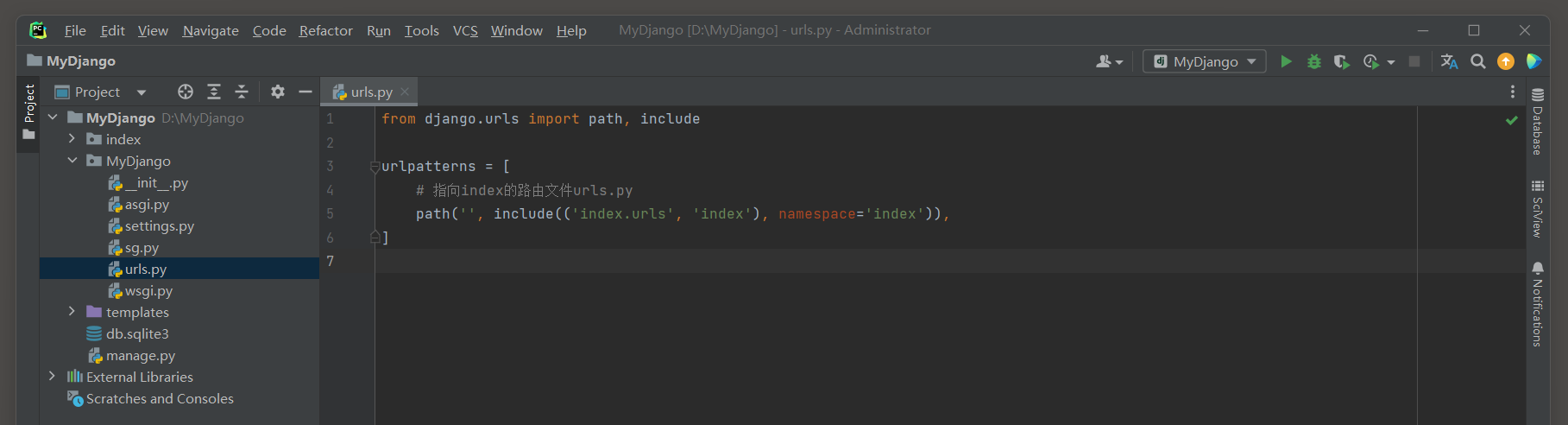
在创建Django项目时, Django已默认启用Session功能,
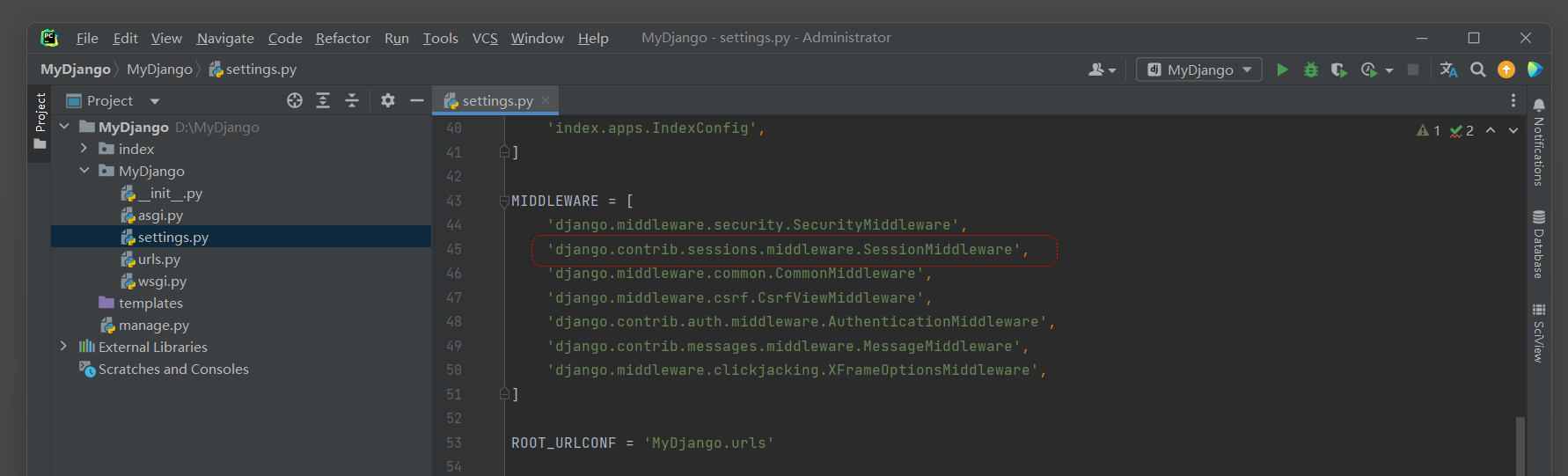
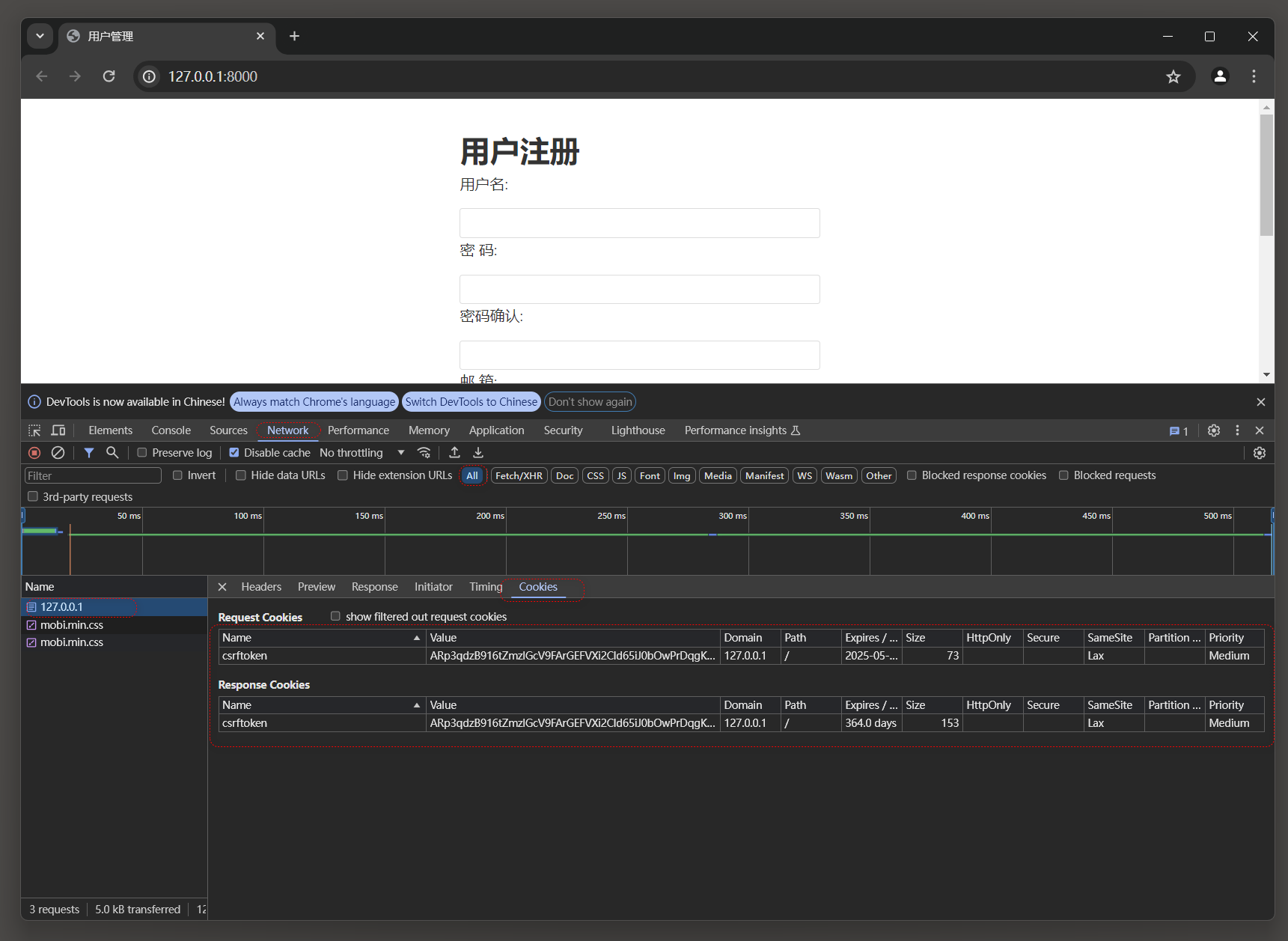
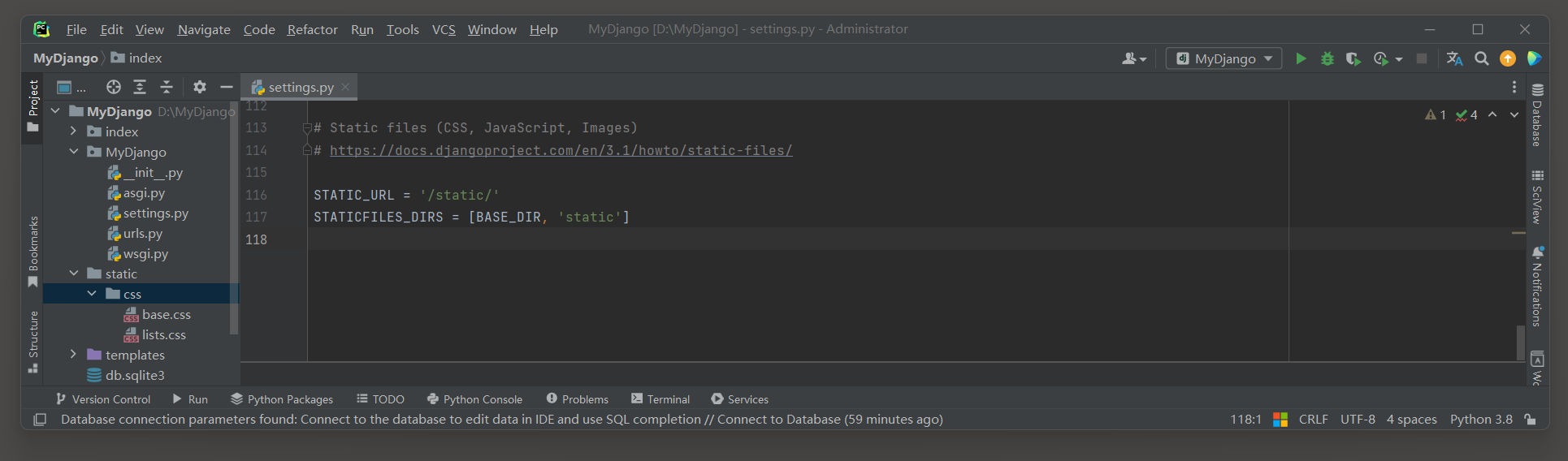
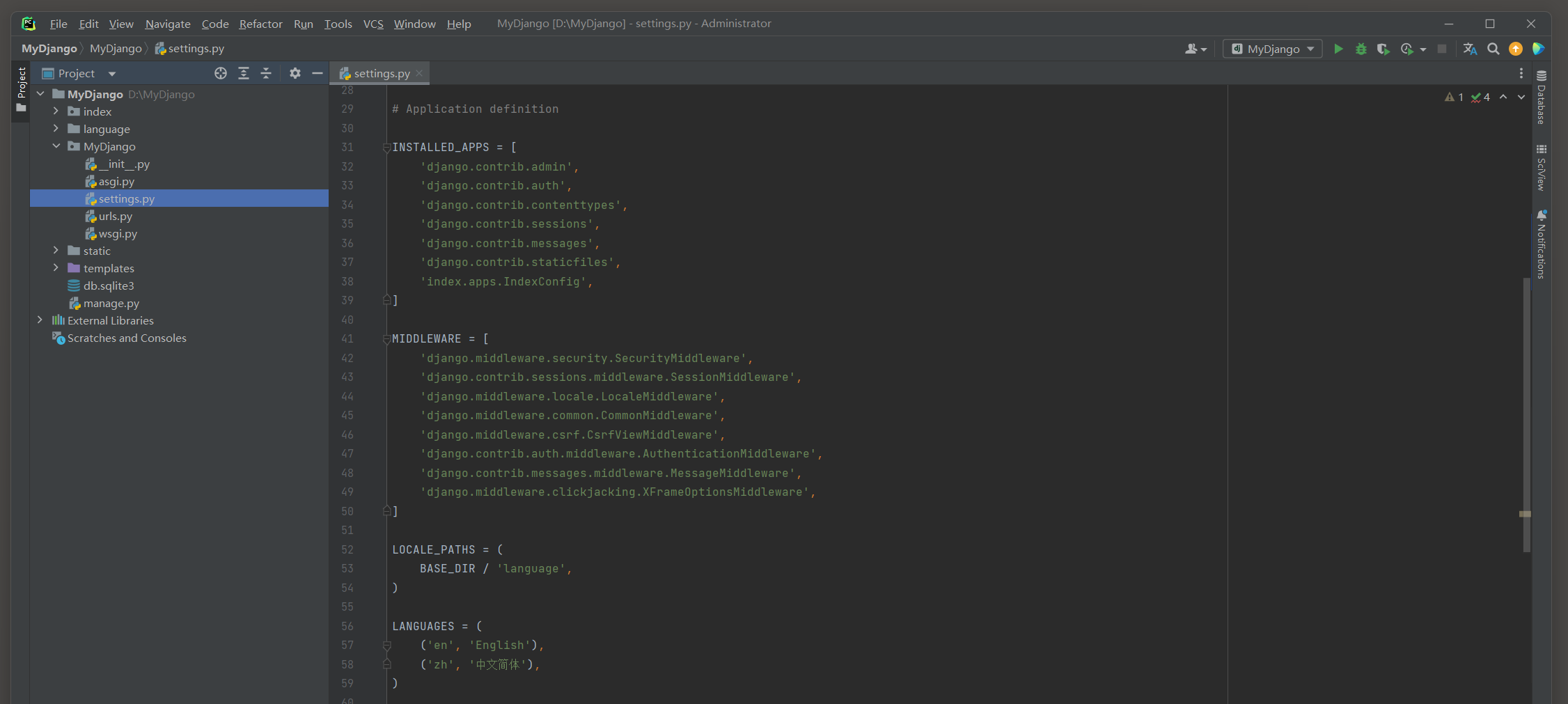
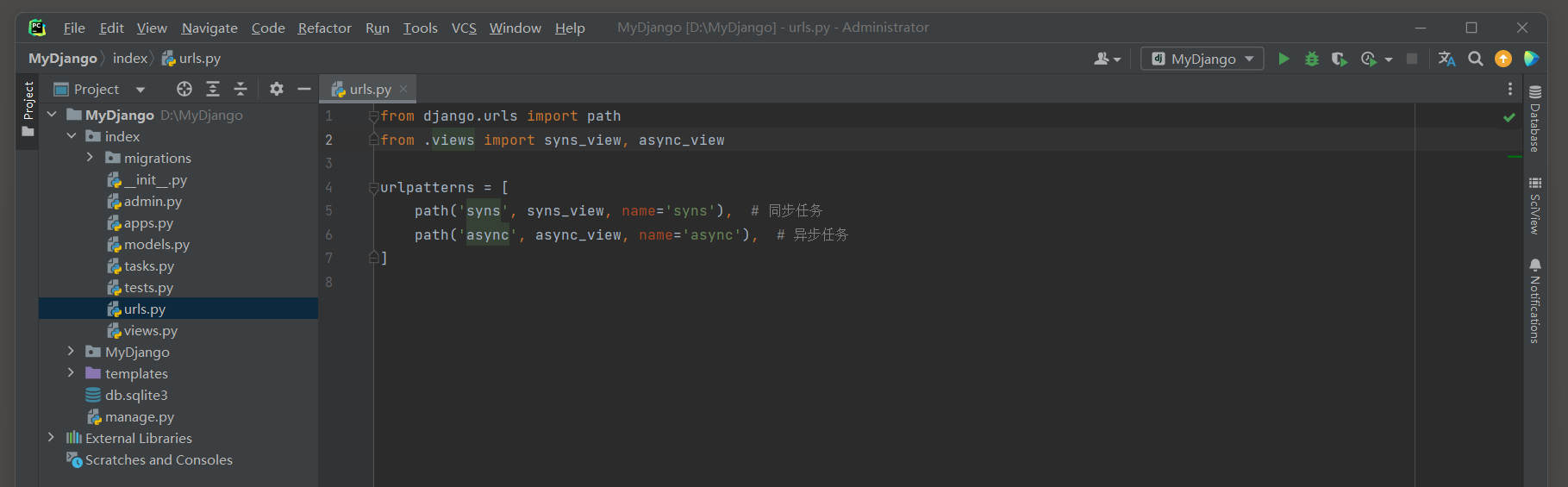
每个用户的Session通过Django的中间件MIDDLEWARE接收和调度处理, 可以在配置文件settings.py中找到相关信息, 如图11-1所示.
图11-1 Session功能配置
当访问网站时, 所有的HTTP请求都经过中间件处理,
而会话中间件SessionMiddleware会判断当前请求的用户身份是否存在, 并根据判断结果执行相应的程序处理.
会话中间件SessionMiddleware相当于HTTP请求接收器, 根据请求信息做出相应的调度,
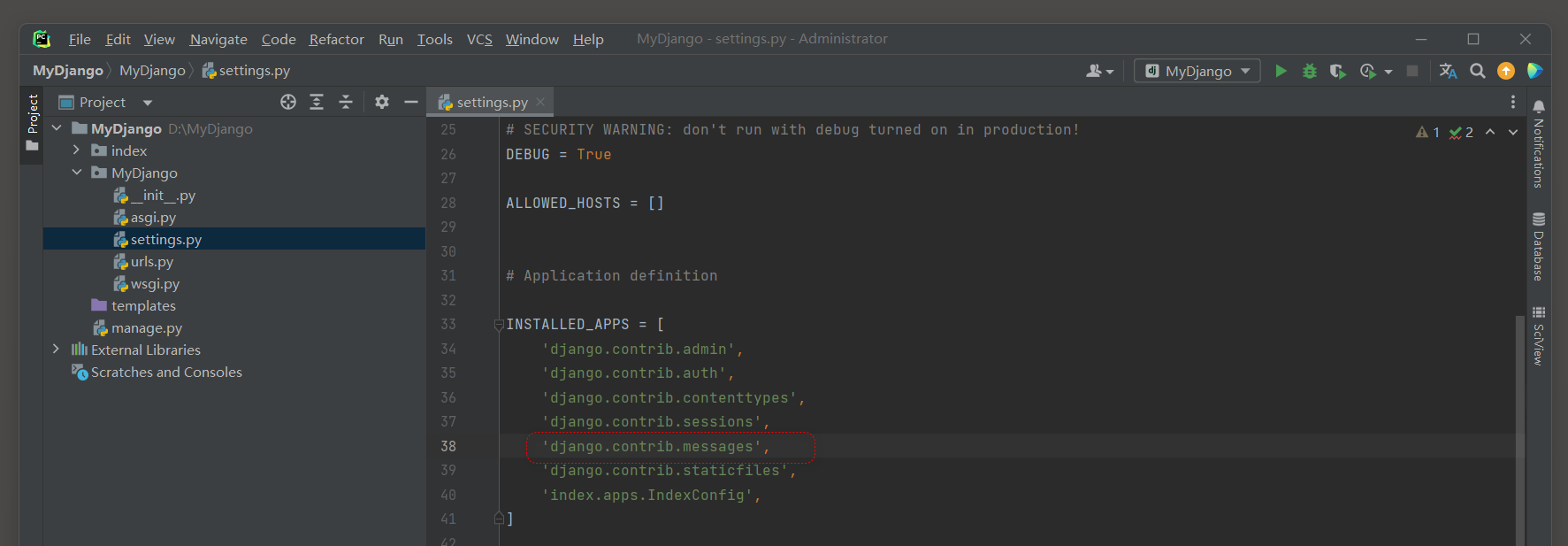
而程序的执行则由settings.py的配置属性INSTALLED_APPS的django.contrib.sessions完成, 其配置信息如图11-2所示.
图11-2 Session的处理程序
django.contrib.sessions实现了Session的创建和操作处理, 如创建或存储用户的Session对象, 管理Session的生命周期等.
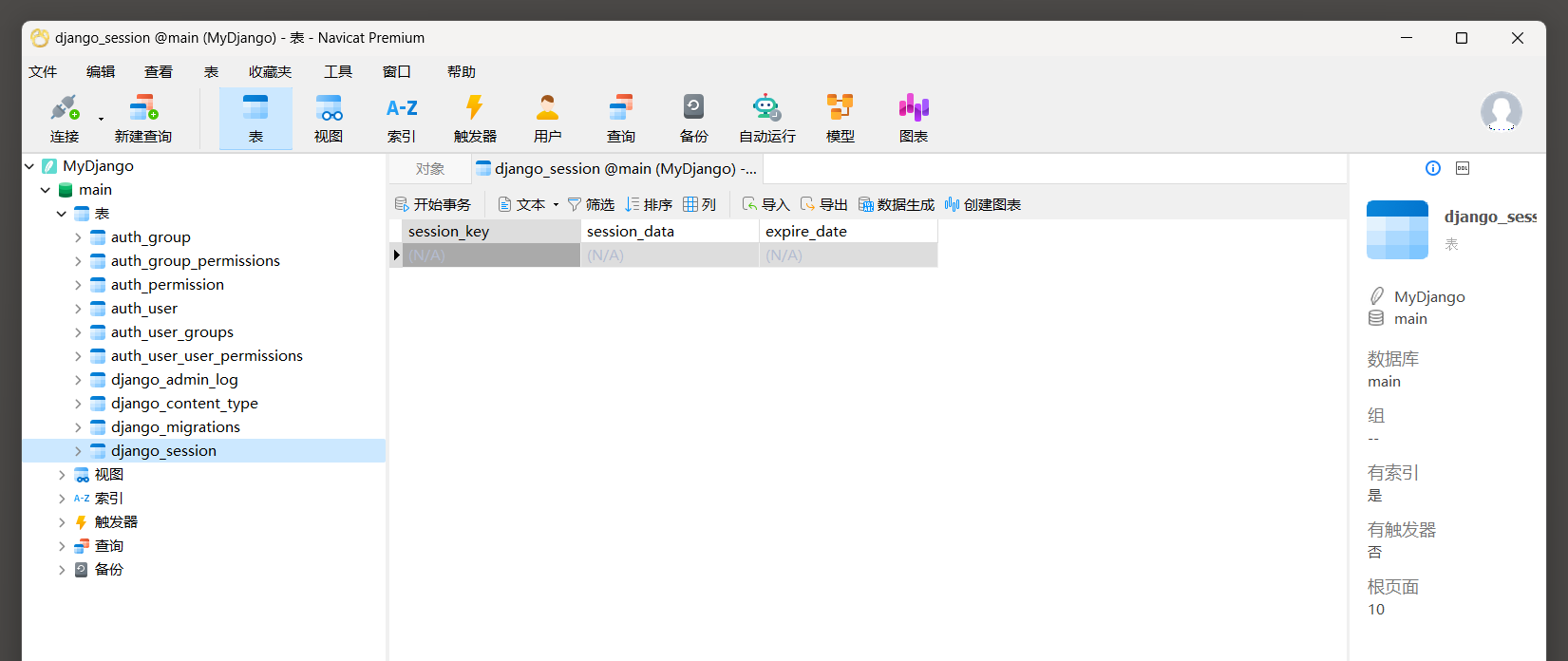
它默认使用数据库存储Session信息, 执行数据迁移后, 在数据库中可以看到数据表django_session, 如图11-3所示.
图11-3 数据表django_session
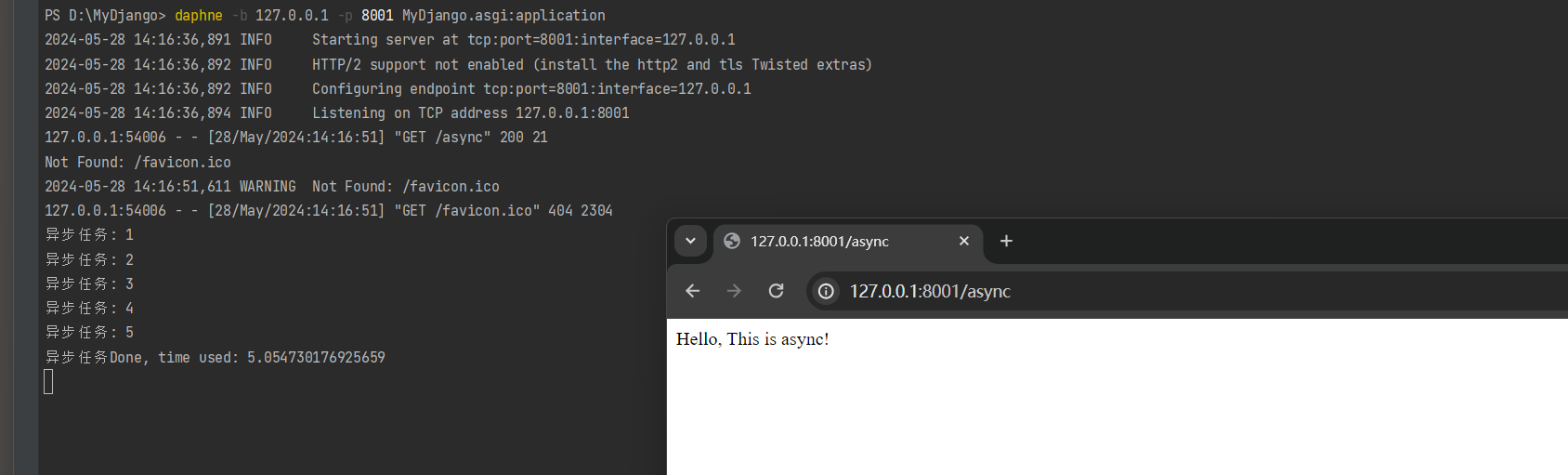
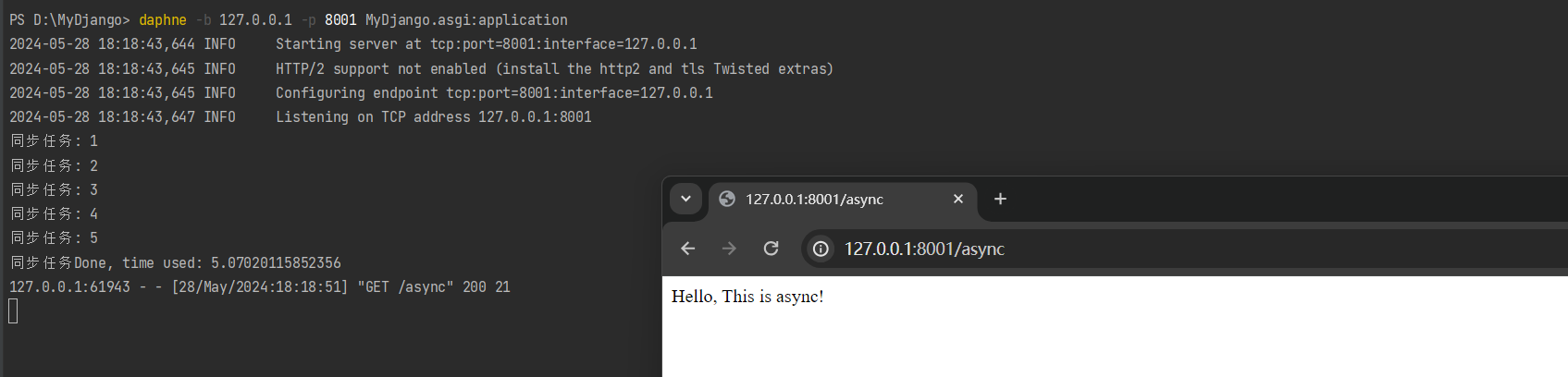
以10.6节的MyDjango项目为例, 我们将通过例子来讲述Session运行机制.
首先清除浏览器的历史记录, 确保以游客身份访问MyDjango, 即用户在未登录状态下访问Django.
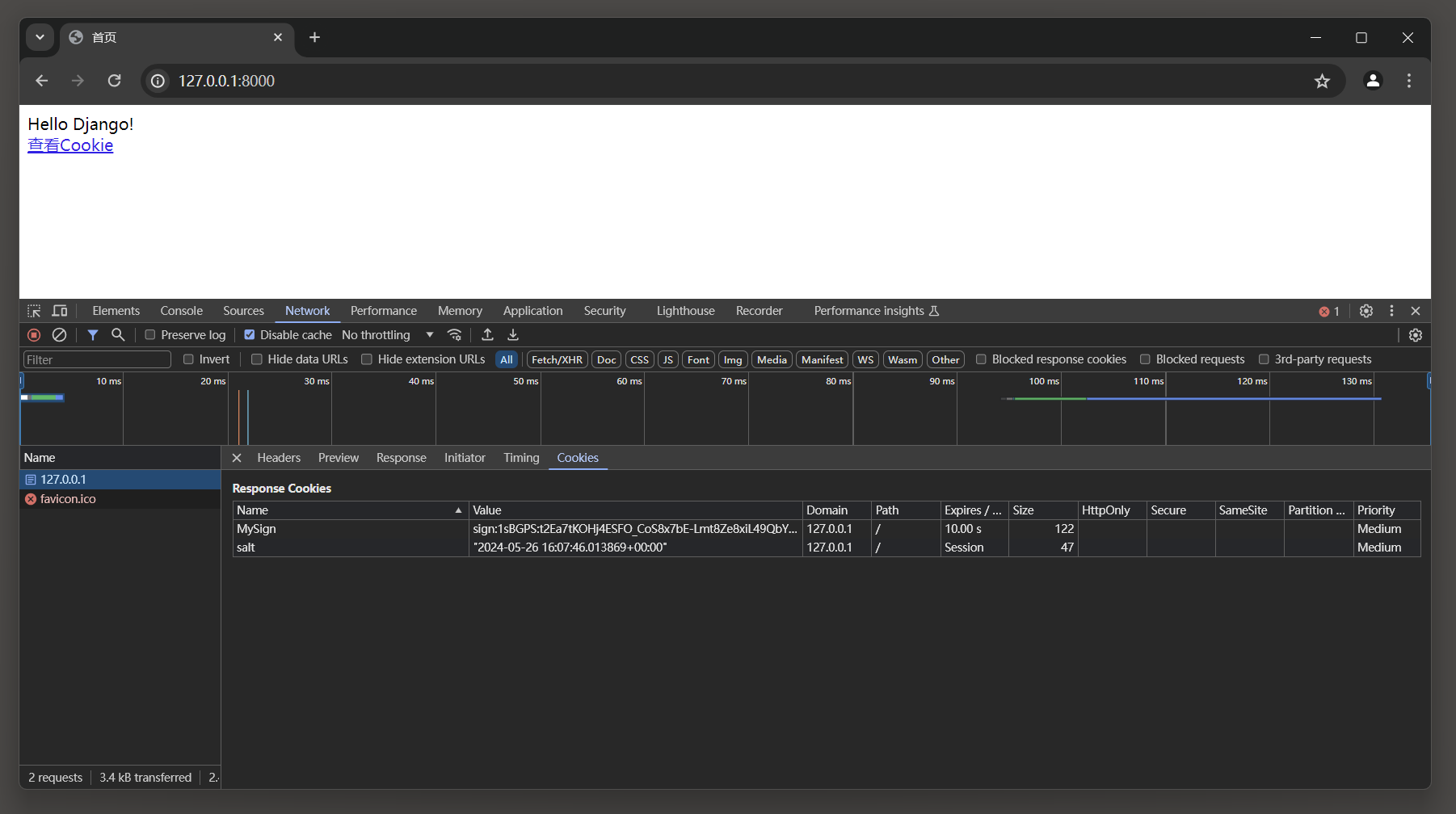
在浏览器打开开发者工具并访问: 127.0.0.1:8000, 从开发者工具的Network标签的All选项里找到127.0.0.1:8000的请求信息,
若当前Cookie没有生成sessionid, 则说明一般情况下, Django不会为游客身份创建Session, 如图11-4所示.
图11-4 Cookie信息
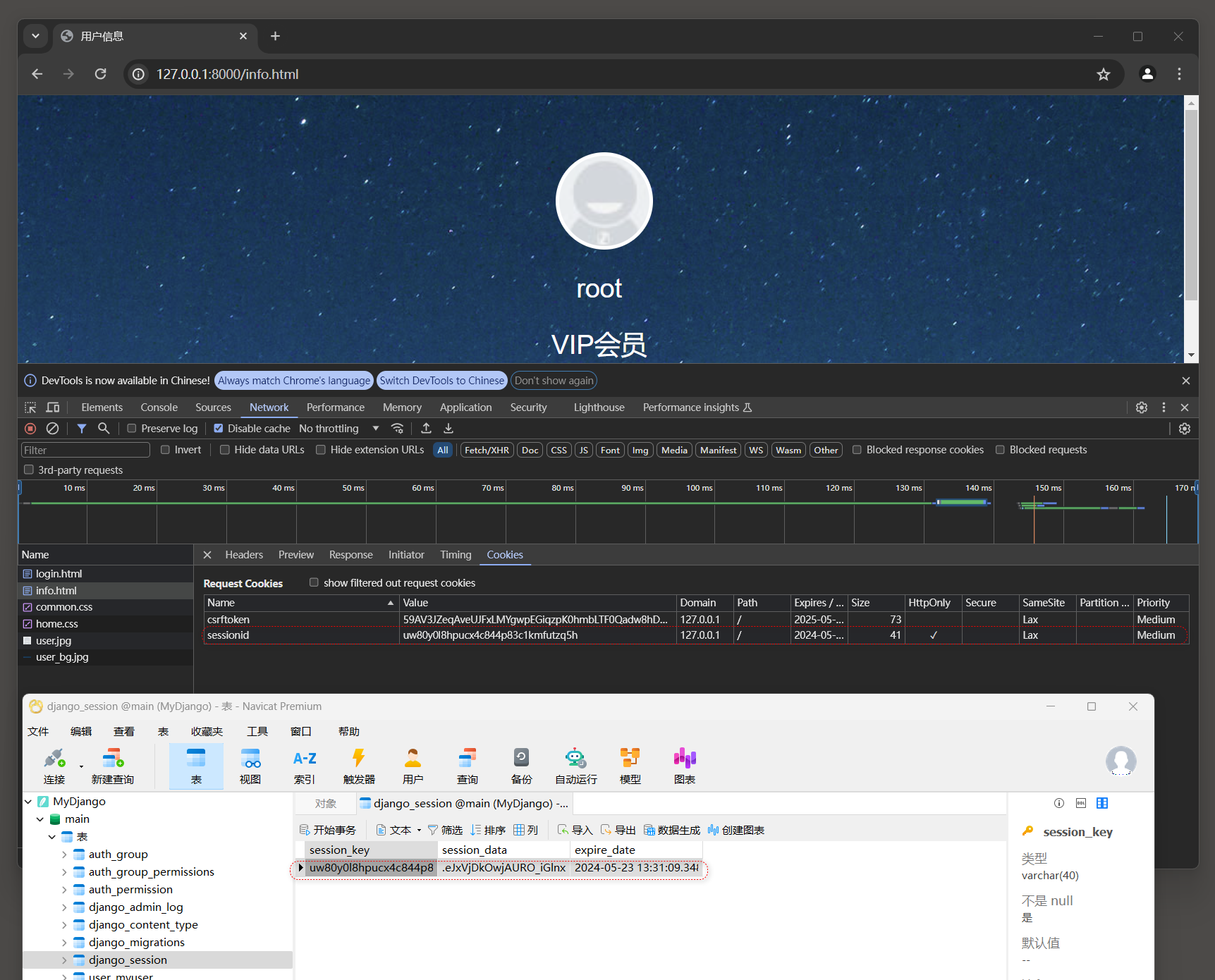
访问用户登录页面(127.0.0.1:8000/login.html)并完成用户登录, 打开用户中心页面的请求信息,
可以看到Cookie生成带有sessionid的数据, 并且数据表django_session记录了当前sessionid的信息, 如图11-5所示.
图11-5 Cookie的sessionid信息
在登录状态下再次访问网站, 浏览器将Cookie信息发送到MyDjango,
Django从Cookie获取sessionid并与数据表django_session的session_key进行匹配验证,
从而确定当前访问的用户信息, 保证每个用户的数据信息不会杂乱无章.
Session的数据存储默认使用数据库保存, 如果想变更Session的保存方式,
那么可以在settings.py中添加配置信息SESSION_ENGINE, 该配置可以指定Session的保存方式.
Django提供了5种Session的保存方式, 分别如下:
# 1. 数据库保存方式
# Django默认的保存方式, 使用该方法无须在settings.py中设置
SESSION_ENGINE = 'django.contrib.sessions.backends.db'
# 2. 以文件形式保存
SESSION_ENGINE = 'django.contrib.sessions.backends.file'
# 使用文本保存可设置文件保存路径
# /MyDjango代表将文本保存在项目MyDjango的根目录
SESSION_FILE_PATH = '/MyDjango'
# 3. 以缓存形式保存
SESSION_ENGINE = 'django.contrib.sessions.backends.cache'
# 设置缓存名, 默认是内存缓存方式, 此处的设置与缓存机制的设置相关
SESSION_CACHE_ALIAS = 'default'
# 4. 以数据库+缓存形式保存
SESSION_ENGINE = 'django.contrib.sessions.backends.cached_db'
# 5. 以Cookie形式保存
SESSION_ENGINE = 'django.contrib.sessions.backends.signed_cookies'
SESSION_ENGINE用于配置服务器Session的保存方式, 而浏览器的Cookie用于记录数据表django_session的session_key,
Session还可以设置相关的配置信息, 如生命周期, 传输方式和保存路径等, 只需在settings.py中添加配置属性即可, 说明如下:
● SESSION_COOKIE_NAME = "sessionid": 浏览器的Cookie以键值对的形式保存数据表django_session的session_key,
该配置是设置session_key的键, 默认值为sessionid.
● SESSION_COOKIE_PATH = "/": 设置浏览器的Cookie生效路径, 默认值为'/', 即127.0.0.1:8000.
● SESSION_COOKIE_DOMAIN = None: 设置浏览器的Cookie生效域名.
● SESSION_COOKIE_SECURE = False: 设置传输方式, 若为False, 则使用HTTP, 否则使用HTTPS.
● SESSION_COOKIE_HTTPONLY = True: 是否只能使用HTTP协议传输.
● SESSION_COOKIE_AGE = 1209600: 设置Cookie的有效期, 默认时间为两周.
● SESSION_EXPIRE_AT_BROWSER_CLOSE = False: 是否关闭浏览器使得Cookie过期, 默认值为False.
● SESSION_SAVE_EVERY_REQUEST = False: 是否每次发送后保存Cookie, 默认值为False.
了解Session的运行原理和相关配置后, 最后讲解Session的读写操作, Session的数据类型可理解为Python的字典类型,
主要在视图函数中执行读写操作, 并且从用户请求对象中获取, 即来自视图函数的参数request.
Session的读写如下:
# request为视图函数的参数request
# 获取存储在Session的数据k1, 若k1不存在, 则会报错
request.session['k1']
# 获取存储在Session的数据k1, 若k1不存在, 则为空值
# get和setdefault实现的功能是一致的
request.session.get('k1', '')
request.session.setdefault('k1', '')
# 设置Session的数据, 键为k1, 值为123
request.session['k1'] = 123
# 删除Session中k1的数据
del request.session['k1']
# 删除整个Session
request.session.clear()
# 获取Session的键
request.session.keys()
# 获取Session的值
request.session.values()
# 获取Session的session_key
# 即数据表django_session的字段session_key
request.session.session_key
11.1.2 使用会话实现商品抢购
本节将通过实例来讲述如何使用Session实现商品抢购功能.
以MyDjango为例, 创建项目应用index, 在index中创建路由文件urls.py,
然后在MyDjango的根目录创建静态资源文件夹static和模板文件夹templates,
分别放置静态资源和模板文件index.html和order.html.
项目的目录结构如图11-6所示.
图11-6 MyDjango的目录结构
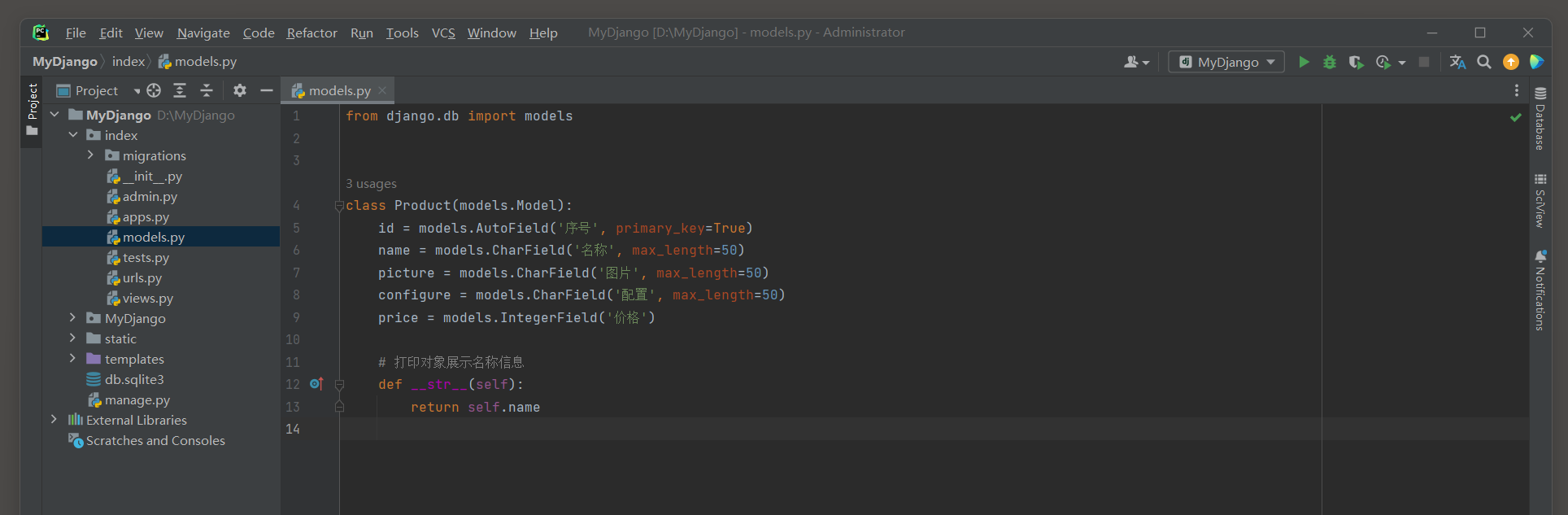
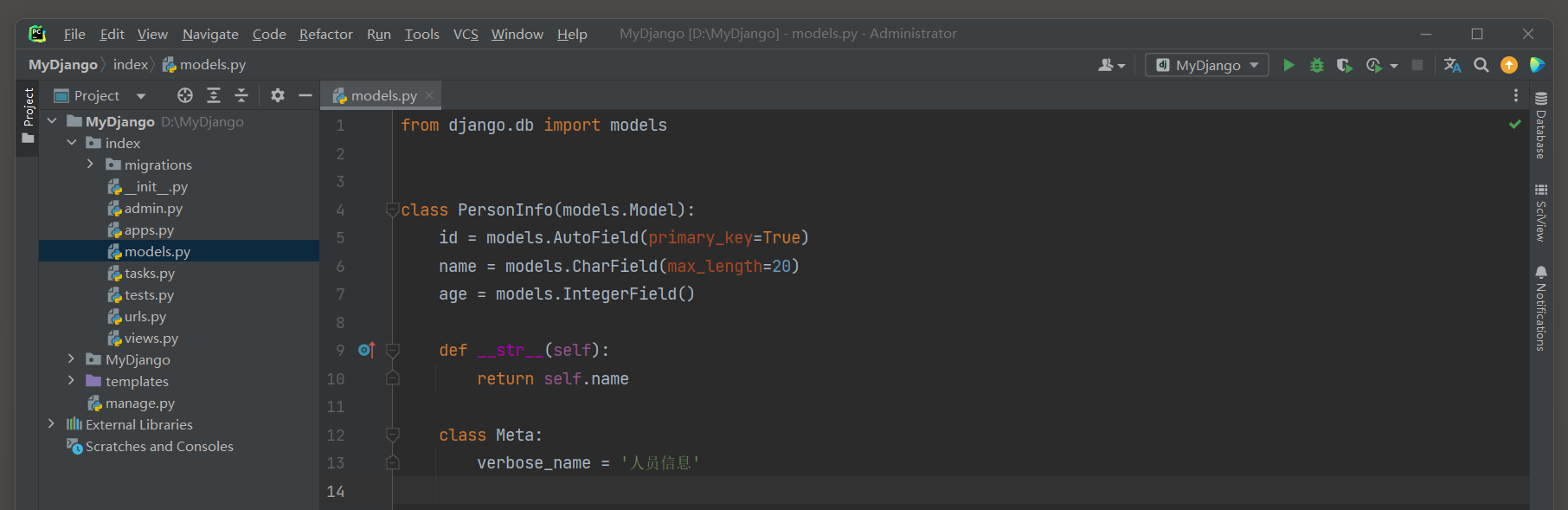
在index的models.py中定义模型Product, 该模型设有6个字段, 其作用是记录商品信息, 在商城首页生成商品列表.
模型Product的定义过程如下:
# index 的 models.py
from django.db import models
class Product(models.Model):
id = models.AutoField('序号', primary_key=True)
name = models.CharField('名称', max_length=50)
picture = models.CharField('图片', max_length=50)
configure = models.CharField('配置', max_length=50)
price = models.IntegerField('价格')
# 打印对象展示名称信息
def __str__(self):
return self.name
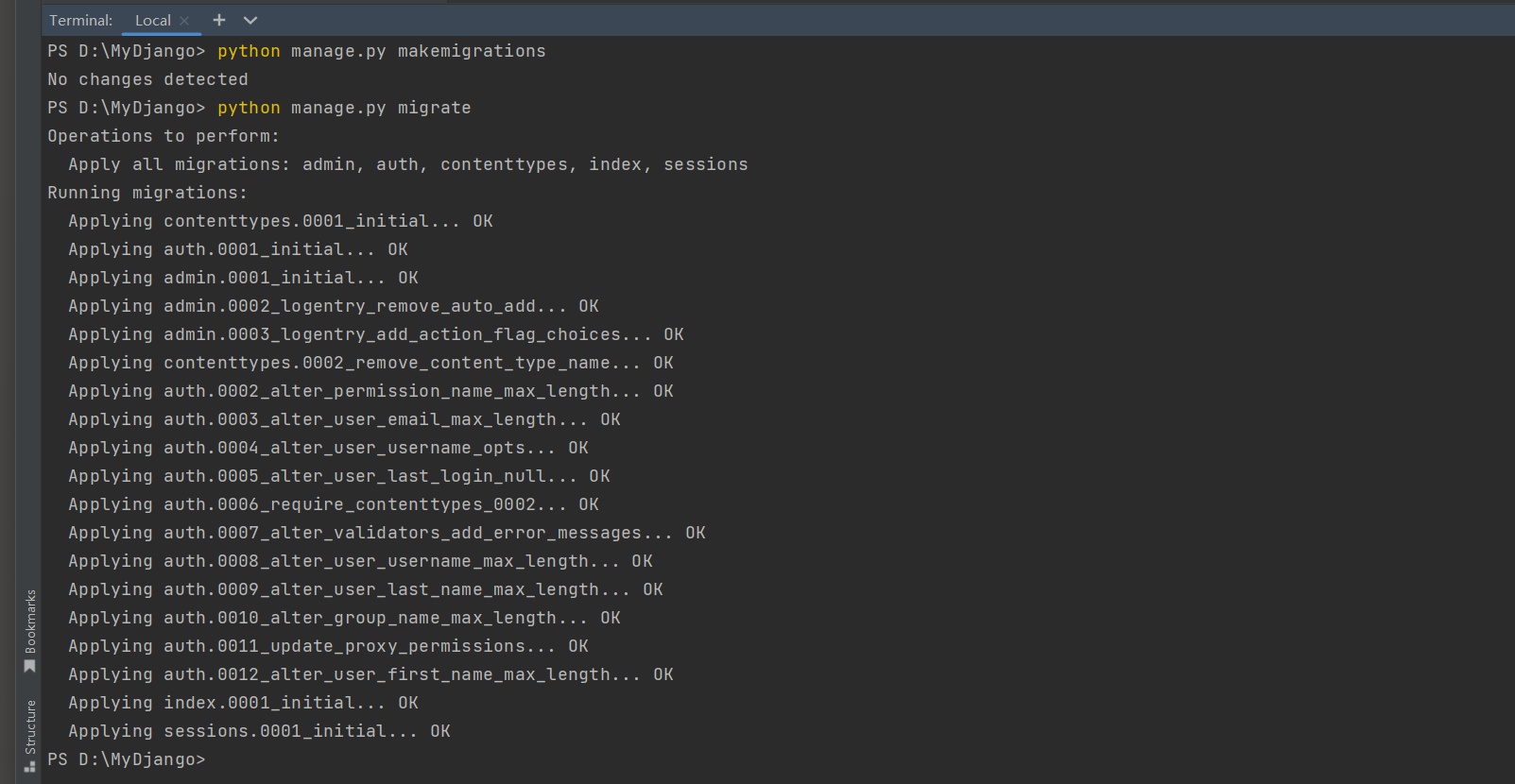
将已定义的模型Product执行数据迁移.
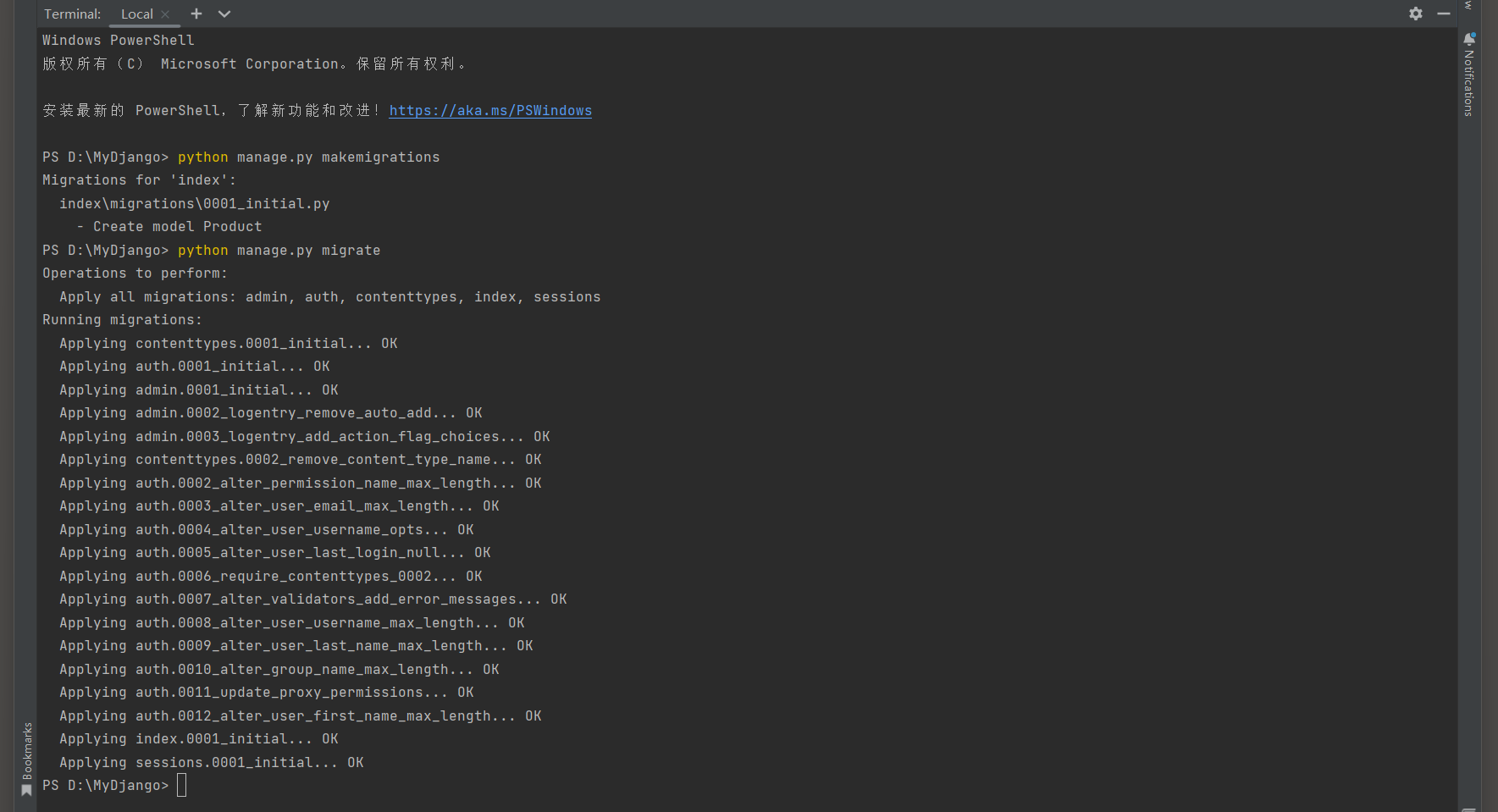
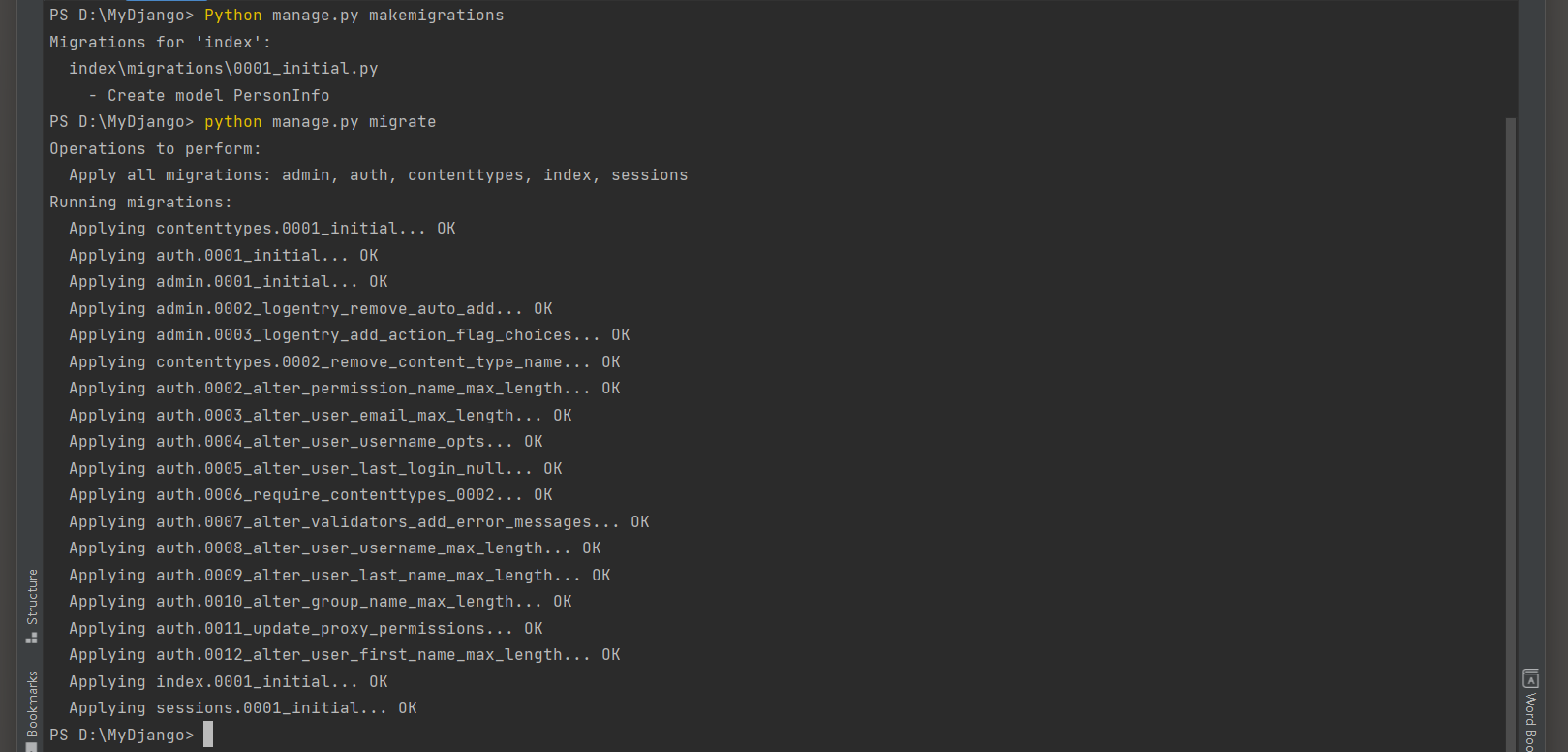
PS D:\MyDjango> python manage.py makemigrations
Migrations for 'index':
index\migrations\0001_initial.py
- Create model Product
PS D:\MyDjango> python manage.py migrate
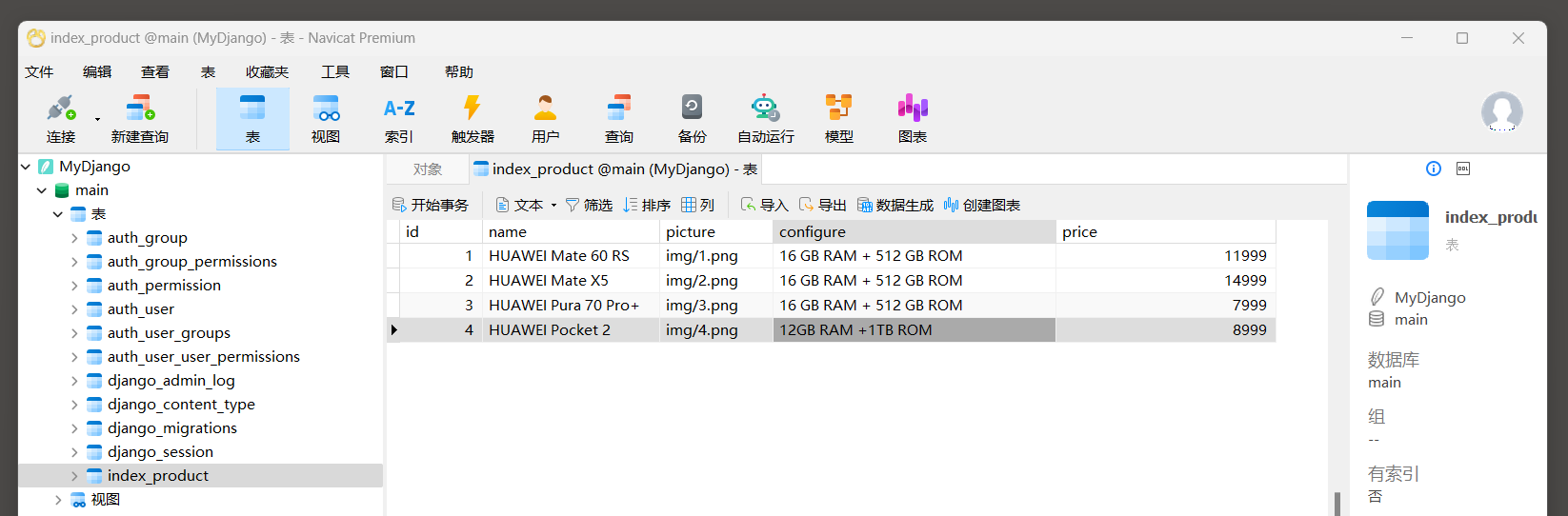
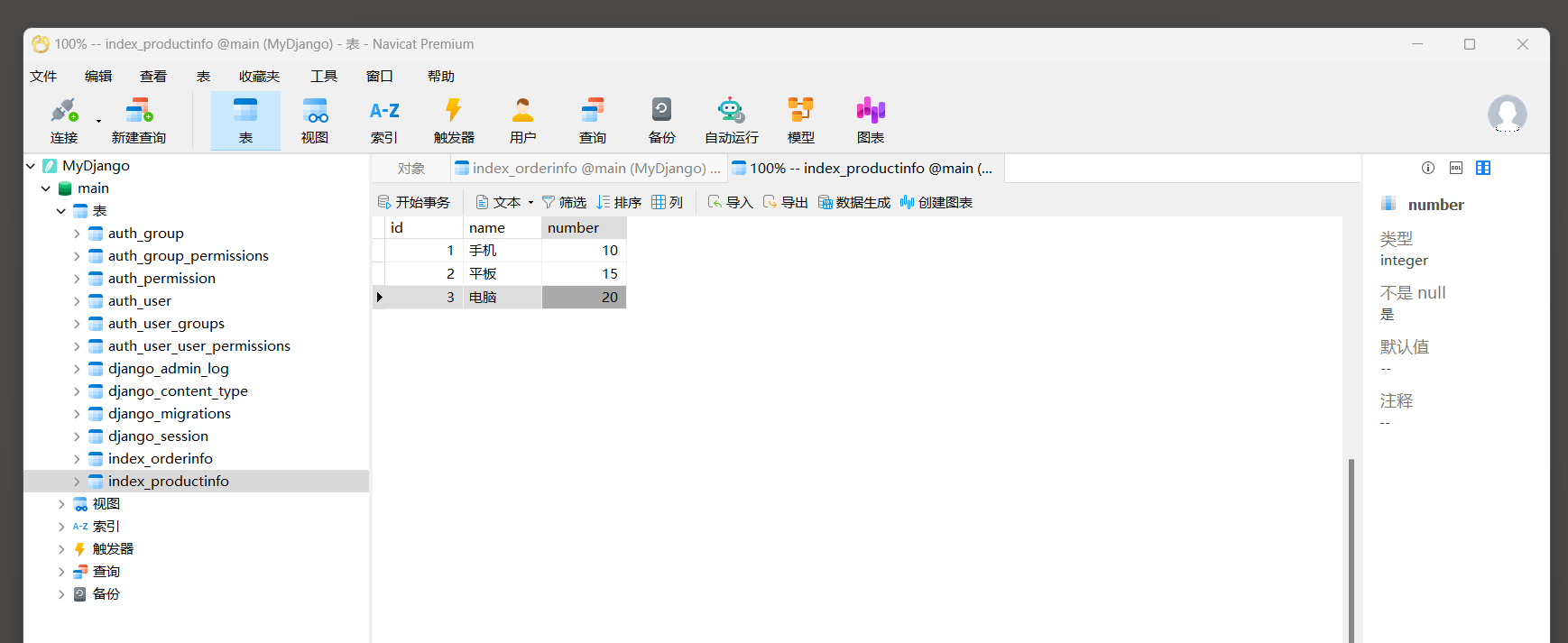
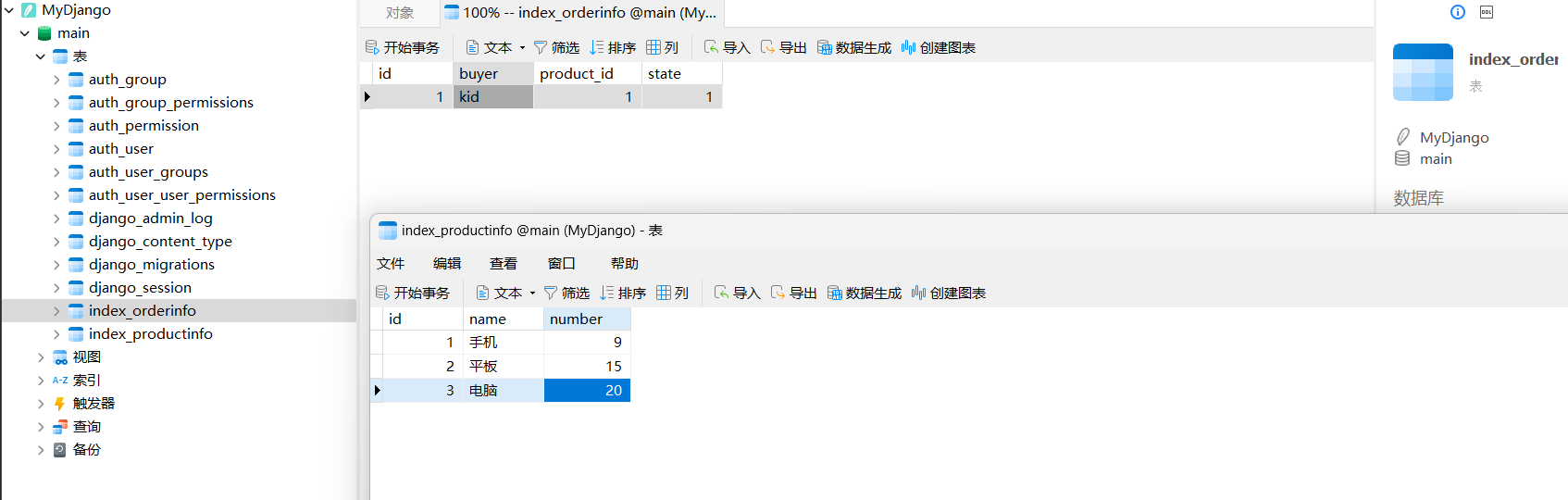
在MyDjango的数据库文件db.sqlite3中创建数据表, 并在数据表index_product中添加商品信息, 如图11-7所示.
图11-7 数据表index_product
-- sql语句:
INSERT INTO "main"."index_product" ("id", "name", "picture", "configure", "price")
VALUES (1, 'HUAWEI Mate 60 RS', 'img/1.png', '16 GB RAM + 512 GB ROM', 11999);
INSERT INTO "main"."index_product" ("id", "name", "picture", "configure", "price")
VALUES (2, 'HUAWEI Mate X5', 'img/2.png', '16 GB RAM + 512 GB ROM', 14999);
INSERT INTO "main"."index_product" ("id", "name", "picture", "configure", "price")
VALUES (3, 'HUAWEI Pura 70 Pro+', 'img/3.png', '16 GB RAM + 512 GB ROM', 7999);
INSERT INTO "main"."index_product" ("id", "name", "picture", "configure", "price")
VALUES (4, 'HUAWEI Pocket 2', 'img/4.png', '12GB RAM +1TB ROM', 8999);
# 配置静态文件
STATIC_URL = '/static/'
STATICFILES_DIRS = [BASE_DIR / 'static']
完成MyDjango的环境搭建后, 下一步开发商品抢购功能, 首先定义Admin后台系统, 商城首页和订单页面的路由信息.
Admin后台系统主要为用户提供登录页面; 商城首页和订单页面实现商品抢购功能.
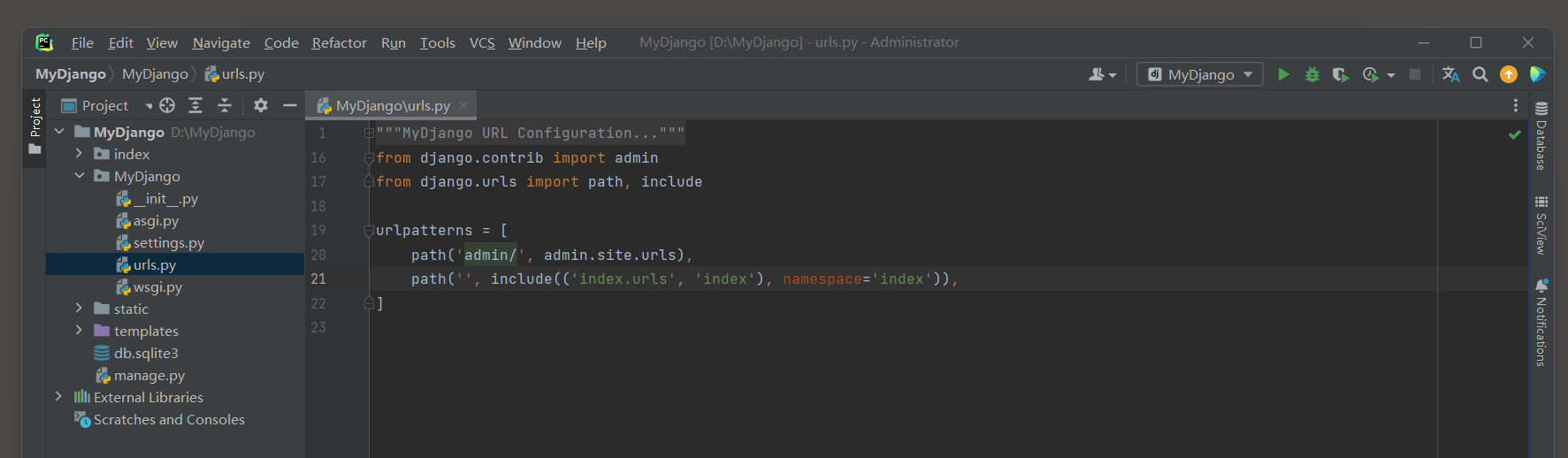
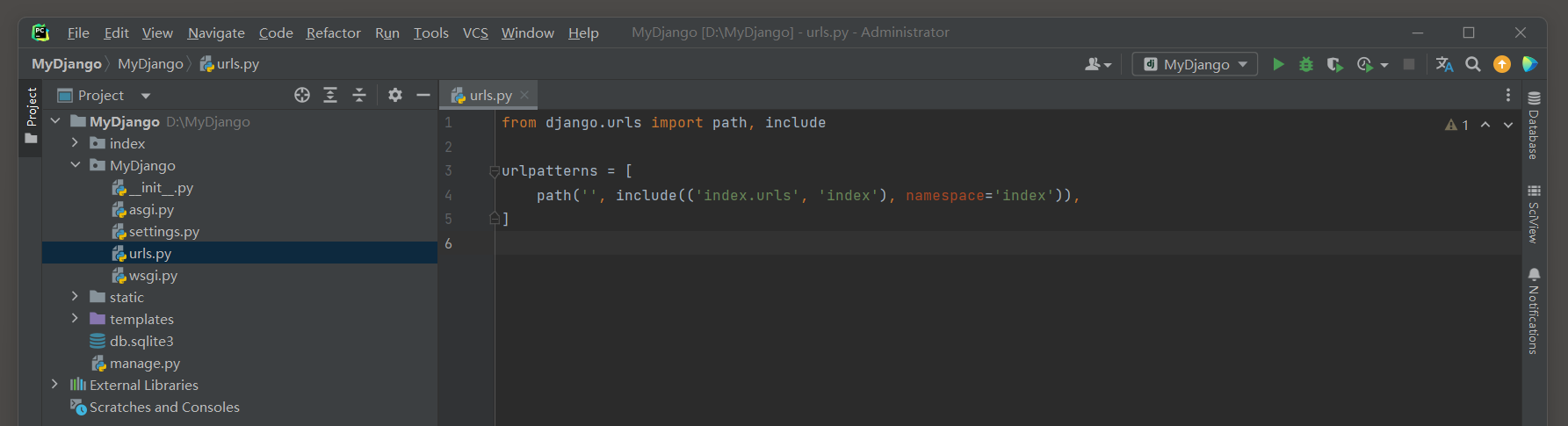
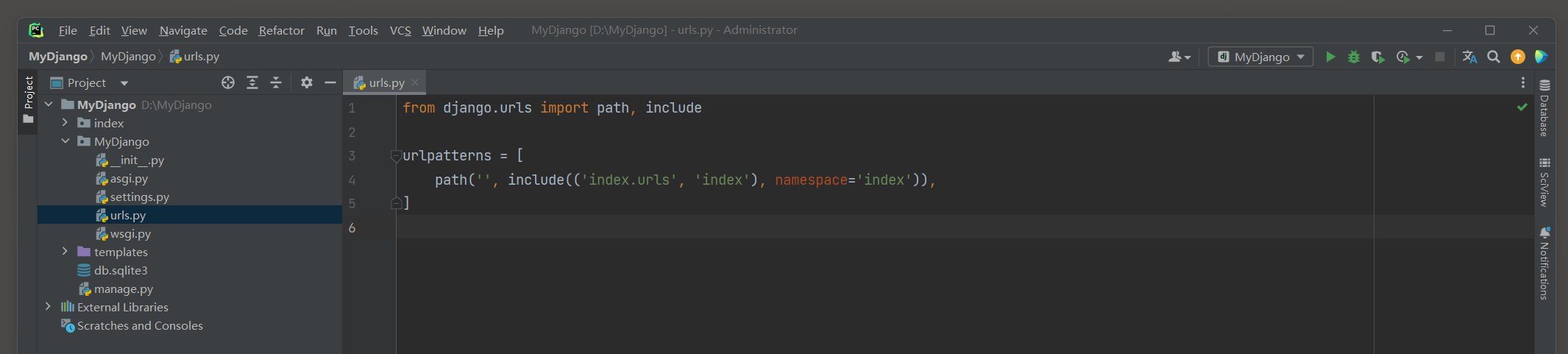
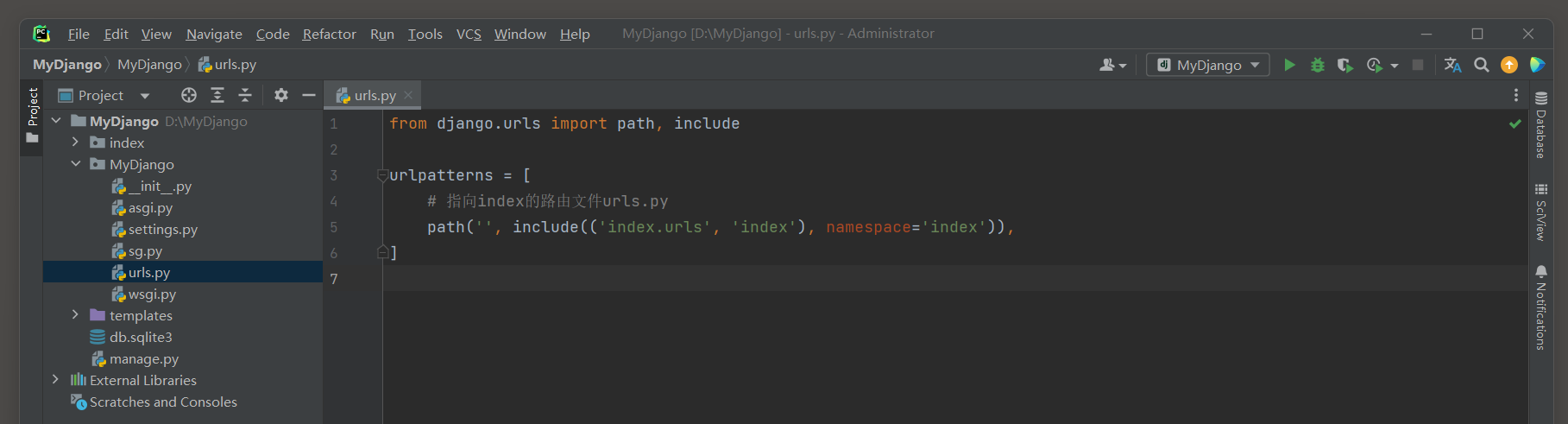
MyDjango的urls.py和index的urls.py的路由定义如下:
# MyDjango 的 urls.py
from django.contrib import admin
from django.urls import path, include
urlpatterns = [
path('admin/', admin.site.urls),
path('', include(('index.urls', 'index'), namespace='index'))
]
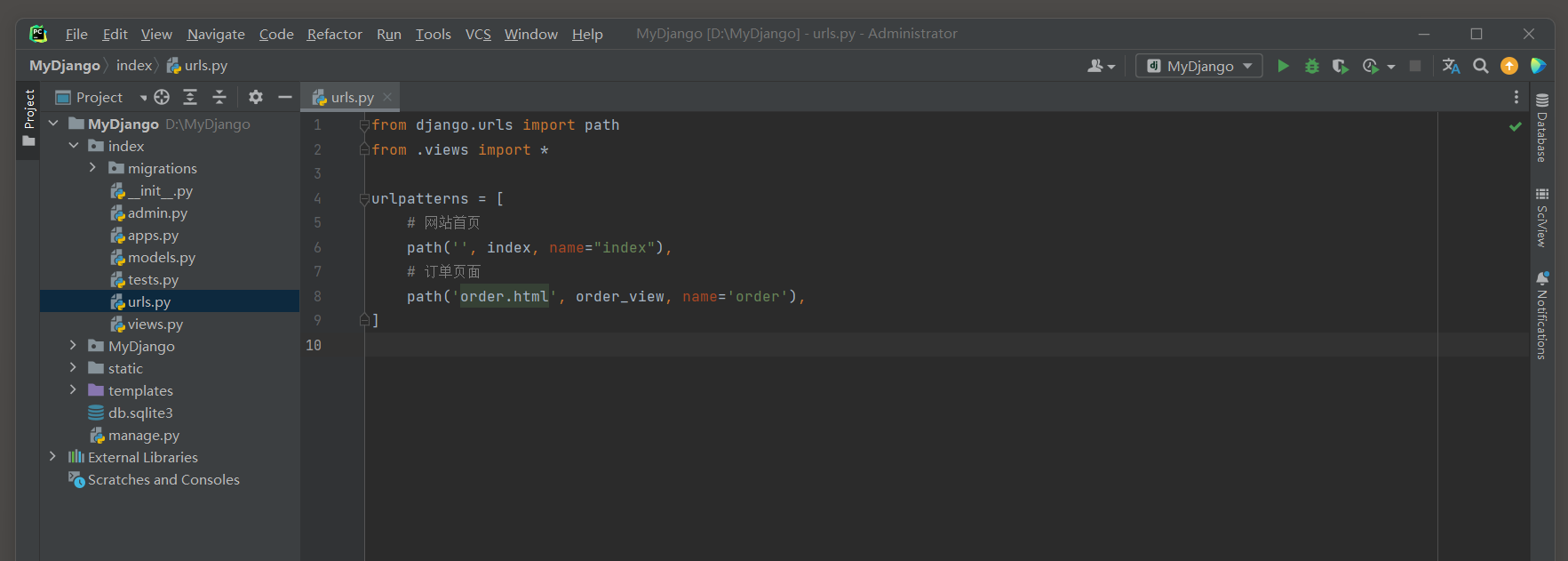
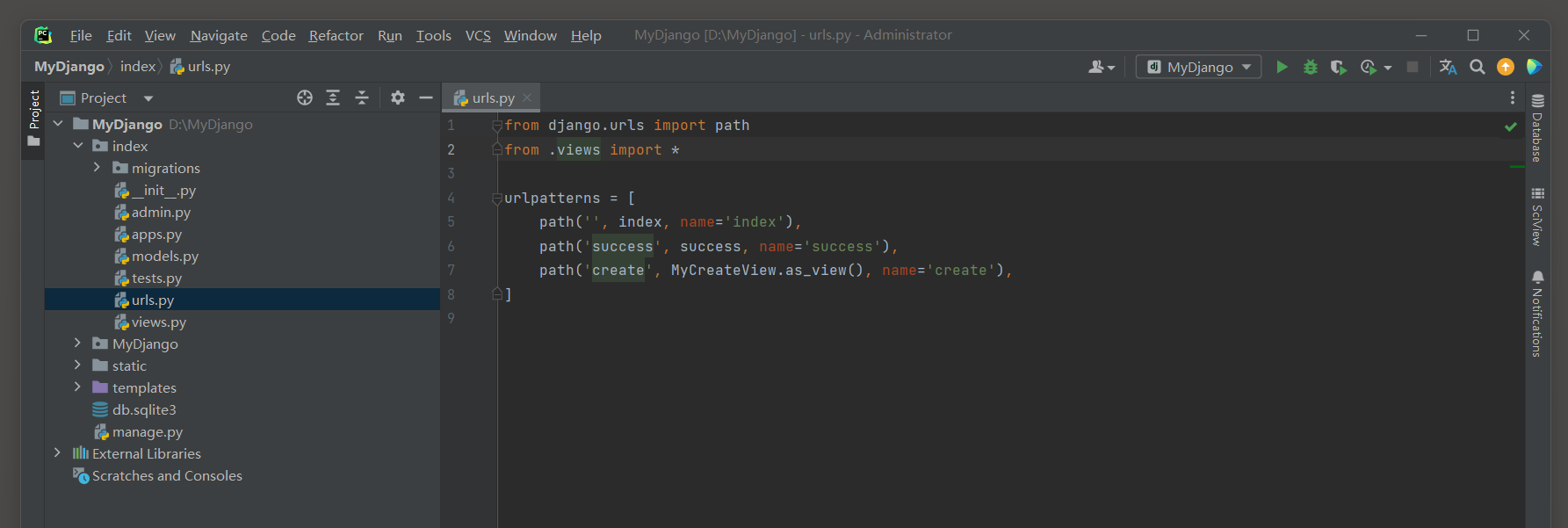
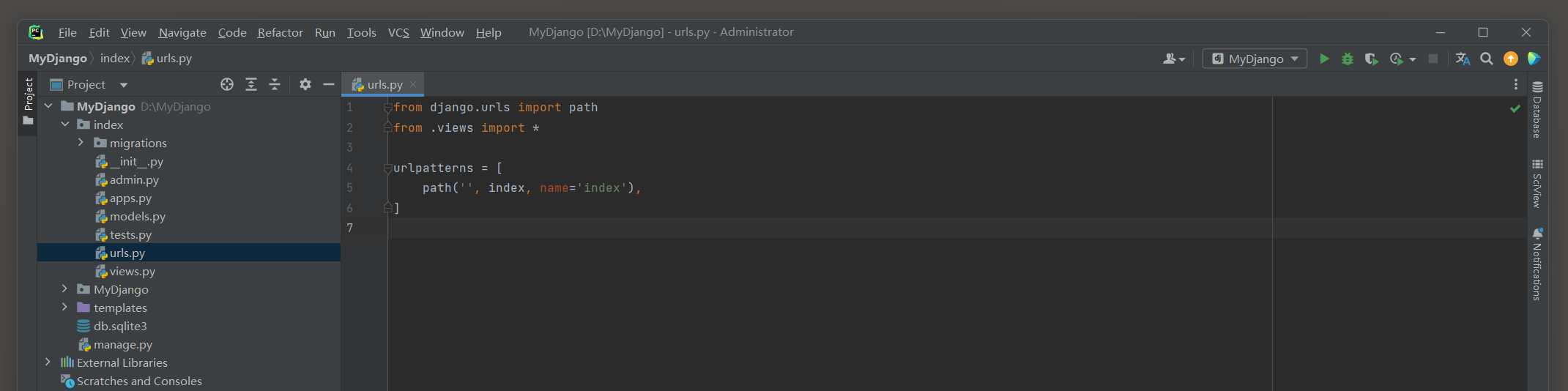
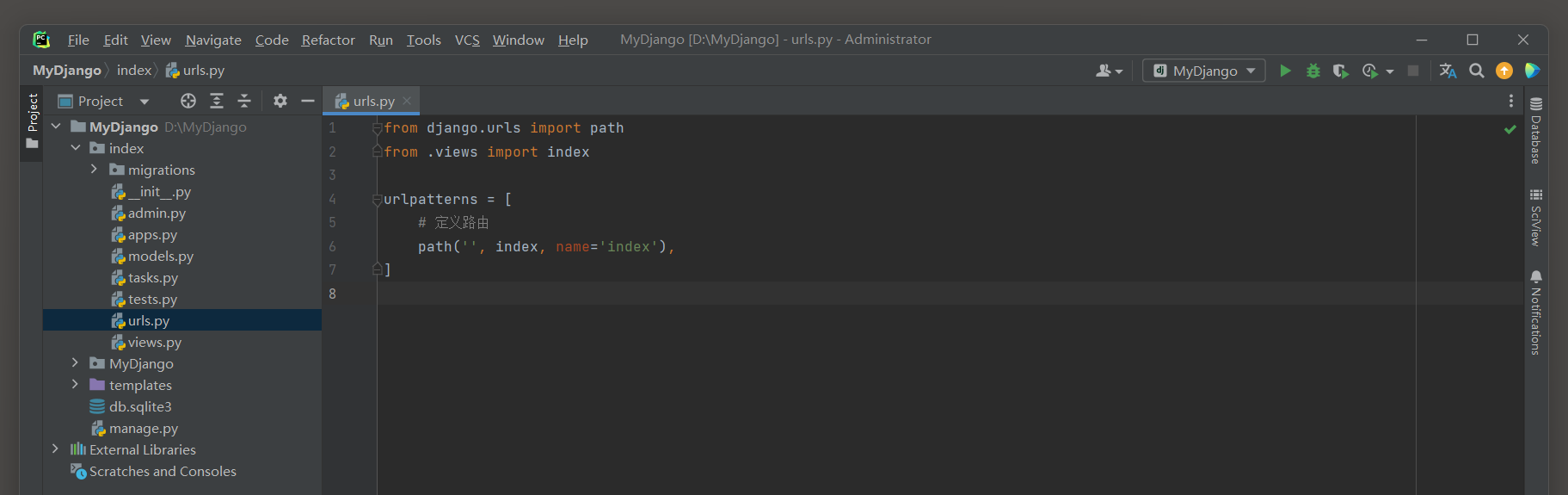
# index 的 urls.py
from django.urls import path
from .views import *
urlpatterns = [
# 网站首页
path('', index, name=index),
# 订单页面
path('orser.html', order_view, name='order'),
]
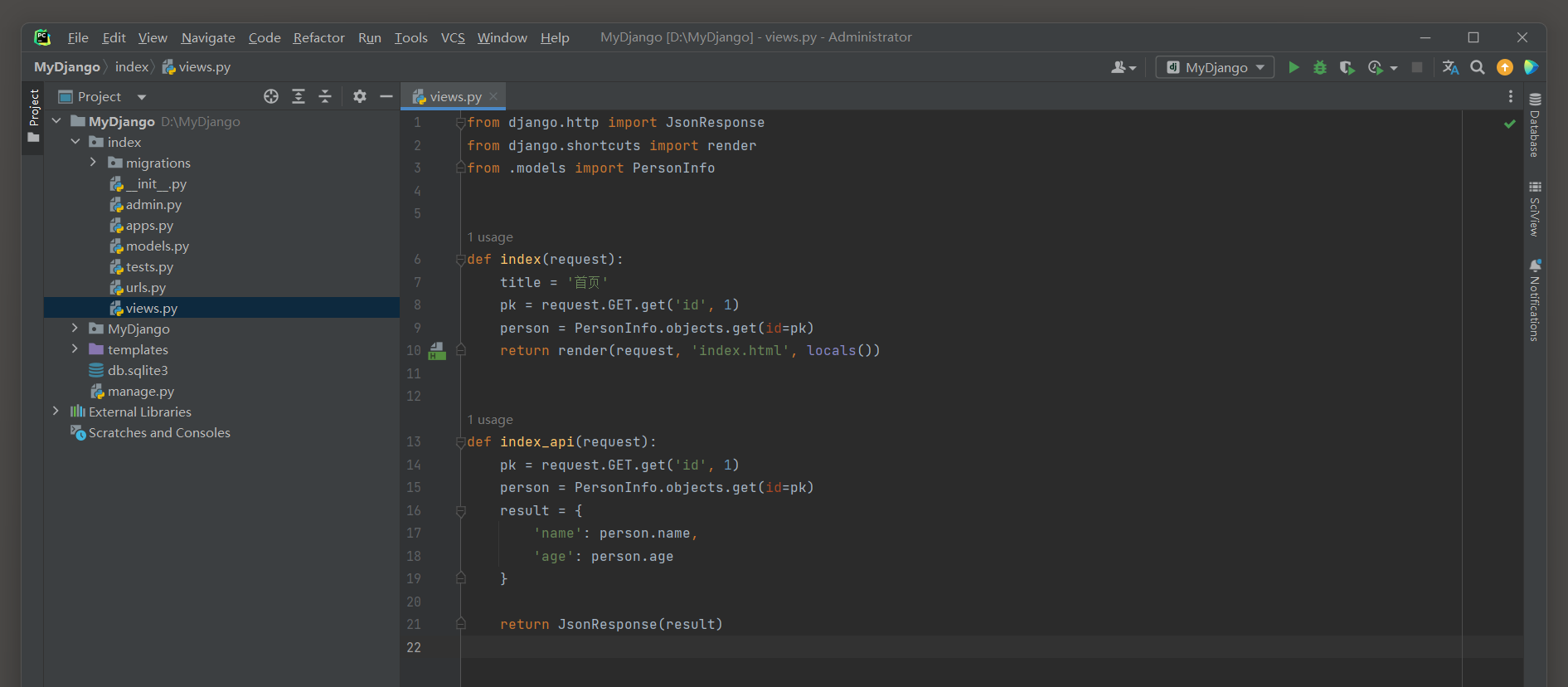
在index的views.py中分别定义视图函数index和order_view.
视图函数index实现商品列表的展示和抢购功能; 视图函数order_view将用户抢购的商品进行结算处理并生成订单信息.
视图函数index和order_view的代码如下:
# index 的 views.py
from django.shortcuts import render, redirect
from .models import Product
from django.contrib.auth.decorators import login_required
@login_required(login_url='/admin/login')
def index(request):
# 获取GET请求参数
pk = request.GET.get('id', '')
if pk:
# 获取存储在Session的id_list
# 若Session中没有id_list, 则返回一个空列表
id_list = request.session.get('id_list', [])
# 首次范围首页会创建空列表, 后续点击抢购会携带id访问首页
# 判断当前请求参数是否已存储在Session中
if pk not in id_list:
# 将商品的主键id存储在id_list中
id_list.append(pk)
# 更新Session的id_list
request.session['id_list'] = id_list
print(id_list)
return redirect('/') # 刷新页面
# 查询所有商品信息
products = Product.objects.all()
return render(request, 'index.html', locals())
def order_view(request):
# 获取存储在Session的id_list
# 若Session不存在id_list, 则返回一个空列表
id_list = request.session.get('id_list', [])
# 获取GET请求参数, 如果没有请求参数, 就返回空值
del_id = request.GET.get('id', '')
# 判断是否为空, 若费控, 则删除session里的商品信息
if del_id in id_list:
# 删除session里某个商品的质检
id_list.remove(del_id)
# 将删除后的数据覆盖原来的session
request.session['id_list'] = id_list
# 根据id_list查询商品所有信息
print(id_list)
products = Product.objects.filter(id__in=id_list)
return render(request, 'order.html', locals())
(index首页视图中, 点击"立刻抢购"是为id_list列表添加商品id,
order_view订单视图中先通过id_list列表的id获取商品数据并展示, 点击"移除商品"是从id_list列表移除商品id.
可以在视图中打印id_list查询id_list列表的变化.)
从视图函数index和order_view的功能实现过程中发现, 两者对Session的处理有相似的地方.
首先从Session中获取id_list的数据内容, 然后对id_list的数据进行读写处理, 最后将处理后的id_list重新写入Session.
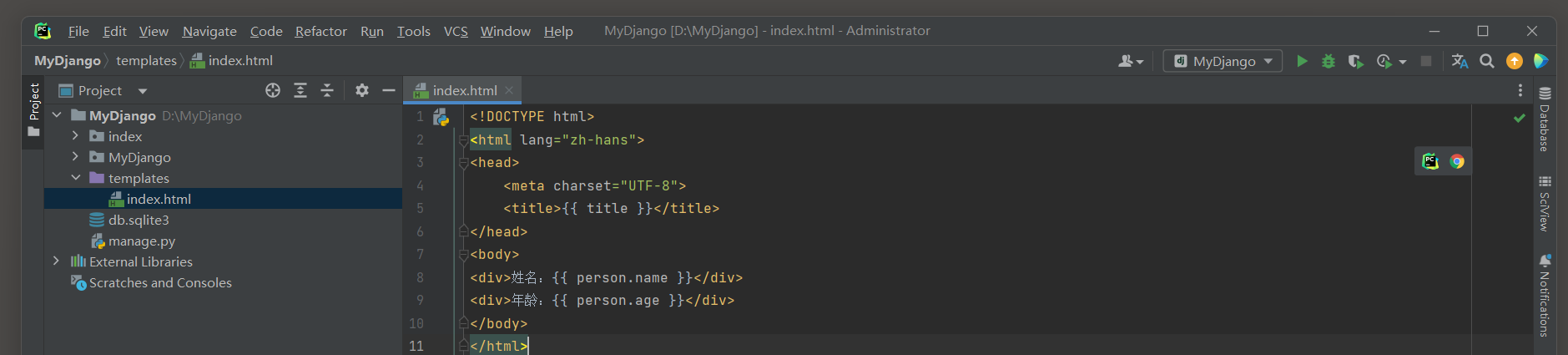
当视图函数完成用户请求的处理后, 再由模板文件生成相应的网页返回给用户, 我们分别对模板文件index.html和order.html编写网页代码.
index.html的模板上下文products是将所有商品信息以列表形式展示;
order.html的模板上下文products是将已抢购的商品以列表形式展示.
模板文件index.html和order.html的代码如下:
<!-- template 的 index.html -->
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>商城首页</title>
{% load static %}
<link rel="stylesheet" href="{% static "css/hw_index.css" %}">
</head>
<body>
<div id="top_main">
<div class="lf" id="my_hw">
当前用户: {{ user.username }}
</div>
<div class="lf" id="settle_up">
<a href="{% url 'index:order' %}">订单信息</a>
</div>
</div>
<section id="main">
<div class="layout">
<div class="fl u-4-3 lf">
<ul style="margin-top: 30px">
{% for p in products %}
<li class="channel-pro-item">
<div class="p-img">
<img src="{% static p.picture %}" alt="手机图片">
</div>
<div class="p-name">
<a href="#">{{ p.name }}</a>
</div>
<div class="p-shining">
<div class="p-promotions">{{ p.configure }}</div>
</div>
<div class="p-price">
<em>¥</em><span>{{ p.price }}</span>
</div>
<div class="p-button lf">
<a href="{% url 'index:index' %}?id={{ p.id }}">立刻抢购</a>
</div>
</li>
{% if forloop.counter == 2 %}
<div class="hr-2"></div>
{% endif %}
{% endfor %}
</ul>
</div>
</div>
</section>
</body>
</html>
<!-- template 的 index.html -->
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>订单信息</title>
{% load static %}
<link rel="stylesheet" href="{% static "css/reset.css" %}">
<link rel="stylesheet" href="{% static "css/carts.css" %}">
<script src="{% static "js/jquery.min.js" %}"></script>
<script src="{% static "js/carts.js" %}"></script>
</head>
<body>
<section class="cartMain">
<div class="cartMain_hd">
<ul class="order_lists cartTop">
<li class="list_chk">
<input type="checkbox" id="all" class="whole_check">
<label for="all"></label>
全选
</li>
<li class="list_con">商品信息</li>
<li class="list_price">单价</li>
<li class="list_amount">数量</li>
<li class="list_sum">金额</li>
<li class="list_op">操作</li>
<li class="list_op">
<a href="{% url 'index:index' %}">返回首页</a>
</li>
</ul>
</div>
<div class="cartBox">
<div class="shop_info">
<div class="all_check">
<!-- 店铺全选 -->
<label for="shop_b" class="shop"></label>
<input type="checkbox" id="shop_b" class="shopChoice">
</div>
<div class="shop_name">
店铺: <a href="javascript:;">MyDjango</a>
</div>
</div>
<div class="order_content">
{% for p in products %}
<ul class="order_lists">
<li class="list_chk">
<label for="checkbox_4"></label>
<input type="checkbox" id="checkbox_4" class="son_check">
<li class="list_con">
<div class="list_text">
<a href="javascript:;">{{ p.name }}</a>
</div>
</li>
<li class="list_price">
<p class="price">¥{{ p.price }}</p>
</li>
<li class="list_amount">
<div class="amount_box">
<a href="javascript:;" class="reduce reSty">-</a>
<input type="text" value="1" class="sum">
<a href="javascript:;" class="plus">+</a>
</div>
</li>
<li class="list_sum">
<p class="sum_price">¥{{ p.price }}</p>
</li>
<li class="list_op">
<p class="del">
<a href="{% url "index:order" %}?id={{ p.id }}" class="delBtn">移除商品</a>
</p>
</li>
</li>
</ul>
{% endfor %}
</div>
</div>
<!-- 底部 -->
<div class="bar-wrapper">
<div class="bar-right">
<div class="piece">已选商品
<strong class="piece_num">0</strong>件
</div>
<div class="totalMoney">共计:
<strong class="total_text">0.0 </strong>
</div>
<div class="calBtn">
<a href="javascript:;">结算</a>
</div>
</div>
</div>
</section>
</body>
</html>
# 创建超级用户
PS D:\MyDjango> python manage.py createsuperuser
Username (leave blank to use 'blue'): admin
Email address:
Password: 123456
Password (again): 123456
This password is too short. It must contain at least 8 characters.
This password is too common.
This password is entirely numeric.
Bypass password validation and create user anyway? [y/N]: y
Superuser created successfully.
至此, 我们已完成商品抢购功能的开发.
为了验证功能是否正常运行, 在PyCharm里使用Django内置指令创建超级管理员,
因为视图函数index设置了装饰器login_required, 所以只有已登录的用户才能访问商城首页, 这样才能确保视图函数index能够读写Session.
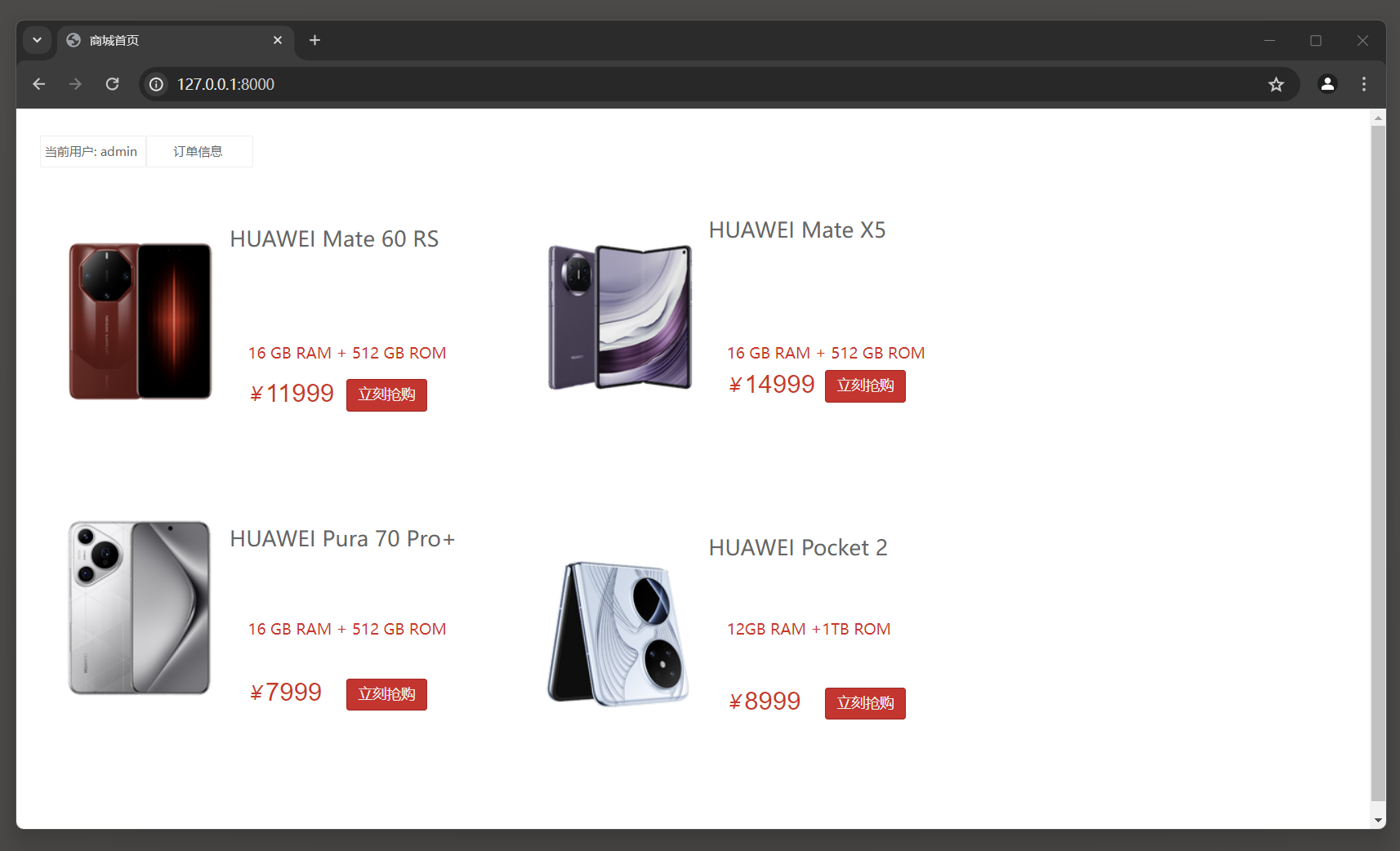
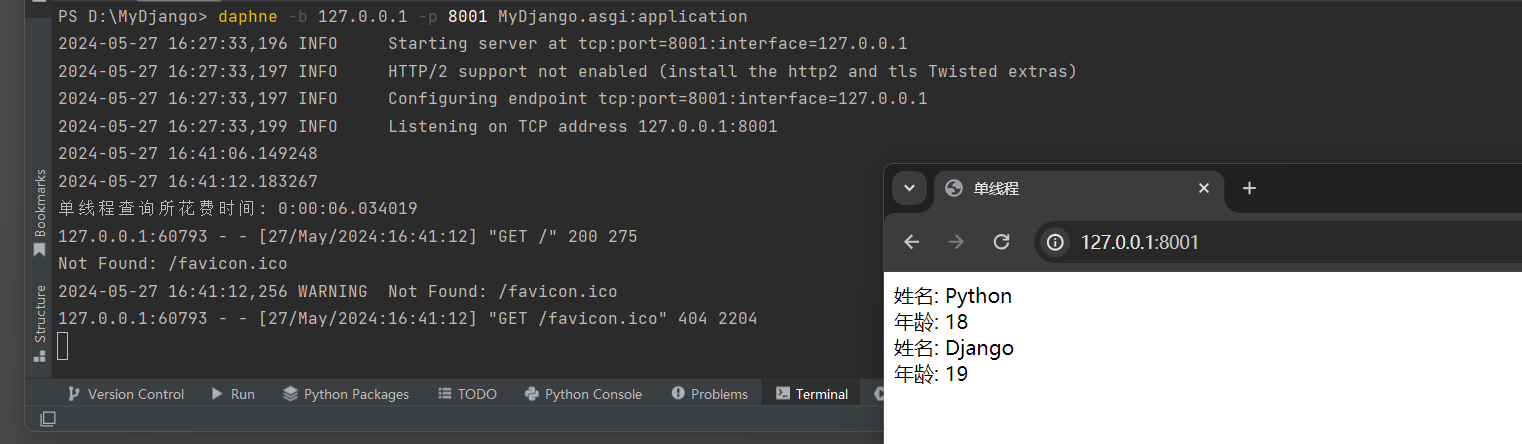
运行MyDjango并访问: 127.0.0.1:8000 , 若当前用户尚未登录, 则跳转到Admin后台系统的登录页面, 完成用户登录后就自动跳转到商城首页, 并在商城首页显示当前用户名, 如图11-8所示.
图11-8 商城首页
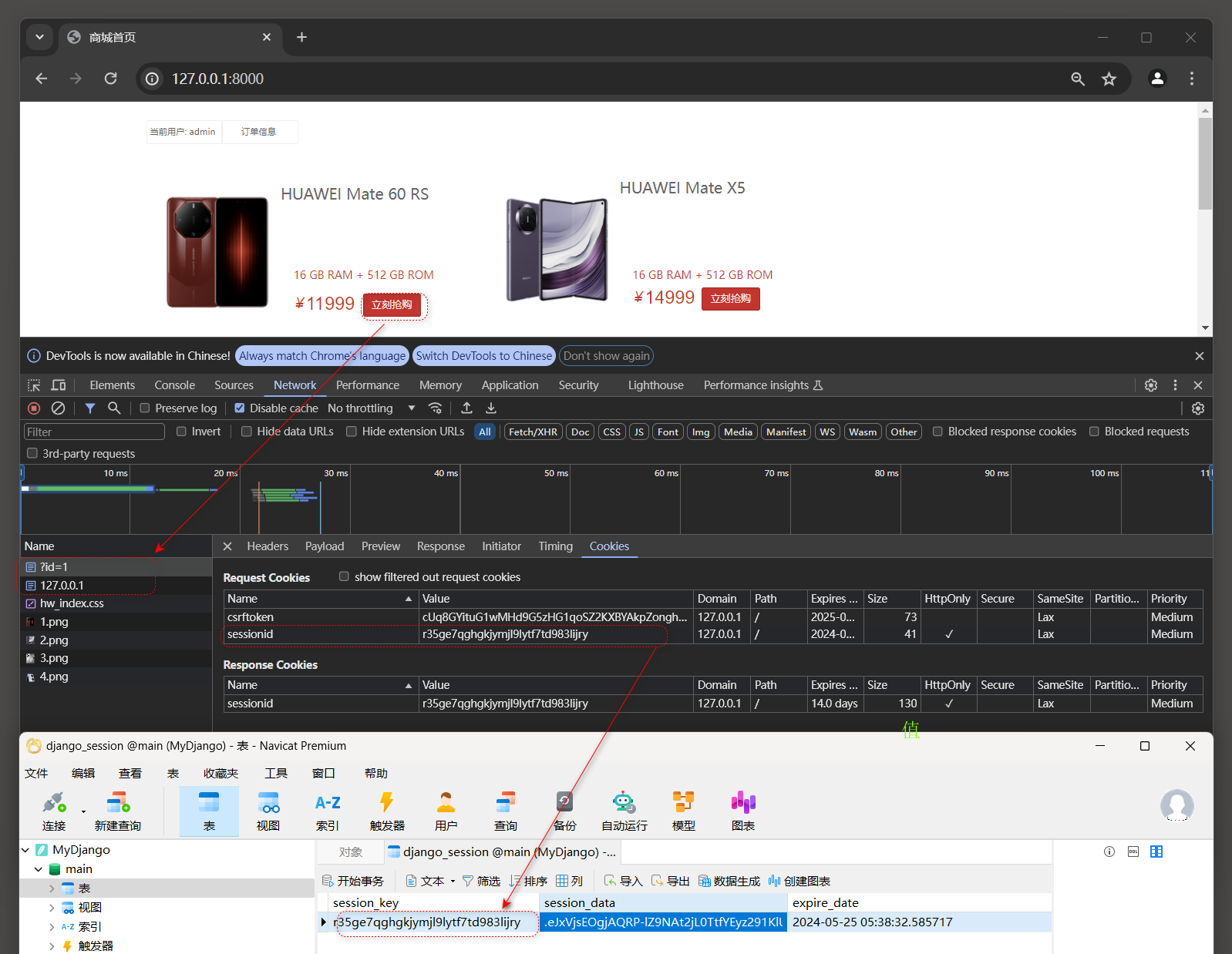
在商城首页单击某个商品的'立即抢购'按钮就会自动刷新商城首页, 页面刷新过程向Django发送了两次GET请求,
第一次请求带有请求参数id, 视图函数index将请求参数id写入当前用户的Session并重定向到商城首页, 如图11-9所示.
第二次请求是视图函数中更新id值到id_list列表中后使用redirect('/')函数重定向到商城首页.
图11-9 抢购商品
在商城首页可以单击多个商品的'立即抢购'按钮, 同一商品的'立即抢购'按钮可以重复单击, 但用户的Session不会重复记录同一商品的主键id.
单击'订单信息'就能进入订单页面, 如图11-10所示.
图11-10 订单页面
订单页面根据用户的Session所存储的数据生成商品列表, 单击某商品的'移除商品'按钮就会自动刷新订单页面,
页面刷新机制与商城首页的刷新机制相同, 只不过订单页面的刷新机制是删除当前用户Session的商品主键id.
订单页面只实现商品的展示和移除功能, 其他功能皆由前端的JavaScript实现, 如商品勾选, 数量与金额的计算等.
综上所述, 整个MyDjango项目主要实现商城首页和订单信息页, 两个页面之间的数据传递由Session实现, 详细说明如下:
● 商城首页实现Session的读取和写入.
首先获取Session的id_list, 如果当前请求存在请求参数id, 就判断Session的id_list是否存在请求参数id的值,
若不存在, 则将请求参数id的值写入Session的id_list.
● 订单信息页实现Session的读取和删除.
首先获取Session的idList, 如果当前请求存在请求参数id, 就判断Session的id_list是否存在请求参数id的值,
若存在, 则从Session的id_list删除请求参数id的值.
11.2 缓存机制
现在的网站都以动态网站为主, 当网站访问量过大时, 网站的响应速度必然大大降低, 这就有可能出现卡死的情况.
为了解决网站访问量过大的问题, 可以在网站上使用缓存机制.
11.2.1 缓存的类型与配置
缓存是将一个请求的响应内容保存到内存, 数据库, 文件或者高速缓存系统(Memcache)中,
若某个时间内再次接收同一个请求, 则不再执行该请求的响应过程, 而是直接从内存或者高速缓存系统中获取该请求的响应内容返回给用户.
Django提供5种不同的缓存方式, 每种缓存方式说明如下:
● Memcached: 一个高性能的分布式内存对象缓存系统, 用于动态网站, 以减轻数据库负载.
通过在内存中缓存数据和对象来减少读取数据库的次数, 从而提高网站的响应速度.
使用Memcached需要安装Memcached系统服务器, Django通过python-memcached或pylibmc模块调用Memcached系统服务器,
实现缓存读写操作, 适合超大型网站使用.
● 数据库缓存: 缓存信息存储在网站数据库的缓存表中, 缓存表可以在项目的配置文件中配置, 适合大中型网站使用.
● 文件系统缓存: 缓存信息以文本文件格式保存, 适合中小型网站使用.
● 本地内存缓存: Django默认的缓存保存方式, 将缓存存放在计算机的内存中, 只适用于项目开发测试.
● 虚拟缓存: Django内置的虚拟缓存, 实际上只提供缓存接口, 不能存储缓存数据, 只适用于项目开发测试.
每种缓存方式都有一定的适用范围, 因此选择缓存方式需要结合网站的实际情况而定.
若在项目中使用缓存机制, 则首先在配置文件settings.py中设置缓存的相关配置. 每种缓存方式的配置如下:
# Memcached配置
# BACKEND用于配置缓存引擎, LOCATION是Memcached服务器的IP地址
# django.core.cache.backends.memcached.MemcacheCache
# 使用python模块连接Memcached
CACHES = {
'default': {
'BACKEND': 'django.core.cache.backends.memcached.MemcachedCache',
# 'BACKEND': 'django.core.cache.backends.memcached.PyLibMCCache',
'LOCATION': [
'172.19.26.240:11211',
'172.19.26.242:11211',
]
}
}
# 数据库缓存配置
# BACKEND用于配置缓存引擎, LOCATION是数据表的命名
CACHES = {
'default': {
'BACKEND': 'django.core.cache.backends.db.DatabaseCache',
'LOCATION': 'my_cache_table',
}
}
# 文件系统缓存
# BACKEND用于配置缓存引擎, LOCATION是文件的绝对路径
CACHES = {
'default': {
'BACKEND': 'django.core.cache.backends.filebased.FileBasedCache',
'LOCATION': 'D:/django_cache',
}
}
# 本地内存缓存
# BACKEND用于配置缓存引擎, LOCATION对存储器命名, 用于识别单个存储器
CACHES = {
'default': {
'BACKEND': 'django.core.cache.backends.locmem.LocMemCache',
'LOCATION': 'unique-snowflake',
}
}
# 虚拟缓存
# BACKEND用于配置缓存引擎
CACHES = {
'default': {
'BACKEND': 'django.core.cache.backends.dummy.DummyCache',
}
}
上述缓存配置仅仅是基本配置, 也就是说缓存配置的参数BACKEND和LOCATION是必选参数, 其余的配置参数可自行选择.
我们以数据库缓存配置为例, 完整的缓存配置如下:
# settings.py
# 数据库缓存设置
# BACKEND用于配置缓存引擎, LOCATION是数据表的命名
CACHES = {
# 默认缓存数据表
'default': {
'BACKEND': 'django.core.cache.backends.db.DatabaseCache',
'LOCATION': 'my_cache_table',
# TIMEOUT设置缓存的生命周期, 以秒为单位, 若为None, 则永不过期
'TIMEOUT': 60,
'OPTIONS': {
# MAX_ENTRIES代码最大缓存的记录
'MAX_ENTRIES': 1000,
# 当缓存达到最大数量之后, 设置剔除缓存的数量
'CULL_FREQUENCY': 3
},
},
# 设置多个缓存数据表
'MyDjango': {
'BACKEND': 'django.core.cache.backends.db.DatabaseCache',
'LOCATION': 'MyDjango_cache_table',
}
}
Django允许同时配置和使用多种不同类型的缓存方式, 配置方法与多数据库的配置方法相似.
上述配置是在同一个数据库中使用不同的数据表存储缓存信息, 使用数据库缓存需要根据缓存配置来创建缓存数据表.
缓存数据表的创建依赖于settings.py的数据库配置DATABASES,
如果DATABASES配置多个数据库, 缓存数据表就默认在DATABASES的default的数据库中生成.
在PyCharm的Terminal中输入: python manage.py createcachetable 指令创建缓存数据表,
然后在数据库中查看缓存数据表, 如图11-11所示.
图11-11 缓存数据表
11.2.2 缓存的使用
完成数据库缓存配置以及缓存数据表的创建后, 下一步在项目功能中使用缓存机制.
缓存的使用方式有4种, 主要根据不同的使用对象进行划分, 具体说明如下:
● 全站缓存: 将缓存作用于整个网站的全部页面.
一般情况下不采用这种方式实现, 如果网站规模较大, 缓存数据相应增多, 就会对数据库或Memcached造成极大的压力.
● 视图缓存: 当用户发送请求时, 若该请求的视图函数已生成缓存数据,
则以缓存数据作为响应内容, 这样可省去视图函数处理请求的时间和资源.
● 路由缓存: 其作用与视图缓存相同, 但两者是有区别的, 例如两个路由指向同一个视图函数, 分别访问这两个路由地址时,
路由缓存会判断路由地址是否已生成缓存而决定是否执行视图函数.
● 模板缓存: 对模板某部分的数据设置缓存, 常用于模板内容变动较少的情况,
如HTML的<head>标签, 设置缓存能省去模板引擎解析生成HTML页面的时间.
11.2.2.1 全站缓存
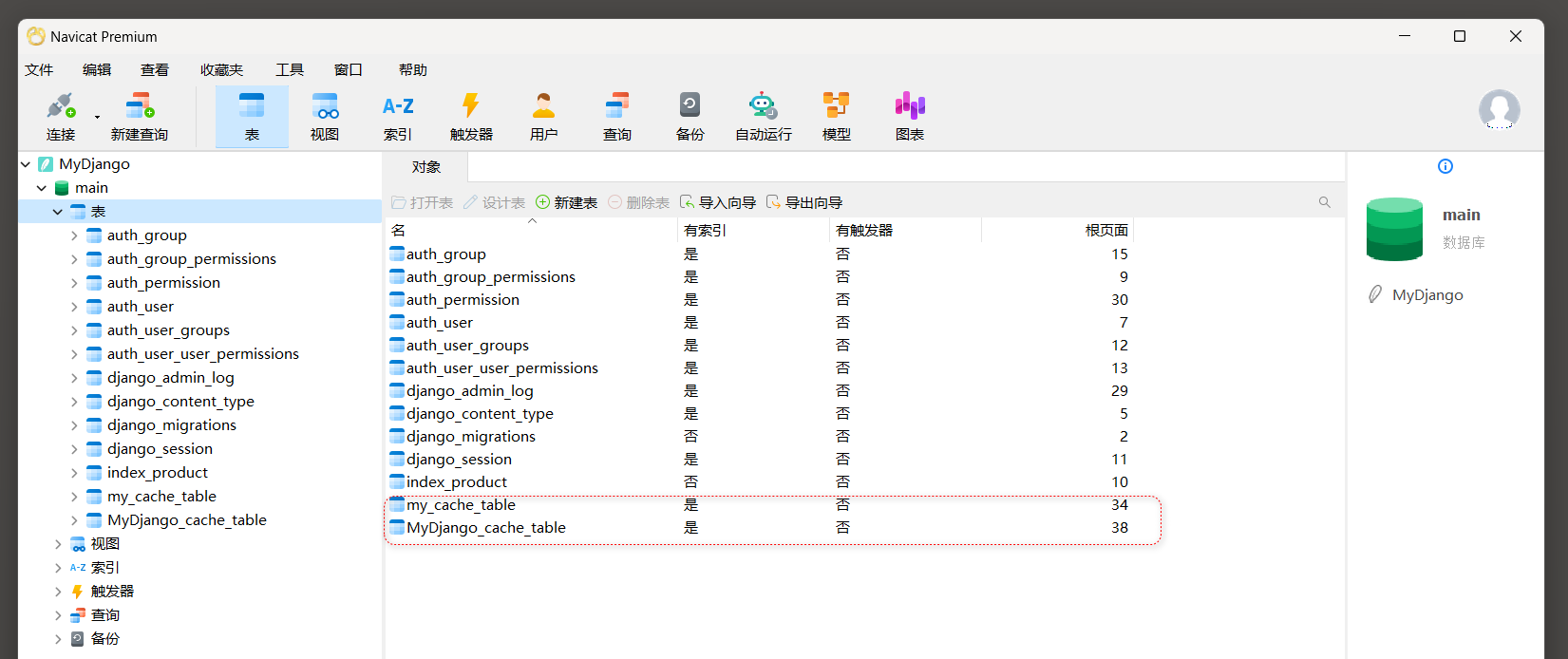
全站缓存作用于整个网站, 当用户向网站发送请求时, 首先经过Django的中间件进行处理.
因此, 使用全站缓存应在Django的中间件中配置, 配置信息如下:
# MyDjango的settings.py
MIDDLEWARE = [
# 配置全站缓存
'django.middleware.cache.UpdateCacheMiddleware', # 更新缓存
'django.middleware.security.SecurityMiddleware',
'django.contrib.sessions.middleware.SessionMiddleware',
# 添加本地化中间件LocaleMiddleware
'django.middleware.locale.LocaleMiddleware',
'django.middleware.common.CommonMiddleware',
'django.middleware.csrf.CsrfViewMiddleware',
'django.contrib.auth.middleware.AuthenticationMiddleware',
'django.contrib.messages.middleware.MessageMiddleware',
'django.middleware.clickjacking.XFrameOptionsMiddleware',
# 配置全站缓存
'django.middleware.cache.FetchFromCacheMiddleware', # 从缓存中获取数据
]
# 设置缓存的生命周期
CACHE_MIDDLEWARE_SECONDS = 15
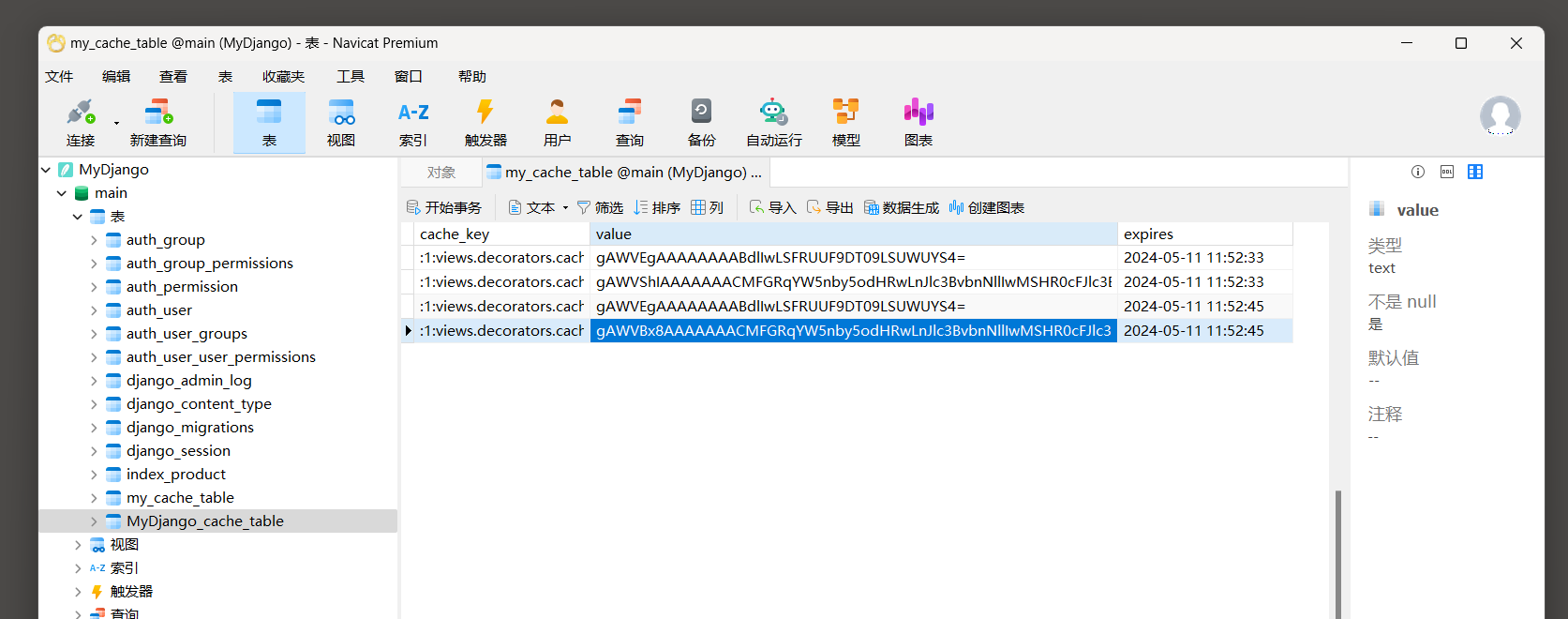
# 设置缓存数据保存在数据表my_cache_table中
# 属性值default来自于缓存配置CACHES的default
CACHE_MIDDLEWARE_ALIAS = 'default'
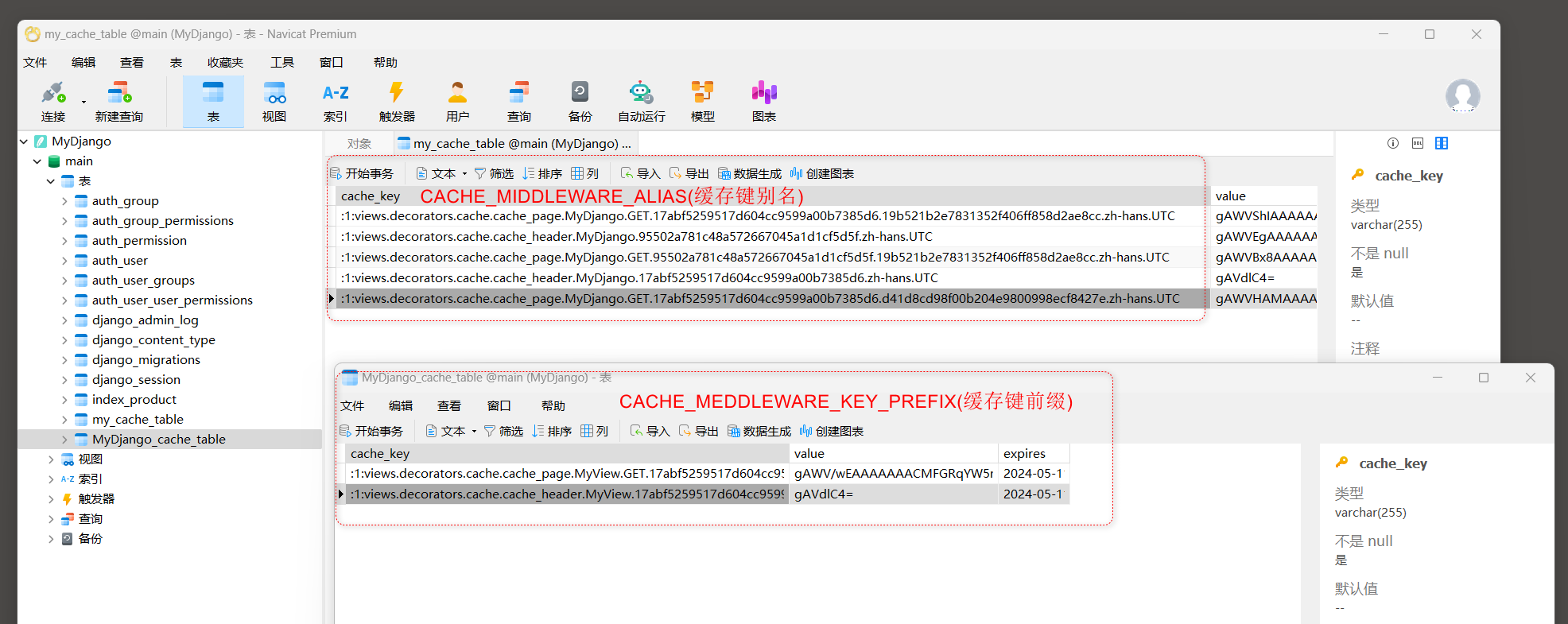
# 设置缓存表字段cache_key的值
# 用于同一个Django项目多个站点之间的共享缓存
CACHE_MIDDLEWARE_KEY_PREFIX = 'MyDjango'
全局缓存是使用Django内置中间件cache实现的, 上述配置的说明如下:
● 在配置属性MIDDLEWARE的首位元素和末位元素时分别添加cache中间件UpdateCacheMiddleware和FetchFromCacheMiddleware.
FetchFromCacheMiddleware中间件: 用于从缓存中获取已经缓存的HTTP响应.
当一个请求到达时, 它会首先检查缓存中是否有对应的响应, 如果有, 则直接返回缓存的响应, 而不是重新生成响应.
这样可以提高网站的响应速度, 减轻服务器的压力.
UpdateCacheMiddleware中间件用于更新缓存中的HTTP响应.
当一个请求被处理并生成响应后, 这个中间件会将响应存储到缓存中, 以便下次请求时可以直接从缓存中获取.
这样可以避免重复生成相同的响应, 提高网站的性能.
● CACHE_MIDDLEWARE_SECONDS设置缓存的生命周期.
若在视图, 路由和模板中使用缓存并设置生命周期属性TIMEOUT, 则优先选择CACHE_MIDDLEWARE_SECONDS.
● CACHE_MIDDLEWARE_ALIAS设置缓存的保存路径, 默认为default.
如果缓存配置CACHES中设置多种缓存方式, 没有设置缓存的保存路径, 就默认保存在缓存配置CACHES的default的配置信息中.
● CACHE_MIDDLEWARE_KEY_PREFIX指定某个Django站点的名称.
在一些大型网站中都会采用分布式站点实现负载均衡, 这是将同一个Django项目部署在多个服务器上,
当网站访问量过大的时候, 可以将访问量分散到各个服务器, 提高网站的整体性能.
如果多个服务器使用共享缓存, 那么该属性是为了区分各个服务器的缓存数据, 这样每个服务器只能使用自己的缓存数据.
以11.2.1小节的MyDjango项目为例, 将上述配置信息写入配置文件settings.py中,
然后启动MyDjango, 在浏览器上访问任意页面都会在缓存数据表my_cache_table上生成相应的缓存信息, 如图11-12所示.
图11-12 缓存数据表my_cache_table
11.2.2.2 视图缓存
视图缓存是在视图函数或视图类的执行过程中生成缓存数据, 视图使用装饰器生成, 并保存缓存数据.
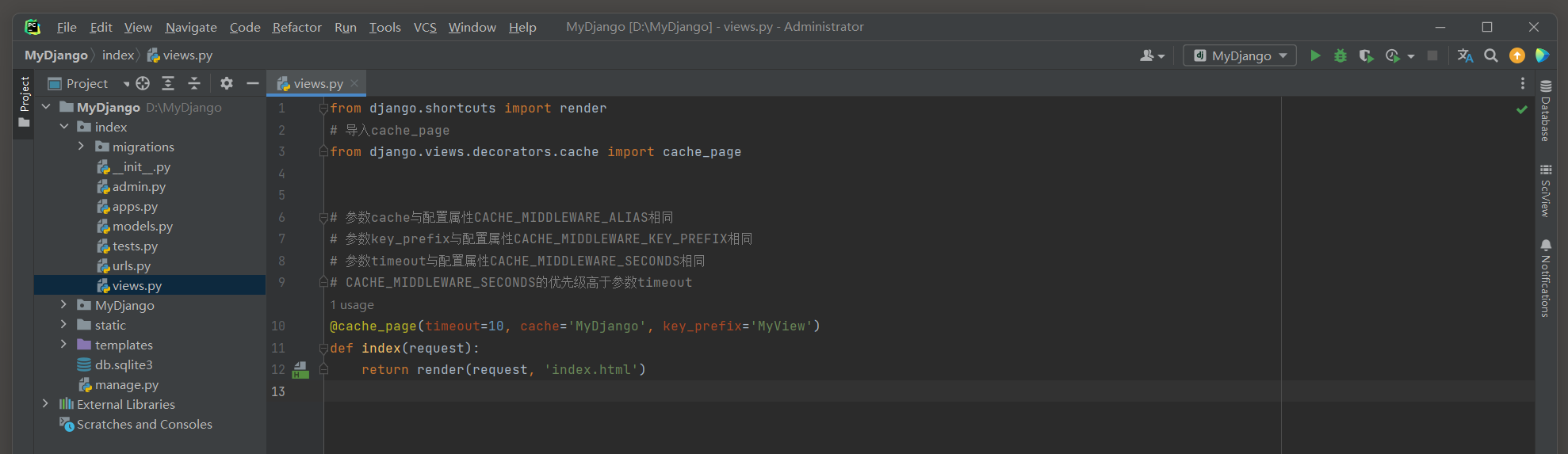
装饰器cache_page设有参数timeout, cache和key_prefix, 参数timeout是必选参数,
其余两个参数是可选参数, 参数的作用与全局缓存的配置属性相同, 代码说明如下:
# index的views.py
from django.shortcuts import render
# 导入cache_page
from django.views.decorators.cache import cache_page
# 参数cache与配置属性CACHE_MIDDLEWARE_ALIAS相同
# 参数key_prefix与配置属性CACHE_MIDDLEWARE_KEY_PREFIX相同
# 参数timeout与配置属性CACHE_MIDDLEWARE_SECONDS相同
# CACHE_MIDDLEWARE_SECONDS的优先级高于参数timeout
@cache_page(timeout=10, cache='MyDjango', key_prefix='MyView')
def index(request):
return render(request, 'index.html')
# index 的 urls.py
from django.urls import path
from .views import *
urlpatterns = [
# 网站首页
path('', index, name="index"),
]
<!-- templates 的 index.html-->
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>首页</title>
</head>
<body>
<h1>首页</h1>
</body>
</html>
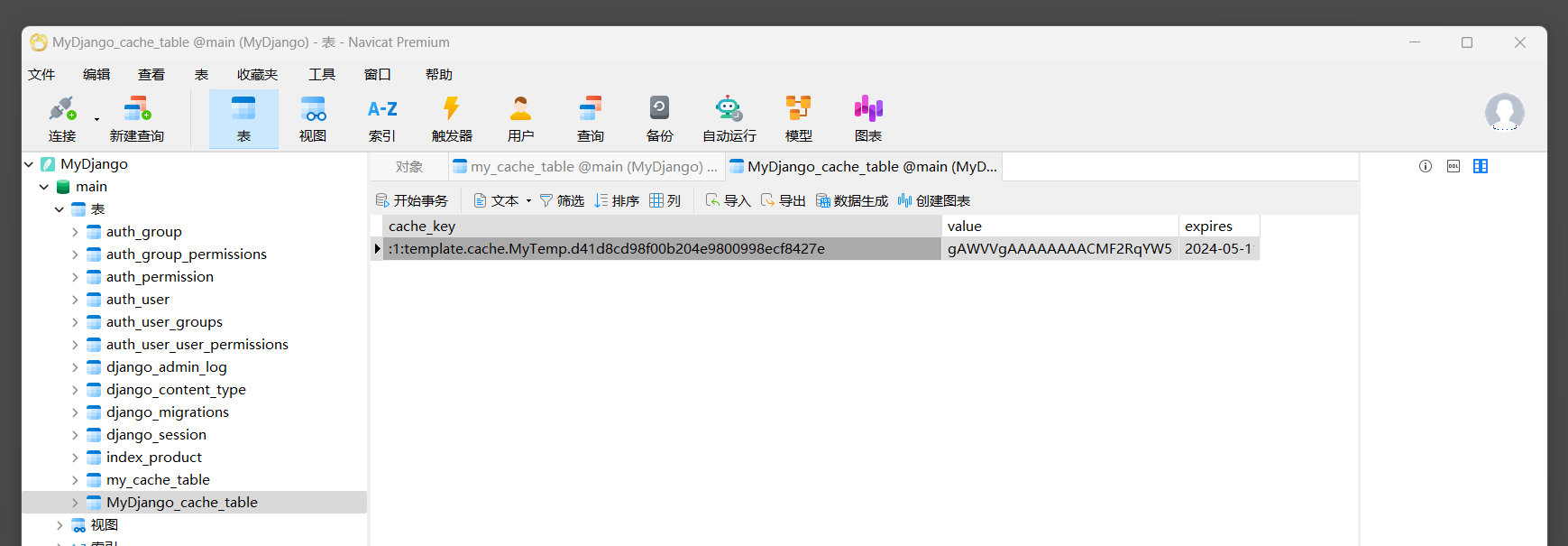
上述配置是将视图缓存存放在缓存数据表MyDjango_cache_table中, 并且缓存数据的字段cache_key含有关键词MyView.
运行MyDjango, 在浏览器上访问127.0.0.1:8000, 打开数据库查看缓存数据表MyDjango_cache_table的视图缓存信息, 如图11-13所示.
图11-13 缓存数据表MyDjango_cache_table
11.2.2.3 路由缓存
cache_header: 这种类型的缓存主要用于对特定URL的响应进行缓存.
当使用cache_header装饰器时, Django会为每个请求的URL生成一个唯一的缓存键, 这样可以为每个URL的响应独立缓存.
缓存键通常包含URL的哈希值和其他相关信息, 以确保唯一性.
cache_page: 这种类型的缓存是针对整个页面的输出进行缓存.
当使用cache_page装饰器时, Django会根据请求的方法(如GET或POST)和URL来生成缓存键.
这种缓存适用于整个页面的内容, 而不仅仅是响应头.
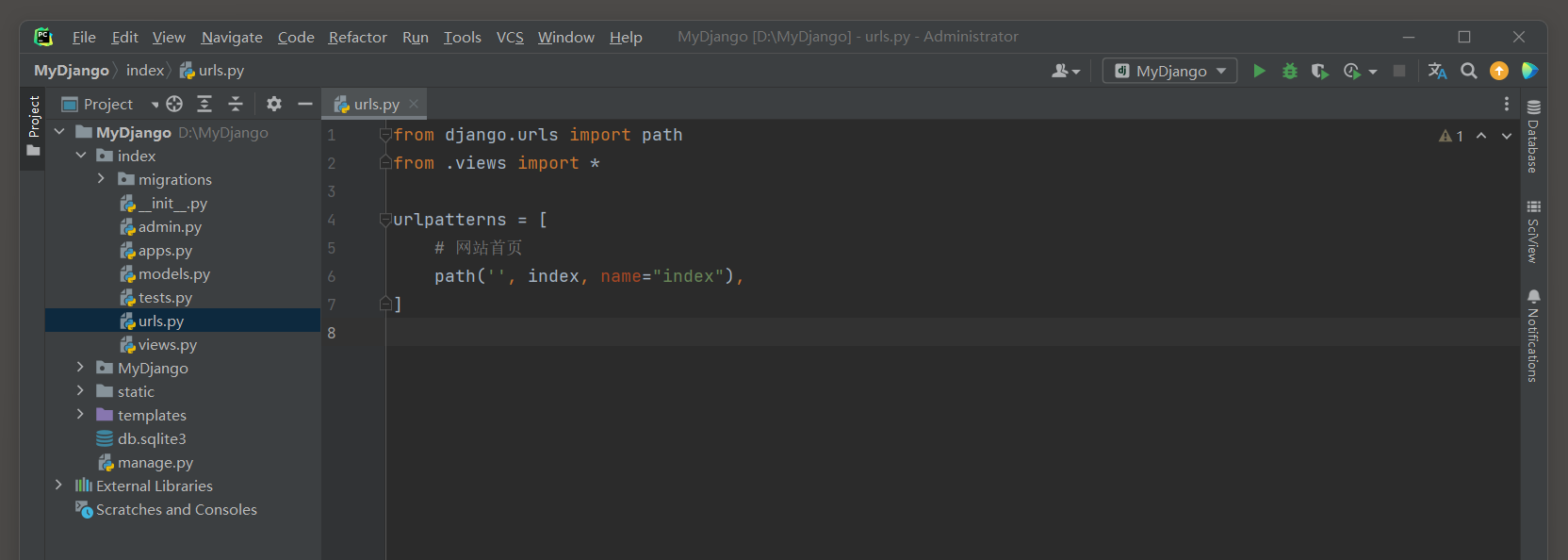
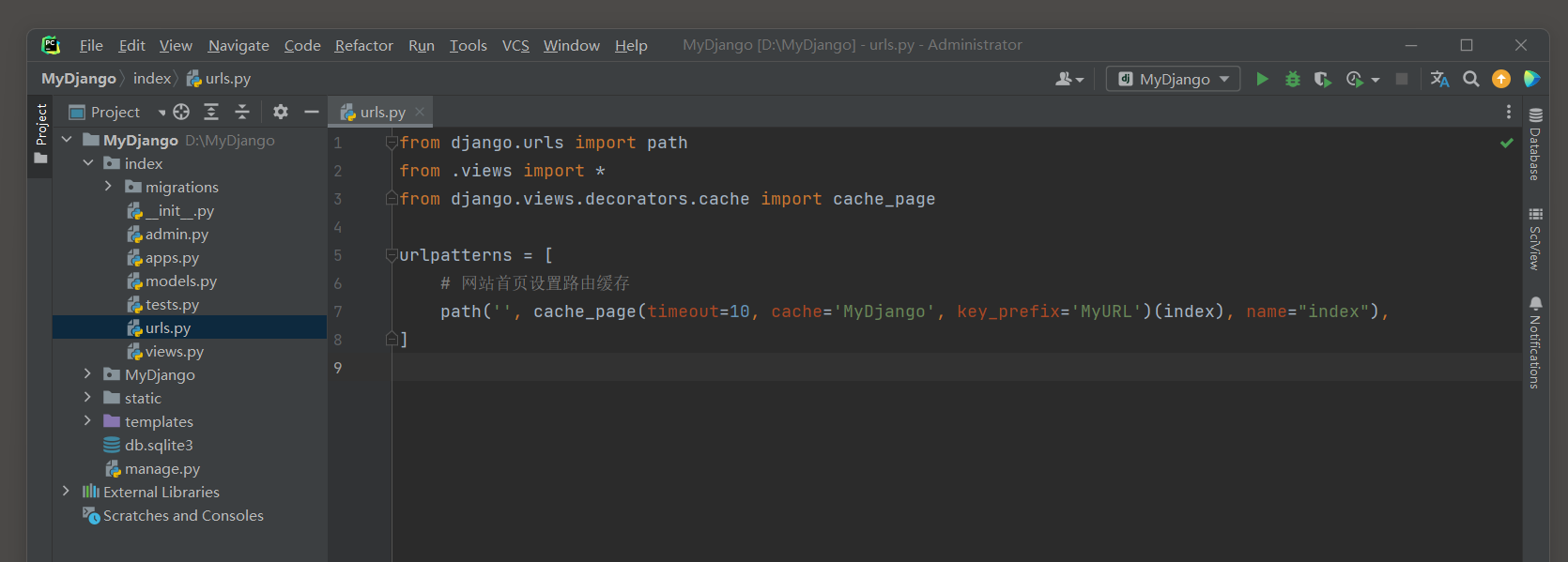
路由缓存是在路由文件urls.py中生成和保存的, 路由缓存也是使用缓存函数cache_page实现的.
我们在index的urls.py中设置路由index的缓存数据, 代码如下:
from django.urls import path
from .views import *
from django.views.decorators.cache import cache_page
urlpatterns = [
# 网站首页设置路由缓存
path('', cache_page(timeout=10, cache='MyDjango', key_prefix='MyURL')(index), name="index"),
]
在浏览器上访问网站首页, 打开数据库查看缓存数据表MyDjango_cache_table的路由缓存数据, 如图11-14所示.
图11-14 缓存数据表MyDjango_cache_table
11.2.2.4 模板缓存
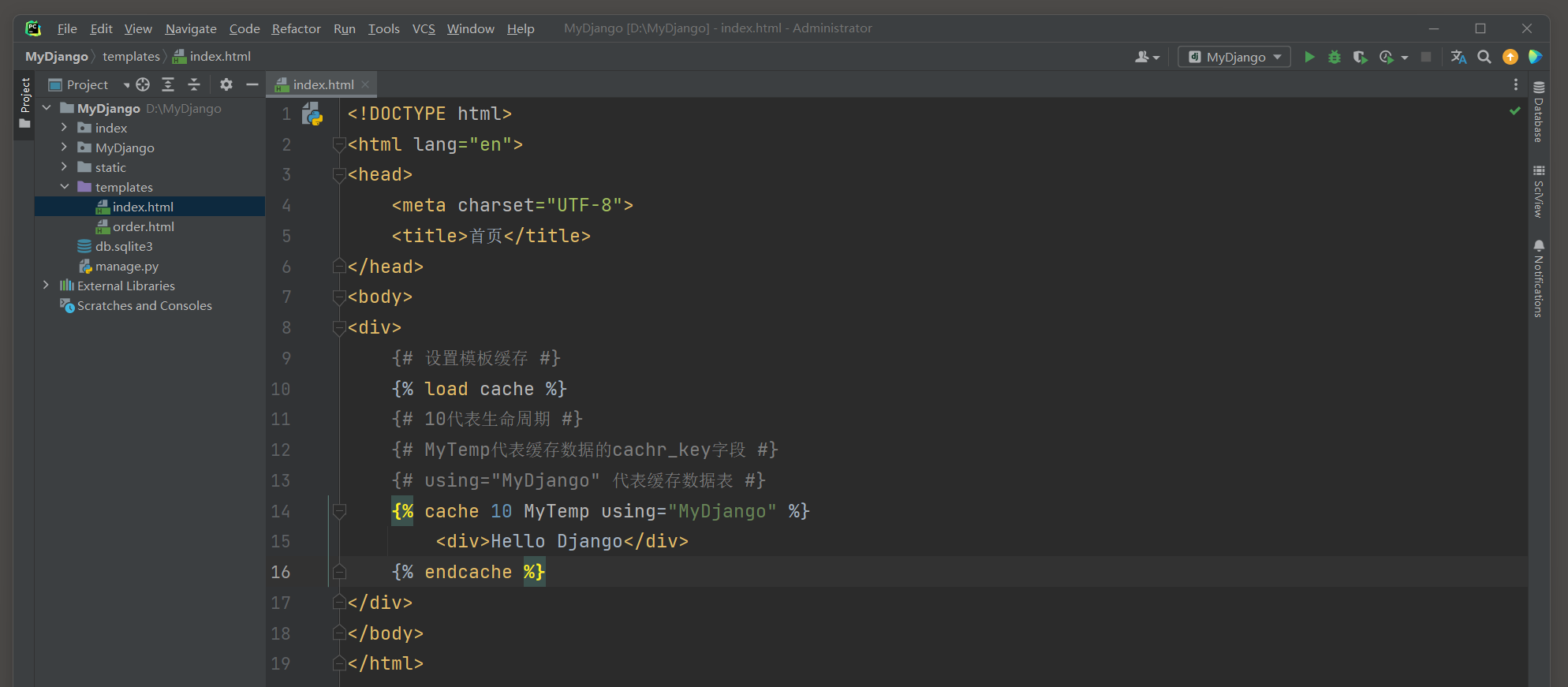
模板缓存是通过Django的缓存标签实现的, 缓存标签可以设置缓存的生命周期,
缓存的关键词和缓存数据表(函数cache_page的参数timeout, key_prefix和cache),
三者的设置顺序和代码格式是固定不变的, 以模板文件index.html为例实现模板缓存, 代码如下:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>首页</title>
</head>
<body>
<div>
{# 设置模板缓存 #}
{% load cache %}
{# 10代表生命周期 #}
{# MyTemp代表缓存数据的cachr_key字段 #}
{# using="MyDjango" 代表缓存数据表 #}
{% cache 10 MyTemp using="MyDjango" %}
<div>Hello Django</div>
{% endcache %}
</div>
</body>
</html>
重启MyDjango, 在浏览器上再次访问网站首页, 然后打开数据库查看缓存数据表MyDjango_cache_table的模板缓存数据, 如图11-15所示.
图11-15 缓存数据表MyDjango_cache_table
11.3 CSRF防护
CSRF(Cross-Site Request Forgery, 跨站请求伪造)也称为One Click Attack或者Session Riding,
通常缩写为CSRF或者XSRF, 这是一种对网站的恶意利用, 窃取网站的用户信息来制造恶意请求.
Django为了防护这类攻击, 在用户提交表单时, 表单会自动加入csrfmiddlewaretoken隐藏控件,
这个隐藏控件的值会与网站后台保存的csrfmiddlewaretoken进行匹配, 只有匹配成功, 网站才会处理表单数据.
这种防护机制称为CSRF防护, 原理如下:
(1) 在用户访问网站时, Django在网页表单中生成一个隐藏控件csrfmiddlewaretoken, 控件属性value的值是由Django随机生成的.
(2) 当用户提交表单时, Django校验表单的csrfmiddlewaretoken是否与自己保存的csrfmiddlewaretoken一致, 用来判断当前请求是否合法.
(3) 如果用户被CSRF攻击并从其他地方发送攻击请求, 由于其他地方不可能知道隐藏控件csrfmiddlewaretoken的值,
因此导致网站后台校验csrfmiddlewaretoken失败, 攻击就被成功防御.
在Django中使用CSRF防护功能, 首先在配置文件settings.py中设置CSRF防护功能.
它是由settings.py的CSRF中间件CsrfViewMiddleware实现的, 在创建项目时已默认开启, 如图11-16所示.
(CSRF防止其他网站向自己的网站发送请求, 除非你得的随机生成的token值, 放到伪装的页面中.)
CSRF防御策略中使用随机令牌的基本步骤:
* 1. 生成令牌: 当服务器生成一个会话(如用户登录时), 它会生成一个随机的, 不可预测的令牌,
并将其存储在用户的会话数据中(如服务器端的session cookie或浏览器的localStorage).
* 2. 将令牌发送到客户端: 服务器在发送HTML页面给客户端时, 会将令牌嵌入到页面中, 通常作为隐藏的表单字段或作为JavaScript变量.
* 3. 在请求中包含令牌: 当客户端向服务器发送请求时(如提交表单或执行AJAX请求), 它需要将令牌包含在请求中.
这通常是通过在表单字段中添加一个额外的输入字段或将令牌作为请求头(如X-CSRF-Token)来实现的.
* 4. 验证令牌: 服务器在收到请求时, 会检查请求中是否包含令牌, 并且令牌是否与存储在服务器上的会话数据中的令牌匹配.
如果令牌不存在或不匹配, 服务器将拒绝请求.
图11-16 设置CSRF防护功能
CSRF防护只适用于POST请求, 并不防护GET请求, 因为GET请求是以只读形式访问网站资源的, 一般情况下并不破坏和篡改网站数据.
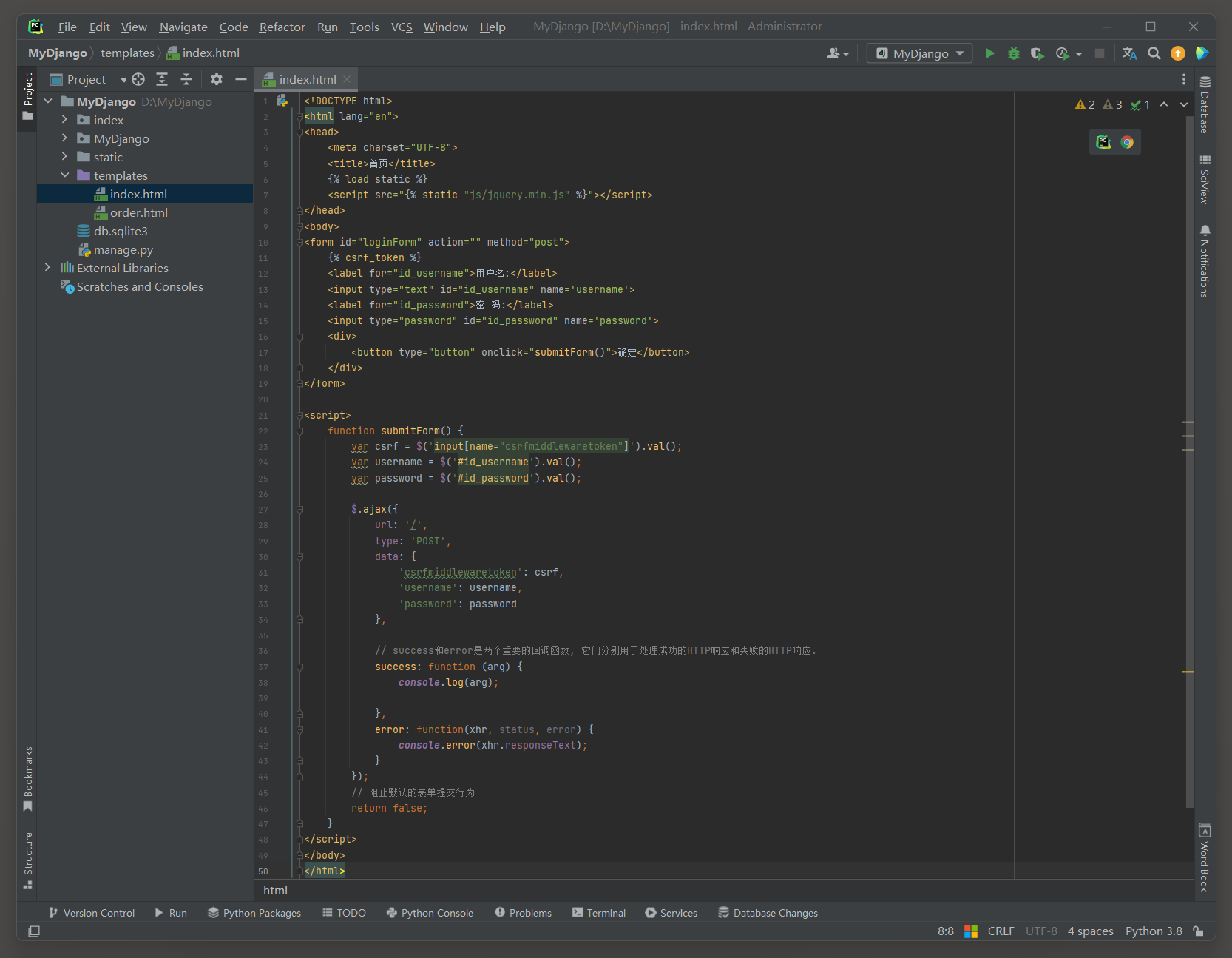
以MyDjango为例, 在模板文件index.html的表单<form>标签中加入内置标签csrf_token即可实现CSRF防护, 代码如下:
<!-- templates的index.html -->
<html>
<body>
<form action="" method="post">
{% csrf_token %}
<div>用户名:</div>
<input type="text" name='username'>
<div>密 码:</div>
<input type="password" name='password'>
<div><button type="submit">确定</button></div>
</form>
</body>
</html>
启动运行MyDjango, 在浏览器中访问网站首页(127.0.0.1:8000), 然后打开浏览器的开发者工具,
可以发现表单设有隐藏控件csrfmiddlewaretoken, 隐藏控件是由模板语法{% csrf_token %}生成的.
用户每次提交表单或刷新网页时, 隐藏控件csrfmiddlewaretoken的属性value都会随之变化, 如图11-17所示.
图11-17 隐藏控件csrfmiddlewaretoken
如果想要取消表单的CSRF防护, 那么可以在模板文件上删除{% csrf_token %},
并且在对应的视图函数中添加装饰器@csrf_exempt, 代码如下:
# index的views.py
from django.shortcuts import render
from django.views.decorators.csrf import csrf_exempt
# 取消CSRF防护
@csrf_exempt
def index(request):
return render(request, 'index.html')
如果只在模板文件上删除{% csrf_token %}, 并没有在对应的视图函数中设置过滤器@csrf_exempt,
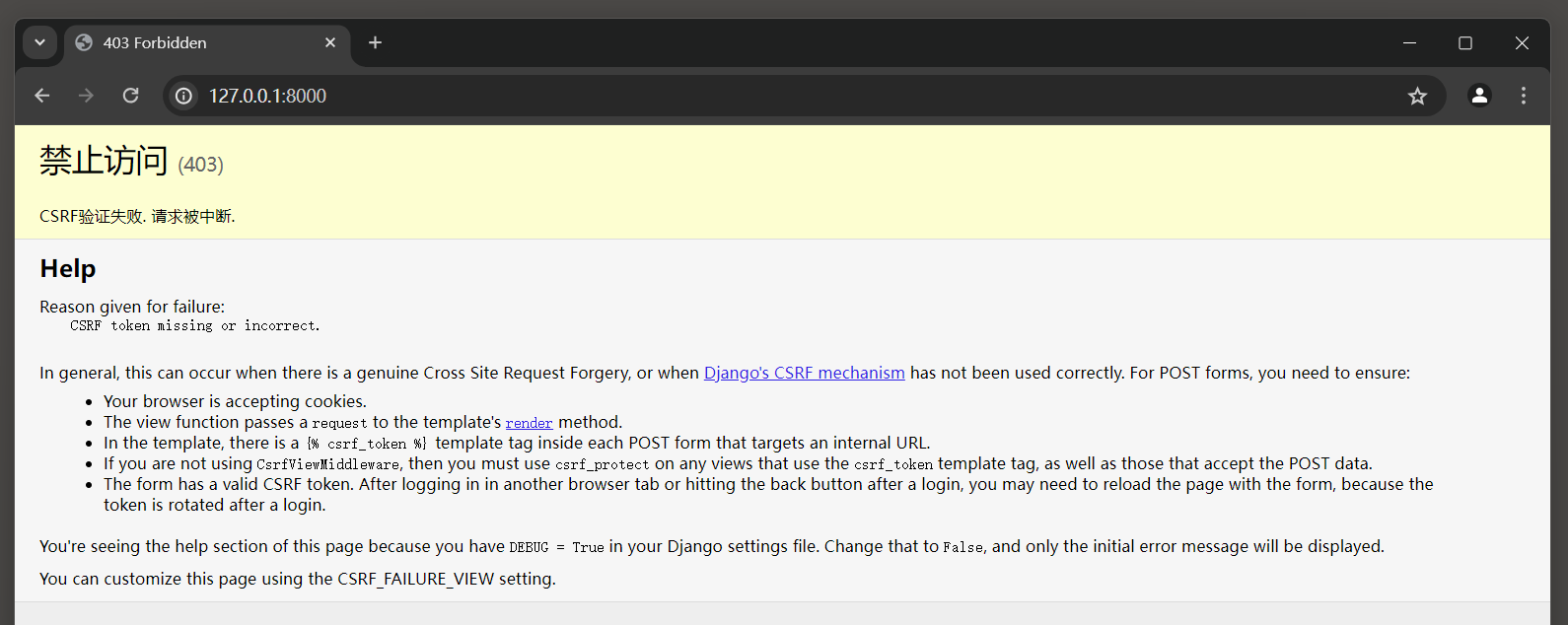
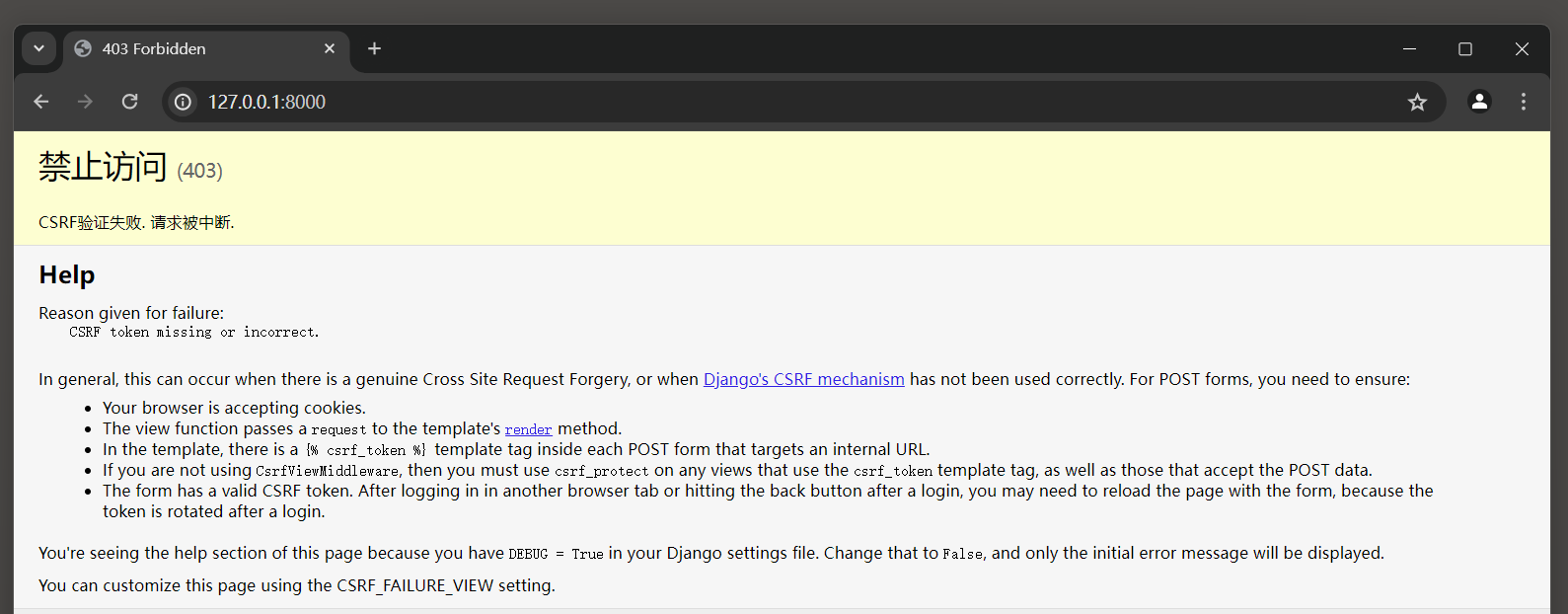
那么用户提交表单时, 程序会因CSRF验证失败而抛出403异常的页面, 如图11-18所示.
<!-- templates的index.html -->
<html>
<body>
<form action="" method="post">
<div>用户名:</div>
<input type="text" name='username'>
<div>密 码:</div>
<input type="password" name='password'>
<div><button type="submit">确定</button></div>
</form>
</body>
</html>
图11-18 CSRF验证失败
如果想取消整个网站的CSRF防护, 那么可以在settings.py的MIDDLEWARE注释的CSRF中间件CsrfViewMiddleware.
但在整个网站没有CSRF防护的情况下, 又想对某些请求设置CSRF防护, 那么可以在模板文件上添加模板语法{% csrf_token %},
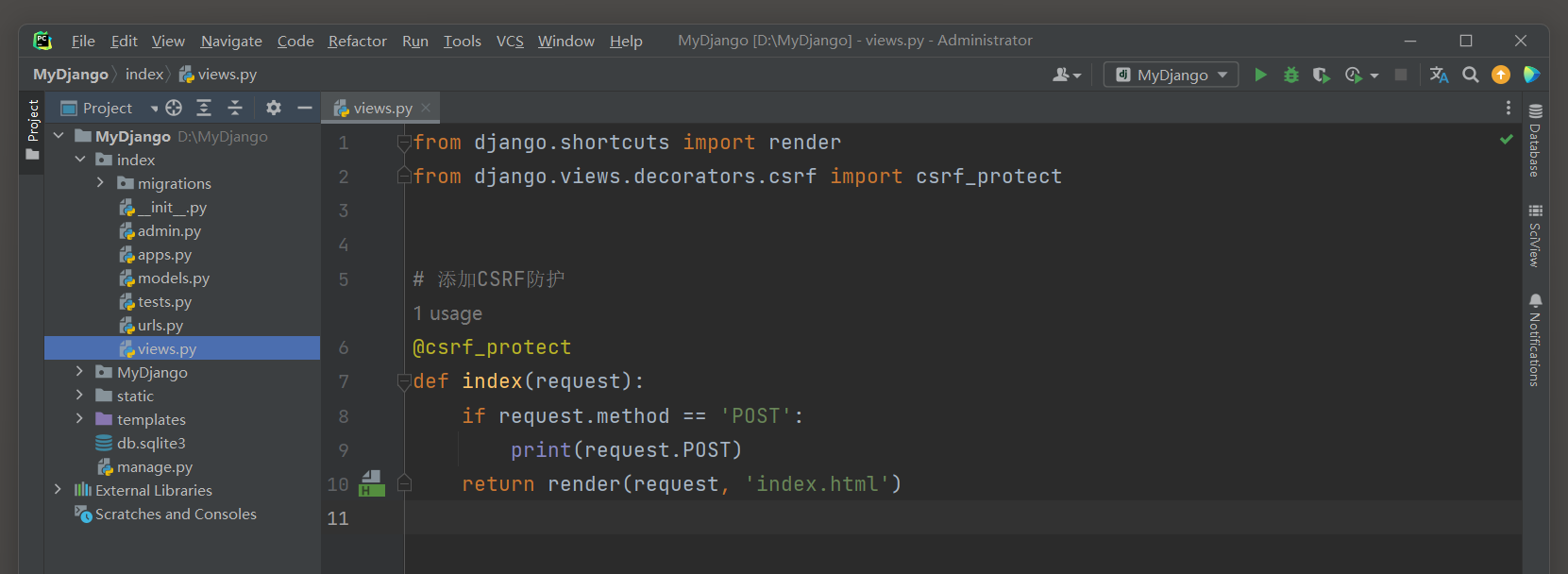
然后在对应的视图函数中添加装饰器@csrf_protect实现, 代码如下:
# index的views.py
from django.shortcuts import render
from django.views.decorators.csrf import csrf_protect
# 添加CSRF防护
@csrf_protect
def index(request):
if request.method == 'POST':
print(request.POST)
return render(request, 'index.html')
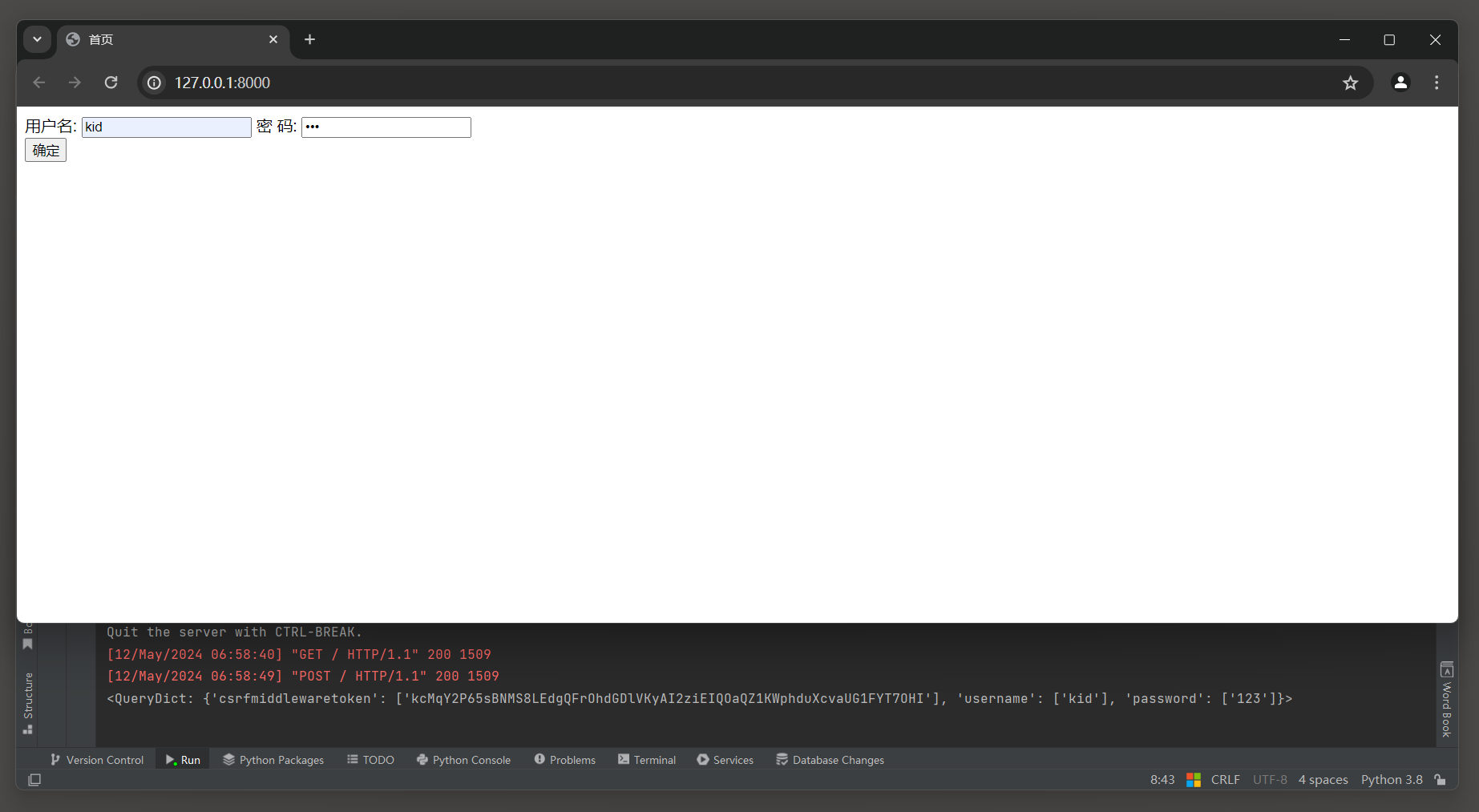
启动Django项目, 访问: 127.0.0.1:8000 , 在模板页面中没有添加csrf控件的时候, 提交表单结果如下:
如果网页表单是使用前端的Ajax向Django提交表单数据的, Django设置了CSRF防护功能,
Ajax发送POST请求就必须设置请求参数csrfmiddlewaretoken, 否则Django会将当前请求视为恶意请求.
Ajax发送POST请求的功能代码如下:
<!-- templates的index.html -->
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>首页</title>
{% load static %}
<script src="{% static "js/jquery.min.js" %}"></script>
</head>
<body>
<form id="loginForm" action="" method="post">
{% csrf_token %}
<label for="id_username">用户名:</label>
<input type="text" id="id_username" name='username'>
<label for="id_password">密 码:</label>
<input type="password" id="id_password" name='password'>
<div>
<button type="button" onclick="submitForm()">确定</button>
</div>
</form>
<script>
function submitForm() {
var csrf = $('input[name="csrfmiddlewaretoken"]').val();
var username = $('#id_username').val();
var password = $('#id_password').val();
$.ajax({
url: '/',
type: 'POST',
data: {
'csrfmiddlewaretoken': csrf,
'username': username,
'password': password
},
// success和error是两个重要的回调函数, 它们分别用于处理成功的HTTP响应和失败的HTTP响应.
success: function (arg) {
console.log(arg);
},
error: function(xhr, status, error) {
console.error(xhr.responseText);
}
});
// 阻止默认的表单提交行为
return false;
}
</script>
</body>
</html>
在HTML表单中, 如果使用了<button type="submit">或者没有指定type属性的<button>(默认就是type="submit"),
当用户点击这个按钮时, 浏览器会执行默认的表单提交行为, 这通常会导致页面跳转到表单的action属性所指定的URL.
然而, 如果想要使用AJAX来异步提交表单数据, 并且不想页面跳转或者刷新, 需要阻止这个默认的表单提交行为.
这可以通过在JavaScript的表单提交事件监听器中调用event.preventDefault()方法来实现.
除此之外, 还可以简单地返回false来达到同样的效果.
返回false实际上会同时调用event.preventDefault()和event.stopPropagation(),
这意味着它不仅阻止了表单的默认提交行为, 还阻止了事件向DOM树上级元素的冒泡.
不过, 在现代开发中, 更推荐使用event.preventDefault()来明确表明你的意图是阻止默认行为, 而不是阻止事件冒泡.
Ajax之所以被称为异步提交, 是因为它允许在不重新加载整个页面的情况下, 与服务器进行数据的交换并更新部分网页内容.
这种交换数据的方式是异步的, 意味着它不会阻塞用户的界面操作, 而是允许用户在等待服务器响应的同时继续与页面进行交互.
启动Django项目, 访问: 127.0.0.1:8000 , 提交表单结果如下:
11.4 消息框架
在网页应用中, 当用户完成某个功能操作时, 网站会有相应的消息提示.
Django内置的消息框架可以供开发者直接调用, 它允许开发者设置功能引擎, 消息类型和消息内容.
11.4.1 源码分析消息框架
消息框架由中间件SessionMiddleware(会话中间件), MessageMiddleware(消息中间件)
和INSTALLED_APPS的django.contrib.sessions(会话框架), django.contrib.messages(消息框架)共同实现.
在创建Django项目时, 消息框架已默认开启, 如图11-19所示.
图11-19 消息框架的配置信息
消息框架必须依赖会话中间件SessionMiddleware, 因为它的功能引擎默认使用FallbackStorage(备用存储),
而FallbackStorage是在Session的基础上实现的, 这说明中间件SessionMiddleware必须设置在MessageMiddleware的前面.
根据中间件MessageMiddleware的文件路径找到消息框架的源码文件,
为了更好地展示源码文件的目录结构, 我们在PyCharm里打开消息框架的源码文件, 如图11-20所示.
(Python38\Lib\site-packages\django\contrib\messages\storage)
图11-20 消息框架的目录结构
源码文件夹storage共有5个.py文件, 其中cookie.py, session.py和fallback.py,
分别定义消息框架的功能引擎CookieStorage, SessionStorage和FallbackStorage, 每个功能引擎说明如下:
● CookieStorage(Cookie存储): 是将消息提示的数据存储在浏览器的Cookie中, 并且数据经过加密处理,
如果存储的数据超过2048字节, 就将之前存储在Cookie的消息销毁.
● SessionStorage(会话存储): 是将消息提示的数据存储在服务器的Session中,
因此它依赖于INSTALLED_APPS的sessions和中间件SessionMiddleware.
● FallbackStorage(备用存储): 是将CookieStorage和SessionStorage结合使用,
这是Django默认使用的功能引擎, 它根据数据大小选择合适的存储方式, 优先选择CookieStorage存储.
然后分析源码文件constants.py, 它一共定义了5种消息类型, 每种类型设置了不同的级别, 每种消息类型说明如表11-1所示.
类型
级别值
说明
DEBUG10开发过程的调试信息, 但运行时无法生成信息
INFO20提示信息, 如用户信息
SUCCESS25提示当前操作执行成功
WARNING30警告当前操作存在风险
ERROR40提示当前操作错误
表11-1 Django内置的5种消息类型
最后分析源码文件api.pym该文件定义消息框架的使用方法, 一共定义9个函数, 每个函数的说明如下:
● add_message(): 为用户添加消息提示.
参数request代表当前用户的请求对象; 参数level是消息类型或级别; 参数message为消息内容;
参数extra_tags是自定义消息提示的标记, 可在模板里生成上下文;
参数fail_silently在禁用中间件MessageMiddleware的情况下还能添加消息提示, 一般情况下使用默认值即可.
● debug(): 添加消息类型为debug的消息提示.
● info(): 添加消息类型为info的消息提示.
● success(): 添加消息类型为success的消息提示.
● warning(): 添加消息类型为warning的消息提示.
● error(): 添加消息类型为error的消息提示.
● get_messages(): 获取用户的消息提示.
参数request代表当前用户的请求对象.
● get_level(): 获取用户所有消息提示最低级别的值.
参数request代表当前用户的请求对象.
● set_level(): 对不同类型的消息提示进行筛选处理.
参数request代表当前用户的请求对象;
参数level是消息类型或级别, 从用户的消息提示筛选并保留比参数level级别高的消息提示.
11.4.2 消息框架的使用
在开发过程中, 我们在视图里使用消息框架为用户添加消息提示,
然后将消息提示传递给模板, 再由模板引擎解析上下文, 最后生成相应的HTML网页.
也就是说, 消息框架主要在视图和模板里使用, 而且消息框架在视图函数和视图类中有着不一样的使用方式.
以MyDjango为例, 在配置文件settings.py中设置消息框架的功能引擎, 3种功能引擎的设置方式如下:
# MyDjango的settings.py
# 设置消息框架的功能引擎(设置消息存储使用的方式)
# MESSAGE_STORAGE = 'django.contrib.messages.storage.cookie.CookieStorage'
# MESSAGE_STORAGE = 'django.contrib.messages.storage.session.SessionStorage'
# FallbackStorage是默认使用的, 无须设置
MESSAGE_STORAGE = 'django.contrib.messages.storage.fallback.FallbackStorage'
在MyDjango的urls.py和项目应用index的urls.py中分别定义路由index, success和create.
路由index和create分别指向视图函数index和视图类MyCreateView,
路由success用于设置视图类MyCreateView的属性success_url(意思是MyCreateView中数据创建成功后, 重定向到success路由).
MyDjango的路由信息如下:
# MyDjango的urls.py
from django.urls import path, include
urlpatterns = [
path('', include(('index.urls', 'index'), namespace='index')),
]
# index的urls.py
from django.urls import path
from .views import *
urlpatterns = [
path('', index, name='index'),
path('success', success, name='success'),
path('create', MyCreateView.as_view(), name='create'),
]
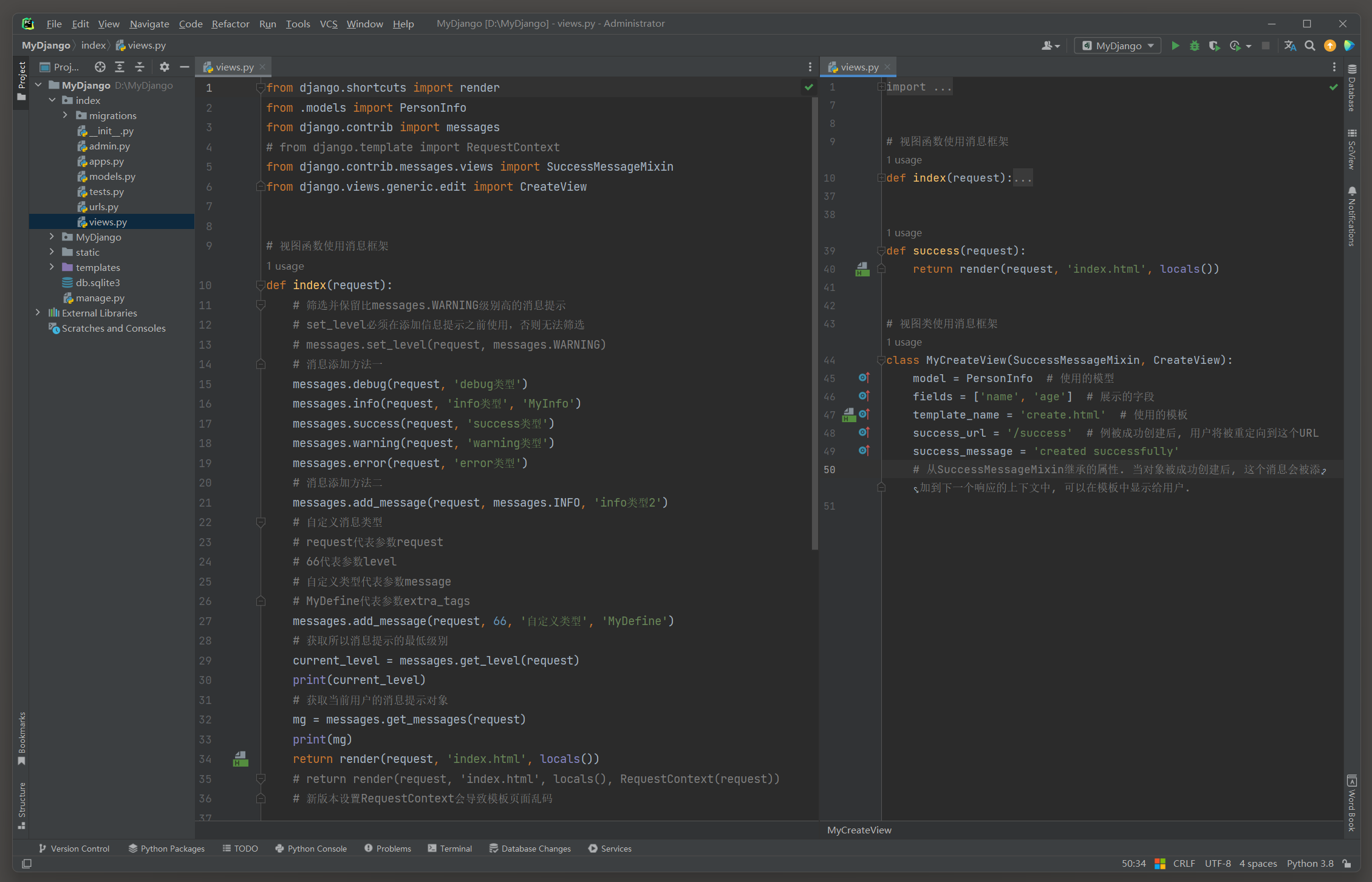
下一步在index的views.py中定义视图函数index, success和视图类MyCreateView, 三者的代码如下:
# index的views.py
from django.shortcuts import render
from .models import PersonInfo
from django.contrib import messages
# from django.template import RequestContext
from django.contrib.messages.views import SuccessMessageMixin
from django.views.generic.edit import CreateView
# 视图函数使用消息框架
def index(request):
# 筛选并保留比messages.WARNING级别高的消息提示
# set_level必须在添加信息提示之前使用,否则无法筛选
# messages.set_level(request, messages.WARNING)
# 消息添加方法一
messages.debug(request, 'debug类型')
messages.info(request, 'info类型', 'MyInfo')
messages.success(request, 'success类型')
messages.warning(request, 'warning类型')
messages.error(request, 'error类型')
# 消息添加方法二
messages.add_message(request, messages.INFO, 'info类型2')
# 自定义消息类型
# request代表参数request
# 66代表参数level
# 自定义类型代表参数message
# MyDefine代表参数extra_tags
messages.add_message(request, 66, '自定义类型', 'MyDefine')
# 获取所以消息提示的最低级别
current_level = messages.get_level(request)
print(current_level)
# 获取当前用户的消息提示对象
mg = messages.get_messages(request)
print(mg)
return render(request, 'index.html', locals())
# return render(request, 'index.html', locals(), RequestContext(request))
# 新版本设置RequestContext会导致模板页面乱码
def success(request):
return render(request, 'index.html', locals())
# 视图类使用消息框架
class MyCreateView(SuccessMessageMixin, CreateView):
model = PersonInfo # 使用的模型
fields = ['name', 'age'] # 展示的字段
template_name = 'create.html' # 使用的模板
success_url = '/success' # 例被成功创建后, 用户将被重定向到这个URL
success_message = 'created successfully'
# 从SuccessMessageMixin继承的属性. 当对象被成功创建后, 这个消息会被添加到下一个响应的上下文中, 可以在模板中显示给用户.
视图函数index列举了9个函数的使用方法, 这是整个消息框架的使用方法,
-- 视图函数的返回值必须设置RequestContext(request), 这是Django的上下文处理器, 确保消息提示对象messages能在模板中使用. --
( 使用RequestContext(request)后会导致模板页面乱码!!!, 不设置这个返回值也可以使用消息提示!!!
在Django 1.8及以后的版本中, render函数已经默认使用RequestContext(或类似的机制), 所以不需要显式地传递RequestContext.
然而, 如果你需要确保使用RequestContext(或只是出于某种原因想要这样做),
可以手动创建一个RequestContext实例并将其与模板一起传递给render_to_response函数(注意, 不是render函数).
但是, 通常建议使用 render 函数. )
视图类iClass继承父类SuccessMessageMixin和CreateView, 父类的继承顺序是固定不变的, 否则无法生成消息提示.
SuccessMessageMixin由消息框架定义, CreateView是数据新增视图类.
视图类iClass的类属性success_message来自SuccessMessageMixin, 其他的类属性均来自CreateView.
消息框架定义的SuccessMessageMixin只能用于数据操作视图,
也就是说只能与视图类FormView, CreateView, UpdateView和DeleteView结合使用.
(SuccessMessageMixin不应与不涉及表单处理或数据库操作的视图一起使用, 例如:
TemplateView: 仅用于渲染模板, 不涉及表单处理或数据库操作.
RedirectView: 仅用于重定向到另一个URL, 不涉及表单处理或数据库操作.
DetailView: 用于显示数据库对象的详细信息, 但不涉及表单处理或数据库对象的修改. )
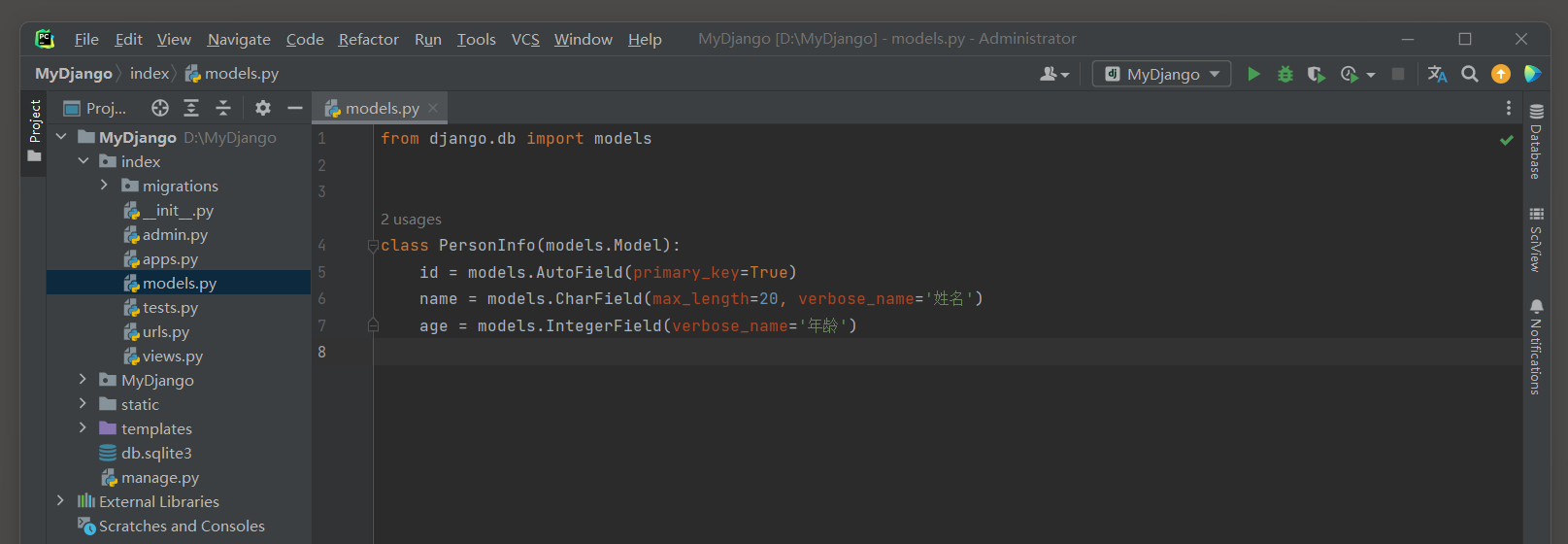
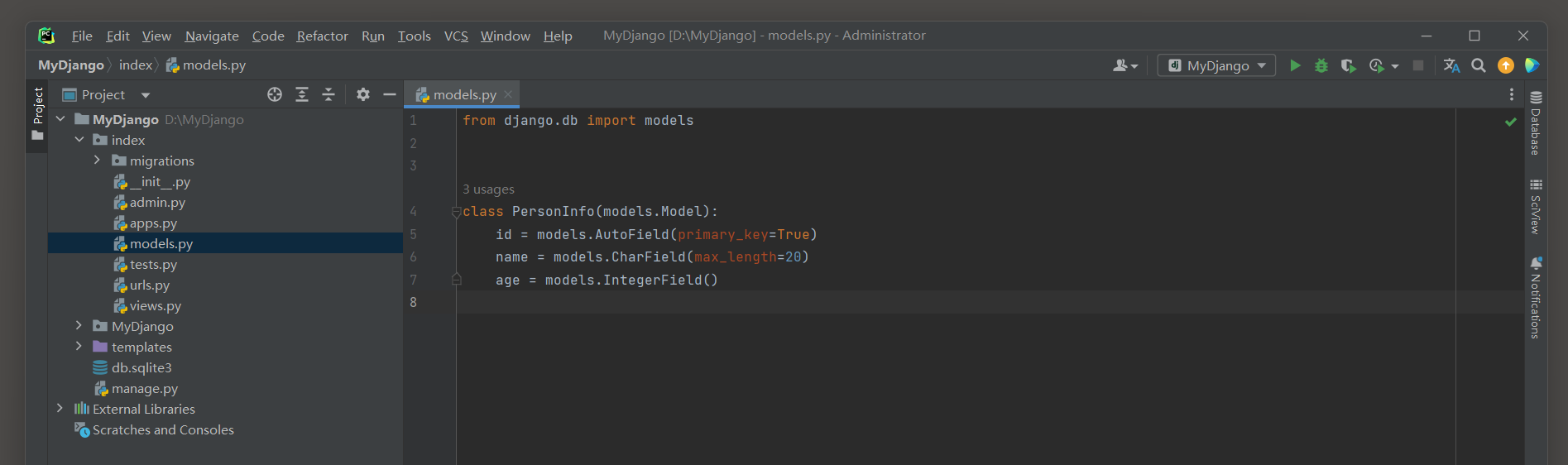
由于视图函数index使用模板文件index.html, 视图类MyCreateView使用模型PersonInfo和模板文件create.html,
因此在index的models.py中定义模型PersonInfo, 然后在模板文件夹templates中创建index.html和create.html,
最后分别在index的models.py, 模板文件index.html和create.html中编写以下代码:
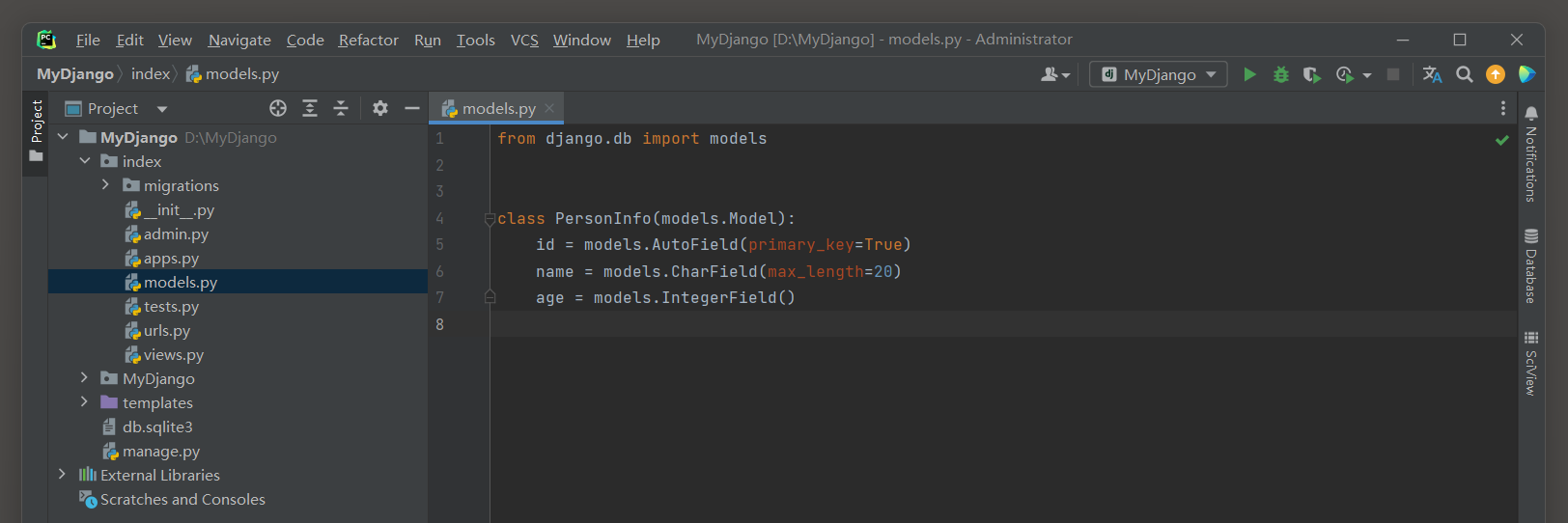
# index的models.py
from django.db import models
class PersonInfo(models.Model):
id = models.AutoField(primary_key=True)
name = models.CharField(max_length=20, verbose_name='姓名')
age = models.IntegerField(verbose_name='年龄')
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>消息提示</title>
</head>
<body>
{% if messages %}
<ul>
{% for m in messages %}
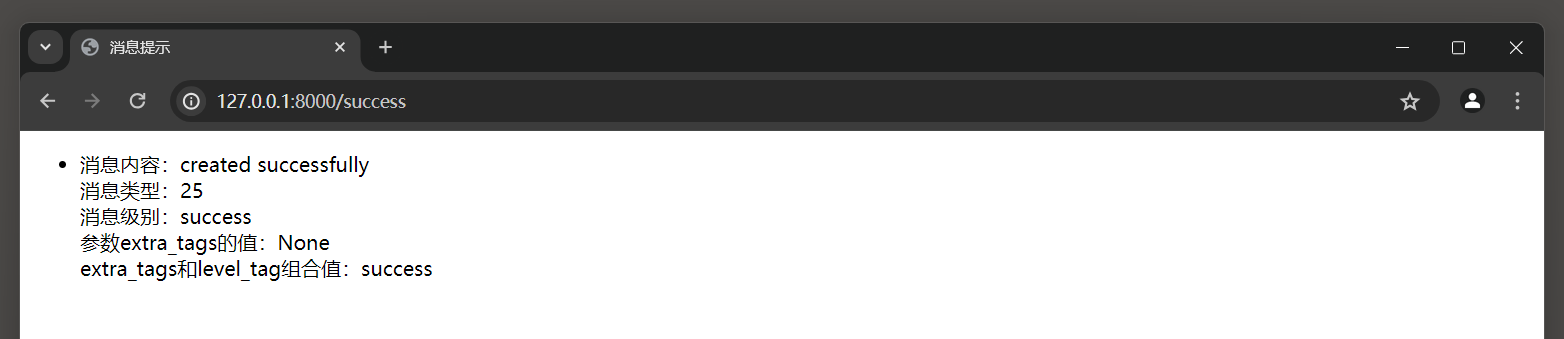
<li>消息内容: {{ m.message }}</li>
<div>消息类型: {{ m.level }}</div>
<div>消息级别: {{ m.level_tag }}</div>
<div>参数extra_tags的值: {{ m.extra_tags }}</div>
<div>extra_tags和level_tag组合值: {{ m.tags }}</div>
{% endfor %}
</ul>
{% else %}
<script>alert('暂无消息!');</script>
{% endif %}
</body>
</html>
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>数据新增</title>
</head>
<body>
<h3>数据新增</h3>
<form action="" method="post">
{% csrf_token %}
{{ form.as_p }}
<input type="submit" value="确定">
</form>
</body>
</html>
模板文件index.html将消息提示对象messages进行遍历访问, 每次遍历获取某条消息提示,
并将当前消息提示的所有属性进行列举说明, 通过这些属性可以控制消息提示的输出和CSS样式设置等操作.
在运行MyDjango之前, 记得执行数据迁移, 让模型PersonInfo在数据库中生成数据表,
否则视图类iClass无法正常使用模型PersonInfo.
# 数据库迁移
D:\MyDjango> python manage.py makemigrations
Migrations for 'index':
index\migrations\0002_auto_20240512_1826.py
- Create model PersonInfo
- Delete model Product
D:\MyDjango> python manage.py migrate
Operations to perform:
Apply all migrations: admin, auth, contenttypes, index, sessions
Running migrations:
Applying index.0002_auto_20240512_1826... OK
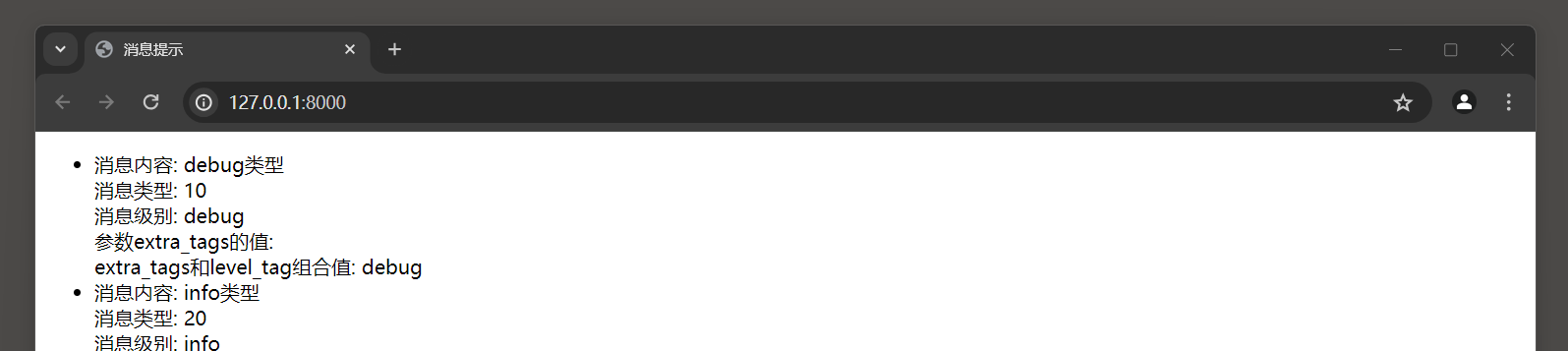
最后运行MyDjango, 在浏览器上访问: 127.0.0.1:8000 , 可以看到每条消息提示的属性内容, 如图11-21所示.
图11-21 消息提示
如果想要使用DEBUG级别的消息, 可以手动将消息的级别设置可以在Django的设置文件中添加如下代码
# MyDajgno 的 settings.py
MESSAGE_LEVEL = 10 # 设置等级为dubug级别
在浏览器上访问: 127.0.0.1:8000/create 并在网页表单中输入数据, 然后单击'确定'按钮, 即可在数据表index_personinfo中新增数据.
在新增数据的过程中, 视图类MyCreateView创建消息提示对象messages, 并将对象messages传递给视图函数success,
再由视图函数success传递给模板文件index.html, 最终生成相应的消息提示, 如图11-22所示.
图11-22 消息提示
11.5 分页功能
在网页上浏览数据的时候, 数据列表的下方能够看到翻页功能, 而且每一页的数据各不相同.
比如在淘宝上搜索某商品的关键字, 淘宝会根据用户提供的关键字返回符合条件的商品信息,
并且对这些商品信息进行分页处理, 用户可以在商品信息的下方单击相应的页数按钮查看.
11.5.1 源码分析分页功能
Django已为开发者提供了内置的分页功能, 开发者无须自己实现数据分页功能, 只需调用Django内置分页功能的函数即可实现.
实现数据的分页功能需要考虑多方面的因素, 分别说明如下:
● 当前用户访问的页数是否存在上(下)一页.
● 访问的页数是否超出页数上限.
● 数据如何按页截取, 如何设置每页的数据量.
对于上述考虑因素, Django内置的分页功能已提供解决方法, 而且代码的实现方式相对固定, 便于开发者理解和使用.
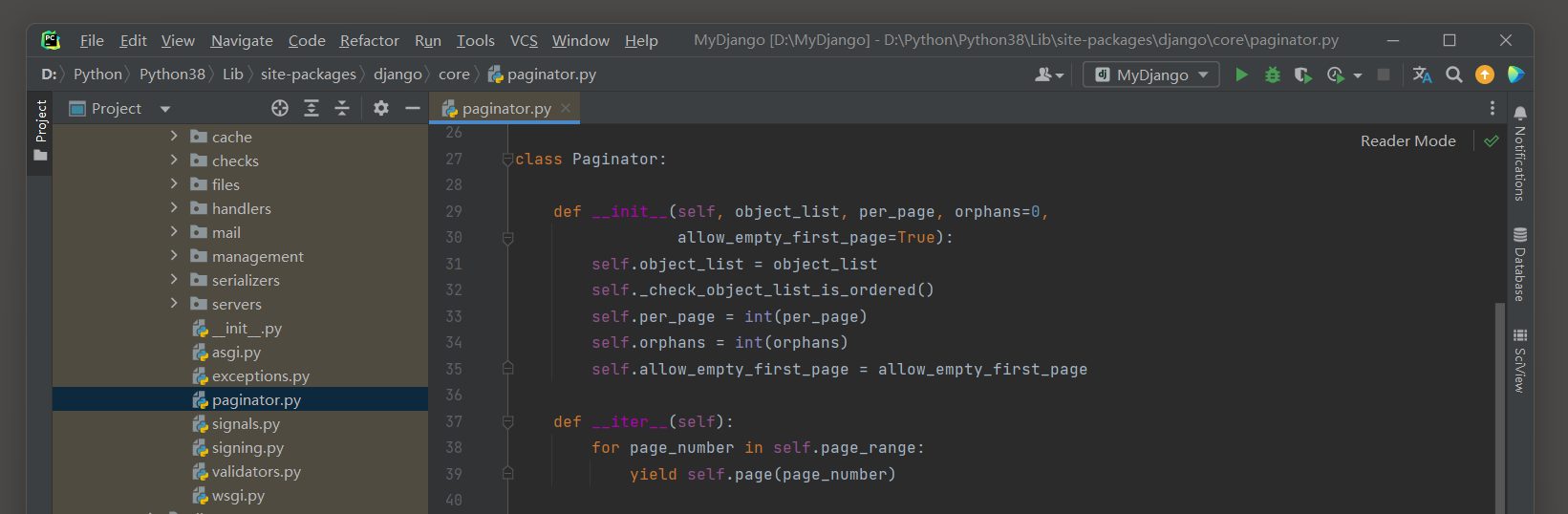
分页功能由Paginator类实现, 我们在PyCharm里查看该类的定义过程, 如图11-23所示.
图11-23 源码文件paginator.py
Paginator类一共定义了4个初始化参数和8个类方法, 每个初始化参数和类方法的说明如下:
● object_list: 必选参数, 代表需要进行分页处理的数据, 参数值可以为列表, 元组或ORM查询的数据对象等.
● per_page: 必选参数, 设置每一页的数据量, 参数值必须为整型.
● orphans: 可选参数, 如果最后一页的数据量小于或等于参数orphans的值, 就将最后一页的数据合并到前一页的数据.
比如有23行数据, 若参数per_page=10, orphans=5, 则数据分页后的总页数为2, 第一页显示10行数据, 第二页显示13行数据.
● allow_empty_first_page: 可选参数, 是否允许第一页为空.
如果参数值为False并且参数object_list为空列表, 就会引发EmptyPage错误.
● validate_number(): 验证当前页数是否大于或等于1.
● get_page(): 调用validate_number()验证当前页数是否有效, 函数返回值调用page().
● page(): 根据当前页数对参数object_list进行切片处理, 获取页数所对应的数据信息, 函数返回值调用_get_page().
● _get_page(): 调用Page类, 并将当前页数和页数所对应的数据信息传递给Page类, 创建当前页数的数据对象.
● count(): 获取参数object_list的数据长度.
● num_pages(): 获取分页后的总页数.
● page_range(): 将分页后的总页数生成可循环对象.
● _check_object_list_is_ordered(): 如果参数object_list是ORM查询的数据对象,
并且该数据对象的数据是无序排列的, 就提示警告信息.
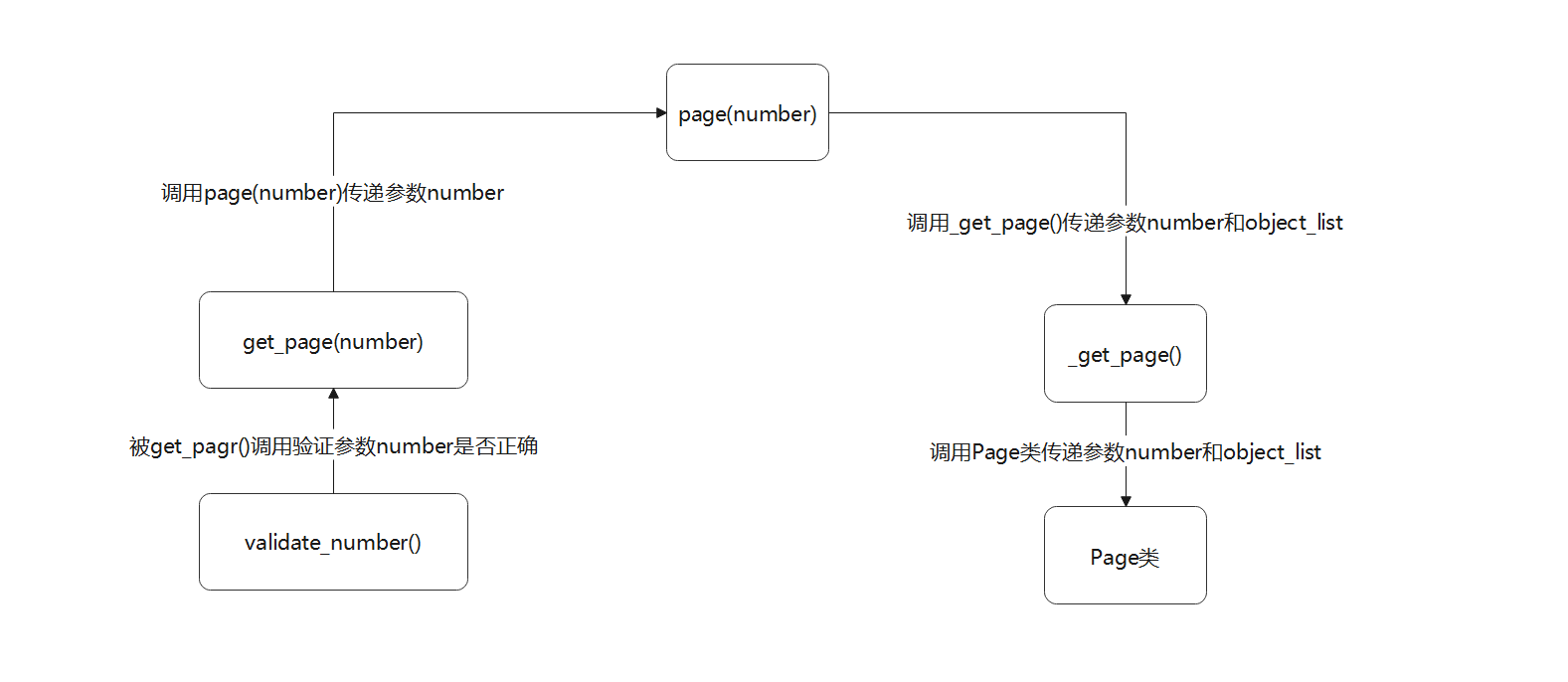
从Paginator类定义的get_page(), page()和_get_page()得知, 三者之间存在调用关系,
我们将它们的调用关系以流程图的形式表示, 如图11-24所示.
图11-24 函数的调用关系
从图11-24得知, 我们将Paginator类实例化之后, 再由实例化对象调用get_page()即可得到Page类的实例化对象.
在源码文件paginator.py中可以找到Page类的定义过程, 它一共定义了3个初始化参数和7个类方法, 每个初始化参数和类方法的说明如下:
● object_list: 必选参数, 代表已切片处理的数据对象.
● number: 必选参数, 代表用户传递的页数.
● paginator: 必选参数, 代表Paginator类的实例化对象.
● has_next(): 判断当前页数是否存在下一页.
● has_previous(): 判断当前页数是否存在上一页.
● has_other_pages(): 判断当前页数是否存在上一页或者下一页.
● next_page_number(): 如果当前页数存在下一页, 就输出下一页的页数, 否则抛出EmptyPage异常.
● previous_page_number(): 如果当前页数存在上一页, 就输出上一页的页数, 否则抛出EmptyPage异常.
● start_index(): 输出当前页数的第一行数据在整个数据列表的位置, 数据位置从1开始计算.
● end_index(): 输出当前页数的最后一行数据在整个数据列表的位置, 数据位置从1开始计算.
上述是从源码的角度剖析分页功能的参数和方法, 下一步在PyCharm的Terminal中开启Django的Shell模式,
简单地讲述如何使用分页功能, 代码如下:
D:\MyDjango> python manage.py shell
# 导入分页功能模块
>>> from django.core.paginator import Paginator
# 生成数据列表(将数字转换为字母a-j)
>>> objects = [chr(x) for x in range(97, 107)]
>>> objects
['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j']
# 将数据列表以每3个元素分为一页
>>> p = Paginator(objects, 3)
# 输出全部数据, 即整个数据列表
>>> p.object_list
['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j']
# 获取数据列表的长度
>>> p.count
10
# 分页后的总页数
>>> p.num_pages
4
# 将页数转换成range循环对象
>>> p.page_range
range(1, 5)
# 获取第二页的数据信息
>>> page2 = p.get_page(2)
# 判断第二页是否存在上一页
>>> page2.has_previous()
True
# 如果当前页存在上一页, 就输出上一页的页数
# 否则抛出EmptyPage异常
>>> page2.previous_page_number()
1
# 判断第二页是否存在下一页
>>> page2.has_next()
True
# 如果当前页存在下一页, 就输出下一页的页数
# 否则抛出EmptyPage异常
>>> page2.next_page_number()
3
# 判断当前页是否存在上一页或者下一页
>>> page2.has_other_pages()
True
# 输出第二页所对应的数据内容
>>> page2.object_list
['d', 'e', 'f']
# 输出第二页的第一行数据在整个数据列表的位置
# 数据位置从1开始计算
>>> page2.start_index()
4
# 输出第二页的最后一行数据在整个数据列表的位置
# 数据位置从1开始计算
>>> page2.end_index()
11.5.2 分页功能的使用
我们对Django的分页功能已经深入地分析过了, 并初步掌握了使用方式, 本节将以项目的形式来讲述如何在开发过程中使用分页功能.
以MyDjango为例, 首先在index的models.py中定义模型PersonInfo, 模型的定义过程如下:
# index的models.py
from django.db import models
class PersonInfo(models.Model):
id = models.AutoField(primary_key=True)
name = models.CharField(max_length=20)
age = models.IntegerField()
下一步对模型PersonInfo执行数据迁移, 在数据库中创建相应的数据表.
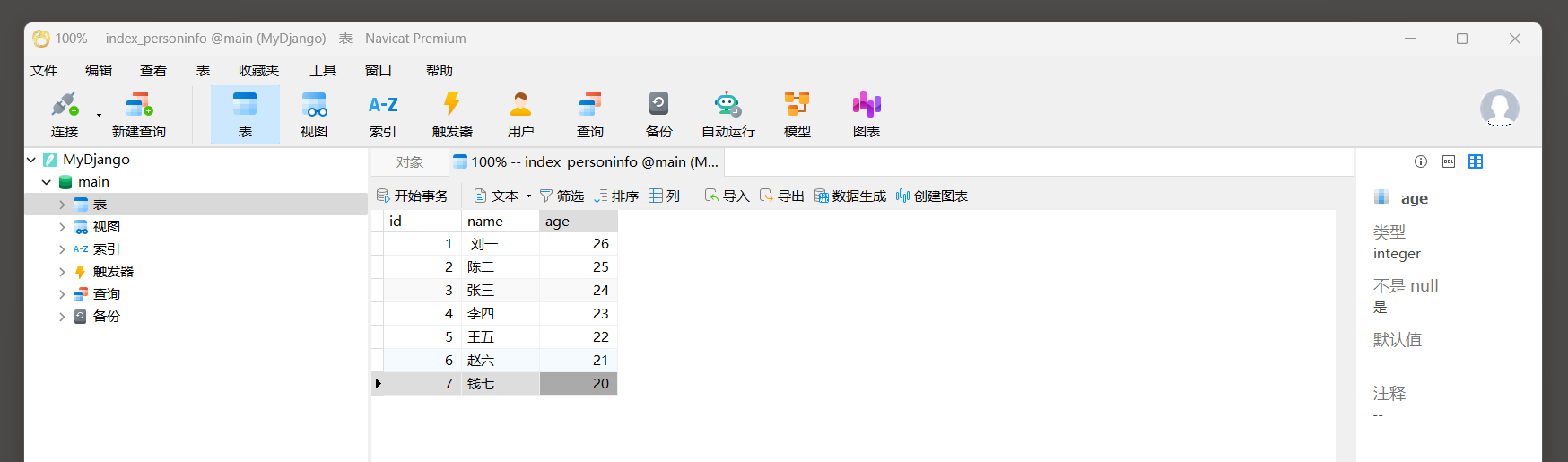
完成数据迁移后, 使用数据库可视化工具(Navicat Premium)连接MyDjango的db.sqlite3文件,
查看数据表index_personinfo, 并在数据表中添加数据信息, 如图11-25所示.
# 进行数据迁移
PS D:\MyDjango> Python manage.py makemigrations
Migrations for 'index':
index\migrations\0001_initial.py
- Create model PersonInfo
PS D:\MyDjango> python manage.py migrate
图11-25 数据表index_personinfo
完成项目的数据搭建后, 我们将进入数据页面进行开发.
在MyDjango的urls.py和index的urls.py中定义数据页面的路由信息, 代码如下:
# MyDjango 的 urls.py
from django.urls import path, include
urlpatterns = [
path('', include(('index.urls', 'index'), namespace='index')),
]
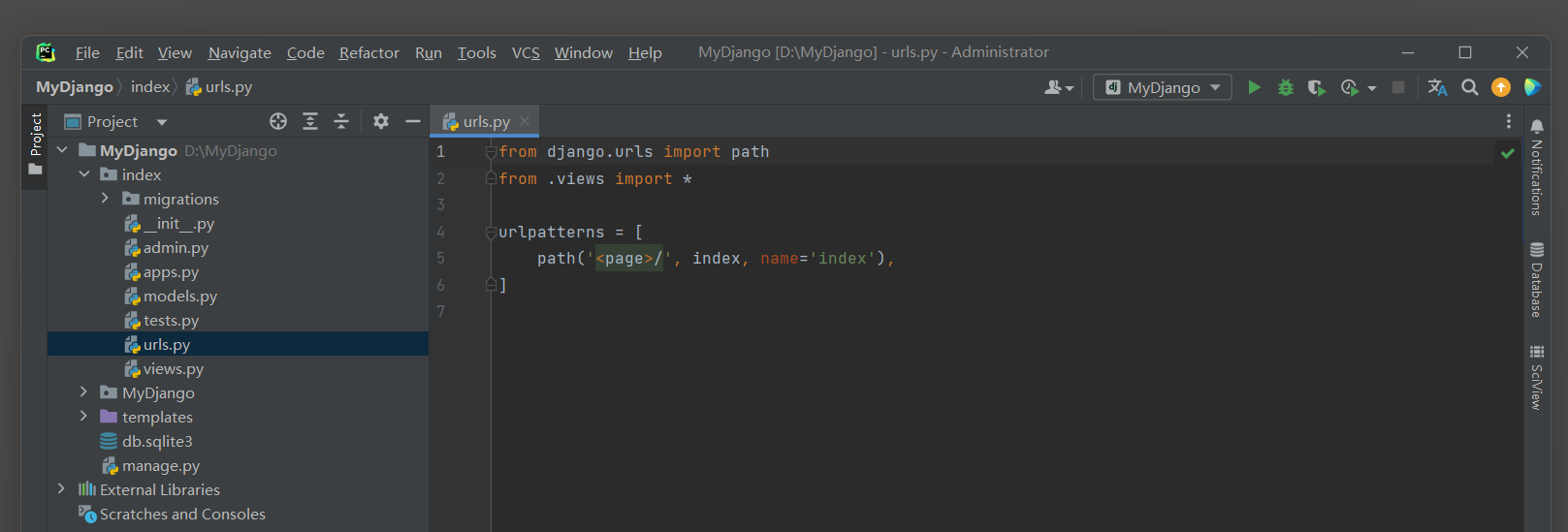
# index的urls.py
from django.urls import path
from .views import *
urlpatterns = [
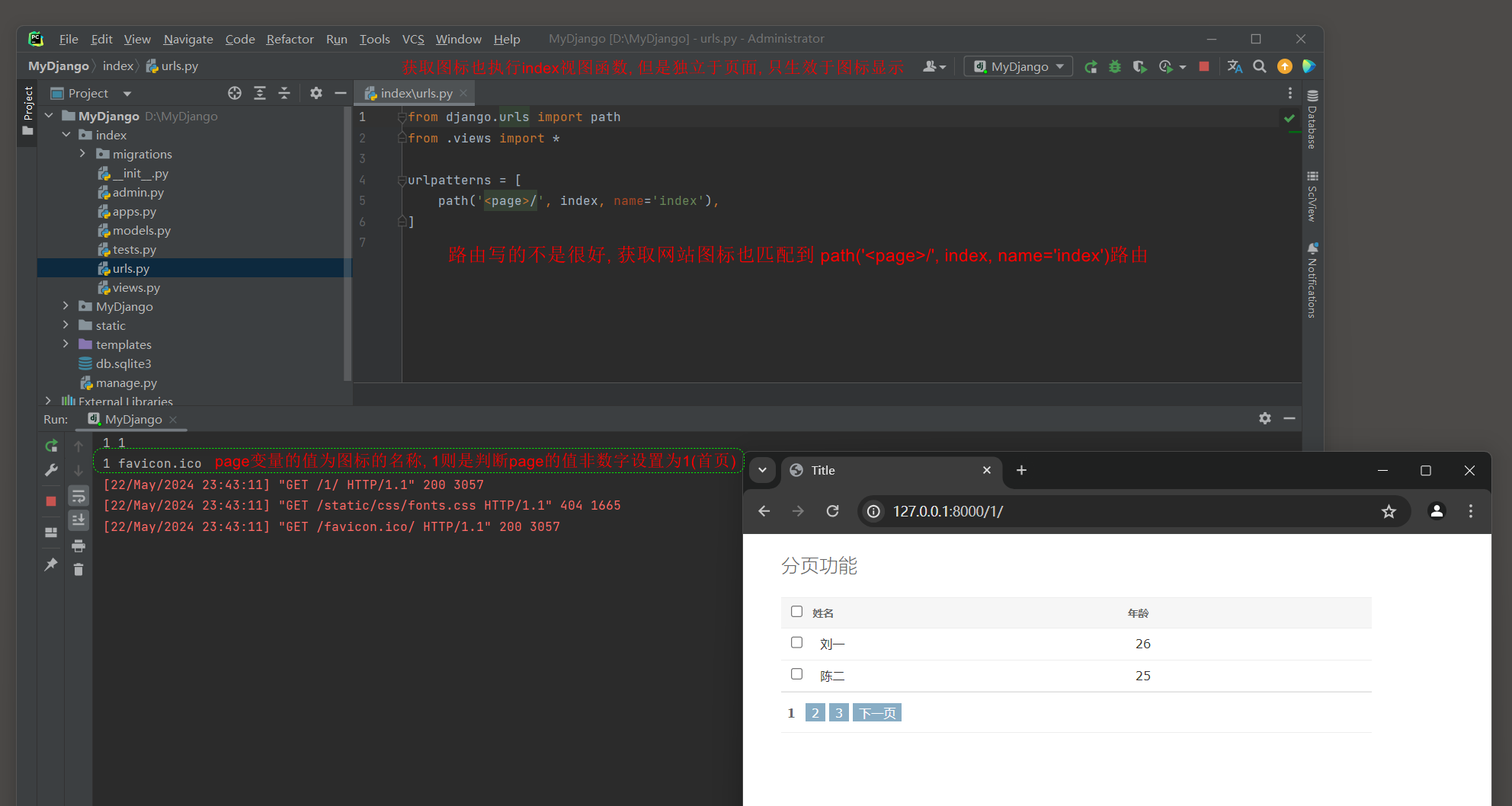
path('<page>/', index, name='index'),
]
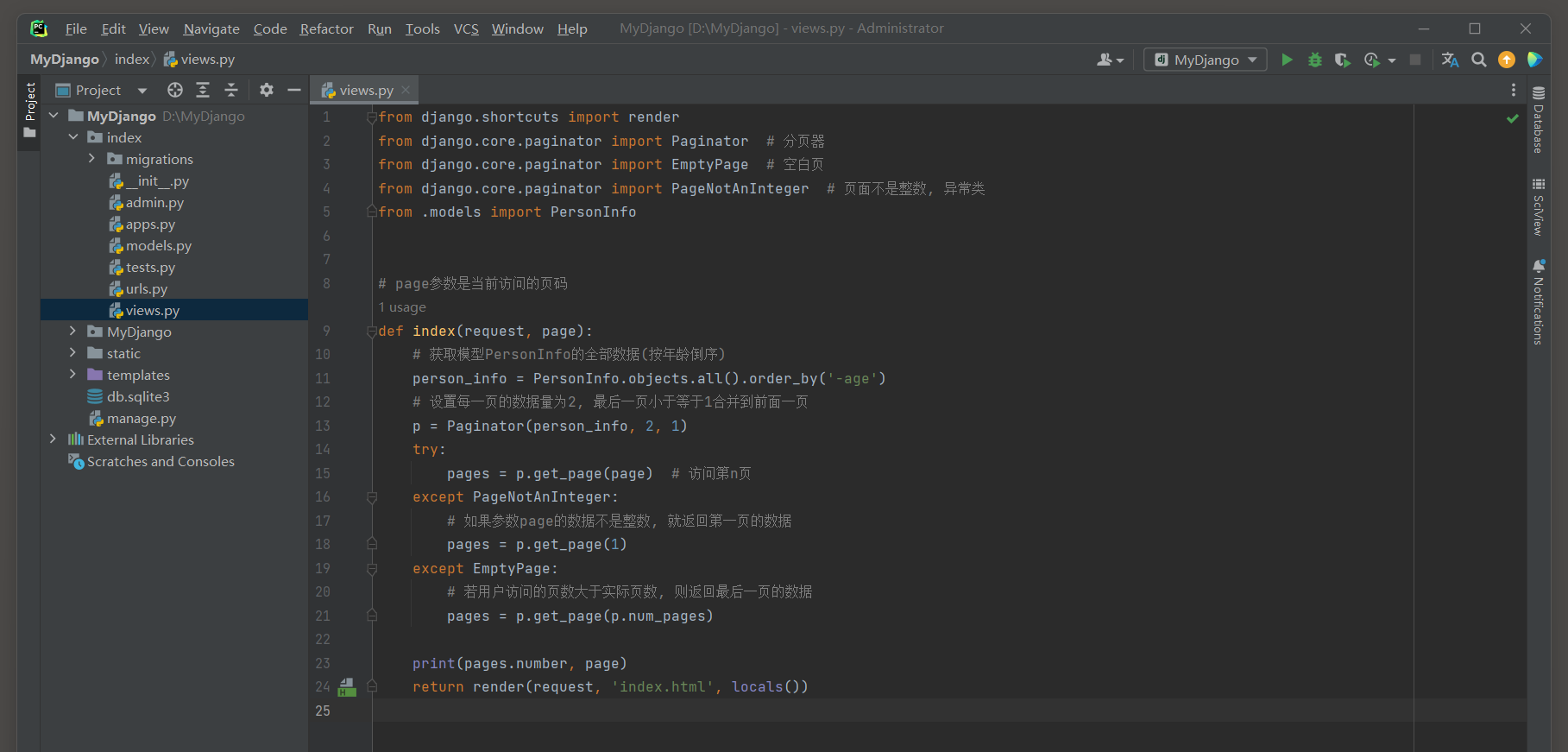
在index的views.py中定义视图函数index, 视图函数查询模型PersonInfo的所有数据并对数据执行分页处理, 实现的代码如下:
from django.shortcuts import render
from django.core.paginator import Paginator # 分页器
from django.core.paginator import EmptyPage # 空白页
from django.core.paginator import PageNotAnInteger # 页面不是整数, 异常类
from .models import PersonInfo
# page参数是当前访问的页码
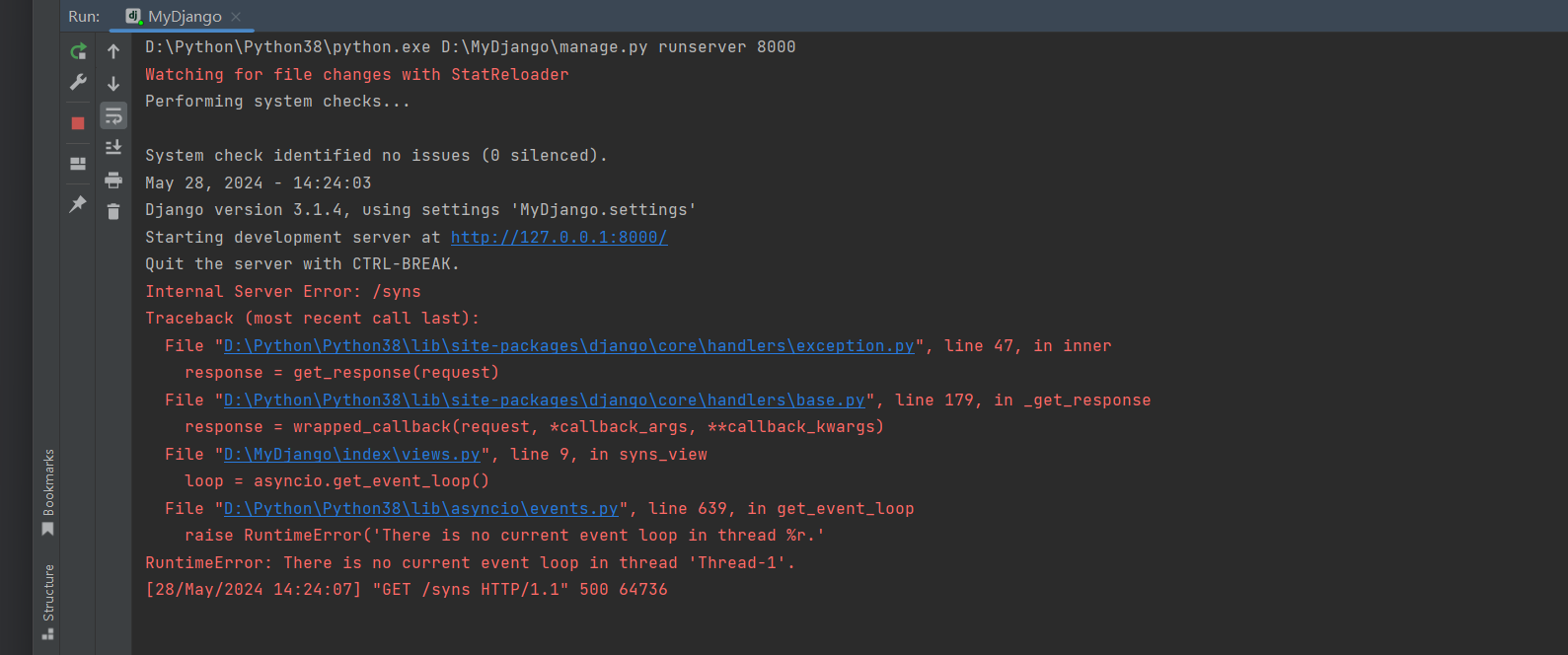
def index(request, page):
# 获取模型PersonInfo的全部数据(按年龄倒序)
person_info = PersonInfo.objects.all().ordered_by('-age')
# 设置每一页的数据量为2, 最后一页小于等于1合并到前面一页
p = Paginator(person_info, 2, 1)
try:
pages = p.get_page(page) # 访问第n页
except PageNotAnInteger:
# 如果参数page的数据不是整数, 就返回第一页的数据
pages = p.get_page(1)
except EmptyPage:
# 若用户访问的页数大于实际页数, 则返回最后一页的数据
pages = p.get_page(p.num_pages)
return render(request, 'index.html', locals())
7条数据, 两条为一页展示, 7 // 2 = 3 ... 1 , 设置最后一页的记录小于等于3合并到前一页展示.
p.num_pages查看总页数是3.
视图函数index设有参数page, 参数page来自路由变量page; 变量person_info用于查询模型PersonInfo的数据对象,
数据查询过程使用order_by对数据进行排序, 否则在执行分页处理时将会提示警告信息, 如图11-26所示.
图11-26 提示警告信息
(对未排序的QuerySet进行分页时, 如果数据库中的数据有所变动(例如, 有新的数据插入或旧的数据被删除),
那么相同的页码可能会显示不同的数据, 因为数据库在返回结果时可能会选择不同的顺序.
这可能会导致用户体验不一致, 或者在某些情况下, 甚至可能导致数据安全问题.
Django的Paginator类在创建分页对象时, 会检查QuerySet是否使用了order_by()方法.
如果没有, Django就会发出UnorderedObjectListWarning警告, 以提醒你注意这个问题.
这个警告通常是通过Django的内部检查机制触发的, 这个机制会检查传递给Paginator的QuerySet是否包含了一个显式的排序.
具体来说, Django会查看QuerySet的query属性, 该属性是一个Query对象, 它包含了查询的详细信息, 包括是否使用了ORDER BY子句.)
参数page和变量person都是为分页功能提供数据信息,
使用分页功能实现数据分页是在视图函数index的try...except代码里实现的, 实现过程如下:
(1) 实例化Paginator类, 参数object_list为变量person, 参数per_page设为2, 参数orphans设为1,
这是对变量person的数据进行分页处理, 每页的数据量为2, 若最后一页的数据量小于或等于1, 则将最后一页的数据合并到前一页的数据.
(2) 由对象p调用函数get_page, 并传入参数page; 函数get_page将参数page传入Page类执行实例化, 生成实例化对象pages.
(3) 参数page传入Page类执行实例化的过程中可能出现3种情况.
① 第一种是参数page的值在总页数的范围内, 根据参数page的值获取对应页数的数据信息.
② 第二种是参数page的数据类型不是整型, 这时将触发PageNotAnInteger异常, 异常处理是返回第一页的数据信息.
③ 第三种是参数page的值超出总页数的范围, 这时触发EmptyPage异常, 异常处理是返回最后一页的数据信息.
在MyDjango项目目录下添加static目录, 并settings.py中配置静态文件地址.
# settings.py
STATIC_URL = '/static/'
STATICFILES_DIRS = [BASE_DIR, 'static']
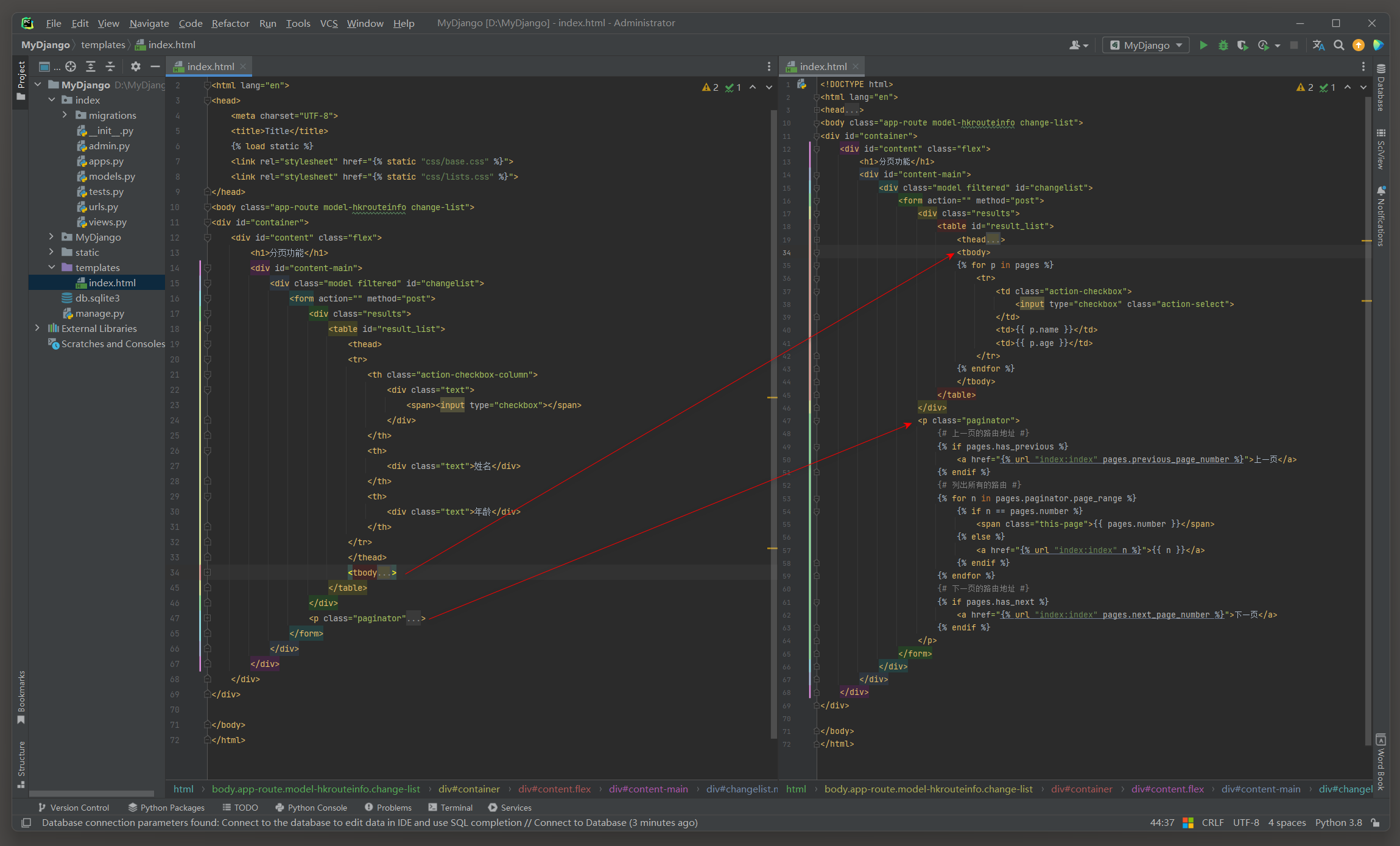
最后在模板文件index.html中实现数据列表和分页功能的展示, 这两个功能是由视图函数index的变量pages实现的, 详细代码如下:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
{% load static %}
<link rel="stylesheet" href="{% static "css/base.css" %}">
<link rel="stylesheet" href="{% static "css/lists.css" %}">
</head>
<body class="app-route model-hkrouteinfo change-list">
<div id="container">
<div id="content" class="flex">
<h1>分页功能</h1>
<div id="content-main">
<div class="model filtered" id="changelist">
<form action="" method="post">
<div class="results">
<table id="result_list">
<thead>
<tr>
<th class="action-checkbox-column">
<div class="text">
<span><input type="checkbox"></span>
</div>
</th>
<th>
<div class="text">姓名</div>
</th>
<th>
<div class="text">年龄</div>
</th>
</tr>
</thead>
<tbody>
{% for p in pages %}
<tr>
<td class="action-checkbox">
<input type="checkbox" class="action-select">
</td>
<td>{{ p.name }}</td>
<td>{{ p.age }}</td>
</tr>
{% endfor %}
</tbody>
</table>
</div>
<p class="paginator">
{# 上一页的路由地址 #}
{% if pages.has_previous %}
<a href="{% url "index:index" pages.previous_page_number %}">上一页</a>
{% endif %}
{# 列出所有的路由 #}
{% for n in pages.paginator.page_range %}
{% if n == pages.number %}
<span class="this-page">{{ pages.number }}</span>
{% else %}
<a href="{% url "index:index" n %}">{{ n }}</a>
{% endif %}
{% endfor %}
{# 下一页的路由地址 #}
{% if pages.has_next %}
<a href="{% url "index:index" pages.next_page_number %}">下一页</a>
{% endif %}
</p>
</form>
</div>
</div>
</div>
</div>
</body>
</html>
综上所述, 整个MyDjango项目的分页功能已开发完成,
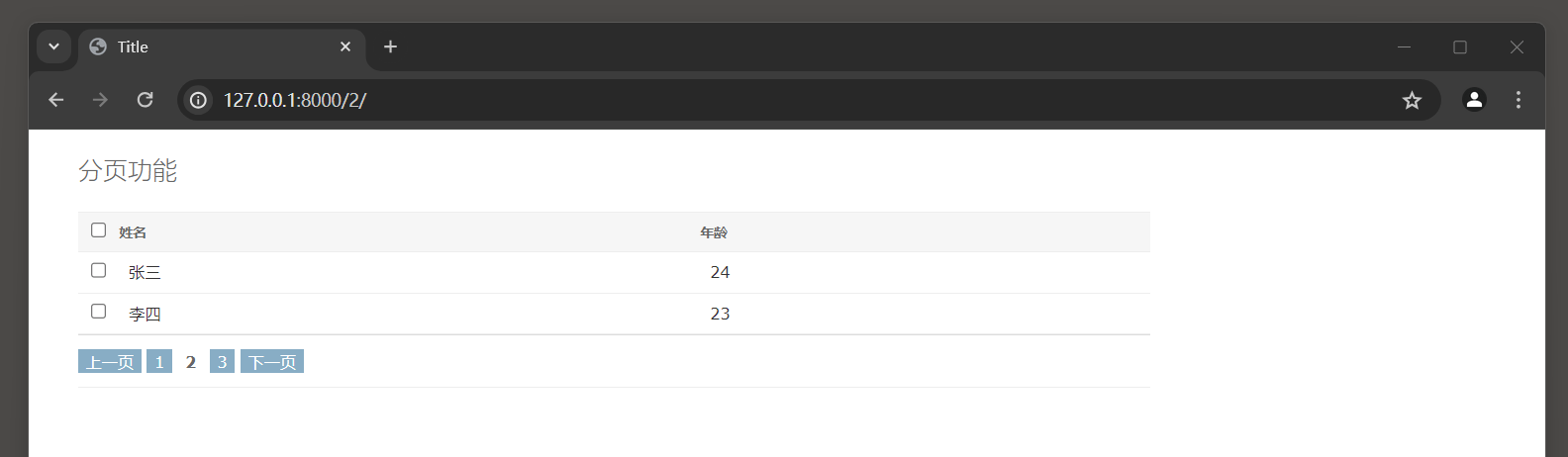
运行MyDjango, 在浏览器上访问: 127.0.0.1:8000/1 即可看到第一页的数据信息,
单击下方的翻页功能可以切换相应的页数和数据信息, 运行结果如图11-27所示.
图11-27 运行结果
我在主程序中加了一行: print(pages.number, page) 想看看pages.number当前页码的值.
查看get_page方法内部源码已经实现了返回有效页面的代码, number的值就是当前页面的页码, 也就是page参数.
运行时查看终端, 发现视图函数执行了两次, 原因如下是获取图标也执行index视图函数.
然而, 获取图标虽然执行了视图函数, 但是他不会改变页面的显示, 只针对网站图标区域.
11.6 国际化和本地化
国际化和本地化是指使用不同语言的用户在访问同一个网页时能够看到符合其自身语言的网页内容.
国际化: 是指在Django的路由, 视图, 模板, 模型和表单里使用内置函数配置翻译功能.
本地化: 是根据国际化的配置内容进行翻译处理.
简单来说, 国际化和本地化是让整个网站的每个网页具有多种语言的切换方式.
(在Django中, 国际化(i18n)和本地化(l10n)是两个重要的概念, 用于支持多语言和多地区的环境.
* 1. 国际化(Internationalization, i18n): 国际化是指使软件产品(如Django项目)能够支持多种语言和文化的过程.
在Django中. 国际化通常涉及以下步骤:
1. 标记可翻译字符串: 在Django的模板, 视图, 模型和表单中, 使用gettext(通常简写为_())
或django.utils.translation模块中的其他函数来标记需要翻译的字符串.
2. 提取可翻译字符串: 使用Django的makemessages命令从源代码中提取这些标记的字符串,
并生成.po(Portable Object)文件. 这些文件包含了待翻译的原始字符串和它们的上下文.
3. 翻译字符串: 翻译人员使用诸如Poedit等工具编辑.po文件, 为每种目标语言提供翻译.
这会产生.mo(Machine Object)文件, 这是Django用于查找翻译的文件.
4. 配置语言和地区: 在Django的设置中, 配置LANGUAGES和LANGUAGE_CODE来指定项目支持的语言和默认语言.
* 2. 本地化(Localization, l10n): 本地化是指根据特定地区或国家的语言和文化习惯来调整国际化后的软件产品的过程.
在Django中, 本地化通常涉及以下方面:
1. 使用翻译: 当Django处理一个请求时, 它会根据用户的语言设置(通常通过HTTP头中的Accept-Language字段或URL中的语言代码)
查找相应的.mo文件, 并使用其中的翻译来替换标记的字符串.
2. 日期, 时间和数字格式: Django允许您为每种语言配置不同的日期, 时间和数字格式.
这包括日期和时间的表示方式, 数字的千位分隔符和货币符号等.
3. 时区支持: Django支持时区感知的日期和时间, 允许您根据用户的时区显示时间.
4. 本地化的模板和表单: 在模板和表单中, 可以使用Django的模板标签和表单字段来自动显示本地化后的内容.
例如, 可以使用{% localize %}模板标签来在模板中启用本地化,
或者使用forms.DateField和forms.TimeField等表单字段来显示和验证日期和时间.
* 3. 总结: 国际化使软件能够支持多种语言, 而本地化则根据特定地区或国家的文化和习惯来调整软件.
在Django中, 国际化涉及标记和提取可翻译字符串以及配置语言和地区,
而本地化则涉及使用翻译, 配置日期, 时间和数字格式以及支持时区等.
通过结合使用国际化和本地化功能, 可以轻松地创建支持多种语言和文化的Django项目.)
11.6.1 环境搭建与配置
Django的国际化和本地化是默认开启的, 如果不需要使用此功能, 那么在配置文件settings.py中设置USE_I18N = False即可,
Django在运行时将执行某些优化, 不再加载国际化和本地化机制.
国际化和本地化需要依赖GNU Gettext工具, 不同的操作系统, GNU Gettext的安装方式有所不同.
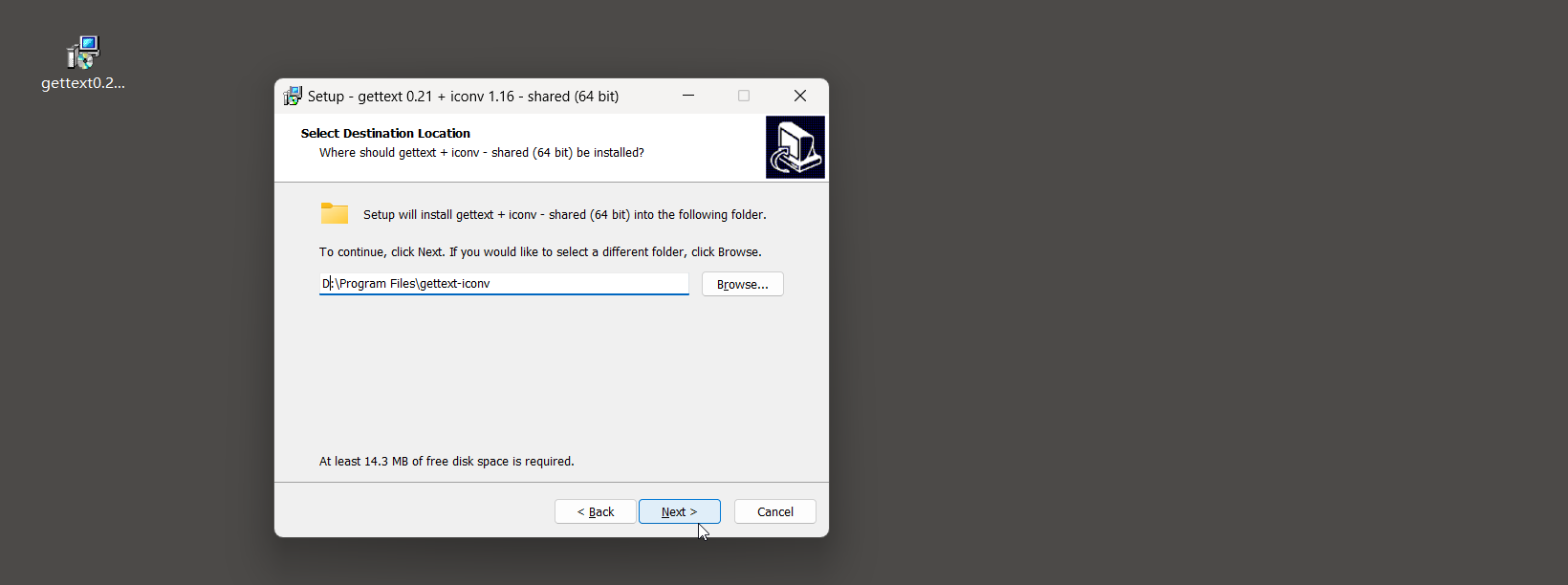
以Windows系统为例, 在浏览器上访问: mlocati.github.io/articles/gettext-iconv-windows.html,
根据计算机的位数下载相应的.exe安装包即可, 如图11-28所示.
图11-28 GNU Gettext安装包
GNU Gettext安装成功后, 接着配置Django的国际化和本地化功能.
以MyDjango为例, 在根目录下创建文件夹language, 然后在配置文件settings.py的MIDDLEWARE中添加中间件LocaleMiddleware,
新增配置属性LOCALE_PATHS和LANGUAGES, 代码如下:
# MyDjango的settings.py
# 中间件
MIDDLEWARE = [
......
'django.contrib.sessions.middleware.SessionMiddleware',
'django.middleware.locale.LocaleMiddleware', # 本地化中间件
'django.middleware.common.CommonMiddleware',
......
]
# 翻译文件路径
LOCALE_PATHS = (
BASE_DIR / 'language',
)
# 可用语言
LANGUAGES = (
('en', 'English'),
('zh', '中文简体'),
)
在上述配置中, 中间件LocaleMiddleware, 新增配置属性LOCALE_PATHS和LANGUAGES的说明如下:
● 中间件LocaleMiddleware使用国际化和本地化功能.
● 新增配置属性LOCALE_PATHS指向MyDjango的language文件夹,
该文件夹用于存储语言文件, 实现路由, 视图, 模板, 模型和表单的数据翻译.
● 新增配置属性LANGUAGES用于定义Django支持翻译的语言, 每种语言的定义格式以元组表示,
如('en', 'English'), 其中en和English可自行命名, 一般默认采用各国语言的缩写.
11.6.2 设置国际化
完成MyDjango的环境搭建与配置后, 我们将在路由, 视图和模板里使用国际化设置.
首先在MyDjango的urls.py中设置路由的国际化, 同一个路由可以根据配置属性LANGUAGES的值来创建不同语言的路由信息, 设置方式如下:
# MyDjango的urls.py
from django.urls import path, include
from django.conf.urls.i18n import i18n_patterns
urlpatterns = i18n_patterns(
path('', include(('index.urls', 'index'), namespace='index')),
)
在Django的URL配置中, i18n_patterns是用于支持国际化i18n的URL模式的工具. 这允许你为应用程序创建多语言版本的URL.
urlpatterns = i18n_patterns(...): 这意味着以下的所有path或url模式都会支持国际化.
当Django使用i18n_patterns时, 它会自动为每一个URL添加语言前缀(例如/en/, /zh/等).
这些前缀基于Django的国际化设置和当前请求的Accept-Language头部来确定(后续说明).
# index的urls.py
from django.urls import path
from .views import *
urlpatterns = [
path('', index, name='index'),
]
路由的国际化设置必须在MyDjango的urls.py里实现, 路由的定义方式不变, 只需在路由urlpatterns中使用函数i18n_patterns即可.
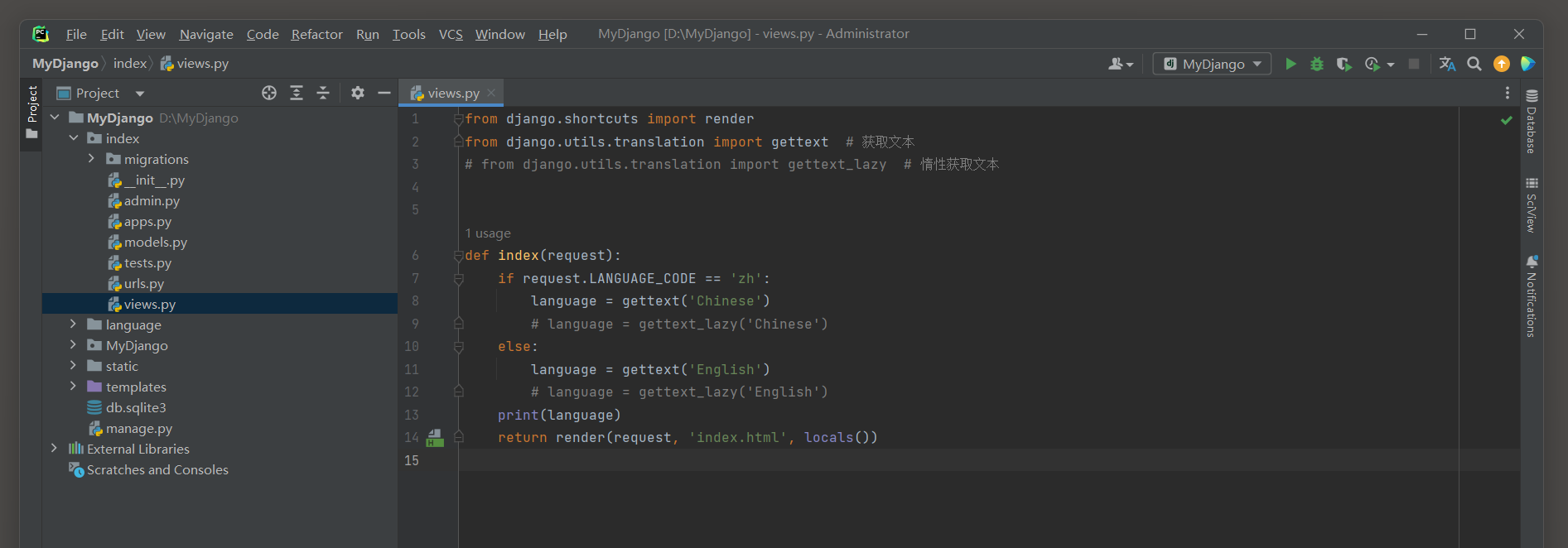
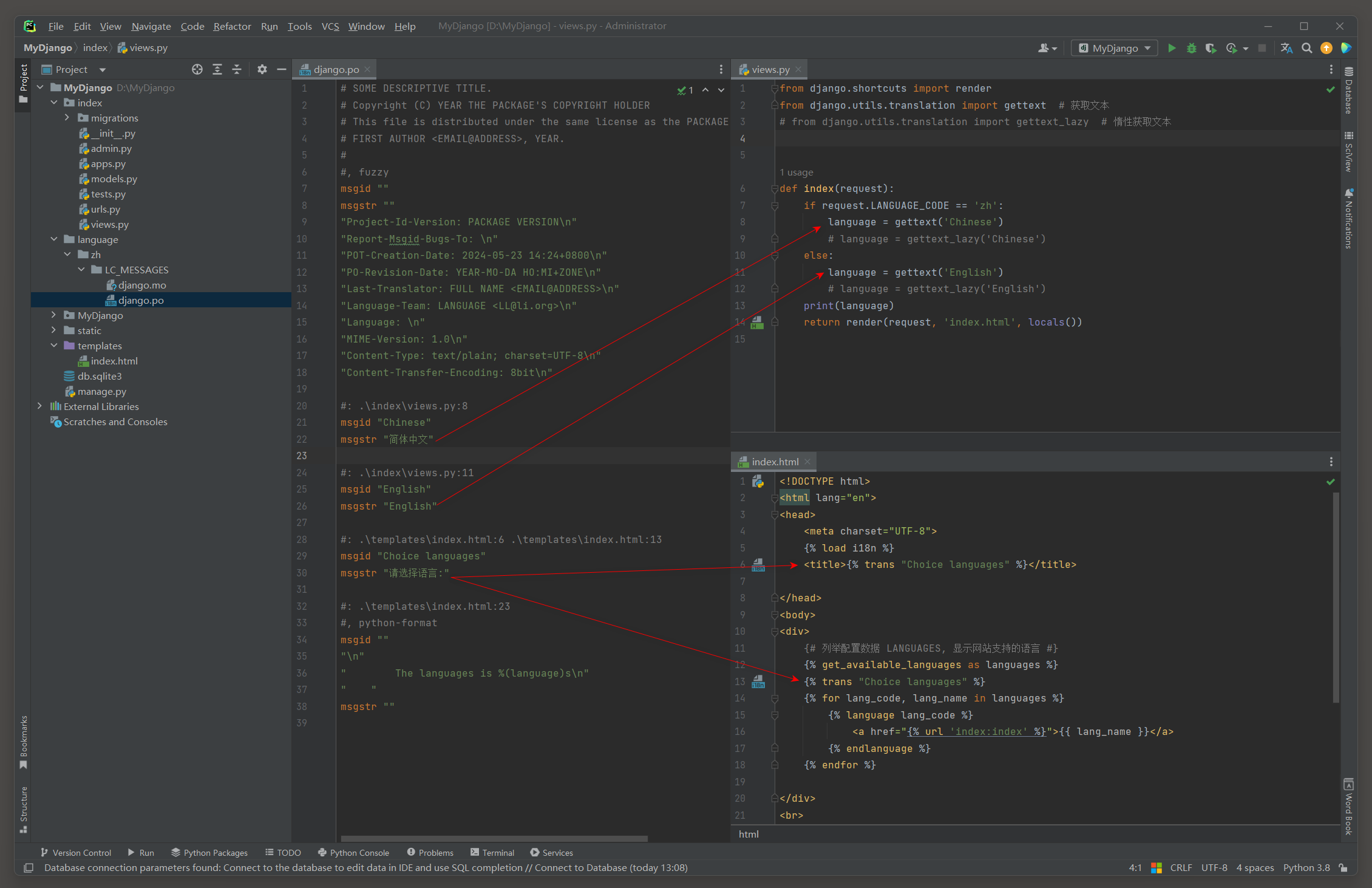
下一步在index的views.py中设置视图函数index的国际化, 代码如下:
# index的views.py
from django.shortcuts import render
from django.utils.translation import gettext # 获取文本
# from django.utils.translation import gettext_lazy # 惰性获取文本
def index(request):
if request.LANGUAGE_CODE == 'zh':
language = gettext('Chinese')
# language = gettext_lazy('Chinese')
else:
language = gettext('English')
# language = gettext_lazy('English')
print(language)
return render(request, 'index.html', locals())
视图函数index根据当前请求的语言类型来设置变量language的值, 说明如下:
(1) 请求对象request的属性LANGUAGE_CODE由中间件LocaleMiddleware生成(后续有说明),
通过判断该属性的值可以得知当前用户选择的语言类型.
(2) 变量language调用内置函数gettext或gettext_lazy设置变量值.
若当前用户选择中文模式, 则变量值为Chinese; 否则为英文类型, 变量值为English.
最后在模板文件index.html中实现数据展示, 数据展示分为中文和英文模式, 当选择某个语言模式后,
浏览器跳转到相应的路由地址并将数据转换成相应的语言模式, 代码如下:
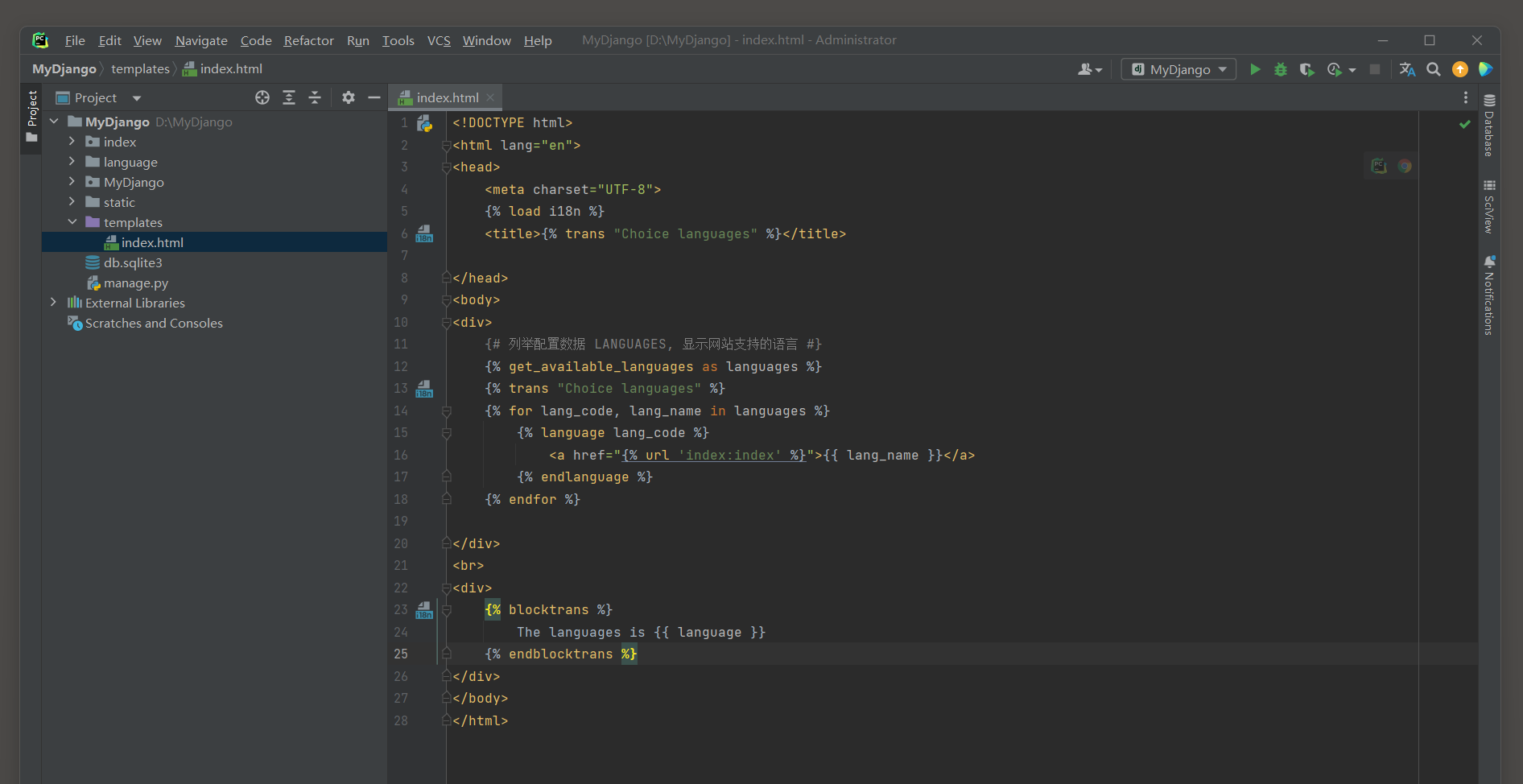
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
{% load i18n %}
<title>{% trans "Choice languages" %}</title>
</head>
<body>
<div>
{# 列举配置数据 LANGUAGES, 显示网站支持的语言 #}
{% get_available_languages as languages %}
{% trans "Choice languages" %}
{% for lang_code, lang_name in languages %}
{% language lang_code %}
<a href="{% url 'index:index' %}">{{ lang_name }}</a>
{% endlanguage %}
{% endfor %}
</div>
<br>
<div>
{% blocktrans %}
The languages is {{ language }}
{% endblocktrans %}
</div>
</body>
</html>
模板文件index.html导入Django内置文件i18n.py, 该文件用于定义国际化的模板标签.
上述代码使用内置标签trans, get_available_languages, language和blocktrans, 每个标签的说明如下:
● trans: 使标签里的数据可支持语言转换, 标签里的数据可为模板上下文或字符串, 但两者不能组合使用,
比如{% trans "Hello" value %}, "Hello"为字符串, value为模板上下文, 两者混合使用将提示TemplateSyntaxError异常.
● get_available_languages: 获取配置属性LANGUAGES的值.
● language: 在模板里生成语言选择的功能.
● blocktrans: 与标签trans的功能相同, 但支持模板上下文和字符串的组合使用.
除了上述的国际化函数与标签之外, Django还定义了许多国际化函数与标签, 本书不再详细讲述, 读者可在官方文档中自行查阅.
11.6.3 设置本地化
完成路由, 视图和模板的国际化设置后, 下一步执行本地化操作.
我们以管理员身份运行命令提示符窗口, 将命令提示符窗口的路径切换到MyDjango, 然后执行makemessages指令创建语言文件,
该指令设有两个参数: 第一个参数为-l (字母L的小写), 这是固定参数; 第二个参数为zh, 这来自配置属性LANGUAGES, 如图11-29所示.
C:\Users\blue\Desktop> D:
D:\>cd MyDjango
D:\MyDjango> python manage.py makemessages -l zh
processing locale zh
D:\MyDjango>
图11-29 执行makemessages指令创建语言文件
执行makemessages指令必须以管理员身份运行, 如果在PyCharm的Terminal中执行该指令,
Django将提示CommandError异常信息, 如图11-30所示.
(我的电脑上权限不同, 创建成功了...)
图11-30 CommandError异常信息
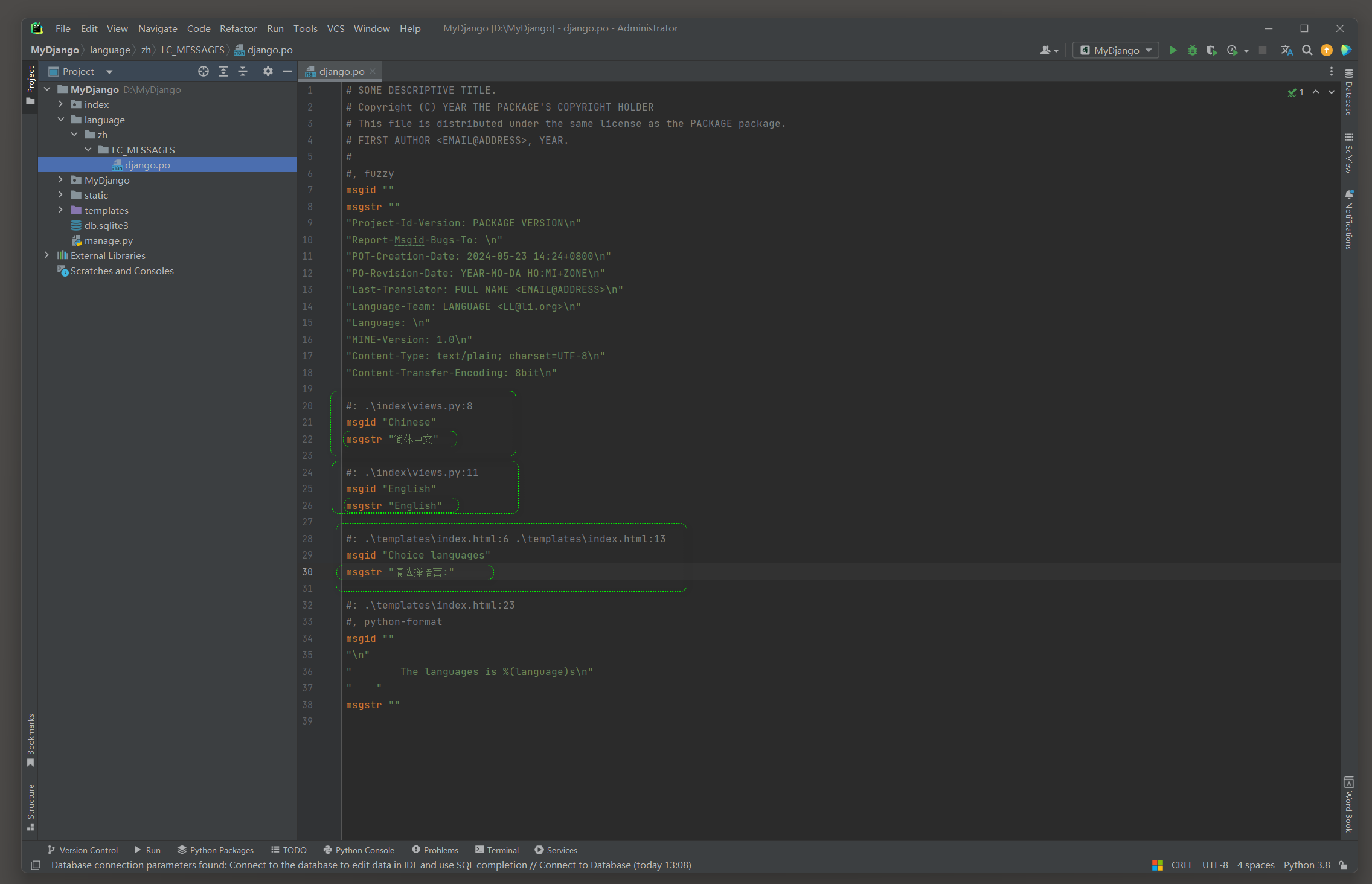
makemessages指令执行完成后, 打开language文件夹可以看到新建的文件django.po,
该文件为路由, 视图, 模板, 模型或表单的国际化设置提供翻译内容.
打开django.po文件, 我们需要为视图函数index和模板文件index.html的国际化设置编写翻译内容, 如图11-31所示.
图11-31 编写翻译内容
从图11-31看到, 只要在视图, 模板, 模型或表单里使用了国际化函数, 我们都可以在django.po文件中看到相关信息.
在django.po文件中, 一个完整的信息包含3行数据, 以msgid "Chinese"为例, 说明如下:
● #: .\index\views.py:7 代表国际化设置的位置信息.
● msgid"Chinese"代表国际化设置的名称, 标记和区分每个国际化设置, 比如视图函数index设置的gettext('Chinese').
● msgstr代表国际化设置的翻译内容, 默认值为空, 需要翻译人员逐条填写.
(#: .\index\views.py:7 是一个注释, 它指示原始字符串"Chinese"在文件index\views.py的第7行中.
msgid "Chinese" 是原始字符串, 即软件中的英文标签或文本.
msgstr "简体中文" 是对msgid的翻译, 即"Chinese"被翻译为"简体中文".)
最后以管理员身份运行命令提示符窗口, 在命令提示符窗口中输入并执行compilemessages指令,
将django.po文件编译成语言文件django.mo, 如图11-32所示.
C:\Users\blue\Desktop>D:
D:\>cd MyDjango
D:\MyDjango>python manage.py compilemessages
processing file django.po in D:\MyDjango\language\zh\LC_MESSAGES
D:\MyDjango>
图11-32 执行compilemessages编译语言文件
至此, 我们已完成Django的国际化和本地化的功能开发.
运行MyDjango, 在浏览器上访问: 127.0.0.1:8000 就会自动跳转到127.0.0.1:8000/zh/, 默认返回中文类型的网页信息,
因为Django根据用户的语言偏好(浏览器默认语言)来显示符合其自身语言的网页内容, 如图11-33所示.
图11-33 运行结果
首选语言为中文, 则访问: 127.0.0.1:8000 就会自动跳转到127.0.0.1:8000/zh/
首选语言为英文, 则访问: 127.0.0.1:8000 就会自动跳转到127.0.0.1:8000/en/
当单击'English'链接的时候, 浏览器的网页地址将切换为127.0.0.1:8000/en/, 网页内容将以英文模式展现, 如图11-34所示.
图11-34 运行结果
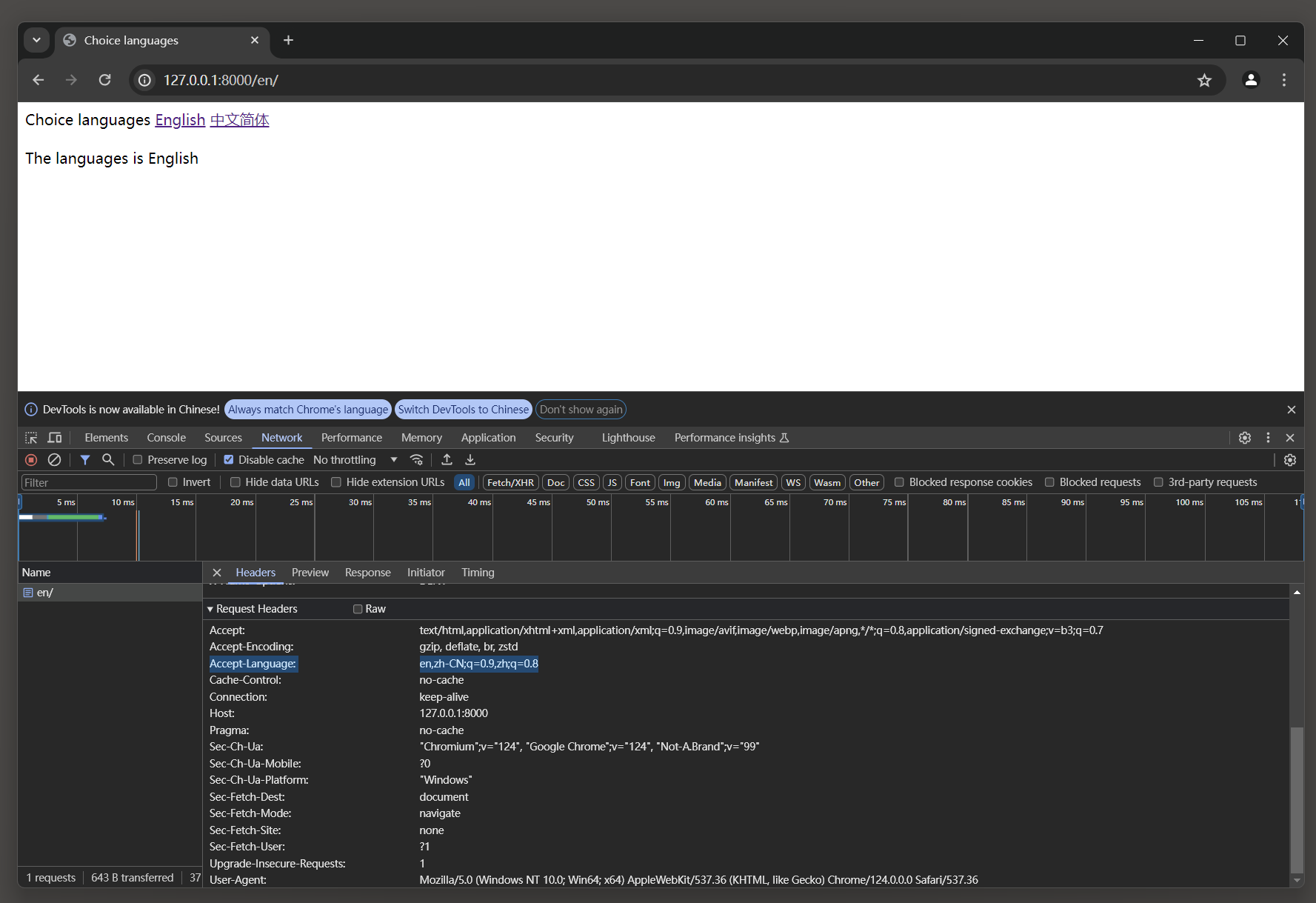
Accept-Language是一个HTTP请求头字段, 用于告诉服务器客户端(如浏览器)能够理解和偏好哪些自然语言, 以及这些语言之间的相对优先级.
示例中: Accept-Language: en,zh-CN;q=0.9,zh;q=0.8
这个字段表示: 客户端首选(最想要)的语言是英语(en).
如果服务器不能提供英语的响应, 那么它应该考虑使用简体中文(zh-CN), 但优先级稍微低一些(权重为 0.9).
如果服务器连简体中文都不能提供, 那么它可以考虑使用更一般的中文(zh), 但优先级更低(权重为 0.8).
这里的 q 参数代表'质量因子'(quality factor), 用于指定每个语言标签的相对优先级.
默认的质量因子是1, 但在这里没有为英语明确指定, 因此它默认为1. 质量因子的范围是0到1, 其中1是最高优先级, 0是不接受.
注意, zh-CN 和 zh 是两个不同的语言标签.
zh-CN: 代表中国大陆使用的简体中文, 而zh是一个更通用的标签, 可以代表任何形式的中文(如简体中文, 繁体中文等).
因此, 虽然它们都代表中文, 但服务器可能会根据这两个标签返回不同的内容.
在Django框架中, request.LANGUAGE_CODE通常用于表示当前请求的语言代码(例如:'en', 'zh-hans' 等).
这个值通常是通过几个不同的机制来确定的:
* 1. 浏览器语言设置: 当用户访问一个网站时, 他们的浏览器通常会发送一个名为 Accept-Language 的HTTP头,
其中包含了用户偏好的语言列表.
Django的LocaleMiddleware(或者类似的中间件)会解析这个头, 并尝试确定一个合适的语言代码.
* 2. URL前缀: 如果你使用了Django的国际化(i18n)URL模式, 那么URL本身可能包含一个语言代码前缀(例如 /en/path/to/view/).
这个前缀会被解析并用于设置request.LANGUAGE_CODE.
* 3. 用户设置: 在某些情况下, 用户可能能够在网站内选择他们的语言偏好, 并且这个偏好可能会被存储在用户的会话(session)或数据库中. 当用户再次访问网站时, 这个偏好会被用来设置request.LANGUAGE_CODE.
* 4. 默认设置: 如果以上所有方法都无法确定一个语言代码, Django将回退到在settings.py文件中设置的默认语言(LANGUAGE_CODE).
request.LANGUAGE_CODE的值被用于多个方面, 包括:
* 1. 翻译字符串(使用gettext, ngettext等函数).
* 2. 格式化日期, 时间, 数字等(使用Django的模板标签和过滤器).
* 3. 确定应该使用哪个语言版本的静态文件(如果你使用了Django的静态文件国际化).
11.7 单元测试
当我们完成网站的功能开发后, 通常需要运行Django项目, 在浏览器上单击测试网页功能是否正常.
但这种测试方式比较麻烦, 因为每次更改或新增网站功能, 都可能会影响已有功能的正常使用, 这样又要重新测试网站功能.
Django设有单元测试功能, 我们可以对开发的每一个功能进行单元测试, 只需要运行操作命令就可以测试网站功能是否正常.
单元测试还可以驱动功能开发, 比如我们知道需要实现的功能, 但并不知道代码如何编写,
这时就可以利用测试驱动开发(Test Driven Development).
首先完成单元测试的代码编写, 然后编写网站的功能代码, 直到功能代码不再报错, 这样就完成网站功能的开发了.
11.7.1 定义测试类
Django的单元测试在项目应用的tests.py文件里定义, 每个单元测试以类的形式表示, 每个类方法代表一个测试用例.
以MyDjango为例, 打开项目应用index的tests.py发现, 该文件导入Django的TestCase类, 用于实现单元测试的定义.
打开并查看TestCase类的源码文件, 如图11-35所示.
图11-35 TestCase类的源码文件
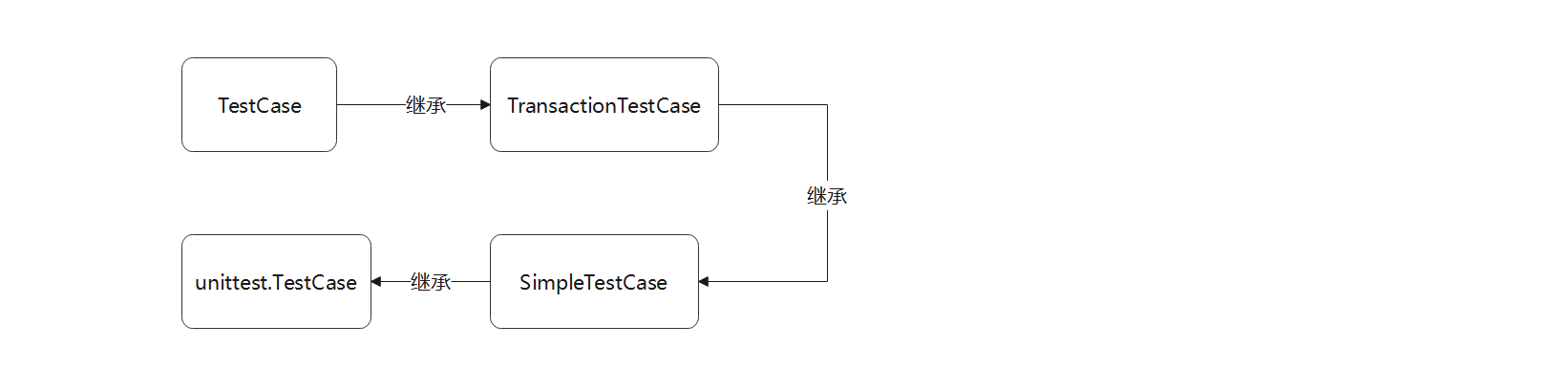
从源码分析TestCase类得知, 它继承父类TransactionTestCase,
而父类是通过递进方式继承SimpleTestCase和unittest.TestCase的, 继承关系如图11-36所示.
unittest.TestCase是Python内置的单元测试框架, 也就是说, Django使用Python的标准库unittest实现单元测试的功能开发.
对于大部分读者来说, 可能对unittest框架较为陌生, 因此我们通过简单的例子讲述如何开发Django的单元测试功能.
图11-36 TestCase类的继承关系
首先实现网站的功能开发, 我们在项目应用index中定义两条路由信息, 分别实现网站首页和API接口.
在MyDjango的urls.py和index的urls.py中定义路由信息, 代码如下:
# MyDjango的urls.py
from django.urls import path, include
urlpatterns = [
path('', include(('index.urls', 'index'), namespace='index')),
]
# index的urls.py
from django.urls import path
from .views import *
urlpatterns = [
path('', index, name='index'),
path('api/', index_api, name='index_api'),
]
路由index和index_api对应视图函数index和index_api, 因此在index的views.py中分别定义视图函数index和index_api, 代码如下:
# index的views.py
from django.http import JsonResponse
from django.shortcuts import render
from .models import PersonInfo
def index(request):
title = '首页'
pk = request.GET.get('id', 1)
person = PersonInfo.objects.get(id=pk)
return render(request, 'index.html', locals())
def index_api(request):
pk = request.GET.get('id', 1)
person = PersonInfo.objects.get(id=pk)
result = {
'name': person.name,
'age': person.age
}
return JsonResponse(result)
视图函数index和index_api使用模型PersonInfo查询数据, 并且视图函数index调用了模板文件index.html,
因此在index的models.py中定义模型PersonInfo, 在模板文件index.html中编写网页的HTML代码, 代码如下:
# index的models.py
from django.db import models
class PersonInfo(models.Model):
id = models.AutoField(primary_key=True)
name = models.CharField(max_length=20)
age = models.IntegerField()
<!-- templates的index.html -->
<!DOCTYPE html>
<html lang="zh-hans">
<head>
<meta charset="UTF-8">
<title>{{ title }}</title>
</head>
<body>
<div>姓名:{{ person.name }}</div>
<div>年龄:{{ person.age }}</div>
</body>
</html>
由于index的models.py定义了模型PersonInfo, 因此Django还需要执行数据迁移,
在MyDjango的数据库文件db.sqlite3中创建数据表, 并且数据表index_personinfo无须添加任何数据.
# 数据迁移:
PS D:\MyDjango> python manage.py makemigrations
No changes detected
PS D:\MyDjango> python manage.py migrate
至此, 已完成MyDjango的功能开发. 下一步根据已有的功能编写单元测试.
我们定义的单元测试主要测试视图的业务逻辑和模型的读写操作, 根据MyDjango的视图函数,
模型PersonInfo和内置模型User分别定义测试类PersonInfoTest和UserTest, 代码如下:
# index的test.py
from django.test import TestCase
from .models import PersonInfo
from django.contrib.auth.models import User
from django.test import Client
class PersonInfoTest(TestCase):
# 添加数据
def setUp(self):
PersonInfo.objects.create(name='张三', age=18)
PersonInfo.objects.create(name='李四', age=19)
# 编写测试用例
def test_personInfo_age(self):
# 编写用例
name1 = PersonInfo.objects.get(name='张三')
name2 = PersonInfo.objects.get(name='李四')
# 判断测试用例的执行结果
self.assertEqual(name1.age, 18) # 断言age的值是18
self.assertEqual(name2.age, 19) # 断言age的值是18
# 编写测试用例
def test_api(self):
# 编写用例
c = Client()
response = c.get('/api/')
# 判断测试用例的执行结果
self.assertIsInstance(response.json(), dict)
# 编写测试用例
def test_html(self):
# 编写用例
c = Client()
response = c.get('/?id=2') # 发送一个get请求并返回一个响应对象
# context参数是locals()函数的返回传递的
name = response.context['person'].name
# 判断测试用例的执行结果
self.assertEqual(name, '李四')
self.assertTemplateUsed(response, 'index.html')
class UserTest(TestCase):
# 添加数据
@classmethod
def setUpTestData(cls):
User.objects.create_user(username='test', password='test', email='1@1.com')
# 编写测试用例
def test_user(self):
# 编写用例
r = User.objects.get(username='test')
# 判断测试用例的执行结果
self.assertEquals(r.email, '123@456.com')
self.assertTrue(r.password)
# 编写测试用例
def test_login(self):
# 编写用例
c = Client()
r = c.login(username='test', password='test')
# 判断测试用例的执行结果
self.assertTrue(r)
测试类PersonInfoTest主要测试模型PersonInfo的数据读写, 视图函数index和indexApi的业务逻辑,
它一共定义了4个类方法, 每个类方法说明如下:
(1) setup(): 重写父类TestCase的方法, 该方法在运行测试类的时候, 为测试类提供数据信息.
因为单元测试在运行过程中会创建一个虚拟的数据库, 所以模型的数据操作都在虚拟数据库完成.
通过重写setup()可以为虚拟数据库添加数据, 为测试用例提供数据支持.
(2) test_personInfo_age(): 自定义测试用例, 函数名必须以test开头, 否则单元测试无法识别该方法是否为测试用例.
该方法用于查询模型PersonInfo的数据信息, 然后将查询结果与我们预测的结果进行对比,
比如self.assertEqual(name1.age, 18),其中'self.assertEqual'是父类TestCase内置的方法, 这是将查询结果与预测结果进行对比; 'name1.age'是模型PersonInfo的查询结果; '18'是我们预测的结果.
(3) test_api(): 自定义测试用例, 主要实现视图函数index_api的测试.
首先使用Client实例化生成HTTP请求对象, 再由HTTP请求对象向路由index_api发送GET请求,
并使用内置方法assertIsInstance判断响应内容是否为字典格式.
(4) test_html(): 自定义测试用例, 主要实现视图函数index的测试.
首先由HTTP请求对象向路由index发送GET请求, 从响应内容获取模板上下文person的属性name,
使用内置方法assertEqual判断name的值是否为'李四',
使用内置方法assertTemplateUsed判断响应内容是否由模板文件index.html生成.
测试UserTest主要测试内置模型User的功能逻辑, 一共定义了3个类方法, 每个类方法的说明如下:
(1) setUpTestData(): 重写父类TestCase的方法, 该方法与测试类PersonInfoTest的setup()的功能一致.
(2) test_user(): 自定义测试用例, 在模型User中查询test的用户信息,
使用内置方法assertEquals和assertTrue分别验证用户的邮箱和密码是否与预测结果一致.
(3) test_login(): 自定义测试用例, 首先使用Client实例化生成HTTP请求对象,
再调用内置方法login实现用户登录, 最后由assertTrue验证用户登录是否成功.
从测试类PersonInfoTest和UserTest的定义过程得知, 通过重写内置方法setup()或setUpTestData()为测试用例提供数据支持.
测试用例是将业务逻辑执行实体化操作, 即通过输入具体的数据得出运行结果, 然后将运行结果与预测结果进行对比,
从而验证网站功能是否符合开发需求.
运行结果与预测结果的对比是由测试类TestCase定义的方法实现的, 分析TestCase的继承关系得知,
TestCase及其父类SimpleTestCase定义了多种的对比方法, 分别说明如下:
● assertRedirects(): 由SimpleTestCase定义, 判断当前网页内容是否由重定向方式生成.
比如路由index重定向路由user, 因此路由user的网页内容是由路由index重定向生成的.
参数response为网页内容, 即路由user的网页内容; 参数expected_url是重定向路由地址, 即路由index.
● assertURLEqual(): 由SimpleTestCase定义, 判断两条路由地址是否相同, 参数url1和url2代表两条不同的路由地址.
● assertContains():由SimpleTestCase定义, 判断网页内容是否存在某些数据信息, 若存在, 则返回True, 否则返回False.
参数response为网页内容; 参数text为数据信息; 参数count代表数据信息出现的次数, 默认值为None, 代表数据至少出现一次.
● assertNotContains(): 由SimpleTestCase定义, 与assertContains()的判断结果相反, 若不存在, 则返回True, 否则返回False,
该函数不存在参数count.
● assertFormError: 由SimpleTestCase定义, 判断网页表单是否存在异常信息.
参数response为网页内容; 参数form为表单对象; 参数field为表单字段; 参数errors为表单的错误信息.
● assertFormError(): 由SimpleTestCase定义, 判断多个网页表单(表单集)是否存在异常信息.
参数response为网页内容; 参数formset代表多个表单的集合对象; 参数form_index代表表单集合的索引;
参数field为表单字段; 参数errors为表单的错误信息.
● assertTemplateUsed(): 由SimpleTestCase定义, 判断当前网页是否使用某个模板文件生成.
参数response为网页内容; 参数template_name为模板文件的名称.
● assertTemplateNotUsed(): 由SimpleTestCase定义, 与assertTemplateUsed()的判断结果相反.
● assertHTMLEqual(): 由SimpleTestCase定义, 判断两个网页内容是否相同. 参数html1和html1代表两个不同的网页内容.
● assertHTMLNotEqual(): 由SimpleTestCase定义, 与assertHTMLEqual()的判断结果相反.
● assertInHTML(): 由SimpleTestCase定义, 判断网页内容是否存在某个HTML元素.
参数needle代表HTML控件元素; 参数haystack代表网页内容; 参数count代表参数needle出现的次数, 默认值为None, 代表至少出现一次.
● assertJSONEqual(): 由SimpleTestCase定义, 判断两份JSON格式的数据是否相同.
参数raw和expected_data代表两份不同的JSON数据.
● assertJSONNotEqual(): 由SimpleTestCase定义, 与assertJSONNotEqual()的判断结果相反.
● assertXMLEqual(): 由SimpleTestCase定义, 判断两份XML格式的数据是否相同.
参数xml1和xml2代表两份不同的的XML数据.
● assertXMLNotEqual(): 由SimpleTestCase定义, 与assertXMLEqual()的判断结果相反.
● assertFalse(): 由unittest.TestCase定义, 判断对象的真假性是否为False, 参数expr为数据对象.
● assertTrue(): 由unittest.TestCase定义, 判断对象的真假性是否为True, 参数expr为数据对象.
● assertEqual(): 由unittest.TestCase定义, 判断两个对象是否相同,
参数first和second为两个不同的对象, 对象类型可为元组, 列表, 字典等.
● assertNotEqual(): 由unittest.TestCase定义, 与assertEqual()的判断结果相反.
● assertAlmostEqual(): 由unittest.TestCase定义, 判断两个浮点类型的数值在特定的差异范围内是否相等.
参数first和second为两个不同的浮点数; 参数places为小数点位数; 参数delta为两个数值之间的差异值.
● assertNotAlmostEqual(): 由unittest.TestCase定义, 与assertAlmostEqual()的判断结果相反.
● assertSequenceEqual(): 由unittest.TestCase定义, 判断两个列表或元组是否相等, 参数seq1和seq2为两个不同的列表或元组.
● assertListEqual(): 由unittest.TestCase定义, 判断两个列表是否相等, 参数list1和list2为两个不同的的列表.
● assertTupleEqual(): 由unittest.TestCase定义, 判断两个元组是否相等, 参数tuple1和tuple2为两个不同的元组.
● assertSetEqual(): 由unittest.TestCase定义, 判断两个集合是否相等, 参数set1和set1为两个不同的集合.
● assertIn(): 由unittest.TestCase定义, 判断某个数据是否在某个对象里(Python的IN语法).
参数member为某个数据; 参数container为某个对象.
● assertNotIn(): 由unittest.TestCase定义, 与assertIn()的判断结果相反.
● assertIs(): 由unittest.TestCase定义, 判断两个数据是否来自同一个对象(Python的IS语法).
参数expr1和expr2为两个不同的数据.
● assertIsNot(): 由unittest.TestCase定义, 与assertIs()的判断结果相反.
● assertDictEqual(): 由unittest.TestCase定义, 判断两个字典的数据是否相同, 参数d1和d2代表两个不同的字典对象.
● assertDictContainsSubset(): 由unittest.TestCase定义, 判断某个字典是否为另一个字典的子集.
参数dictionary代表某个字典; 参数subset代表某个字典的子集.
● assertCountEqual(): 由unittest.TestCase定义, 判断两个序列的元素出现的次数是否相同, 参数first和second为两个不同的序列.
● assertMultiLineEqual(): 由unittest.TestCase定义, 判断两个多行数的字符串是否相同,
参数first和second为两个不同的多行字符串.
● assertLess(): 由unittest.TestCase定义, 参数a和b代表两个不同的对象, 判断a是否小于b,
如果a≥b, 就会引发failureException异常.
● assertLessEqual(): 由unittest.TestCase定义, 与assertLess()类似, 判断a是否小于或等于b.
● assertGreater(): 由unittest.TestCase定义, 参数a和b代表两个不同的对象, 判断a是否大于b,
如果a≤b, 就会引发failureException异常.
● assertGreaterEqual(): 由unittest.TestCase定义, 与assertGreater()类似, 判断a是否大于或等于b.
● assertIsNone(): 由unittest.TestCase定义, 判断某个对象是否为None.
● assertIsNotNone(): 由unittest.TestCase定义, 与assertIsNone()的判断结果相反.
● assertIsInstance(): 由unittest.TestCase定义, 判断某个对象是否为某个对象类型.
参数obj代表某个对象; 参数cls代表某个对象类型.
● assertNotIsInstance(): 由unittest.TestCase定义, 与assertIsInstance()的判断结果相反.
上述例子只简单测试了视图的业务逻辑和模型的数据操作, 而Django的单元测试还提供了很多测试方法,
本书不再详细讲述, 有兴趣的读者可以自行查阅官方文档.
11.7.2 运行测试用例
我们在11.7.1小节里已完成模型PersonInfo, 模型User, 视图函数index和indexApi的单元测试开发,
下一步执行测试类PersonInfoTest和UserTest的测试用例, 检验网站功能是否符合开发需求.
Django的测试类是由内置test指令执行的, test指令设有多种方式执行测试类,
比如执行整个项目的测试类, 某个项目应用的所有测试类, 某个项目应用的某个测试类.
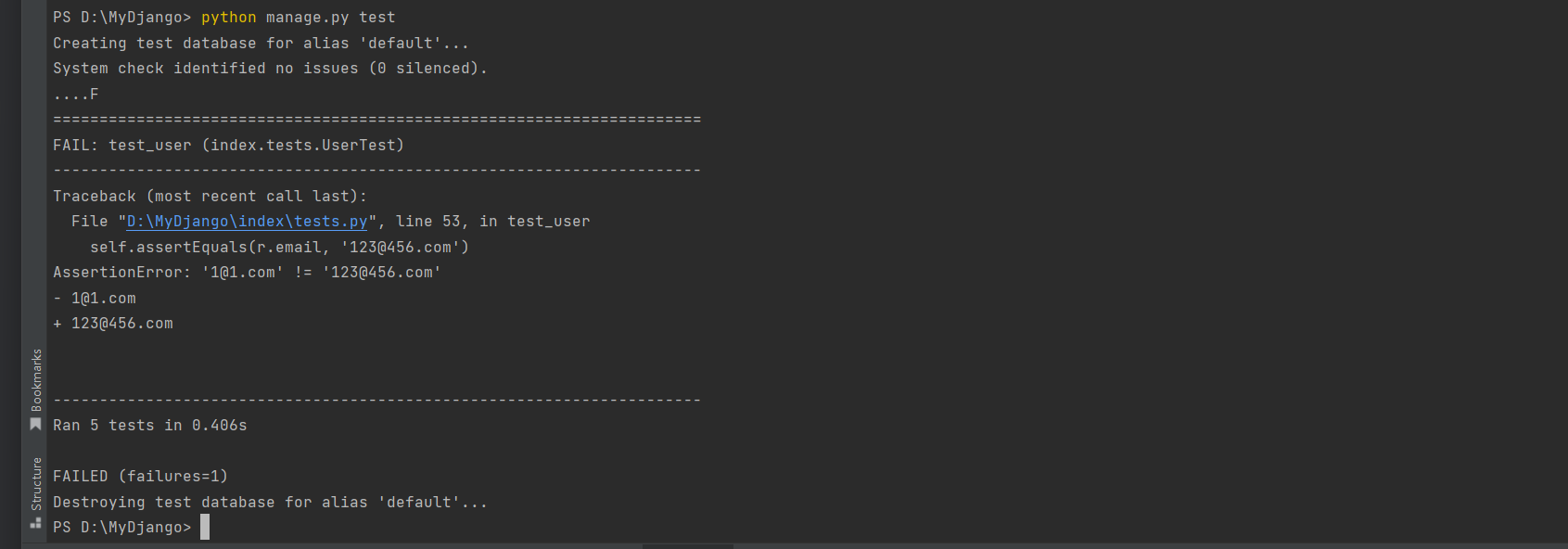
在PyCharm的Terminal中输入test指令, 以执行整个项目的测试类为例, 测试结果如下:
PS D:\MyDjango> python manage.py test
Creating test database for alias 'default'... # 正在为别名'default'创建测试数据库...
System check identified no issues (0 silenced). # 系统检查未发现任何问题(0已静音).
...F
======================================================================
FAIL: test_user (index.tests.UserTest) # 失败
----------------------------------------------------------------------
Traceback (most recent call last):
File "D:\MyDjango\index\tests.py", line 53, in test_user
self.assertEquals(r.email, '123@456.com')
AssertionError: '1@1.com' != '123@456.com' # 断言错误: '1@1.com' 不等于'123@456.com'
- 1@1.com # 正确邮箱
+ 123@456.com # 错误邮箱
----------------------------------------------------------------------
Ran 5 tests in 0.406s # 在0.406秒内进行了5次测试
FAILED (failures=2) # 不合格(失败=2)
Destroying test database for alias 'default'... # 正在销毁别名'default'的测试数据库...
PS D:\MyDjango>
从test指令的运行结果看到, 整个运行过程分为4个步骤完成, 每个步骤的说明如下:
(1) "Creating test database for alias 'default'"用于创建虚拟数据库, 为测试用例提供数据支持.
(2) 执行测试类的测试用例, 如果某个测试类的测试用例执行失败, Django就会对失败原因进行跟踪说明.
例如上述的"AssertionError: '1@1.com' != '123@456.com'",
这是说明测试类UserTest的测试用例test_user的运行结果与预测结果不相符.
(3) 测试用例执行完成后, Django将对执行情况进行汇总.
例如"Ran 5 tests in 0.464s"代表5个测试用例运行消耗0.406秒, "FAILED (failures=1)"代表测试用例运行失败的数量.
(4) 执行"Destroying test database for alias 'default'", 这是销毁虚拟数据库, 释放计算机的内存资源.
如果想要执行某个测试类或者某个测试类的测试用例, 那么可以在PyCharm的Terminal中输入带参数的test指令, 具体如下:
# 执行项目应用index的所有测试类
python manage.py test index
# 执行项目应用index的tests.py定义的测试类
# 由于测试类没有硬性规定在tests.py中定义
# 因此Django允许在其他.py文件中定义测试类
python manage.py test index.tests
# 执行项目应用index的测试类PersonInfoTest
python manage.py test index.tests.PersonInfoTest
# 执行项目应用index的测试类PersonInfoTest的测试用例test_api
python manage.py test index.tests.PersonInfoTest.test_api
# 使用正则表达式查找整个项目带有tests开头的.py文件
# 运行整个项目带有tests开头的.py文件所定义的测试类
python manage.py test --pattern="tests*.py"
11.8 自定义中间件
我们在2.5节已讲述过中间件的概念和运行原理, 中间件是一个处理请求和响应的钩子框架,
它是一个轻量, 低级别的插件系统, 用于在全局范围内改变Django的输入和输出.
开发中间件不仅能满足复杂的开发需求, 而且能减少视图函数或视图类的代码量,
比如编写Cookie内容实现反爬虫机制, 微信公众号开发商城等.
因此, 本节将深入了解中间件的定义过程, 通过开发中间件实现Cookie的反爬虫机制.
11.8.1 中间件的定义过程
中间件在settings.py的配置属性MIDDLEWARE中进行设置, 在创建项目时, Django已默认配置了7个中间件, 每个中间件的说明如下:
● SecurityMiddleware: 内置的安全机制, 保护用户与网站的通信安全.
● SessionMiddleware: 会话Session功能.
● CommonMiddleware: 处理请求信息, 规范化请求内容.
● CsrfViewMiddleware: 开启CSRF防护功能.
● AuthenticationMiddleware: 开启内置的用户认证系统.
● MessageMiddleware: 开启内置的信息提示功能.
● XFrameOptionsMiddleware: 防止恶意程序点击劫持.
为了深入了解中间件的定义过程, 我们在PyCharm里打开并查看某个中间件的源码文件,
分析中间件的定义过程, 以中间件SessionMiddleware为例, 其源码文件如图11-37所示.
图11-37 SessionMiddleware的源码文件
中间件SessionMiddleware继承父类MiddlewareMixin, 父类MiddlewareMixin只定义函数__init__和__call__,
而中间件SessionMiddleware除了重写父类的__init__之外, 还定义了钩子函数process_request和process_response.
一个完整的中间件设有5个钩子函数, Django将用户请求到网站响应的过程进行阶段划分,
每个阶段对应执行某个钩子函数, 每个钩子函数的运行说明如下:
●__init__():初始化函数,运行Django将自动执行该函数。
● process_request(): 完成请求对象的创建, 但用户访问的网址尚未与网站的路由地址匹配.
● process_view(): 完成用户访问的网址与路由地址的匹配, 但尚未执行视图函数.
● process_exception(): 在执行视图函数的期间发生异常, 比如代码异常, 主动抛出404异常等.
● process_response(): 完成视图函数的执行, 但尚未将响应内容返回浏览器.
每个钩子函数都有固定的执行顺序, 我们将通过简单的例子来说明钩子函数的执行过程.
以MyDjango为例, 在MyDjango文件夹中创建myMiddleware.py文件, 该文件用于定义中间件.
在定义中间件之前, 首先实现网站功能, 分别在MyDjango的urls.py, index的urls.py,
index的views.py和templates的index.html中编写以下代码:
# MyDjango的urls.py
from django.urls import path, include
urlpatterns = [
path('', include(('index.urls', 'index'), namespace='index')),
]
# index的urls.py
from django.urls import path
from .views import *
urlpatterns = [
path('', index, name='index'),
]
# index的views.py
from django.shortcuts import render
from django.shortcuts import Http404
def index(request):
if request.GET.get('id', ''):
raise Http404('404')
return render(request, 'index.html', locals())
<!-- template的index.html -->
<!DOCTYPE html>
<html lang="zh-hans">
<head>
<meta charset="UTF-8">
<title>首页</title>
</head>
<body>
<div>Hello Django!</div>
</body>
</html>
视图函数index设置了主动抛出404异常, 这是验证钩子函数process_exception.
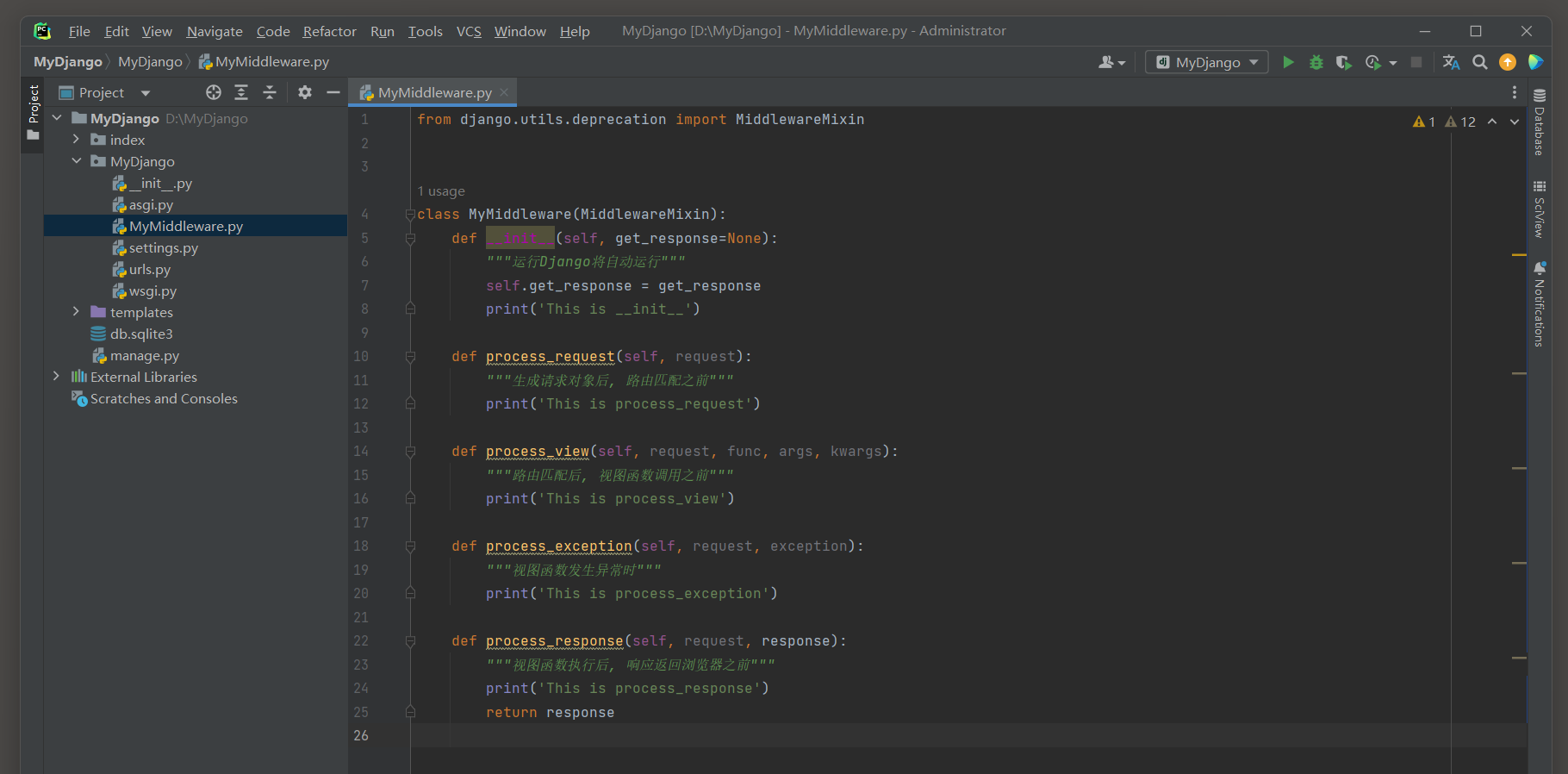
下一步在MyDjango的myMiddleware.py中定义中间件MyMiddleware, 代码如下:
# MyDjango的MyMiddleware
from django.utils.deprecation import MiddlewareMixin
class MyMiddleware(MiddlewareMixin):
def __init__(self, get_response=None):
"""运行Django将自动运行"""
self.get_response = get_response
print('This is __init__')
def process_request(self, request):
"""生成请求对象后, 路由匹配之前"""
print('This is process_request')
def process_view(self, request, func, args, kwargs):
"""路由匹配后, 视图函数调用之前"""
print('This is process_view')
def process_exception(self, request, exception):
"""视图函数发生异常时"""
print('This is process_exception')
def process_response(self, request, response):
"""视图函数执行后, 响应返回浏览器之前"""
print('This is process_response')
return response
运行MyDjango, 项目将自动运行中间件MyMiddleware的初始化函数__init__,
初始化函数必须设置函数参数get_response, 还需要将参数get_response设为类属性self.get_response,
否则在访问网站时将提示AttributeError异常, 如图11-38所示.
图11-38 AttributeError异常
当用户在浏览器上访问某个网址时, Django为当前用户创建请求对象, 请求对象创建成功后,
程序将执行钩子函数process_request, 通过重写该函数可以获取并判断用户的请求是否合法.
函数参数request代表用户的请求对象, 它与视图函数的参数request相同.
钩子函数process_request执行完成后, Django将用户访问的网址与路由信息进行匹配,
在调用视图函数或视图类之前, 程序将执行钩子函数process_view.
函数参数request代表用户的请求对象; 参数func代表视图函数或视图类的名称;
参数args和kwargs是路由信息传递给视图函数或视图类的变量对象.
钩子函数process_view执行完成后, Django将执行视图函数或视图类.
如果在执行视图函数或视图类的过程中出现异常报错, 程序就会执行钩子函数process_exception.
函数参数request代表用户的请求对象; 参数exception代表异常信息.
视图函数或视图类执行完成后, Django将执行钩子函数process_response, 该函数可以对视图函数或视图类的响应内容进行处理.
当钩子函数process_response执行完成后, 程序才把响应内容返回给浏览器生成网页信息.
(process_response方法可以对响应对象进行修改(比如添加, 删除或者修改headers, 修改响应体内容等), 然后将修改后的响应对象返回.
如果不做任何修改, 也应该直接返回传入的response对象.
如果忘记返回response或者返回了None, 那么Django应用将会遇到问题, 因为客户端不会收到有效的HTTP响应.)
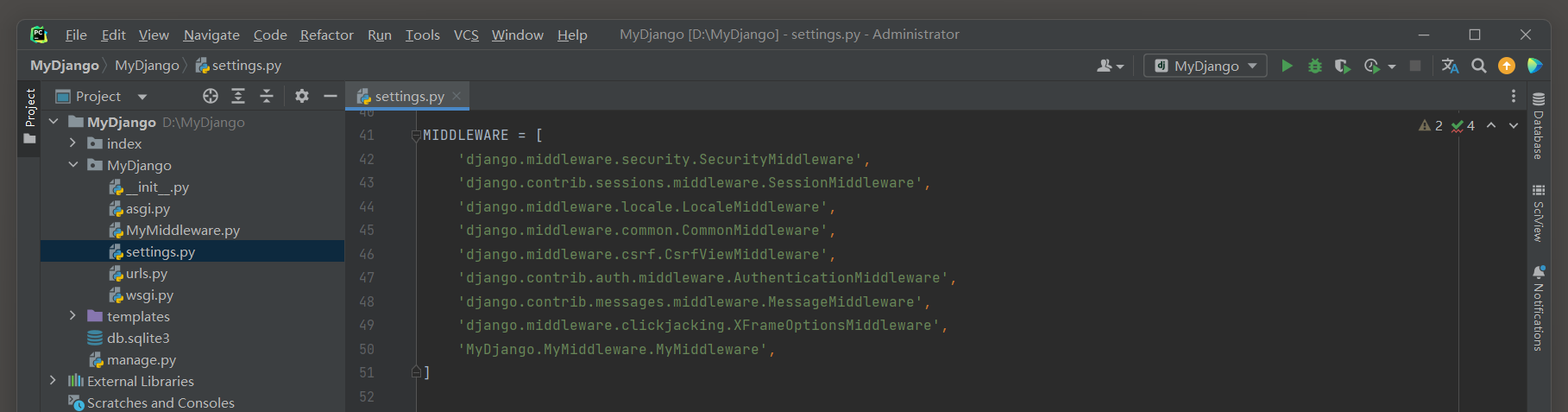
最后, 我们在MyDjango的settings.py中添加自定义中间件MyMiddleware, 配置信息如下:
MIDDLEWARE = [
'django.middleware.security.SecurityMiddleware',
'django.contrib.sessions.middleware.SessionMiddleware',
'django.middleware.common.CommonMiddleware',
'django.middleware.csrf.CsrfViewMiddleware',
'django.contrib.auth.middleware.AuthenticationMiddleware',
'django.contrib.messages.middleware.MessageMiddleware',
'django.middleware.clickjacking.XFrameOptionsMiddleware',
'MyDjango.MyMiddleware.MyMiddleware',
]
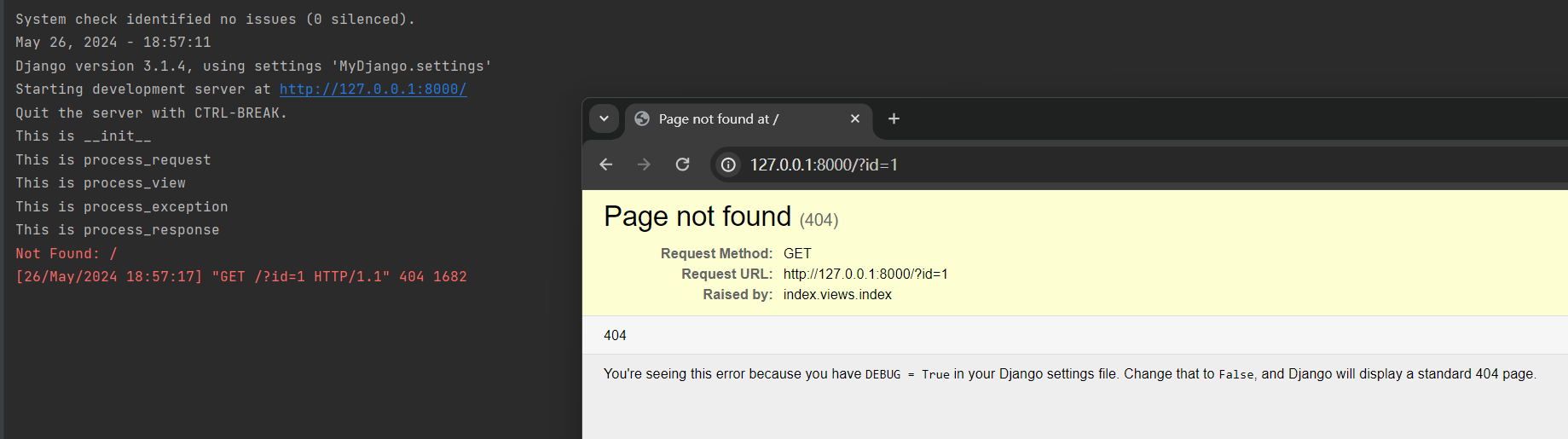
在PyCharm里运行MyDjango, 在浏览器上访问: 127.0.0.1:8000/?id=1,
由于路由地址设有请求参数id, 因此视图函数将主动抛出404异常Django将触发process_exception函数,
在PyCharm的Debug界面可以看到钩子函数的输出信息, 如图11-39所示.
图11-39 钩子函数的输出信息
11.8.2 中间件实现Cookie反爬虫
我们在4.2.3小节实现了简单的反爬虫机制, 它是在视图函数的基础上加以实现的, 本节将在中间件里实现Cookie反爬虫机制.
以11.8.1小节的MyDjango为例, 在index的urls.py中定义路由index和my_mookie, 代码如下:
# index的urls.py
from django.urls import path
from .views import *
urlpatterns = [
path('', index, name='index'),
path('my_cookie', my_cookie, name='my_cookie')
]
路由index是为用户创建Cookie; 路由my_cookie必须验证用户的Cookie才能访问, 否则抛出404异常.
然后在index的views.py中定义视图函数index和my_Cookie, 代码如下:
from django.shortcuts import render
from django.shortcuts import HttpResponse
from django.shortcuts import Http404
def index(request):
if request.GET.get('id', ''):
raise Http404('404')
return render(request, 'index.html', locals())
def my_cookie(request):
return HttpResponse('Done!')
由于定义了路由my_cookiem因此还需要在模板文件index.html中添加路由my_cookie的路由地址,
便于我们从路由index的网页跳转并访问路由myCookie.
模板文件index.html的代码如下:
<!DOCTYPE html>
<html lang="zh-hans">
<head>
<meta charset="UTF-8">
<title>首页</title>
</head>
<body>
<div>Hello Django!</div>
<a href="{% url 'index:my_cookie' %}">查看Cookie</a>
</body>
</html>
完成MyDjango的网页功能开发, 下一步在MyDjango的myMiddleware.py文件中自定义中间件MyMiddleware,
由中间件MyMiddleware实现Cookie反爬虫机制, 实现代码如下:
from django.utils.deprecation import MiddlewareMixin
from django.utils.timezone import now
from django.shortcuts import Http404
class MyMiddleware(MiddlewareMixin):
# 如果不是请求首页, 则验证Cookie
def process_view(self, request, func, args, kwargs):
if func.__name__ != 'index':
# 从cookie中取出盐
salt = request.COOKIES.get('salt', '')
try: # 提供键和盐, 内部会通过 cookie_value = self.COOKIES[key] 获取值
request.get_signed_cookie('MySign', salt=salt)
except Exception as e:
print(e)
raise Http404('当前Cookie无效')
def process_response(self, request, response):
salt = str(now())
response.set_signed_cookie( # 设置cookie
'MySign', # key
'sign', # value
salt=salt, # 盐
max_age=10 # 过期时间
)
response.set_cookie('salt', salt) # 将盐保存到cookie
return response
中间件MyMiddleware重写了钩子函数process_view和process_response, 两个钩子函数实现的功能说明如下:
● process_view用于判断参数func的__name__属性是否为index, 如果属性__name__的值不等于index,
就说明当前请求不是由视图函数index处理的, 从当前请求获取Cookie并进行解密处理.
若解密成功, 则说明当前请求是合法的请求; 否则判为非法请求并提示404异常.
● process_response是在响应内容里添加Cookie信息, 这是为下一次请求提供Cookie信息,
确保每次请求的Cookie信息都是动态变化的, 并将Cookie的生命周期设为10秒.
为了验证Cookie的变化过程, 我们运行MyDjango, 在浏览器中打开开发者工具并访问: 127.0.0.1:8000,
然后在开发者工具的Network标签的All选项里找到127.0.0.1:8000的Cookie信息,
首次访问路由index的时候, 只有响应内容才会生成Cookie信息, 如图11-40所示.
图11-40 Cookie信息
在网页上单击'查看Cookie'链接将访问路由my_cookie, 浏览器将路由index生成的Cookie作为路由my_cookie的请求信息,
并且路由myCookie的响应内容更新了Cookie信息, 如图11-41所示.
图11-41 Cookie信息
如果在Cookie失效或没有Cookie的情况下访问路由myCookie,
钩子函数process_view就无法获取当前请求的Cookie信息, 导致Cookie解密失败, 从而提示404异常.
11.9 异步编程
异步编程是使用协程, 线程, 进程或者消息队列等方式实现.
Django支持多线程, 内置异步和消息队列方式实现, 每一种实现方式的说明如下:
(1) 多线程是在当前运行的Django服务中开启新的线程执行.
(2) 内置异步是从Django 3新增的内置功能, 主要使用Python的内置模块asyncio和关键词Async/Await实现,
异步功能主要在视图中实现, 我们简称为异步视图.
(3) 消息队列是使用Celery框架和消息队列中间件搭建, 它在Django的基础上独立运行,
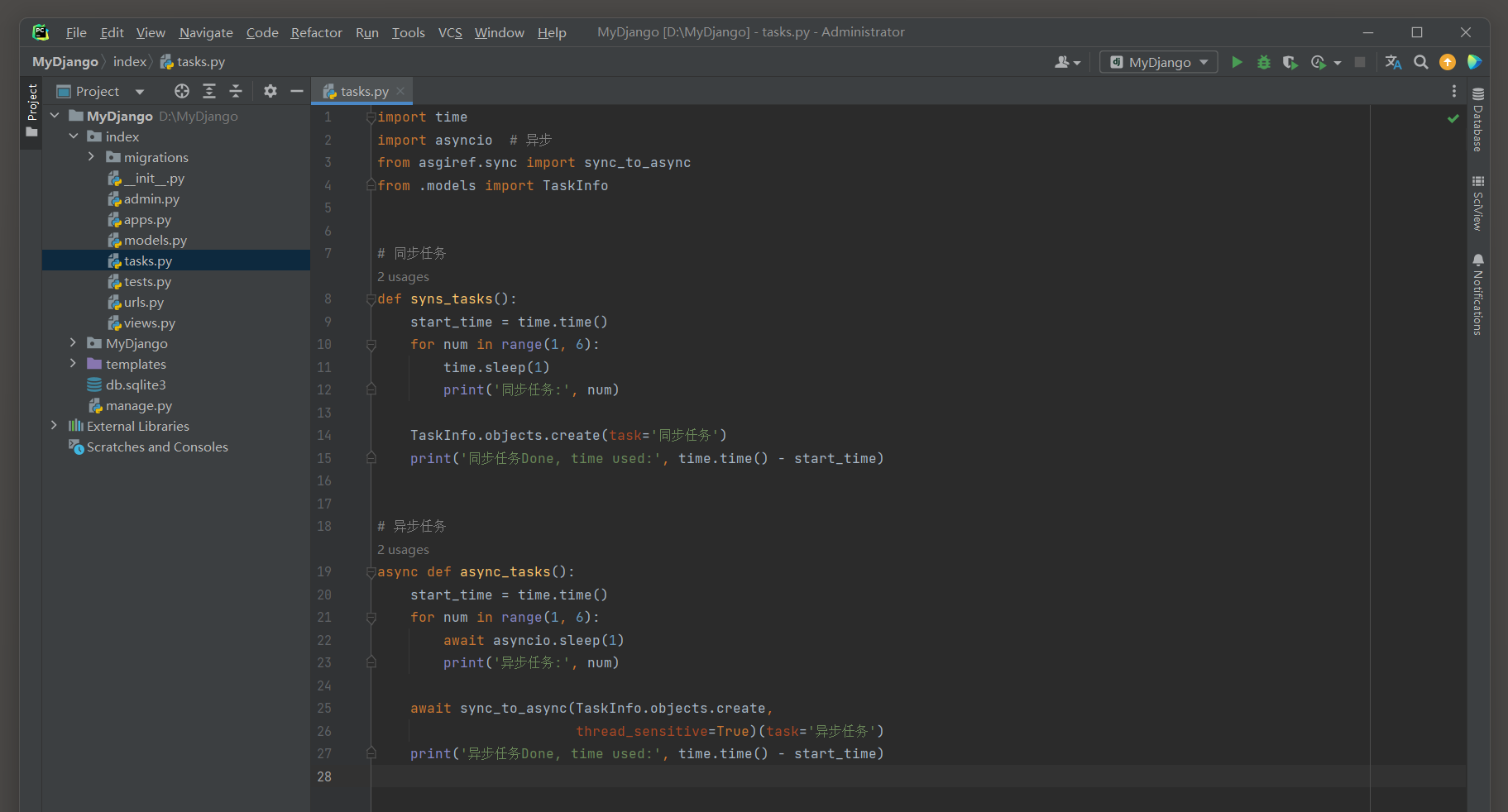
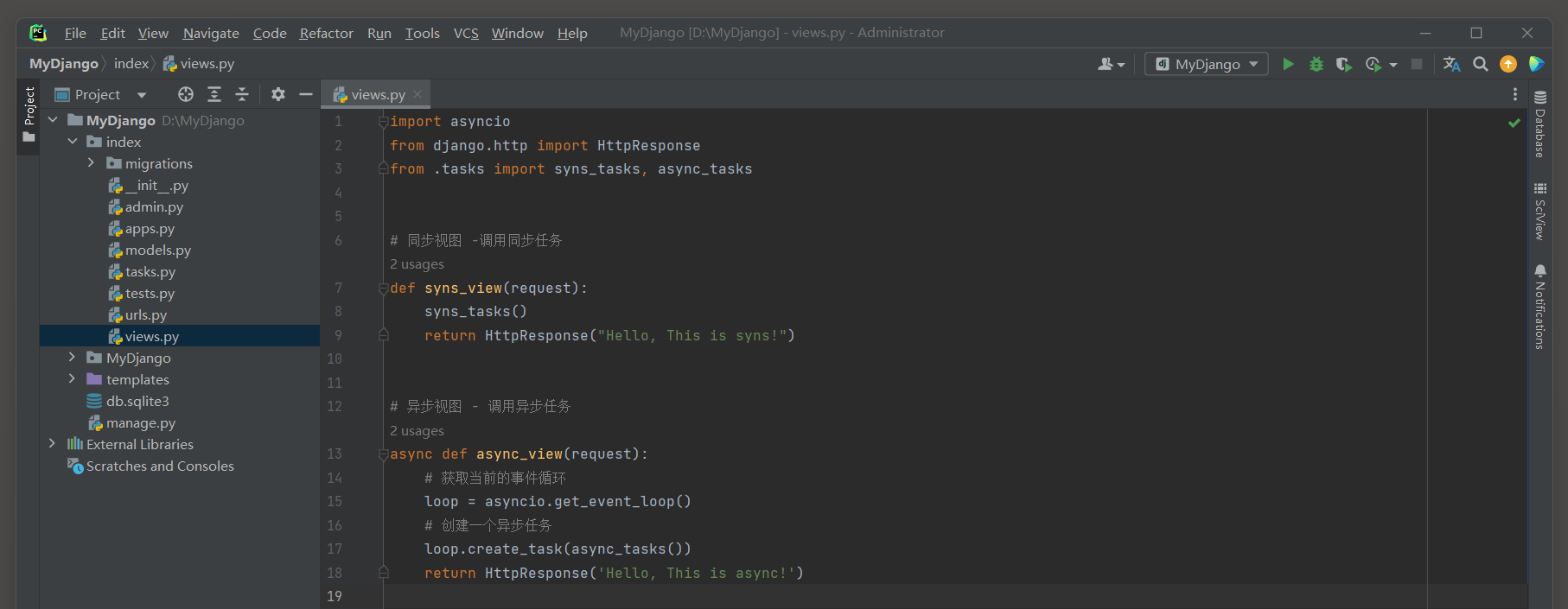
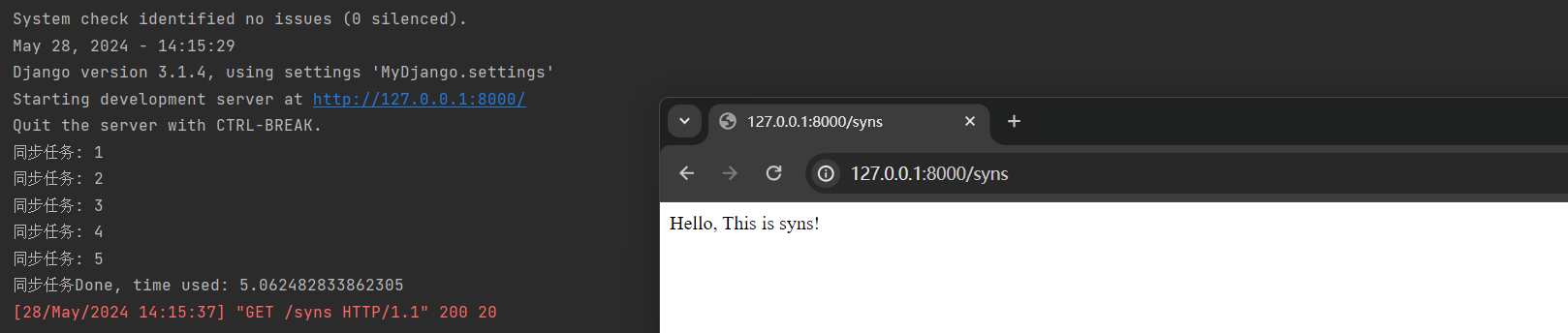
但Django必须运行后才能启用, 主要解决了应用耦合, 异步消息, 流量削锋等问题, 实现高性能, 高可用, 可伸缩和一致性的系统架构.
11.9.1 使用多线程
Django的多线程编程主要应用在视图函数中, 当用户在浏览器访问某个路由的时候, 其实质是向Django发送HTTP请求,
Django收到HTTP请求后, 路由对应的视图函数执行业务处理,
如果某些业务需要耗费时间处理, 可交给多线程执行, 加快网站的响应速度, 提高用户体验.
为了更好地区分单线程和多线程的差异, 我们对同一个业务功能分别执行单线程和多线程处理.
以MyDjango为例, 在项目应用index的models.py定义模型PersonInfo, 并对模型执行数据迁移,
在Sqlite3数据库中创建相应的数据表, 模型的定义过程如下:
# index的models.py
from django.db import models
class PersonInfo(models.Model):
id = models.AutoField(primary_key=True)
name = models.CharField(max_length=20)
age = models.IntegerField()
# 数据迁移
D:\MyDjango> python manage.py makemigrations
No changes detected
D:\MyDjango> python manage.py migrate
...
模型的数据迁移执行完成后, 下一步在MyDjango文件夹的urls.py定义路由的命名空间index,
并指向项目应用index的urls.py, 在index的urls.py定义路由index和thread_index, 代码如下:
# MyDjango的urls.py
from django.urls import path, include
urlpatterns = [
path('', include(('index.urls', 'index'), namespace='index')),
]
# index的urls.py
from django.urls import path
from .views import *
urlpatterns = [
path('', index, name='index'),
path('thread', thread_index, name='thread_index')
]
首页路由和thread路由分别指向视图函数index和thread_index, 两个视图函数都是用于查询模型PersonInfo的数据,
并把查询结果传递给模板文件index.html, 再由模板文件生成网页.
视图函数index和thread_index分别使用单线程和多线程查询模型PersonInfo的数据, 实现代码如下:
# index的views.py
from django.shortcuts import render
from .models import PersonInfo
from concurrent.futures import ThreadPoolExecutor
import datetime
import time
def index(request):
start_time = datetime.datetime.now()
print(start_time)
title = '单线程'
results = []
for i in range(1, 3):
person = PersonInfo.objects.filter(id=i).filter()
time.sleep(3) # 延时三秒
results.append(person) # 保存结果
end_time = datetime.datetime.now()
print(end_time)
print('单线程查询所花费时间:', end_time - start_time)
return render(request, 'index.html', locals())
# 定义多线程任务
def get_info(pk):
person = PersonInfo.objects.filter(pk).first()
time.sleep(3) # 延时三秒
return person # 返回结果
def thread_index(request):
# 计算运行时间
start_time = datetime.datetime.now()
print(start_time)
title = '多线程'
results = []
fs = []
thread = ThreadPoolExecutor(max_workers=2)
# 执行多线程
for i in range(1, 3):
# 异步执行, 提交任务到线程池执行器, 并立即返回一个Future对象(存放执行结果)
t = thread.submit(get_info, i)
fs.append(t)
# 获取多线程的执行结果
for t in fs:
# 如果相应的任务还没有完成, result()方法会阻塞当前线程, 直到任务完成并返回结果
results.append(t.result())
# 计算运行时间
end_time = datetime.datetime.now()
print(end_time)
print('多线程查询所花费时间:', end_time - start_time)
return render(request, 'index.html', locals())
(thread.submit(get_info, i)将get_info函数及其参数提交给ThreadPoolExecutor,
并且该函数会在线程池中的一个可用线程上异步执行.
submit方法会立即返回一个Future对象, 这个对象代表了异步计算的结果.
Future对象本身并不包含结果, 它只是一个占位符, 表示计算正在进行中.
可以使用 Future.result() 方法来获取结果, 但是这个方法会阻塞调用线程, 直到计算完成并返回结果.)
在上述代码中, 视图函数的业务处理是查询模型PersonInfo的id=1和id=2的数据,
每次查询的间隔时间为3秒, 然后将所有查询结果写入列表results, 再由模板文件解析列表results的数据.
视图函数index将模型PersonInfo的两次数据查询是单线程执行, 每次查询间隔为3秒, 所以整个视图函数的处理时间约为6秒左右;
视图函数thread_index将模型PersonInfo的两次数据查询分别交给两条线程执行,
假设两条线程并发执行, 数据查询后的等待时间同时发生, 所以整个视图函数的处理时间约为3秒左右.
最后在模板文件index.html中编写模板语法, 对视图函数传递的列表results进行解析, 生成相应的网页信息.
模板文件index.html的代码如下:
<!-- templates的index.html -->
<!DOCTYPE html>
<html lang="zh-hans">
<head>
<title>{{ title }}</title>
</head>
<body>
{% for r in results %}
<div>姓名:{{ r.name }}</div>
<div>年龄:{{ r.age }}</div>
{% endfor %}
</body>
</html>
为了测试功能是否正常运行, 我们在模型PersonInfo对应的数据表中新增数据, 如图11-42所示.
图11-42 新增数据
使用PyCharm运行MyDjango, 在浏览器中分别访问路由index和thread_index,
两者返回相同的网页内容, 查看PyCharm的Run窗口, 对比路由index和thread_index从请求到响应的时间, 如图11-43所示.
图11-43 请求信息
11.9.2 启用ASGI服务
内置异步是从Django 3新增的内置功能, 它是在原有Django服务的基础上再创建一个Django服务, 两者是独立运行, 互不干扰.
新的Django服务实质是开启一个ASGI服务, ASGI是异步网关协议接口,
一个介于网络协议服务和Python应用之间的标准接口, 能够处理多种通用的协议类型, 包括HTTP, HTTP2和WebSocket.
使用python manage.py runserver运行Django服务是在WSGI模式下运行,
WSGI是基于HTTP协议模式, 不支持WebSocket, 而ASGI的诞生是为了解决WSGI不支持当前Web开发中一些新的协议标准, 如WebSocket协议.
在Django 3.0或以上版本, Django会在项目同名的文件夹中新建asgi.py文件,
以MyDjango为例, 其目录结构如图11-44所示, MyDjango文件夹中分别有asgi.py和wsgi.py文件.
使用python manage.py runserver开启Django服务器的时候, Django会自动执行wsgi.py的代码.
图11-44 目录结构
如果要运行Django的ASGI服务, 需要依赖第三方模块实现.
ASGI服务可由Daphne, Hypercorn或Uvicorn启动.
Daphne, Hypercorn或Uvicorn作为ASGI的服务器, 为ASGI服务提供高性能的运行环境.
Daphne, Hypercorn或Uvicorn均可使用pip指令安装, 这里以Daphne为例, 讲述其如何使用Daphne开启ASGI服务.
首先在PyCharm打开MyDjango项目, 然后在Terminal窗口下输入: pip install daphne安装Daphne.
(Daphne是一个纯Python的ASGI服务器, 由Django项目的成员维护.
ASGI是WSGI的继任者, 虽然提供了更多的功能和优势, 但在成熟度和稳定性方面可能还需要进一步完善和验证.
以下是关于Django Daphne的主要特点和功能:
* 1. ASGI兼容: Daphne实现了ASGI(Asynchronous Server Gateway Interface)规范,
可以与任何符合ASGI标准的应用程序框架进行集成, 如: Django, Flask, Starlette等.
* 2. WebSocket支持: Daphne提供了对WebSocket协议的原生支持, 使得在使用Django Channels构建实时应用程序时更加方便.
* 3. 多协议支持: 除了HTTP和WebSocket, Daphne还支持其他协议, 如: HTTP/2和Server-Sent Events(SSE),
使得应用程序能够满足不同的需求.
* 4. 配置灵活: Daphne提供了配置选项, 可以根据需求进行调整, 包括并发连接数, SSL证书配置等.
* 5. 与Django集成: 作为Django框架的推荐服务器, Daphne可以与Django无缝集成,
通过简单的配置即可将Django应用程序部署到Daphne服务器上.)
当Daphne安装成功后, 在Terminal窗口输入Daphne指令开启Django的ASGI服务,
Terminal窗口的当前路径必须是项目的路径地址, 如图11-45所示.
PS D:\MyDjango> daphne -b 127.0.0.1 -p 8001 MyDjango.asgi:application
2024-05-27 16:27:33,196 INFO Starting server at tcp:port=8001:interface=127.0.0.1
2024-05-27 16:27:33,197 INFO HTTP/2 support not enabled (install the http2 and tls Twisted extras)
2024-05-27 16:27:33,197 INFO Configuring endpoint tcp:port=8001:interface=127.0.0.1
2024-05-27 16:27:33,199 INFO Listening on TCP address 127.0.0.1:8001
图11-45 开启Django的ASGI服务
在daphne -b 127.0.0.1 -p 8001 MyDjango.asgi:application的指令中, 每个参数说明如下:
(1) -b 127.0.0.1 是设置ASGI服务的IP地址.
(2) -p 8001 是设置ASGI服务的端口.
(3) MyDjango.asgi:application是MyDjango文件夹的asgi.py定义的application对象.
总的来说, ASGI服务是WSGI服务的扩展, 两个服务之间是独立运行互不干扰, Django中定义的所有路由都可以在WSGI服务和ASGI服务访问.
浏览器中访问: http://127.0.0.1:8001/ .
11.9.3 异步视图
这里以MyDjango项目为例, 项目使用Sqlite3数据库存储数据, 并设有项目应用index,
在index的models.py中定义模型TaskInfo, 模型TaskInfo是在异步执行过程中实现数据库操作, 模型TaskInfo的定义如下:
# index的models.py
from django.db import models
class TaskInfo(models.Model):
id = models.AutoField(primary_key=True)
task = models.CharField(max_length=50)
# 数据迁移
D:\MyDjango> python manage.py makemigrations
No changes detected
D:\MyDjango> python manage.py migrate
完成模型定义后, 下一步使用Django内置指令执行数据迁移, 在Sqlite3数据库中创建数据表,
然后在MyDjango文件夹的urls.py中定义路由命名空间index, 指向项目应用index的urls.py,
并在项目应用index的urls.py中分别定义路由syns和async, 代码如下:
# MyDjango的urls.py
from django.contrib import admin
from django.urls import path, include
urlpatterns = [
path('admin/', admin.site.urls),
path('', include(('index.urls', 'index'), namespace='index')),
]
# index的urls.py
from django.urls import path
from .views import syns_view, async_view
urlpatterns = [
path('syns', syns_view, name='syns'), # 同步
path('asyn', async_view, name='async'), # 异步
]
路由syn和asyn分别对应视图函数syns_tasks()和async_tasks(),
视图函数syns_tasks()是执行同步任务, 视图函数async_tasks()是执行异步任务.
假如视图函数syns_tasks()和async_tasks()实现相同的业务逻辑, 这样可以对比两者在运行上的差异.
下一步在项目中应用index创建文件tasks.py, 在文件中定义函数syns_tasks()和async_tasks(), 代码如下:
# index 的 task.py
import time
import asyncio # 异步
from asgiref.sync import sync_to_async
from .models import TaskInfo
# 同步任务
def syns_tasks():
start_time = time.time()
for num in range(1, 6):
time.sleep(1)
print('同步任务:', num)
TaskInfo.objects.create(task='同步任务')
print('同步任务Done, time used:', time.time() - start_time)
# 异步任务(加括号调用返回一个协程对象)
async def async_tasks():
start_time = time.time()
for num in range(1, 6):
await asyncio.sleep(1)
print('异步任务:', num)
await sync_to_async(TaskInfo.objects.create,
thread_sensitive=True)(task='异步任务')
print('异步任务Done, time used:', time.time() - start_time)
( 在Python中, 定义一个使用 async def 的函数时, 这个函数被称为异步函数.
调用这个异步函数时(即加括号), 并没有直接执行它的代码, 而是得到了一个协程对象(coroutine object).
这个协程对象代表了要执行的异步操作, 但它本身不会自动执行. )
函数syns_tasks()和async_tasks()实现了相同功能, 两者都是循环遍历5次, 每次遍历会延时1秒,
循环遍历结束就对模型TaskInfo进行数据写入操作, 整个执行过程会自动计算所消耗时间, 从而对比两者的执行效率.
在tasks.py中定义的syns_tasks()和async_tasks()分别由视图函数syns_view()async_view()调用,
视图函数syns_view()和async_view()的定义过程如下:
# index的views.py
import asyncio
from django.http import HttpResponse
from .tasks import syns_tasks, async_tasks
# 同步视图 -调用同步任务
def syns_view(request):
syns_tasks()
return HttpResponse("Hello, This is syns!")
# 异步视图 - 调用异步任务
async def async_view(request):
# 获取当前的事件循环
loop = asyncio.get_event_loop()
# 创建一个异步任务, 参数是协程对象
loop.create_task(async_tasks())
return HttpResponse('Hello, This is async!')
(asyncio.get_event_loop(): 返回是当前事件循环的实例.
在Python的异步编程中, 事件循环是一个至关重要的组件, 它负责执行和调度异步任务.
调用asyncio.get_event_loop()时, 实际上是在获取当前线程的事件循环.
在大多数情况下, 每个线程都应该有一个独立的事件循环, 尽管在Python 3.7及以后的版本中,
主线程(通常是启动Python解释器的线程)默认已经有一个事件循环了.
create_task(coro): 安排一个协程(coroutine)的执行, 并返回一个Task对象.
这个Task对象可以用来跟踪协程的执行状态, 获取协程的返回结果或者等待协程的完成. )
在PyCharm的Run窗口启动Django的WSGI服务, Terminal窗口启动Django的ASGI服务, 当服务启动成功后,
在浏览器中分别访问 127.0.0.1:8000/syns 和 127.0.0.1:8001/async ,
从PyCharm的Run窗口和Terminal窗口查看请求信息, 如图11-46所示.
启动ASGI服务: daphne -b 127.0.0.1 -p 8001 MyDjango.asgi:application .
图11-46 请求信息
路由syn和asyn从请求到响应所消耗时间相同, 但从用户体验分析, 两者的差异如下:
(1) 路由syns从请求到响应过程需要花费5秒时间, 用户需要等待5秒才能看到网页内容.
因为延时功能与当前请求是同步执行, 两者是在同一个线程中依次执行, 所以需要花费5秒才能完成整个请求到响应过程.
(2) 路由async从请求到响应无须等待就能看到网页内容, 它将延时功能交由异步处理,
当前请求与延时功能在不同的线程中执行, 使当前请求减少不必要的堵塞, 提高了系统的响应速度.
11.9.4 异步与同步的转换
在11.9.3小节中, 视图函数syns_view()调用syns_tasks(),async_view()调用async_tasks(),
如果将两个视图函数调用的函数进行互换, 比如视图函数syns_view()调用async_tasks(),
Django就会提示RuntimeError异常, 如图11-47所示.
图11-47 RuntimeError异常
在Django中, 同步视图只能调用同步任务, 异步视图只能调用异步任务,
如果同步视图调用异步任务或异步视图调用同步任务, 程序就会提示RuntimeError异常.
在某些特殊情况下, 我们需要在同步视图调用已定义的异步任务, 还可能是同步任务和异步任务实现同一个功能,
为了减少代码冗余, 将同步任务和异步任务定义在同一个函数中.
为了使同步视图和异步视图能够调用同一个函数, 可以使用asgiref模块将函数转换为同步任务或异步任务, 再由同步视图或异步视图进行调用.
如果读者细心观察, tasks.py的async_tasks()对模型TaskInfo执行数据新增的时候,
已调用了asgiref模块的sync_to_async()将ORM的数据操作转为异步实现.
(主要是为了方便在异步上下文中调用同步代码(比如Django ORM操作), 但它并不改变同步代码本身的性质.
这意味着, 即使使用了sync_to_async()将ORM操作转换为异步调用, ORM操作本身仍然是同步执行的, 它会在后台线程中阻塞直到完成.
为了真正实现ORM操作的异步化, 需要使用支持异步的数据库库或ORM. 然而, Django的默认ORM并不支持异步操作.)
我们将演示如何使用asgiref模块的async_to_sync()或sync_to_async()转换同步任务或异步任务.
比如同步视图syns_view()调用异步任务async_tasks(), 异步视图async_view()调用同步任务syns_tasks(), 实现方式如下:
# index的views.py
import asyncio
from django.http import HttpResponse
from .tasks import syns_tasks, async_tasks
from asgiref.sync import async_to_sync, sync_to_async
# 同步视图 - 调用异步任务
def syns_view(request):
# 异步任务转为同步任务
s = async_to_sync(async_tasks)
# 调用同步函数
s()
return HttpResponse("Hello, This is syns!")
# 异步视图 - 调用同步任务
async def async_view(request):
# 同步任务转为异步任务
a = sync_to_async(syns_tasks)
# 获取循环事件
loop = asyncio.get_event_loop()
# 创建任务
loop.create_task(a())
return HttpResponse("Hello, This is async!")
最后在PyCharm的Run窗口启动Django的WSGI服务, Terminal窗口启动Django的ASGI服务,
当服务启动成功后, 在浏览器分别访问: 127.0.0.1:8000/syns 和 127.0.0.1:8001/async,
从PyCharm的Run窗口和Terminal窗口查看请求信息, 如图11-48所示.
图11-48 请求信息
虽然asgiref模块的async_to_sync()或sync_to_async()可以将异步任务和同步任务进行转换,
但访问路由syns和async的时候, 它们都要等待5秒才能看到网页内容, 也就是说asgiref模块将同步任务转为异步任务的时候,
同步任务并没有添加异步特性, 只是满足了异步视图的调用.
异步视图和同步视图的区别在于是否使用Python的内置模块asyncio和关键词Async/Await定义视图,
它们与ASGI服务和WSGI服务没有太大关联, 异步视图和同步视图都能在ASGI服务和WSGI服务进行访问.
11.10 信号机制
信号机制是执行Django某些操作的时候而触发的,
例如在保存模型数据之前将触发内置信号pre_save, 保存模型数据之后将触发内置信号post_save等.
同时, 为了满足实际的业务场景, Django允许开发者自定义信号.
11.10.1 内置信号
在Linux编程中也存在信号的概念, 它主要用于进程之间的通信, 通知进程发生的异步事件.
而Django的信号用于在执行操作时达到解耦目的.
当某些操作发生的时候, 系统会根据信号的回调函数执行相应的操作, 该模式称为观察者模式, 或者发布-订阅(Publish/Subscribe)模式,
Django的信号主要包含以下3个要素:
(1) 发送者(sender): 信号的发出方.
(2) 信号(signal): 发送的信号本身.
(3) 接收者(receiver): 信号的接收者.
信号机制与中间件的功能原理较为相似, 中间件主要作用在HTTP请求到响应的过程中,
信号机制作用在框架的各个功能模块中, Django内置了许多的信号机制, 详细说明如下:
● pre_init: 模型执行初始化函数__init__()之前触发.
● post_init: 模型执行初始化函数__init__()之后触发.
● pre_save: 保存模型数据之前触发.
● post_save: 保存模型数据之后触发.
● pre_delete: 删除模型数据之前触发.
● post_delete: 删除模型数据之后触发.
● m2m_changed: 操作多对多关系表的时候触发.
● class_prepared: 程序运行时, 检测每个模型的时候触发.
● pre_migrate: 执行migrate命令之前触发.
● post_migrate: 执行migrate命令之后触发.
● request_started: HTTP请求之前触发.
● request_finished: HTTP请求之后触发.
● got_request_exception: HTTP请求发生异常之后触发.
● setting_changed: 使用单元测试修改配置文件的时候触发.
● template_rendered: 使用单元测试渲染模板的时候触发.
● connection_created: 创建数据库连接的时候触发.
信号机制在许多开发场景中非常实用, 常见的应用场景如下:
(1) 当用户登录成功后, 给该用户发送通知消息; 或者在论坛博客更新话题动态, 可以使用信号机制实现信息推送;
当发布动态有其他用户评论的时候, 也可以使用信号机制通知.
(2) 当网站设有缓存功能, 数据库的数据发生变化的时候, 缓存数据也要随之变化. 为了使数据保持一致, 可由信号机制更新缓存数据.
比如数据库的数据发生变化, 即模型执行增改删操作之后, 使用内置信号post_save更新缓存数据即可.
(3) 订单状态对库存的影响, 用户创建订单并完成支付的时候, 商品库存数量应减去订单中商品购买数量;
如果用户取消订单, 商品库存数量应加上订单中商品购买数量.
订单的创建和取消操作应在订单信息表完成, 当订单信息表的数据发生变化时, 商品库存表的数据也要随之变化.
通过使用内置信号post_save监听订单信息表, 当数据发生变化, Django就会自动修改商品库存表的数据.
若要使用Django的内置信号机制, 只需将内置信号绑定到某个函数(即设置回调函数), 并将其导入视图文件即可.
以MyDjango为例, 在MyDjango文件夹中创建sg.py文件, 该文件是为需要使用的内置信号设置回调函数,
本示例使用内置信号request_started, 其回调函数设置方式如下:
# MyDjango的sg.py
from django.core.signals import request_started
# 编写方法1:
# 设置内置信号request_started的回调函数signal_request
# def signal_request(sender, **kwargs):
# print("request is coming") # 请求来了
# print(sender) # 当前信号是由那个对象触发的
# print(kwargs) # 当前触发对象的属性与方法
# # 将内置信号request_started与回调函数signal_request绑定
#
#
# request_started.connect(signal_request)
# 编写方法2:
from django.dispatch import receiver
# 使用内置函数receiver作为回调函数的装饰器
# 将内置信号request_started与回调函数signal_request_2绑定
@receiver(request_started)
# 设置内置信号request_started的回调函数signal_request
def signal_request_2(sender, **kwargs):
print("request is coming too")
print(sender)
print(kwargs)
上述代码中, 我们使用两种方法设置内置信号request_started的回调函数, 详细说明如下:
(1) 第一种方法是由内置信号调用connect()方法, 在connect()方法里面传入回调函数的函数名.
(2) 第二种方法是在回调函数中使用内置装饰器receiver, 装饰器的参数为信号名称.
回调函数设有参数sender和kwargs, 在Django源码中可以找到参数的详细说明, 如图11-49所示, 每个参数说明如下:
(1) 参数sender代表当前信号是由那个对象触发的.
(2) 参数kwargs代表当前触发对象的属性与方法.
图11-49 receiver源码
下一步在MyDjango中定义路由index以及视图函数index(), 用于检验信号机制的触发效果.
在MyDjango的urls.py, index的urls.py和views.py中编写以下代码:
# MyDjango的urls.py
from django.urls import path, include
urlpatterns = [
# 指向index的路由文件urls.py
path('', include(('index.urls', 'index'), namespace='index')),
]
# index的urls.py
from django.urls import path
from .views import index
urlpatterns = [
# 定义路由
path('', index, name='index'),
]
# index的views.py
from django.http import HttpResponse
# 在视图中必须导入sg文件, 否则信号机制不会生效
from MyDjango.sg import *
def index(request):
print('This is view')
return HttpResponse('请求成功')
由于Django的内置信号已为我们设定了触发机制, 当某些程序运行的时候, 信号机制就会自动触发,
Django将自动调用并执行信号机制的回调函数.
在上述例子中, 内置信号request_started设置了回调函数signal_request()和signal_request_2(),
在Django接收HTTP请求之前, 它将触发内置信号request_started, 执行回调函数signal_request()和signal_request_2(),
只有回调函数执行完成后, HTTP请求才会交给视图进行下一步处理.
运行MyDjango, 打开浏览器访问: http://127.0.0.1:8000/, 在PyCharm的Run窗口查看当前请求信息, 如图11-50所示.
图11-50 请求信息
11.10.2 自定义信号
当Django内置的信号机制无法满足开发需求的时候, 我们通过自定义信号实现.
在自定义信号之前, 首先了解一下信号类的定义过程,
在Python安装目录下打开Django源码文件Lib\site-packages\django\dispatch\dispatcher.py, 如图11-51所示.
图11-51 源码文件dispatcher.py
信号类Signal的初始化函数__init__()设置了参数providing_args和use_caching, 每个参数的说明如下"
(1) 参数providing_args是设置信号的回调函数的参数**kwargs.
(2) 参数use_caching是否使用缓存, 默认值为False.
信号类Signal还定义了8个方法, 每个方法在源码上已有英文注释, 本书只列举常用方法,
分别有connect(), disconnect()和send(), 它们的详细说明如下:
(1) connect()将信号与回调函数进行绑定操作.
(2) disconnect()将信号与回调函数进行解绑操作.
(3) send()是触发信号, 使信号执行回调函数.
大致了解信号类Signal的定义过程后, 我们尝试自定义信号, 自定义信号是对信号类Signal执行实例化操作,
通过实例化对象设置回调函数, 从而完成自定义过程.
以MyDjango为例, 为了更好地演示自定义信号的应用, 在项目应用index的models.py中定义模型PersonInfo, 定义过程如下:
from django.db import models
class PersonInfo(models.Model):
id = models.AutoField(primary_key=True)
name = models.CharField(max_length=20)
age = models.IntegerField()
def __str__(self):
return self.name
class Meta:
verbose_name = '人员信息'
# 执行数据迁移:
PS D:\MyDjango> python manage.py makemigrations
Migrations for 'index':
index\migrations\0001_initial.py
- Create model PersonInfo
PS D:\MyDjango> python manage.py migrate
Operations to perform:
...
模型PersonInfo定义成功后执行数据迁移, 在Sqlite3数据库中生成对应的数据表;
然后在MyDjango文件夹的sg.py文件中自定义信号my_signals和回调函数mySignal(), 代码如下:
# MyDjango的sg.py
from index.models import PersonInfo
from django.dispatch import Signal
my_signals = Signal()
# 注册信号的回调函数
def my_signal(sender, **kwargs):
print('sender is ', sender)
print('kwargs is ', kwargs)
print(PersonInfo.objects.all())
# 将自定义的信号my_signals与回调函数mySignal绑定
my_signals.connect(my_signal)
# 如果一个信号有多个回调函数, 可以通过connect()和disconnect()进行切换
# my_signals.disconnect(my_signal)
在上述代码中, 我们将信号类Signal实例化生成my_signals对象, 再由my_signals对象调用方法connect()绑定回调函数my_signal(),
回调函数my_signal()分别输出参数sender, kwargs和模型PersonInfo的全部数据.
最后在MyDjango的urls.py, index的urls.py和views.py定义路由index和视图函数index(), 代码如下:
# MyDjango的urls.py
from django.urls import path, include
urlpatterns = [
# 指向index的路由文件urls.py
path('', include(('index.urls', 'index'), namespace='index')),
]
# index的urls.py
from django.urls import path
from .views import *
urlpatterns = [
# 定义路由
path('', index, name='index'),
]
# index的views.py
from django.http import HttpResponse
from MyDjango.sg import my_signals
def index(request):
# 使用自定义信号
print('已连接信号')
my_signals.send(sender='MySignals', name='kid', age=18)
return HttpResponse('请求成功')
视图函数index()导入sg.py的实例化对象my_signals,
并由实例化对象my_signals调用send()方法触发信号, 使自定义信号执行回调函数my_signal().
send()方法传入3个参数, 分别为sender, name和age,
参数sender作为回调函数的参数sender, 参数name和age作为回调函数的参数**kwargs.
在PyChram中运行MyDjango, 打开浏览器访问: http://127.0.0.1:8000/ ,
查看PyChram的Run窗口并找到回调函数mySignal()的参数内容, 如图11-52所示.
图11-52 mySignal()的参数内容
11.10.3 订单创建与取消
信号机制在实际开发中有广泛的应用场景, 以订单的创建与取消为例, 使用信号机制如何实现订单状态与商品库存的动态变化.
业务场景描述如下: 用户在商城中购买商品, 在购买过程中系统会根据商品购买信息生成订单,
当用户成功创建订单, 则说明当前交易正式生效, 商品库存应根据订单的购买数量进行递减;
如果用户取消订单, 则发生了退货行为, 商品重新进入商品库存中, 商品库存应根据订单的退货数量进行递加.
总得来说, 只要创建或取消订单, 商品的库存数量应执行相应操作.
以MyDjango为例, 在项目应用index的models.py中定义ProductInfo和OrderInfo, 定义过程如下:
# index 的models.py
from django.db import models
# 产品信息
class ProductInfo(models.Model):
id = models.AutoField(primary_key=True)
name = models.CharField(max_length=20)
number = models.IntegerField()
def __str__(self):
return self.name
class Meta:
verbose_name = '产品信息'
verbose_name_plural = '产品信息'
STATE = (
(0, '取消'),
(1, '创建'),
)
# 订单信息
class OrderInfo(models.Model):
id = models.AutoField(primary_key=True)
buyer = models.CharField(max_length=20)
product_id = models.IntegerField() # 外键
state = models.IntegerField(choices=STATE, default=1)
def __str__(self):
return self.buyer
class Meta:
verbose_name = '订单信息'
verbose_name_plural = '订单信息'
模型OrderInfo的字段product_id设为整数类型, 它与模型ProductInfo的主键ID相关联,
模型字段product_id不设为ForeignKey类型是减少模型OrderInfo和ProductInfo的耦合;
模型字段state代表订单的当前状态, 参数choices设置字段的可选值, 使字段值只能为0或1.
模型OrderInfo和ProductInfo定义后执行数据迁移, 在MyDjango的Sqlite3数据库中生成相应的数据表,
只要订单状态发生改变, 商品库存也要相应变化, 即模型OrderInfo的数据发生变化, 模型ProductInfo也要随之变化,
使用内置信号post_save即可满足开发需求.
# 数据库迁移:
D:\MyDjango> python manage.py makemigrations
Migrations for 'index':
index\migrations\0001_initial.py
- Create model OrderInfo
- Create model ProductInfo
D:\MyDjango> python manage.py migrate
我们在sg.py中定义内置信号post_save的回调函数signal_orders(), 定义过程如下:
# MyDjango的sg.py
from django.db.models.signals import post_save # 保存模型数据之后触发
from index.models import ProductInfo, OrderInfo
# 设置内置信号post_save的回调函数
def signal_orders(sender, **kwargs):
print('post_save is coming')
print(sender) # 输出sender的数据
# 打印: <class 'index.models.OrderInfo'>
print(kwargs) # 输出kwargs的所有数据
# {'signal': <django.db.models.signals.ModelSignal object at 0x000002052667C460>,
# 'instance': <OrderInfo: kid>, 'created': True, 'update_fields': None,
# 'raw': False, 'using': 'default'}
# instance代表当前修改或新增的模型对象
instance = kwargs.get('instance') # 订单详情表
# created判断当前操作是否在模型中新增数据, 若新增数据则为True
created = kwargs.get('created')
# using代表当前使用的数据库
# 如果连接了多个数据库, 则显示当前修改或新增的数据表所在数据库的名称
using = kwargs.get('using')
# update_fields控制需要更新的字段, 默认为None
update_fields = kwargs.get('update_fields')
# 当订单状态等于0的时候, 说明订单已经取消, 商品数量加1
if instance.state == 0:
p = ProductInfo.objects.get(id=instance.product_id) # 通过外键获取产品表信息
p.number += 1
p.save()
# 当订单状态等于1, 说明订单是新增, 商品数量减1
elif instance.state == 1:
p = ProductInfo.objects.get(id=instance.product_id) # 通过外键获取产品表信息
p.number -= 1
p.save()
# 将内置信息post_save与回调函数signal_post_save绑定, sender指定生效的模型,
post_save.connect(signal_orders, sender=OrderInfo)
# 当 OrderInfo 模型的实例被保存时, signal_orders函数才会被调用
回调函数signal_orders()从参数instance的state获取当前订单状态并进行判断,
如果订单状态等于0, 说明订单已经取消, 商品数量加1l
如果订单状态等于1, 说明订单是新增, 商品数量减1.
参数instance从函数参数kwargs获取, 函数参数sender和kwargs的说明如下:
(1) 参数sender是模型OrderInfo的实例化对象,
由post_save.connect(signal_orders,sender=OrderInfo)的sender=OrderInfo设置.
(2) 参数kwargs代表当前信号的模型对象, 包括参数instance, created, using和update_fields,
各个参数说明在代码注释中已有说明, 此处不再重复讲述.
最后在MyDjango的urls.py, index的urls.py和views.py定义路由create,
cancel以及视图函数creatView(), cancelView(), 代码如下:
# MyDjango的urls.py
from django.urls import path, include
urlpatterns = [
# 指向index的路由文件urls.py
path('', include(('index.urls', 'index'), namespace='index')),
]
# index的urls.py
from django.urls import path
from .views import create, cancel
urlpatterns = [
# 定义路由
path('create/', create, name='create'),
path('cancel/', cancel, name='cancel'),
]
# index 的 views.py
from django.http import HttpResponse
from MyDjango.sg import post_save
from .models import OrderInfo
# 创建订单, 触发post_save信号
def create(request):
product_id = request.GET.get('product_id', '') # 产品ID
buyer = request.GET.get('buyer', '') # 买方
if product_id and buyer:
o = OrderInfo(product_id=product_id, buyer=buyer)
o.save()
return HttpResponse('订单创建成功!')
return HttpResponse('参数无效!')
# 如果使用update修改数据, 不会触发post_save信号
# 取消订单, 触发post_save信号
def cancel(request):
pk = request.GET.get('id', '')
if pk:
o = OrderInfo.objects.get(id=pk)
# 判断订单状态
if o.state == 1:
o.state = 0
o.save()
return HttpResponse('订单取消成功!')
return HttpResponse('订单已经取消!')
return HttpResponse('参数无效!')
视图函数creat()和cancel()在操作模型OrderInfo的时候, 不能使用ORM定义的create()和update()方法操作模型数据,
否则无法触发内置信号post_save.
为了更好地验证内置信号post_save的触发过程, 我们使用Navicat Premium 12工具连接MyDjango的Sqlite3数据库文件,
在数据表index_productinfo输入商品信息, 如图11-53所示.
图11-53 数据表index_productinfo
运行MyDjango, 在浏览器中访问: http://127.0.0.1:8000/create/?buyer=kid&product_id=1,
程序根据请求参数创建订单信息, 并触发内置信号post_save的回调函数signal_orders(),
分别查看数据表index_productinfo和index_orderinfo, 如图11-54所示.
图11-54 数据表index_productinfo和index_orderinfo
在浏览器中访问: http://127.0.0.1:8000/cancel/?id=1, 请求参数id是数据表index_orderinfo的主键ID,
代表当前请求是取消id=1的订单, 请求成功后再查看数据表index_productinfo和index_orderinfo, 如图11-55所示.
图11-55 数据表index_productinfo和index_orderinfo
11.11 本章小结
Django为开发者提供了常见的Web应用程序,
如会话控制, 缓存机制, CSRF防护, 消息框架, 分页功能, 国际化和本地化, 单元测试和自定义中间件.
内置的Web应用程序大大优化了网站性能, 并且完善了安全防护机制, 同时也提高了开发者的开发效率.
Django内置的会话控制简称为Session, 可以为用户提供基础的数据存储.
数据主要存储在服务器上, 并且网站的任意站点都能使用会话数据.
当用户第一次访问网站时, 网站的服务器将自动创建一个Session对象,
该Session对象相当于该用户在网站的一个身份凭证, 而且Session能存储该用户的数据信息.
当用户在网站的页面之间跳转时, 存储在Session对象中的数据不会丢失, 只有Session过期或被清理时,
服务器才将Session中存储的数据清空并终止该Session.
Django提供5种不同的缓存方式, 每种缓存方式说明如下:
● Memcached: 一个高性能的分布式内存对象缓存系统, 用于动态网站, 以减轻数据库负载.
通过在内存中缓存数据和对象来减少读取数据库的次数, 从而提高网站的响应速度.
使用Memcached需要安装Memcached系统服务器, Django通过python-memcached或pylibmc模块调用Memcached系统服务器,
实现缓存读写操作, 适合超大型网站使用.
● 数据库缓存: 缓存信息存储在网站数据库的缓存表中, 缓存表可以在项目的配置文件中配置, 适合大中型网站使用.
● 文件系统缓存: 缓存信息以文本文件格式保存, 适合中小型网站使用.
● 本地内存缓存: Django默认的缓存保存方式, 将缓存存放在计算机的内存中, 只适用于项目开发测试.
● 虚拟缓存: Django内置的虚拟缓存, 实际上只提供缓存接口, 并不能存储缓存数据, 只适用于项目开发测试.
在用户提交表单时, 表单会自动加入csrfmiddlewaretoken隐藏控件,
这个隐藏控件的值会与网站后台保存的csrfmiddlewaretoken进行匹配, 只有匹配成功, 网站才会处理表单数据.
这种防护机制称为CSRF防护, 原理如下:
(1) 在用户访问网站时, Django在网页表单中生成一个隐藏控件csrfmiddlewaretoken, 控件属性value的值是由Django随机生成的.
(2) 当用户提交表单时, Django校验表单的csrfmiddlewaretoken是否与自己保存的csrfmiddlewaretoken一致, 用来判断当前请求是否合法.
(3) 如果用户被CSRF攻击并从其他地方发送攻击请求, 由于其他地方不可能知道隐藏控件csrfmiddlewaretoken的值,
因此导致网站后台校验csrfmiddlewaretoken失败, 攻击就被成功防御.
消息框架由中间件SessionMiddleware,
MessageMiddleware和INSTALLED_APPS的django.contrib.messages和django.contrib.sessions共同实现.
消息提示定义了5种消息类型, 每种类型设置了不同的级别.
消息框架的源码文件api.py中定义了消息框架的使用方法, 它一共定义9个函数, 每个函数的说明如下:
● add_message(): 为用户添加消息提示.
参数request代表当前用户的请求对象; 参数level是消息类型或级别; 参数message为消息内容;
参数extra_tags是自定义消息提示的标记, 可在模板里生成上下文;
参数fail_silently在禁用中间件MessageMiddleware的情况下还能添加消息提示, 一般情况下使用默认值即可.
● get_messages(): 获取用户的消息提示.
参数request代表当前用户的请求对象.
● get_level(): 获取用户所有消息提示最低级别的值.
参数request代表当前用户的请求对象.
● set_level(): 对不同类型的消息提示进行筛选处理,
参数request代表当前用户的请求对象; 参数level是消息类型或级别, 从用户的消息提示筛选并保留比参数level级别高的消息提示.
● debug(): 添加消息类型为debug的消息提示.
● info(): 添加消息类型为info的消息提示.
● success(): 添加消息类型为success的消息提示.
● warning(): 添加消息类型为warning的消息提示.
● error(): 添加消息类型为error的消息提示.
Django分页功能由Paginator类和Page类实现.
Paginator类一共定义了4个初始化参数和8个类方法, 每个初始化参数和类方法的说明如下:
● object_list: 必选参数, 代表需要进行分页处理的数据, 参数值可以为列表, 元组或ORM查询的数据对象等.
● per_page: 必选参数, 设置每一页的数据量, 参数值必须为整型.
● orphans: 可选参数, 如果最后一页的数据量小于或等于参数orphans的值, 就将最后一页的数据合并到前一页的数据.
比如有23行数据, 若参数per_page=10, orphans=5, 则数据分页后的总页数为2, 第一页显示10行数据, 第二页显示13行数据.
● allow_empty_first_page: 可选参数, 是否允许第一页为空.
如果参数值为False并且参数object_list为空列表, 就会引发EmptyPage错误.
● validate_number(): 验证当前页数是否大于或等于1.
● get_page(): 调用validate_number()验证当前页数是否有效, 函数返回值调用page().
● page(): 根据当前页数对参数object_list进行切片处理, 获取页数所对应的数据信息, 函数返回值调用_get_page().
● _get_page(): 调用Page类, 并将当前页数和页数所对应的数据信息传递给Page类, 创建当前页数的数据对象.
● count(): 获取参数object_list的数据长度.
● num_pages(): 获取分页后的总页数.
● page_range(): 将分页后的总页数生成可循环对象.
● _check_object_list_is_ordered(): 如果参数object_list是ORM查询的数据对象,
并且该数据对象的数据是无序排列的, 就提示警告信息.
Page类一共定义了3个初始化参数和7个类方法, 每个初始化参数和类方法的说明如下:
● object_list: 必选参数, 代表已切片处理的数据对象.
● number: 必选参数, 代表用户传递的页数.
● paginator: 必选参数,代表Paginator类的实例化对象.
● has_next(): 判断当前页数是否存在下一页.
● has_previous(): 判断当前页数是否存在上一页.
● has_other_pages(): 判断当前页数是否存在上一页或者下一页.
● next_page_number(): 如果当前页数存在下一页, 就输出下一页的页数, 否则抛出EmptyPage异常.
● previous_page_number(): 如果当前页数存在上一页, 就输出上一页的页数, 否则抛出EmptyPage异常.
● start_index(): 输出当前页数的第一行数据在整个数据列表的位置, 数据位置从1开始计算.
● end_index(): 输出当前页数的最后一行数据在整个数据列表的位置, 数据位置从1开始计算.
国际化和本地化是指使用不同语言的用户在访问同一个网页时能够看到符合其自身语言的网页内容.
国际化是指在Django的路由, 视图, 模板, 模型和表单里使用内置函数配置翻译功能;
本地化是根据国际化的配置内容进行翻译处理.
简单来说, 国际化和本地化是让整个网站的每个网页具有多种语言的切换方式.
单元测试还可以驱动功能开发, 比如我们知道需要实现的功能, 但并不知道代码如何编写,
这时就可以利用测试驱动开发(Test Driven Development)/
首先完成单元测试的代码编写, 然后编写网站的功能代码, 直到功能代码不再报错, 这样就完成网站功能的开发了.
一个完整的中间件设有5个钩子函数, Django对用户请求到网站响应的过程进行阶段划分,
每个阶段对应执行某个钩子函数, 每个钩子函数的运行说明如下:
●__init__(): 初始化函数, 运行Django将自动执行该函数.
● process_request(): 完成请求对象的创建, 但用户访问的网址尚未与网站的路由地址匹配.
● process_view(): 完成用户访问的网址与路由地址的匹配, 但尚未执行视图函数.
● process_exception(): 在执行视图函数的期间发生异常, 比如代码异常, 主动抛出404异常等.
● process_response(): 完成视图函数的执行, 但尚未将响应内容返回浏览器.
Django 3内置的异步功能说明如下:
(1) asgi.py文件用于启动ASGI服务; wsgi.py文件用于启动WSGI服务.
ASGI服务是WSGI服务的扩展, 两个服务之间各自独立运行互不干扰, Django中定义的所有路由都可以在WSGI服务和ASGI服务访问.
(2) 异步视图是Django 3.1的新增功能, 异步视图能在ASGI服务和WSGI服务中运行,
并且同步视图只能调用同步任务, 异步视图只能调用异步任务, 如果同步视图调用异步任务或异步视图调用同步任务,
程序就会提示RuntimeError异常.
(3) 如果同步视图调用异步任务或者异步视图调用同步任务,
可以使用asgiref模块的async_to_sync()或sync_to_async()进行转换,
但同步任务转为异步任务的时候, 同步任务并没有添加异步特性, 只是满足了异步视图的调用.
(4) 异步视图和同步视图的区别在于是否使用Python的内置模块asyncio和关键词Async/Await定义视图,
它们与ASGI服务和WSGI服务没有太大关联, 异步视图和同步视图都能在ASGI服务和WSGI服务进行访问.
信号机制是执行Django某些操作的时候而触发的, 例如在保存模型数据之前将触发内置信号pre_save,
保存模型数据之后将触发内置信号post_save等.
同时, 为了满足实际的业务场景, Django允许开发者自定义信号.