- 开发语言:Python
- 框架:django
- Python版本:python3.8
- 数据库:mysql 5.7
- 数据库工具:Navicat12
- 开发软件:PyCharm
系统展示
系统首页

用户登录
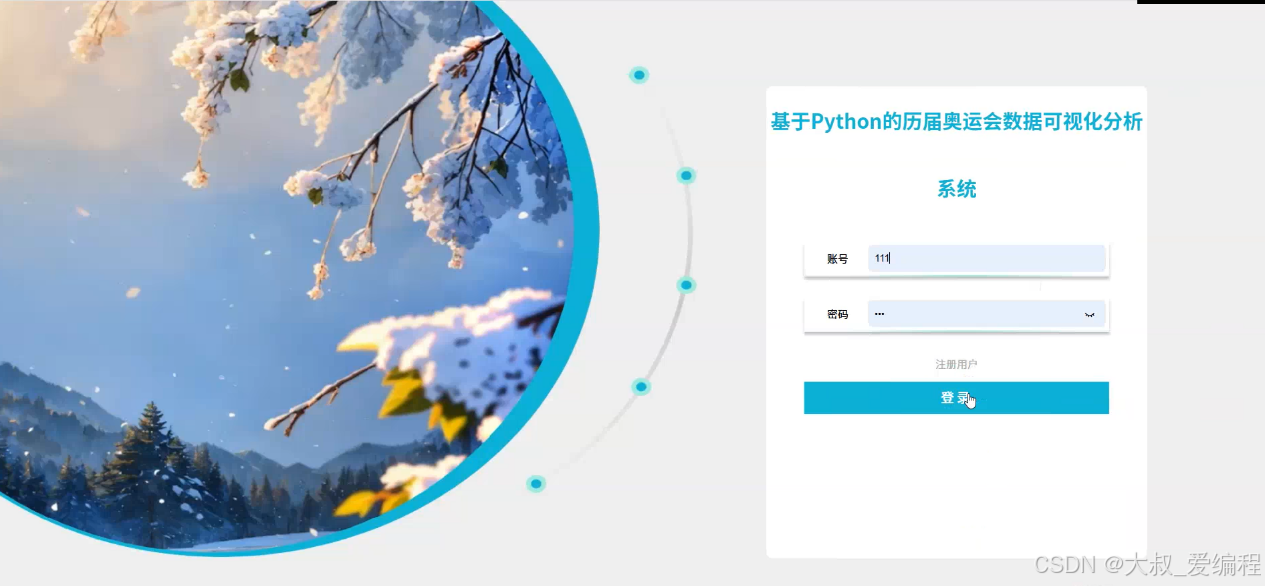
历届奥运会
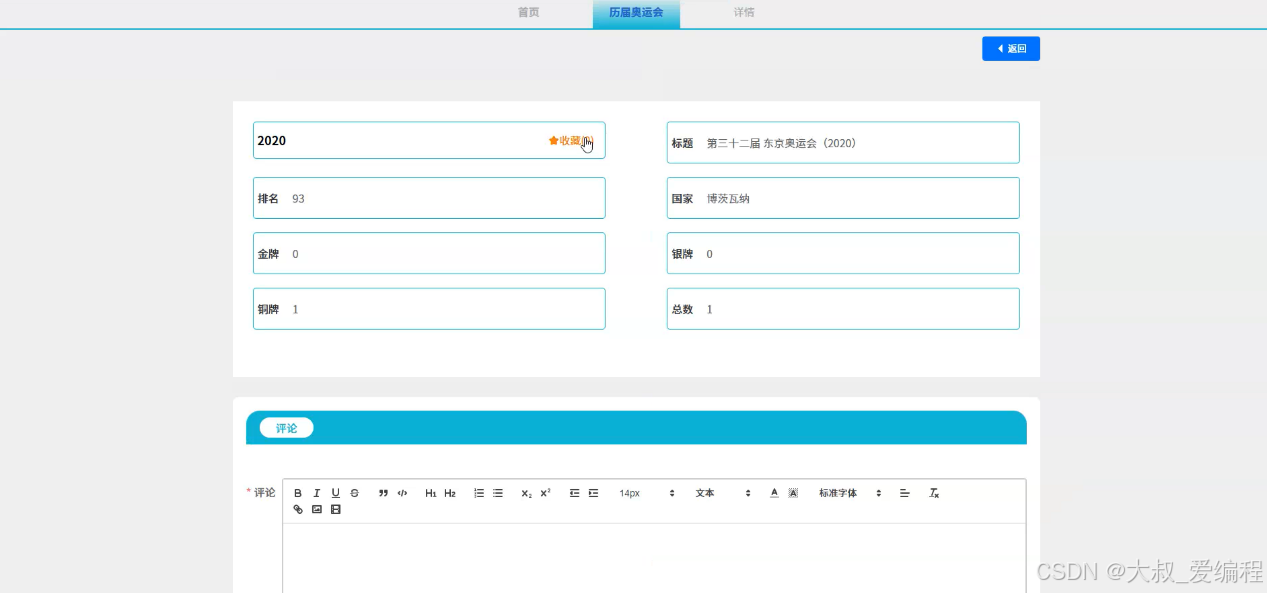
运动员数据
管理员登录
管理员功能界面
用户管理
历届奥运会
运动员数据
看板展示
摘要
本研究旨在设计并实现一个基于python的历届奥运会数据可视化分析系统,在技术选择上,本项目采用了Python语言,MySQL数据库编程,使用django框架管理工具。用户需要先注册账号,然后才能登录系统并使用功能。本文还对历届奥运会数据可视化分析系统的研究现状和意义进行了详细介绍。随着大数据和人工智能技术的不断发展,信息管理系统正逐渐成为网络应用中越来越重要的部分。本文提出的历届奥运会数据可视化分析系统将为用户提供更加高效和准确的信息智能化服务,满足用户的需求。总之,本文旨在介绍一套具有实际应用意义的历届奥运会数据可视化分析系统,针对传统管理方式进行了重要改进。通过对系统的实现和应用,本文展示了高效、准确的历届奥运会数据可视化分析系统应该具备的特点和功能,为历届奥运会数据可视化分析系统的研究和应用提供了有益的参考。
研究背景
随着现代奥运会的发展,参与国家和地区、运动项目以及运动员数量不断增加,产生的数据量庞大。传统的数据呈现方式无法有效展示和分析这些信息,因此需要通过可视化手段进行深入分析。信息技术的快速发展,尤其是大数据、云计算、人工智能等技术的成熟,为数据分析与可视化提供了强大的支持。利用这些技术,可以对历史奥运会的数据进行更全面的分析。对于体育管理机构、研究者、教练和运动员等相关方,充分理解历届奥运会的数据有助于制定更有效的训练计划、提高比赛策略和增强运动员的竞技表现。随着运动文化的普及和全球体育赛事的关注度提升,公众对奥运会的参与和关注也逐渐加深。通过可视化的方式展示奥运会的数据,可以更好地满足公众的信息需求,提高他们对赛事的认知和热情。历届奥运会的数据不仅具有历史价值,同时也为体育科学、社会学、经济学等多学科的研究提供了丰富的素材。通过细致的数据分析,可以揭示出奥运会背后的各种规律和趋势。
关键技术
Python是解释型的脚本语言,在运行过程中,把程序转换为字节码和机器语言,说明性语言的程序在运行之前不必进行编译,而是一个专用的解释器,当被执行时,它都会被翻译,与之对应的还有编译性语言。
同时,这也是一种用于电脑编程的跨平台语言,这是一门将编译、交互和面向对象相结合的脚本语言(script language)。
Django用Python编写,属于开源Web应用程序框架。采用(模型M、视图V和模板t)的框架模式。该框架以比利时吉普赛爵士吉他手詹戈·莱因哈特命名。该架构的主要组件如下:
1.用于创建模型的对象关系映射。
2.最终目标是为用户设计一个完美的管理界面。
3.是目前最流行的URL设计解决方案。
4.模板语言对设计师来说是最友好的。
5.缓存系统。
Vue是一款流行的开源JavaScript框架,用于构建用户界面和单页面应用程序。Vue的核心库只关注视图层,易于上手并且可以与其他库或现有项目轻松整合。
MYSQL数据库运行速度快,安全性能也很高,而且对使用的平台没有任何的限制,所以被广泛应运到系统的开发中。MySQL是一个开源和多线程的关系管理数据库系统,MySQL是开放源代码的数据库,具有跨平台性。
B/S(浏览器/服务器)结构是目前主流的网络化的结构模式,它能够把系统核心功能集中在服务器上面,可以帮助系统开发人员简化操作,便于维护和使用。
系统分析
对系统的可行性分析以及对所有功能需求进行详细的分析,来查看该系统是否具有开发的可能。
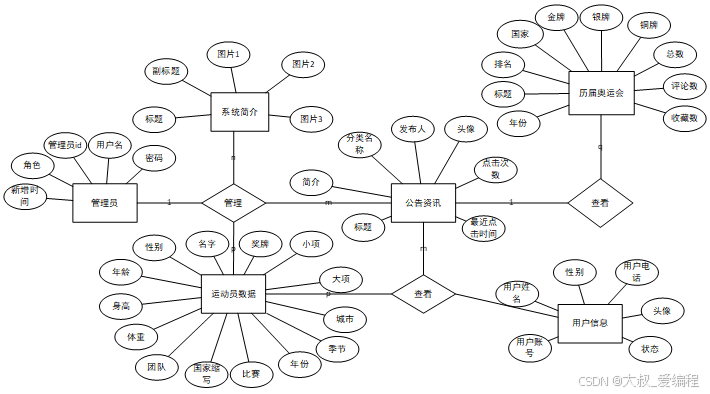
系统设计
功能模块设计和数据库设计这两部分内容都有专门的表格和图片表示。
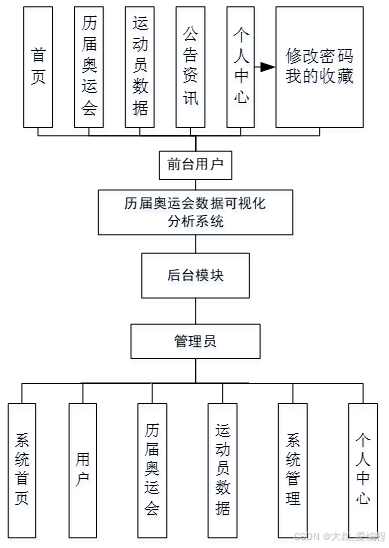
系统实现
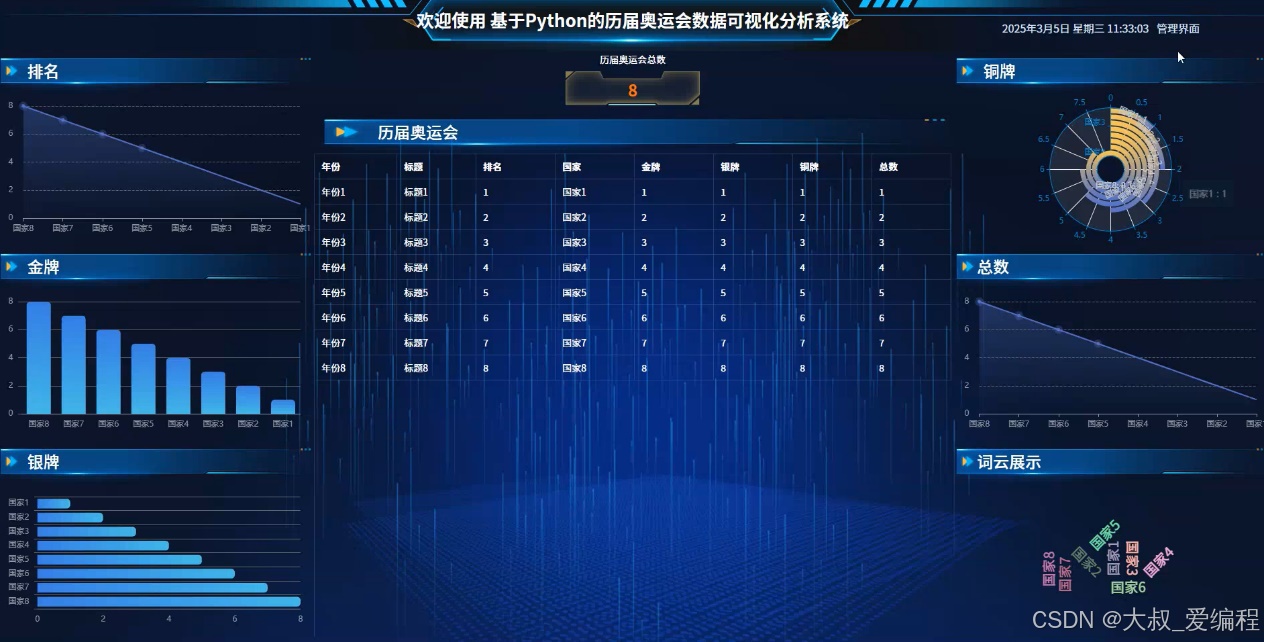
网站首页界面基本设计采用列固定、中间栏、标题、脚注基本布局。每个子模块分别建立一个HTML、CSS网页,各模块功能在HTML、CSS网页下实现。管理员登录进入历届奥运会数据可视化分析系统可以查看用户、历届奥运会、运动员数据、系统信息等功能,进行详细操作。首先,历届奥运会模块通过信息图展示了不同年份的奥运会情况,帮助用户快速了解历届奥运会的总数;其次,金牌模块则采用了柱状图的形式展示出来,再者,银牌模块利用条形图来展示,最后,铜牌模块利用饼图来展示。
代码实现
python
# # -*- coding: utf-8 -*-
# 历届奥运会
class LjaoyunhuiSpider(scrapy.Spider):
name = 'ljaoyunhuiSpider'
spiderUrl = 'https://zhuanlan.zhihu.com/p/714083048'
start_urls = spiderUrl.split(";")
protocol = ''
hostname = ''
realtime = False
def __init__(self,realtime=False,*args, **kwargs):
super().__init__(*args, **kwargs)
self.realtime = realtime=='true'
def start_requests(self):
plat = platform.system().lower()
if not self.realtime and (plat == 'linux' or plat == 'windows'):
connect = self.db_connect()
cursor = connect.cursor()
if self.table_exists(cursor, '31y3eq53_ljaoyunhui') == 1:
cursor.close()
connect.close()
self.temp_data()
return
pageNum = 1 + 1
for url in self.start_urls:
if '{}' in url:
for page in range(1, pageNum):
next_link = url.format(page)
yield scrapy.Request(
url=next_link,
callback=self.parse
)
else:
yield scrapy.Request(
url=url,
callback=self.parse
)
# 列表解析
def parse(self, response):
_url = urlparse(self.spiderUrl)
self.protocol = _url.scheme
self.hostname = _url.netloc
plat = platform.system().lower()
if not self.realtime and (plat == 'linux' or plat == 'windows'):
connect = self.db_connect()
cursor = connect.cursor()
if self.table_exists(cursor, '31y3eq53_ljaoyunhui') == 1:
cursor.close()
connect.close()
self.temp_data()
return
list = response.css('table[data-draft-type="table"] tr')
for item in list:
fields = LjaoyunhuiItem()
if '(.*?)' in '''''':
try:
fields["title"] = str( re.findall(r'''''', item.extract(), re.DOTALL)[0].strip())
except:
pass
else:
try:
fields["title"] = str( self.remove_html(item.css('''''').extract_first()))
except:
pass
if '(.*?)' in '''''':
try:
fields["ranking"] = int( re.findall(r'''''', item.extract(), re.DOTALL)[0].strip())
except:
pass
else:
try:
fields["ranking"] = int( self.remove_html(item.css('').extract_first()))
except:
pass
if '(.*?)' in '''td:nth-child(1)::text''':
try:
fields["guojia"] = str( re.findall(r'''td:nth-child(1)::text''', item.extract(), re.DOTALL)[0].strip())
except:
pass
else:
try:
fields["guojia"] = str( self.remove_html(item.css('''td:nth-child(1)::text''').extract_first()))
except:
pass
if '(.*?)' in '''td:nth-child(2)::text''':
try:
fields["jinpai"] = int( re.findall(r'''td:nth-child(2)::text''', item.extract(), re.DOTALL)[0].strip())
except:
pass
else:
try:
fields["jinpai"] = int( self.remove_html(item.css('td:nth-child(2)::text').extract_first()))
except:
pass
if '(.*?)' in '''td:nth-child(3)::text''':
try:
fields["yinpai"] = int( re.findall(r'''td:nth-child(3)::text''', item.extract(), re.DOTALL)[0].strip())
except:
pass
else:
try:
fields["yinpai"] = int( self.remove_html(item.css('td:nth-child(3)::text').extract_first()))
except:
pass
if '(.*?)' in '''td:nth-child(4)::text''':
try:
fields["tongpai"] = int( re.findall(r'''td:nth-child(4)::text''', item.extract(), re.DOTALL)[0].strip())
except:
pass
else:
try:
fields["tongpai"] = int( self.remove_html(item.css('td:nth-child(4)::text').extract_first()))
except:
pass
if '(.*?)' in '''td:nth-child(5)::text''':
try:
fields["zongshu"] = int( re.findall(r'''td:nth-child(5)::text''', item.extract(), re.DOTALL)[0].strip())
except:
pass
else:
try:
fields["zongshu"] = int( self.remove_html(item.css('td:nth-child(5)::text').extract_first()))
except:
pass
if '(.*?)' in '''''':
try:
fields["nianfen"] = str( re.findall(r'''''', item.extract(), re.DOTALL)[0].strip())
except:
pass
else:
try:
fields["nianfen"] = str( self.remove_html(item.css('''''').extract_first()))
except:
pass
yield fields
# 数据清洗
def pandas_filter(self):
engine = create_engine('mysql+pymysql://root:123456@localhost/spider31y3eq53?charset=UTF8MB4')
df = pd.read_sql('select * from ljaoyunhui limit 50', con = engine)
# 重复数据过滤
df.duplicated()
df.drop_duplicates()
#空数据过滤
df.isnull()
df.dropna()
# 填充空数据
df.fillna(value = '暂无')
# 异常值过滤
# 滤出 大于800 和 小于 100 的
a = np.random.randint(0, 1000, size = 200)
cond = (a<=800) & (a>=100)
a[cond]
# 过滤正态分布的异常值
b = np.random.randn(100000)
# 3σ过滤异常值,σ即是标准差
cond = np.abs(b) > 3 * 1
b[cond]
# 正态分布数据
df2 = pd.DataFrame(data = np.random.randn(10000,3))
# 3σ过滤异常值,σ即是标准差
cond = (df2 > 3*df2.std()).any(axis = 1)
# 不满⾜条件的⾏索引
index = df2[cond].index
# 根据⾏索引,进⾏数据删除
df2.drop(labels=index,axis = 0)
# 去除多余html标签
def remove_html(self, html):
if html == None:
return ''
pattern = re.compile(r'<[^>]+>', re.S)
return pattern.sub('', html).strip()
# 数据库连接
def db_connect(self):
type = self.settings.get('TYPE', 'mysql')
host = self.settings.get('HOST', 'localhost')
port = int(self.settings.get('PORT', 3306))
user = self.settings.get('USER', 'root')
password = self.settings.get('PASSWORD', '123456')
try:
database = self.databaseName
except:
database = self.settings.get('DATABASE', '')
if type == 'mysql':
connect = pymysql.connect(host=host, port=port, db=database, user=user, passwd=password, charset='utf8mb4')
else:
connect = pymssql.connect(host=host, user=user, password=password, database=database)
return connect
# 断表是否存在
def table_exists(self, cursor, table_name):
cursor.execute("show tables;")
tables = [cursor.fetchall()]
table_list = re.findall('(\'.*?\')',str(tables))
table_list = [re.sub("'",'',each) for each in table_list]
if table_name in table_list:
return 1
else:
return 0
# 数据缓存源
def temp_data(self):
connect = self.db_connect()
cursor = connect.cursor()
sql = '''
insert into `ljaoyunhui`(
id
,title
,ranking
,guojia
,jinpai
,yinpai
,tongpai
,zongshu
,nianfen
)
select
id
,title
,ranking
,guojia
,jinpai
,yinpai
,tongpai
,zongshu
,nianfen
from `31y3eq53_ljaoyunhui`
where(not exists (select
id
,title
,ranking
,guojia
,jinpai
,yinpai
,tongpai
,zongshu
,nianfen
from `ljaoyunhui` where
`ljaoyunhui`.id=`31y3eq53_ljaoyunhui`.id
))
order by rand()
limit 50;
'''
cursor.execute(sql)
connect.commit()
connect.close()系统测试
测试任何产品都有两种方法:
黑盒测试:重在测试功能,试图发现功能不正确,界面错误,初始化和终止错误,性能错误,数据结构错误或外部数据库访问错误;
白盒测试:用于测试早期阶段,需要了解产品的内部工作过程,选用不同条件组合、最可能发现某个错误的测试案例进行。
针对本软件功能特性,本次测试采用的是黑盒测试。
结论
根据软件需求以及所有软件测试来看,该软件的功能基本上达到了预期的设计要求。本软件通过排名、历届奥运会、金牌、铜牌、银牌、总数、词云展示给用户提供了一套较为完整的历届奥运会数据可视化分析系统体系,用户用过此软件可以得到更好的智能化体验。软件主要特点分为以下两点:
1.数据库部署在远程VPS服务器上而非本地,以此达到移动端可对其访问的目的。
2.用户级别划分,本软件将用户划分为二个级别:用户和管理员。通过不同用户的级别划分,优化软件的维护和管理。