背景
近来在优化一个图像显示程序,图像数据存储于一个3维数组datax,y,z中,三维数组为一张张图片数据的叠加而来,其中x为图片的张数,y为图片行,Z为图片的列,也就是说这个三维数组存储的为一系列图片的数据集,整个数据集构成了一个现实中的物体(其实就是一个人的某部位CT扫描结果)。
yoz为主视图,xoz为俯视图,xoy为左视图。
在进行数组读取时,发现如果X固定,YZ为变量获取一张图片时(Y从小到大,Z从小到大),整个获取像素的函数运行时间一般为3ms左右;若Y固定,XZ为变量获取俯视图的图处理时,整张图片的获取也差不多在3ms左右;但若Z固定,获取左视图时,则获取整张图片的时间至少为主视图或俯视图的2倍,最大可能为10倍甚至更多。
原因探索------为何Z固定时,获取整张图片的时间会增大?
多维数组的遍历
首先了解一下多维数组的遍历,遍历元素的方式为:首先递增最右边维度的索引,然后是它左边的一个维度,以此类推,向最左的索引遍历元素。
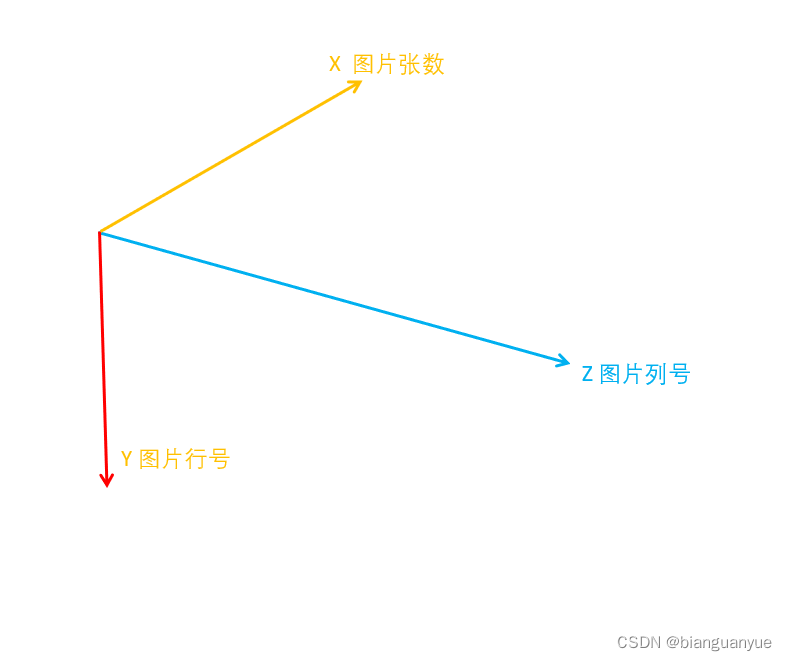
那么对于一个3*3*3的三维数组,X固定获取的获取,就完全是在一个连续的区域获取,如下所示,对于3*3*3的三维数组,X固定3个区域均为连续在一块儿。
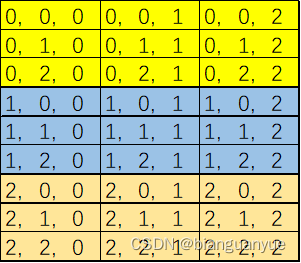
Y固定也是类似,只是相对有些分散,但仍是几个连续的区域,如下所示,Y为0时的黄色区域,Y为1时的白色区域,Y为2时的棕色区域。
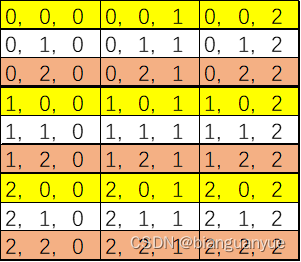
Z固定时,看上去也是连续的区域,读取时间应该不会相差太多,如下图所示:
数组在存储单元中存储
存储单元是一维的结构 ,那么多维数组就需要约定数组的存储次序,C#中数组是以行序为主序(不同语言实现不同)的存储结构,也就是如前面图中3维数组的显示一样以行优先进行存储数据,一行一行将数据存储存储到存储单元。
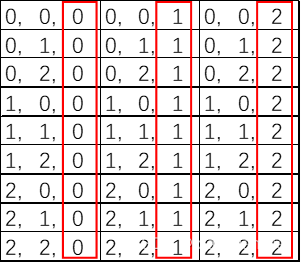
那么数组的读取,读取X为定值的所有值,就只要知道X固定的第一个值位置,然后顺序读取X为定值的整个区间就可以了;Y固定时与此类似,只是区间会变多;而Z固定就完全不一样了,以前述3*3*3的3维数组为例,Z为1时所有数据,都不是连续的,也就是说它相应的存储位置都需要重新去计算,那么它的读取时间肯定就是最长的了。
如何优化?
那么,才能提高3维数组的读取时间呢?了解了产生性能问题的原因,针对此可以用以下方法进行一定的性能提升。
1. 循环展开
关于循环展开的详细解释,可自行查找相应资料,本文不作赘述。
循环展开代码如下:
展开前:
cs
for (int i = 0; i < 4; ++i)
{
var pixelDataindex = y * rowStride + x * 4 + i;
if (i != 3)
PixelData[pixelDataindex] = (byte)HUtoGraysale(ctData16ct[x, y, (int)frameIndex], slope, intercept, imgHeight, imgWidth);
else
PixelData[pixelDataindex] = 255;
}展开后:
cs
var pixelDataindex = y * rowStride + x * 4;
var gray = (byte)HU2Graysale(ctData16ct[x, y, index], slope, intercept, high, low, imgWidth);
UpdatePixelData(PixelData, pixelDataindex, gray);展开后涉及的 UpdatePixelData如下:
cs
private static void UpdatePixelData(byte[] PixelData, int pixelDataindex, byte gray)
{
PixelData[pixelDataindex] = gray;
PixelData[pixelDataindex + 1] = gray;
PixelData[pixelDataindex + 2] = gray;
PixelData[pixelDataindex + 3] = 255;
}通过前后对比测试结果来看,循环展开后的速度比展开前提高了50%。
2. 多线程
在1中对最内层循环进行了循环展开,在最内层循环的外层循环可以将循环的区域拆分为多个,然后每个区域用一个线程来进行相应的计算,最后将整个计算结果返回即可。
此处注意,并不是拆越多用越多的线程越好,一般不要超过CPU的核心数。
3. 减少不必要的操作
如减少循环中的强制转换,装箱拆箱,以及一些可以转到外边的计算。
4. 优化数据结构
如果性能非常敏感,可以考虑针对你需要的那一维数据进行特殊存储。如本文开头提到的datax,y,z,可以将Z存储到x的位置,x存储到Z的位置,那么dataz,y,x的读取速度就会有大的提升。
以上都是在硬件固定的情况下说的,当然,有更好的硬件环境肯定是能提高执行速度的。
参考链接
数组 - C# reference | Microsoft Learn
改几行代码,for循环耗时从3.2秒降到0.3秒!真正看懂的都是牛人!
参考书籍:
数据结构(C语言版)(第2版)------严蔚敏 李冬梅 吴伟民