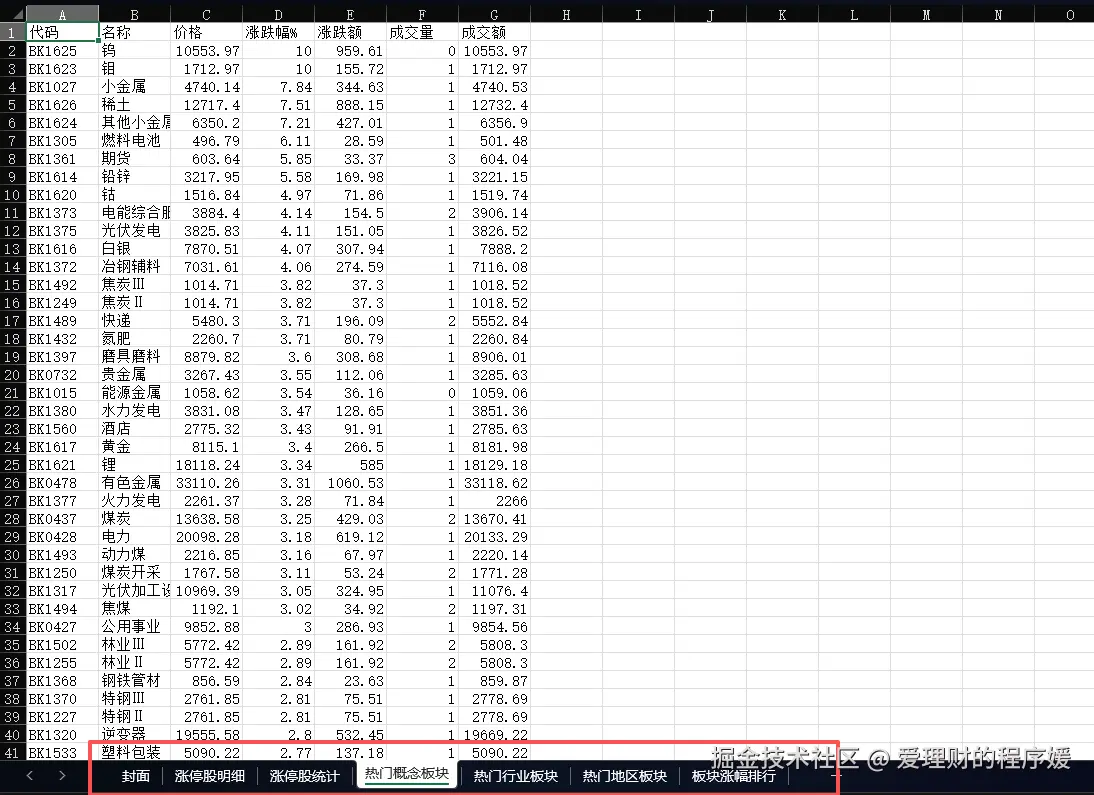
openclaw 盯盘实践
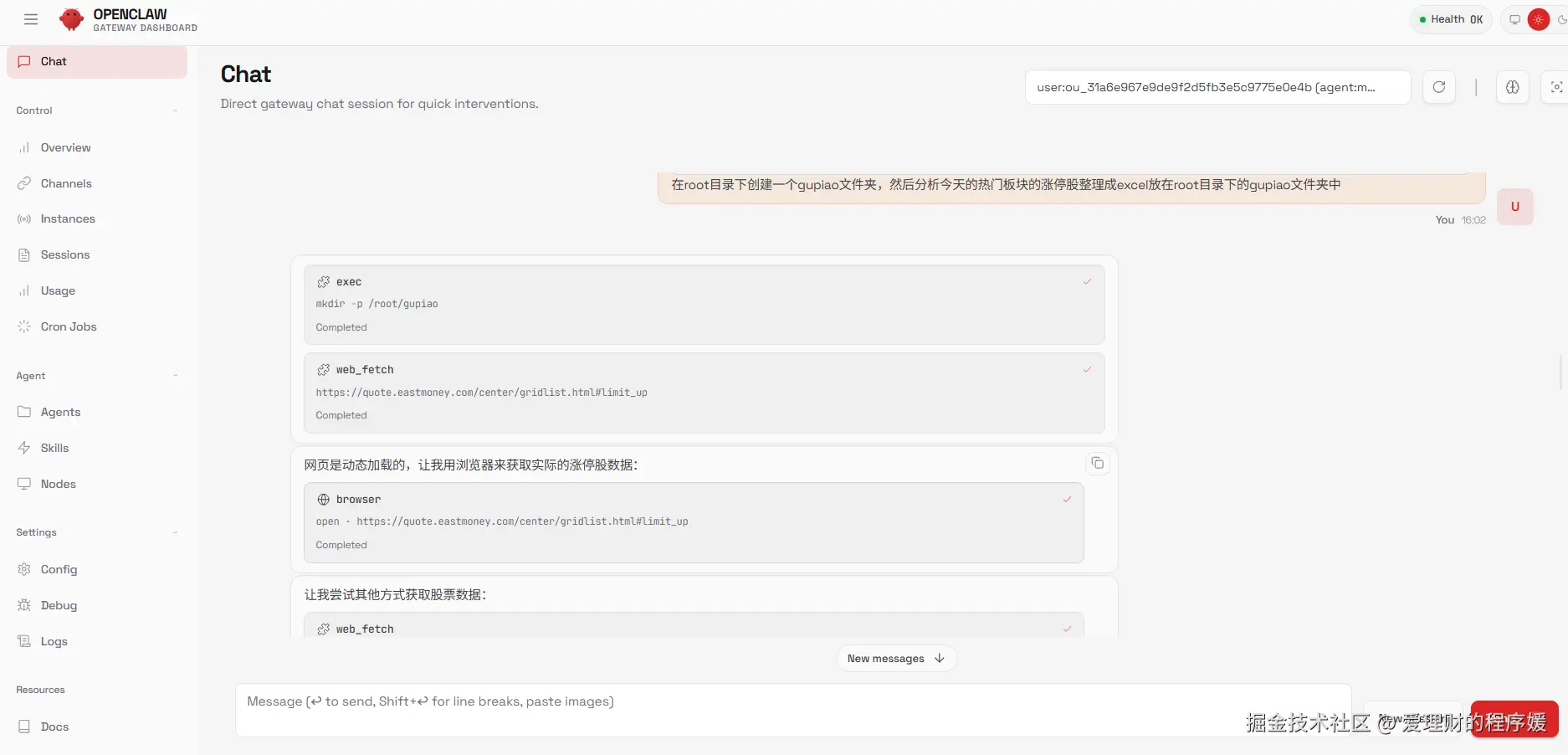
动态生成的脚本(大家可以拿去直接使用)
/root/gupiao/get_limit_up.py
python
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
获取东方财富网涨停股数据并保存为 Excel - 备用版本
"""
import requests
import pandas as pd
from datetime import datetime
import time
def get_limit_up_stocks_v2():
"""获取涨停股数据 - 备用方法"""
# 使用涨停池 API
url = "https://data-interface.eastmoney.com/SEC_Security/GetZTList"
params = {
'callback': 'jQuery',
'type': 'ZT',
'page': '1',
'pageSize': '100',
'field': 'SECURITY_CODE,SECURITY_NAME,NEW_PRICE,CHANGE_RATE,CHANGE_AMOUNT,VOLUME,DEAL_AMOUNT',
'_': int(datetime.now().timestamp() * 1000)
}
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36',
'Referer': 'https://data.eastmoney.com/stock/ztpool/SH.html'
}
try:
response = requests.get(url, params=params, headers=headers, timeout=15)
response.raise_for_status()
text = response.text
# 解析 JSONP
if text.startswith('jQuery'):
text = text[6:] # 去掉 'jQuery'
if text.startswith('(') and text.endswith(')'):
text = text[1:-1] # 去掉括号
import json
data = json.loads(text)
if data.get('data'):
return data['data']
return []
except Exception as e:
print(f"备用 API 失败:{e}")
return []
def get_limit_up_stocks_v3():
"""获取涨停股数据 - 直接获取 HTML 并解析"""
url = "https://quote.eastmoney.com/center/gridlist.html"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36',
}
try:
# 获取涨停股列表 API
api_url = "https://push2.eastmoney.com/api/qt/clist/get"
params = {
'pn': '1',
'pz': '100',
'po': '1',
'np': '1',
'ut': 'bd1d9ddb04089700cf9c27f6f7426281',
'fltt': '2',
'invt': '2',
'fid': 'f3',
'fs': 'm:0+t:6,m:0+t:80,m:1+t:2',
'fields': 'f12,f14,f2,f3,f4,f10,f15,f16,f17,f18,f20,f21,f22,f23,f24,f25,f26',
'_': str(int(datetime.now().timestamp() * 1000))
}
response = requests.get(api_url, params=params, headers=headers, timeout=15)
response.raise_for_status()
data = response.json()
if data.get('data') and data['data'].get('diff'):
return data['data']['diff']
return []
except Exception as e:
print(f"API v3 失败:{e}")
return []
def get_hot_sectors():
"""获取热门板块数据"""
# 概念板块
url = "https://push2.eastmoney.com/api/qt/clist/get"
params = {
'pn': '1',
'pz': '100',
'po': '1',
'np': '1',
'ut': 'bd1d9ddb04089700cf9c27f6f7426281',
'fltt': '2',
'invt': '2',
'fid': 'f3',
'fs': 'm:90+t:2', # 概念板块
'fields': 'f12,f14,f2,f3,f4,f10,f15,f16,f17,f18,f20,f21,f22',
'_': str(int(datetime.now().timestamp() * 1000))
}
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36',
}
try:
response = requests.get(url, params=params, headers=headers, timeout=15)
response.raise_for_status()
data = response.json()
if data.get('data') and data['data'].get('diff'):
return data['data']['diff']
return []
except Exception as e:
print(f"获取板块失败:{e}")
return []
def get_industry_sectors():
"""获取行业板块数据"""
url = "https://push2.eastmoney.com/api/qt/clist/get"
params = {
'pn': '1',
'pz': '100',
'po': '1',
'np': '1',
'ut': 'bd1d9ddb04089700cf9c27f6f7426281',
'fltt': '2',
'invt': '2',
'fid': 'f3',
'fs': 'm:90+t:1', # 行业板块
'fields': 'f12,f14,f2,f3,f4,f10,f15',
'_': str(int(datetime.now().timestamp() * 1000))
}
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36',
}
try:
response = requests.get(url, params=params, headers=headers, timeout=15)
response.raise_for_status()
data = response.json()
if data.get('data') and data['data'].get('diff'):
return data['data']['diff']
return []
except Exception as e:
print(f"获取行业板块失败:{e}")
return []
def create_excel(stocks, concept_sectors, industry_sectors, filename):
"""创建 Excel 文件"""
# 准备股票数据 - 筛选涨停股(涨跌幅 >= 9.5%)
stock_data = []
for stock in stocks:
change_rate = float(stock.get('f3', 0) or 0)
if change_rate >= 9.5:
stock_data.append({
'股票代码': stock.get('f12', ''),
'股票名称': stock.get('f14', ''),
'最新价': float(stock.get('f2', 0) or 0),
'涨跌幅%': change_rate,
'涨跌额': float(stock.get('f4', 0) or 0),
'成交量': int(stock.get('f10', 0) or 0),
'成交额': float(stock.get('f15', 0) or 0),
'振幅%': float(stock.get('f16', 0) or 0),
'最高价': float(stock.get('f17', 0) or 0),
'最低价': float(stock.get('f18', 0) or 0),
'总市值': float(stock.get('f20', 0) or 0),
'流通市值': float(stock.get('f21', 0) or 0),
})
# 准备概念板块数据
concept_data = []
for sector in concept_sectors:
change_rate = float(sector.get('f3', 0) or 0)
if change_rate > 0:
concept_data.append({
'板块代码': sector.get('f12', ''),
'板块名称': sector.get('f14', ''),
'最新价': float(sector.get('f2', 0) or 0),
'涨跌幅%': change_rate,
'涨跌额': float(sector.get('f4', 0) or 0),
'成交量': int(sector.get('f10', 0) or 0),
'成交额': float(sector.get('f15', 0) or 0),
})
# 准备行业板块数据
industry_data = []
for sector in industry_sectors:
change_rate = float(sector.get('f3', 0) or 0)
if change_rate > 0:
industry_data.append({
'板块代码': sector.get('f12', ''),
'板块名称': sector.get('f14', ''),
'最新价': float(sector.get('f2', 0) or 0),
'涨跌幅%': change_rate,
'涨跌额': float(sector.get('f4', 0) or 0),
'成交量': int(sector.get('f10', 0) or 0),
'成交额': float(sector.get('f15', 0) or 0),
})
# 排序
stock_data.sort(key=lambda x: x['涨跌幅%'], reverse=True)
concept_data.sort(key=lambda x: x['涨跌幅%'], reverse=True)
industry_data.sort(key=lambda x: x['涨跌幅%'], reverse=True)
# 创建 Excel
with pd.ExcelWriter(filename, engine='openpyxl') as writer:
# 涨停股数据
if stock_data:
df_stocks = pd.DataFrame(stock_data)
df_stocks.to_excel(writer, sheet_name='涨停股', index=False)
else:
# 创建空 sheet
pd.DataFrame({'提示': ['今日暂无涨停股数据']}).to_excel(writer, sheet_name='涨停股', index=False)
# 概念板块
if concept_data:
df_concept = pd.DataFrame(concept_data[:50])
df_concept.to_excel(writer, sheet_name='热门概念板块', index=False)
# 行业板块
if industry_data:
df_industry = pd.DataFrame(industry_data[:50])
df_industry.to_excel(writer, sheet_name='热门行业板块', index=False)
return len(stock_data), len(concept_data), len(industry_data)
def main():
print("=" * 50)
print("股票涨停数据分析工具")
print("=" * 50)
# 获取股票数据 - 尝试多次
print("\n正在获取股票数据...")
stocks = []
for i in range(3):
if i > 0:
print(f"重试第 {i} 次...")
time.sleep(2)
stocks = get_limit_up_stocks_v3()
if stocks:
print(f"成功获取 {len(stocks)} 只股票数据")
break
if not stocks:
print("警告:无法获取股票数据,将只生成板块数据")
# 获取概念板块
print("\n正在获取概念板块数据...")
concept_sectors = get_hot_sectors()
print(f"成功获取 {len(concept_sectors)} 个概念板块")
# 获取行业板块
print("\n正在获取行业板块数据...")
industry_sectors = get_industry_sectors()
print(f"成功获取 {len(industry_sectors)} 个行业板块")
# 生成文件名
today = datetime.now().strftime('%Y%m%d')
filename = f'/root/gupiao/{today}_涨停股分析.xlsx'
print(f"\n正在生成 Excel 文件:{filename}")
stock_count, concept_count, industry_count = create_excel(
stocks, concept_sectors, industry_sectors, filename
)
print("\n" + "=" * 50)
print("完成!")
print(f" - 涨停股:{stock_count} 只")
print(f" - 热门概念板块:{concept_count} 个")
print(f" - 热门行业板块:{industry_count} 个")
print(f"\n文件已保存至:{filename}")
print("=" * 50)
if __name__ == '__main__':
main()/root/gupiao/get_sectors.py
python
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
获取热门板块数据
"""
import requests
import pandas as pd
from datetime import datetime
import time
def get_sectors_with_retry(url_params, max_retries=5):
"""获取板块数据,带重试机制"""
url = "https://push2.eastmoney.com/api/qt/clist/get"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36',
'Accept': '*/*',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
'Referer': 'https://quote.eastmoney.com/',
}
for i in range(max_retries):
try:
if i > 0:
print(f" 重试第 {i+1} 次...")
time.sleep(3)
response = requests.get(url, params=url_params, headers=headers, timeout=20)
response.raise_for_status()
data = response.json()
if data.get('data') and data['data'].get('diff'):
return data['data']['diff']
return []
except Exception as e:
print(f" 尝试失败:{e}")
continue
return []
def get_concept_sectors():
"""获取概念板块"""
print("获取概念板块...")
params = {
'pn': '1',
'pz': '100',
'po': '1',
'np': '1',
'ut': 'bd1d9ddb04089700cf9c27f6f7426281',
'fltt': '2',
'invt': '2',
'fid': 'f3',
'fs': 'm:90+t:2',
'fields': 'f12,f14,f2,f3,f4,f10,f15',
'_': str(int(datetime.now().timestamp() * 1000))
}
return get_sectors_with_retry(params)
def get_industry_sectors():
"""获取行业板块"""
print("获取行业板块...")
params = {
'pn': '1',
'pz': '100',
'po': '1',
'np': '1',
'ut': 'bd1d9ddb04089700cf9c27f6f7426281',
'fltt': '2',
'invt': '2',
'fid': 'f3',
'fs': 'm:90+t:1',
'fields': 'f12,f14,f2,f3,f4,f10,f15',
'_': str(int(datetime.now().timestamp() * 1000))
}
return get_sectors_with_retry(params)
def get_region_sectors():
"""获取地区板块"""
print("获取地区板块...")
params = {
'pn': '1',
'pz': '100',
'po': '1',
'np': '1',
'ut': 'bd1d9ddb04089700cf9c27f6f7426281',
'fltt': '2',
'invt': '2',
'fid': 'f3',
'fs': 'm:90+t:3',
'fields': 'f12,f14,f2,f3,f4,f10,f15',
'_': str(int(datetime.now().timestamp() * 1000))
}
return get_sectors_with_retry(params)
def main():
print("=" * 50)
print("获取板块数据")
print("=" * 50)
concept = get_concept_sectors()
print(f"概念板块:{len(concept)} 个")
industry = get_industry_sectors()
print(f"行业板块:{len(industry)} 个")
region = get_region_sectors()
print(f"地区板块:{len(region)} 个")
# 保存到 Excel
today = datetime.now().strftime('%Y%m%d')
filename = f'/root/gupiao/{today}_板块数据.xlsx'
with pd.ExcelWriter(filename, engine='openpyxl') as writer:
if concept:
df = pd.DataFrame([{
'代码': s.get('f12', ''),
'名称': s.get('f14', ''),
'价格': float(s.get('f2', 0) or 0),
'涨跌幅%': float(s.get('f3', 0) or 0),
'涨跌额': float(s.get('f4', 0) or 0),
'成交量': int(s.get('f10', 0) or 0),
'成交额': float(s.get('f15', 0) or 0),
} for s in concept])
df = df.sort_values('涨跌幅%', ascending=False)
df.to_excel(writer, sheet_name='概念板块', index=False)
if industry:
df = pd.DataFrame([{
'代码': s.get('f12', ''),
'名称': s.get('f14', ''),
'价格': float(s.get('f2', 0) or 0),
'涨跌幅%': float(s.get('f3', 0) or 0),
'涨跌额': float(s.get('f4', 0) or 0),
'成交量': int(s.get('f10', 0) or 0),
'成交额': float(s.get('f15', 0) or 0),
} for s in industry])
df = df.sort_values('涨跌幅%', ascending=False)
df.to_excel(writer, sheet_name='行业板块', index=False)
if region:
df = pd.DataFrame([{
'代码': s.get('f12', ''),
'名称': s.get('f14', ''),
'价格': float(s.get('f2', 0) or 0),
'涨跌幅%': float(s.get('f3', 0) or 0),
'涨跌额': float(s.get('f4', 0) or 0),
'成交量': int(s.get('f10', 0) or 0),
'成交额': float(s.get('f15', 0) or 0),
} for s in region])
df = df.sort_values('涨跌幅%', ascending=False)
df.to_excel(writer, sheet_name='地区板块', index=False)
print(f"\n板块数据已保存至:{filename}")
if __name__ == '__main__':
main()/root/gupiao/merge_report.py
python
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
合并涨停股和板块数据为完整分析报告
"""
import pandas as pd
from datetime import datetime
def main():
today = datetime.now().strftime('%Y%m%d')
today_cn = datetime.now().strftime('%Y年%m月%d日')
# 读取数据
limit_up_file = f'/root/gupiao/{today}_涨停股分析.xlsx'
sectors_file = f'/root/gupiao/{today}_板块数据.xlsx'
output_file = f'/root/gupiao/{today}_股票涨停分析报告.xlsx'
print(f"正在生成 {today_cn} 股票涨停分析报告...")
with pd.ExcelWriter(output_file, engine='openpyxl') as writer:
# 1. 封面页
cover_data = {
'项目': ['报告日期', '涨停股数量', '概念板块数量', '行业板块数量', '地区板块数量'],
'数值': [today_cn, '', '', '', '']
}
pd.DataFrame(cover_data).to_excel(writer, sheet_name='封面', index=False)
# 2. 读取涨停股数据
try:
df_limit = pd.read_excel(limit_up_file, sheet_name='涨停股')
if '提示' not in df_limit.columns:
# 按涨跌幅排序
df_limit = df_limit.sort_values('涨跌幅%', ascending=False)
df_limit.to_excel(writer, sheet_name='涨停股明细', index=False)
print(f" ✓ 涨停股:{len(df_limit)} 只")
# 涨停股统计
summary_data = []
if '股票代码' in df_limit.columns:
# 按股票代码前缀统计(00=深市主板,30=创业板,60=沪市主板,68=科创板)
for prefix, name in [('00', '深市主板'), ('30', '创业板'), ('60', '沪市主板'), ('68', '科创板')]:
count = len(df_limit[df_limit['股票代码'].astype(str).str.startswith(prefix)])
if count > 0:
summary_data.append({'板块': name, '涨停数量': count})
if summary_data:
pd.DataFrame(summary_data).to_excel(writer, sheet_name='涨停股统计', index=False)
except Exception as e:
print(f" ✗ 读取涨停股数据失败:{e}")
# 3. 读取板块数据
try:
# 概念板块
df_concept = pd.read_excel(sectors_file, sheet_name='概念板块')
df_concept = df_concept.sort_values('涨跌幅%', ascending=False)
df_concept_top50 = df_concept.head(50)
df_concept_top50.to_excel(writer, sheet_name='热门概念板块', index=False)
print(f" ✓ 概念板块:{len(df_concept)} 个")
# 行业板块
df_industry = pd.read_excel(sectors_file, sheet_name='行业板块')
df_industry = df_industry.sort_values('涨跌幅%', ascending=False)
df_industry.to_excel(writer, sheet_name='热门行业板块', index=False)
print(f" ✓ 行业板块:{len(df_industry)} 个")
# 地区板块
df_region = pd.read_excel(sectors_file, sheet_name='地区板块')
df_region = df_region.sort_values('涨跌幅%', ascending=False)
df_region.to_excel(writer, sheet_name='热门地区板块', index=False)
print(f" ✓ 地区板块:{len(df_region)} 个")
# 板块涨幅前十
top_concept = df_concept.head(10)[['名称', '涨跌幅%']].copy()
top_concept.columns = ['概念板块', '涨跌幅%']
top_concept['类型'] = '概念'
top_industry = df_industry.head(10)[['名称', '涨跌幅%']].copy()
top_industry.columns = ['板块', '涨跌幅%']
top_industry['类型'] = '行业'
# 合并展示
top_all = pd.concat([
df_concept.head(10)[['名称', '涨跌幅%']].assign(类型='概念'),
df_industry.head(10)[['名称', '涨跌幅%']].assign(类型='行业')
], ignore_index=True)
top_all = top_all.sort_values('涨跌幅%', ascending=False).head(20)
top_all.columns = ['板块名称', '涨跌幅%', '类型']
top_all.to_excel(writer, sheet_name='板块涨幅排行', index=False)
except Exception as e:
print(f" ✗ 读取板块数据失败:{e}")
print(f"\n{'='*50}")
print(f"报告生成完成!")
print(f"文件:{output_file}")
print(f"{'='*50}")
if __name__ == '__main__':
main()运行结果
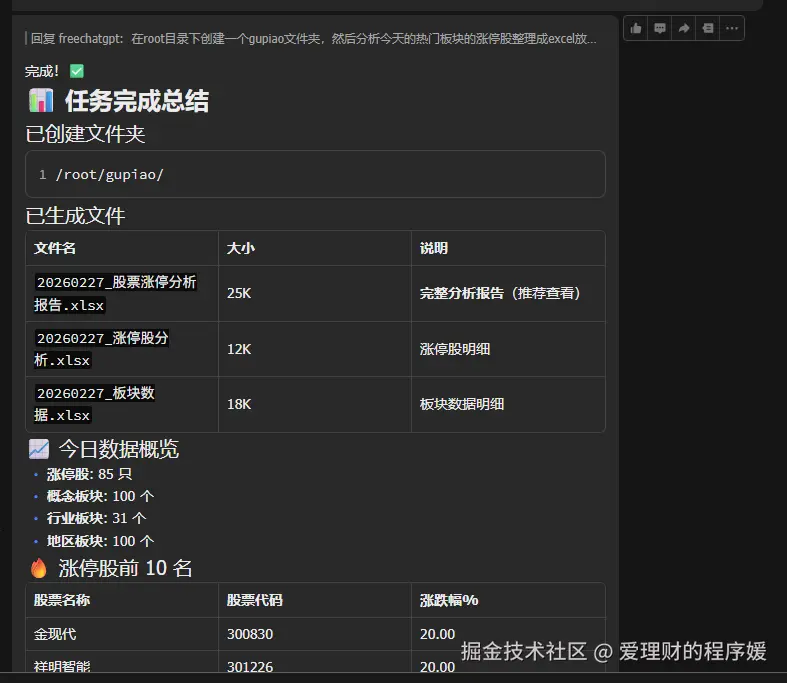
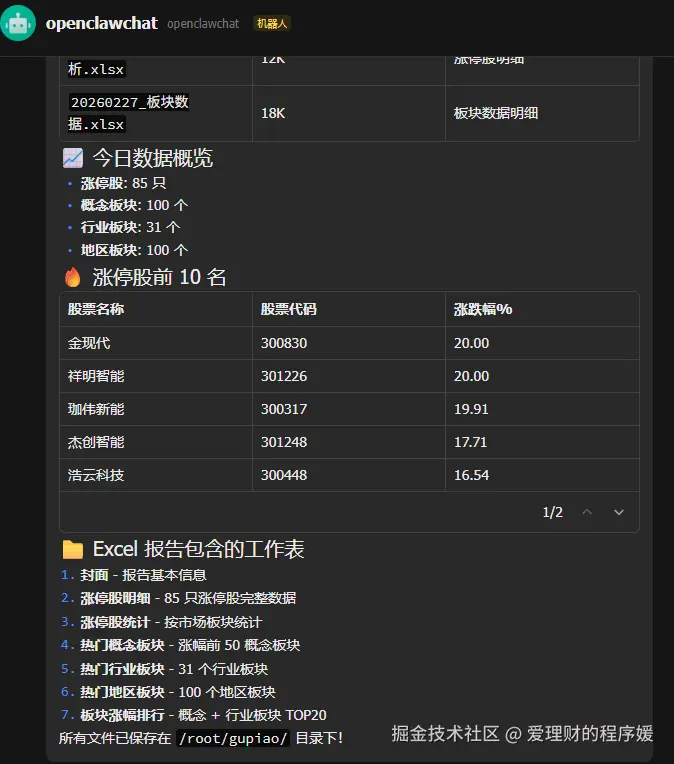
下载后查看效果