我们学习数据库, 最重要的就是要学会对数据表表进行**"增删查改"** (CRUD).(C -- create, R -- retrieve, U -- update, D -- delete)
目录
[一. "增"(create)](#一. "增"(create))
[1. 普通新增](#1. 普通新增)
[2. 指定列新增](#2. 指定列新增)
[3. 一次插入多行](#3. 一次插入多行)
[4. 用insert插入时间](#4. 用insert插入时间)
[5. 小结](#5. 小结)
[二. "查"(retrieve)](#二. "查"(retrieve))
[1. 全列查询](#1. 全列查询)
[2. 指定列查询](#2. 指定列查询)
[3. 查询时指定表达式](#3. 查询时指定表达式)
[4. 去重查询](#4. 去重查询)
[5. 排序查询](#5. 排序查询)
[6. 条件查询(查询中最关键的操作)](#6. 条件查询(查询中最关键的操作))
[7. 分页查询](#7. 分页查询)
[8. 小结](#8. 小结)
[三. "改"(update)](#三. "改"(update))
[四. "删"(delete)](#四. "删"(delete))
一. "增"(create)
MySQL中, 新增元素的基本语法如下:
1. 普通新增
insert into 表名 values (值, 值, 值 ......);
例如:
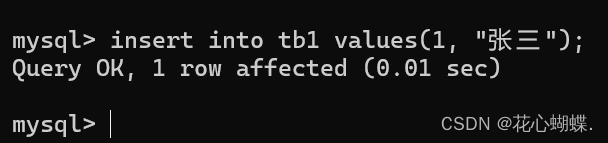
注: MySQL中, 表示++字符串++ 使用++单引号或者双引号都可以++.
注意:
(1) 这里值的个数和类型, 要和表结构相匹配.
 如上图, 列数和值的个数不匹配.
如上图, 列数和值的个数不匹配.
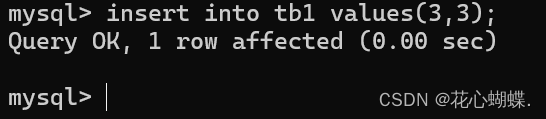
如上图, 明明第二列插入的int类型和表中定义的varchar类型不匹配, 为什么还能插入成功呢? 这里我们就不得不提到SQL语言的"弱类型"特性.
++SQL(结构化查询语言)通常被认为是一种"弱类型"或"动态类型"的语言++. SQL可以在查询执行时自动进行数据类型转换. 例如在这里SQL就自动把int类型的3转换成了字符串类型. 但SQL并非在任何情况下都能将数据类型自动转换.

例如在这里SQL就无法将字符串类型的"李四"转换成int类型, 此时程序就会报错.
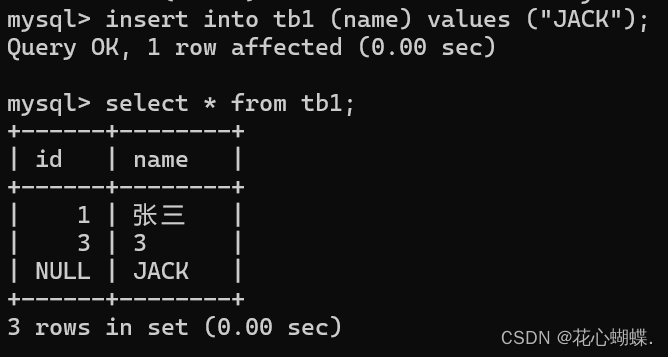
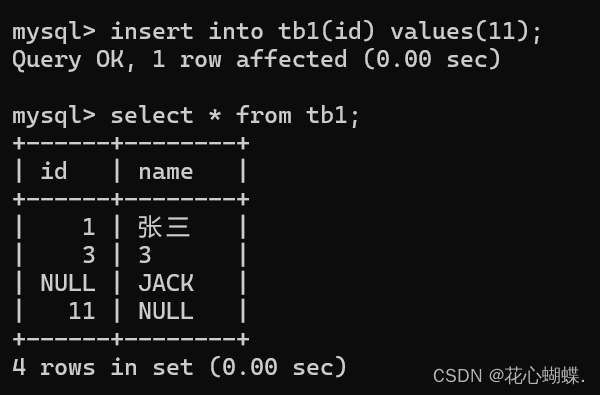
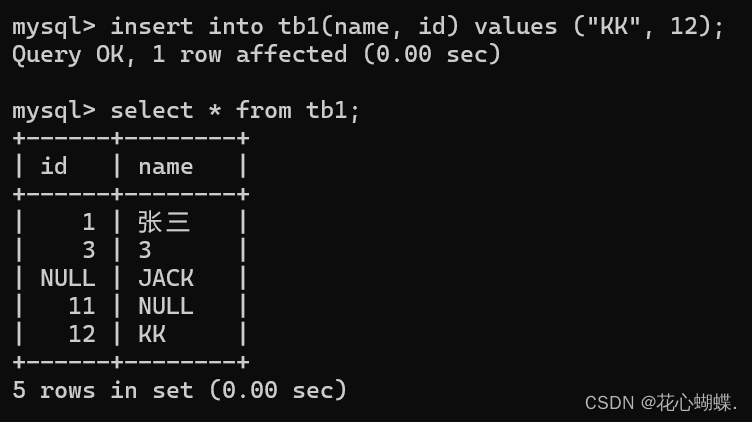
2. 指定列新增
insert into 表名(列名, 列名 ......) values(值, 值 ......);
(注意: 插入值的 个数, 类型, 顺序 要和前面指定的列名匹配).
3. 一次插入多行
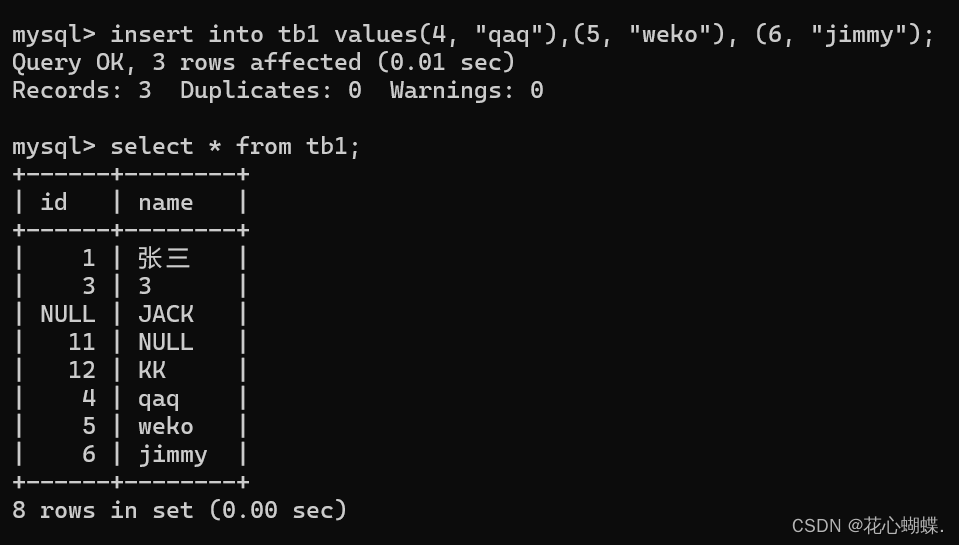
insert into 表名 values(值, 值 ...), (值, 值 ...), (值, 值 ...) ...;
++每个括号表示一行++.
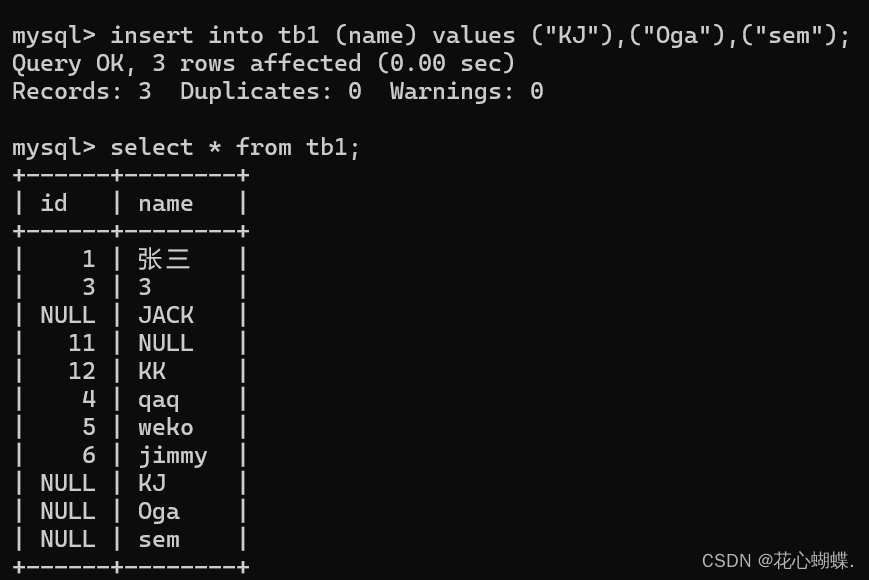
还可以和"指定列新增"配合使用.
例如:
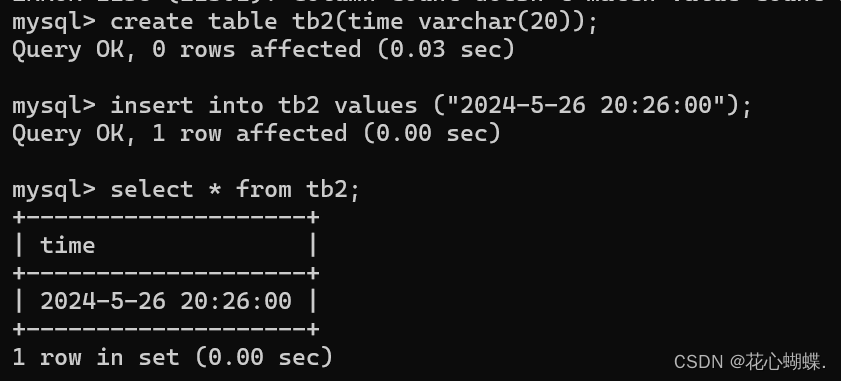
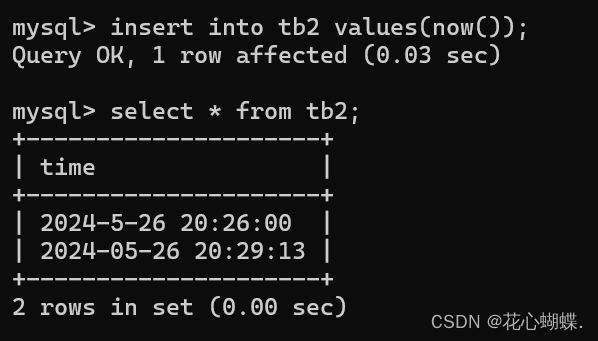
4. 用insert插入时间
以++字符串的形式++插入时间.
可以使用**now()**来插入当前时间. (注: now()获取的时间是字符串类型的).
5. 小结
(1) 普通新增: insert into 表名 values(值, 值, 值 ......);
(2) 指定列新增: insert into 表名(列名, 列名 ......) values(值, 值 ......);
(3) 一次插入多行: insert into 表名 values(值, 值 ...), (值, 值 ...), (值, 值 ...) ...;
(4) 用 insert 插入时间: 以字符串的形式插入时间, 获取当前时间使用now()
二. "查"(retrieve)
SQL中, "增删改"都很简单, "查"比较复杂. 本篇博客我们先介绍简单的"查"操作.
MySQL中, 新增元素的基本语法如下:
1. 全列查询
即查询出指定表的所有行和所有列.
select * from 表名;
(注意: *是通配符. 在这里, *代指所有列)
注意: ++select* 是一个非常危险的操作++ . 因为一旦表的规模非常大, 此时进行select*操作, 就会产生大量的硬盘io和网络io, ++很可能会把硬盘/网卡的带宽"吃满", 造成"拥堵"++. 使得其他客户端在尝试访问数据库时, 访问操作就无法正常进行了.
2. 指定列查询
查询的时候, 手动指定列名, 查询出来的结果就是指定的列.
select 列名, 列名 from 表名;
3. 查询时指定表达式
select 表达式(as 别名) from 表名;
这里的表达式: 可以是++针对某个列的加减乘除, 也可以是针对多个列的加减乘除.++
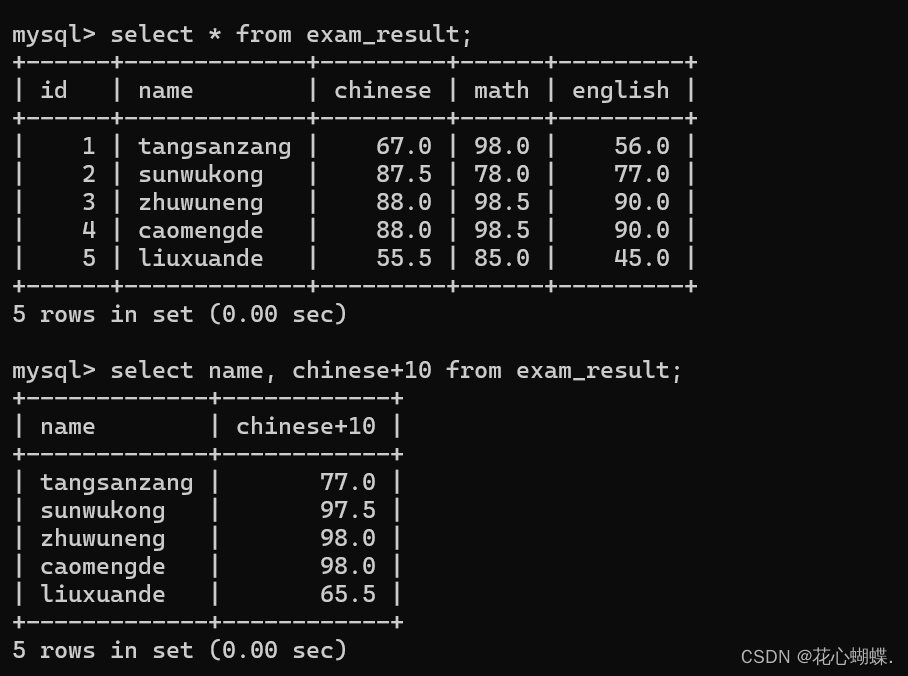
例如: 我们想把成绩表每个学生的语文成绩加10分后查询:
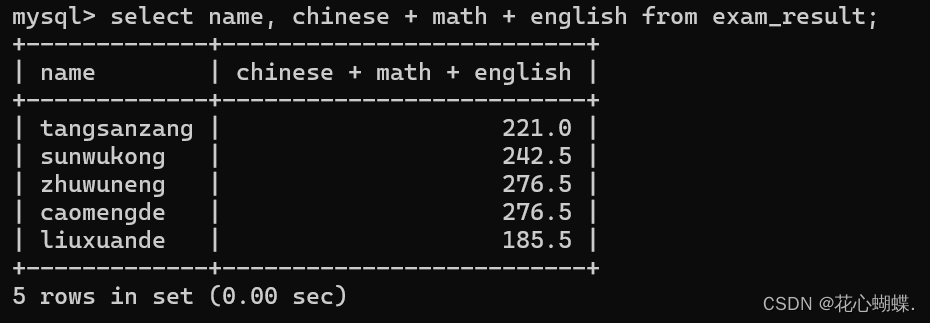
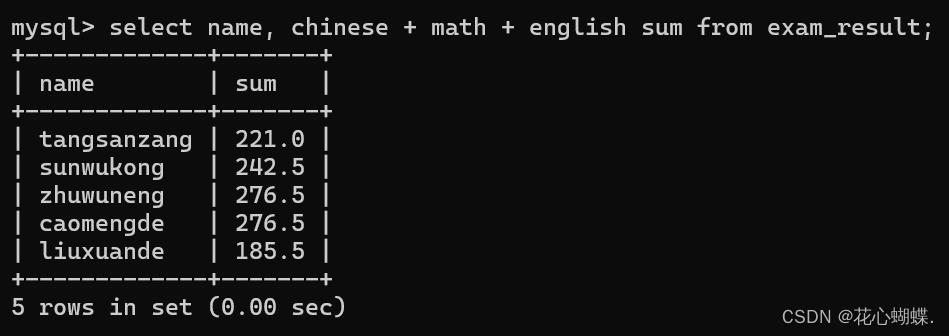
把每个学生的总分查询出来:
注意: 这里可以给chinese,math,english的和取一个别名sum.需要使用到"as".如下:
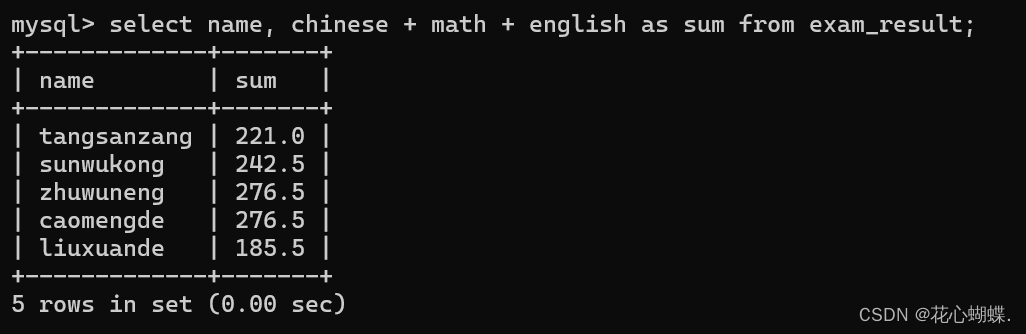 也可以省略as,但是我们并不建议这样做, 因为这样很容易造成SQL语句表达含义不清晰.
也可以省略as,但是我们并不建议这样做, 因为这样很容易造成SQL语句表达含义不清晰.
注意 : 查询操作(select)生成的表只是"临时表". 数据库本体(数据库服务器硬盘上的数据)不会发生任何改变.
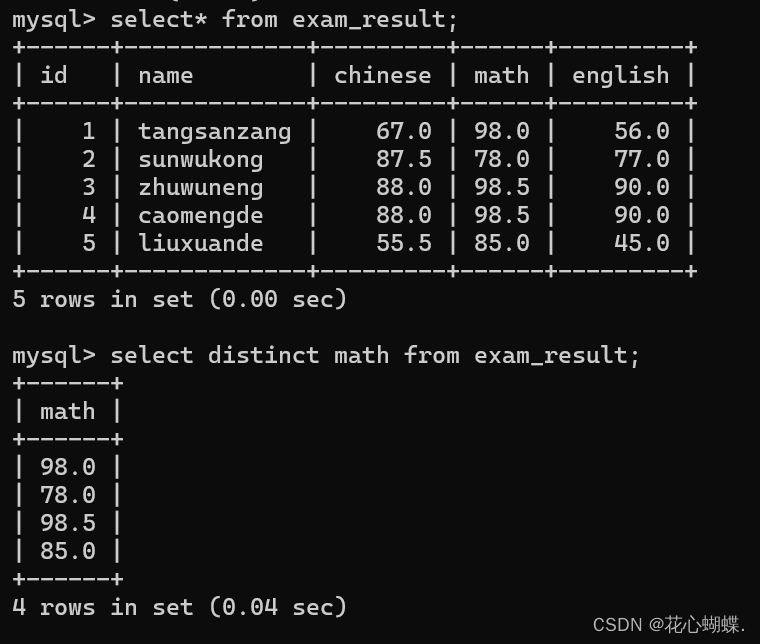
4. 去重查询
去重的含义: 多个行的数据, 如果出现相同的, 就会只保留一份.
select distinct 列名 from 表名;
5. 排序查询
针对查询结果进行排序
... order by 列名;
注意: 如果排序中出现null, null会被视为最小值.
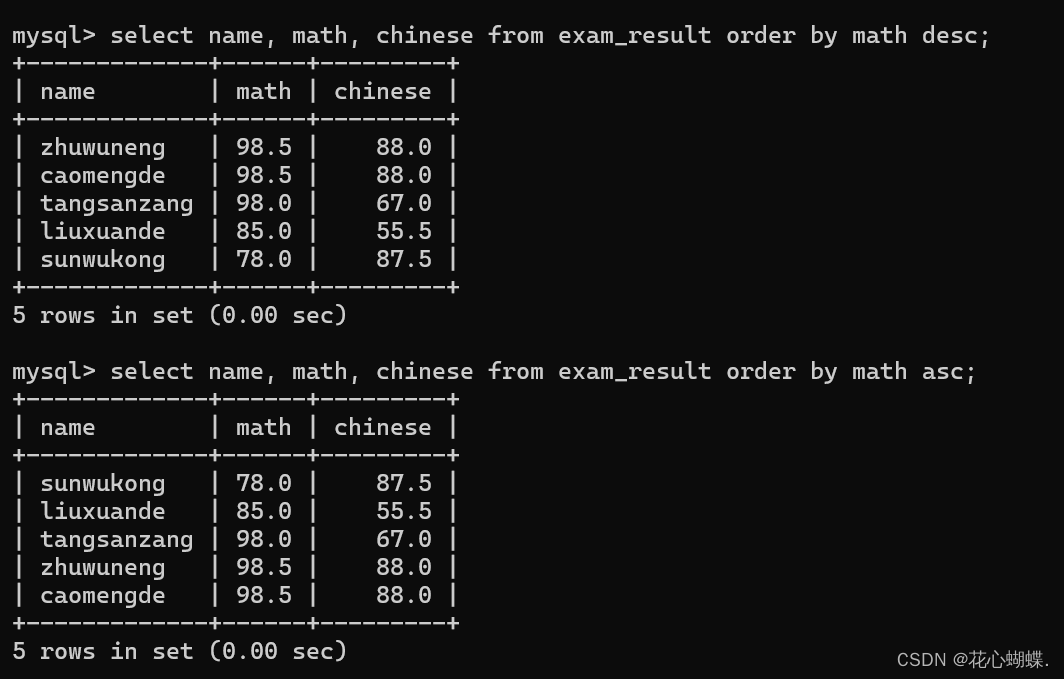
例如: 用数学成绩来排序
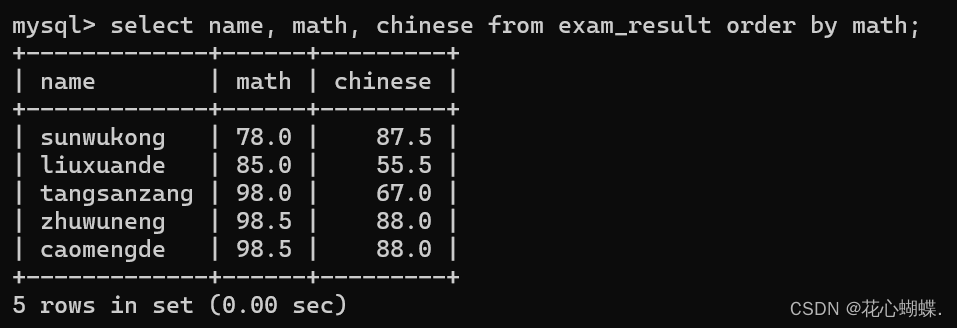
(默认是升序排列) 当然升序还是降序也可以手动指定. (asc -- 升序, desc -- 降序). (这里的asc是ascend的缩写, desc是descend的缩写).
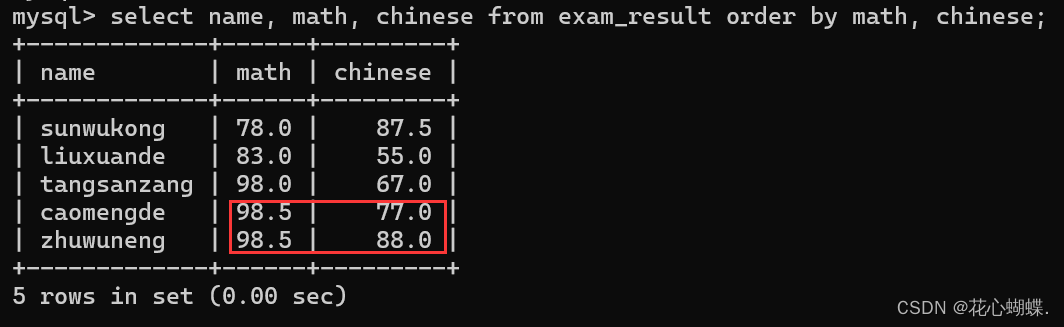
也可以指定多个列排序, 排序规则为: ++先使用第一列来排列, 如果第一列元素相同, 则使用第二列, 如果前两列都相同, 则使用第三列 ......++
... order by 列名, 列名, 列名 ......
6. 条件查询(查询中最关键的操作)
查询过程中: 一行一行地遍历表, 根据筛选条件, 把每一行的数据代入到条件中, 满足就保留并显示, 不满足就跳过.
select 列名 from 表名 where 条件;
条件运算符:
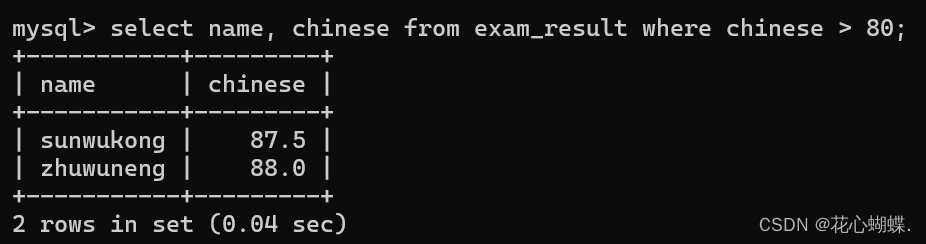
>, >=, <, <= : 大于,大于等于, 小于,小于等于
= : 等于, 不支持null的比较 (例如: null = null 的结果为 null)
<=> : 等于, 支持null的比较 (例如: null <=> null 的结果为 true)
(注意: 只要有null参加的运算,结果都是null)
!= : 不等于
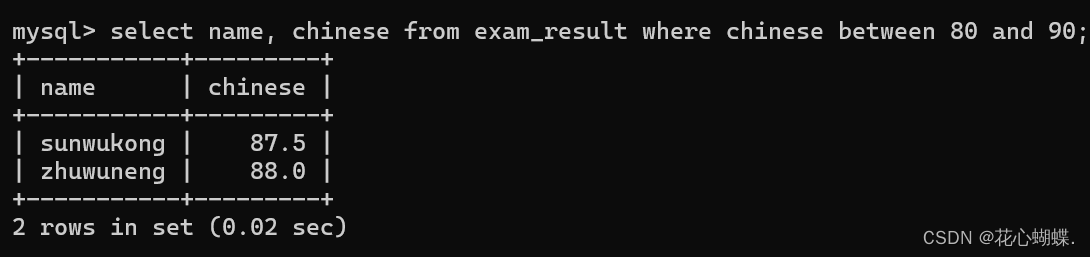
between a and b: 范围匹配, 闭区间a, b. 如果value值在a, b范围内, 就返回true.
例如:
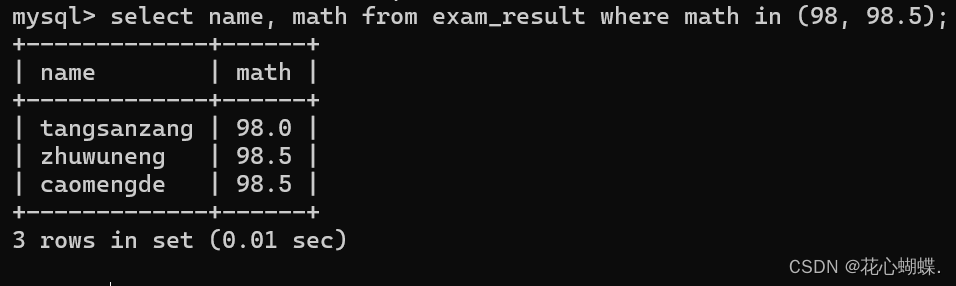
in (option1, option2 ......) : 如果是几个option中的任意一个, 则返回true.
例如:
is null : 是null
is not null : 不是null
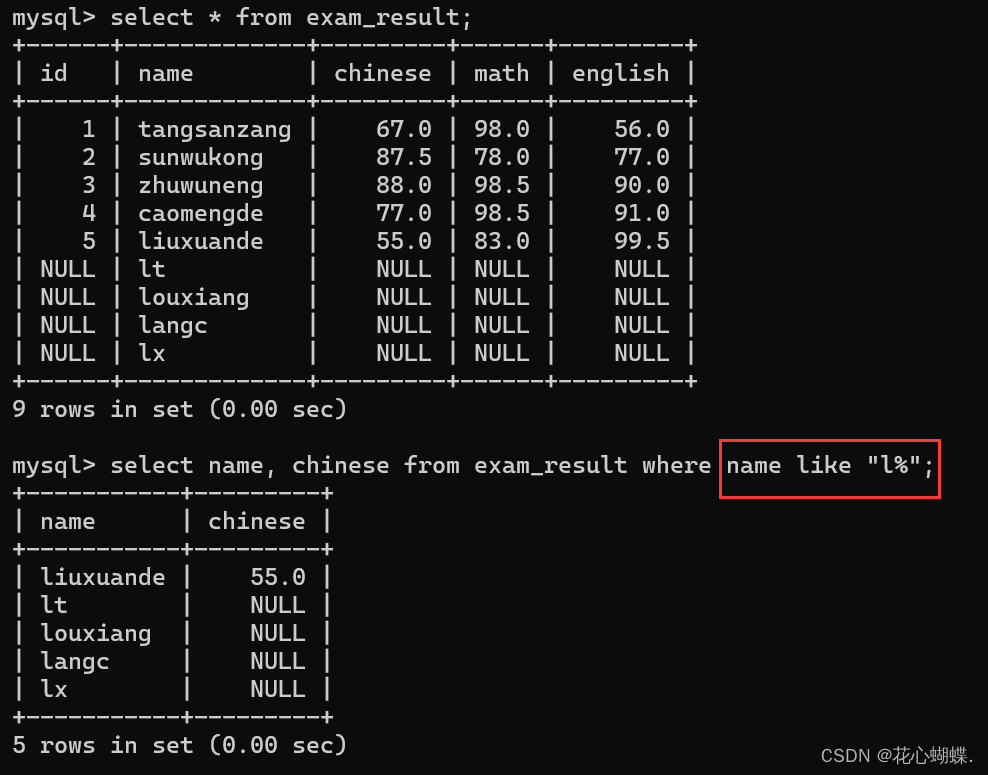
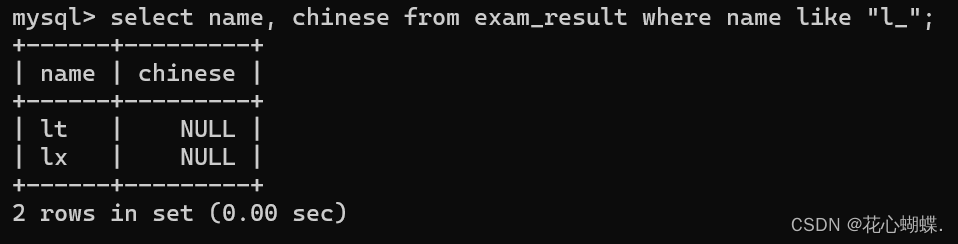
like : 模糊匹配 (即: 不要求完全相等, 满足一些条件可以了) 此外还需要搭配通配符来使用.
(%匹配0个或任意个字符, _匹配一个特定字符)
例如:
and : 并且
or: 或者
not : 非(逻辑取反)
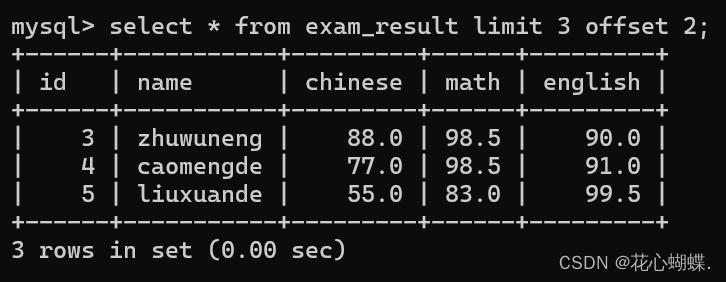
7. 分页查询
select 列名 from 表名 limit N (offset M):
N代表限制查询几条数据.
例如:
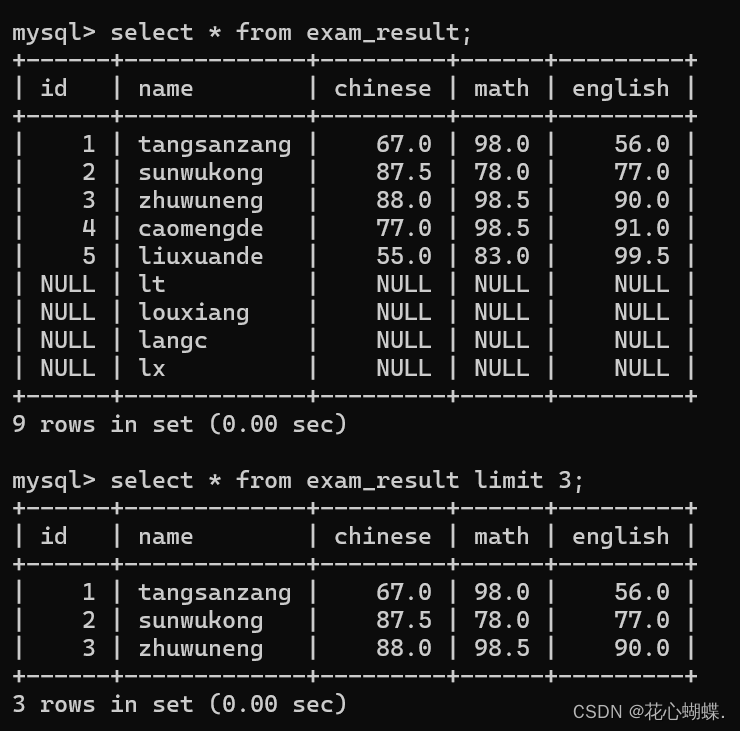
指定limit时, 还可以搭配offset来使用. offset表示从下标为几开始算limit.
例如:
8. 小结
(1) 全列查询: select * from 表名;
(2) 指定列查询: select 列名, 列名 from 表名;
(3) 查询时指定表达式: select 表达式(as 别名) from 表名;
(4) 去重查询: select distinct 列名 from 表名;
(5) 排序查询: ... order by 列名 desc/asc;
(6) 条件查询: select 列名 from 表名 where 条件;
(7) 分页查询: select 列名 from 表名 limit N (offset M):
三. "改"(update)
使用update所完成的修改, 是真正在硬盘上完成了修改 . 这样的修改, 是++"持久有效"++的.
基本语法:
update 表名 set 列名 = 值, 列名 = 值, 列名 = 值 ......;
注意:
(1) 这里还可以配合使用where, order by, limit 来对查询结果进行条件限制/排序/分页.
(2) 如果没有指定条件, 默认对所有列进行修改.
例如, 这里我们要把sunwukong的english成绩改为79:
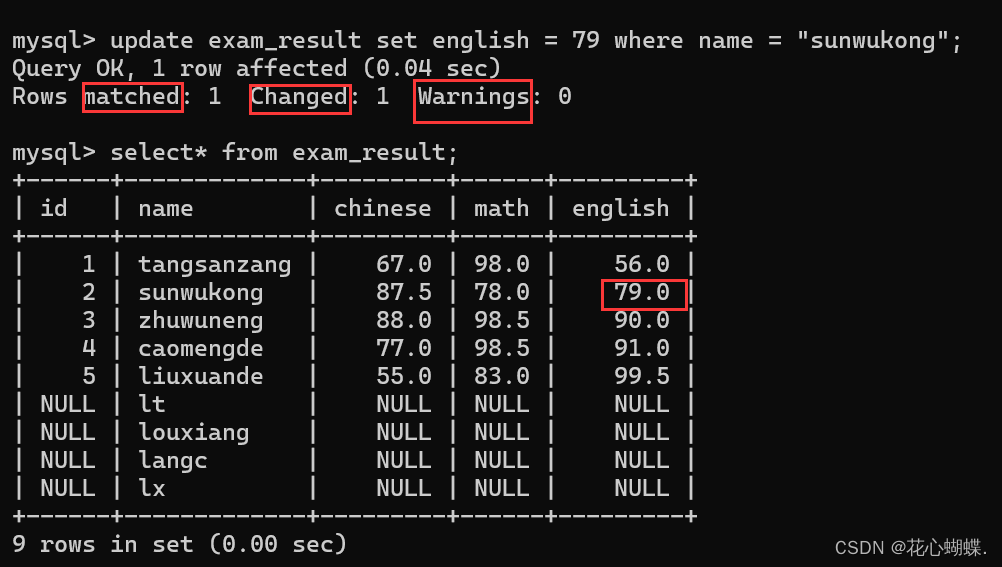 从上面结果我们可以看到: "查询成功, 1行受到影响", "匹配到的行数:1 , 修改的行数:1, 警告: 0".
从上面结果我们可以看到: "查询成功, 1行受到影响", "匹配到的行数:1 , 修改的行数:1, 警告: 0".
注意: 这里匹配到的行数和实际被修改的行数不一定相等, 要根据实际情况决定, 比如:
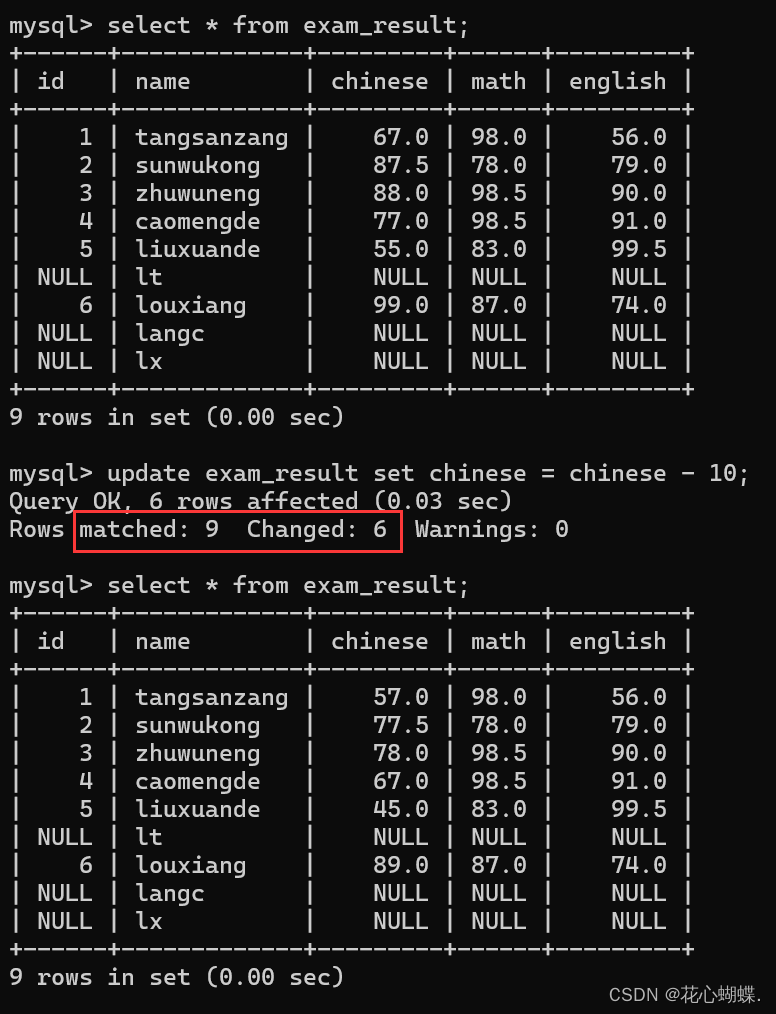
这里虽然匹配到了9行, 但是只修改了6行. 因为++只要有null参与的运算, 结果都是null++, 无法修改.
注意: 这里写到的 ++chinese = chinese + 10 不能写成chinese += 10. 因为SQL语言中没有这样的语法.++
再例: 我们要把louxiang的id 6,成绩 99, 87, 74都记录下来
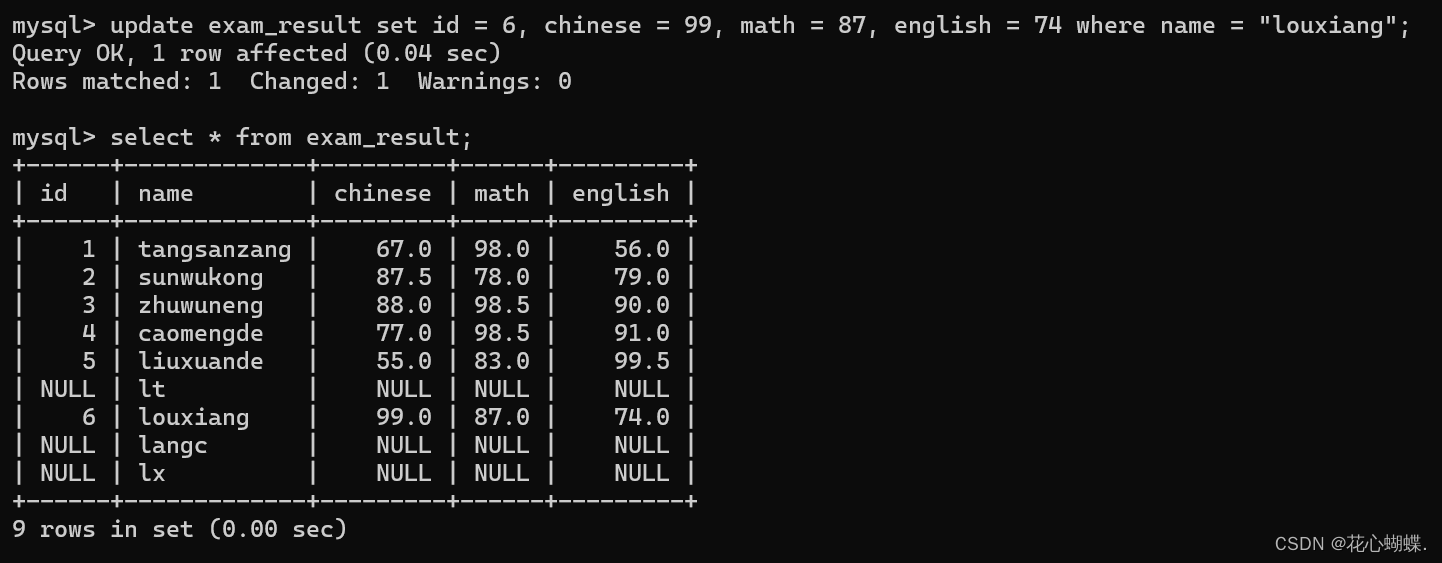
update是一个非常简单单操作, 关于update的操作, 大概就是这么多.
四. "删"(delete)
基本语法:
delete from 表名 where 条件 (order by / limit N).
注意:
(1) delete(删除)操作也是一个非常危险的操作, 在实际开发中, 要谨慎使用.
(2) 如果delete语句没有指定条件 , 那么默认会删除表中所有数据.
(2) 注意辨析delete from 表名 和 drop table 表名 的区别: delete 只是删除表中数据, 但是表依然存在; drop 是连数据带表一块都删除了.
以上就是本篇博客的全部内容啦,如果喜欢小编的文章,可以点赞,评论,收藏~
