目录
[三 . 其他命令](#三 . 其他命令)
[四. 字符串类型内部编码](#四. 字符串类型内部编码)
[五. 典型使用场景](#五. 典型使用场景)
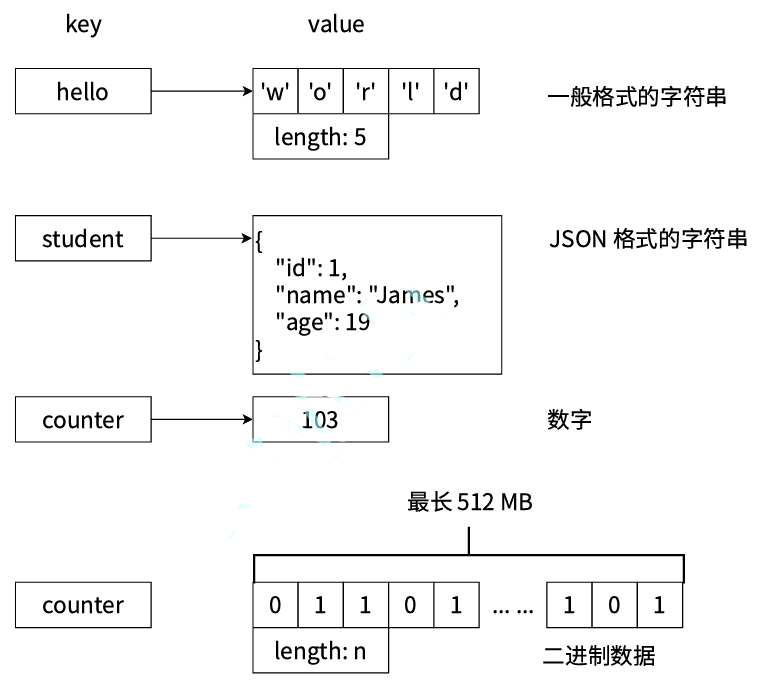
字符串(String)是 Redis 最基础、最核心的数据类型,理解其特性至关重要:
-
基础构建块:
-
键的类型: Redis 中所有的键 (Key) 本质上都是字符串类型。
-
值的基石: 其他复杂数据结构(列表 List、集合 Set、有序集合 Sorted Set、哈希 Hash)的元素值 (Value) 也必须是字符串类型。这使得字符串成为学习和理解 Redis 整个数据模型的基础。
-
-
灵活的值类型 (二进制安全):
-
Redis 字符串类型 存储的值 (Value) 具有极高的灵活性,可以是:
-
文本数据: 普通字符串、JSON、XML、CSV 等格式的文本。
-
数值数据: 整数或浮点数(Redis 提供专门的命令如
INCR,DECR,INCRBYFLOAT来操作数值)。 -
二进制数据: 如图片、音频、视频文件或任何序列化的字节流。
-
-
关键特性:二进制安全 (Binary Safe)
-
Redis 内部存储和操作字符串值完全基于原始字节序列(二进制流)。
-
这意味着 Redis 本身不感知、也不处理任何字符集编码(如 UTF-8, GBK)问题。
-
客户端存入什么编码的字节流,Redis 就原样存储;客户端读取时,也将得到完全相同的字节流。字符集的解析完全由客户端负责。
-
-
容量限制: 单个字符串值的最大容量为 512MB。
-
核心价值与应用场景:
-
缓存 (Cache): 存储 HTML 片段、用户会话信息、序列化对象等。
-
计数器 (Counter): 利用
INCR/DECR命令实现点击计数、库存计数等。 -
分布式锁 (Distributed Lock): 配合
SET命令的NX/PX等选项实现简单锁机制。 -
配置存储: 存储应用配置项。
-
二进制数据存储: 存储小型图片、验证码、序列化数据等(需注意 512MB 限制)。
总结: Redis 字符串类型不仅是键的载体,更是所有复杂数据结构元素的基石。其 二进制安全 的特性赋予了它存储任意数据的强大能力,而 512MB 的上限 和 丰富的操作命令 使其成为 Redis 最常用、最灵活的数据类型之一。
一.常见命令
1.1.SET
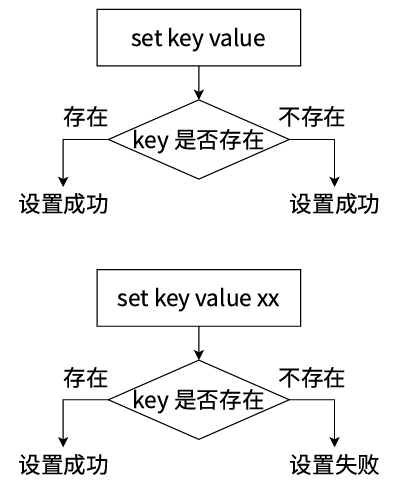
功能: 将字符串类型的值设置到指定的键中。
-
覆盖规则: 如果键已存在,无论其原先存储的数据类型是什么(字符串、列表、哈希等),都会被覆盖为新的字符串值。
-
TTL 处理: 原先与该键关联的任何生存时间(TTL)都会被清除失效。
语法:
SET key value [expiration EX seconds|PX milliseconds] [NX|XX]版本要求: 1.0.0 起可用
时间复杂度: O(1)
选项:
SET 命令提供多种选项来控制其行为:
-
EX seconds: 设置键的过期时间,单位是秒。 -
PX milliseconds: 设置键的过期时间,单位是毫秒。 -
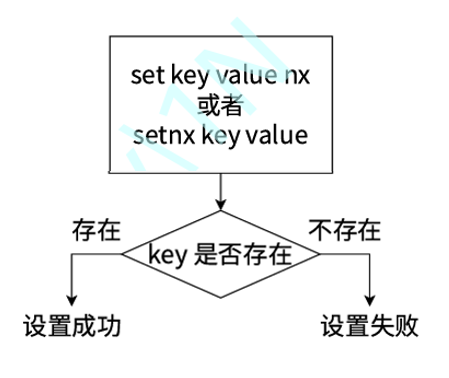
NX: 仅当键不存在 (Not eXists) 时才执行设置操作。如果键已存在,则设置操作不会执行。 -
XX: 仅当键存在 (eXists) 时才执行设置操作。如果键不存在,则设置操作不会执行。
功能整合: 上面这些新选项使得单个 SET 命令能够完全覆盖 SETNX、SETEX、PSETEX 的功能:
-
SET key value NX等价于SETNX key value -
SET key value EX seconds等价于SETEX key seconds value -
SET key value PX milliseconds等价于PSETEX key milliseconds value
重要说明:
-
互斥性:
NX和XX选项是互斥的,同一命令中只能指定其中一个。 -
命令演变: 由于
SET命令结合选项 (NX,XX,EX,PX) 可以完全替代SETNX、SETEX、PSETEX等独立命令的功能,在 Redis 的后续版本中,这些独立命令的实现已被整合到SET命令中。虽然这些独立命令目前通常仍保留可用(以兼容旧脚本或习惯),但推荐优先使用带选项的SET命令,因为它功能更统一、强大。
返回值:
-
如果设置操作成功执行 ,返回字符串
"OK"。 -
如果因为指定了
NX或XX选项但条件不满足 (即NX时键已存在,或XX时键不存在),导致设置操作未执行 ,则返回(nil)。
话不多说,我们看看例子
NX选项
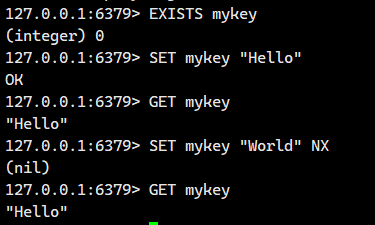
可以看到啊!!上面这个SET mykey "World" NX并没有生效啊!!!这个是因为
NX : 仅当键不存在 (Not eXists) 时才执行设置操作。如果键已存在,则设置操作不会执行。
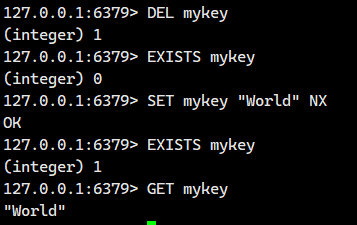
我们看看它生效的样子
XX选项
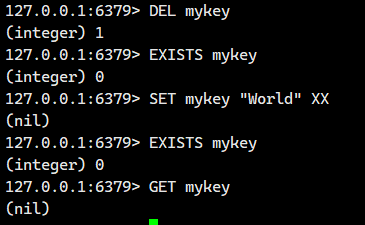
我们看到:上面这个SET mykey "World" XX并没有生效啊!!!这个是因为
XX : 仅当键存在 (eXists) 时才执行设置操作。如果键不存在,则设置操作不会执行。
我们来看看它执行的样子
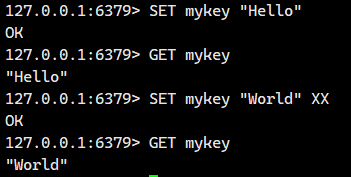
EX选项
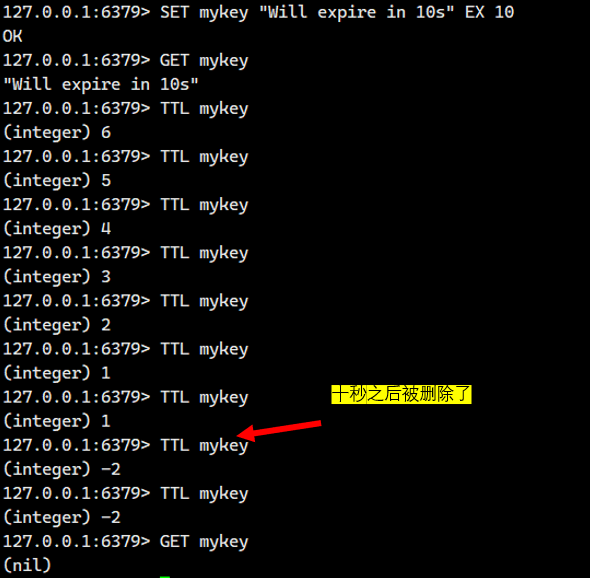
至于这个PX选项,由于时间太短了,我们就不演示了。
1.2.GET
获取 key 对应的 value。
如果 key 不存在,返回 nil。
如果 value 的数据类型不是 string,会报错。
语法:
GET key- 命令有效版本:1.0.0 之后
- 时间复杂度:O(1)
- 返回值:key 对应的 value,或者 nil 当 key 不存在。
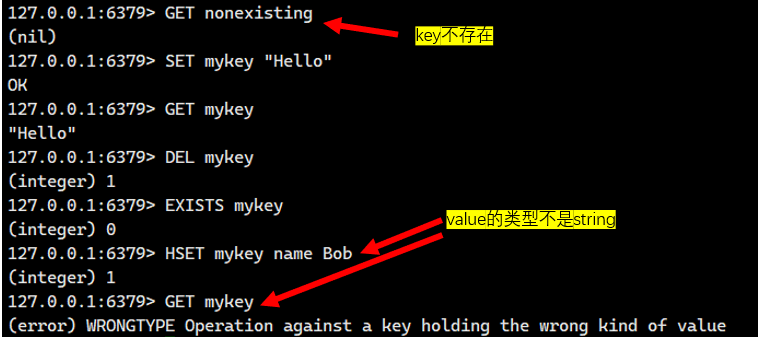
1.3.MGET
一次性获取多个 key 的值。
如果对应的 key 不存在或者对应的数据类型不是 string,返回 nil。
语法:
MGET key [key ...]- 命令有效版本:1.0.0 之后
- 时间复杂度:O(N) ,N 是我们这个命令里要获取的 key 数量 ,不是redis里面所有key的数量
- 返回值:对应 value 的列表
我们来对比一下这个get命令和mget命令啊!!!
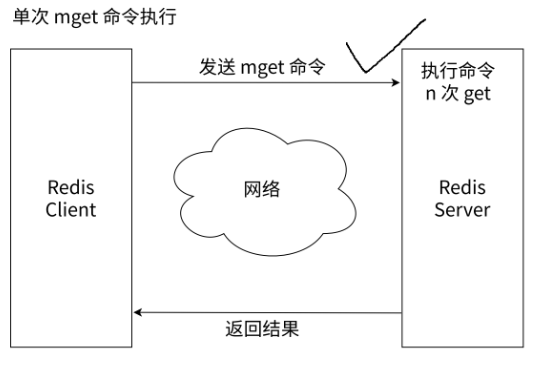
很明显啊,聪明人都会选项mget来获取value。
我们看看怎么使用
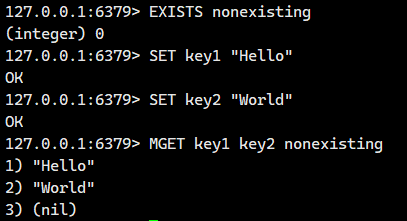
1.4.MSET
一次性设置多个 key 的值。
覆盖规则:
-
如果指定的
key已存在,无论其原先存储的数据类型是什么 (字符串、列表、哈希、集合、有序集合等),MSET都会将其覆盖为新的字符串值。 -
这是由
MSET的设计目标决定的:它是一个原子性的批量设置字符串值的命令。
TTL 处理:
-
对于
MSET命令中指定的、已经存在的key,原先与该键关联的任何生存时间(TTL)都会被清除失效 。执行MSET后,这些键将变成永久的 (没有过期时间),除非后续显式地为它们设置新的 TTL(例如使用EXPIRE或SET的EX/PX选项)。 -
对于
MSET命令中指定的、之前不存在的key,设置后会成为永久键(没有 TTL),除非后续显式设置。
语法:
MSET key value [key value ...] - 命令有效版本:1.0.1 之后
- 时间复杂度:O(N)
- N 是 key 数量
- 返回值:永远是 OK
多说无益,我们直接上手看例子
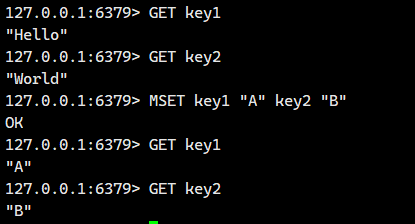
这就很好的说明了:如果指定的 key 已存在,无论其原先存储的数据类型是什么 (字符串、列表、哈希、集合、有序集合等),MSET 都会将其覆盖为新的字符串值。
接下来我们接着看
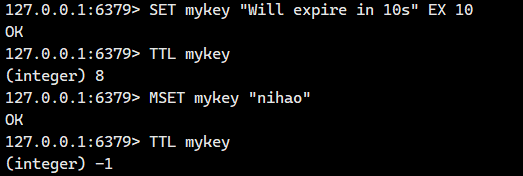
对于 MSET 命令中指定的、之前不存在的 key,设置后会成为永久键(没有 TTL),除非后续显式设置。
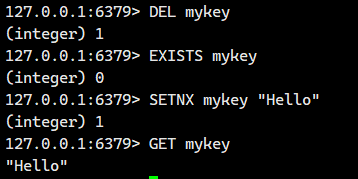
1.5.SETNX
设置key-value但只允许在key之前不存在的情况下。
语法:
SETNX key value命令有效版本:1.0.0之后
时间复杂度:O(1)
返回值:1表⽰设置成功。0表⽰没有设置。
话不多说,我们直接看例子
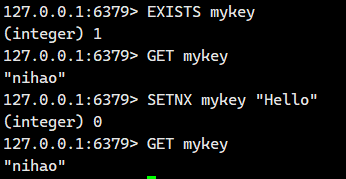
这个就是没有设置成功的情况,我们接下来看看设置成功的情况
SET、SETNX、SETXX执⾏流程
二.计数命令
2.1.INCR
功能:
将键 key 中存储的整数值增加 1。
关键行为:
-
如果键
key不存在,则在执行递增操作前,先将该键的值设置为 0。 -
如果键
key存储的值不是整数类型(无法解析为整数),则命令返回错误。 -
如果键
key存储的值是整数,但递增后超出 64 位有符号整数的表示范围 (即 C/C++ 中的long long类型,范围从-9223372036854775808到9223372036854775807),则命令返回错误。
原子性:
此命令是原子操作 。在分布式环境下,多个客户端同时对同一个键执行 INCR 时,Redis 的单线程执行模型确保该命令不会出现竞态条件,每个操作都会顺序执行,因此非常适合实现高并发场景下的计数器。
与浮点数的区别:
INCR 命令仅适用于整数值。若需操作浮点数,请使用 INCRBYFLOAT 命令。
语法:
INCR key- 命令有效版本:1.0.0 之后
- 时间复杂度:O(1)
- 返回值:integer 类型的加完后的数值。
错误情况:
-
当
key存储的不是字符串类型时,返回类型错误。 -
当
key存储的字符串不能表示为整数,或操作后导致整数溢出时,返回错误。
话不多说,我们直接看例子
将键 key 中存储的整数值增加 1。
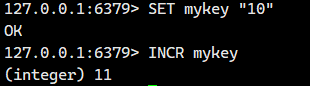
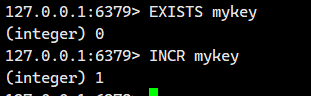
如果键 key 不存在,则在执行递增操作前,先将该键的值设置为 0。
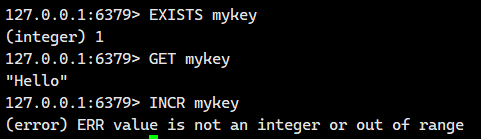
当 key 存储的字符串不能表示为整数,返回错误
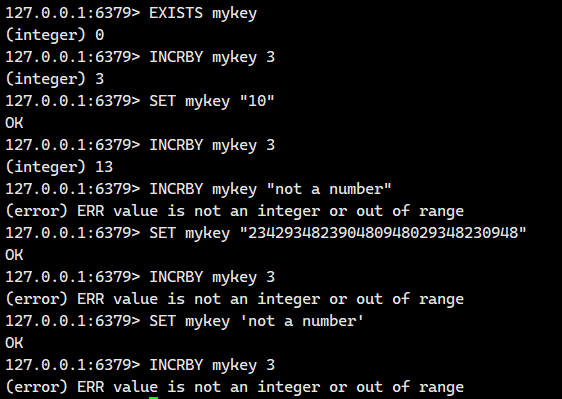
当 key 存储的字符串操作后导致整数溢出时,返回错误

2.2.INCRBY
将 key 对应的 string 表示的数字加上对应的值。
如果 key 不存在,则视为 key 对应的 value 是 0。
如果 key 对应的 string 不是一个整型或者范围超过了 64 位有符号整型,则报错。
语法:
INCRBY key decrement- 命令有效版本:1.0.0 之后
- 时间复杂度:O(1)
- 返回值:integer 类型的加完后的数值。
错误情况:
-
decrement不是整数时
-
当
key存储的不是字符串类型时 -
当
key存储的字符串不能表示为整数时 -
当操作结果超出 64 位有符号整数范围时
话不多说,我们直接看例子
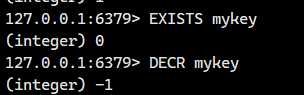
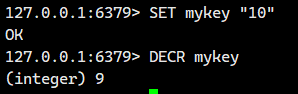
2.3.DECR
将 key 对应的 string 表示的数字减一。
如果 key 不存在,则视为 key 对应的 value 是 0。
如果 key 对应的 string 不是一个整型或者范围超过了 64 位有符号整型,则报错。
语法:
DECR key- 命令有效版本:1.0.0 之后
- 时间复杂度:O(1)
- 返回值:integer 类型的减完后的数值。
话不多说,我们直接看例子


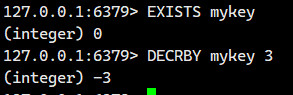
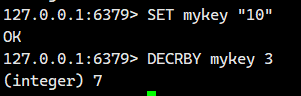
2.4.DECYBY
将 key 对应的 string 表示的数字减去对应的值。
如果 key 不存在,则视为 key 对应的 value 是 0。
如果 key 对应的 string 不是一个整型或者范围超过了 64 位有符号整型,则报错。
语法:
DECBBY key decrement- 命令有效版本:1.0.0 之后
- 时间复杂度:O(1)
- 返回值:integer 类型的减完后的数值。



2.5.INCRBYFLOAT
功能:
对键 key 存储的浮点数值执行加减操作。
核心行为:
-
数值操作:
-
将键对应的字符串值解析为浮点数
-
加上指定的增量值
-
若增量为负数,则执行减法操作
-
-
键不存在时:
- 自动视为该键的值为
0.0
- 自动视为该键的值为
-
科学计数法:
- 支持使用科学计数法表示浮点数(如
1.23e4)
- 支持使用科学计数法表示浮点数(如
-
错误条件:
-
键存在但非字符串类型 → 报错
-
键值无法解析为浮点数 → 报错
-
语法:
INCRBYFLOAT key increment- 命令有效版本:2.6.0 之后
- 时间复杂度:O(1)
- 返回值:加/减完后的数值。
话不多说,我们直接看例子

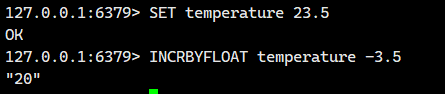
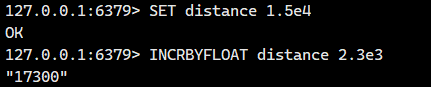
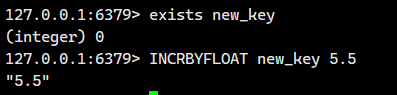
很多存储系统和编程语言内部使用 CAS 机制实现计数功能,会有一定的 CPU 开销,但在 Redis 中完全不存在这个问题,因为 Redis 是单线程架构,任何命令到了 Redis 服务端都要顺序执行。
Redis里面整数和小数的存储方式
Redis 在存储数值类型时,对整数和小数采取了不同的底层处理方式。
-
整数: 直接使用高效的整型数据结构(在 Redis 内部通常表示为
long类型,对应 C 语言的long long或 Java 的long,即 64 位有符号整数)。这使得整数的算术运算(如INCR,DECR,INCRBY)非常高效,因为它们直接在内存中的二进制数值上进行操作。 -
小数: 则是以序列化后的字符串形式存储的(例如,
"3.14")。这意味着每次需要对小数进行任何算术运算时(无论是 Redis 内置命令如INCRBYFLOAT,还是客户端应用逻辑),都必须:-
将存储的字符串解析 为编程语言中的浮点数类型(如
double)。 -
在浮点数上执行运算。
-
将运算结果重新序列化为字符串。
-
最后再将字符串写回 Redis。
-
这种"字符串-数值-字符串"的转换过程,相比于整数的直接二进制运算,会带来显著的额外开销(CPU 用于解析/序列化,内存用于存储字符串)。选择这种设计主要是因为:
-
保持精度和可移植性: 字符串表示可以精确地记录用户输入的小数值(尤其是涉及特定精度时),避免了二进制浮点数固有的精度损失问题(如 0.1 无法精确表示)。它也确保了不同客户端或系统之间传输时值的一致性和可读性。
-
简化实现: 统一用字符串存储简化了 Redis 内部对值类型的处理逻辑。
因此,虽然 Redis 提供了 INCRBYFLOAT 等命令支持小数运算,但其底层实现机制决定了其性能开销远大于整数的等效操作。在设计需要频繁进行数值计算的数据结构时,应充分考虑这种差异。
三 . 其他命令
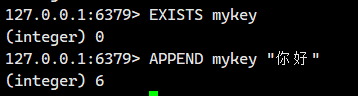
3.1.APPEND
如果 key 已经存在并且是一个 string,命令会将 value 追加到原有 string 的后边。
如果 key 不存在,则效果等同于 SET 命令。
语法:
APPEND KEY VALUE- 命令有效版本:2.0.0 之后
- 时间复杂度:O(1). 追加的字符串一般长度较短, 可以视为 O(1).
- 返回值:追加完成之后 string 的长度。返回的是字节数!!!
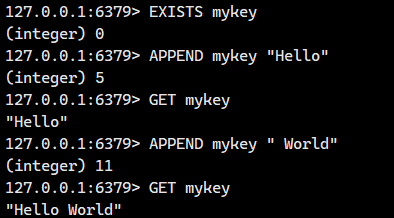
注意事项
append 返回值, 长度的单位是 字节!!
redis 的字符串, 不会对字符编码做任何处理. (redis 不认识字符, 只认识字节)
当前咱们的 xshell 终端, 默认的字符编码是 utf8.
在终端中输入汉字之后, 也就是按照 utf8 编码的~~
一个汉字在 utf8 字符集中, 通常是 3 个字节的~
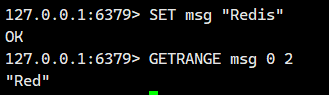
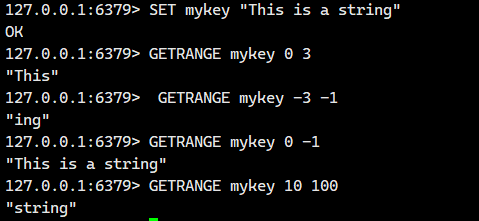
3.2.GETRANGE
功能:
返回键 key 对应字符串值的子串,子串范围由 start 和 end 下标确定(包含两端字符)。
索引规则:
-
正数索引:从左向右计数(0 表示第一个字符)
-
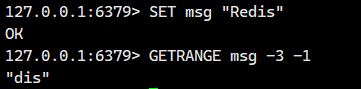
负数索引:从右向左计数
-
-1:倒数第一个字符 -
-2:倒数第二个字符 -
其他负数依此类推
-
-
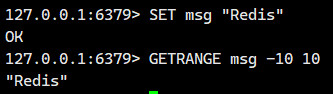
范围处理:
-
若
start超出字符串左边界,视为 0 -
若
end超出字符串右边界,视为最后一个字符 -
若
start > end,返回空字符串
-
语法:
GETRANGE key start end- 命令有效版本:2.4.0 之后
- 时间复杂度:O(N). N 为 start, end 区间的长度. 由于 string 通常比较短, 可以视为是 O(1)
- 返回值:string 类型的子串、
闭区间包含
负数索引
越界处理
空键处理
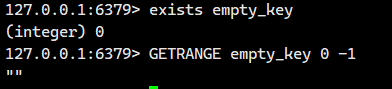
完整实例
3.3.SETRANGE
功能:
从指定偏移量 offset 开始,覆盖键 key 存储的字符串值的部分内容。
注意这里的偏移量可是以字节为单位的。
核心行为:
-
覆盖规则:
-
从
offset位置开始,用value覆盖原字符串 -
若
offset大于原字符串长度,自动用空字节(\x00)填充中间空缺
-
-
键不存在时:
-
视为空字符串
""处理 -
等同于在指定位置创建新字符串
-
-
长度变化:
-
操作后字符串长度 = max(原长度, offset + value长度)
-
可能扩展字符串长度
-
语法:
SETRANGE key offset value- 命令有效版本:2.2.0 之后
- 时间复杂度:O(N),N 为 value 的长度。由于一般给的 value 比较短,通常视为 O(1)。
- 返回值:替换后的 string 的长度。
话不多说,直接看例子:
基础覆盖:从指定偏移量 offset 开始,覆盖键 key 存储的字符串值的部分内容。
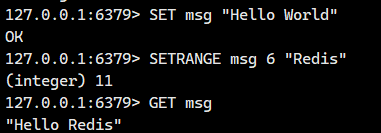
超出长度处理:若 offset 大于原字符串长度,自动用空字节(\x00)填充中间空缺
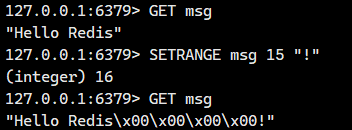
空键操作:键不存在时,视为空字符串 "" 处理,偏移量前面的全部自动用空字节(\x00)填充
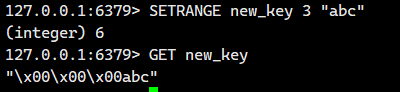
注意这里的偏移量可是以字节为单位的。
如果我们当前的value是中文字符串,进行 SETRANGE操作的话可能会出现问题的。因为一个中文字符通常不止一个字节。
我们看看
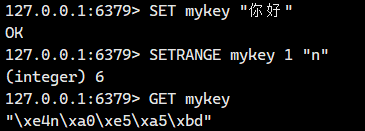
3.4.STRLEN
获取 key 对应的 string 的长度。也就是对应string的字节数。
当 key 存放的类似不是 string 时,报错。
语法:
STRLEN key- 命令有效版本:2.2.0 之后
- 时间复杂度:O(1)
- 返回值:string 的长度。或者当 key 不存在时,返回 0。
注意事项:
1.字节长度
无论字符串使用何种编码(如 ASCII、UTF-8、GBK),STRLEN 始终返回字符串占用的 字节数 。
例如:
- 字符串
"hello"(ASCII)→ 5 字节 → 返回 5 - 字符串
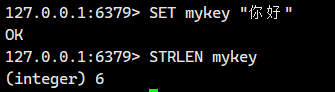
"你好"(UTF-8 编码)→ 每个汉字占 3 字节 → 总 6 字节 → 返回 6
2.非字符串类型报错
若 Key 存储的不是字符串类型(如 List/Hash/Set),Redis 会返回错误:(error) WRONGTYPE Operation against a key holding the wrong kind of value
3.Key 不存在 :若 Key 不存在,返回 0(视为空字符串)。
话不多说,我们直接看例子
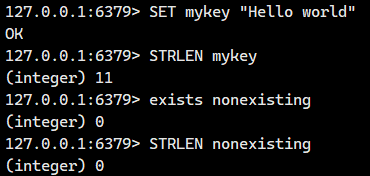
字符串 "你好"(注意我们现在是使用了UTF-8 编码)→ 每个汉字占 3 字节 → 总 6 字节 → 返回 6
在编程和数据库设计中,理解字符串长度和字符编码至关重要,不同环境下的处理方式存在显著差异:
长度单位:
C++:
std::string的length()或size()方法返回的是字节数。Java:
String的length()方法返回的是 字符数。MySQL:
VARCHAR(N)定义中的N指定的是字符数。一个字符可以是一个英文字母、一个汉字或其他语言符号。
四. 字符串类型内部编码
Redis 为了优化内存使用和性能,会根据字符串值的类型和长度动态选择三种不同的内部编码表示:
- int:8个字节的⻓整型。
- embstr:⼩于等于39个字节的字符串。
- raw:⼤于39个字节的字符串。
Redis 会根据当前值的类型和⻓度动态决定使⽤哪种内部编码实现。
int(整型):
当字符串值可以表示为 8 字节长整型 (long) 时使用。
优势: 内存占用小,操作效率高(支持数值计算)。
示例:
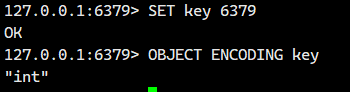
值 '6379' 被识别为整数,使用 int 编码
embstr(嵌入式字符串):
用于存储长度 小于或等于 44 字节 的字符串值 (注意:Redis 版本演进中,这个阈值从早期的 39 字节提高到了 5.0 及以后版本的 44 字节)。
特点: RedisObject 对象头和数据本身存储在一块连续的内存中。
优势: 内存分配和释放只需一次操作,缓存局部性好,访问效率高。
示例:
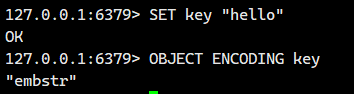
短字符串 "hello" 使用 embstr 编码
raw(原始字符串):
用于存储长度 大于 44 字节 的字符串值。
特点: RedisObject 对象头和数据本身存储在两块独立分配的内存中。
原因: 对于长字符串,分配连续的大块内存代价更高且不灵活。
示例:

"raw" # 长字符串使用 raw 编码
忠告
不建议大家去记, 长度大于 39 这样的数字~~
给大家讲个情景吧:
对于某个业务场景, 有很多很多的 key , 类型都是 string
但是每个 value 的 string 长度都是 100 左右~~ 更关注与整体的内存空间.
因此的话, 这样的字符串使用 embstr 来存储也不是 不能考虑~~
上述效果具体怎么实现?
- 先看 redis 是否提供了对应的配置项, 可以修改 39 这个数字~~
- 如果没有提供配置型, 就需要针对 redis 源码进行魔 改~
为啥很多大厂, 往往是自己造轮子, 而不是直接使用业 界成熟的呢?
开源的组件, 往往考虑的是通用性~~ 但是大厂往往会遇到一些极端的业务场景~~ 往往就需要根据当前的极端业务, 针对上述的开源组件 进行定制化~~
五. 典型使用场景
5.1.缓存(Cache)功能
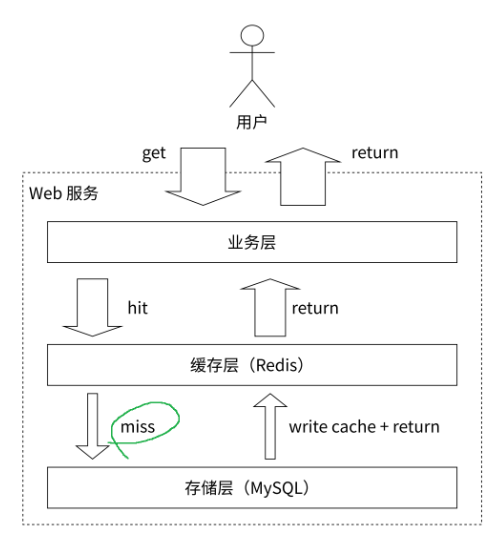
缓存(Cache)功能是⽐较典型的缓存使⽤场景,其中Redis作为缓冲层,MySQL作为存储层,绝⼤部分请 求的数据都是从Redis中获取。
缓存读取的核心流程:
-
优先查询 Redis: 当应用服务器需要数据时,首先尝试从 Redis 缓存中读取。
-
缓存命中 (Cache Hit): 如果所需数据存在于 Redis 中,则直接将其返回给应用服务器。此时不会访问后端数据库,显著提升响应速度和降低数据库负载。
-
缓存未命中 (Cache Miss):
-
如果 Redis 中不存在所需数据,则应用服务器转而查询后端数据库 (如 MySQL)。
-
从数据库获取到结果后,将其返回给应用服务器。
-
同时,将这个查询结果写入 Redis 缓存,以备后续相同的请求使用。
-
Redis 与"热点数据":
-
Redis 缓存最典型的应用场景就是存储高频访问的数据,即"热点数据"。
-
上述缓存策略(最近查询到的数据写入缓存)本质上是将最近被访问的数据视为潜在的热点数据。
-
这隐含了一个假设:某个数据一旦被访问,它在近期内很可能被再次访问(时间局部性原理)。这种策略(如 LRU - Least Recently Used 的变体)能有效捕捉并加速访问这类热点数据。
潜在问题:缓存膨胀与解决方案
上述策略存在一个明显的问题:随着时间推移,越来越多的 Key 会因为首次访问而从数据库加载并写入 Redis。如果不加控制,Redis 中存储的数据量会持续增长,最终可能导致:
-
内存耗尽: Redis 主要依赖内存存储,无限增长的数据必然耗尽内存资源。
-
性能下降: 内存不足可能导致 Redis 自身操作变慢,甚至触发更严重的问题。
核心解决方案:
-
设置过期时间 (TTL - Time To Live):
-
在将数据写入 Redis 时,必须为其设置一个合理的过期时间 。例如:
SET key value EX 3600(设置 key 在 3600 秒后过期)。 -
这确保了即使数据不再被访问,也会在过期后被自动删除,释放内存空间。
-
过期时间的选择需要结合业务场景(数据更新频率、重要性、容忍的陈旧度等)。
-
-
配置内存淘汰策略 (Eviction Policies):
-
当 Redis 内存使用达到配置的最大限制 (
maxmemory) 时,它会根据设定的淘汰策略自动删除部分 Key 以释放空间,保证新数据可以写入。 -
常见的淘汰策略包括:
-
volatile-lru/allkeys-lru: 淘汰最近最少使用的 Key(有过期时间的 / 所有Key)。 -
volatile-lfu/allkeys-lfu: 淘汰最不经常使用的 Key(有过期时间的 / 所有Key)。 -
volatile-ttl: 淘汰即将过期的 Key。 -
volatile-random/allkeys-random: 随机淘汰 Key(有过期时间的 / 所有Key)。 -
noeviction: 不淘汰,新写入操作会报错(通常不推荐用于缓存场景)。
-
-
选择合适的淘汰策略对于平衡内存使用和缓存命中率至关重要。
-
由于Redis具有⽀撑⾼并发的特性,所以缓存通常能起到加速读写和降低后端压⼒的作⽤。
下⾯的伪代码模拟了业务数据访问过程:
1)假设业务是根据⽤⼾uid获取⽤⼾信息
UserInfo getUserInfo(long uid) {
...
}2)⾸先从Redis获取⽤⼾信息,我们假设⽤⼾信息保存在"user:info:"对应的键中:
// 根据 uid 得到 Redis 的键
String key = "user:info:" + uid;
// 尝试从 Redis 中获取对应的值
String value = Redis 执行命令: get key;
// 如果缓存命中 (hit)
if (value != null) {
// 假设我们的用户信息按照 JSON 格式存储
UserInfo userInfo = JSON 反序列化(value);
return userInfo;
}3)如果没有从 Redis 中得到用户信息,及缓存 miss,则进一步从 MySQL 中获取对应的信息,随后写入缓存并返回:
// 如果缓存未命中(miss)
if (value == null) {
// 从数据库中,根据 uid 获取用户信息
UserInfo userInfo = MySQL 执行 SQL: select * from user_info where uid = <uid>
}
// 如果表中没有 uid 对应的用户信息
if (userInfo == null) {
响应 404
return null;
}
// 将用户信息序列化成 JSON 格式
String value = JSON 序列化(userInfo);
// 写入缓存,为了防止数据腐烂(rot),设置过期时间为 1 小时(3600 秒)
Redis 执行命令: set key value ex 3600
// 返回用户信息
return userInfo;
}通过增加缓存功能,在理想情况下,每个用户信息,一个小时期间只会有一次 MySQL 查询,极大地提升了查询效率,也降低了 MySQL 的访问数。
与 MySQL 等关系型数据库不同的是,Redis 没有表、字段这种命名空间,而且也没有对键名有强制要求(除了不能使用一些特殊字符)。
但设计合理的键名,有利于防止键冲突和项目的可维护性,比较推荐的方式是使用 "业务名:对象名:唯一标识:属性" 作为键名。
例如 MySQL 的数据库名为 vs,用户表名为 user_info,那么对应的键可以使用 "vs:user_info:6379"、"vs:user_info:6379:name" 来表示,如果当前 Redis 只会被一个业务
使用,可以省略业务名 "vs:"。
如果键名过程,则可以使用团队内部都认同的缩写替代,例如 "user:6379:friends:messages:5217" 可以被 "u:6379:fr:m:5217" 代替。
毕竟键名过长,还是会导致 Redis 的性能明显下降的。
5.2.计数(Counter)功能
许多应用都会使用 Redis 作为计数的基础工具,它可以实现快速计数、查询缓存的功能,同时数据可以异步处理或者落地到其他数据源。
如图所示,例如视频网站的视频播放次数可以使用 Redis 来完成:用户每播放一次视频,相应的视频播放数就会自增 1。
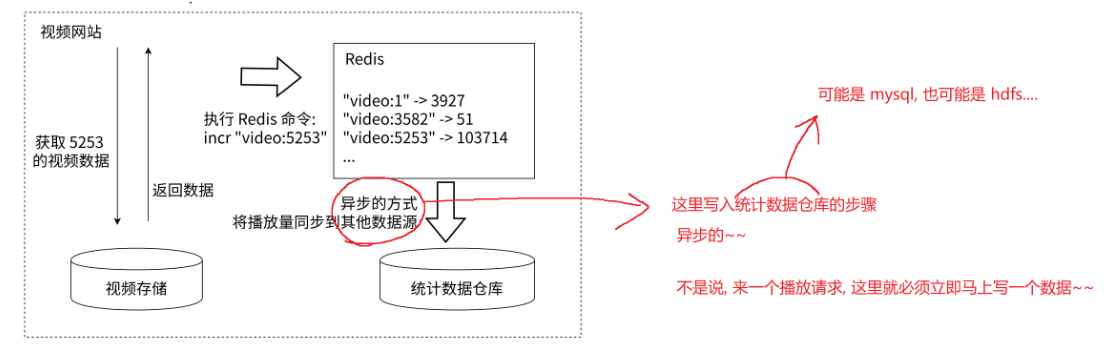
sql
// 在 Redis 中统计某视频的播放次数
long incrVideoCounter(long vid) {
key = "video:" + vid;
long count = Redis 执行命令:incr key
return counter;
}实际上要开发一个成熟、稳定的真实计数系统,要面临的挑战远不止如此简单:防作弊、按照不同维度计数、避免单点问题、数据持久化到底层数据源等。
Redis 并不擅长数据统计!
为什么呢? Redis 的核心优势在于快速的键值存取和丰富的数据结构操作,但它缺乏内置的复杂聚合计算能力,特别是像排序、分组、多键关联统计这类操作。
典型例子: 比如,你想在上面提到的 Redis 缓存(或存储)中,统计出播放量排名前 100 的视频有哪些。要实现这个需求:
-
基于 Redis 搞就很麻烦! 你可能需要:
-
遍历所有相关的视频 Key(如果数据量大,
KEYS命令是灾难性的,SCAN也慢)。 -
逐个获取它们的播放量(多次
GET/HGET命令,网络开销大)。 -
在客户端(应用服务器)内存中对所有视频的播放量进行排序。
-
最后取出前 100 名。
这个过程不仅性能开销巨大(O(N) 复杂度) ,容易阻塞 Redis(如果遍历不当),而且实现逻辑复杂,代码量多。
-
相比之下,MySQL 的优势就显现了:
-
如果上述播放量数据是存储在 MySQL 数据库中的(比如存在一个
videos表里,有video_id和play_count字段)。 -
那么,一个简单的 SQL 查询就搞定了! 例如:
sqlSELECT video_id, play_count FROM videos ORDER BY play_count DESC LIMIT 100; -
MySQL 强大的查询优化引擎 会高效地处理排序 (
ORDER BY) 和限制结果集 (LIMIT),通常利用索引就能快速完成,复杂度远低于 Redis 的 O(N) 遍历,而且代码极其简洁。
5.3.共享会话(Session)
如图所示,一个分布式 Web 服务将用户的 Session 信息(例如用户登录信息)保存在各自的服务器中,但这样会造成一个问题:出于负载均衡的考虑,分布式服务会将用户的访问请求均衡到不同的服务器上,并且通常无法保证用户每次请求都会被均衡到同一台服务器上,这样当用户刷新一次访问是可能会发现需要重新登录,这个问题是用户无法容忍的。
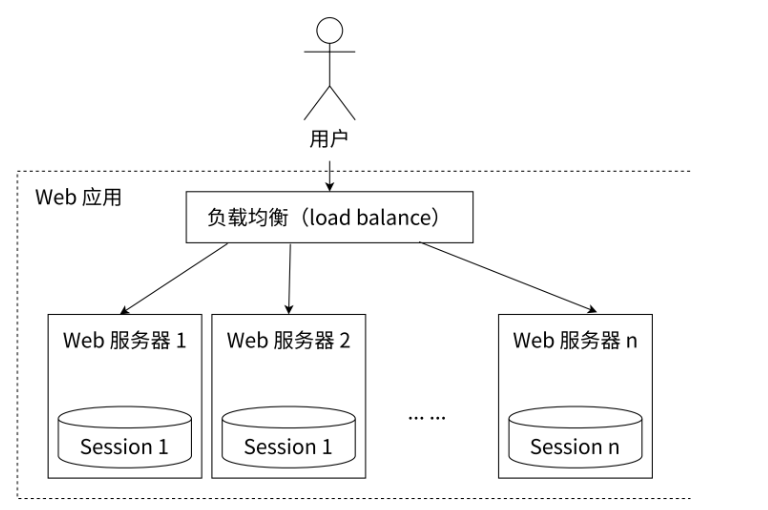
为了解决这个问题,可以使⽤Redis将⽤⼾的Session信息进⾏集中管理,如图2-13所⽰,在这种模 式下,只要保证Redis是⾼可⽤和可扩展性的,⽆论⽤⼾被均衡到哪台Web服务器上,都集中从 Redis 中查询、更新Session信息。
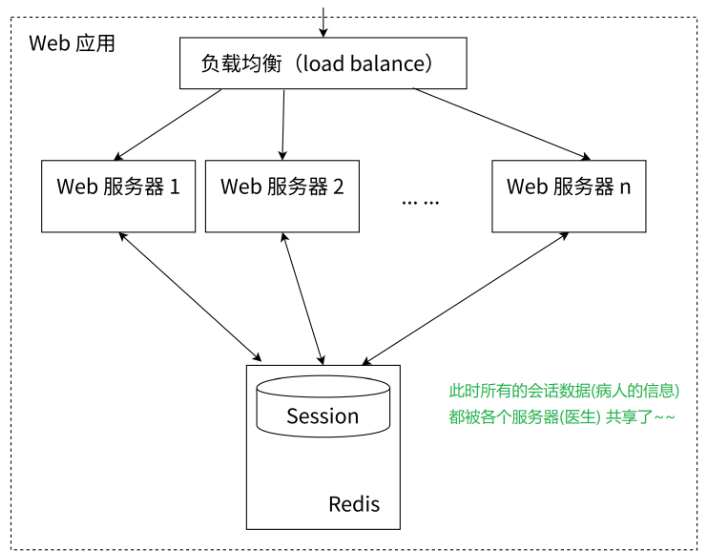 总结一下,就是下面这样子:
总结一下,就是下面这样子:
分布式 Session 问题
在分布式 Web 服务中,若用户 Session 信息(如登录状态)存储在各自服务器内存 中,当负载均衡将用户请求分配到不同服务器时,用户可能因访问不同服务器而丢失 Session 状态(例如刷新页面后需重新登录)。这种体验是用户无法容忍的。
解决方案:Redis 集中管理
-
统一存储:所有服务器将 Session 数据(键值对结构)集中存储到 Redis。
-
高可用保障:通过 Redis 集群(主从复制+哨兵)或 Redis Cluster 确保服务连续性。
-
全局访问 :用户请求携带 Session ID (通常存于浏览器 Cookie),无论分配到哪台服务器,均从 Redis 查询/更新状态。
→ 实现效果 :用户登录状态、购物车等会话数据在分布式环境下保持全局一致。
医疗场景类比
原始案例
"我前段时间生病,声带发炎到完全说不出话~~
挂号看专家,做喉镜、雾化理疗,开了一周药量。医生嘱托:'先搞一周看看,一周后复查~~'
一周后复查,发现首诊医生不在!!! 新医生未接触过我的病例,不了解情况~~
硬着头皮就诊,新医生刷我的就诊卡,电脑上立即显示完整病史~~"
技术映射
-
病人=客户端:需要连续医疗服务
-
医生=Web服务器:多实例并行服务
-
医生凭个人记忆=服务器本地存储Session:导致切换服务器时状态丢失
-
就诊卡=Session ID:唯一标识患者身份(通过Cookie传递)
-
医院病例系统=Redis:集中存储病史(会话状态),实现医生(服务器)间数据共享
核心结论
会话(Session)本质是客户端与服务器交互中产生的专属中间状态 ,分布式系统必须通过集中存储 (如Redis)解决状态一致性问题,如同医院依赖共享病例系统保障连续诊疗。
5.4.⼿机验证码
很多应⽤出于安全考虑,会在每次进⾏登录时,让⽤⼾输⼊⼿机号并且配合给⼿机发送验证码, 然后让⽤⼾再次输⼊收到的验证码并进⾏验证,从⽽确定是否是⽤⼾本⼈。
为了短信接⼝不会频繁访 问,会限制⽤⼾每分钟获取验证码的频率,例如⼀分钟不能超过5次,如图所⽰。

此功能可以用以下伪代码说明基本实现思路:
sql
String 发送验证码(phoneNumber) {
key = "shortMsg:limit:" + phoneNumber;
// 设置过期时间为 1 分钟 (60 秒)
// 使用 NX,只在不存在 key 时才能设置成功
bool r = Redis 执行命令: set key 1 ex 60 nx
if (r == false) {
// 说明之前设置过该手机的验证码了
long c = Redis 执行命令: incr key
if (c > 5) {
// 说明超过了一分钟 5 次的限制了
// 限制发送
return null;
}
}
// 说明要么之前没有设置过手机的验证码;要么次数没有超过 5 次
String validationCode = 生成随机的 6 位数的验证码();
validationKey = "validation:" + phoneNumber;
// 验证码 5 分钟 (300 秒) 内有效
Redis 执行命令: set validationKey validationCode ex 300;
// 返回验证码,随后通过手机短信发送给用户
return validationCode ;
}
// 验证用户输入的验证码是否正确
bool 验证验证码(phoneNumber, validationCode) {
validationKey = "validation:" + phoneNumber;
String value = Redis 执行命令: get validationKey;
if (value == null) {
// 说明没有这个手机的验证码记录,验证失败
return false;
}
if (value == validationCode) {
return true;
} else {
return false;
}
}以上介绍了使用 Redis 的字符串数据类型可以使用的几个场景,但其适用场景远不止于此,开发人员可以结合字符串类型的特点以及提供的命令,充分发挥自己的想象力,在自己的业务中去找到合适的场景去使用 Redis 的字符串类型。