lakeformation在IAM权限模型之外提供独立的更细粒度的权限,控制数据湖数据的访问
- 能够提供列、行和单元格级别的精细控制
lakeformation的目的是要取代s3和iam策略,主要功能为
- 数据摄入,LF可以将不同类型的数据统一管理
- 安全管理,混合接入,访问日志,行和单元格级别的安全,TBAC控制
工作流程
权限管理的工作流如下图
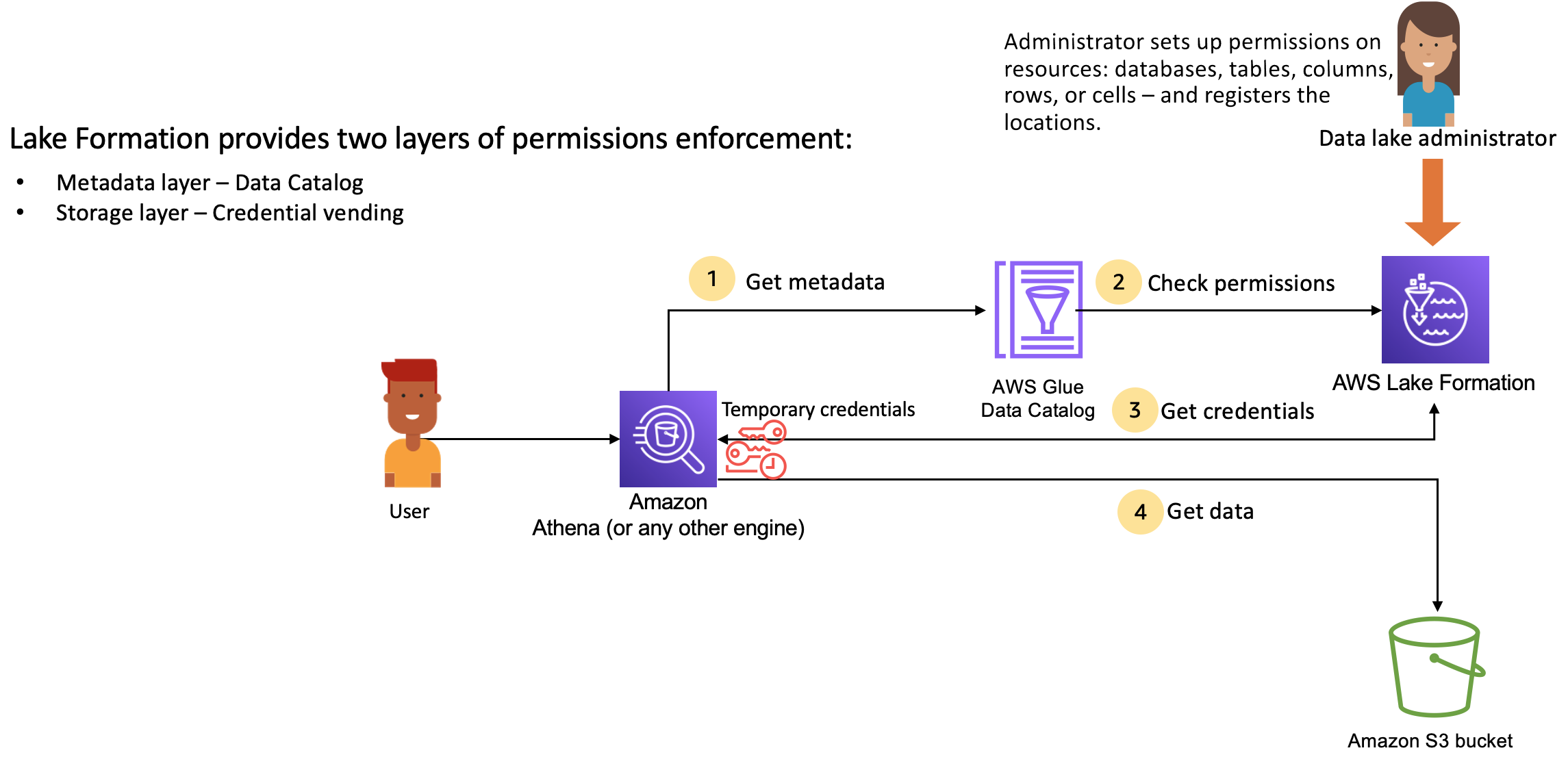
元数据的访问权限
默认将所有数据库和表的权限设置到名为**IAMAllowedPrincipal**的virtual group(只在LF可见)
所有的iam用户之所以可以访问datalake中的元数据,是因为IAM主体和IAMAllowedPrincipal组进行了映射,如果需要转换到使用lakeformation权限,则需要revoke数据库和表对这个group的授权
-
包括通过iam策略和Glue资源策略有权访问datacatalog的所有主体
-
删除
IAMAllowedPrincipal后LF将强制执行其他关联的策略 -
保持账户级别的setting配置默认,
IAMAllowedPrincipal在创建所有新数据库和表时都具有权限
数据湖管理员可以授权的权限有
- 创建表和数据库的权限
- 数据库和表级别控制权限
- 数据存储位置权限
- 隐式和显式授权
临时凭证签发
LF通过临时凭证自动签发的机制 为其他服务访问数据湖的数据,包括Athena、Redshift Spectrum、Amazon EMR、Amazon Glue、Amazon QuickSight 和 Amazon SageMaker,在授予权限时,用户无需更新其 Amazon S3 存储桶策略或 IAM 策略,也不需要直接访问 Amazon S3

即当user用户不具备目标底层数据s3的权限时,也能够通过athena查询表数据
跨账户共享数据
LF可实现数据库和表的
- 账户内共享
- 跨账户共享
- 跨账户的某个IAM主体共享
LF使用Amazon Resource Access Manager(ARM)来促进账户之间的权限授予
数据湖管理员并不等于具备AdministratorAccess权限的用户(也不建议选取此类用户),能够向其他用户授权元数据和数据的访问权限。最多可以有30个数据湖管理员。但是具备AdministratorAccess权限的用户隐式为数据湖管理员plus
超级管理员(AdministratorAccess)具备以下权限才能创建数据湖管理员,超级管理员隐式具备以下权限
lakeformation:PutDataLakeSettings
lakeformation:GetDataLakeSettingsAWSLakeFormationDataAdmin策略包含如下deny策略,因此创建数据胡管理员用户实际上无法修改lakeformation setting
{
"Effect": "Deny",
"Action": [
"lakeformation:PutDataLakeSettings"
],
"Resource": "*"
}