为了提升写入效率,JuiceFS 提供了 writeback 功能。例如在写入 1 万条数据的案例中,启用 writeback 后,数据传输在 10 秒 内完成;未启用 writeback 时则需要 2 分钟。然而,writeback 功能也伴随着一些风险和使用限制。本文将详细介绍 JuiceFS 的写入机制,解析 writeback 的工作原理、适用场景以及使用时的注意事项,帮助用户全面了解该功能的优势与潜在问题。
01 JuiceFS 常规写入模式
JuiceFS 数据写入过程分为两步:
- 数据块写入对象存储并同步返回: 客户端首先将切分好的数据块写入对象存储。无论对象存储的写入速度如何(即使延迟高达数百毫秒),JuiceFS 都会等待其返回确认后再进行后续操作。
- 元数据写入: 对象存储返回响应后,JuiceFS 接着写入元数据。
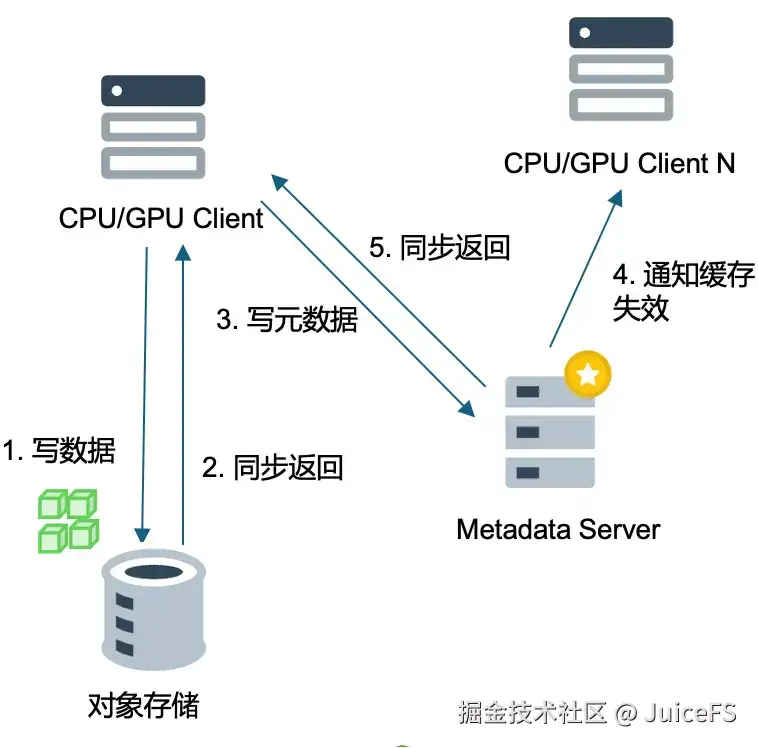
社区版和企业版在缓存失效机制上有所不同,因而其数据一致性的处理方式也不同。
- 社区版:每个客户端都有内存中的元数据缓存,默认缓存失效时间为 1 秒。这是由于社区版缺乏主动通知机制,客户端只能被动等待缓存过期才能获取最新数据,所以我们折中将默认时间定在1秒,在确保只读的场景下才建议调大该设置。
- 企业版:企业版支持主动通知缓存失效。当文件被修改后,企业版会向所有使用该文件的客户端发送缓存失效通知,指示它们下次读取时直接向元数据服务器请求数据,而不是使用本地缓存。这样,企业版就可以实现更长的元数据缓存时间,进一步降低服务器压力。
02 writeback 工作原理
writeback 模式主要目的是加速写入过程。数据首先写入本地磁盘,并且在 cache-dir 目录下会额外创建一个 rawstaging 目录,用于存放尚未上传到对象存储的本地数据,这部分数据称为 staging 数据。
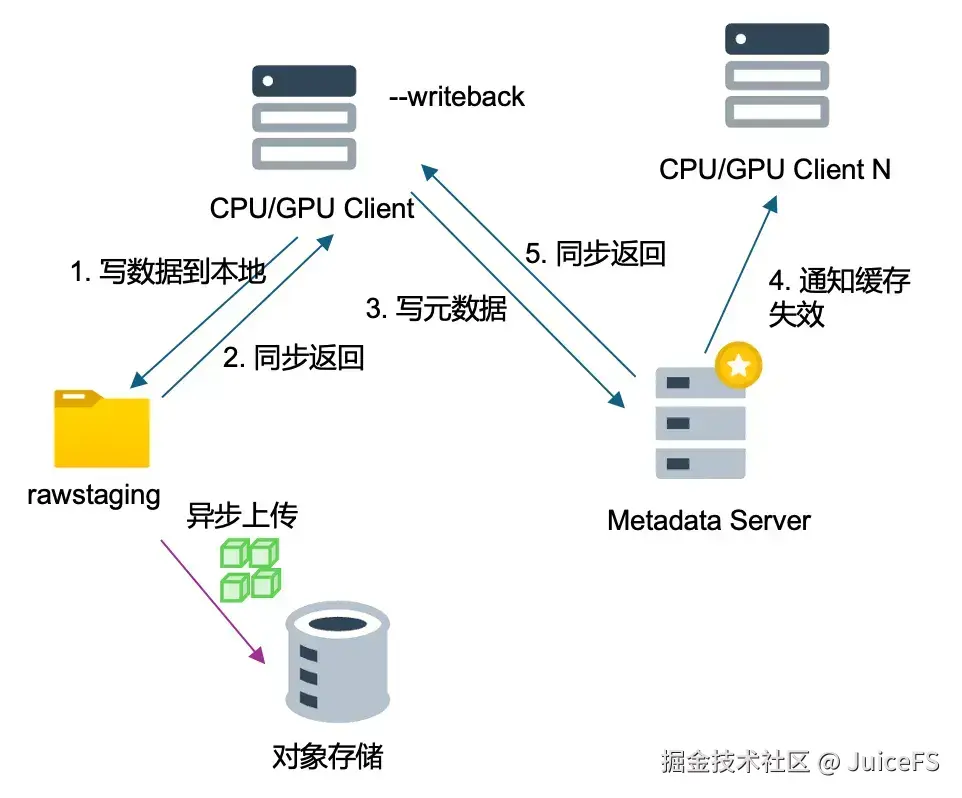
数据写入本地磁盘并立即返回响应,写入速度远快于直接写入对象存储,通常在几毫秒之间,高性能的 NVMe 磁盘延迟甚至可低至零点几毫秒。写入后,客户端会通知元数据服务器数据已完成写入,后续同步流程与常规写入一致。然而,数据块会异步上传到对象存储,上传速度和完成时间取决于网络和机器负载,因此在初期无法预知上传的具体情况。
尽管 writeback 模式提供了更高的写入速度,我们通常不推荐客户使用此模式,主要是出于以下两点考虑:
-
数据未上传风险: 许多客户在收到同步返回响应后,业务层面会误认为数据已成功写入到对象存储。但实际上,数据可能仍停留在本地,尚未上传。如果此时客户关闭甚至销毁机器,虽然重启后数据会继续上传,但若机器被销毁,数据将永久丢失。
-
其他节点无法马上读取: 写到 staging 目录下的本地文件在上传对象存储之前其他的节点是无法读取的,所以这破坏了 read-after-write 的一致性,也破坏了 close-to-open 的强一致性,这在有些场合是不可接受的。
03 writeback 适用场景
尽管 writeback 模式存在一定风险,但它在提升写入速度方面具有显著优势。特别是在需要快速响应的写入场景中,如在写入大量小文件时,只要能够有效规避数据未及时写入对象存储以及异步上传导致的数据丢失风险,writeback 模式 是一种高效且实用的选择。用户可根据实际需求灵活使用。
以一个向 JuiceFS 的 numbers 中写入 1 万条数据的案例为例。若不开启缓存和写缓存直接写入数据,监控显示对象存储的 put 流量每次仅几百字节,put 延迟为20多毫秒,写入1万行数据约需两分钟,速度极慢。
当开启 writeback 模式后,put 延迟变化不大,但 put 流量实现了聚合,每次发送的数据量达到几万字节(如 21KB、70KB等)。此时,业务端 5 秒内即可收到返回,10 秒内就能完成数据传输,效率大幅提高。

在不同场景下,需要评估其风险点。写入任务慢的风险在于耗时久,期间业务变动可能导致数据问题;而先快速写完再聚合上传,虽然存在数据丢失风险,但耗时短。在真实案例中,这种效率差异可能从 5 秒扩大到 5 小时,这 5 小时内业务变动带来的风险不容忽视。
根据以上分析,我们总结了 writeback 模式的推荐场景:
- 频繁写入检查点的训练任务:例如,某些训练任务每小时写入一次检查点,写入时 GPU 需等待返回才能继续运行。开启 writeback 模式 后,即使机器故障且无法恢复,损失仅为一小时的训练数据,且故障概率较低。业务角度来看,写入后立即返回可以显著提高 GPU 利用率,减少等待时间。但如果一天只写入一个检查点,建议等待几分钟,确保数据写入对象存储后再返回,以保障数据安全。
- 用户开发环境:例如,在 AI 场景中,许多用户将 home 目录设置在 JuiceFS 中。若不开启写缓存,安装一个软件包可能需要三到五分钟;而开启 writeback 模式 后,安装时间可缩短至十几秒。由于这通常是个人目录,也很少有共享其他挂载点访问的情况存在,数据销毁风险较低,因此可以考虑开启 writeback 模式 来加速操作。
- 小文件多或临时解压文件的场景:例如,从 JuiceFS 拉取文件并进行解压时,涉及大量小文件的处理。开启 writeback 模式 可以显著提高解压速度,提升效率。
- 随机写入多的场景
关于 writeback 模式的应用,也可参考阶跃星辰在大模型训练场景中的实践。他们采用分布式文件系统 GPFS 作为缓存盘,并将 staging 目录也放在 GPFS 上,从而解决了数据安全性和数据不可读的问题。需要注意的是,GPFS 的节点数量不能过多,否则可能带来稳定性风险。尽管如此,收益非常显著:在 Checkpoint 数据写入过程中,启用 writeback 模式大幅提升了写入的容错能力和吞吐性能。
04 未来优化方向
在 JuiceFS 企业版 5.3 版本中,我们计划引入共享块设备概念,以替代单节点本地磁盘的写回模式。简单而言,就是一个块设备将被多个客户端同时挂载来作为 staging 目录,这样就可以满足 read-after-write 的一致性。而共享块设备通常为云盘,具备高可靠性,不易出现故障,可以有效解决数据访问一致性问题。
然而,共享云盘存在一定限制,一块云盘最多支持 16 个客户端挂载。为此,我们准备使用单挂载设备方案,即一台机器挂载设备,其他机器通过该机器读取数据,当有足够多的节点提供足够多的单挂载盘时,一定程度解决了数据热点问题,是一个值得期待的在对象存储之上的写加速方案。