残差网络(Residual Network,简称ResNet)诞生是为了解决深度神经网络的训练困难性问题。深度神经网络在图像分类等任务上取得了重大突破,但随着网络层数的增加,训练变得更加困难。
一、神经网络深度过深会出现哪些问题?
在2015年前后,尽管研究者们已经认识到深度神经网络在诸多任务中能够提供更强的学习能力和表达能力,但随着网络层数的增加,新的挑战也浮现出来。特别是,网络的训练变得异常困难,这主要是由于梯度消失和梯度爆炸 问题,导致模型性能在达到一定深度后不仅没有提升,反而可能下降,这种现象称为网络退化。
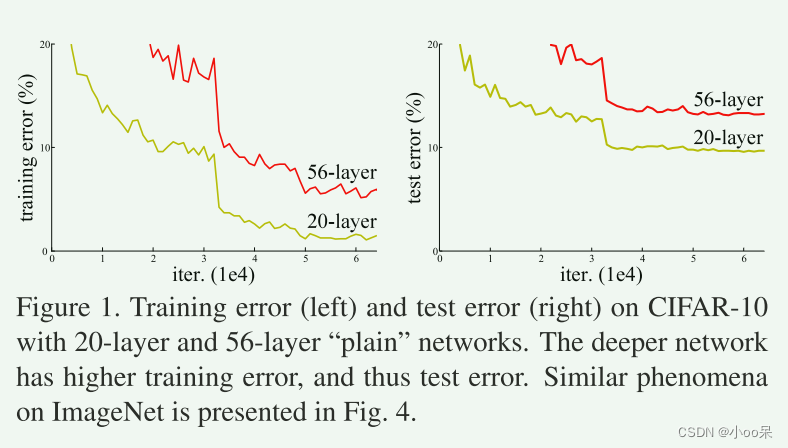 56层的神经网络误差反而比20层的大
56层的神经网络误差反而比20层的大
如图1,使用20层和56层"普通"网络的CIFAR-10上的训练误差(左)和测试误差(右)。更深的网络具有更高的训练误差,从而具有更高的测试误差。
关于什么是梯度消失和梯度爆炸,如果大家想了解详细知识点,可以点击下面的链接:
【机器学习300问】77、什么是梯度消失和梯度爆炸?![]() https://blog.csdn.net/qq_39780701/article/details/137976701
https://blog.csdn.net/qq_39780701/article/details/137976701
二、什么是残差网络?
ResNet的核心创新在于其独特的残差块(Residual Block)设计。所以要想知道残差网络是什么首先就得了解残差块的结构。
(1)复习一下没有残差的普通网络长什么样
拿一个两层神经网络进行举例说明。输入在第一层激活后得到
,由经过第二层后得到输出
如下图所示。
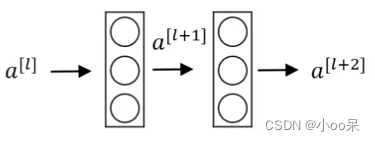 两层神经网络
两层神经网络
在这样一个网络中,从输入到输出一共会经过4个函数运算依次是:
1、第一层:线性函数
第一层线性函数加权后的输出用表示
2、第一层:激活函数
第一层激活函数的计算用表示
3、第二层:线性函数
第二层线性函数加权后的输出用表示
4、第二层:激活函数
第二层激活函数的计算用表示
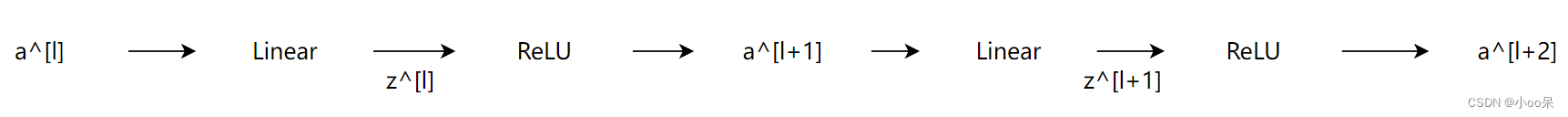 信息流动没有跳跃
信息流动没有跳跃
现在让我们把这两层神经网络中的计算函数用可视化的方式表示出来,如下图所示:
 普通网络(plain networks)
普通网络(plain networks)
(2)什么是残差块 Residual Block
每个残差块内部包含两条路径:一条 是常规的信号传递路径,包括一系列卷积操作;另一条则是快捷路径(skip connection),直接将输入跳过几层直接传递到后面,与经过卷积操作后的信号相加。
 信息流动发生跳跃
信息流动发生跳跃
这样的设计使得网络能够更容易学习到身份映射(即输入等于输出的映射),从而简化了学习任务,使得网络能够专注于学习残差(即输入到输出的变化),而非完整的变换。
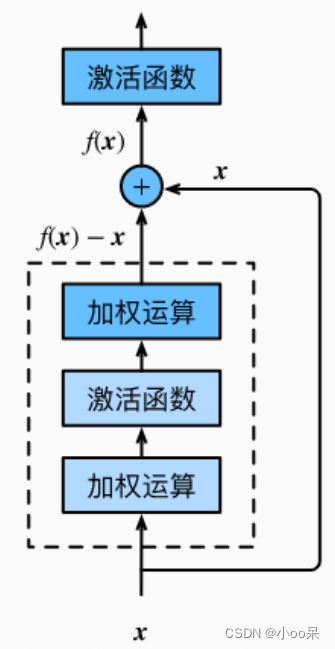 残差块(Residual Block)
残差块(Residual Block)
【注】跳跃连接的起点终点是很有讲究的,是将输入x加到第二层线性函数之后,ReLU非线性激活函数之前。
(3)残差网络的结构长什么样
上面的残差块里详细的表示展示了计算函数,如果我们不关心这些中间计算过程,那么一个残差块还可以表示成下面这样:
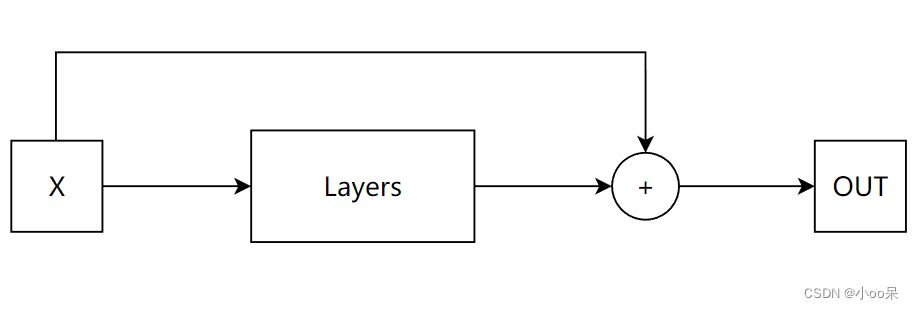 残差块简化表示
残差块简化表示
残差网络的整体模型结构,就是不断重复上面这个最简单残差块,通过堆叠多个这样的残差块,ResNet能够构建出非常深的网络架构,例如ResNet-50、ResNet-101、ResNet-152等。其中数字代表网络中的残差块数量或者总层数。
 残差网络的结构简单示意图
残差网络的结构简单示意图
来给大家看一下Residual Network原论文中何凯明大佬画的图:
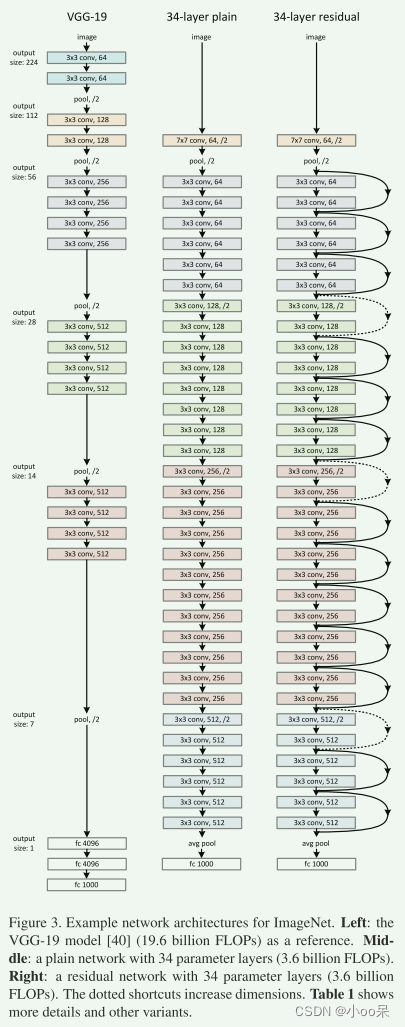
上图是残差网络论文中的配图,左边是VGG-19;中间是普通网络,有34个参数层;右边是具有34个参数层的残差网络。
三、残差网络是怎么解决这些问题的?
在传统神经网络中,每一层尝试直接学习从输入到输出的复杂变换。**而在残差网络中,我们换了个思路:不是直接学习输出相对于输入的变换,而是学习这个变换的"残差"部分,也就是输出相比于输入的改变量。**换句话说,如果能让网络学习到"怎么从上一层的输出更进一步",而不是"从头开始构想整个输出",事情就简单多了。
(1)解决梯度消失和梯度爆炸
通过引入捷径又叫跳跃连接(skip connections),残差块允许信息直接跨层传递,即使经过很多层后,最初的输入信号仍然可以影响到最终的输出,从而缓解了深度网络中的梯度消失问题。
(2)简化学习任务
网络可以更容易地学习残差函数(即输入到输出的小改变),而不是整个复杂的变换函数,这降低了学习难度,使得网络可以更深而不至于性能退化。
(3)提高训练效率
残差结构使得网络能够更容易收敛,并且能够训练出非常深的网络(例如152层),而不会遭遇性能饱和甚至下降的问题,从而在许多视觉识别、自然语言处理等任务上取得了显著的性能提升。
四、总结
残差网络的核心思想在于,如果新增的层不能学到比先前层更好的特征,它们至少可以通过捷径传递信息,不造成损害,相当于做了"无害旁观"。而当这些层能够学到额外有价值的信息时,它们就对原有特征进行了有效增强。
这样的设计鼓励网络进行有效的特征学习,而不会因为深度增加而退化。简单来说,残差网络通过设计允许网络专注于学习每个层级上真正需要改变的部分,从而克服了深度网络训练中的关键障碍。