高频原因:推理成本是落地最大障碍。
热门工具链:
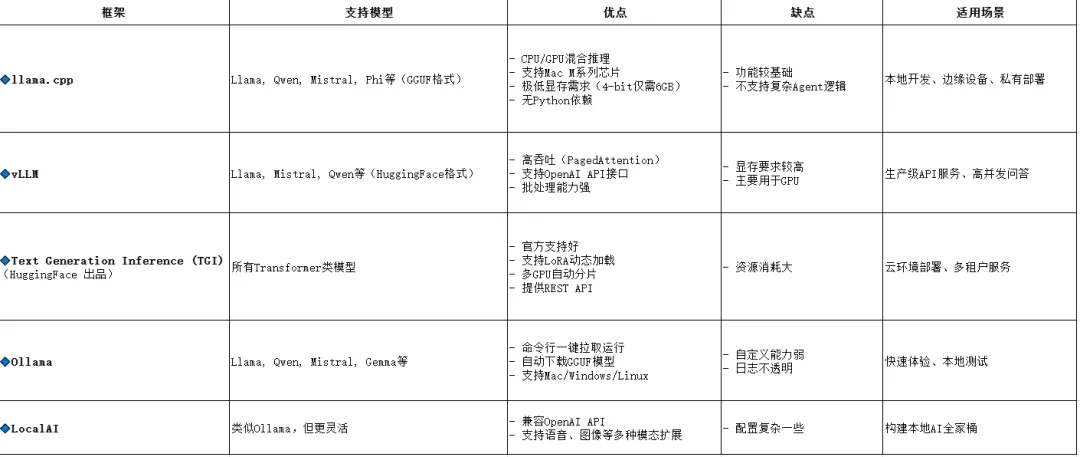
vLLM(高吞吐推理);
llama.cpp(CPU/手机端部署);
TensorRT-LLM(NVIDIA 优化);
Ollama(本地一键运行)。
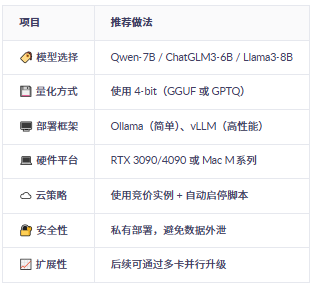
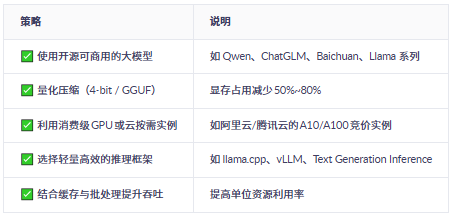
一、低成本部署的核心思路
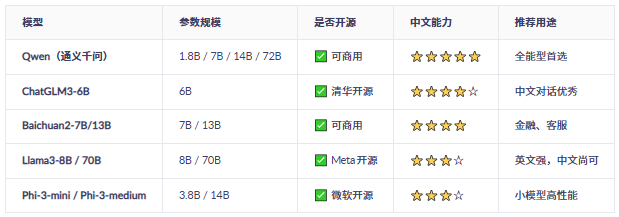
二、推荐的开源大模型(适合中文场景)
📌 建议:
中文为主 → 优先选 Qwen-7B / ChatGLM3-6B
成本极低 → 试试 Phi-3-mini(可在手机跑)
性能优先 → 上 Qwen-14B / Llama3-8B
三、推荐的开源部署框架(含对比)
四、硬件成本估算(以运行7B模型为例)


五、关键技术:模型量化(大幅降本)
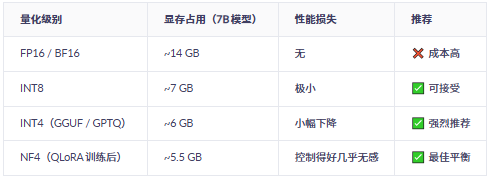
六、完整低成本方案推荐(三种模式)
方案 1:【个人开发者】本地运行(零成本)
工具:Ollama 或 llama.cpp
模型:qwen:7b-q4_K_m
硬件:MacBook Pro / Windows游戏本
成本:¥0(利用现有设备)
场景:学习、写作辅助、代码补全
方案 2:【中小企业】私有化部署(万元内)
模型:Qwen-7B + LoRA微调
框架:vLLM 或 TGI
硬件:一台 RTX 3090 服务器(二手约 ¥8,000)
部署:Docker + Nginx + HTTPS
成本:一次性投入 < ¥1.5万,后续接近零成本
方案 3:【按需使用】云端弹性部署
平台:阿里云 / AWS / Lambda Labs
实例:A10/A100 竞价实例(¥3~6/小时)
框架:vLLM + FastAPI
用完即停,按秒计费
成本:每天运行4小时 ≈ ¥100/月
总结:低成本部署 checklist