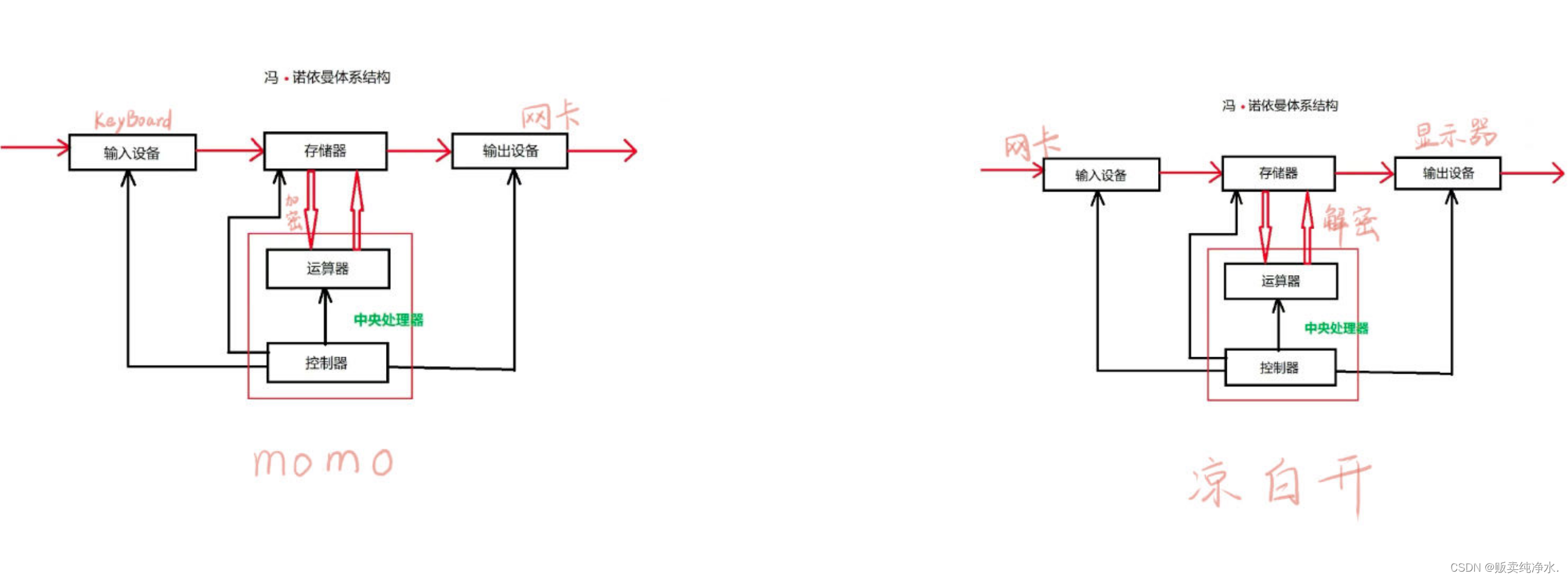
冯·诺依曼体系结构
一个计算机在工作的时候是怎样的呢?
我们所认识的计算机都是由一个个的硬件组件组成:
输入设备:键盘、鼠标、摄像头、话筒、磁盘、网卡
中央处理器(CPU):运算器、控制器
输出设备:显示器、声卡、磁盘、网卡
是不是大家通常会觉得计算机是这样设计的:
但其实并不是,计算机是遵循冯·诺依曼体系结构来设计的,增加了个设备:存储器(内存)

量化概念:
CPU:纳秒
内存:微秒
设备:毫秒
它们基本上的速度差别就是
、
冯·诺依曼体系是一种架构构成,设备是相互链接的,数据的流动本质是从一个设备传输到另一个设备的过程,数据是要在计算机的体系结构中进行流动的,流动过程中进行数据的加工处理
从一个设备到另一个设备的本质是一种拷贝,数据在设备间拷贝的效率决定了计算机整机的基本效率(主要矛盾)
CPU计算的速度肯定很快
存储金字塔
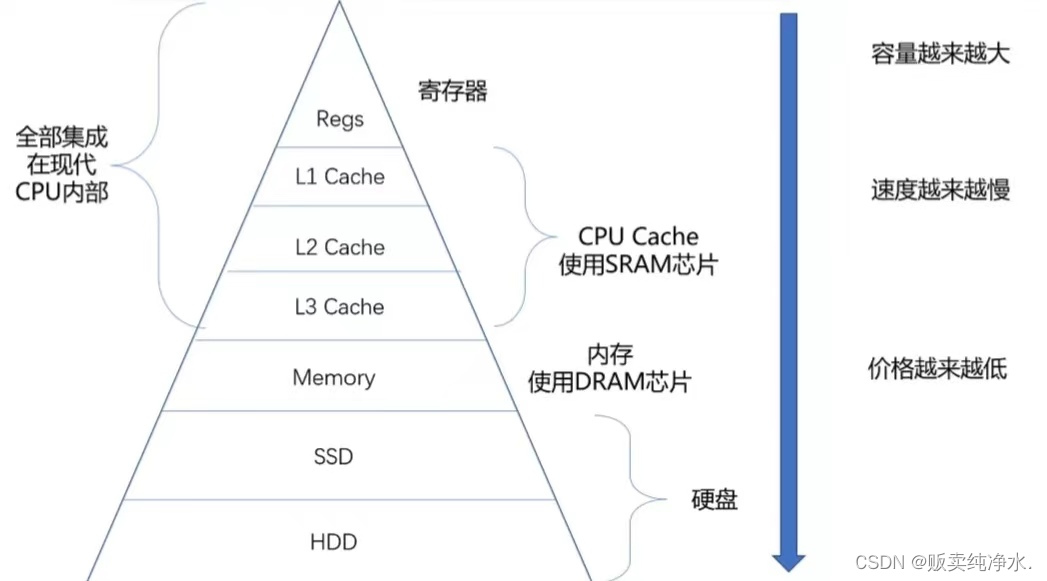
存储结构距离CPU越近,效率越高,成本越高
比如寄存器,速度很快,离CPU近,造价高
计算机的存储架构不是这样就很显而易见咯:
根据木桶原理,若是这种体系结构,那太慢了(能盛水取决于最短的木板)
CPU大部分时间不是在算,而是在等(等输入设备把外部数据拷过来,等着把数据拷给输出设备)
计算机的基本效率取决于输入和输出设备,冯·诺依曼架构的设计将计算机从毫秒级别拔高到微秒级别
利用冯·诺依曼体系架构设计计算机快慢就取决于存储器了,存储器是一个巨大的缓存,可以很大程度上提高效率
那假设,我是土豪我有钱,我就用寄存器,我所有的硬件都用寄存器,硬件工程师,你做是不做?
老板大气,这台计算机五百万卖你,但又不是所有人都像你一样有钱
各个体系架构存在是必要的,创新带来范围影响,技术上突破,传播上普及(历史意义)
做个简单的总结
在硬件流动角度:
1.在数据层面,CPU不和外设直接打交道,只和内存打交道
2.外设(输入和输出)的数据不是直接给CPU的,而是先放入内存中
那程序的运行为什么要加载到内存中?
程序=代码+数据,需要被CPU访问、执行,而CPU只会从内存中读取代码和数据(冯·诺依曼体系规定这么做)
程序没有被加载到内存的时候在哪里呢?
是磁盘(外设)上的一个普通二进制文件
还是来举个栗子吧:
已知墨墨酱(IP北京)是一个超绝程序员,她觉得通信是一件很神奇巧妙的事情,某天她在QQ上认识了一位朋友凉白开(IP湖北),正所谓君子之交淡如水,于是墨墨酱打招呼的第一句话是:你好!
那么在这个过程中,消息是怎样流动的呢?
既然对方用电脑,我也用电脑,那么我们两个本质就是两个冯·诺依曼体系(软件玩的再怎么花,硬件必须这样流动)
操作系统
概念
首先,操作系统是一款软件,是一款进行软硬件资源管理的软件
广义:操作系统内核+操作系统外壳周边程序(给用户提供使用操作系统的方式)
狭义:操作系统的内核
架构
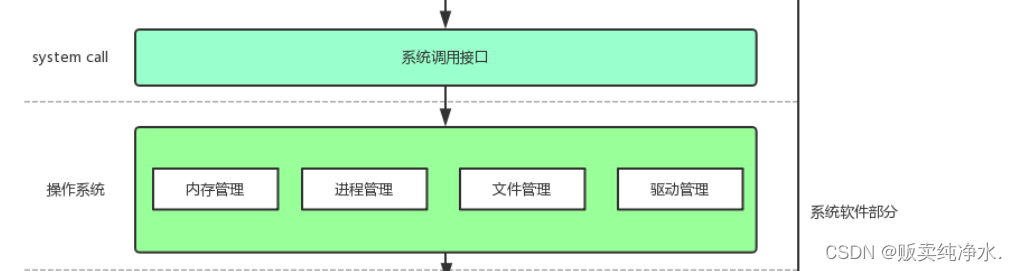
既然操作系统可以管理硬件,那一定是可以被操作系统访问的,每一种硬件的物理特性肯定不同,如果由操作系统直接访问硬件,则一旦硬件发生变化,操作系统就要响应的做出改变,所以增加了操作系统与硬件层中的驱动层(软件,每一种硬件都有自己的驱动层),大部分驱动层都是由厂商自己提供的

体系架构的层状划分
在我们外接设备的时候,比如键盘,鼠标,但是当接入电脑的时候会显示驱动程序正在启动,大约等个一两秒才能动
存在意义
操作系统对软硬件资源进行管理(手段),为用户提供一个良好的运行环境(目的)
以人为本,工具
操作系统对下提供基本的管理工作,让各种硬件工作在一个稳定的,高效的,安全的状态当中。(针对计算机,手段)
操作系统对上要提供一个高效的稳定的,安全运行环境(针对用户,目的)
理解
操作系统中的"管理"是什么概念呢?
拿简单的学校来举个例子,墨墨酱是一所学校的校长,校园中存在着很多角色:校长、主任、老师、学生...
我们在完成一件事的时候,离不开两个动作:
1.决策
2.执行
管理者之所以被称作管理者是因为他的任务绝大多数和决策有关
学校里真正的管理者是校长,被管理者是学生,中间夹杂着一层角色:辅导员(可是灿灿,人生是旷野~)虽然校长是管理者,但是我们平常基本上没机会见到他(他不会早上一脚踹开我的房门叫我起床上早八)
好管理不需要管理者和被管理者直接接触,可是不直接接触又是怎样进行管理的呢?
见面不是目的,拿到数据才是目的!
管理的本质不是对人的管理,而是对人身上的数据进行管理!
但是校长见不到学生又是怎样拿取数据的呢?
当然是引进一个中间角色:辅导员
校长关心的是学生,而不是某个人
校长关心学生的成绩,绩点,参加竞赛情况...不关注学生爱吃啥最近谈恋爱了没有...
随着被管理同学的增多,人的信息也变多,校长难于管理
前文说过墨墨酱前身是程序员,会敲代码,给上面的问题作总结就是:关心的属性类别是相同的,属性值不同
cpp
struct stu
{
char name[16];
char sex;
int age;
...
int Math;
int Chinese
double English
...
double score
struct stu* next;
}将表格转化成结构体,这个过程叫:面向对象!
cpp
struct stu* zhangsan = new struct stu{...};对于任何管理,我们都先描述,再组织,上面的由日常校长对学生的管理工作变为对链表的增删查改是完成了对学生管理工作的计算机建模的过程
拿STL来举例,本质是C++的一种容器,容器的本质就是数据结构,对数据结构进行封装,封装的本质描述对象,是对STL的组织分析
Linux理念一切皆文件,C++理念一切皆对象
特定对象直接先描述再组织,那操作系统对于硬件怎么管理捏?

还是先描述再组织,对设备的管理变成对链表的增删查改
讲个故事,墨墨酱是一个大学牲,她有一天去银行办理业务,银行的职员很多,有放贷的,有存款的,有和企业对接的,有接待大用户的...
她想要建立自己的小金库,她要存一百块,银行肯定不允许墨墨酱自己存(那像什么话),银行不相信任何人,群众里面也有坏人,银行又必须执行它的任务,发挥它的作用,那银行怎样在保证自身系统安全的情况下为用户提供服务呢?
可以用柜台实现人办理业务,用户把身份证和银行卡递交,交给银行的工作人员办理业务

操作系统内部涵盖属性结构 ,如果用户非法入侵篡改,对操作系统的影响是致命的,操作系统也不相信任何人,但要为用户提供业务,所以它为用户提供软件层(系统调用),不能直接进入,系统调用(操作系统提供的函数)保证用户调用接口传参,操作系统自己进行操作再返回给用户,会让操作系统处于稳定的状态,进程状态就是处理大量的系统调用接口
因为操作系统不信任用户,内核是用C写的,所以就为用户提供了大量的系统调用接口,用成员函数的方式访问类属性(成员函数是类对外提供的接口)
对于银行我想说,银行是一个庞大的机构,它不仅可以做到为普通用户提供业务,还要为特殊用户提供业务,比如老燃已经七老八十了,不识字,想给孙子暖暖存一千块压岁钱,银行职员怎么应对这样的特殊用户呢?
银行为了更好地给老燃这样的人提供服务,银行不仅设置窗口柜台,在大厅也会设有咨询工作人员

老燃去银行历险,大厅工作人员直呼内行,直接帮扶老燃完成所有业务(暖暖也是有钱花了)

(其实是委托算命)大堂经理直说:老燃,我帮你叫号,你写啥资料我可以代写,您歇着就行!
大堂经理和算命说,你,去帮老燃弄后面的事情!
算命接收了这个任务,完成了这个任务,帮助老燃这样的弱势群体也能进行存款取款业务办理
映射到操作系统这边就是,操作系统调用是操作系统提供的接口,有些难以理解,需要会一些知识,不适应大众使用,于是用户操作接口应运而生(为了方便老燃这样的特殊人士也能使用),这些库我们也早就接触过:C/C++标准库
我们一直都在用,之前已经说过,链接有动态链接有静态链接,这条命令可以查询某个可执行程序都用到了哪些库:
bash
ldd 文件名
/lib64/libc.so.6就是传说中的C语言的动态库:

其实我和老燃也差不多,历史上并没有直接使用过系统调用,都在用用户操作接口,所有动作都是用库来做的(用C/C++的动态标准库来做)
如果要自己实现一门编程语言,那这三剑客必不可少:语法、标准库、编译器
这样以后就直接用库而不用系统接口的(安装VS的时候一方面在安装编译器,一方面在安装标准库、开发包)
操作系统不同,提供的接口不同(函数名,参数,返回类型...)在用户层若直接使用系统调用接口,那在 Linux下所写的代码只能在Linux下编译运行,无法在Windows下编译运行(由于系统调用接口不同),但是若使用用户操作接口就都能运行(在Windows下打印用printf,Linux下亦然),底层差异上层看不到,用起来就很方便(跨平台性)
这部分可以被称作比较完备的操作系统:
进程
什么叫做进程呢?打开Windows任务管理器(Ctrl+Shift+Esc),这些都是进程:

操作系统中,进程可以同时存在非常多,所以操作系统肯定要管理进程(先描述,再组织)
进程
课本概念:程序的一个执行实例,正在执行的程序等
内核观点:担当分配系统资源(CPU时间、内存)的实体
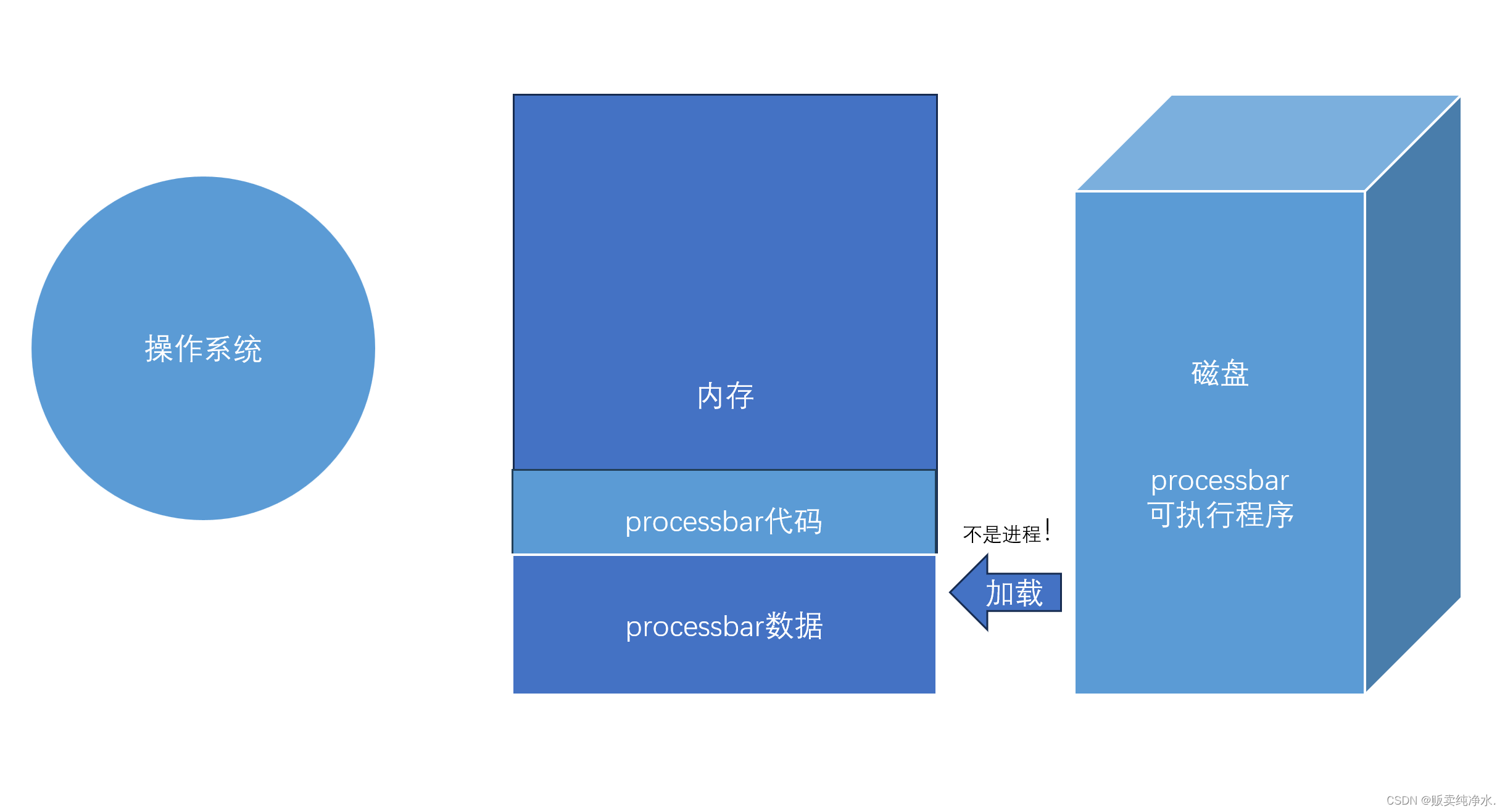
在这里processbar 是一个二进制文件,运行起来就可以被称作一个进程
那processbar在没有加载时在哪里呢?
在磁盘里!描述图解:
每个进程创建时都会有一个对应的struct PCB:
cpp
struct PCB
{
//所有属性
struct PCB* next;
//内存指针(指向自己的代码和数据)
//一个进程一个PCB
//进程=代码、数据+PCB
}这样以后对进程的管理就变成了对链表的增删查改
PCB
概念
PCB,江湖人称process control block(进程控制块),就是描述一个进程的结构体,这个数据结构是操作系统内部管理进程的内核数据结构(操作系统的数据结构)
操作系统是软件,使用(开机)的过程就是在加载操作系统,操作系统在没开机的时候也是存在磁盘的二进制文件一枚~开机是讲操作系统加载到内存中的过程,操作系统是计算机启动时加载的第一个软件,进程不仅需要讲可执行程序的代码和数据加载到内存中,还要操作系统malloc结构体PCB出来(一个进程有一个PCB,对进程的管理变为对PCB的管理)
学校管理学生,那怎么证明我是邮专的学生呢?(门禁刷不进来,只有赔笑脸才能刷进来,我已经被邮专开除了)
有人说:那就看在没在校内呗,在校内的肯定是学生啊,保安大叔应如是,保洁阿姨有话说,宿管阿姨呼内行,和人无关,决定这个的是人的属性信息是否在学校的教务管理系统内(学校==内存)
操作系统=教务管理系统
怎么证明是一个进程呢?
学生的属性信息存到教务系统中相当于PCB在操作系统内部,使用指针将PCB连接起来,将PCB管理好相当于将进程管理好了,对进程的管理也就变成了对链表的增删查改(并不是直接将可执行程序加载进来,而是管理PCB)
存在意义
为什么要有PCB捏?
因为OS要对进程进行管理(先描述,再组织)
进程=内核task_struct结构体+程序的代码和数据
Linux是一款操作系统,而PCB是操作系统这个学科下的概念,Linux下PCB(进程控制块)具体的结构是:
cpp
struct task_struct
{
//Linux进程控制块
}举个栗子吧:墨墨酱是一名大学生,她今年已经大三了,该去实习界闯荡一番了,她去慢手、丑团、饱了么、字节跳动不了一点投递简历,算命、暖暖、燃燃,笙宝也要把简历投给这些大厂,这投递的本质并不是把人交给公司,而是将简历投了过去,而每个人对应的简历就是描述每个人的task_struct,简历放成一摞,面试官一个一个看的过程本质上就是简历在排队,简历在排队也就相当于人在排队
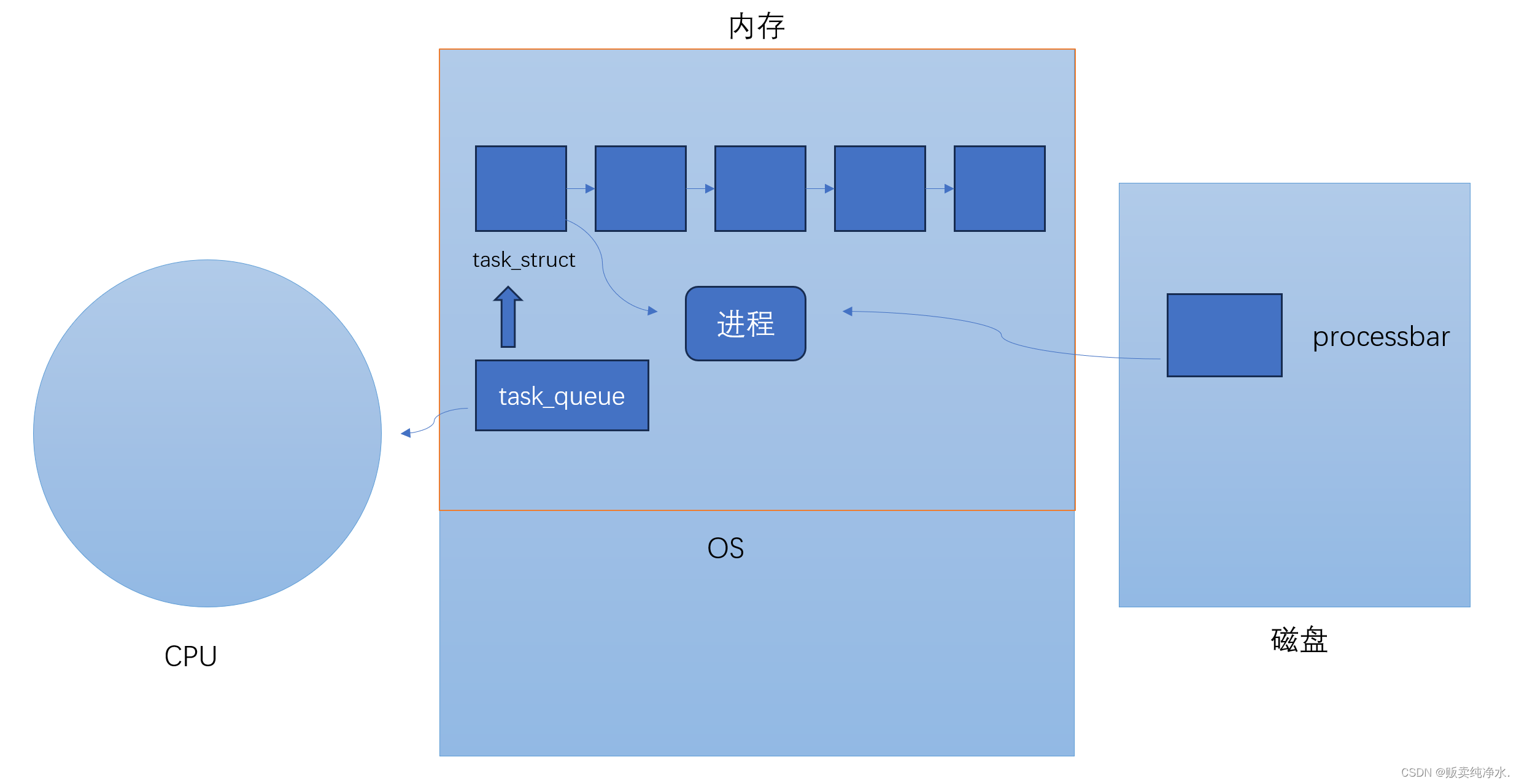
调度运行进程本质就是让进程控制块task_struct进行排队
对于进程,进程的代码和数据相当于进程的实体,管理是在管理进程的task_struct(task_struct是进程的简历),对应聘者的操作变成了对简历的增删查改,这就是进程控制块存在的意义
理解
课本上常说:进程是动态运行的,怎么理解这个概念呢?
应聘面试流程:投简历 --> 笔试 --> 一面 --> 二面 --> 三面
持续周期可能2~3周,,并不是人在周转,而是简历在被一二三轮面试官拿到,这个过程叫动态面试,而对于进程来讲,进程一会被放到运行队列里被CPU运行、一会在等待显示器、键盘、磁盘、网络资源,进程动态运行的特点主要体现在CPU或其他设备想要被进程访问执行时,都是以PCB为代表被来回调度运行的,只要进程的task_struct在不同的队列中,进程就可以访问不同的资源(PCB结点被放到不同地方了)
PCB是进程的简历,包含进程的诸多属性,可以来学习下:
task_struct属性
启动
./xxxx运行某个程序本质就是让系统创建进程并运行
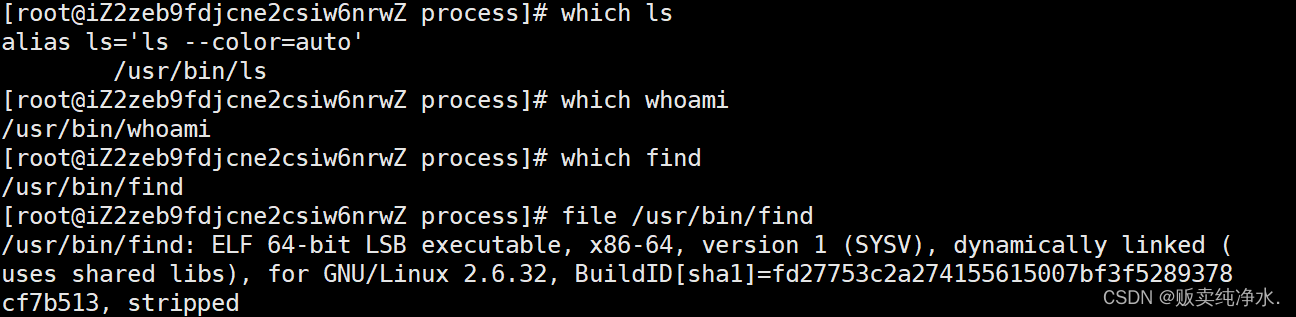
之前学过的命令也是可执行程序,比如上面的这个find是x86-64位下的一个可执行程序
自己的程序本质上也是x86-64位下的一个可执行程序

我们自己写的可执行程序、系统的命令都属于可执行文件,在Linux中运行的大部分执行操作本质都是运行进程
那该怎样查看进程呢?
用这条命令:
bash
ps axj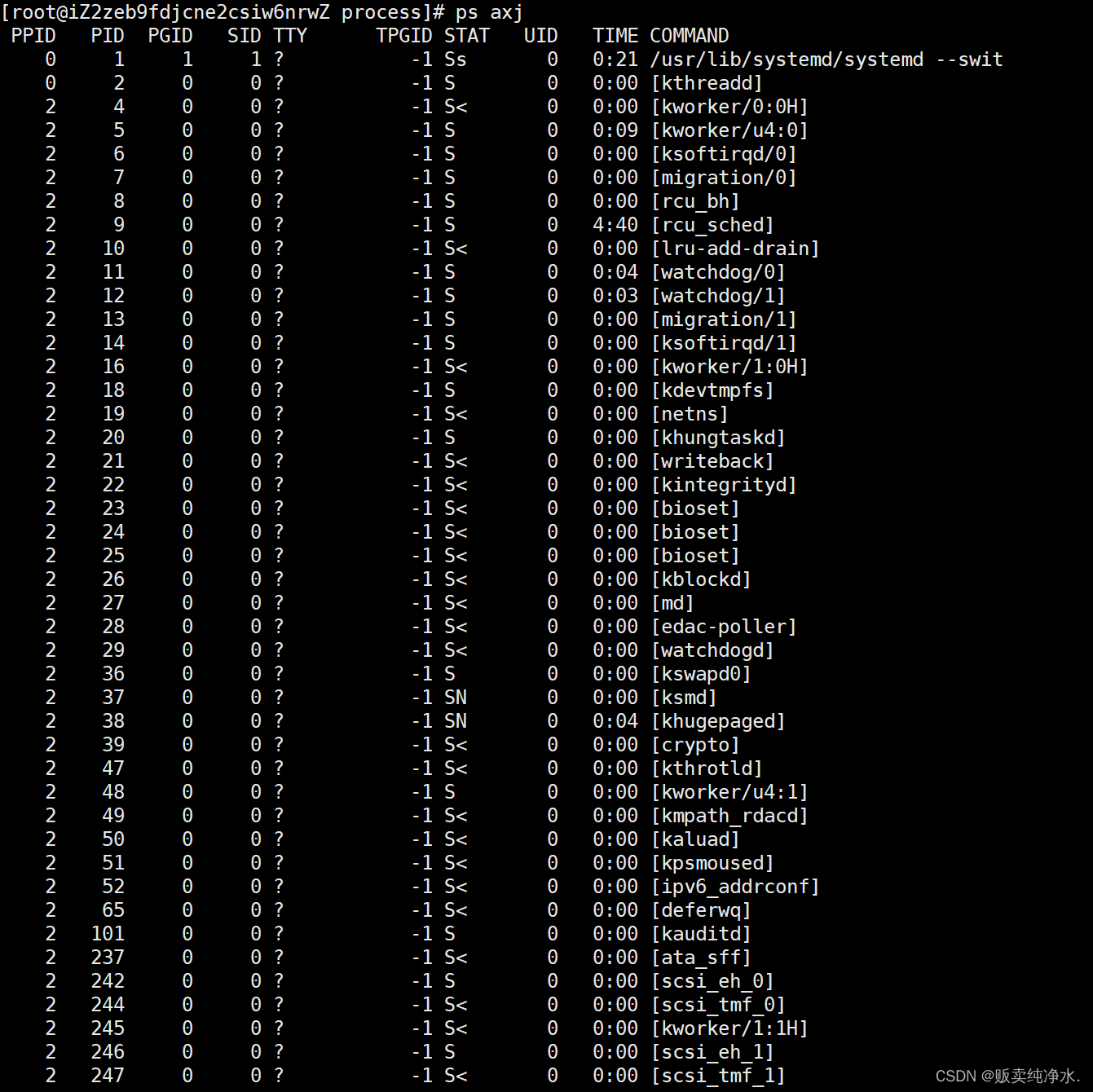
这样是查所有进程,如果想查询特定的某个进程,那就:
bash
ps axj | grep myprocess
为什么这里还带了grep?
通过管道和关键词检索的方式查出了指定进程,grep本身也是一个进程,所以也被检索出来了
那每一列都是什么含义呢?
这样查,将首行解释列出:
bash
ps ajx | head -1两条命令的同时执行连接用&&
bash
ps ajx | head -1 && ps axj | grep myprocess
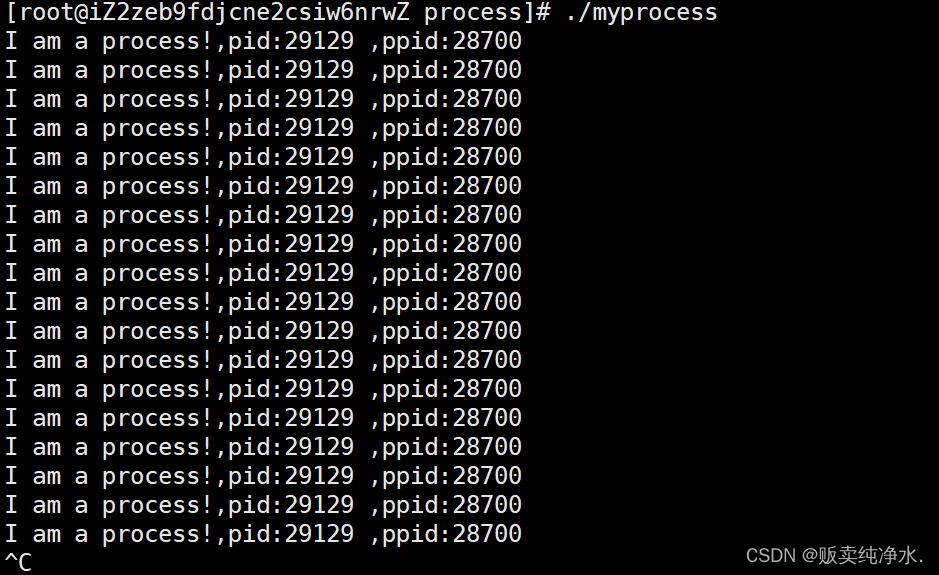
每一个进程都要有自己的唯一标识符,叫做进程pid(和学生学号一样),进程PCB唯一,区分用unsigned int pid
如果一个进程想要知道自己的pid该怎么办呢?
struct task_struct被称为内核数据结构,用户是不能直接访问操作系统内部内核数据结构的pid的,那么用户该如何获得进程的pid呢?
需要操作系统为我们提供系统调用

myprocess.c:
cpp
#include<stdio.h>
#include<unistd.h>
#include<sys/types.h>
#include<unistd.h>
int main()
{
pid_t id = getpid();
while(1)
{
printf("I am a process!,pid:%d\n",id);
sleep(1);
}
return 0;
}运行一下可以看到进程的pid:

这样可以查到确实是这个进程的pid
bash
ps axj | head -1 && ps axj | grep myprocess 
在Windows中双击可以启动进程(点开这个.exe文件,我们中国人有自己的打金服,别管我闲的没事养蛊玩)
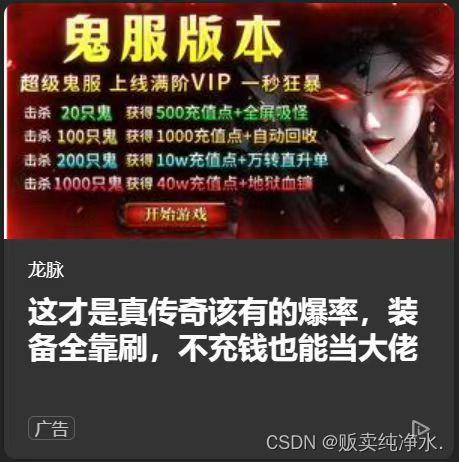























在Linux下启动一个进程就是./执行可执行程序,既然进程已经启动,那就当然可以用ps命令来查找进程,那假如想要终止进程该怎么做呢?
之前说过,有事无事无脑Ctrl+C一下(在用户层面终止进程),乖乖停下哩:

还有一计:

每个进程pid唯一,所以可以这样结束进程:
bash
kill -9 18318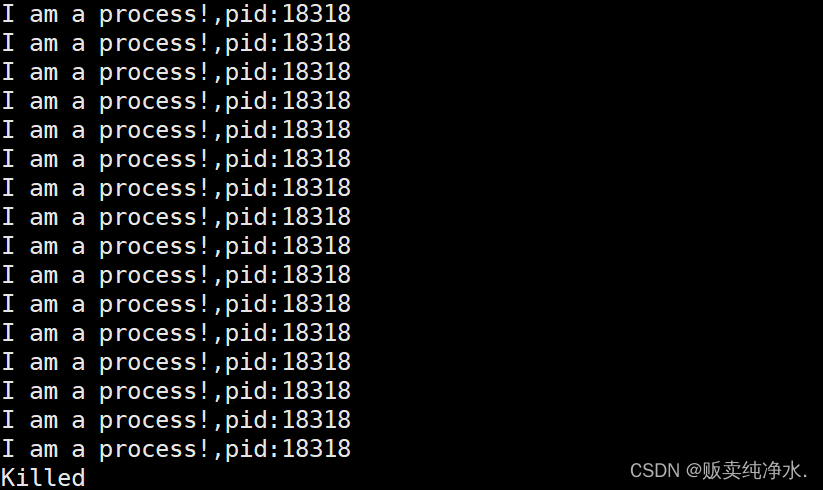
进程创建的代码方式
来看这张图吧:
getpid我知道是啥意思了,那getppid是啥意思呢?
第一个p:parent,第二个p:process
bash
pid_t getppid(void);
cpp
#include<stdio.h>
#include<unistd.h>
#include<sys/types.h>
#include<unistd.h>
int main()
{
pid_t id = getpid();
pid_t parent = getppid();
while(1)
{
printf("I am a process!,pid:%d ,ppid:%d\n",id,parent);
sleep(1);
}
return 0;
}所以它的意思就是获取父进程的id
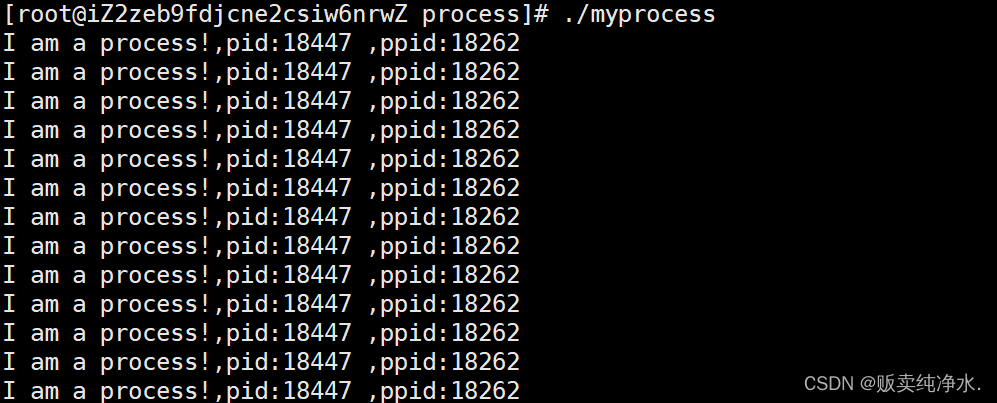
这样查询:
bash
ps ajx | head -1 && ps axj | grep myprocess
进程每次启动时pid都不同,这正常吗?
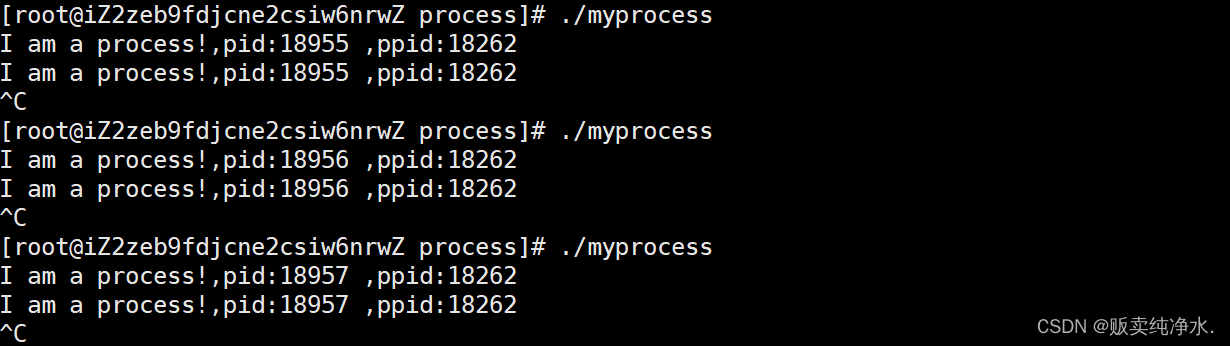
那很正常呀,笙宝是一个热爱学习的小男孩,他第一次高考完报了清华的通工专业,但是念了半年感觉不太对劲,于是去找道士switch算了一卦,switch说他命中多水,星盘为火,遇土木则吉,于是笙宝痛定思痛,复读一年终于考入了梦寐以求的清华土木工程,功德圆满,那清华给他两次发的学号不一样不也很正常嘛(进程每一次运行的时候pid不一样)
我们同样可以看到,每次运行的时候ppid是一样的(父进程都是同一个)那18262是谁呀?
bash
ps ajx | head -1 && ps ajx | grep 18262查一下捏:

Bash就是父进程,命令行解释器,不知道的可以先看看这篇燃冬:
Shell命令及运行原理-CSDN博客![]() https://blog.csdn.net/chestnut_orenge/article/details/137106046实习生==紫禁城(子进程)
https://blog.csdn.net/chestnut_orenge/article/details/137106046实习生==紫禁城(子进程)
创建一个进程是否代表着操作系统内多了一个进程?
是这样的捏,那多了一个进程就相当于多了一份PCB和一套该进程对应的代码和数据
创建一套进程会创建PCB(内核数据结构),可是用户是没有权限对内核数据结构进行增删查改的,用户不能直接创建个task_struct,操作系统需要为用户提供系统调用!
浅查一下呢?
bash
man fork
可以发现它不仅有叉子的意思,还有岔路,分支的意思,它作用的解释就是:
bash
fork - create a child process创建一个紫禁城
cpp
#include<stdio.h>
#include<unistd.h>
#include<sys/types.h>
#include<unistd.h>
int main()
{
printf("process is running,only me!\n");
sleep(3);
fork();
printf("hello world\n");
sleep(5);
return 0;
}这是一个监控小脚本:
bash
while :; do ps ajx | head -1 && ps axj | grep myprocess | grep -v grep; sleep 1; done这样可以实时监控进程咯:

刚开始启动的进程:19137一定是父进程, 通过调用fork看到了两个执行流,查到了两个不同的进程,有两个不同的pid(19156就是传说中的紫禁城),在fork之后,父子代码共享:创建一个进程,本质是系统中多了一个进程,多了一个进程就是多了一个task_struct进程控制块,多了的进程还要有自己的代码和数据,那紫禁城的代码和数据从哪来呢?父进程的代码和数据是从磁盘加载进来的,在默认情况下,紫禁城继承父进程的代码和数据(紫禁城没有代码和数据,只能继承,只有自己的task_struct)
cpp
#include<stdio.h>
#include<unistd.h>
#include<sys/types.h>
#include<unistd.h>
int main()
{
printf("process is running,only me!,pid:%d\n",getpid());
sleep(3);
fork();
printf("hello world,pid:%d,ppid:%d\n",getpid(),getppid());
sleep(5);
return 0;
}

可以看到执行进程一个是父,一个是子
我们可以通过这样的的代码来查看进程运行状况
我们为何执着于创建紫禁城?父进程一个人不足以吗?
主要是因为我们想让紫禁城执行和父进程不一样的代码,这方面还需要来学一下fork的返回值,,,
cpp
pid_t fork(void);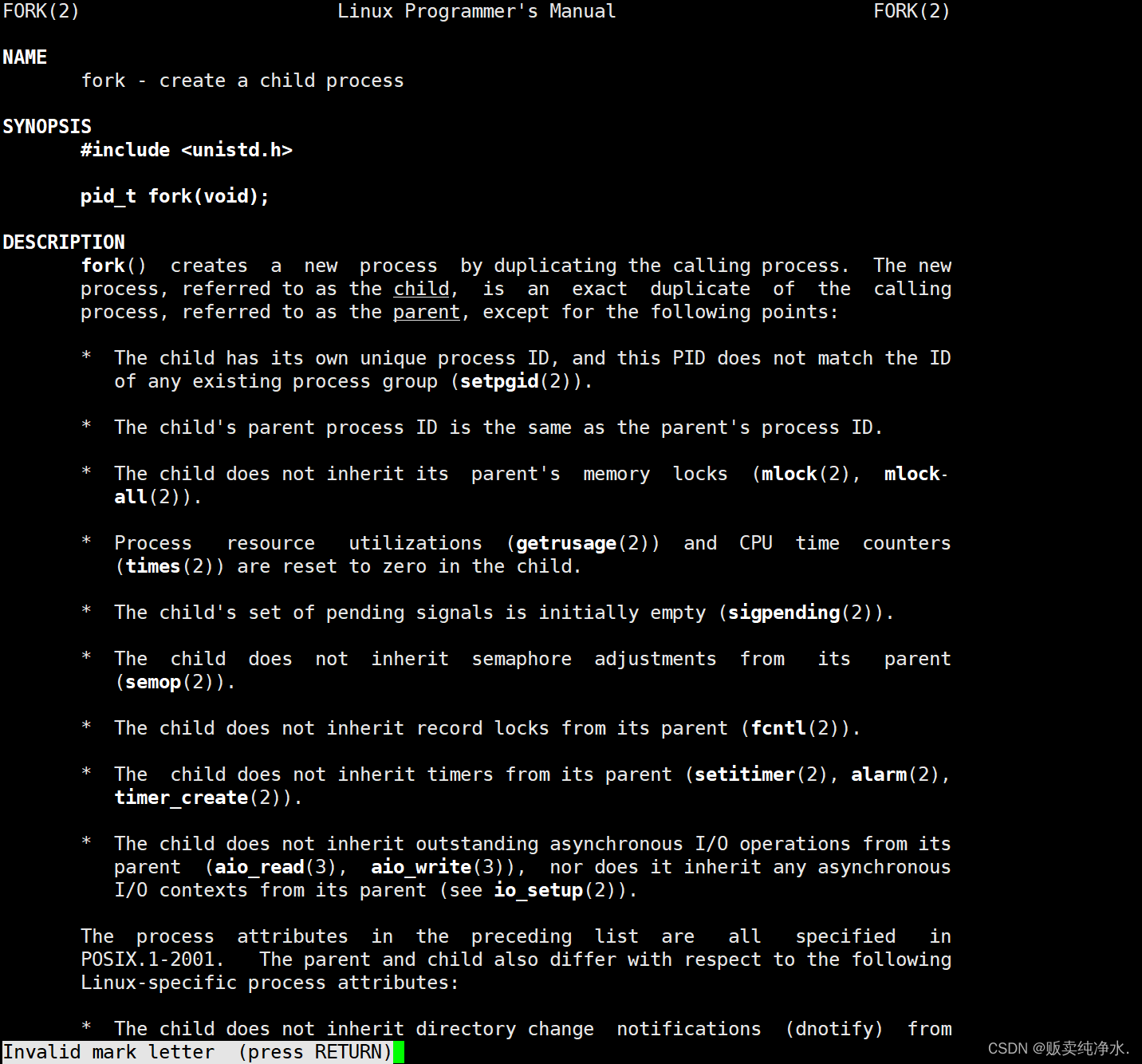
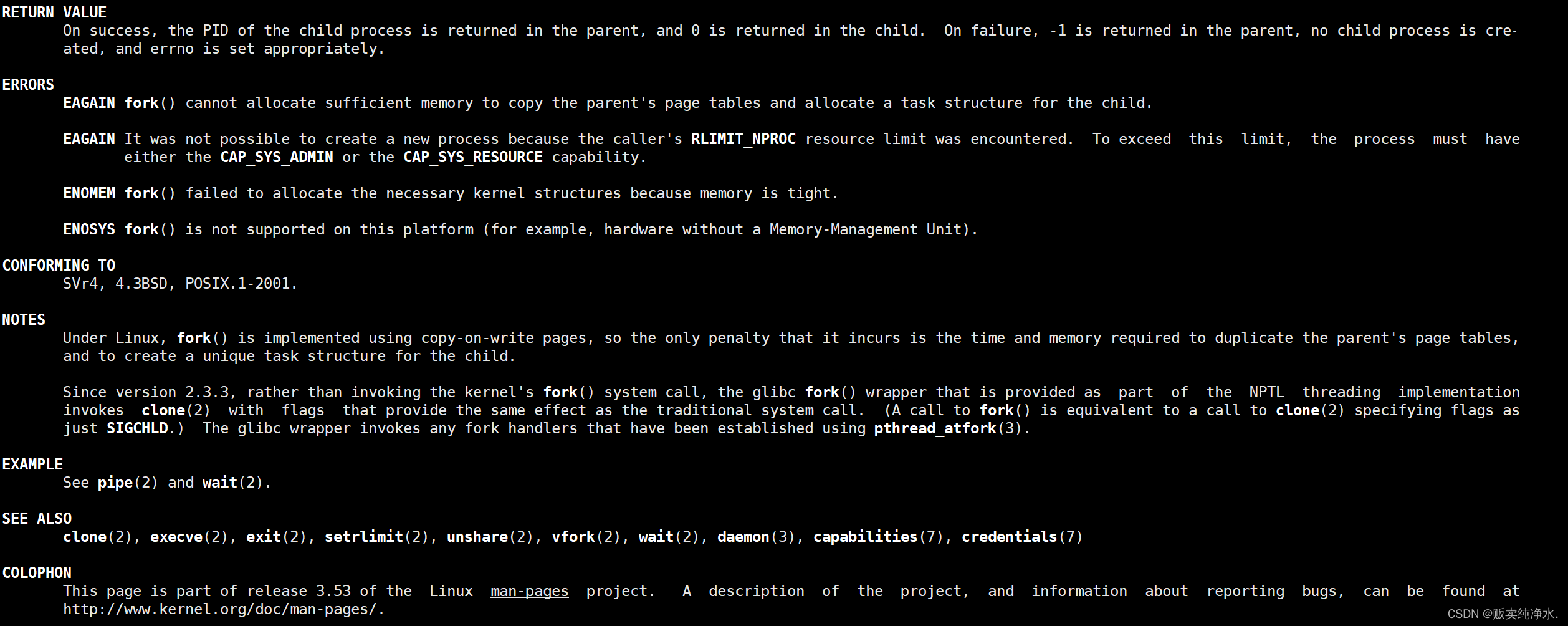

如果fork函数成功了,则它会返回紫禁城的pid给父进程,返回0给紫禁城,如果创建失败则返回-1,错误码被设置,也就是说fork会返回两次,每次不同的返回值
cpp
#include<stdio.h>
#include<unistd.h>
#include<sys/types.h>
#include<unistd.h>
int main()
{
printf("process is running,only me!,pid:%d\n", getpid());
sleep(3);
pid_t id = fork();
if (id == -1) return 1;
else if (id == 0)
{
//child
while (1)
{
printf("id:%d,I am child process, pid: % d, ppid : % d\n",id,getpid(),getppid());
sleep(1);
}
}
else
{
//parent
while (1)
{
printf("id:%d,I am parent process,pid:%d,ppid:%d\n",id, getpid(), getppid());
sleep(2);
}
}
return 0;
}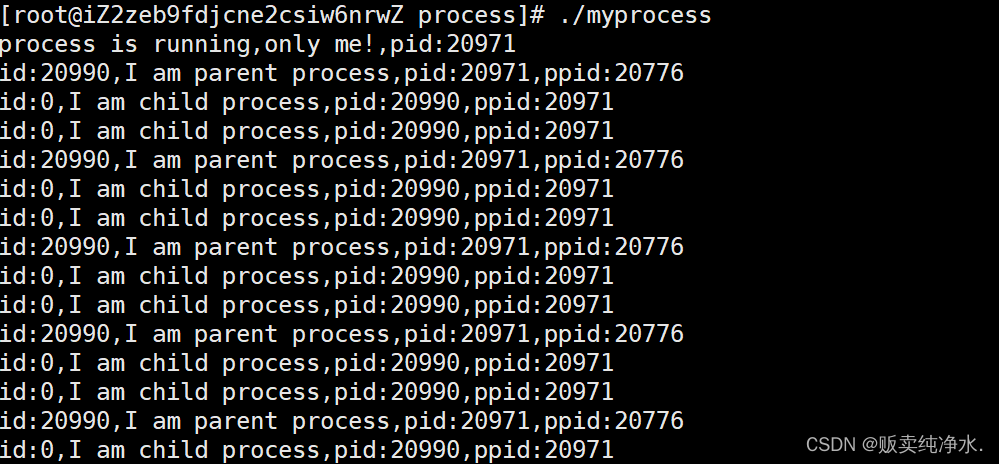
浅浅来解释下:fork之后,父子进程的代码都是共享的
对于id=0是给紫禁城的,id=紫禁城pid是给父进程的,因为是分支结构,所以进入到两个分支,实现父子进程同时跑,但是你看代码,在之前的学习中肯定是不可能出现两个while循环同时跑的情况的(以前学的全部都是单进程,多进程情况也是适用的)再想想,同一个id值,为什么又>0又=0啊,教练教教我?
fork会有两个返回值,返回两次,怎么理解啊?
首先fork()是一个函数,只不过是由操作系统(OS)提供的,会有自己的实现逻辑,会有return id,那当我们的函数执行到return的时候,是否意味着函数的核心工作已经完成?
对啊!
我们今天要执行的函数是fork(),紫禁城已经存在了,而且已经可以被调度了
那return是代码么?
肯定是啊!
fork内部前半部分由父进程创建紫禁城,执行到return的时候已经有两个进程了,代码共享,父进程执行一次return,紫禁城执行一次return
孩子们,这并不奇怪
tips:kill掉紫禁城不会影响到父进程


那同一个id即>0又=0是怎么会事呢?
紫禁城在创建的时候要有自己的PCB,这个PCB在数据结构层面与父进程的PCB是并列的,在逻辑上是存在父子关系的,父进程的代码和数据都是从磁盘上加载进来的,紫禁城继承父进程的代码和数据,紫禁城肯定也要用父进程=的数据对吧
进程一定要做到:
进程具有独立性(哪怕是父子的亲密关系)
进程 = 内核数据结构task_struct + 代码(只读,不可被修改)和数据
数据在原则上要分开独立,出于对效率的考量,父子的id有独立的数据的,只不过是共同用了id这个变量名,内容是不一样的
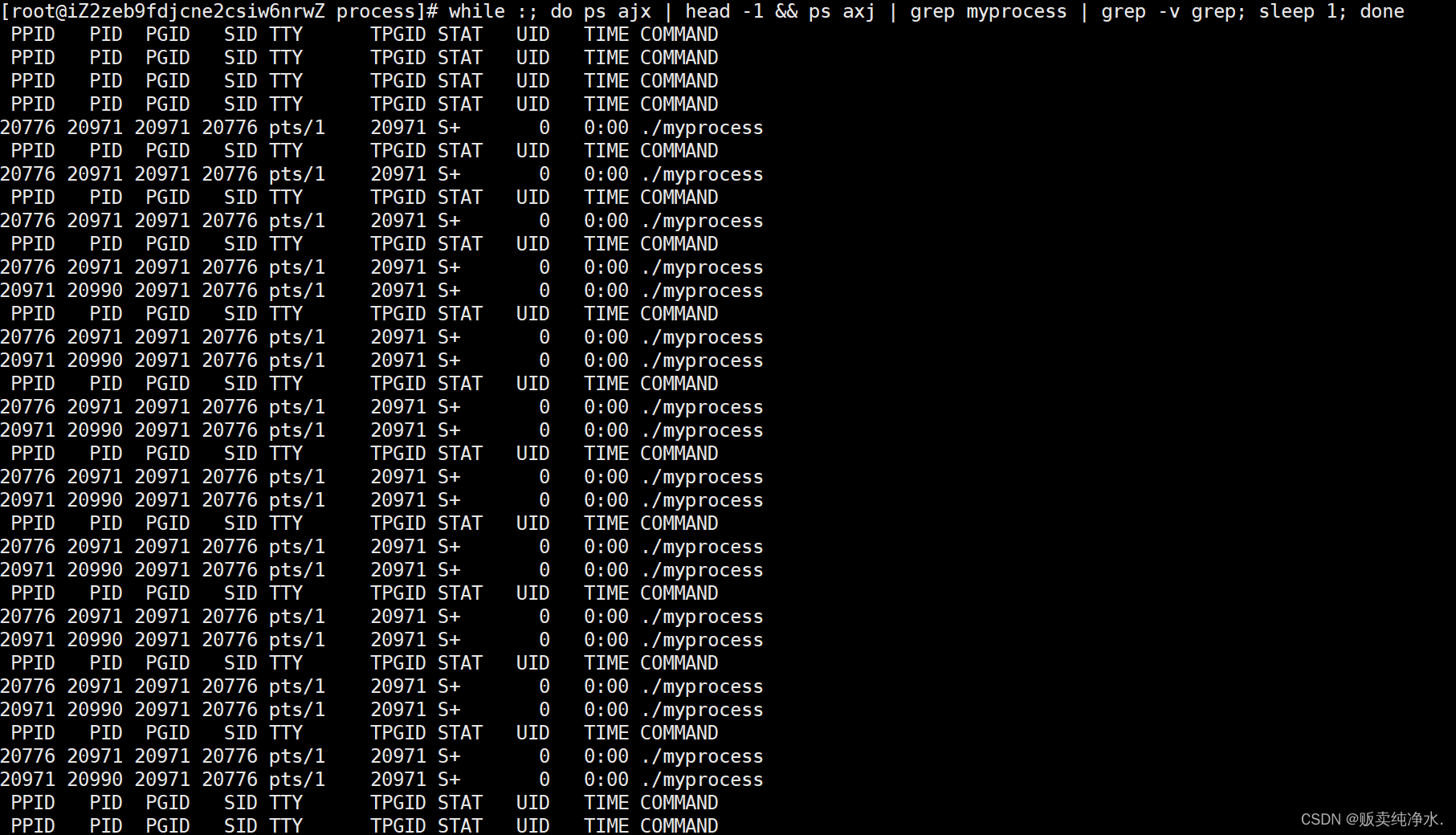
一次创建多个进程
cpp
#include<stdio.h>
#include<unistd.h>
#include<sys/types.h>
#include<unistd.h>
void RunChild()
{
while (1)
{
printf("I am parent, pid :%d,ppid: %d\n", getpid(), getppid());
sleep(1);
}
}
int main()
{
const int num = 5;
int i = 0;
for (i = 0; i < num; i++)
{
pid_t id = fork();
if (id == 0) //因为父进程的id不等于0,所以直接跳过判断执行下次循环,创建紫禁城
{
RunChild();
}
sleep(1);
}
while (1)
{
sleep(1);
printf("I am parent, pid :%d,ppid: %d\n", getpid(), getppid());
}
return 0;
}
进程创建可以用代码的方式:fork(),而不是每次都需要./来启动进程
task_struct内容
task_struct
标示符: 描述本进程的唯一标示符,用来区别其他进程
状态: 任务状态,退出代码,退出信号等
优先级: 相对于其他进程的优先级
程序计数器: 程序中即将被执行的下一条指令的地址
内存指针: 包括程序代码和进程相关数据的指针,还有和其他进程共享的内存块的指针上下文数据: 进程执行时处理器的寄存器中的数据休学例子,要加图CPU,寄存器
I/O状态信息: 包括显示的I/O请求,分配给进程的I/O设备和被进程使用的文件列表。记账信息: 可能包括处理器时间总和,使用的时钟数总和,时间限制,记账号等
其他信息
优先级:哪个进程先运行 (食堂排队打饭就是在确定打饭的优先级,确定进程的优先级是在给进程的task_struct排队)
可以在内核源代码里找到组织进程,所有运行在系统里的进程都以task_struct链表的形式存在内核里
查看进程
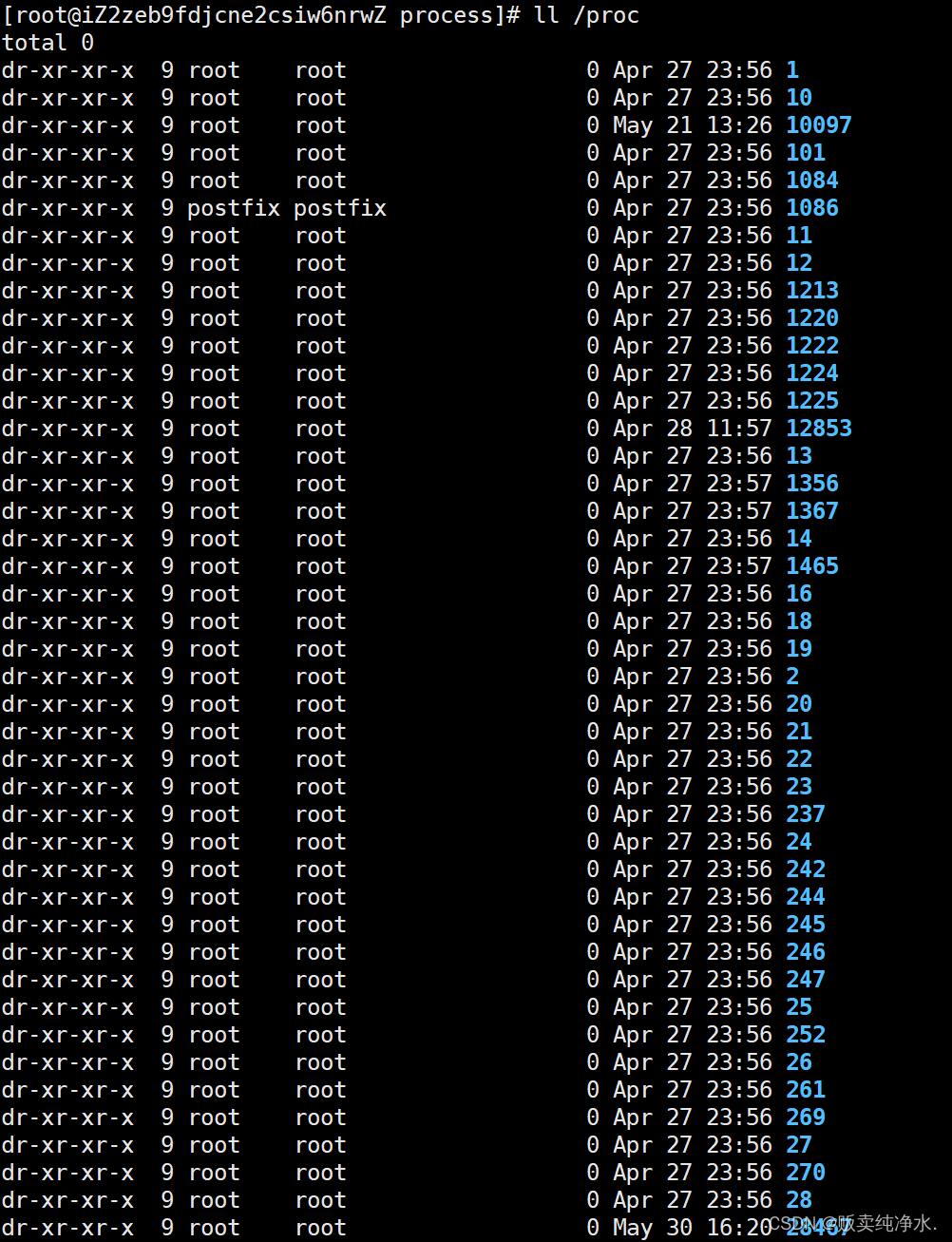
除了ps命令,进程还可以通过/proc系统文件夹查看(proc是根目录下的一个文件夹):

cpp
#include<stdio.h>
#include<unistd.h>
#include<sys/types.h>
#include<unistd.h>
int main()
{
pid_t id = getpid();
pid_t parent = getppid();
while (1)
{
printf("I am a process!,pid:%d ,ppid:%d\n", id, parent);
sleep(1);
}
return 0;
}
要获取PID为1的进程信息,你需要查看/proc/1这个文件夹,其中目录是以进程的pid命名的:
bash
ll /proc/29129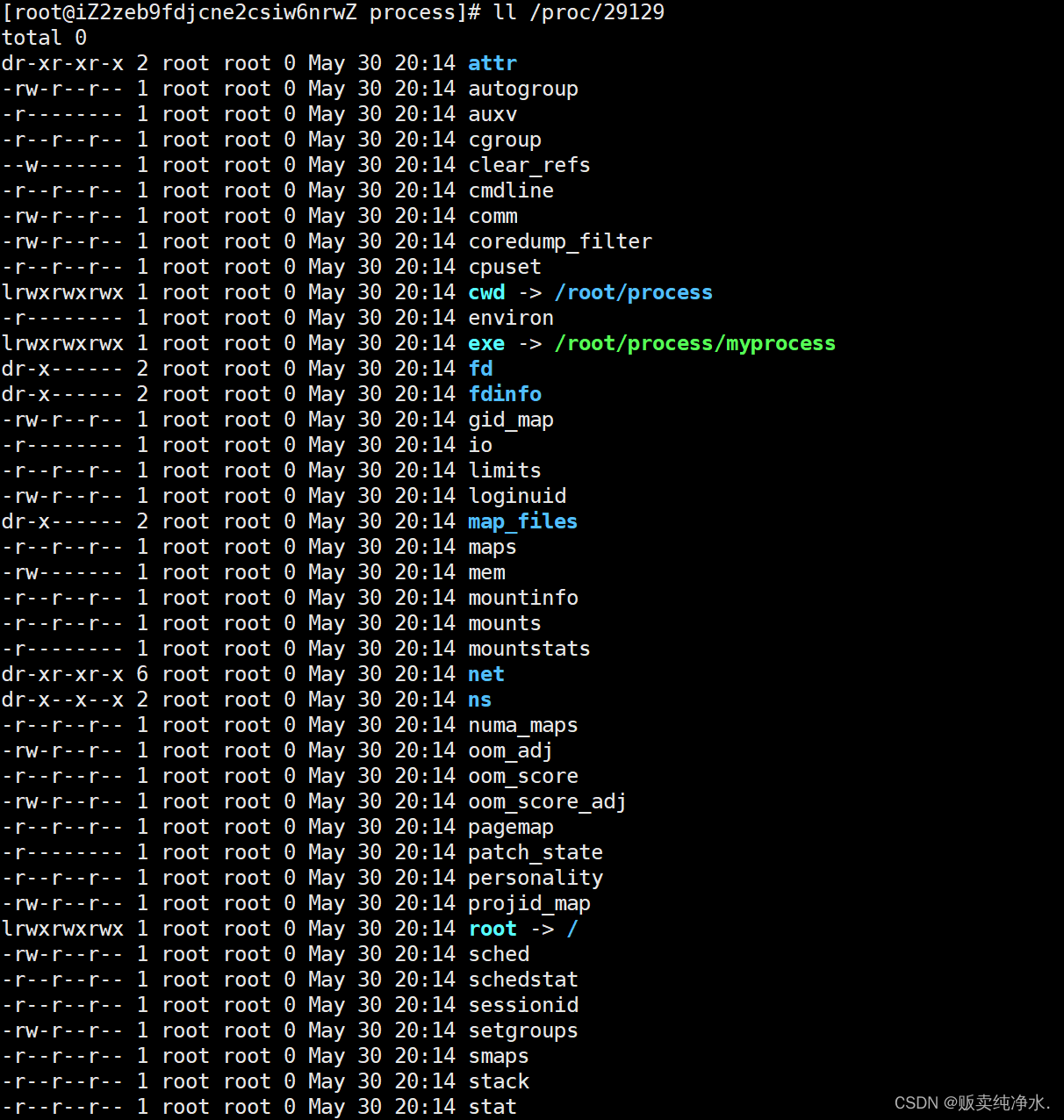
其中比较重要的一个属性是exe :

也就是说这个exe是由绿色路径下的可执行程序加载出来的
我们假如把可执行程序干掉,那程序也还能跑,这是为什么捏?
因为如果文件要被进程调度,那在内存中已经有一份了,所以把磁盘上的可执行程序删掉了进程也照样可以跑(内存中有,原则上能跑)

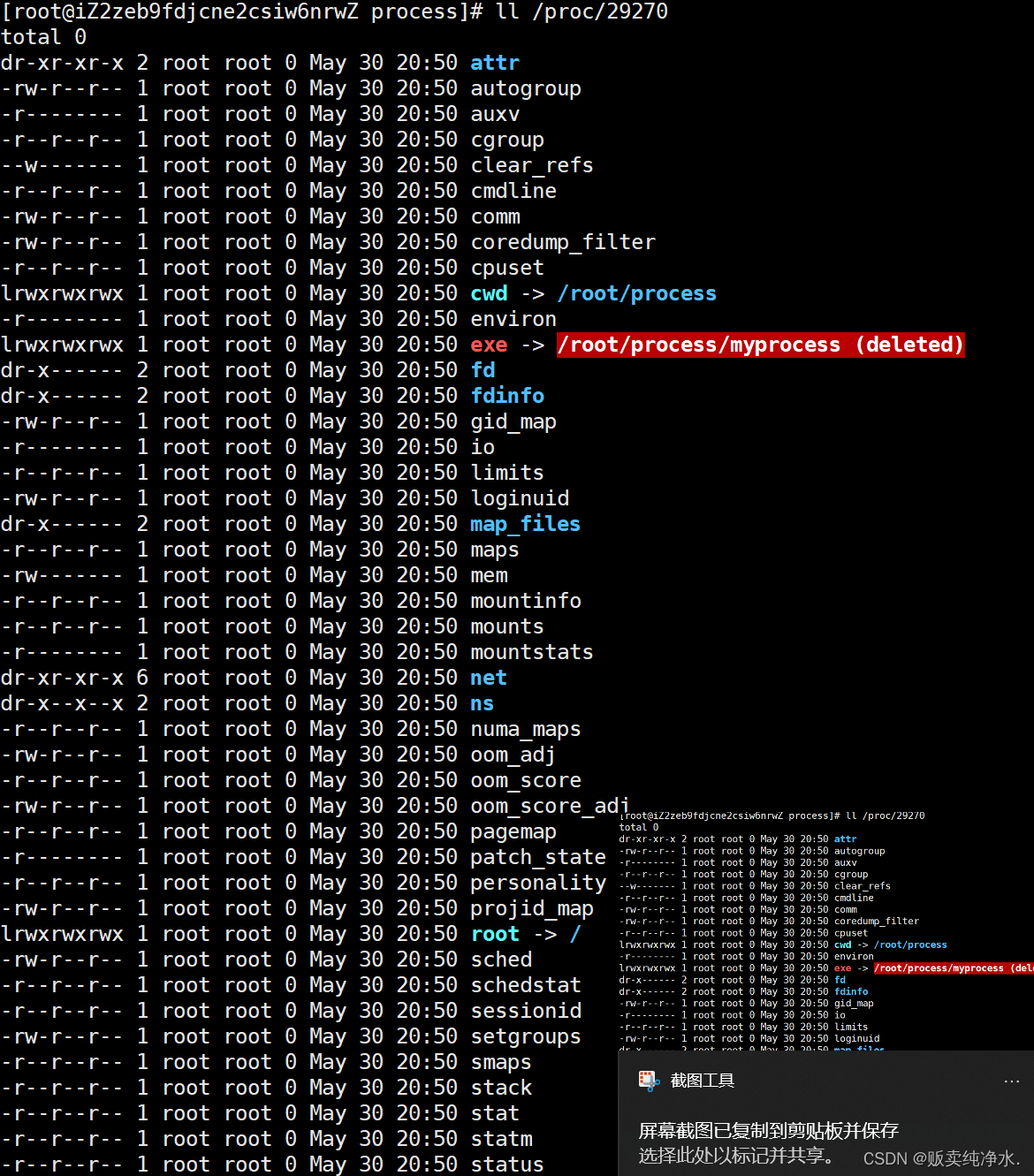
万一程序非常大就够呛了,电脑内存假设只有8G,可执行程序有16G,如果删掉了,进程可能运行着运行着就出问题了(事已至此,就讲一下暖暖和劫的相爱相杀吧,劫在早期出的时候是要花钱买的(好像八十多?),暖暖作为一个游戏重度爱好者(大收藏家)肯定是不会错过这样一个炫酷的游戏,于是激情购入),可是他的电脑空间不太够,于是他买了个固态硬盘以获取足够大的空间下载这个3A巨作,但是他下好之后进入游戏,发现逐帧播放,游戏卡成PPT,于是他又买了个内存条,百事百不灵,只好作罢,为了一个八十块的游戏花了八百块,暖暖暖暖的在暖群)

进程的PCB会记录自己对应可执行程序的路径,那这个cwd是什么呢?
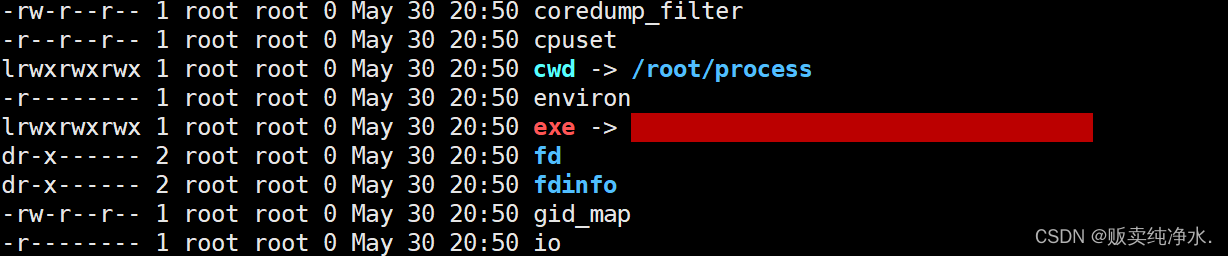
current work dir -- 进程的当前工作路径
每个进程在启动时,会记录自己在哪个路径下启动 --- 进程的当前路径
在前面学C的时候,文件操作那(呜呜,想鹏哥了)
cpp
fopen("log.txt","w");都是进程的代码在执行 cwd/log.txt
这样它会在当前路径下新建,什么是"当前路径"?,看个例子:
cpp
#include<stdio.h>
int main()
{
FILE *fp = fopen("log.txt","w");
(void)fp; //ignore warnning
return 0;
}
cpp
#include<stdio.h>
#include<sys/types.h>
#include<unistd.h>
int main()
{
chdir("/root/ice");
FILE *fp = fopen("log.txt","w");
(void)fp; //ignore warnning
fclose(fp);
while(1)
{
printf("I am a process,pid:%d\n",getpid());
sleep(1);
}
return 0;
}可以发现路径发生改变了:
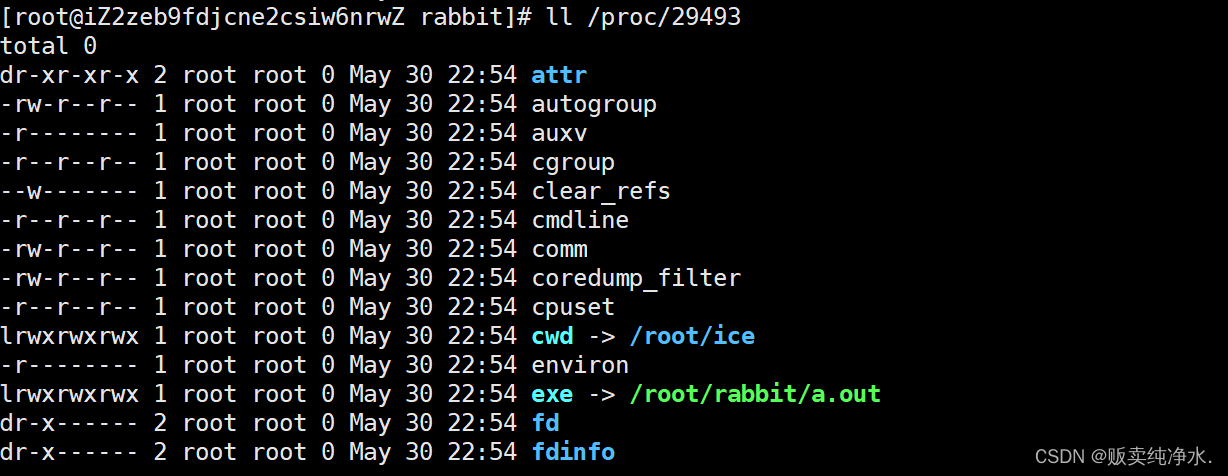
也确实在我们指定的目录下新建文件了:

进程状态
每个进程都要有自己的状态
Linux进程状态
进程状态是task_struct内部的一个属性:
cpp
#define RUN 1
#define SLEEP 2
#define STOP 3
struct task_struct
{
//内部属性
int status;
}
struct task_struct process1;
process1.status = RUN;Linux改变一个进程的状态就是在改变task_struct的内部属性 (定义出的标志位,为了表示进程的状态)
Linux内核中对于状态有什么定义呢?
可以看看kernel的源码:
bash
/*
* The task state array is a strange "bitmap" of
* reasons to sleep. Thus "running" is zero, and
* you can test for combinations of others with
* simple bit tests.
*/
static const char * const task_state_array[] = {
"R (running)", /* 0 */
"S (sleeping)", /* 1 */
"D (disk sleep)", /* 2 */
"T (stopped)", /* 4 */
"t (tracing stop)", /* 8 */
"X (dead)", /* 16 */
"Z (zombie)", /* 32 */
};定义进程的显示为了方便采用数组的形式显示
R运行状态(running): 并不意味着进程一定在运行中,它表明进程要么是在运行中要么在运行队列里
S睡眠状态(sleeping): 意味着进程在等待事件完成(这里的睡眠有时候也叫做可中断睡眠 (interruptible sleep))
D磁盘休眠状态(Disk sleep)有时候也叫不可中断睡眠状态(uninterruptible sleep),在这个状态的 进程通常会等待IO的结束
T停止状态(stopped): 可以通过发送 SIGSTOP 信号给进程来停止(T)进程。这个被暂停的进程可 以通过发送 SIGCONT 信号让进程继续运行
X死亡状态(dead):这个状态只是一个返回状态,你不会在任务列表里看到这个状态
怎么验证进程有着这样那样的状态呢?
bash
ps aux / ps axj 命令
首先先看一下关于makefile的骚操作:
bash
myprocess:myprocess.c
gcc -o $@ $^
.PHONY:clean
clean:
rm -f myprocess这是一段已经写好的makefile,怎样可以快速copy呢?
在底行模式下,我们可以这样干一键替换
bash
%s/myprocess/testStatus/ 后者替换前者

再把依赖文件改一下就好哩:
bash
testStatus:testStatus.c
gcc -o $@ $^
.PHONY:clean
clean:
rm -f testStatus
bash
while :; do ps ajx | head -1 && ps ajx | grep testStatus | grep -v grep; sleep 1; done我们可以发现这个进程一直在狂刷:
cpp
#include<stdio.h>
#include<sys/types.h>
#include<unistd.h>
int main()
{
while(1)
{
printf("I am a process\n,pid:%d\n",getpid());
}
return 0;
}
但是一看状态怎么他喵的是sleep啊?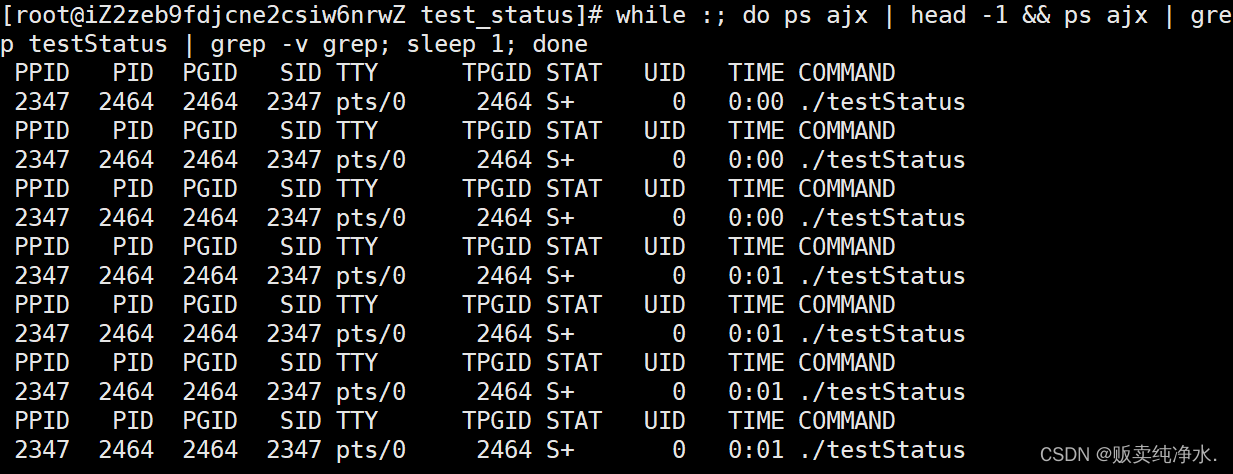
我把源码稍加改动:
cpp
#include<stdio.h>
#include<sys/types.h>
#include<unistd.h>
int main()
{
while(1)
{
// printf("I am a process\n,pid:%d\n",getpid());
}
return 0;
}现在检测可以发现是正常运行的哩: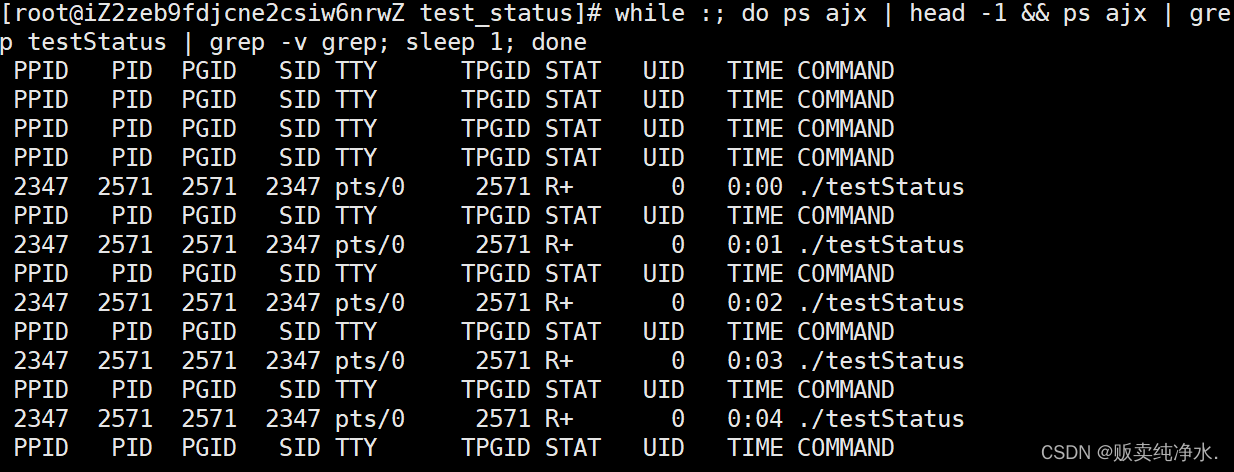
R表示进程正在运行,可是打印又是什么很邪恶的操作吗?凭什么说我在睡觉???
S表示休眠状态,即进程什么都没做
首先我们明确一点:printf打印是往哪打?
往显示器上打印对吧,程序是在远隔万里的云服务器上跑的,但是打印的结果却返回到了近在咫尺的显示器,根据冯·诺依曼体系架构,显示器是一个外设,所以CPU在跑的时候,一直要把数据写到内存里,再刷新到外设上,那我能保证每次打印的时候显示器都是就绪的么?
程序是CPU在跑,CPU的速度可比显示器快多了,所以进程在被调度时需要访问显示器资源,大部分时间都在等待设备资源就绪,只要没就绪,就处于S状态,CPU执行(ns),打印(ms),所以我们在查询时可能查到的很多都是处于等待状态而并非运行状态,这也是为什么把printf注释掉之后就一直是R状态(可想而知差距有多大才会在刷屏的时候依旧查到很多S)
休眠状态就是进程在等待资源就绪的过程
我们如何真正的看到一个资源在休眠呢?
cpp
#include<stdio.h>
#include<sys/types.h>
#include<unistd.h>
int main()
{
while(1)
{
sleep(10);
printf("I am a process\n,pid:%d\n",getpid());
}
return 0;
}上面的进程就是在休眠,使用Ctrl+C可以把进程终止
所以S是可以被中断的睡眠 ,这是让进程在后端运行:
bash
./testStatus &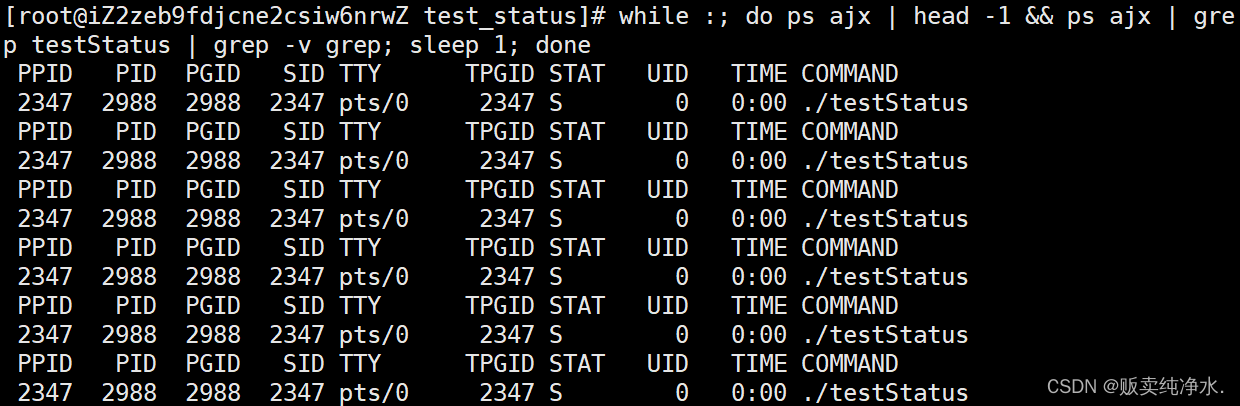
在后端运行的进程休眠S则不带+了 ,带不带+就是区分进程在前台和后台运行,在后台运行的进程是没法Ctrl+C的,只好干掉哩:
bash
kill -9 2988我们的进程有不同的状态,有一个状态叫T即停止状态,很有意思的点就在于我们可以通过一个进程控制其他进程:
bash
kill -l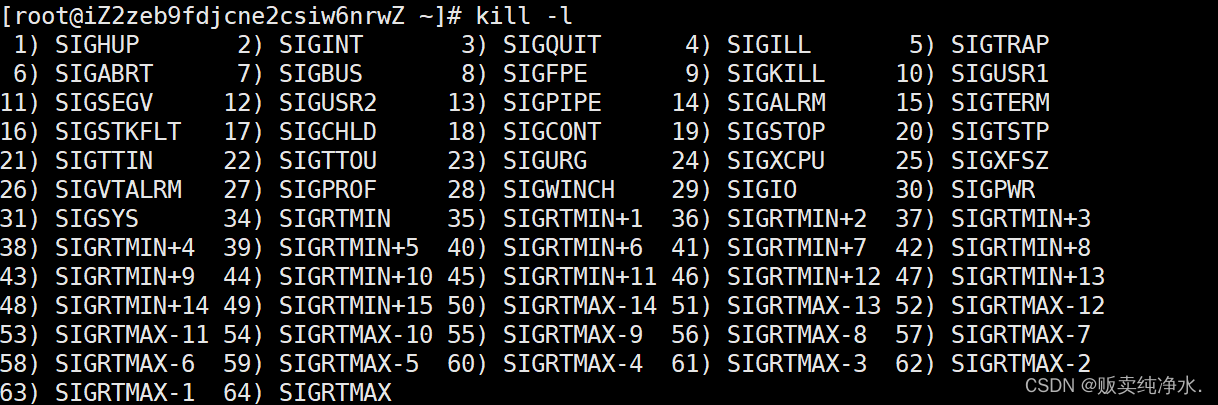
这是很多信号,我们曾经用过的信号9就是杀掉进程,使用kill可以向指定信号发信号,信号就是数字,发信号时也有自己对应的名字(大写的,数字代号----宏!),可以看到成功将进程终止了
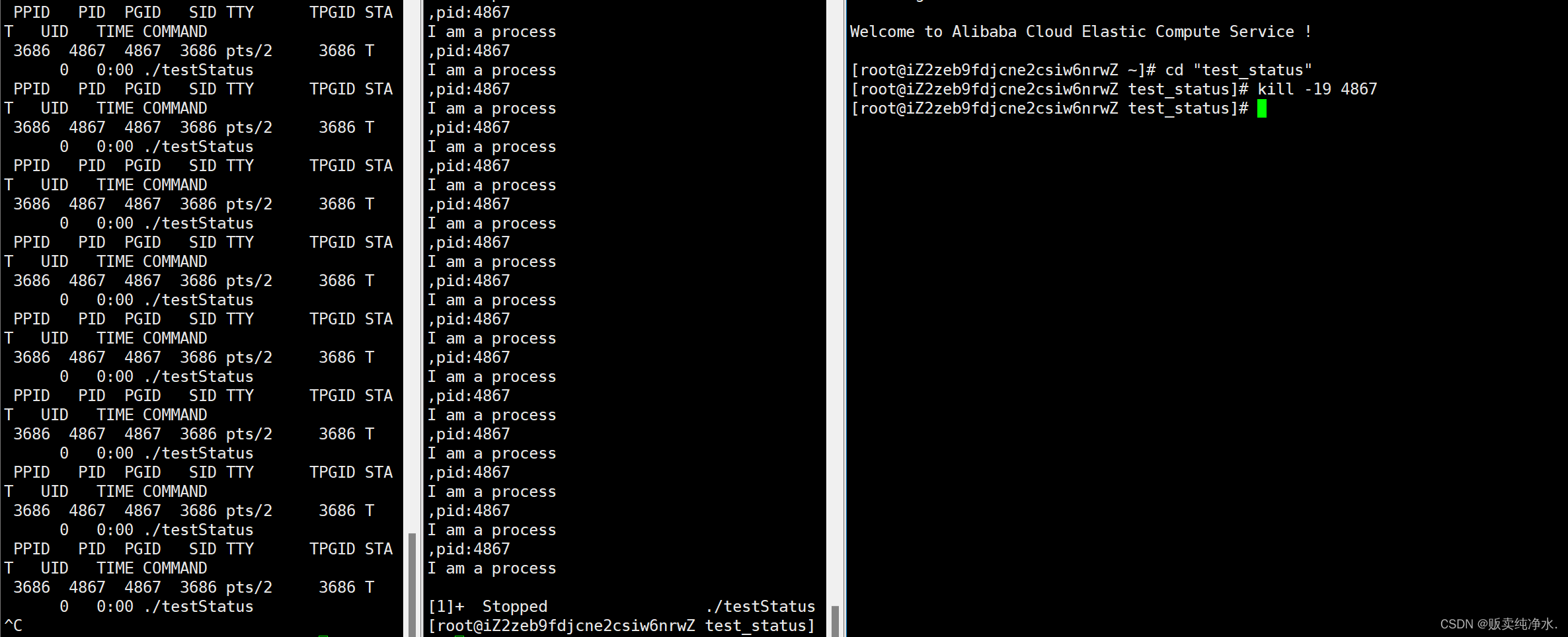
T:让进程暂停,等待被进一步唤醒
19是将进程暂停,18则是继续:

其实我们之前也做过让进程暂停的操作,这个操作叫做调试(在断点处不就停下来了吗,悟了没)
为了让进程可以被调试,修改下makefile文档:
bash
myprocess:myprocess.c
gcc -o $@ $^ -g
.PHONY:clean
clean:
rm -f myprocess浅查一下吧:
bash
readelf -S myprocess | grep debug
我们开启监控会发现查不到:

这个正在跑的是gdb,并不是我的进程(相关操作移步我的另一篇)
炫酷gdb-CSDN博客![]() https://blog.csdn.net/chestnut_orenge/article/details/138551058 看看怎么个事:
https://blog.csdn.net/chestnut_orenge/article/details/138551058 看看怎么个事:
cpp
ps ajx | grep myprocess
可恶!明明查得到!!!大骗子
奥,原来我只是开启了调试,并没有让进程跑起来啊
在第十行处打个断点再让进程跑起来:
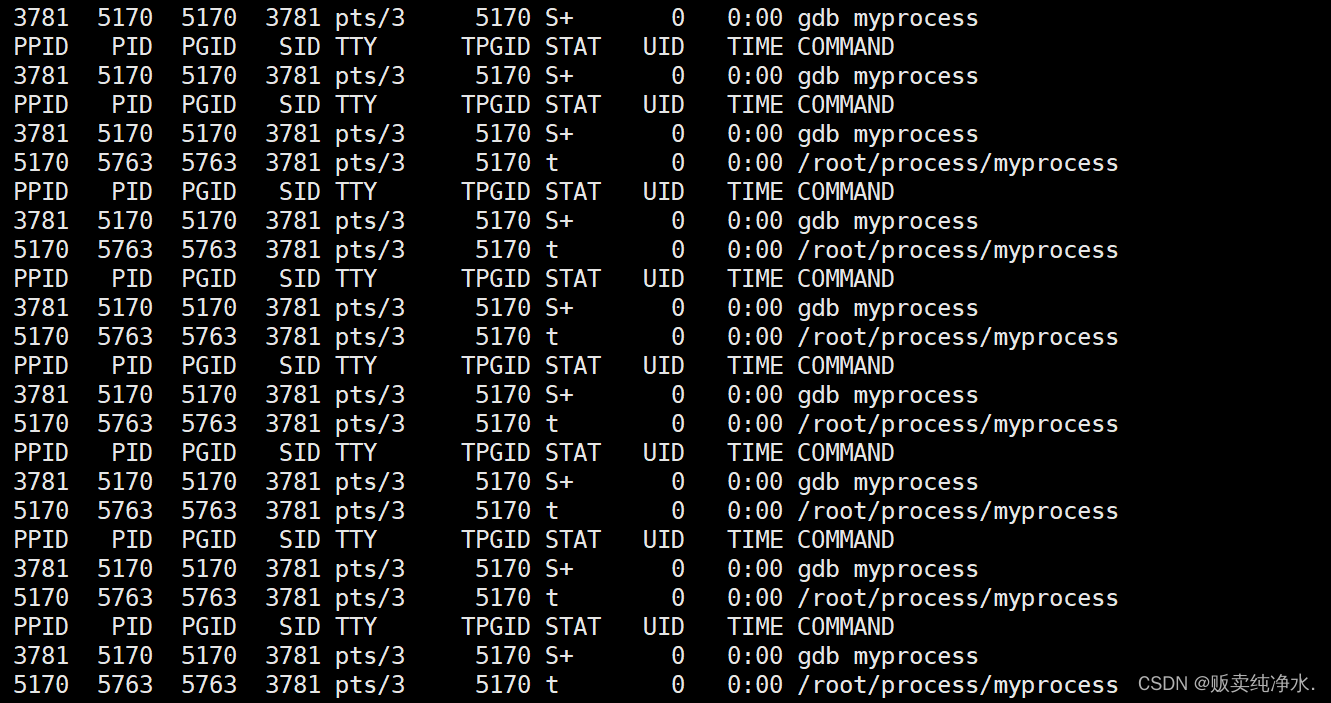
惊奇发现S+爆改t
t表示当前进程因被追踪而暂停,遇到断点进程即暂停
D状态是Linux系统中比较特有的一种进程状态,名为磁盘暂停状态
操作系统在开机时就在内存中存在着,即开机时操作系统就被从磁盘加载到内存
假设这样的场景:内存中1GB的数据要存到磁盘中(把数据交给外设)
进程在等外设写数据,所以当前的进程就处于一个S状态(休眠),等待写入完毕
Linux操作系统有权利杀掉进程来释放空间(内存严重不足,杀鸡儆猴以儆效尤)
磁盘忙完一圈回来想反馈发现进程被干掉了,啊?不是哥们?
但又不止有一个进程等着磁盘帮忙写入,就造成1GB的数据丢失问题(如果这1GB数据是银行里记录的一天内用户的转账记录,那事可就大发咯)
那锅该甩给谁?
操作系统、进程、磁盘。。。谁有问题?
进程:"老大呜呜呜,我是受害者呜呜呜,我在那正工作呢突然就有个比我官大的不分青红皂白就把我干掉了呜呜呜"
操作系统:"进程你还放上洋屁装起可怜了,我要是完蛋了,我们大家伙都得玩完,老大都说了我作为操作系统,在极端条件下有资格杀掉进程,要是我挂了丢10GB数据这个锅你背得起吗?!"
磁盘:"老大,说白了我就是个送外卖跑腿的,人家让我干嘛我干嘛,只是写入失败了,是硬件出错误了,这总不能怪我吧。。。"
为了防止后续问题再发生,问题的根源就在于操作系统杀掉进程的时候是毫无类别的去杀,想杀就杀,但是这种在写入关键数据的进程是不可以被杀掉的!
那也不能怪操作系统啊,那长得都一样,它还那么大块头,不删留着过年吗?
所以此后规定操作系统执行这样的法则:凡是在进行数据IO的进程一律不允许删!
在传数据的时候,进程要变为D状态:不可被杀!
D状态就是一种睡眠状态:深度睡眠:不可中断睡眠
那怎样结束D状态呢?
肯定可以让它自己醒过来呀!
还可以重启,如果重启都不管用就只能断电了(重启有时也会将数据向磁盘内刷新,如果不成功卡死就只能断电了)
僵尸进程和孤儿进程
进程退出的时候不是干巴巴的退出,是要把退出信息保存到进程的PCB中的,如果没有人读取PCB中进程退出的消息,那进程就一直不释放(代码和数据释放掉,PCB一直存在,直到等待,否则一直处于僵尸状态)当等待时,进程的状态才会转为X,进而将空间全部释放(刑事案件:封锁现场
-->法医验尸-->联系家属火化尸体),所以一个进程退出的时候并不会直接退出,而是会先处于一个僵尸状态,如果父进程不对其进行回收,那么对应的进程将一直处于僵尸状态
cpp
#include<stdio.h>
#include<sys/types.h>
#include<unistd.h>
int main()
{
pid_t id = fork();
if (id == 0)
{
//child
int cnt = 5;
while (cnt)
{
printf("I am a child,cnt:%d,pid:%d\n", cnt, getpid());
sleep(1);
cnt--;
}
}
else
{
//parent
while (1)
{
printf("I am a parent,running always!,pid:%d\n", getpid());
sleep(1);
}
}
return 0;
}上面的进程退出后,紫禁城将处于僵尸状态,监控一下发现确实是这样:

Z状态表示已经运行完毕,但是需要维持自己的退出信息,在自己的进程task_struct会记录自己的退出信息,未来让父进程进行读取(要让父进程知道他为什么退出),如果没有父进程读取,僵尸进程会一直存在
进程 = 内核数据结构task_struct(一直存在,可能会造成内存泄漏) + 进程的代码和数据(被释放)
僵死状态(Zombies)是一个比较特殊的状态
当进程退出并且父进程(使用wait()系统调用)没有读取到子进程退出的返回代码时就会产生僵死(尸)进程
僵死进程会以终止状态保持在进程表中,并且会一直在等待父进程读取退出状态代码
所以,只要子进程退出,父进程还在运行,但父进程没有读取子进程状态,子进程进入Z状态
kill是不能干掉僵尸进程的,它已经死了,你这个顶多算鞭尸
谈完僵尸进程,谈谈孤儿进程:
如果父进程先退出,我们把子进程叫做孤儿进程,孤儿进程一般都是会被1号进程(OS本身)进行领养的
cpp
#include<stdio.h>
#include<sys/types.h>
#include<unistd.h>
int main()
{
pid_t id = fork();
if(id == 0)
{
//child
while(1)
{
printf("I am a child,pid:%d\n",getpid());
sleep(1);
}
}
else
{
//parent
int cnt = 5;
while(cnt--)
{
printf("I am a parent,cnt:%d pid:%d\n",cnt,getpid());
sleep(1);
}
}
return 0;
}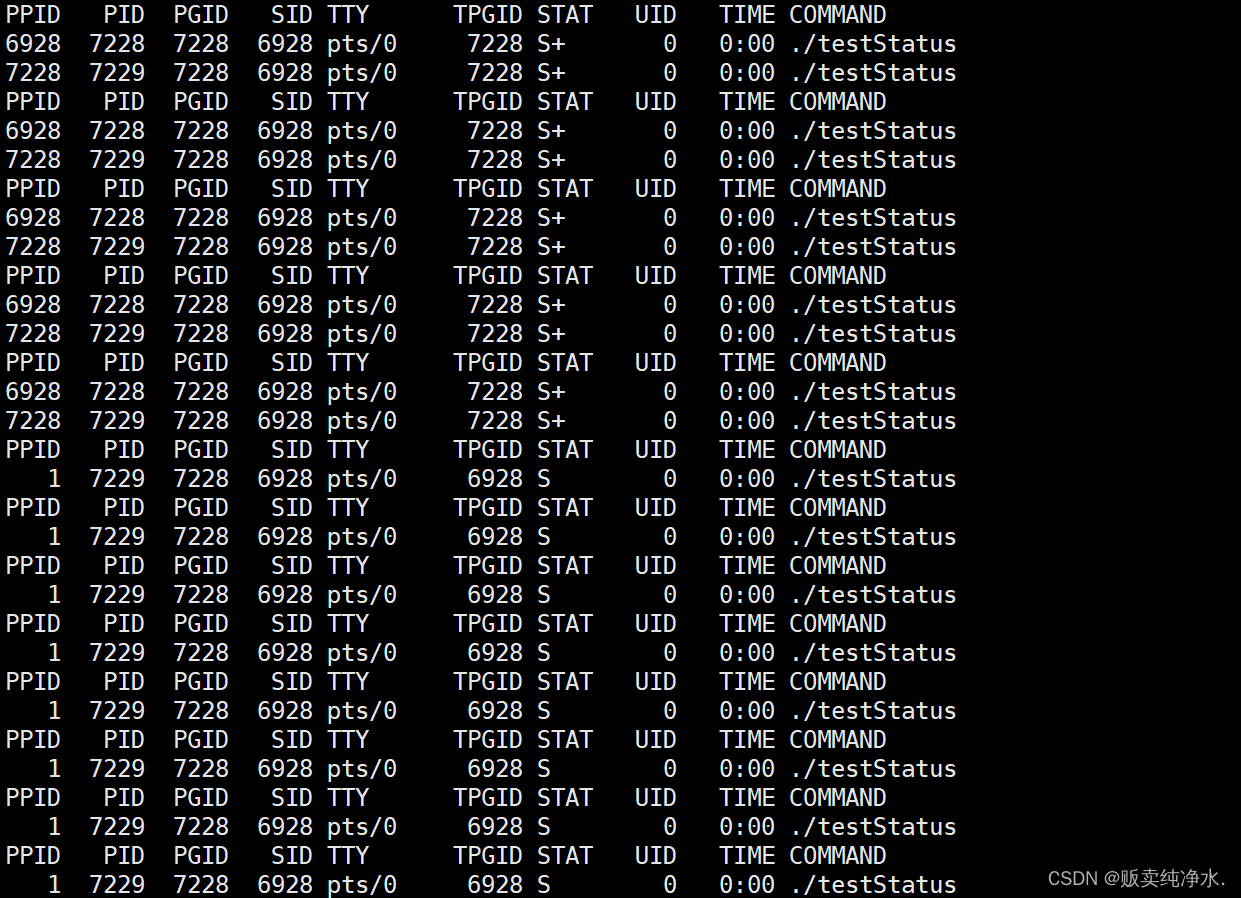
孤儿进程为什么要被OS领养?
因为我们依旧要保证紫禁城正常被回收
可是教练,,,我之前敲代码也不关心内存泄漏(僵尸进程啊),这东西,,九九成稀罕物
cpp
#include<stdio.h>
#include<sys/types.h>
#include<unistd.h>
int main()
{
int cnt = 5;
while(cnt)
{
sleep(1);
printf("I am a process,pid:%d\n",getpid());
cnt--;
}
return 0;
}我们会发现,这也不异常啊,不是很快自己就退下了?
主要是因为,命令行中启动的所有进程的父进程是Bash,Bash会自动回收新进程的僵尸问题
进程的阻塞、挂起、运行
我们操作系统讲的进程状态也不是这样式的呀。。。