0.知识引入
mysql的事务,有四个比较核心的特性.
- 原子性
2.一致性
3.持久性 =>(和持久化说的是一回事)【把数据存储在硬盘À =>持久把数据存储茌内存上>不持久~】【重启进程/重启主机 之后,数据是否存在!!】
4.隔离性~
- Redis 是一个 内存 数据库.把数据存储在内存中的!!(Redis 相比于 MySQL 这样的关系型数据库,最明显的特点/优势 =>效率高/快~~)
- 内存中的数据是不持久的~~要想能够做到持久, 就需要让 redis 把数据存储到硬盘上
- 最终选择的策略:为了保证速度快,数据肯定还是得在内存中,
但是为了持久,数据还得想办法存储在硬盘上.(我全都要) - Redis 决定,内存中也存数据. 硬盘上也存数据
- 这样的两份数据,理论上是完全相同的
- 实际上可能存在一个小的概率有差异~~
取决于咱们具体怎么进行持久化~ - 当要插入一个新的数据的时候,就需要把这个数据,同时写入到内存和硬盘。
- 说是两边都写,但是实际上具体怎么写硬盘还有不同的策略~~ 可以保证整体的效率还是足够高~~
- 当查询某个数据的时候直接从内存读取,硬盘的数据只是在 redis 重启的时候,用来恢复内存中的数据的~
- 代价就是消耗了更多的空间.同一份数据,存储了两遍~~(但是毕竟硬盘比较便宜~~,这样的开销并不会带来太多的成本~~
Redis ⽀持 RDB 和 AOF 两种持久化机制,持久化功能有效地避免因进程退出造成数据丢失问题,
当下次重启时利⽤之前持久化的⽂件即可实现数据恢复。
Redis 实现持久化的时候,具体是按照什么样的策略来实现的呢?
1.RDB =>Redis DataBase
2. AOF => Append Only File
- RDB
- 1.定期备份.
- 每个月,把我电脑硬盘上的学习资料,整体的备份到这个备份盘中~~
- AOF
- 2.实时备份.
- 只要我下载了一个新的学习资料,立即把这个学习资料往备份盘中拷贝一份~~
1.RDB
RDB 持久化是把当前进程数据⽣成快照保存到硬盘的过程,触发 RDB 持久化过程分为⼿动触发和
⾃动触发。
- RDB 定期的把我们 Redis 内存中的所有数据,都给写入硬盘中,生成一个"快照"
- Redis 给内存中当前存储的这些数据,赶紧拍个照片生成一个文件,存储在硬盘中~~
- 后续 Redis 一旦重启了,(内存数据就没了),就可以根据刚才的"快照就能把内存中的数据给恢复回来~
- "定期"具体来说,又有两种方式:
1.手动触发.
- 程序猿通过 redis 客户端,执行特定的命令,来触发快照生成。
- 【save】执行 save 的时候,redis 就会全力以赴的进行"快照生成"操作,此时就会阻塞 redis 的其他save客户端的命令~导致类似于 keys*的后果~~
- 一般不建议使用 save
- 【bgsave bg】 =>background (后面) 不会影响 Redis 服务器处理其他客户端的请求和命令~~
- Redis 咋做到的?是不是偷摸搞了个多线程啥的? 并非如此!!
- 并发编程 的场景. 此处 redis 使用的是**"多进程"** 的方式,来完成的并发编程,来完成的 bgsave 的实现~~
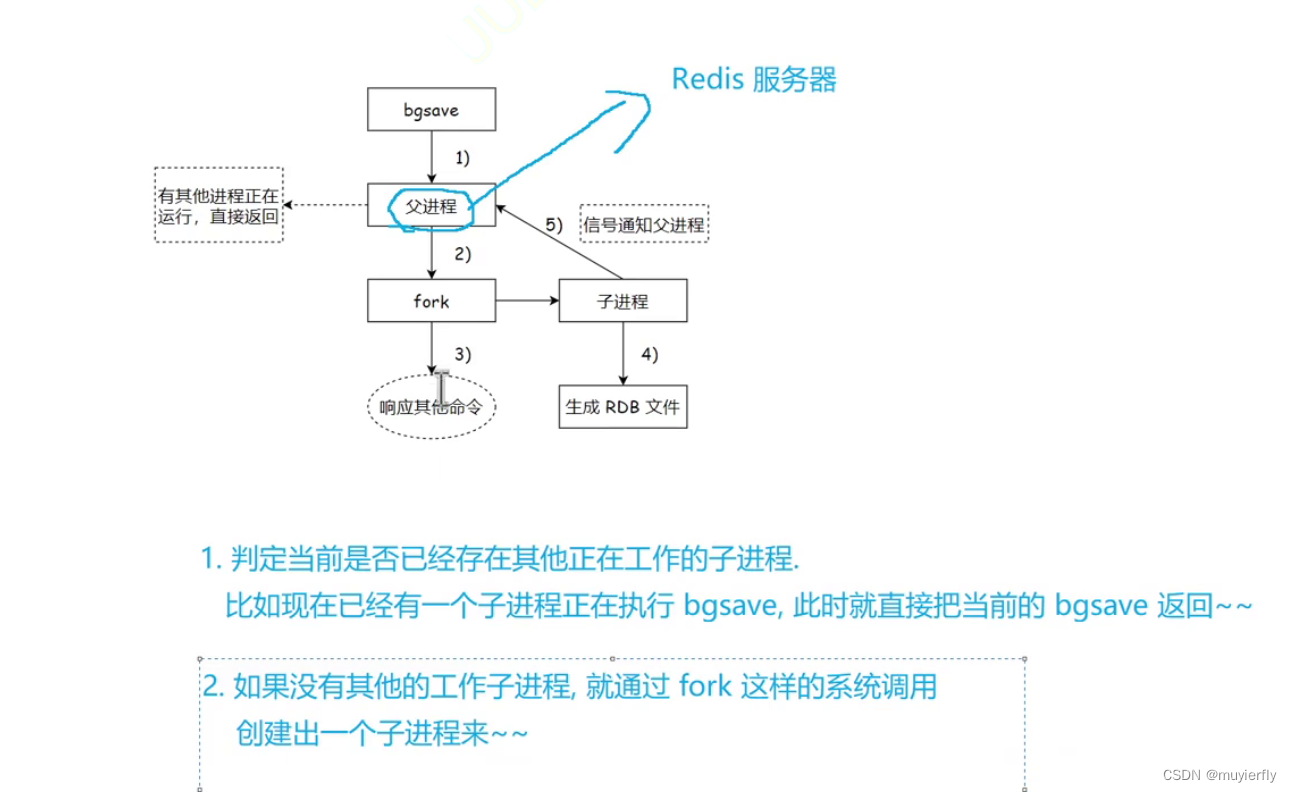
- fork:【进程 和 线程Java 进行并发编程,主要是通过"多线程"的方式~~
fork 是 linux 系统提供的一个创建子进程的 api(系统调用)如果是其他系统,比如windows,创建子进程就不是 fork(CreateProcess....
fork 创建子进程,简单粗暴, 直接把当前的进程(父进程)复制一份(会复制,pcb,虚拟地址空间(内存中的数据),文件描述符表....
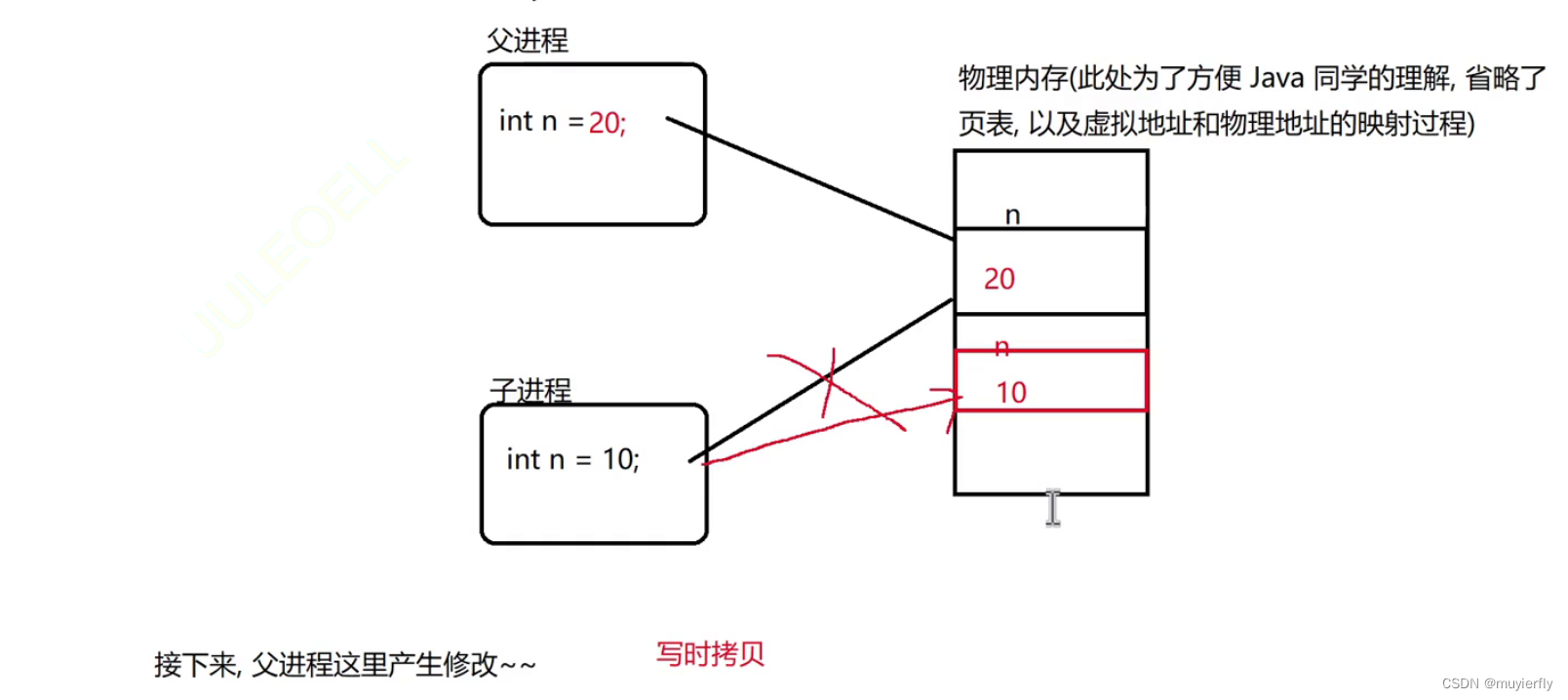
本来 redis server 中,有若干变量, 保存了一些键值对数据~~随着这样的 fork 的进行,子进程的这个内存里也会存在和刚才父进程中一模一样的变量~~<因此,复制出来的这个"克隆体"(子进程) 的内存中的数据就是和"本体"(父进程) 是一样的.接下来安排子进程去执行"持久化"操作,也就相当于把父进程本体这里的内存数据给持久化了~~>父进程打开了一个文件,fork 了之后,子进程也是可以同样使用这个文件的~~也就导致了子进程持久化写入的那个文件和父进程本来要写的文件是同一个了【question:如果当前, Redis 服务器中存储的数据特别多,内存消耗特别大(比如 100GB)此时,进行上述的复制操作,是否会有很大的性能开销?此处的性能开销,其实挺小的~~fork 在进行内存拷贝的时候,不是简单无脑的直接把所有数据都拷贝一遍,而是"写时拷贝"的机制来完成的!! 如果子进程里的这个内存数据,和父进程的内存数据完全一样了~~ 此时就不会触发真正的 拷贝 动作.(而是爷俩其实用一份内存数据)但是,其实这俩进程的内存空间,应该是各自独立的~~ 一旦某一方针对这个内存数据做了修改就会立即触发真正的 物理内存 上的数据拷贝~~ 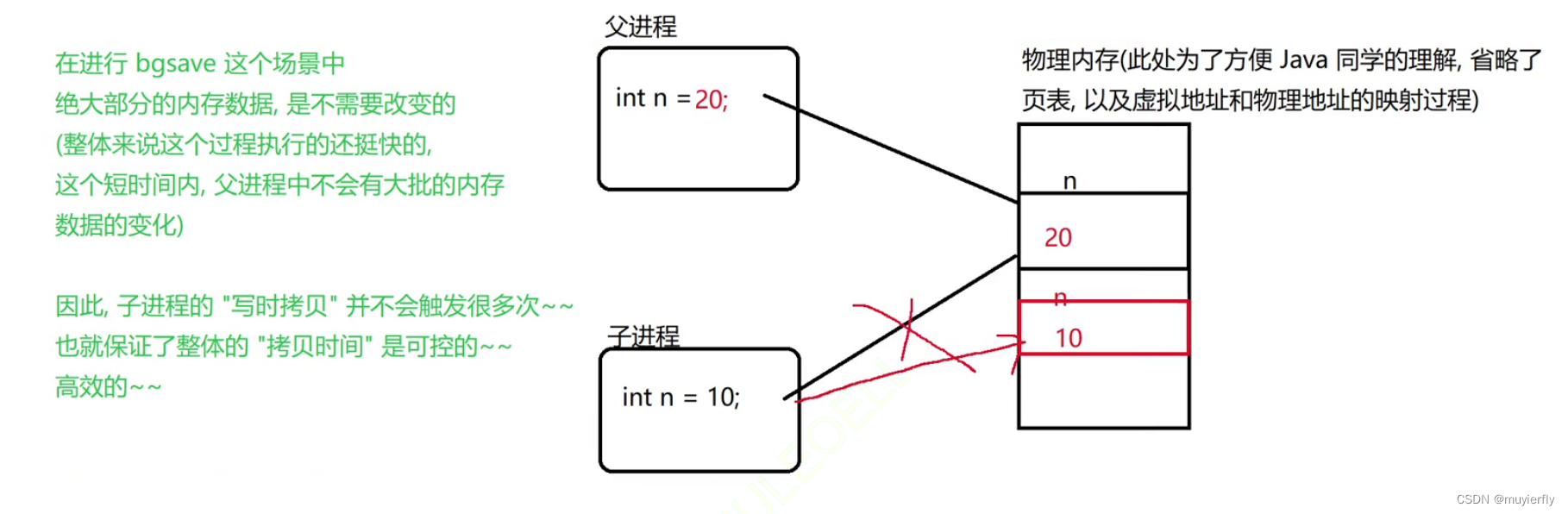
 **】)**作为 子进程 ~~一旦复制完成了,父子进程就是两个独立的进程,就各自执行各自的了~~】
**】)**作为 子进程 ~~一旦复制完成了,父子进程就是两个独立的进程,就各自执行各自的了~~】- 1.判定当前是否已经存在其他正在工作的子进程比如现在已经有一个子进程正在执行 bqsave,此时就直接把当前的 bgsave 返回
- 2.如果没有其他的工作子进程,就通过 fork 这样的系统调用创建出一个子进程来~~
- 3.子进程负责进行 写文件,生成快照的过程.父进程继续接收客户端的请求,继续正常提供服务
- 4.子进程完成整体的持久化过程之后, 就会通知父进程干完了,父进程就会更新一些统计信息.子进程就可以结束销毁了
- redis 生成的 rdb 文件, 是存放在 redis 的工作目录中的也是在 redis 配置文件中, 进行设置的




2.自动触发
- 在 Redis 配置文件中, 设置一下,让 Redis 每隔多长时间/每产生多少次修改 就触发
- 除了⼿动触发之外,Redis 运⾏⾃动触发 RDB 持久化机制,这个触发机制才是在实战中有价值的。
-
- 使⽤ save 配置。如 "save m n" 表⽰ m 秒内数据集发⽣了 n 次修改,⾃动 RDB 持久化。
-
- 从节点进⾏全量复制操作时,主节点⾃动进⾏ RDB 持久化,随后将 RDB ⽂件内容发送给从结点。
-
- 执⾏ shutdown 命令关闭 Redis 时,执⾏ RDB 持久化。
1.1 实践

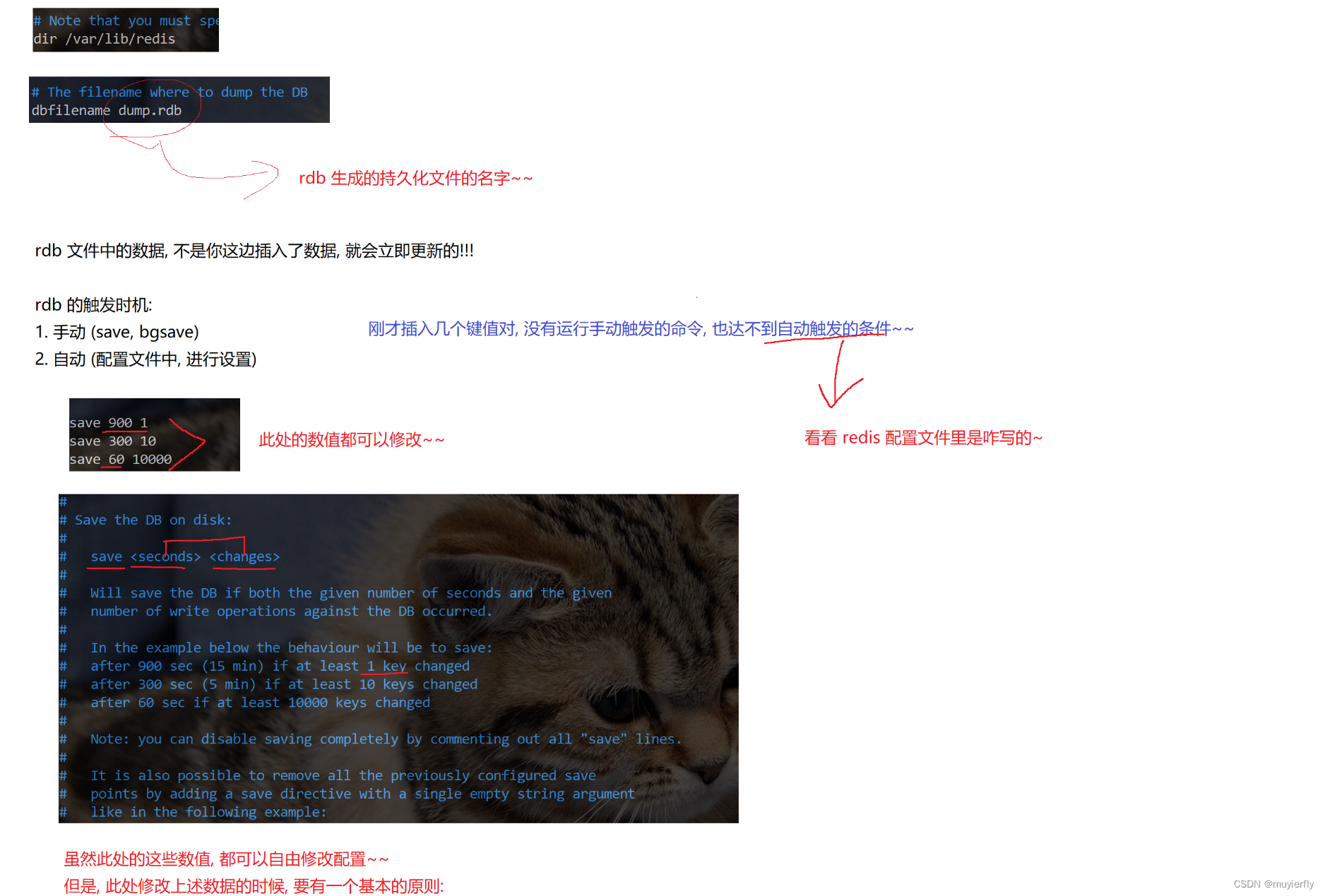
- 虽然此处的这些数值,都可以自由修改配置~~
但是,此处修改上述数据的时候,要有一个基本的原则!
生成一次 rdb 快照,这个成本是一个比较高的成本,不能让这个操作执行的太频繁!!
正因为 rdb 生成的不能太频繁,这就导致,快照里的数据,和当前实时的数据情况可能存在偏差~~ - 正因为 rdb 生成的不能太频繁,这就导致,快照里的数据, 和当前实时的数据情况可能存在偏差~~

1.手动执行bgsave


- 手动执行 save & bqsave 触发一次生成快照~~
- 由于咱们这里的数据比较少, 执行 bgsave 瞬间就完成了.立即査看应该就是有结果的.如果以后咱们接触到的数据多了,执行 bgsave 就可能需要消耗一定的时间. 立即查看不一定就是生成完毕了~~
- 通过上述的操作,就可以看到,redis 服务器在重新启动的时候,加载了 rdb 文件的内容,恢复了内存中之前的状态了~~
2.插入新的 key, 不手动执行 bgsave,重新启动 redis 服务器~

- redis 生成快照操作,不仅仅是手动执行命令才触发,也可以自动触发!!
- 如果是通过正常流程重新启动 redis 服务器, 此时 redis 服务器会在退出的时候,自动触发生成 rdb 操作但是如果是异常重启(kil -9 或者 服务器掉电)此时 redis 服务器来不及生成 rdb,内存中尚未保存到快照中的数据,就会随着重启而丢失~~
- 1)通过刚才配置文件中 save 执行 M 时间内,修改 N 次...
- 2)通过 shutdown 命令(redis 里的一个命令) 关闭 redis 服务器,也会触发.(service redis-server restart)正常关闭。
- 3)redis 进行主从复制的时候,,主节点也会自动生成 rdb 快照,然后把 rdb 快照文件内容传输给从节
- 更害怕的是异常关闭的情况

3.bgsave 操作流程是创建子进程,子进程完成持久化操作.(持久化速度太快了(数据少)难以观察到子进程。)
持久化会把数据写入到新的文件中,然后使用新的文件替换旧的文件 (这个是容易观察到的~~)

Linux 文件系统.
文件系统典型的组织方式(ext4)主要是把整个文件系统分成了三个大的部分~~
1.超级块(放的是一些管理信息)
2.inode 区(存放 inode 节点,每个 文件 都会分配一个 inode 数据结构, 包含了文件的各种元数据)
- block 区,存放文件的数据内容了.
4. 通过配置自动生成 rdb 快照(执行 flushall 也会清空 rdb 文件)
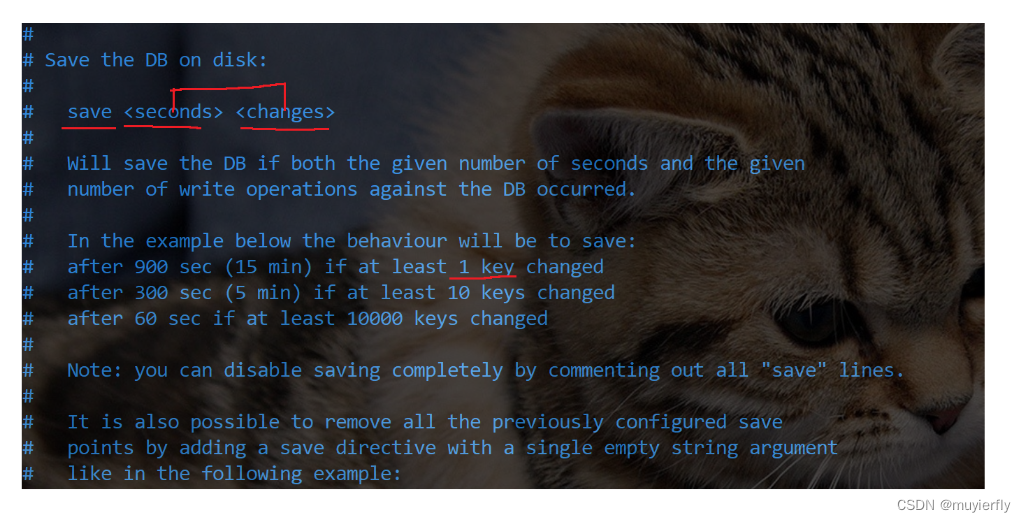
- redis 来说, 配置文件修改之后,一定要重新启动服务器,才能生效!!
- 当然, 如果想立即生效,也可以通过命令的方式修改~~

5.如果把 rdb 文件,故意改坏了,会咋样??
- 手动的把 rdb 文件内容改坏
- 然后一定是通过 ki 进程的方式, 重新启动 redis 服务器如果通过 service redis-server restart 重启,就会在 redis 服务器退出的时候, 重新生成 rdb 快照就把咱们刚才改坏了的文件给替换掉了(替换成好的了)~~
- 刚才是改坏了,但是看起来好像 redis 服务器没有收到啥影响~~ 还是能正常启动,还是能正确获取到 key ~~这里具体 redis 会咋样, 取决于 rdb 文件坏了的地方在哪~~刚才是改坏的地方正好是文件末尾,对前面的内容没啥影响,如果是中间位置坏了,可就不一定了~~

- rdb 文件是二进制的~~
直接就把坏了的 rdb 文件交给 redis 服务器去使用,得到的结果是不可预期的~~
可能 redis 服务器能启动,但是得到的数据可能正确也可能有问题也可能 redis 服务器直接启动失败......
redis 也提供了 rdb 文件的检查工具~~可以先通过检査工具,检査一下 rdb 文件格式是否符合要求~~
1.2 rdb的特点
- RDB 是一个紧凑压缩的二进制文件,代表 Redis 在某个时间点上的数据快照。非常适用于备份全量复制等场景/比如每6小时执行 bgsave 备份,并把 RDB 文件复制到远程机器或者文件系统中(如 hdfs)用于灾备。
- Redis 加载 RDB 恢复数据远远快于 AOF 的方式。【RDB 这里使用二进制的方式来组织数据,直接把数据读取到内存中,按照字节的格式取出来放到 结构体/对象 中即可~~
AOF 是使用文本的方式来组织数据的,则需要进行一系列的字符串切分操作~~】 - RDB 方式数据没办法做到实时持久化!秒级持久化。因为 bgsave 每次运行都要执行fork 创建子进程,属于重量级操作,频繁执行成本过高。
- RDB 文件使用特定二进制格式保存,kedis 版本演进过程中有多个 RDB 版本,兼容性可能有风险。【老版本的 redis 的rdb文件,放到新版本的 redis 中不一定能识别~
一般来说,实际工作中,redis 版本都是统一的~~
如果确实需要有一些"升级版本"的需求~~
确实需要升级, 确实遇到了不兼容的问题~~就可以通过写一个程序的方式,直接遍历旧的 redis 中的所有 key,把数据取出来,插入到新的 redis 服务器中即可~~】 - RDB 最大的问题,不能实时的持久化保存数据在两次生成快照之间,实时的数据可能会随着重启而丢失~~
2.AOF
2.1 AOF的基本使用
- 当开启 aof 的时候,rdb 就不生效了~~
- 启动的时候不再读取 rdb 文件内容了~~
- 类似于 mysql 的 binlog就会把用户的每个操作,都记录到文件中,
- 当 redis 重新启动的时候,就会读取这个 aof 文件中的内容,用来恢复数据~~
- aof 默认一般是关闭状态,修改配置文件,来开启 aof 功能~~

相关操作

2.2 AOF是否会影响redis的性能
为啥速度快? 重要原因,只是操作内存~~
引入 AOF 之后, 又要写内存, 又要写硬盘~~ 还能和之前一样快了嘛??
实际上,是没有影响的!!! 并没有影响到 redis 处理请求的速度~~
1.AOF 机制并非是直接让工作线程把数据写入硬盘,而是先写入一个内存中的缓冲区,积累一波之后,再统一写入硬盘【大大降低了,写硬盘的次数~~
假设 100 个请求,100 个请求的数据,一次写入硬盘比 分 100 次,每次写入一个请求要快很多!!!
写硬盘的时候,写入硬盘数据的多少,对于性能影响没有很大,但是写入硬盘的次数则影响很大了~~】
2.硬盘上读写数据,顺序读写的速度是比较快的(还是比内存要慢很多)随机访问则速度是比较慢的~~
AOF 是每次把新的操作写入到原有文件的末尾.属于 顺序写入~~
2.3 AOF缓冲区刷新策略
- 如果把数据写入到缓冲区里,本质还是在内存中呀~~万一这个时候,突然进程挂了,或者主机掉电了,咋办?? 是不是缓冲区中的数据就丢了???
- 是的!!! 缓冲区中没来得及写入硬盘的数据是会丢的~~
- redis 给出了一些选项,让程序猿,根据实际情况来决定怎么取舍~~
- 缓冲区的刷新策略~~
- 刷新频率越高,性能影响就越大,同时数据的可靠性就越高
- 刷新频率越低,性能影响就越小,数据的可靠性就越低~~

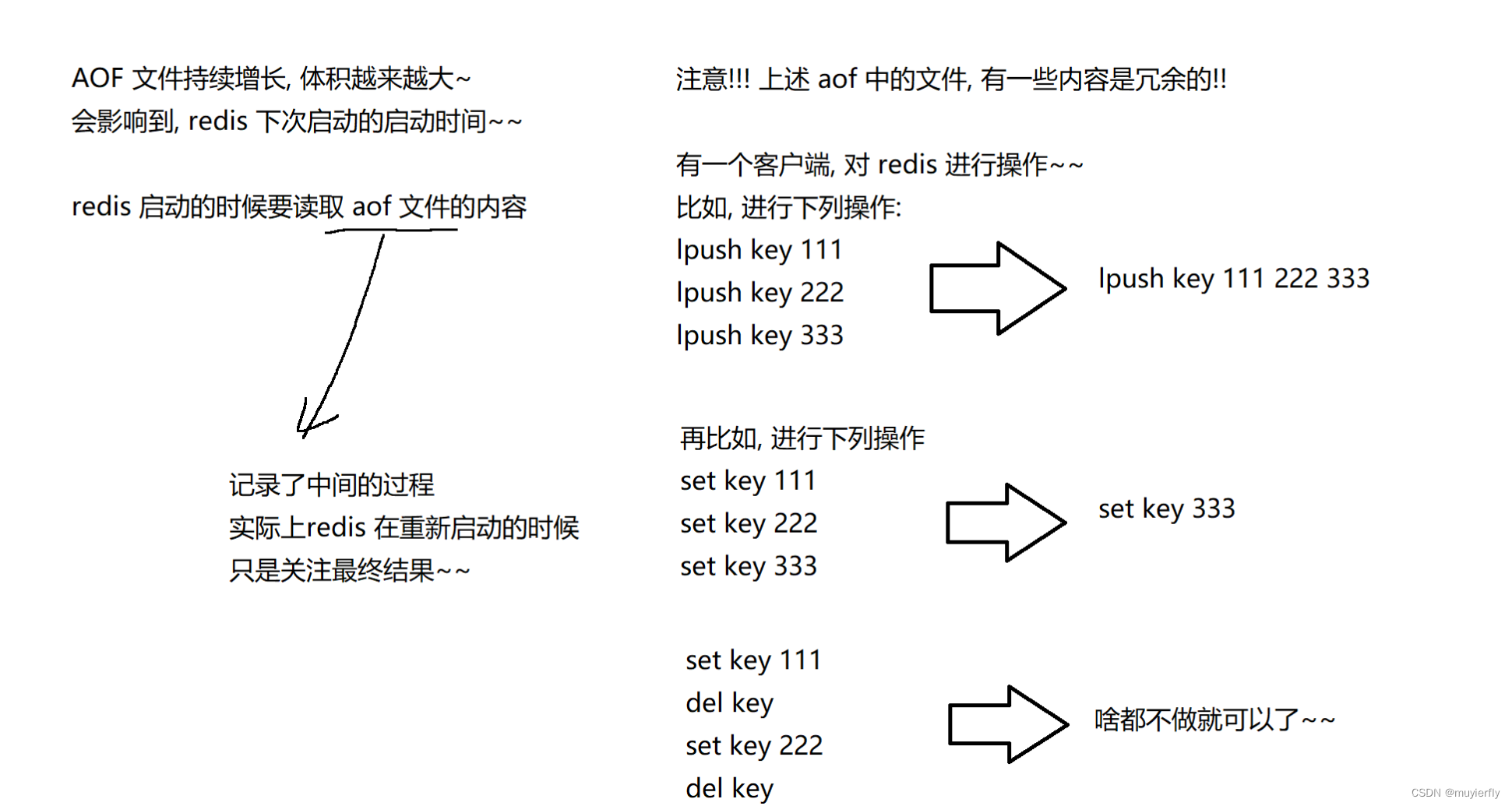
- 因此 redis 就存在一个机制,能够针对 aof 文件进行 整理 操作.
- 这个整理就是能够剔除其中的冗余操作,并且合并一些操作,达到给 aof 文件 瘦身 这样的效果

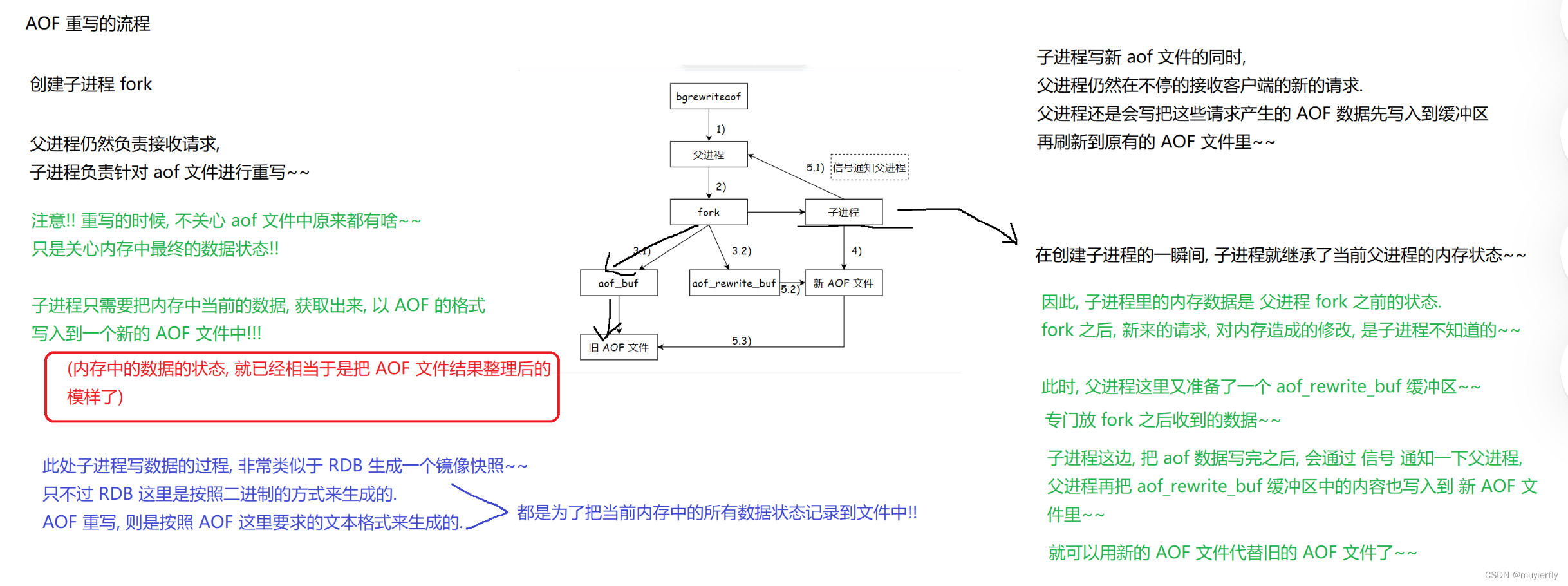
1.AOF的重写流程
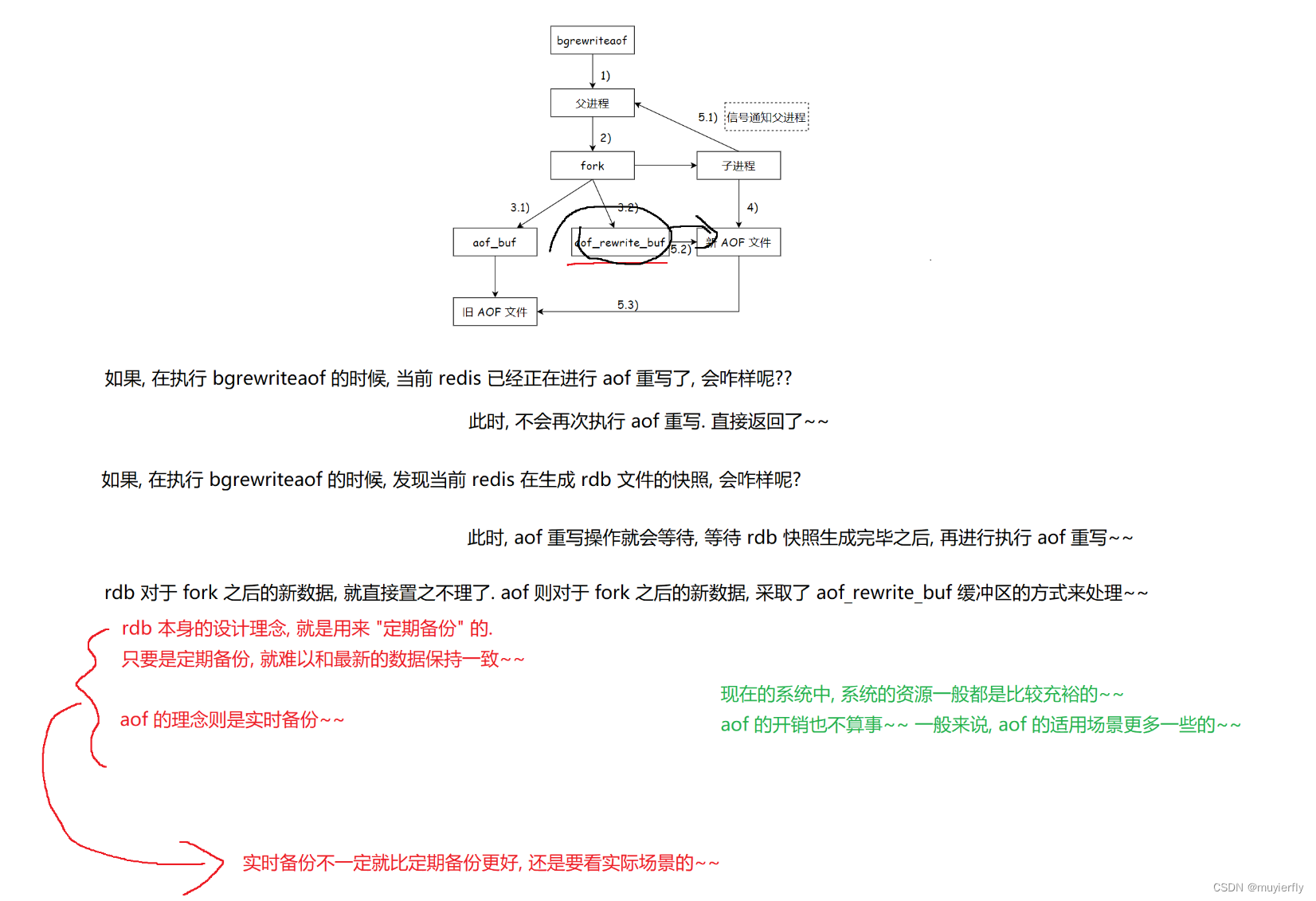

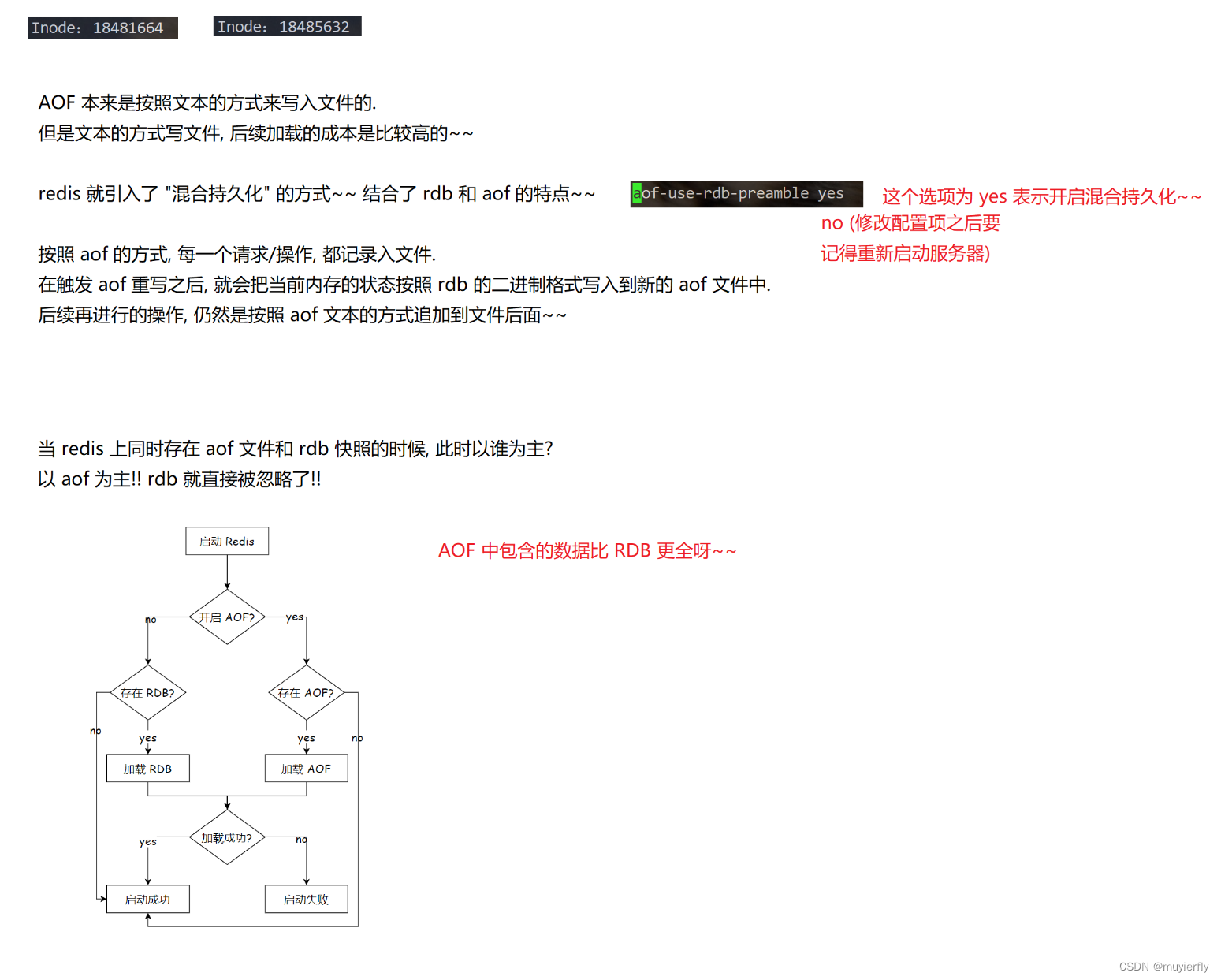
2.4 混合持久化
3.对于信号的解释
