一、Linux下载httpd服务并开启
yum install y httpd
systemctl start httpd
systemctl enable httpd二、获取已制作好的安装包
flink-1.12.2-bin-scala_2.11.tar
FLINK_ON_YARN-1.12.2.jar
flink-shaded-hadoop-2-uber-3.0.0-cdh6.3.2-10.0.jar三、集成CM
1.上传编译好的parcel
将编译好的flink-1.12.2-bin-scala_2.11.tar解压到/var/www/html并重命名
# 将flink-1.12.2-bin-scala_2.11.tar解压到/var/www/html
[root@bigdata1 html] tar -xvf /opt/software/flink-parcel/flink-1.12.2-bin-scala_2.11.tar -C /var/www/html/
[root@bigdata1 html] cd /var/www/html/
# 重命名目录名称
[root@bigdata1 html] mv FLINK-1.12.2-BIN-SCALA_2.11_build/ flink1.12.2-on-cdh6.3.2
[root@bigdata1 html] cd flink1.12.2-on-cdh6.3.2
# 创建flink-on-cdh的本地仓库,确保createrepo工具已经安装
[root@bigdata1 flink1.12.2-on-cdh6.3.2] yum install -y createrepo
[root@bigdata1 flink1.12.2-on-cdh6.3.2] createrepo .开启httpd服务后,可以通过以下网址查看是否正常上传
http://bigdata1/flink1.12.2-on-cdh6.3.2/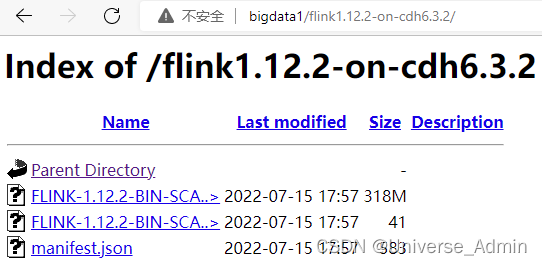
配置局域网flink的yum
[root@bigdata1 html] vim /etc/yum.repos.d/flink-on-cdh.repo添加如下配置
[flink-on-cdh]
name=flink-on-cdh
baseurl=http://bigdata1/flink1.12.2-on-cdh6.3.2/
enabled=1
gpgcheck=0将上述配置repo配置文件分发到所有节点上
所有节点上清除yum并建立yum缓存
yum clean all
yum makecache在CM-Server主节点 上,将FLINK_ON_YARN-1.12.2.jar包复制到/opt/cloudera/csd/目录下(目的是让cm识别)
[root@bigdata1 bin] cp /opt/software/flink-parcel/FLINK_ON_YARN-1.12.2.jar /opt/cloudera/csd/重启集群的CM-Server及CM-agent
service cloudera-scm-server restart
service cloudera-scm-agent restart2.配置parcel库
CM页面--->主机---> parcel ---> 配置,添加上传的parcel的位置

添加上传的parcel的位置
http://bigdata1/flink1.12.2-on-cdh6.3.2/
检查新Parcel ,然后下载--->分配--->激活
下载后报哈希验证失败错误
需要修改httpd配置文件
[root@bigdata1 flink1.12.2-on-cdh6.3.2] cp /etc/httpd/conf/httpd.conf /etc/httpd/conf/httpd.conf.bak
[root@bigdata1 flink1.12.2-on-cdh6.3.2] vim /etc/httpd/conf/httpd.conf在AddType中添加.parcel
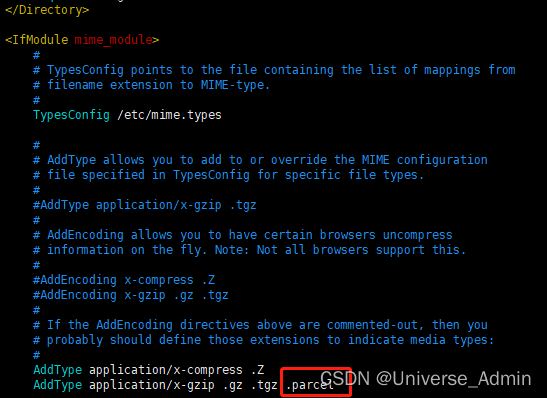
重启httpd服务
[root@bigdata1 flink1.12.2-on-cdh6.3.2] systemctl restart httpd再次下载--->分配--->激活成功
3.部署flink-yarn服务
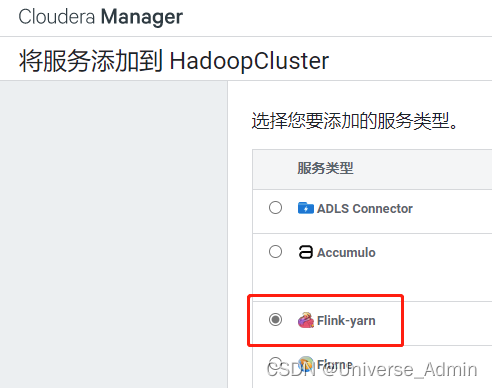
点击添加服务
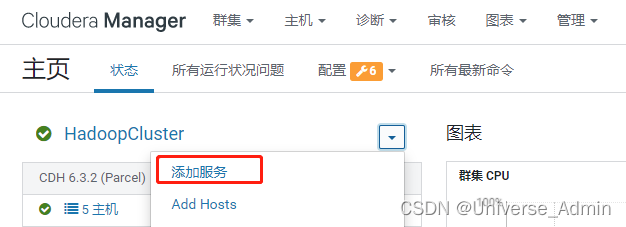
添加Flink-yarn服务
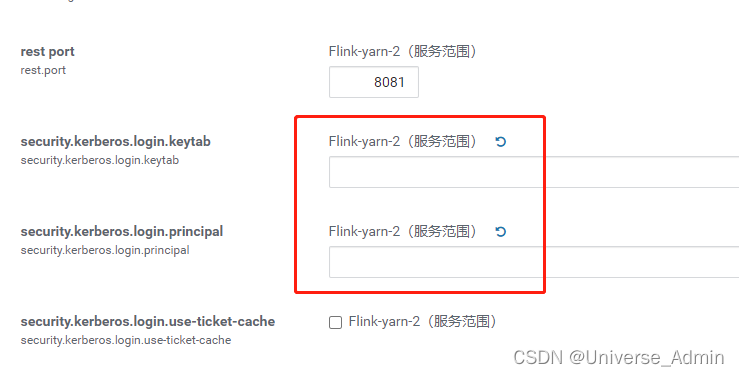
配置参数,kerberos的配置默认值清除掉,不填
其他参数按默认值继续安装
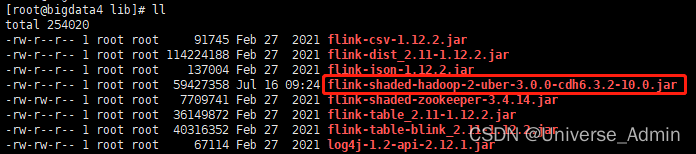
安装完成后,登录部署flink-yarn服务的后台上传flink-shaded-hadoop-2-uber-3.0.0-cdh6.3.2-10.0.jar
将其上传到/opt/cloudera/parcels/FLINK/lib/flink/lib目录下
然后启动flink-yarn服务
启动服务后,需要重启cm后端
service cloudera-scm-server restart4.webUI
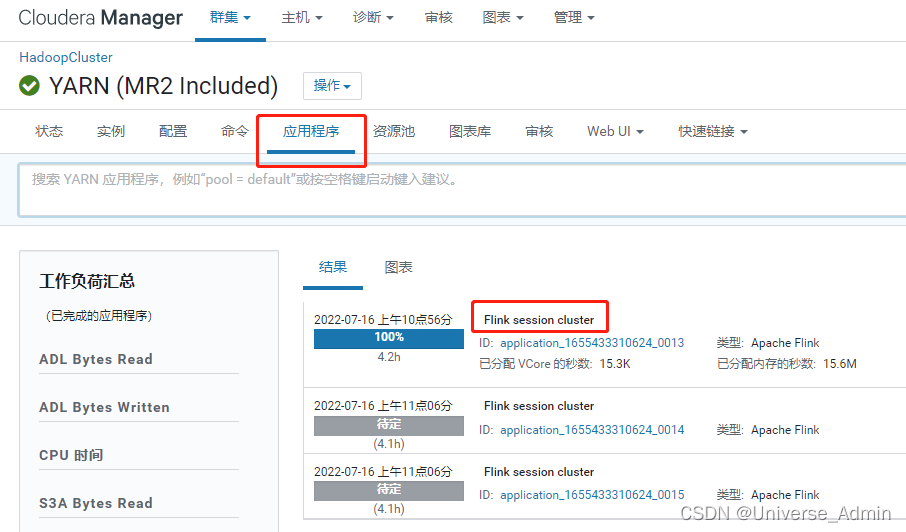
进入YARN

查看应用程序,其中的Flink session cluster即为Flink on yarn进程