《论文阅读》通过顺序不敏感的表示正则化实现稳健的个性化对话生成 ACL 2023
前言
亲身阅读感受分享,细节画图解释,再也不用担心看不懂论文啦~
无抄袭,无复制,纯手工敲击键盘~
今天为大家带来的是《Towards Robust Personalized Dialogue Generation via Order-Insensitive Representation Regularization》

出版:ACL
时间:2023
类型:个性化对话生成
特点:个性化;回复生成;鲁棒性;表示正则化
作者:Liang Chen
第一作者机构:The Chinese University of Hong Kong
相关个性化生成论文推荐
-
论文 《论文阅读》Learning to Know Myself: A Coarse-to-Fine Persona-Aware Training for Personalized Dialogue Generation 注重让模型捕获个性化信息,如通过问题生成个性化信息,利用对比学习构造相关但不一致的个性化信息作为负样本,提高模型捕获回复中关键个性化 Token 的能力【个性一致性】
-
论文 《论文阅读》具有人格自适应注意的个性化对话生成 AAAI 2023 认为生成个性化回复的关键是需要平衡上下文和个性化信息,由此提出利用个性化适应的注意力(Persona-Adaptive Attention,PAA)来适应性地调整两者之间的权重,此外一个动态地掩码矩阵用于去除冗余的信息,并进行正则化处理以防过拟合【权衡个性化信息和上下文】
简介
生成个性化一致性回复是至关重要的,过往的方法只是将个性化信息进行简单地拼接,然而作者通过实验分析发现,个性化信息输入模型的顺序会产生相差较大的结果,为了避免模型对顺序过于敏感,本文提出一种对顺序不敏感的生成方法(限制的优化方法)
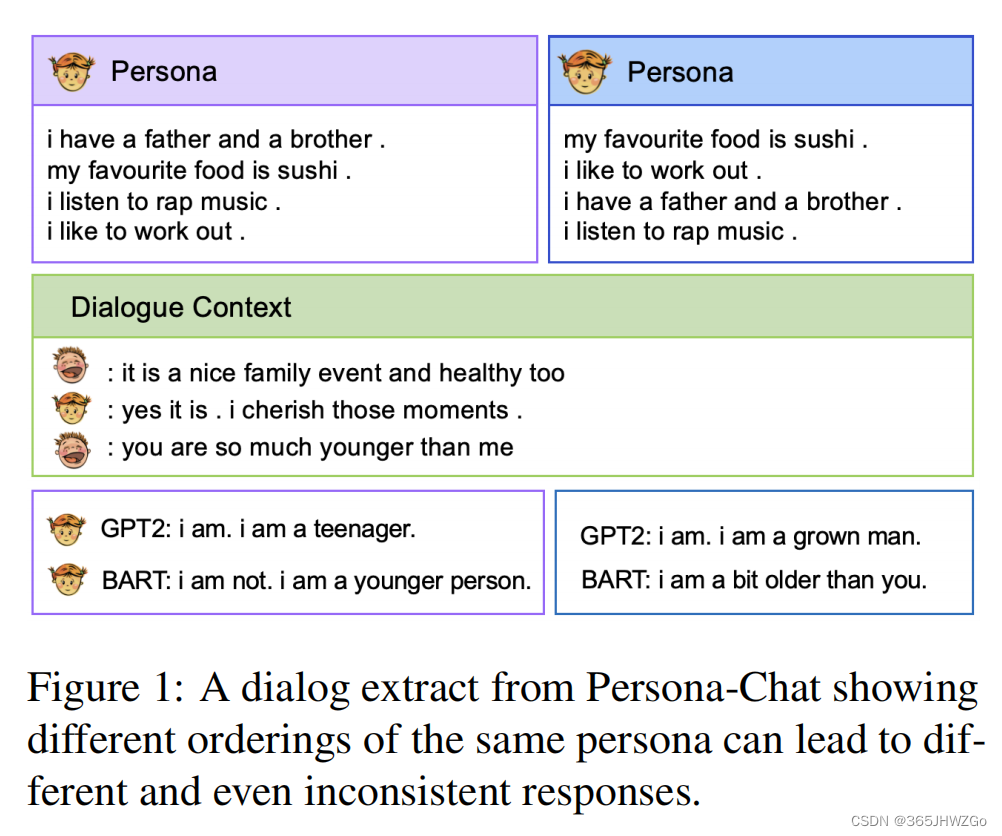
如上图所示,不同的 Persona 对于生成的结果有较大的影响,紫色框的回复明显比蓝色框的回复更具有一致性
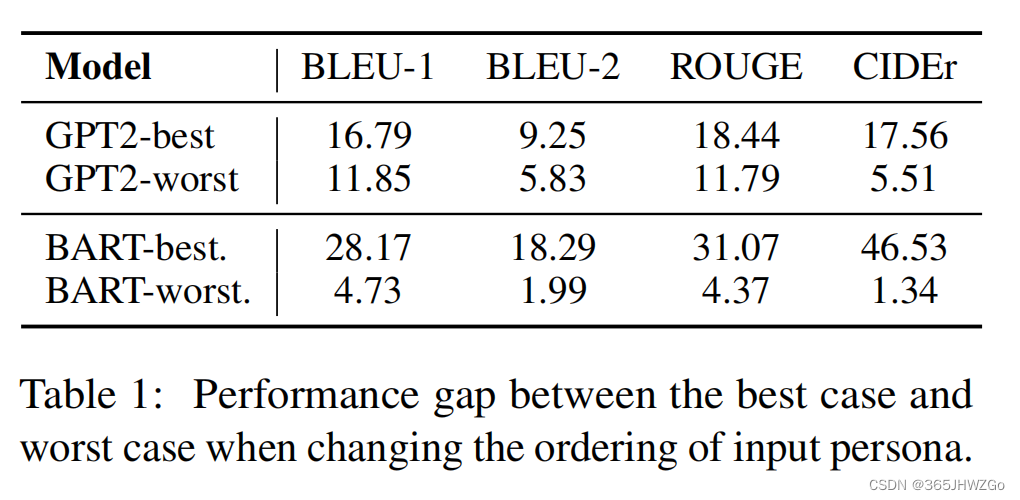
更具体的实验数据可以从上表中看出,作者将个性化信息所有可能的结果拼接上上下文依次输入到模型中,将最好的结果和最差的结果分别记录下来,由此得知,the ordering of persona in the input leads to different representations of context and response
问题定义

方法
作者将个性化优化问题转化为在不确定个性化信息输入顺序的情况下优化个性化模型
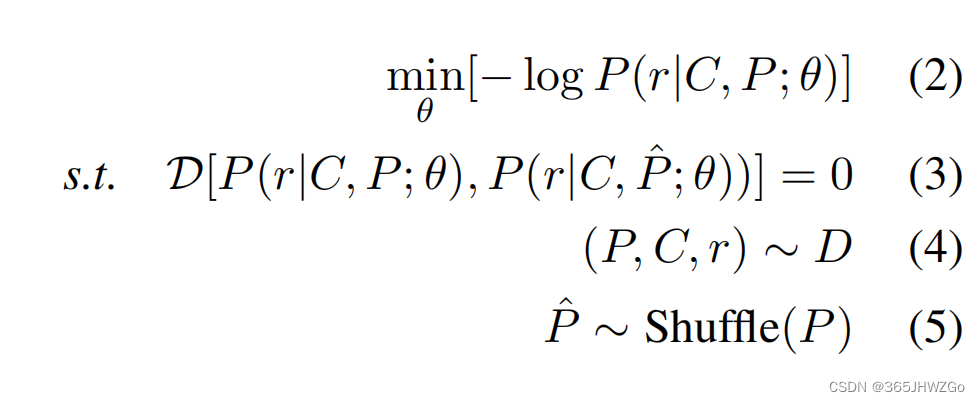
具体做法就是将不同的个性化顺序输入模型后,使得输出的表示彼此之间差异不大,理想情况下,不管什么输入顺序最后都能输出相同的表示
损失函数
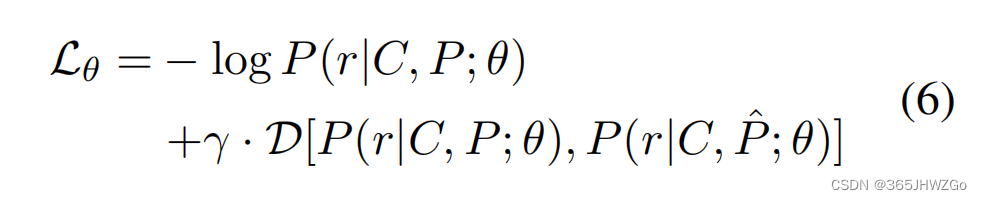
γ \gamma γ 是一个乘数,可以随着训练过程进行更新
实验结果
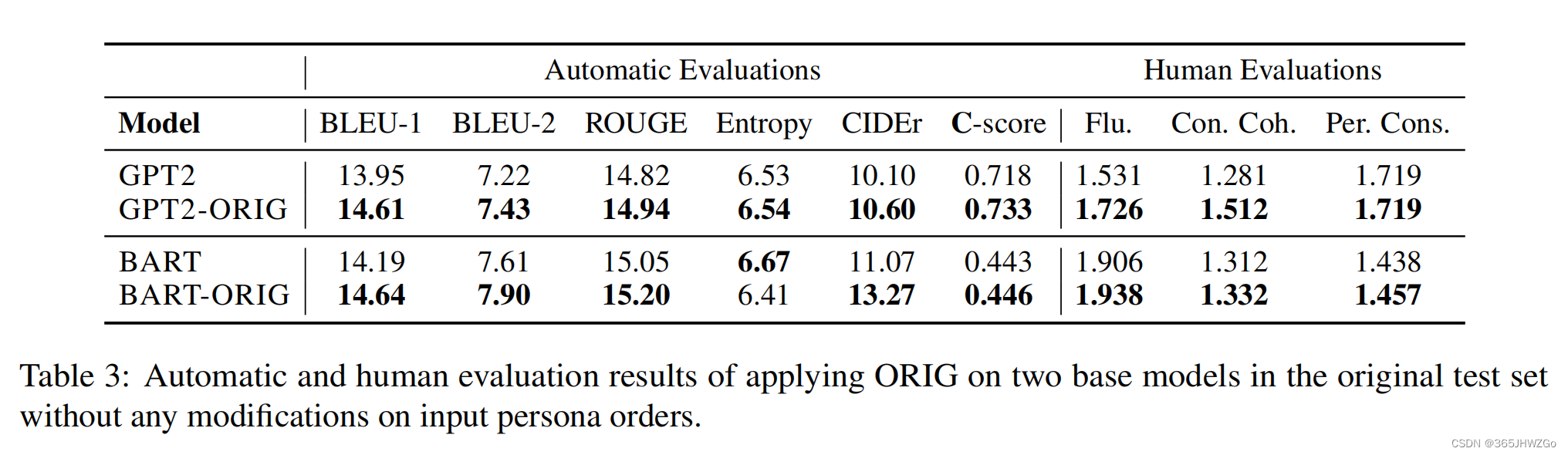
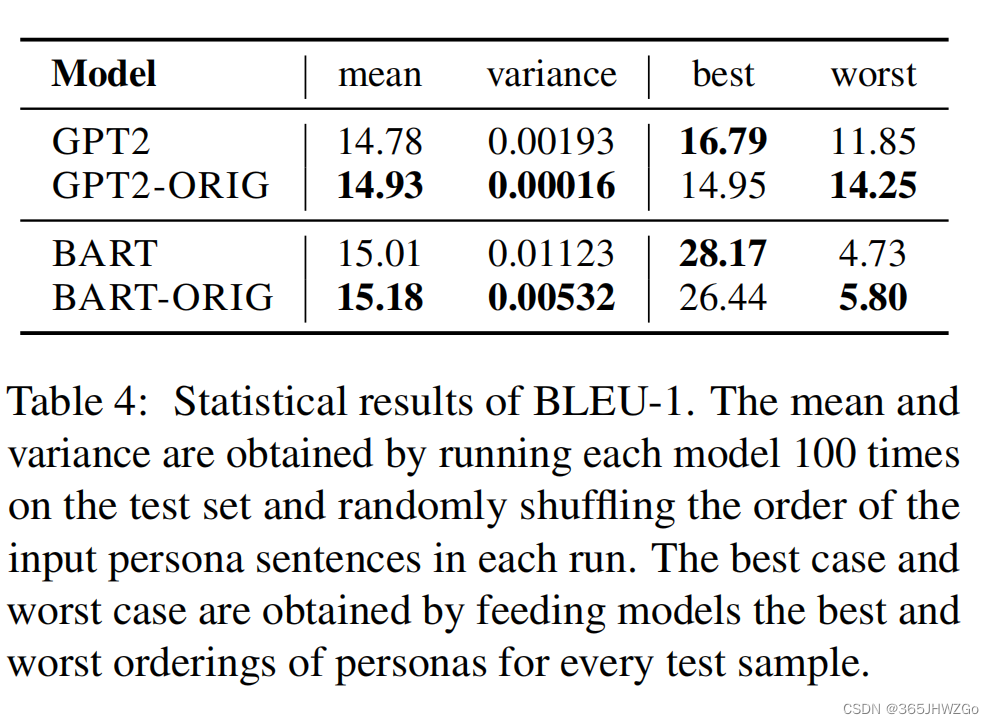
从实验结果可以看出,使用ORIG之后提高了最差顺序的表现,降低了最好顺序的表现,总体来说就是提高了均值和方差