主要特点:出轨迹是迭代了多次,每次出一条,然后去找和真值最近并且出现最早的轨迹,进行监督。
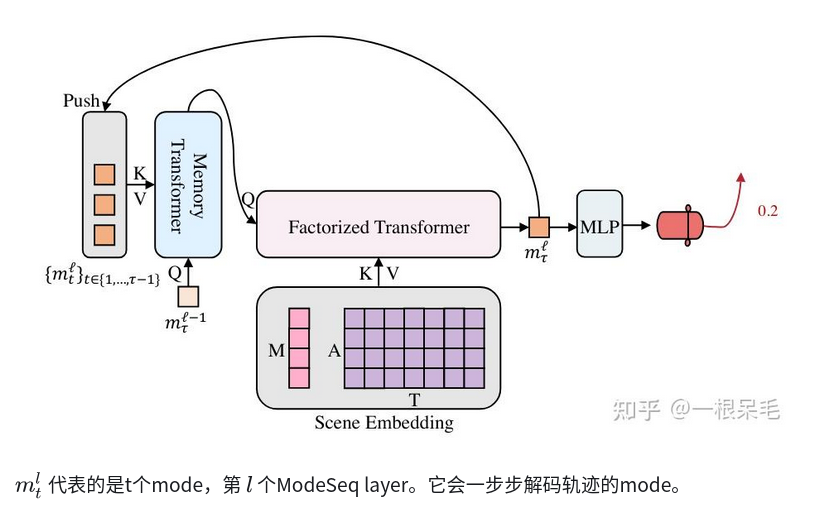 和QCNet一样loss是基于Laplace negative log-likelihood的。传统的WTA的策略只会监督和GT差异最小的那条轨迹。而EMTA策略会监督在RNN结构中找和GT match上的并且是相对更早decode出来的那条轨迹(也就是在RNN结构中认为概率更高的那条)。这里决定是不是match用的是Miss Rate的判定标准。如果没有match上的话,就退回WTA策略。这样就能让model尽早decode出目标的模态,也能提升Miss Rate的表现。
和QCNet一样loss是基于Laplace negative log-likelihood的。传统的WTA的策略只会监督和GT差异最小的那条轨迹。而EMTA策略会监督在RNN结构中找和GT match上的并且是相对更早decode出来的那条轨迹(也就是在RNN结构中认为概率更高的那条)。这里决定是不是match用的是Miss Rate的判定标准。如果没有match上的话,就退回WTA策略。这样就能让model尽早decode出目标的模态,也能提升Miss Rate的表现。
ModeSeq论文阅读
ZHANG8023ZHEN2025-08-03 13:15
相关推荐
柳叶方舟6 天前
npj Digital Medicine IF=15.1 | 多模态数字活检:术前无创预测胃癌隐匿性腹膜转移chnyi6_ya9 天前
论文阅读笔记 | VIDEOPHY: Evaluating Physical Commonsense for Video Generation闲研随记9 天前
【文献阅读 ICML 2026】RL算法:R2VPO0X7810 天前
从随机几何看下行卫星网络覆盖概率分析Eastmount10 天前
[论文阅读] (51)ESWA25 基于启发式优化器的入侵检测系统STLearner11 天前
ICML 2026 | LLM×Graph论文总结[1]【图基础模型,文本属性图,多模态属性图,图对齐,图提示学习,关系深度学习STLearner11 天前
ICML 2026 | 时间序列(Time Series)论文总结(3)【因果,可解释性,不规则时序,表示学习,benchmarzhuanshulz13 天前
《论文阅读 | LoopFrog: In-Core Hint-Based Loop Parallelization》EQUINOX113 天前
【论文阅读】| Swin-Transformer精读EQUINOX114 天前
【论文阅读】| MoCo精读