Editing Large Language Models: Problems, Methods, and Opportunities
-
原文摘要
-
研究背景与问题提出
-
核心问题 :尽管LLM已具备强大的能力,但如何长期维持其时效性 并修正错误仍缺乏系统方法论。
-
现状 :近年来,针对LLMs的模型编辑技术 兴起,其目标是通过高效修改模型在特定领域的行为,同时避免对其他输入的性能产生负面影响。
-
研究目标
-
系统梳理:明确模型编辑的任务定义与核心挑战。
-
实证分析:对当前最先进的编辑方法 进行深入评估。
-
构建新基准 :提出一个更鲁棒的评测数据集,以揭示现有技术的固有缺陷。
-
-
方法论与贡献
-
-
理论层面 :
-
提供任务定义的详尽综述 ,明确模型编辑的边界与评价标准。
-
分析技术挑战,如编辑的局部性与全局影响的权衡。
-
-
实践层面 :
-
实证分析 :对比现有方法的有效性与可行性。
-
新基准数据集:通过标准化评测暴露当前方法的共性问题(如过编辑/欠编辑、泛化性不足等)。
-
-
关键词:
-
鲁棒评测:强调新数据集需覆盖多样场景,避免评估偏差。
-
任务/上下文适配:不同编辑方法可能适用于不同需求(如事实更新 vs. 行为调整)。
-
研究意义
-
-
根据具体任务或上下文,选择最优编辑方法。
-
识别当前技术的局限性,推动未来研究,如如何实现长期稳定的模型编辑。
-
1. Introduction
-
研究背景与现状
-
LLMs的能力与局限:
- 能力:LLMs在文本理解与生成上的已有显著突破。
- 局限 :训练高效LLMs虽可行,但长期维护模型时效性 和修正错误缺乏明确策略。
-
核心需求 :在世界状态持续变化的背景下,避免全模型重训练,实现高效更新。
-
-
现有工作与不足
-
技术进展: 编辑方法分为两类
- 参数修改:直接调整模型参数。
- 外部干预:通过附加组件干预输出。
-
现存缺陷:
- 缺乏统一评估 :现有研究在实验设置上差异大,导致无法公平比较各方法优劣。
- 评估维度单一 :多数工作仅关注基础编辑任务,忽略泛化性 、副作用 、效率 等实际应用指标。
- 于是作者提出了更全面的评估维度:
- Portability:编辑后模型在相关但未见过输入上的泛化能力。
- Locality:对非目标输入的副作用(如无关领域性能下降)。
- Efficiency:时间与内存开销(实际部署关键指标)。
- 于是作者提出了更全面的评估维度:
-
-
研究发现与意义
-
主要结论:
- 当前方法在基础事实编辑上有效,但在泛化性、副作用控制、效率方面存在局限。
- 这些局限阻碍实际应用,需未来研究突破。
-
研究价值:
- 通过系统评估,提供技术选择指南(如医疗领域需高locality,实时系统需高效率)。
- 揭示未来方向:如如何平衡编辑强度与模型稳定性。
-
2. Problems Definition
2.1 数学定义
-
基础模型:
- 初始模型表示为 fθ:X→Yf_\theta: X \rightarrow Yfθ:X→Y
- θ\thetaθ 为参数,x∈Xx \in Xx∈X 为输入,y∈Yy \in Yy∈Y为输出。
- 初始模型表示为 fθ:X→Yf_\theta: X \rightarrow Yfθ:X→Y
-
编辑目标:
- 给定一个需要修改 的输入-输出对 (xe,ye)(x_e, y_e)(xe,ye),要求编辑后模型 fθef_{\theta_e}fθe 满足 fθe(xe)=yef_{\theta_e}(x_e) = y_efθe(xe)=ye
-
编辑范围的划分
-
编辑域内 In-Scope :I(xe,ye)I(x_e, y_e)I(xe,ye)
- 包含目标样本 xex_exe 及其等价邻域 N(xe,ye)N(x_e, y_e)N(xe,ye)(如语义相似的输入或改写句式)。
-
编辑域外 Out-of-Scope : O(xe,ye)O(x_e, y_e)O(xe,ye)
- 与编辑无关的输入
- 编辑要求
fθe(x)={yeif x∈I(xe,ye)fθ(x)if x∈O(xe,ye) f_{\theta_e}(x) = \begin{cases} y_e & \text{if } x \in I(x_e, y_e) \\ f_\theta(x) & \text{if } x \in O(x_e, y_e) \end{cases} fθe(x)={yefθ(x)if x∈I(xe,ye)if x∈O(xe,ye)
-
2.2 编辑效果的评价维度
2.2.1 可靠性 Reliability
- 定义 :编辑后的模型必须对目标样本 (xe,ye)(x_e, y_e)(xe,ye) 输出正确结果。
E(xe′,ye′)∼{(xe,ye)}1argmaxyfθe(y∣xe′)=ye′ \mathbb{E}_{(x'_e, y'_e) \sim \{(x_e, y_e)\}} \mathbb{1}\left\\arg\\max_y f_{\\theta_e}(y \\mid x'_e) = y'_e\\right E(xe′,ye′)∼{(xe,ye)}1argymaxfθe(y∣xe′)=ye′
2.2.2 泛化性 Generalization
- 定义 :编辑需推广到等价邻域 N(xe,ye)N(x_e, y_e)N(xe,ye)(如语义相似的输入)。
E(xe′,ye′)∼N(xe,ye)1argmaxyfθe(y∣xe′)=ye′ \mathbb{E}_{(x'_e, y'_e) \sim N(x_e, y_e)} \mathbb{1}\left\\arg\\max_y f_{\\theta_e}(y \\mid x'_e) = y'_e\\right E(xe′,ye′)∼N(xe,ye)1argymaxfθe(y∣xe′)=ye′
2.2.3 局部性 Locality
- 定义 :编辑不得影响无关输入(域外样本)的输出。
E(xe′,ye′)∼O(xe,ye)1fθe(y∣xe′)=fθ(y∣xe′) \mathbb{E}_{(x'_e, y'_e) \sim O(x_e, y_e)} \mathbb{1}\leftf_{\\theta_e}(y \\mid x'_e) = f_\\theta(y \\mid x'_e)\\right E(xe′,ye′)∼O(xe,ye)1fθe(y∣xe′)=fθ(y∣xe′)
3. Current Methods
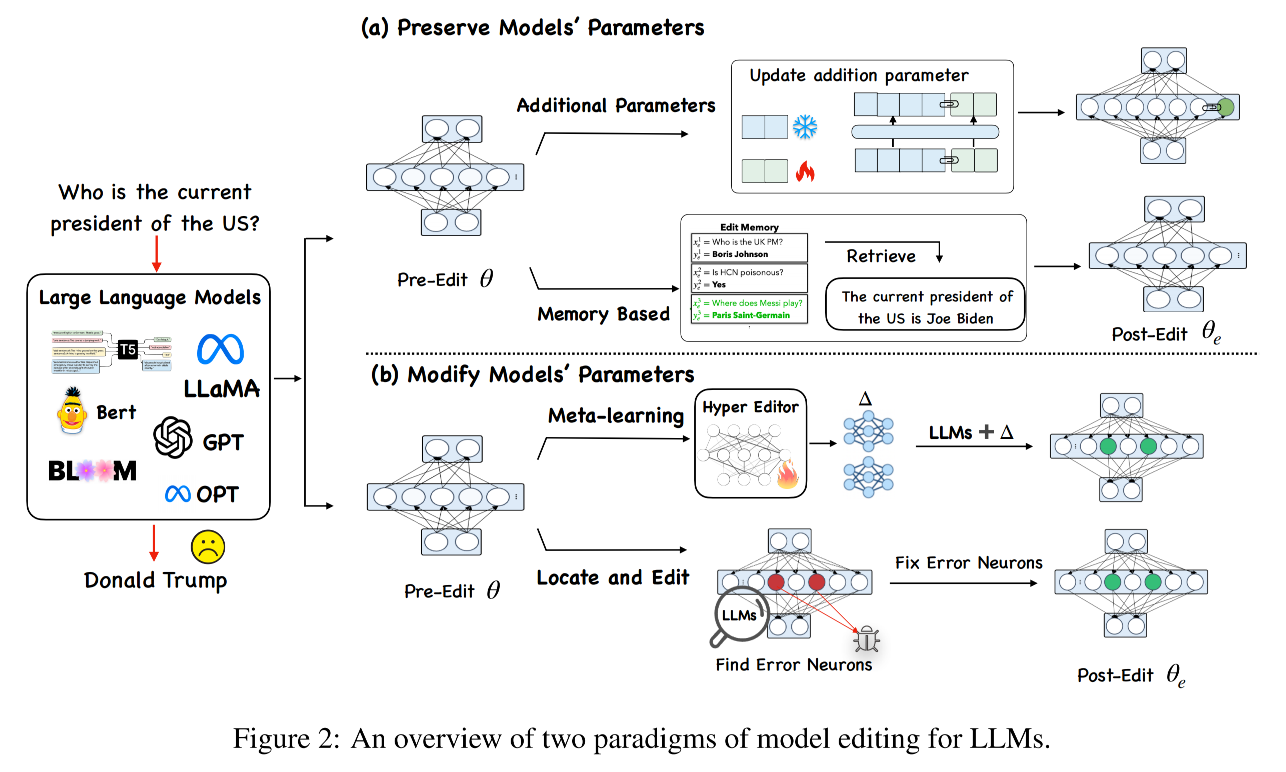
3.1 不修改LLM参数的方法
3.1.1 基于记忆的方法
- 核心思想:把所有的编辑样本显式存储到一个记忆库中,当有新输入时,通过检索找出最相关的编辑事实,用它们来引导模型生成包含这些修改知识的答案。
- SERAC :
- 保留原始模型不变
- 引入一个counterfactual model:同样是一个语言模型,专门用来处理编辑过的事实
- 使用一个scope classifier 判断输入是否属于编辑过的范围:
- 如果是,则由 counterfactual model 结合最可能的编辑事实来输出答案。
- 如果不是,则用原始模型的预测结果。
- In-context Learning :
- 利用 LLM 强大的上下文学习能力,不需要额外训练新的模型,只需在 Prompt 中提供编辑过的事实和从记忆库中检索到的示例,模型就能输出对应的知识。
3.1.2 引入额外参数的方法
-
核心思想:在模型中额外引入小部分可训练参数,训练时只更新这部分参数,而原始 LLM 的参数保持不变。
-
代表方法:
-
T-Patcher:在 FFN 最后一层为每个错误增加一个patch(类神经元),只在遇到对应错误时才激活。
-
CaliNET:不只一个 patch,而是为多个编辑情况引入多个神经元。
-
GRACE :使用一个离散的codebook 适配器,在需要时添加或更新其中的元素来修正模型输出。
-
Codebook 的构成
-
Key:离散化后的 latent code
-
Value:存储需要替换或添加的知识的向量表示
-
-
-
3.2 修改LLM参数的方法
- 这一类方法会直接修改原始模型的部分参数 (θ\thetaθ),通常通过一个参数更新矩阵 Δ\DeltaΔ 来完成编辑。
3.2.1 Locate-Then-Edit 先定位再编辑
-
核心思想:先找到模型内部与特定知识对应的参数位置,再直接修改这些参数。
-
代表方法:
-
Knowledge Neuron (KN):用知识归因方法找到对应知识的知识神经元,然后更新它们。
-
知识归因方法
-
把一个神经元的激活置零,看预测的变化幅度。
-
按重要性排序,选出贡献最大的神经元集合作为 知识神经元。
-
-
-
ROME :++不是改单个神经元,而是修改整个矩阵++。
- 一次只能编辑一个事实。
-
MEMIT:基于 ROME,支持同时编辑多个事实。
-
PMET:在 MEMIT 的基础上,引入注意力值来提升性能。
-
3.2.2 Meta-learning
- 核心思想 :用一个超网络学习如何生成合适的参数更新 Δ\DeltaΔ,以最小化编辑对其他知识的破坏。
- 代表方法:
- Knowledge Editor (KE)
- 用双向 LSTM 作为超网络,为每个数据点预测权重更新,实现受约束的知识编辑。
- 缺点:不适合直接编辑 LLM。
- MEND
- 解决 KE 在 LLM 上的局限性。
- 学习如何将微调模型的梯度转化为低秩梯度更新,从而在 LLM 上有更好的效果。
- Knowledge Editor (KE)
4. Preliminary Experiments
- 因为现有关于事实知识的研究和数据集非常丰富,所以选择事实知识作为主要比较对象。
- 通过在两个重要数据集上做对照实验,可以直接比较不同方法的优缺点。
4.1 实验设置
- 数据集:ZsRE、COUNTERFACT
- 模型选择
- 之前的研究通常在小模型上验证,比如 BERT。
- 本文希望探究更大模型 是否也适用这些编辑方法:
- T5-XL(3B):encoder-decoder架构
- GPT-J(6B):decoder-only架构
- 对比方法 :
- 各类别的代表性方法
- FT-L:只微调 ROME 找到的相关层,以减少计算量并保持公平比较。
4.2 实验结果
-
base model
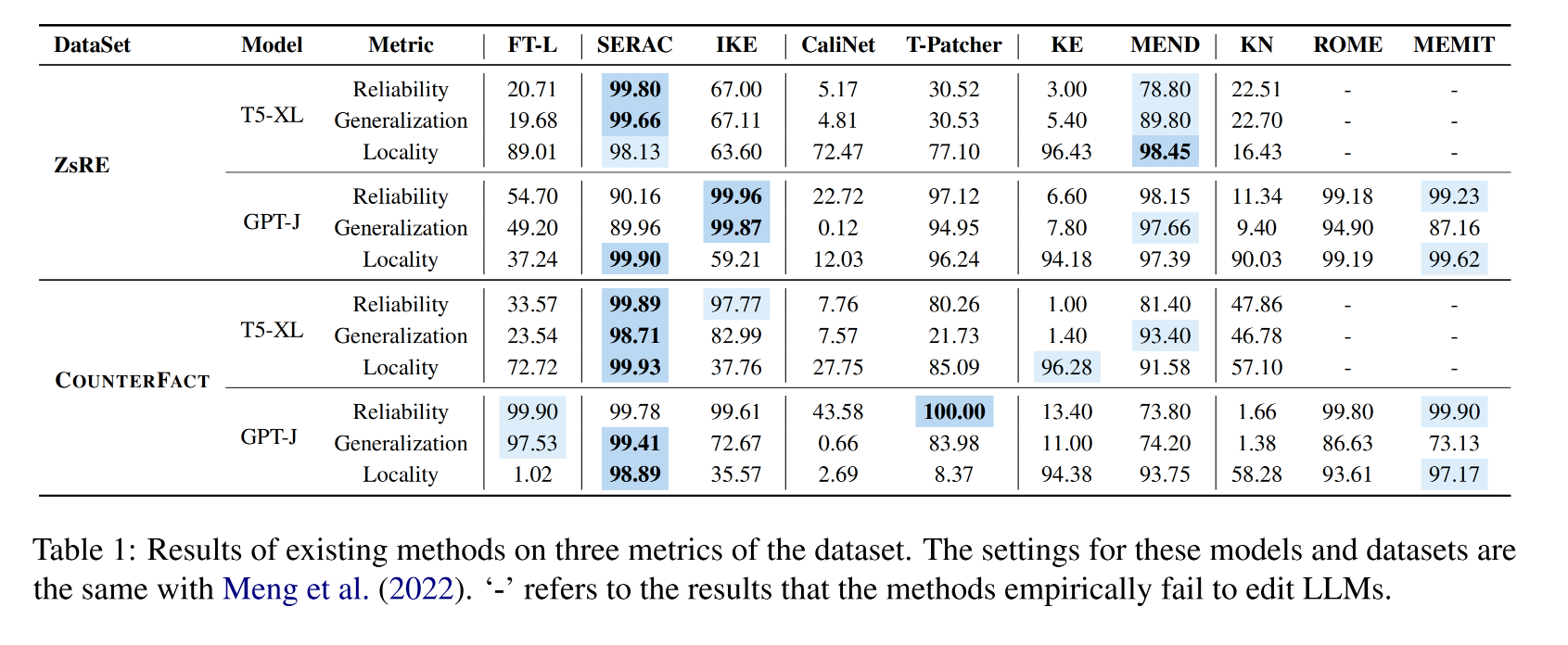
-
模型扩展实验
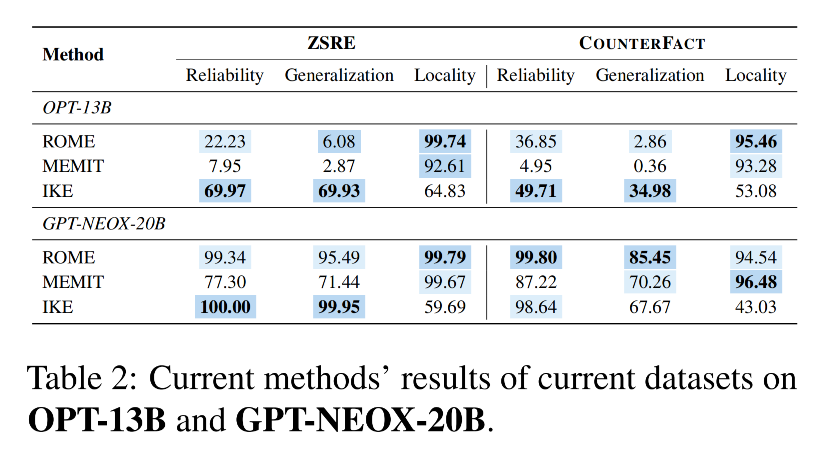
-
批量编辑实验
-
现实中可能一次改很多知识,所以测试批量修改:

-
-
连续编辑实验
- 默认评测是改一条--评估--回滚--再改下一条,但现实中模型要保留之前的修改,所以测试连续编辑能力
- 冻结参数类方法(SERAC, T-Patcher)在连续编辑中性能稳定
- 改参数类方法 性能会下降:
- ROME:n=10 还好,n=100 明显下降
- MEMIT:n=100 后下降,但没 ROME 那么快
- MEND:n=1 很好,n=10 就掉得很厉害
- 原因:多次编辑会让模型偏离原始状态,性能变差
- 默认评测是改一条--评估--回滚--再改下一条,但现实中模型要保留之前的修改,所以测试连续编辑能力
5. Comprehensive Study
5.1 可迁移性:鲁棒的泛化
-
背景问题:
- 以前的泛化测试只是改了少量措辞,并没有涉及事实层面的重大变化。
- 现实应用需要验证模型能否真正理解并迁移被编辑的知识。
-
Portability指标
-
衡量模型能否将编辑过的知识迁移到相关内容上,为此设计了三个子任务:
-
Subject Replace(主体替换)
- 用同义词或别名替换问题中的主体,看模型是否能将修改的属性泛化到该主体的其他称呼。
-
Reversed Relation(反向关系)
- 如果修改了主体和关系的目标,那么目标实体的属性也应随之改变。
- 例如如果修改"X的首都是Y",那么"Y是X的首都"也应一致更新。
- 如果修改了主体和关系的目标,那么目标实体的属性也应随之改变。
-
One-hop Reasoning(一跳推理)
- 编辑后的知识能否用于推理相关事实。
- 例如,修改了"Watts Humphrey 就读于 University of Michigan",那么问"他大学期间住在哪个城市"时,应答"Ann Arbor in Michigan State"而不是原先的"Dublin in Ireland"。
- 编辑后的知识能否用于推理相关事实。
-
-
-
数据集构造 :基于原始数据集,增加 P(xe,ye)P(x_e, y_e)P(xe,ye) 部分------可迁移数据集
-
结果
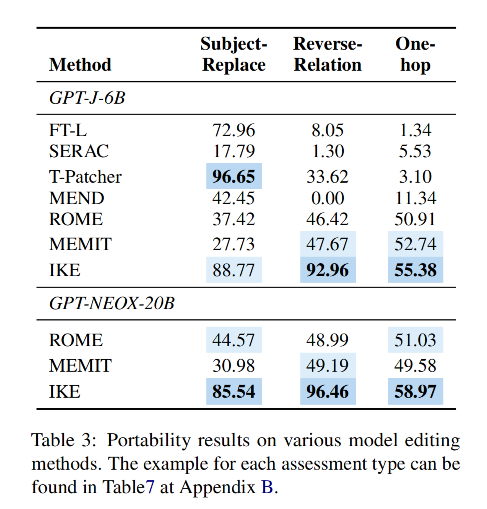
5.2 局部性:编辑的副作用
-
背景问题:
- 局部性是指模型在修改目标知识时,不应无意中改变其他知识或任务性能。
- 现有 COUNTERFACT 和 ZsRE 从不同数据分布测试局部性,但结果差异明显,说明需要更细化的测试。
-
新的三类评估:
-
Other Relations(其他关系):编辑主体的某个属性后,其他未编辑的属性应保持不变。
-
Distract Neighbourhood(干扰邻域):测试编辑样例被拼接在无关输入前,模型是否会被带偏。
-
Other Tasks(其他任务):检查编辑是否影响模型在其他任务上的表现(如常识推理)。
-
5.3 效率
-
目标: 编辑应尽量减少时间和显存消耗,同时保持性能。
-
时间分析:
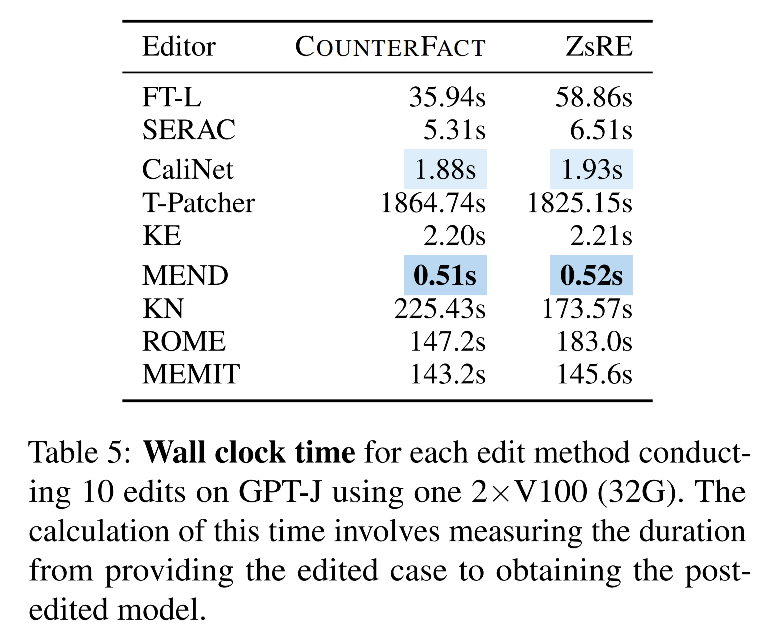
-
显存分析
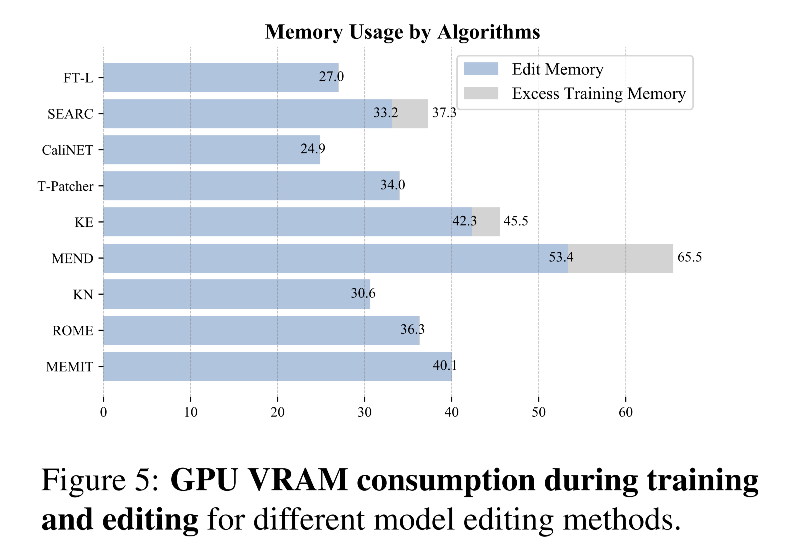
6. Relationship with Relevant Works
6.1 大模型中的知识表示
-
核心问题 :LLMs如何存储和表示知识?这对精准编辑至关重要。
-
知识存储机制:
- 研究表明,知识主要分布在FFN层的中间神经元。
- 知识归因技术:通过激活分析定位特定知识对应的参数子集。
-
与知识增强的联系:
- 模型编辑可视为动态知识注入,类似检索增强,但编辑直接修改参数而非依赖外部检索。
6.2 持续学习与机器遗忘
-
持续学习(Continual Learning)
- 关联性 :模型编辑需支持终身学习 ,即在不遗忘旧知识的前提下增量学习新知识。
- 传统持续学习通过正则化或参数隔离防止灾难性遗忘,但计算成本高。
- 模型编辑(如MEMIT)通过局部参数更新实现高效持续学习,避免全模型微调。
- 关联性 :模型编辑需支持终身学习 ,即在不遗忘旧知识的前提下增量学习新知识。
-
机器遗忘(Machine Unlearning)
- 隐私需求 :要求模型主动遗忘 敏感信息(如用户隐私、有害内容)。
- 编辑技术可直接擦除参数中的特定知识。
- 对比传统遗忘方法,模型编辑(如SERAC)通过外部记忆库控制知识访问更高效。
- 隐私需求 :要求模型主动遗忘 敏感信息(如用户隐私、有害内容)。
6.3 安全与隐私
-
核心挑战:LLMs可能泄露隐私或生成有害内容。
-
编辑技术的应用:
- 抑制有害输出:通过修改参数或注入安全规则,阻止模型生成暴力、偏见等内容。
- 隐私保护:删除训练数据中的敏感信息。