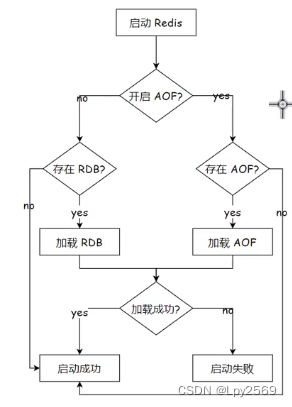
Redis ⽀持 RDB ( 定期备份 ) 和 AOF ( 实时备份 ) 和 混合持久化 (结合RDB 和 AOF 的特点) 持久化机制,持久化功能有效地避免因进程退出造成数据丢失问题, 当下次重启时利⽤之前持久化的⽂件即可实现数据恢复。
RDB(Redis DataBase)
RDB 是一种快照备份机制,在指定的时间间隔内将内存中的数据集快照写入磁盘。
1. 手动触发
save:执行 save 的时候,redis 就会全力以赴的进行 " 快照生成 " 操作,此时就会阻塞 redis 的其他客户端的命令,直到进行 RDB 为止,导致类似于 keys * 的后果。一般不建议使用 save。
bgsave:Redis 进程执⾏ fork 操作创建⼦进程,RDB 持久化过程由⼦进程负责,完成后⾃动 结束。阻塞只发⽣在 fork 阶段,⼀般时间很短。不会影响 Redis 服务器处理其他客户端的请求和命令。
2. 自动触发
Redis 运行自动触发 RDB 持久化机制。
-
使用 save 配置。如 "save m n" 表示 m 秒内数据集至少发生了 n 次修改,自动 RDB 持久化。
-
执行 shutdown 命令关闭 Redis 时,执行 RDB 持久化
-
从节点进行全量复制操作时,主节点自动进行 RDB 持久化,随后将 RDB ⽂件内容发送给从结点。
特点
**(1)数据恢复:**RDB 存储的是 Redis 在某个时间点的数据,恢复时只需从磁盘中读取最近保存的快照文件即可,因此恢复速度非常快。
**(2)数据完整性:**由于是按一定时间间隔进行备份,数据可能会存在一部分的丢失,对数据完整性和一致性要求不高时更适合使用。
**(3)磁盘空间:**RDB文件是二进制数据压缩文件,数据落地速度快,体积小,节省磁盘空间。
**(4)性能影响:**在Fork的时候,内存中的数据被克隆了一份,大致2倍的膨胀性需要考虑。虽然Redis 在 fork 时使用了写时拷贝技术,但如果数据庞大时还是比较消耗性能。
**使用场景:**更适合于对数据完整性要求不高、需要快速恢复且数据量较大的场景,如数据备份存储。
AOF(Append Only File)
AOF 是以日志的形式来记录每个写操作(增量保存),将 Redis 执行过的所有写指令记录下来(读操作不记录)。每次 Redis 重启的时候会读取 AOF 文件中的内容用来恢复数据(开启AOF 时 RDB 就不生效了,启动的时候不会再读取 RDB 了)
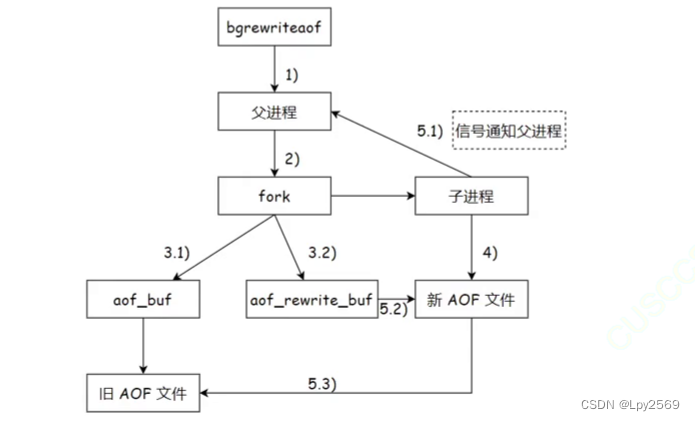
AOF 重写机制:
在进行 AOF 进行重写数据时,会有大量冗余操作(比如你set key 又 del key 就相当于啥都没干),redis 中就存在重写机制对 AOF 文件进行整理(为内存中的如今状态)。
特点
**数据恢复:**Redis 重启时会根据 AOF 文件的内容将写指令从前到后执行一次以完成数据的恢复工作,备份机制更稳健,丢失数据概率更低。
**可读性:**AOF 文件是可读的日志文本,通过操作AOF文件可以处理误操作。 磁盘空间:AOF 相比RDB 会占用更多的磁盘空间。
**恢复速度:**由于 AOF 记录了所有的写操作,恢复备份速度要慢于 RDB。
**性能影响:**如果每次读写都同步到 AOF 文件,会有一定的性能压力。
**使用场景:**更适合于对数据完整性要求高、需要记录每次写操作的场景,如数据恢复和误操作处理。
扩展问题
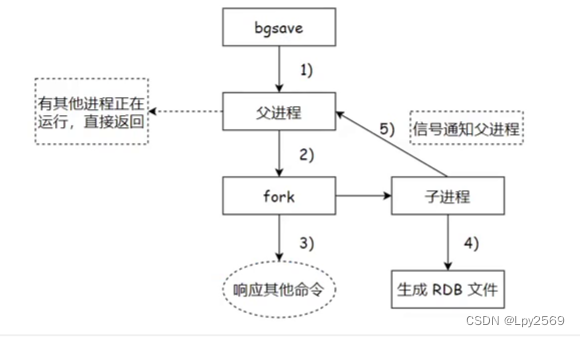
Redis 是单线程,怎么做到实现bgsave这个多线程的场景呢???
答:redis 在此处使用的是 "多进程" 的方式来完成的并发编程。
-
执行 bgsave 命令,Redis 父进程判断当前进是否存在其他正在执⾏的子进程,如 RDB / AOF 子进程,如果存在 bgsave 命令直接返回。(也就是看看是不是只有一个在执行 bgsave)
-
没有子进程的话,就通过 fork 创建子进程(就是把父进程复制一份,互不干扰)。
-
父进程完成 fork 后不再阻塞,可以继续响应其他命令。
-
子进程创建 RDB 文件,根据⽗进程内存生成临时快照文件,完成后对原有文件进行原子替换。
-
进程发送信号给父进程表示完成,父进程更新统计信息。
Redis 快重要原因是操作内存,但是引入 AOF 后,既要写内存还要写硬盘,为啥 Redis 还是很" 快 " ???
AOF 不会影响到 redis 处理请求的速度:
- AOF 机制不是直接让工作线程把数据写到硬盘,而是先写到内存中的缓冲区,进行积累,再统一写入硬盘。大大降低了写硬盘的次数。(写到硬盘中的数据大小对性能影响不大,写入的次数是重要因素)
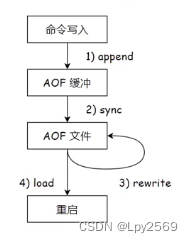
- 硬盘上读写数据,顺序读写相对比较快(还是比读内存慢),随机访问比较慢。AOF 就是把新的操作写入到原有文件的末尾属于顺序写入。
上面说写入到缓冲区,那么缓冲区刷新策略是什么呢 ?
always:写一条数据到缓冲区就立马刷新。
everysec:每秒刷新一次。
no:操作系统自己进行刷新。