一、SQL执行流程
MySQL是客户端-服务器的模式。一条SQL的执行流程如下:
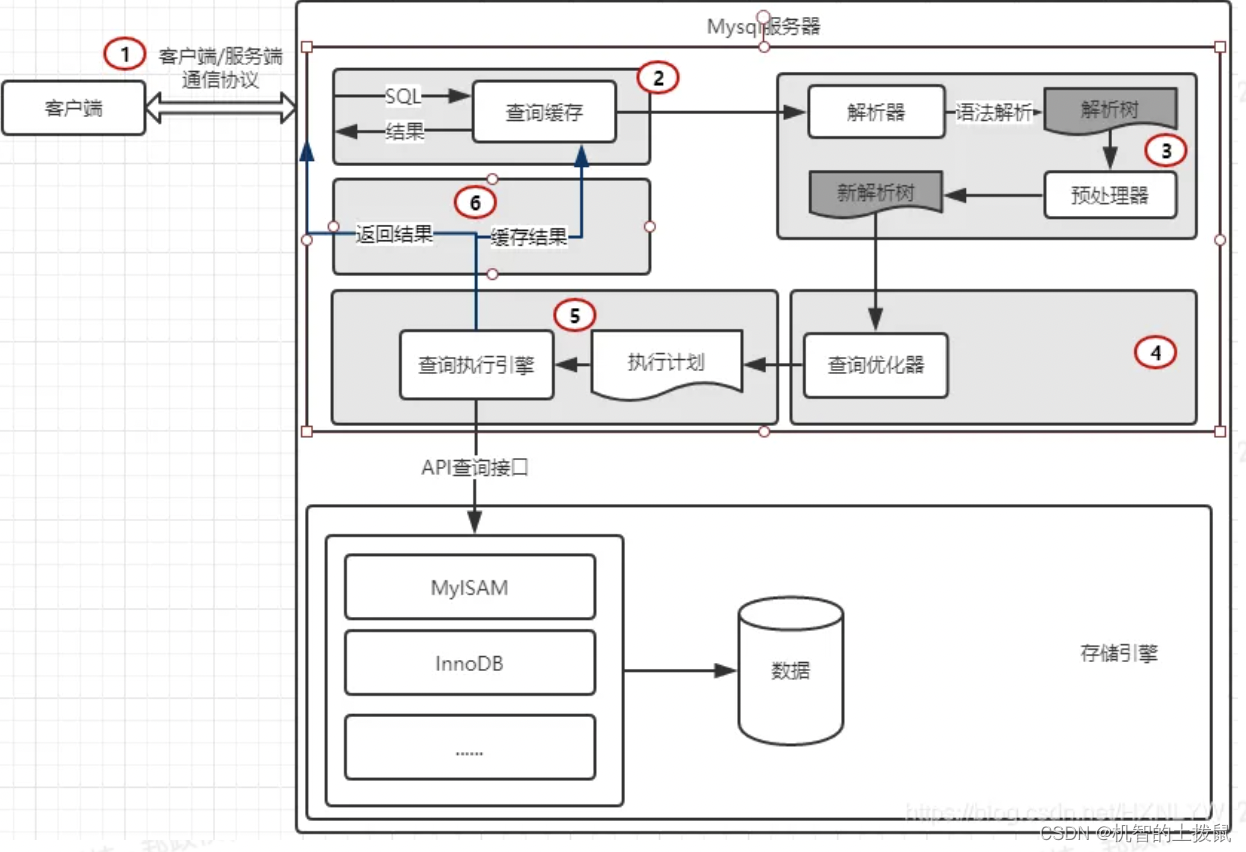
在执行过程中,主要有三类角色:客户端、服务器、存储引擎。
大致可以分为三层:
第一层:客户端连接到服务器,构造SQL并发送给服务器。
第二层:服务器收到SQL进行解析及优化,最终生成执行计划并执行
第三层:服务器调用存储引擎的API,进行数据的查询和存储。
上述的查询缓存,在MySQL8.0版本后移出,原因是不太实用,对表进行修改操作后,需要进行删除缓存并重新添加,对于一些写并不频繁的表还好,但市面上还有一些更加实用做缓存的工具,因此这个功能比较尴尬。
二、执行计划分析
可以通过explain提前知道当前MySQL是如何处理SQL语句的。
在我们要执行的SQL前加上explain即可。
sql
explain select * from user;
explain insert into user values(user_name, password, email) values('1', '1', '1');
通过分析执行计划,我们可以得出以下几点:
1.表的读取顺序 -> id
2.表读取操作的类型 -> select_type
3.可以被使用的索引 -> possible_keys
4.实际使用的索引 -> key
5.表之间的引用 -> ref
6.每张表有多少行被优化器查询 -> rows
上述查询结果字段的含义:
1.id:表示查询中执行select子句或操作表的顺序,id越大,执行优先级越高,id相同,则从上至下
2.select_type:表示查询的类型,用来区分普通查询、联合查询、子查询等。一共有9种类型。
3.table: 输出行所引用的表名,如果使用了别名则显示别名
4.partitions ***:***使用的哪个分区
5.type:查询使用了那种类型。描述的是当前如何去找数据的,如:all 表示扫描全表。
6.possible_keys:可能有助于查询的索引
7.key:实际使用的索引
8.key_len: 使用的索引的长度
9.ref:显示索引的哪一列被使用了
10.rows:请求数据大概返回的行数
11.f*iltered:*表示存储引擎返回的数据在server层过滤后,剩下多少满足查询的记录数量的比例
12.extra: 其他信息,出现Using filesort、Using temporary 意味着不能使用索引,效率会受到重大影响。应尽可能对此进行优化。
其中比较重要的字段:
1.type:可以看出是如何查询数据的方式。一般需要达到 ref、eq_ref 级别,范围查找需要达到 range。
2.key:是否使用索引,如果为NULL表示没有使用索引,需要优化调整。
3.rows:表示返回的行数,可以直观观察到结果。
4.extra:有Using filesort、Using temporary 的一定需要优化。
三、表结构优化
**数据库效率的影响主要是因为数据量太大,进行一次查找需要扫描很多数据(**硬盘上的磁头需要越过很多数据来找到目标数据),通过表结构优化的方式可以减轻当前访问的数据量。
3.1 数据类型优化
主旨就是能用小字段类型就不用大字段类型~
- 使用简单的数据类型。int 要比 varchar 类型在mysql处理简单
- 尽量使用 tinyint、smallint、mediumint 作为整数类型而非 int
- 尽可能使用 not null 定义字段,因为 null 占用4字节空间。数字可以默认0,字符串默认""
- 尽量少用 text 类型,非用不可时最好考虑分表
- 尽量使用 timestamp而非 datetime
- 单表不要有太多字段,建议在 20 以内
3.2 分库分表优化
当数据太多的时候,即使走索引啥的也不能解决效率问题,根本就在于要扫描的数据太多了,并且存储也是比较难的。
这时候就可以采用分表的方式,将一张表拆分成多张,然后通过编号等手段进行查询。
拆分大致也有两种方式:
垂直拆分:
按照列的维度,将表中的列拆分开来,分别放在多张表中。例如:某些字段在一张表中可能更加平凡的查询,可以将这些字段放到一张表中,不常用的放在另一张表中。
但需要注意的是,这种方式需要保证原子性!可以在进行插入的时候使用事务~
水平拆分:
按照行的维度,将一张表的数据切分。如0-100的数据放在这张表中,101-200的数据放在另一张表中。
3.3 读写分离优化
由于一台数据库服务器的性能肯定是有瓶颈的,可以进行部署一个数据库集群。并采用主从的方式。设置一些主库,一些从库,主库用来负责写入数据,从库用来负责读取数据,当一个新的数据写入的时候,主库需要将数据同步到从库中,以保证数据的完整性。
四、查询语句优化
4.1避免使用 select *
sql在解析过程中,还需要把*依次转换为所有的列名,这个工作需要查询数据字典完成。额外开销!因此建议将需要的列写出来。
4.2多表联查时,小表在前,大表在后
from 后的表关联查询是从左往右执行的(Oracle相反),第一张表会涉及到全表扫描,所以将小表放在前面,先扫小表,扫描快效率较高,在扫描后面的大表。
4.3调整where子句中的连接顺序
where子句是从左往右,自上而下的顺序执行的(Oracle相反),根据这个原理,应将过滤数据多的条件往前放,最快速度缩小结果集。
4.4调整group by和order by子句中的顺序
group by和order by子句是从左往右的顺序执行的,根据这个原理,应将排序影响数据多的条件往前放,最快速度缩小结果集。
4.5用exists、not exists和in、not in相互替代
exists以外层表为驱动表,先被访问,适合于外表小而内表大的情况。
in则是先执行子查询,适合外表大而内表小的情况,一般情况是不推荐使用not in,因为效率非常低。
原则是哪个的子查询产生的结果集小,就选哪个
4.6用where子句替换having子句
where子句搜索条件在进行分组操作之前应用;而having子句条件在进行分组操作之后应用。
尽可能让where来缩小结果集!
4.7分段和分页查询
使用合理的分页方式,在数据表量级逐渐增加的时候,limit分页查询的效率会降低。
可以根据字段索引进行快速定位,直接找到偏移量。
五、索引优化
众所周知,索引是通过牺牲空间来换取时间的。当我们频繁的去进行插入/删除的时候,会影响性能,因此索引更适合于"读多写少"的场景。
索引可以帮助我们提高查询效率,因此需要避免索引失效的场景。
5.1尽量避免在字段开头模糊查询
sql
select * from user where user_name like '%陈%'; -不走索引
select * from user where user_name like '陈%'; -走索引5.2尽量避免使用not in和in
如果是连续数值,可以用between代替
sql
select * from user id in(1,2); -不走索引
select * from user id between 1 and 2; -走索引如果是子查询,可以用exists代替
sql
select * from A where A.id in (select id from B); -- 不走索引
select * from A where exists (select * from B where B.id = A.id); -- 走索引5.3尽量避免使用or或in
sql
SELECT * FROM t WHERE id = 1 OR id = 3; -- 不走索引
SELECT * FROM t WHERE id in (1, 3); -- 不走索引
SELECT * FROM t WHERE id = 1
UNION
SELECT * FROM t WHERE id = 3; -- 走索引5.4尽量避免查询条件使用用!=或者<>
5.5尽量避免进行null值的判断
优化方式:可以给字段添加默认值,0,对0值进行判断.
sql
SELECT * FROM t WHERE score IS NULL; -- 不走索引
SELECT * FROM t WHERE score = 0; -- 走索引5.6尽量避免在where条件中等号的左侧进行表达式、函数操作
sql
SELECT * FROM T WHERE score/10 = 9; -- 不走索引
SELECT * FROM T WHERE score = 9*10; -- 走索引5.7尽量避免隐式数据类型转换
有些字符串可以自动转换为数字类型,可以避免转换
5.8尽量避免使用复合索引时,不使用第一个索引列
复合(联合)索引包含key1,key2,key3三列,SQL语句没有包含索引前置列"key1"
sql
select col1 from table where key2=2 and key3=3; -- 不走索引
select col1 from table where key1=1 and key2=2 and key3=3; -- 走索引5.9order by 条件要与where中条件一致,否则order by不会利用索引进行排序
sql
SELECT * FROM t order by age; -- 不走age索引
SELECT * FROM t where age > 0 order by age; -- 走age索引当order by 中的字段出现在where条件中时,才会利用索引而不再二次排序,更准确的说,order by 中的字段在执行计划中利用了索引时,不用排序操作。