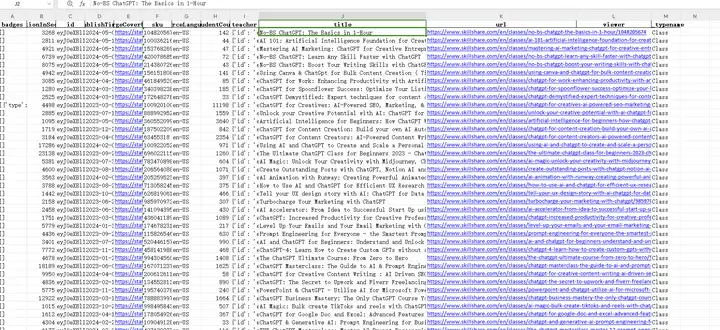
任务:爬取网站www.skillshare.com搜索结果页面数据:
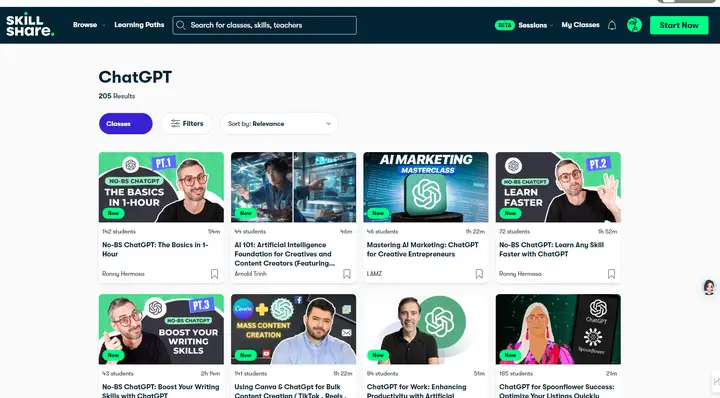
查看网站的请求信息:
请求网址:
https://www.skillshare.com/api/graphql
请求方法:
POST
状态代码:
200 OK
远程地址:
127.0.0.1:10809
引荐来源网址政策:
strict-origin-when-cross-origin
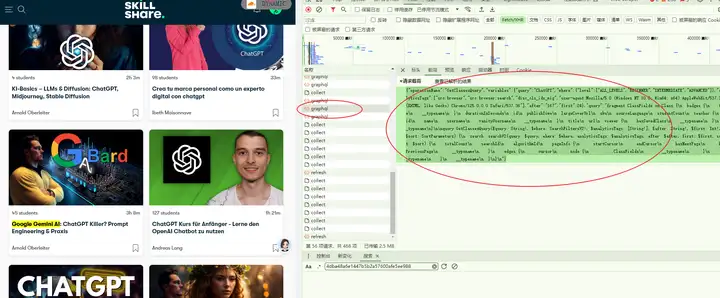
请求载荷:
{"operationName":"GetClassesQuery","variables":{"query":"ChatGPT","where":{"level":"ALL_LEVELS","BEGINNER","INTERMEDIATE","ADVANCED"},"analyticsTags":"src:browser","src:browser:search","disc_cls_idx_mig","user-agent:Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36","after":"191","first":24},"query":"fragment ClassFields on Class {\n badges {\n type\n __typename\n }\n durationInSeconds\n id\n publishTime\n largeCoverUrl\n sku\n sourceLanguage\n studentCount\n teacher {\n id\n name\n username\n vanityUsername\n __typename\n }\n title\n url\n viewer {\n hasSavedClass\n __typename\n }\n __typename\n}\n\nquery GetClassesQuery(query: String!, where: SearchFiltersV2!, analyticsTags: \[String!\], after: String!, first: Int!, sort: SortParameters) {\n search: searchV2(query: query, where: where, analyticsTags: analyticsTags, after: after, first: first, sort: sort) {\n totalCount\n searchId\n algorithmId\n pageInfo {\n startCursor\n endCursor\n hasNextPage\n hasPreviousPage\n __typename\n }\n edges {\n cursor\n node {\n ...ClassFields\n __typename\n }\n __typename\n }\n __typename\n }\n}\n"}
{"operationName":"GetClassesQuery","variables":{"query":"ChatGPT","where":{"level":"ALL_LEVELS","BEGINNER","INTERMEDIATE","ADVANCED"},"analyticsTags":"src:browser","src:browser:search","disc_cls_idx_mig","user-agent:Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36","after":"167","first":24},"query":"fragment ClassFields on Class {\n badges {\n type\n __typename\n }\n durationInSeconds\n id\n publishTime\n largeCoverUrl\n sku\n sourceLanguage\n studentCount\n teacher {\n id\n name\n username\n vanityUsername\n __typename\n }\n title\n url\n viewer {\n hasSavedClass\n __typename\n }\n __typename\n}\n\nquery GetClassesQuery(query: String!, where: SearchFiltersV2!, analyticsTags: \[String!\], after: String!, first: Int!, sort: SortParameters) {\n search: searchV2(query: query, where: where, analyticsTags: analyticsTags, after: after, first: first, sort: sort) {\n totalCount\n searchId\n algorithmId\n pageInfo {\n startCursor\n endCursor\n hasNextPage\n hasPreviousPage\n __typename\n }\n edges {\n cursor\n node {\n ...ClassFields\n __typename\n }\n __typename\n }\n __typename\n }\n}\n"}
这段请求载荷是一个GraphQL查询,用于获取与搜索查询 "ChatGPT" 相关的不同方面的数据(facets)。下面是对这段查询的详细解释:
-
`operationName`: "GetFacets",这指定了操作的名称,用于标识这个特定的查询操作。
-
`variables`: 这是一个对象,包含了查询所需的变量:
-
`analyticsTags`: 一个包含多个字符串的数组,用于分析目的。
-
`query`: 搜索查询的关键字,这里是 "ChatGPT"。
-
`where_type`, `where_language`, `where_level`, `where_length`, `where_with`, `where_publish`, `where_rating`: 这些字段包含了搜索过滤条件,每个字段都设置为相同的值,即包含所有级别("ALL_LEVELS", "BEGINNER", "INTERMEDIATE", "ADVANCED")的数组。这些过滤条件用于指定搜索的不同维度。
-
`query`: 这是GraphQL查询的主体,它定义了要获取的数据:
-
`fragment FacetsData on SearchResultItemConnectionV2`: 这是一个片段,定义了搜索结果项连接的类型,包括总数量(totalCount)和方面(facets)。
-
`totalCount`: 搜索结果的总数。
-
`facets`: 一个包含不同方面选项的对象数组,每个选项都有计数(count)和名称(name)。
-
接下来的部分定义了多个 `searchV2` 查询,每个查询都针对不同的搜索维度(type, language, level, length, with, publish, rating),并使用上面定义的片段 `FacetsData` 来获取每个维度的总数量和方面数据。
这个查询的主要目的是为搜索 "ChatGPT" 提供一个多维度的概览,包括不同类别(如类型、语言、难度级别等)的统计信息和选项。通过这种方式,用户可以了解每个维度下的课程分布情况,从而帮助他们进行更精确的搜索和选择。
找了两段不同的请求载荷,主要区别在于`variables`对象中的`after`字段的值不同。
两个请求载荷的共同点:
-
`operationName`:两个请求都使用了相同的操作名称 `"GetClassesQuery"`。
-
`variables`中的其他字段:`query`、`where`、`analyticsTags`、`first` 在两个请求中都是相同的。
-
`query`:两个请求中的GraphQL查询字符串是相同的。
以下是两个请求载荷的不同点:
-
`variables`中的`after`字段:
-
第一个请求的`after`字段值是 `"191"`。
-
第二个请求的`after`字段值是 `"167"`。
`after`字段通常用于分页,它指定了从哪个点开始获取数据。在这个GraphQL查询中,它决定了从搜索结果的哪一条记录开始返回数据。因此,第一个请求将从记录191开始获取数据,而第二个请求将从记录167开始获取数据。
这意味着两个请求将返回不同的数据集,即使它们都是基于相同的查询和过滤条件。第一个请求可能是为了获取第一页或后续某页的数据,而第二个请求可能是为了获取另一页的数据。其他字段如`first`指定了每页返回的记录数,在这种情况下,都是24条记录。
再继续查看其他请求载荷的after字段:-1、47、 71、95
搜索结果是205 个,显然`after`字段值是从-1开始,每次递增24,以215结束
在chatgpt中输入提示词:
你是一个Python专家,要完成一个编写爬虫的Python脚本,具体步骤:
请求网址:
https://www.skillshare.com/api/graphql
请求方法:
POST
状态代码:
200 OK
远程地址:
127.0.0.1:10809
引荐来源网址政策:
strict-origin-when-cross-origin
请求标头:
Accept:
*/*
Accept-Encoding:
gzip, deflate, br, zstd
Accept-Language:
zh-CN,zh;q=0.9,en;q=0.8
Content-Length:
1302
Content-Type:
application/json
Origin:
Priority:
u=1, i
Referer:
https://www.skillshare.com/en/search/classes?query=ChatGPT
Sec-Ch-Ua:
"Google Chrome";v="125", "Chromium";v="125", "Not.A/Brand";v="24"
Sec-Ch-Ua-Mobile:
?0
Sec-Ch-Ua-Platform:
"Windows"
Sec-Fetch-Dest:
empty
Sec-Fetch-Mode:
cors
Sec-Fetch-Site:
same-origin
User-Agent:
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36
请求载荷:
{"operationName":"GetClassesQuery","variables":{"query":"ChatGPT","where":{"level":"ALL_LEVELS","BEGINNER","INTERMEDIATE","ADVANCED"},"analyticsTags":"src:browser","src:browser:search","disc_cls_idx_mig","user-agent:Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36","after":"{pagenumber}","first":24},"query":"fragment ClassFields on Class {\n badges {\n type\n __typename\n }\n durationInSeconds\n id\n publishTime\n largeCoverUrl\n sku\n sourceLanguage\n studentCount\n teacher {\n id\n name\n username\n vanityUsername\n __typename\n }\n title\n url\n viewer {\n hasSavedClass\n __typename\n }\n __typename\n}\n\nquery GetClassesQuery(query: String!, where: SearchFiltersV2!, analyticsTags: \[String!\], after: String!, first: Int!, sort: SortParameters) {\n search: searchV2(query: query, where: where, analyticsTags: analyticsTags, after: after, first: first, sort: sort) {\n totalCount\n searchId\n algorithmId\n pageInfo {\n startCursor\n endCursor\n hasNextPage\n hasPreviousPage\n __typename\n }\n edges {\n cursor\n node {\n ...ClassFields\n __typename\n }\n __typename\n }\n __typename\n }\n}\n"}
其中,"after"键对应的字段值"{pagenumber}"是从-1开始,每次递增24,以215结束。
获取网页响应的json数据,打印出来;
提取"data"键中嵌套的"search"键嵌套的"edges"键的内容;
"edges"键对应的值是一个json数据;
将这个json数据所有的键名作为Excel表格的表头,键对应的值作为Excel表格的列数据,全部写入Excel表格中;
保存Excel表格到文件夹"F:\AI自媒体内容\AI行业数据分析",文件名为:skillshareChatgptcourse20240604.xlsx
注意:每一步信息都要输出到屏幕上
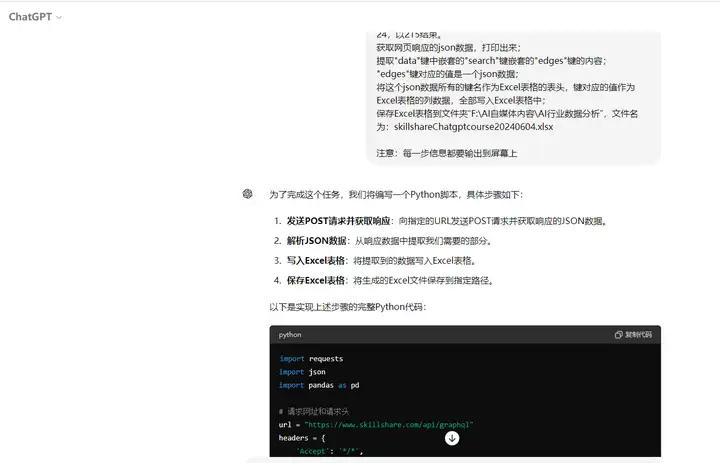
ChatGPT生成的Python源代码:
import requests
import json
import pandas as pd
请求网址和请求头
url = "https://www.skillshare.com/api/graphql"
headers = {
'Accept': '*/*',
'Accept-Encoding': 'gzip, deflate, br, zstd',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
'Content-Length': '1302',
'Content-Type': 'application/json',
'Origin': 'https://www.skillshare.com',
'Priority': 'u=1, i',
'Referer': 'https://www.skillshare.com/en/search/classes?query=ChatGPT',
'Sec-Ch-Ua': '"Google Chrome";v="125", "Chromium";v="125", "Not.A/Brand";v="24"',
'Sec-Ch-Ua-Mobile': '?0',
'Sec-Ch-Ua-Platform': '"Windows"',
'Sec-Fetch-Dest': 'empty',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Site': 'same-origin',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36'
}
定义请求载荷的模板
payload_template = {
"operationName": "GetClassesQuery",
"variables": {
"query": "ChatGPT",
"where": {
"level": "ALL_LEVELS", "BEGINNER", "INTERMEDIATE", "ADVANCED"
},
"analyticsTags": [
"src:browser",
"src:browser:search",
"disc_cls_idx_mig",
"user-agent:Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36"
],
"after": "",
"first": 24
},
"query": """
fragment ClassFields on Class {
badges {
type
__typename
}
durationInSeconds
id
publishTime
largeCoverUrl
sku
sourceLanguage
studentCount
teacher {
id
name
username
vanityUsername
__typename
}
title
url
viewer {
hasSavedClass
__typename
}
__typename
}
query GetClassesQuery(query: String!, where: SearchFiltersV2!, analyticsTags: \[String!\], after: String!, first: Int!, sort: SortParameters) {
search: searchV2(query: query, where: where, analyticsTags: analyticsTags, after: after, first: first, sort: sort) {
totalCount
searchId
algorithmId
pageInfo {
startCursor
endCursor
hasNextPage
hasPreviousPage
__typename
}
edges {
cursor
node {
...ClassFields
__typename
}
__typename
}
__typename
}
}
"""
}
初始化数据列表
all_data = \[\]
循环请求每一页的数据
for i in range(-1, 216, 24):
payload = payload_template.copy()
payload'variables''after' = str(i)
response = requests.post(url, headers=headers, json=payload)
if response.status_code == 200:
print(f"Page {i//24 + 1} data fetched successfully.")
data = response.json()
print(json.dumps(data, indent=2)) # 打印响应的JSON数据
提取我们需要的部分
edges = data.get('data', {}).get('search', {}).get('edges', \[\])
all_data.extend(edge\['node' for edge in edges])
else:
print(f"Failed to fetch page {i//24 + 1}. Status code: {response.status_code}")
break
将数据转换为DataFrame
df = pd.DataFrame(all_data)
print(df.head()) # 打印表格的前几行
保存DataFrame到Excel
output_path = "F:/AI自媒体内容/AI行业数据分析/skillshareChatgptcourse20240604.xlsx"
df.to_excel(output_path, index=False)
print(f"Data saved to {output_path}")
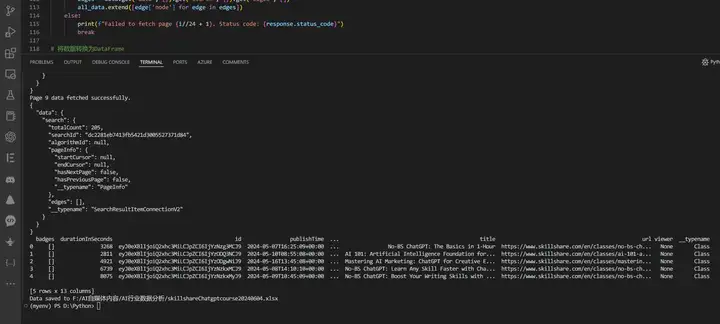
Vscode中运行程序,获取所有查询结果数据: