🌈个人主页: 鑫宝Code
🔥热门专栏: 闲话杂谈| 炫酷HTML | JavaScript基础
**💫个人格言: "如无必要,勿增实体"**

文章目录
- [GBDT (Gradient Boosting Decision Tree) 深入解析](#GBDT (Gradient Boosting Decision Tree) 深入解析)
-
- 引言
- 一、GBDT基础理论
-
- [1.1 梯度提升算法简介](#1.1 梯度提升算法简介)
- [1.2 决策树基础](#1.2 决策树基础)
- 二、GBDT算法流程
-
- [2.1 初始化与迭代](#2.1 初始化与迭代)
- [2.2 损失函数与梯度](#2.2 损失函数与梯度)
- 三、关键参数与调优
-
- [3.1 参数解释](#3.1 参数解释)
- [3.2 调优策略](#3.2 调优策略)
- 四、GBDT的应用与挑战
-
- [4.1 应用场景](#4.1 应用场景)
- [4.2 面临的挑战](#4.2 面临的挑战)
- 五、优化与进阶技术
-
- [5.1 LightGBM与XGBoost](#5.1 LightGBM与XGBoost)
- [5.2 特征重要性](#5.2 特征重要性)
- [5.3 高维稀疏数据处理](#5.3 高维稀疏数据处理)
- 结语
GBDT (Gradient Boosting Decision Tree) 深入解析
引言
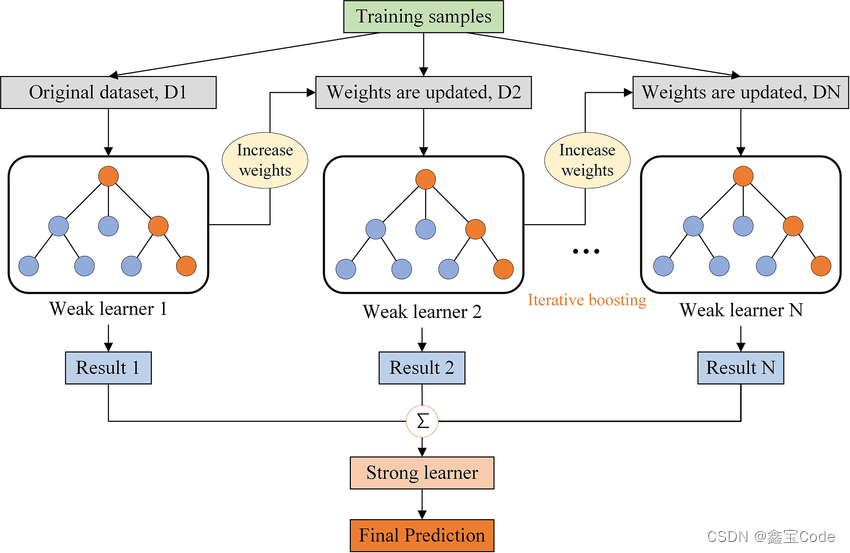
GBDT,全称为Gradient Boosting Decision Tree,即梯度提升决策树,是机器学习领域中一种高效且强大的集成学习方法。它通过迭代地添加决策树以逐步降低预测误差,从而在各种任务中,尤其是回归和分类问题上表现出色。本文将深入浅出地介绍GBDT的基本原理、算法流程、关键参数调整策略以及其在实际应用中的表现与优化技巧。
一、GBDT基础理论
1.1 梯度提升算法简介
梯度提升是一种迭代的机器学习算法,其核心思想是利用前一个模型的残差(即真实值与预测值之差)作为当前模型的学习目标,通过不断添加弱学习器(通常是决策树),逐步降低训练数据的损失函数值,直至达到预设的停止条件。
1.2 决策树基础
决策树是GBDT中最常用的弱学习器。它通过一系列if-then规则对数据进行分割,每个内部节点表示一个特征上的测试,每个分支代表一个测试结果,而叶节点则存储一个预测值。决策树的构建过程包括特征选择、节点分裂等步骤,旨在最大化信息增益或基尼不纯度等分裂标准。
二、GBDT算法流程
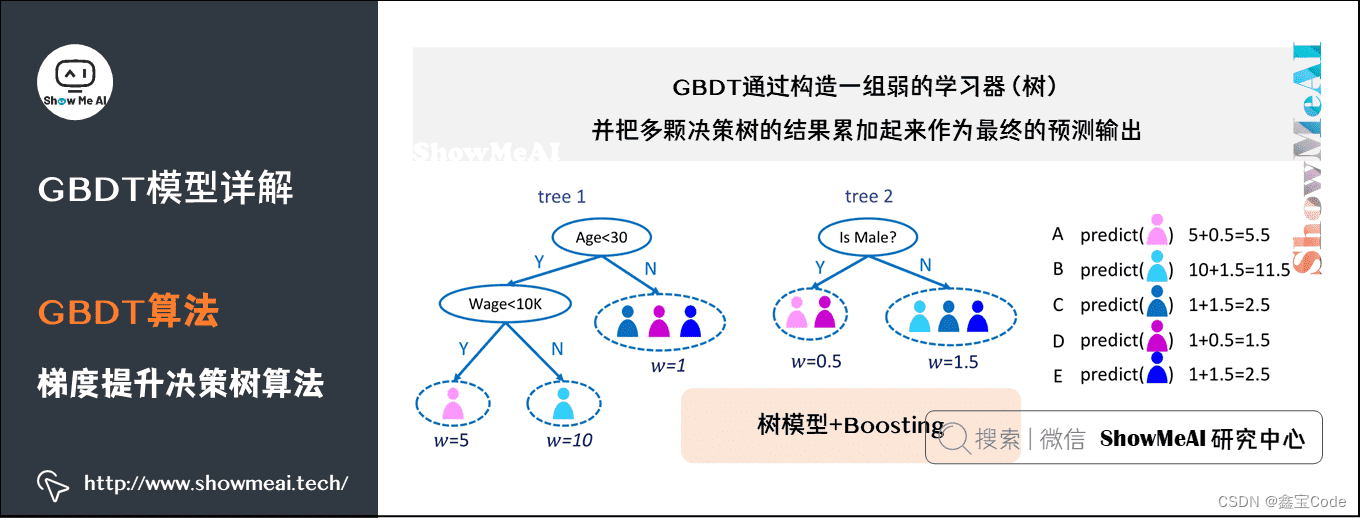
2.1 初始化与迭代
- 初始化:首先,GBDT会用一个简单的模型(如常数模型)对所有样本做出初始预测。
- 迭代过程 :
- 计算残差:基于当前模型的预测结果,计算每个样本的真实标签与预测值之间的梯度(对于回归问题通常是真实值减去预测值;对于分类问题,则使用损失函数的负梯度)。
- 拟合决策树:将这些残差作为新的目标变量,训练一个决策树来拟合这些残差。决策树的深度和节点数决定了模型的复杂度。
- 更新预测:将新训练的决策树加入到模型中,更新每个样本的预测值为原预测值加上新决策树的输出。
- 重复上述过程,直到达到预设的迭代次数或满足停止条件。
2.2 损失函数与梯度
GBDT的核心在于如何有效地利用梯度信息指导决策树的生成。不同的任务(如平方损失对应回归,对数损失对应二分类)会有不同的损失函数,其梯度直接指导了模型如何针对当前错误进行修正。
下面是一个使用Python语言及sklearn库实现的简单GBDT(Gradient Boosting Decision Tree)示例代码。这个例子展示的是如何使用GBDT进行一个基本的回归任务。
首先,请确保你的环境中安装了scikit-learn库。如果未安装,可以通过pip命令安装:
bash
pip install scikit-learn然后,你可以使用以下代码来训练一个GBDT模型:
python
# 导入必要的库
from sklearn.datasets import load_boston
from sklearn.model_selection import train_test_split
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.metrics import mean_squared_error
# 加载波士顿房价数据集
boston = load_boston()
X, y = boston.data, boston.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 初始化GBDT回归器
gbdt_reg = GradientBoostingRegressor(n_estimators=100, learning_rate=0.1, max_depth=3, random_state=42)
# 训练模型
gbdt_reg.fit(X_train, y_train)
# 预测
y_pred = gbdt_reg.predict(X_test)
# 计算并打印均方误差
mse = mean_squared_error(y_test, y_pred)
print(f"Mean Squared Error: {mse:.2f}")这段代码做了以下几件事:
- 导入波士顿房价数据集,这是一个常用的回归问题数据集。
- 将数据集划分为训练集和测试集。
- 初始化一个GBDT回归器,设置了迭代次数(
n_estimators)、学习率(learning_rate)、决策树最大深度(max_depth)等参数。 - 在训练集上训练模型。
- 对测试集进行预测。
- 计算并输出预测结果的均方误差(Mean Squared Error, MSE),作为评估模型性能的一个指标。
请注意,实际应用中可能需要根据具体任务和数据特性调整模型参数以达到最佳性能。
三、关键参数与调优
3.1 参数解释
- n_estimators:迭代次数,即最终模型中弱学习器的数量。
- learning_rate(学习率):每次迭代时,新决策树对预测结果的贡献权重。
- max_depth:决策树的最大深度,控制着树的复杂度。
- min_samples_split:节点分裂所需的最小样本数。
- subsample:用于训练每棵树的样本采样比例,小于1时可实现随机梯度提升。
3.2 调优策略
- 学习率与迭代次数的平衡:较低的学习率通常需要更多的迭代次数来达到较好的性能,但能减少过拟合的风险。
- 树的深度与样本采样:合理限制树的深度和采用子采样可以提高模型的泛化能力。
- 早停机制:在验证集上监控性能,一旦性能不再显著提升,则提前终止训练。
四、GBDT的应用与挑战
4.1 应用场景
GBDT因其优秀的性能,在多个领域得到广泛应用,包括但不限于:
- 推荐系统:用户行为预测、点击率预测。
- 金融风控:信用评分、欺诈检测。
- 广告投放:CTR预估、广告排序。
- 自然语言处理:文本分类、情感分析。
4.2 面临的挑战
- 计算成本:随着迭代次数增加,训练时间与资源消耗显著增长。
- 过拟合风险:特别是在数据量有限时,容易过拟合。
- 解释性:虽然单个决策树易于解释,但集成后的模型解释性较差。
五、优化与进阶技术
5.1 LightGBM与XGBoost

为了解决GBDT的效率问题,LightGBM和XGBoost等先进框架被提出,它们通过优化算法结构(如直方图近似)、并行计算等方式显著提高了训练速度。

5.2 特征重要性
GBDT能够自然地评估特征的重要性,这对于特征选择和理解模型有重要价值。
5.3 高维稀疏数据处理
在处理高维稀疏数据(如文本分类)时,引入正则化、剪枝策略以及稀疏矩阵运算技术可以有效提升模型的效率和效果。
结语
GBDT以其卓越的性能和广泛的适用性,在机器学习领域占据了一席之地。通过深入理解其基本原理、熟练掌握调参技巧,并结合现代优化技术,开发者可以更高效地利用GBDT解决各类复杂问题。随着算法研究的不断深入,GBDT及其衍生技术将持续在人工智能领域发挥重要作用。