文章目录
-
[1. 查看数据文件](#1. 查看数据文件)
-
[2. 读取数据文件得到单例数据帧](#2. 读取数据文件得到单例数据帧)
-
[3. 将单列数据帧转换成多列数据帧](#3. 将单列数据帧转换成多列数据帧)
-
在本次实战中,我们的目标是将存储在HDFS上的以逗号分隔的文本文件
student.txt转换为结构化的Spark DataFrame。首先,使用spark.read.text读取文件,得到一个包含单列value的DataFrame。然后,利用split函数按逗号分割每行字符串,并通过withColumn和类型转换cast创建新的列id、name、gender和age。最后,使用drop函数移除原始的value列,并使用show和printSchema验证转换结果。通过这一系列操作,我们成功地将原始文本数据转换为具有明确数据类型和列名的结构化数据集,为后续的数据分析和处理打下了基础。
1. 查看数据文件
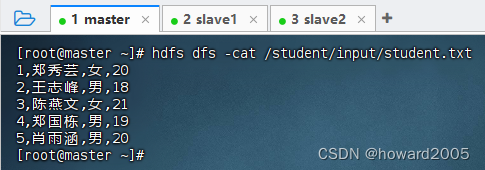
- 执行命令:
hdfs dfs -cat /student/input/student.txt
2. 读取数据文件得到单例数据帧
- 执行命令:
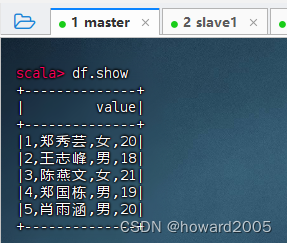
val df = spark.read.text("hdfs://master:9000/student/input/student.txt")

- 执行命令:
df.show
3. 将单列数据帧转换成多列数据帧
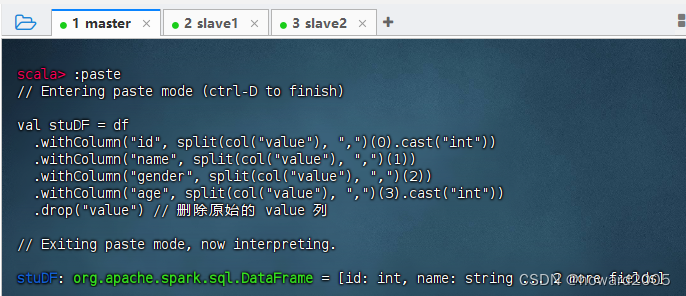
scala
val stuDF = df
.withColumn("id", split(col("value"), ",")(0).cast("int"))
.withColumn("name", split(col("value"), ",")(1))
.withColumn("gender", split(col("value"), ",")(2))
.withColumn("age", split(col("value"), ",")(3).cast("int"))
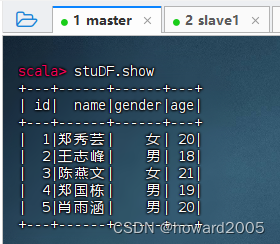
.drop("value") // 删除原始的 value 列- 执行上述命令
- 执行命令:
stuDF.printSchema
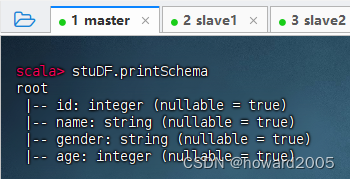
- 执行命令:
stuDF.show