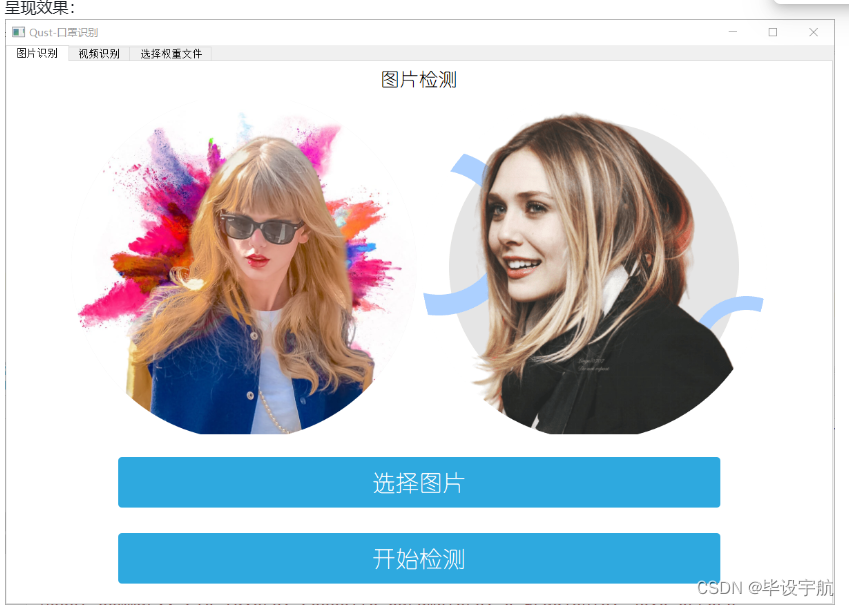
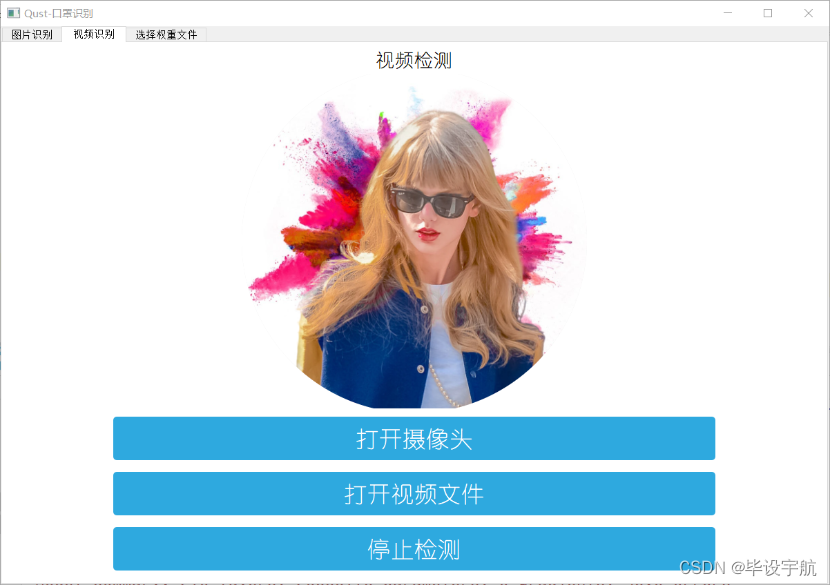
基于YOLOv5模型的口罩识别系统,结合了GUI界面,旨在帮助用户快速、准确地识别图像或视频中佩戴口罩的情况。YOLOv5是一种流行的目标检测模型,具有高效的实时检测能力,而GUI界面则提供了友好的用户交互界面,使得整个系统更易于操作和使用。
通过该系统,用户可以上传图像或者选择视频进行口罩识别,系统会使用YOLOv5模型自动检测图中人脸并判断是否佩戴口罩。识别结果将会在界面上直观显示,同时还可以导出识别结果或者保存分析报告。这样的系统可以被广泛应用于监控系统、安全检查等领域,提高工作效率和准确性。

使用方式
-
安装依赖
pip install -r requirements.txt
-
运行 PyqtGUI.py 文件
python PyqtGUI.py
备注:best1、2、3.pt为模型文件,如有需要自行替换。
目标检测:
目标检测是计算机视觉和数字图像处理的一个热门方向,广泛应用于无人驾驶、智能视频监控、工业检测、航空航天等诸多领域,通过计算机视觉减少对人力资本的消耗,具有重要的现实意义。 因此,目标检测也就成为了近年来理论和应用的研究热点,它是图像处理和计算机视觉学科的重要分支,也是智能监控系统的核心部分,同时目标检测也是泛身份识别领域的一个基础性的算法,对后续的人脸识别、步态识别、人群计数、实例分割等任务起着至关重要的作用。
YOLOv5简介:
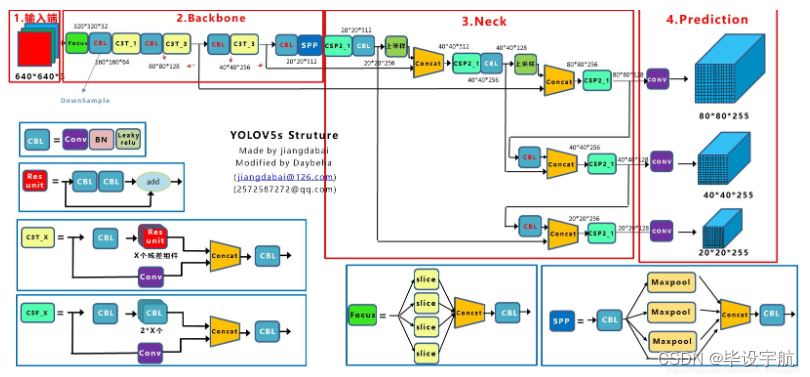
YOLOV4出现之后不久,YOLOv5横空出世。YOLOv5在YOLOv4算法的基础上做了进一步的改进,检测性能得到进一步的提升。YOLOv5在COCO数据集上面的测试效果非常不错。工业界也往往更喜欢使用这些方法,而不是利用一个超级复杂的算法来获得较高的检测精度。 YOLOv5是一种单阶段目标检测算法,速度与精度都得到了极大的性能提升。主要的改进思路如下所示:
- 输入端:在模型训练阶段,提出了一些改进思路,主要包括Mosaic数据增强、自适应锚框计算、自适应图片缩放。
- 基准网络:融合其它检测算法中的一些新思路,主要包括:Focus结构与CSP结构。
- Neck网络:目标检测网络在BackBone与最后的Head输出层之间往往会插入一些层,Yolov5中添加了FPN+PAN结构。
- Head输出层:输出层的锚框机制与YOLOv4相同,主要改进的是训练时的损失函数GIOU_Loss,以及预测框筛选的DIOU_nms。
YOLOv5S模型的网络架构:
YOLOV5目录结构:
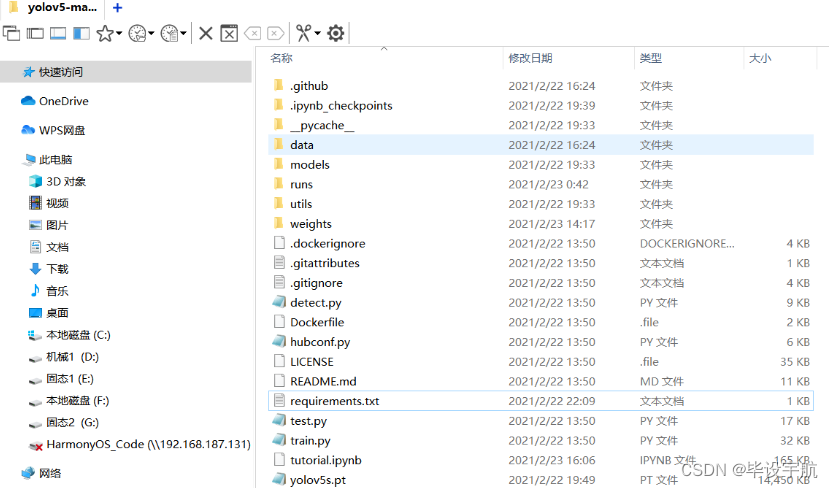
其中,train.py这个文件也是我们接下来训练yolo模型需要用到的启动文件。 requirement.txt 中有我们所需要的的全部依赖,采用pip安装。
pip install -r requirements.txt #安装完依赖后准备工作完成每个文件作用:
YOLOv5
| detect.py #检测脚本
| hubconf.py # PyTorch Hub相关代码
| LICENSE # 版权文件
| README.md #README markdown 文件
| requirements.txt #项目所需的安装包列表
| sotabench.py #COCO 数据集测试脚本
| test.py #模型测试脚本
| train.py #模型训练脚本
| tutorial.ipynb #Jupyter Notebook演示代码
|-- data
| | coco.yaml #COCO 数据集配置文件
| | coco128.yaml #COCO128 数据集配置文件
| | hyp.finetune.yaml #超参数微调配置文件
| | hyp.scratch.yaml #超参数启始配置文件
| | voc.yaml #VOC数据集配置文件
| |---scripts
| get_coco.sh # 下载COCO数据集shell命令
| get_voc.sh # 下载VOC数据集shell命令
|-- inference
| | images #示例图片文件夹
| bus.jpg
| zidane.jpg
|-- models
| | common.py #模型组件定义代码
| | experimental.py #实验性质的代码
| | export.py #模型导出脚本
| | yolo.py # Detect 及 Model构建代码
| | yolo5l.yaml # yolov5l 网络模型配置文件
| | yolo5m.yaml # yolov5m 网络模型配置文件
| | yolo5s.yaml # yolov5s 网络模型配置文件
| | yolo5x.yaml # yolov5x 网络模型配置文件
| | __init__.py
| |---hub
| yolov3-spp.yaml
| yolov3-fpn.yaml
| yolov3-panet.yaml
|-- runs #训练结果
| |--exp0
| | | events.out.tfevents.
| | | hyp.yaml
| | | labels.png
| | | opt.yaml
| | | precision-recall_curve.png
| | | results.png
| | | results.txt
| | | test_batch0_gt.jpg
| | | test_batch0_pred.jpg
| | | test_batch0.jpg
| | | test_batch1.jpg
| | | test_batch2.jpg
| | |--weights
| | best.pt #所有训练轮次中最好权重
| | last.pt #最近一轮次训练权重
|-- utils
| | activations.py #激活函数定义代码
| | datasets.py #Dataset 及Dataloader定义代码
| | evolve.py #超参数进化命令
| | general.py #项目通用函数代码
| | google_utils.py # 谷歌云使用相关代码
| | torch_utils.py # torch工具辅助类代码
| | __init__.py # torch工具辅助类代码
| |---google_app_engine
| additional_requirements.txt
| app.yaml
| Dockerfile
|-- VOC #数据集目录
| |--images #数据集图片目录
| | |--train # 训练集图片文件夹
| | | 000005.jpg
| | | 000007.jpg
| | | 000009.jpg
| | | 0000012.jpg
| | | 0000016.jpg
| | | ...
| | |--val # 验证集图片文件夹
| | | 000001.jpg
| | | 000002.jpg
| | | 000003.jpg
| | | 000004.jpg
| | | 000006.jpg
| | | ...
| |--labels #数据集标签目录
| | train.cache
| | val.cache
| | |--train # 训练标签文件夹
| | | 000005.txt
| | | 000007.txt
| | | ...
| | |--val # 验证集图片文件夹
| | | 000001.txt
| | | 000002.txt
| | | ...
|-- weights
dwonload_weights.sh #下载权重文件命令
yolov5l.pt #yolov5l 权重文件
yolov5m.pt #yolov5m 权重文件
yolov5s.mlmodel #yolov5s 权重文件(Core M格式)
yolov5s.onnx #yolov5s 权重文件(onnx格式)
yolov5s.torchscript #yolov5s 权重文件(torchscript格式)
yolov5x.pt #yolov5x 权重文件模型训练过程:
使用环境:Python3.8+torch1.8.1+cuda11.1+pycharm (注:cuda的安装版本取决于显卡类型)
1.数据集的标注:
python打开labelimg这个软件进行标注。
python labelimg.py数据格式建议选择VOC,后期再转换成 yolo格式。 ( VOC会生成 xml 文件,可以灵活转变为其他模型所需格式)
本次训练标注两个标签,佩戴口罩为 mask,未佩戴口罩为 face。
在根目录下建立一个VOCData文件夹,再建立两个子文件,其中,jpg文件放置在VOCData/images下,xml放置在VOCData/Annotations中。(这一步根据个人随意,因为在训练时需要创建配置文件指定模型训练集的目录)
2.数据集的训练:
①、在项目根目录下文件夹下新建mask_data.yaml配置文件,添加如下内容: (根据个人情况修改)
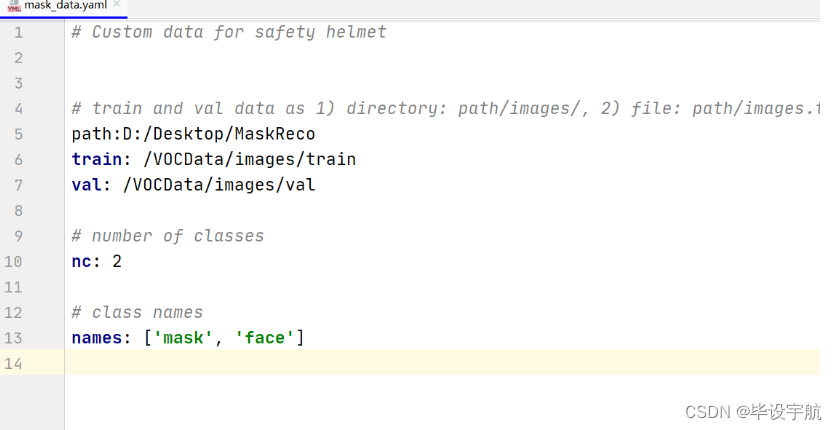
其中: path:项目的根目录 train:训练集与path的相对路径 val:验证集与path的相对路径 nc:类别数量,2个 names:类别名字 (上一步中标注好的训练集,可以按照想要比例划分为训练和验证集,也可以不划分填同一路径。)
②、修改启动文件 train.py:
打开train.py,其相关参数如下:
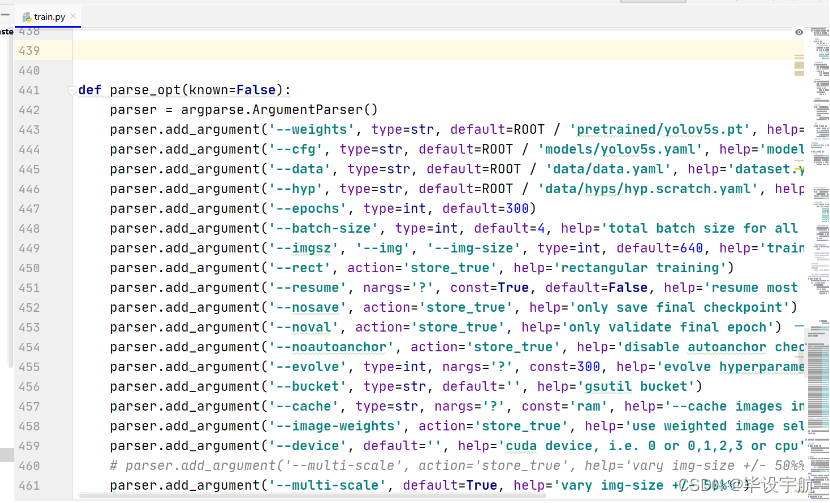
其中: weights:权重文件路径 cfg:存储模型结构的配置文件 data:存储训练、测试数据的文件(上一步中自己创建的那个.yaml) epochs:训练过程中整个数据集的迭代次数 batch-size:训练后权重更新的图片数 img-size:输入图片宽高。 device:选择使用GPU还是CPU workers:线程数,默认是8
#输入命令开始训练:
python train.py --weights data/yolov5s.pt --cfg models/yolov5s.yaml --data data/mask_data.yaml --epoch 100 --batch-size 8 --device 0③、等待慢慢跑完
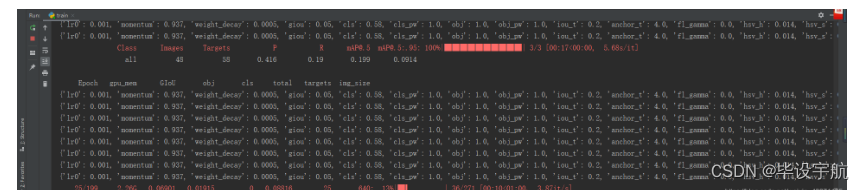
模型结果数据呈现:
1.数据集的分布:
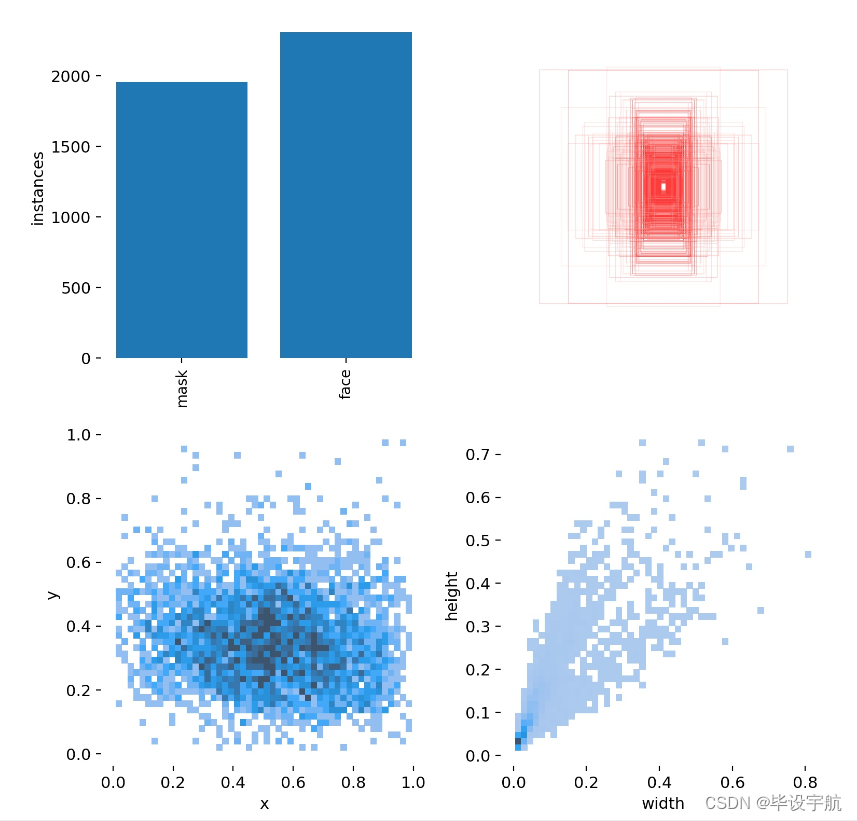
mask的照片约有2000张,face的照片约有2500张。
2.损失函数和准确率:
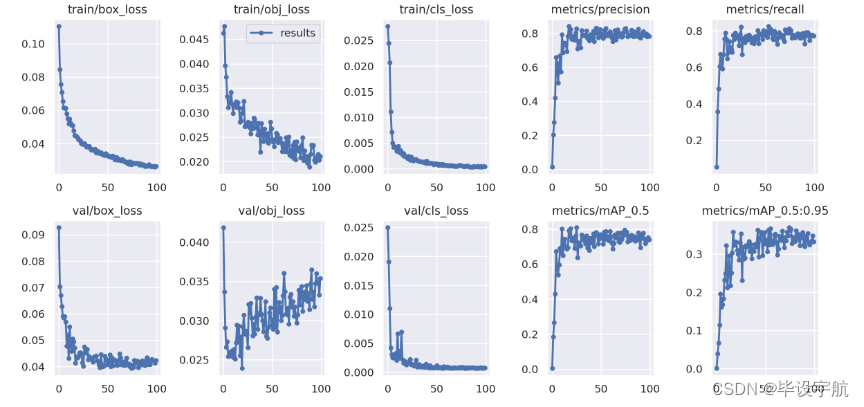
可以看到随着训练的进行,以不同方式呈现的损失函数呈明显下降趋势,准确率呈上升趋势。
3.置信度与准确率:
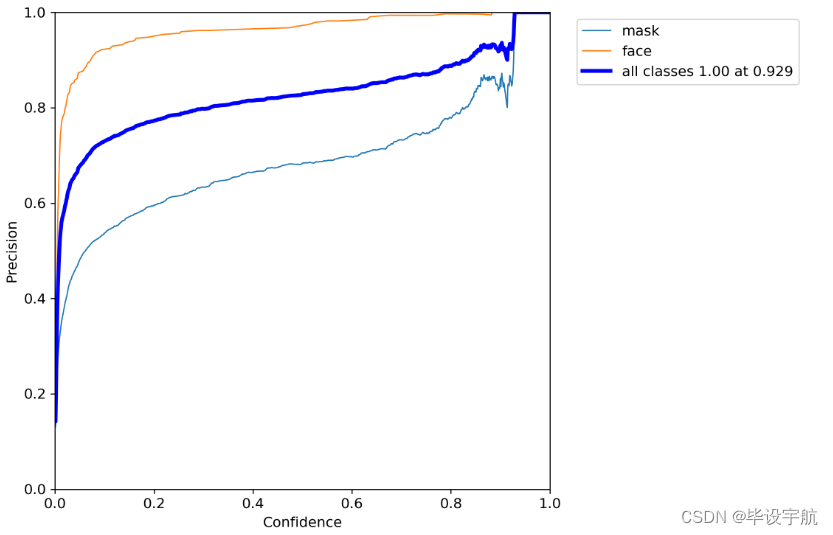
置信度在0.6以上时,准确率接近80%。
GUI编程:
编写GUI界面,方便对权重文件进行一个替换,对图片和视频进行一个监测,以及调用摄像头进行实时监测。