背景意义
研究背景与意义
随着科技的迅猛发展,武器系统的检测与识别在军事和安全领域中变得愈发重要。传统的武器目标检测方法往往依赖于人工识别和经验判断,效率低下且容易受到人为因素的影响。因此,基于深度学习的自动化检测系统应运而生,成为提升武器目标识别精度和效率的关键技术之一。YOLO(You Only Look Once)系列模型以其快速和高效的特性,成为目标检测领域的热门选择。特别是YOLOv11的改进版本,凭借其在实时检测中的卓越表现,展现出在复杂环境中识别武器目标的潜力。
本研究旨在基于改进的YOLOv11模型,构建一个高效的武器目标检测系统。所使用的数据集"MISSILEBULLETROCKET 2"包含1200幅图像,涵盖火箭、子弹和导弹三类目标,具有良好的代表性和多样性。通过对这些图像的深度学习训练,期望能够显著提高模型在武器目标检测中的准确性和鲁棒性。此外,数据集的标注采用YOLOv8格式,确保了与YOLO系列模型的兼容性,为后续的模型训练和优化提供了便利。
本研究的意义不仅在于提升武器目标检测的技术水平,更在于为军事安全、反恐和公共安全等领域提供一种高效、可靠的解决方案。通过实现自动化的武器目标检测系统,可以大幅度降低人工干预的需求,提高反应速度,进而增强整体安全防护能力。同时,随着数据集的不断丰富和模型的持续优化,未来的武器目标检测系统将能够适应更加复杂和多变的环境,为相关领域的应用提供强有力的支持。
图片效果
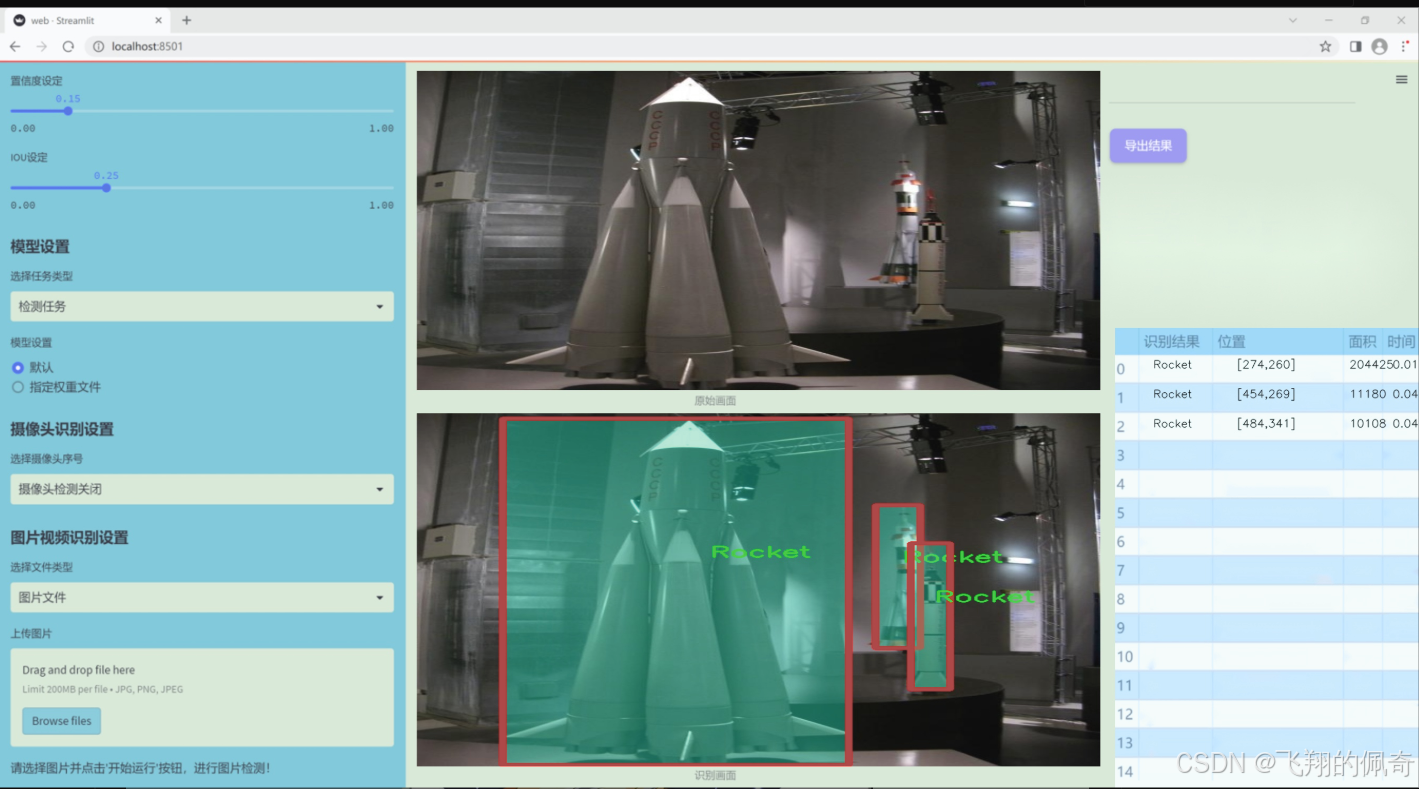
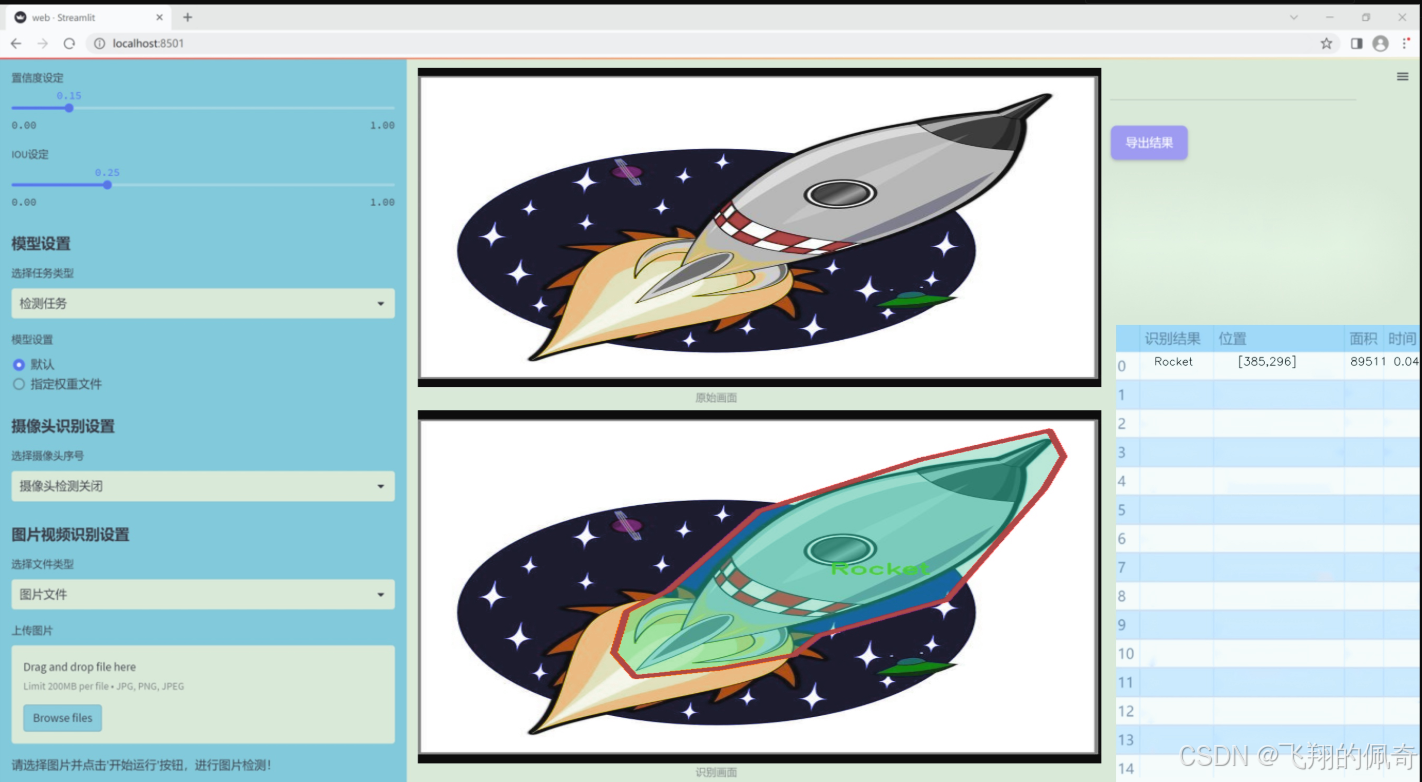
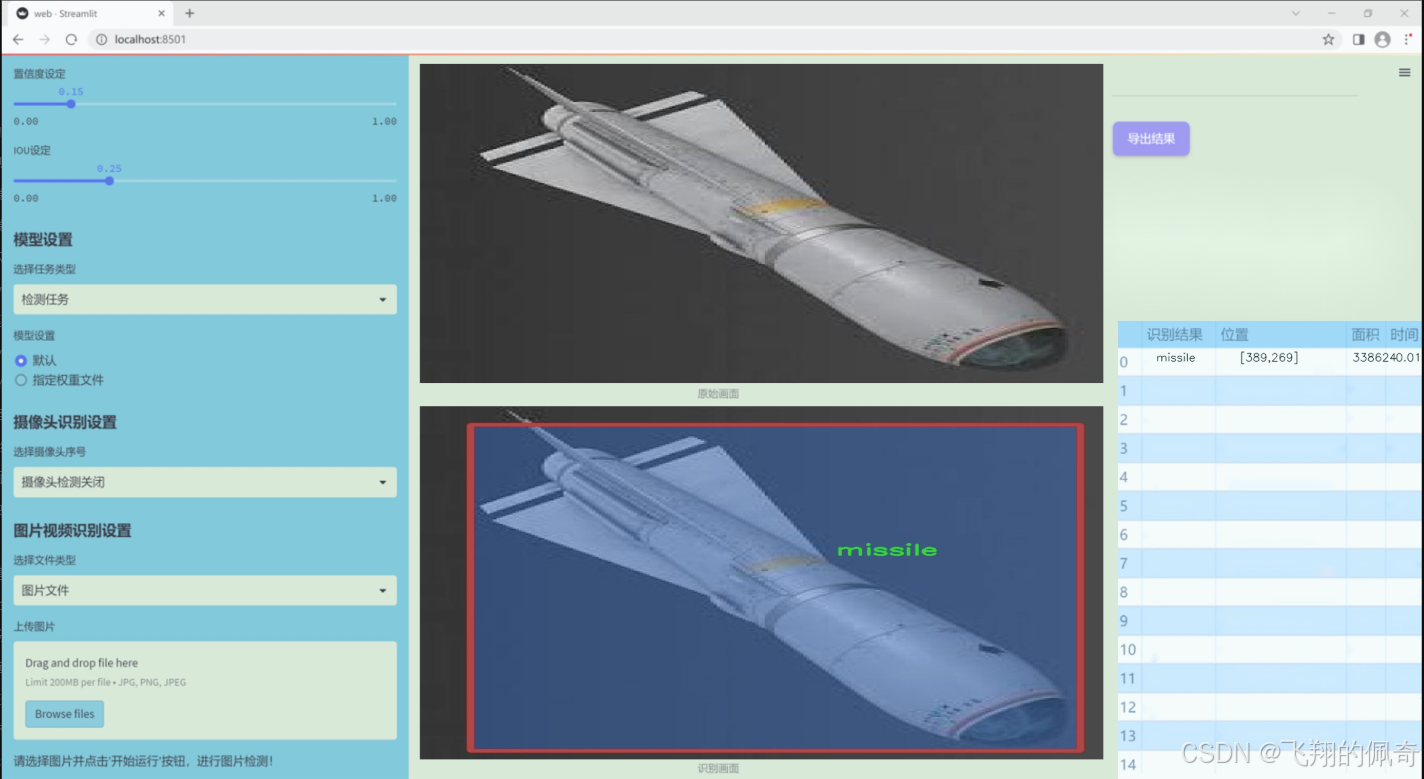
数据集信息
本项目数据集信息介绍
本项目旨在通过改进YOLOv11算法,构建一个高效的武器目标检测系统。为实现这一目标,我们采用了主题为"MISSILEBULLETROCKET 2"的数据集,该数据集专注于三种特定类别的武器目标:火箭(Rocket)、子弹(Bullet)和导弹(Missile)。数据集包含三类目标,这些目标在军事和安全领域中具有重要的应用价值,尤其是在实时监控和威胁评估中。
数据集的构建经过精心设计,确保了样本的多样性和代表性。每一类目标均包含大量的图像样本,这些样本涵盖了不同的拍摄角度、光照条件和背景环境,旨在提高模型的泛化能力和鲁棒性。通过对这些目标的准确标注,数据集为模型训练提供了坚实的基础,使得YOLOv11能够有效地识别和分类不同类型的武器目标。
在数据集的准备过程中,我们特别关注了数据的质量和标注的准确性。每个类别的图像都经过严格筛选,确保其在特征上具有显著的区分度。这种精细化的处理不仅有助于提升模型的检测精度,也为后续的模型评估提供了可靠的依据。此外,数据集还考虑到了实际应用场景中的复杂性,涵盖了多种环境下的武器目标,以便模型能够在真实世界中表现出色。
综上所述,"MISSILEBULLETROCKET 2"数据集为本项目提供了丰富的训练素材,涵盖了火箭、子弹和导弹三大类目标,旨在通过改进YOLOv11算法,提升武器目标检测的准确性和效率,为相关领域的研究和应用提供有力支持。





核心代码
以下是经过简化和注释的核心代码部分:
import torch.nn as nn
import torch
def replace_batchnorm(net):
"""
替换网络中的 BatchNorm2d 层为 Identity 层。
这通常用于模型推理阶段,以提高性能。
"""
for child_name, child in net.named_children():
if hasattr(child, 'fuse_self'):
如果子模块支持融合,进行融合
fused = child.fuse_self()
setattr(net, child_name, fused)
replace_batchnorm(fused)
elif isinstance(child, torch.nn.BatchNorm2d):
替换 BatchNorm2d 为 Identity
setattr(net, child_name, torch.nn.Identity())
else:
replace_batchnorm(child)
class Conv2d_BN(torch.nn.Sequential):
"""
自定义的卷积层,包含卷积和 BatchNorm 层。
"""
def init (self, in_channels, out_channels, kernel_size=1, stride=1, padding=0, dilation=1, groups=1):
super().init ()
添加卷积层
self.add_module('c', torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding, dilation, groups, bias=False))
添加 BatchNorm 层
self.add_module('bn', torch.nn.BatchNorm2d(out_channels))
@torch.no_grad()
def fuse_self(self):
"""
融合卷积层和 BatchNorm 层为一个卷积层。
这样可以在推理时提高性能。
"""
c, bn = self._modules.values()
# 计算融合后的权重和偏置
w = bn.weight / (bn.running_var + bn.eps)**0.5
w = c.weight * w[:, None, None, None]
b = bn.bias - bn.running_mean * bn.weight / (bn.running_var + bn.eps)**0.5
# 创建新的卷积层
m = torch.nn.Conv2d(w.size(1) * c.groups, w.size(0), w.shape[2:], stride=c.stride, padding=c.padding, dilation=c.dilation, groups=c.groups)
m.weight.data.copy_(w)
m.bias.data.copy_(b)
return mclass RepViTBlock(nn.Module):
"""
RepViT 模块的基本构建块,包含 token mixer 和 channel mixer。
"""
def init (self, inp, hidden_dim, oup, kernel_size, stride):
super(RepViTBlock, self).init ()
self.identity = stride == 1 and inp == oup # 判断是否为身份映射
if stride == 2:
当 stride 为 2 时,使用下采样
self.token_mixer = nn.Sequential(
Conv2d_BN(inp, inp, kernel_size, stride, (kernel_size - 1) // 2, groups=inp),
Conv2d_BN(inp, oup, ks=1, stride=1, pad=0)
)
else:
当 stride 为 1 时,使用 RepVGGDW
self.token_mixer = RepVGGDW(inp)
def forward(self, x):
return self.token_mixer(x)class RepViT(nn.Module):
"""
RepViT 模型的整体结构。
"""
def init (self, cfgs):
super(RepViT, self).init ()
self.cfgs = cfgs # 配置参数
layers = \[\]
for k, t, c, s in self.cfgs:
layers.append(RepViTBlock(c, t, c, k, s))
self.features = nn.ModuleList(layers)
def forward(self, x):
for f in self.features:
x = f(x)
return xdef repvit_m2_3(weights=''):
"""
构建 RepViT 模型的特定配置。
"""
cfgs = [
k, t, c, s
3, 2, 80, 1,
3, 2, 80, 1,
3, 2, 160, 2,
3, 2, 320, 2,
]
model = RepViT(cfgs)
if weights:
model.load_state_dict(torch.load(weights))
return model
if name == 'main ':
model = repvit_m2_3('repvit_m2_3_distill_450e.pth')
inputs = torch.randn((1, 3, 640, 640)) # 创建输入张量
res = model(inputs) # 前向传播
for i in res:
print(i.size()) # 输出每层的尺寸
代码说明:
replace_batchnorm: 替换模型中的 BatchNorm 层为 Identity 层,以便在推理时提高性能。
Conv2d_BN: 自定义的卷积层,包含卷积和 BatchNorm,提供了融合功能。
RepViTBlock: RepViT 模型的基本构建块,负责处理输入的特征。
RepViT: 整个模型的结构,包含多个 RepViTBlock。
repvit_m2_3: 构建特定配置的 RepViT 模型,并可加载预训练权重。
以上是代码的核心部分和详细注释,帮助理解模型的结构和功能。
这个程序文件 repvit.py 实现了一个名为 RepViT 的深度学习模型,主要用于计算机视觉任务。它结合了卷积神经网络(CNN)和视觉变换器(ViT)的优点,采用了一种高效的结构设计。
首先,文件中导入了必要的库,包括 PyTorch 的神经网络模块 torch.nn、NumPy、以及 timm 库中的 SqueezeExcite 层。接着,定义了一些工具函数和类。
replace_batchnorm 函数用于替换模型中的 BatchNorm2d 层为 Identity 层,以便在推理时加速计算。它递归遍历模型的子模块,进行相应的替换。
_make_divisible 函数确保网络中所有层的通道数是可被 8 整除的,这在一些特定的模型设计中是必要的,以提高模型的效率。
Conv2d_BN 类是一个组合模块,包含卷积层和 BatchNorm 层,并初始化 BatchNorm 的权重和偏置。它还提供了 fuse_self 方法,将卷积和 BatchNorm 融合为一个卷积层,以减少计算量。
Residual 类实现了残差连接,允许输入直接与经过卷积层处理的输出相加,支持在训练时随机丢弃部分输出以增强模型的鲁棒性。
RepVGGDW 类实现了一种特定的卷积块,结合了深度可分离卷积和残差连接。它的前向传播方法中,将输入通过两个卷积路径进行处理,并将结果与输入相加。
RepViTBlock 类是 RepViT 模型的基本构建块,包含了 token mixer 和 channel mixer。token mixer 负责在空间维度上处理输入,而 channel mixer 则在通道维度上进行处理。
RepViT 类是整个模型的核心,负责构建网络的结构。它根据给定的配置构建多个 RepViTBlock,并在前向传播中提取特征。
switch_to_deploy 方法用于将模型切换到推理模式,调用 replace_batchnorm 函数以优化模型。
update_weight 函数用于更新模型的权重,将加载的权重与当前模型的权重进行匹配。
接下来,定义了一些具体的模型构造函数,如 repvit_m0_9、repvit_m1_0 等,这些函数根据不同的配置构建 RepViT 模型,并可以选择加载预训练的权重。
最后,在文件的主程序部分,创建了一个 RepViT 模型实例,并用随机输入进行前向传播,打印输出特征的尺寸。
整体而言,这个文件实现了一个灵活且高效的深度学习模型,适用于各种计算机视觉任务,并通过模块化设计使得模型的构建和调整变得更加方便。
10.4 test_selective_scan_easy.py
以下是保留的核心代码部分,并附上详细的中文注释:
import torch
import torch.nn.functional as F
def selective_scan_easy(us, dts, As, Bs, Cs, Ds, delta_bias=None, delta_softplus=False, return_last_state=False, chunksize=64):
"""
选择性扫描函数,进行状态更新和输出计算。
参数:
us: 输入张量,形状为 (B, G * D, L)
dts: 时间增量张量,形状为 (B, G * D, L)
As: 系数矩阵,形状为 (G * D, N)
Bs: 系数矩阵,形状为 (B, G, N, L)
Cs: 系数矩阵,形状为 (B, G, N, L)
Ds: 偏置项,形状为 (G * D)
delta_bias: 可选的偏置调整,形状为 (G * D)
delta_softplus: 是否对 dts 进行 softplus 变换
return_last_state: 是否返回最后的状态
chunksize: 每次处理的序列长度
返回:
输出张量和可选的最后状态
"""
def selective_scan_chunk(us, dts, As, Bs, Cs, hprefix):
"""
处理一个块的选择性扫描,计算当前块的输出和状态。
参数:
us: 输入张量块
dts: 时间增量张量块
As: 系数矩阵
Bs: 系数矩阵块
Cs: 系数矩阵块
hprefix: 前一个状态
返回:
当前块的输出和状态
"""
ts = dts.cumsum(dim=0) # 计算时间增量的累积和
Ats = torch.einsum("gdn,lbgd->lbgdn", As, ts).exp() # 计算 A 的指数
scale = 1 # 缩放因子
rAts = Ats / scale # 归一化 A 的指数
duts = dts * us # 计算输入和时间增量的乘积
dtBus = torch.einsum("lbgd,lbgn->lbgdn", duts, Bs) # 计算 B 的贡献
hs_tmp = rAts * (dtBus / rAts).cumsum(dim=0) # 计算当前状态
hs = hs_tmp + Ats * hprefix.unsqueeze(0) # 更新状态
ys = torch.einsum("lbgn,lbgdn->lbgd", Cs, hs) # 计算输出
return ys, hs # 返回输出和状态
# 数据类型设置
dtype = torch.float32
inp_dtype = us.dtype # 输入数据类型
has_D = Ds is not None # 检查是否有 D
# 确保 chunksize 合理
if chunksize < 1:
chunksize = Bs.shape[-1]
# 处理时间增量
dts = dts.to(dtype)
if delta_bias is not None:
dts = dts + delta_bias.view(1, -1, 1).to(dtype) # 添加偏置
if delta_softplus:
dts = F.softplus(dts) # 应用 softplus 变换
# 处理输入和系数矩阵的形状
Bs = Bs.unsqueeze(1) if len(Bs.shape) == 3 else Bs
Cs = Cs.unsqueeze(1) if len(Cs.shape) == 3 else Cs
B, G, N, L = Bs.shape
us = us.view(B, G, -1, L).permute(3, 0, 1, 2).to(dtype)
dts = dts.view(B, G, -1, L).permute(3, 0, 1, 2).to(dtype)
As = As.view(G, -1, N).to(dtype)
Bs = Bs.permute(3, 0, 1, 2).to(dtype)
Cs = Cs.permute(3, 0, 1, 2).to(dtype)
Ds = Ds.view(G, -1).to(dtype) if has_D else None
D = As.shape[1] # 状态维度
oys = [] # 输出列表
hprefix = us.new_zeros((B, G, D, N), dtype=dtype) # 初始化前一个状态
for i in range(0, L, chunksize):
ys, hs = selective_scan_chunk(
us[i:i + chunksize], dts[i:i + chunksize],
As, Bs[i:i + chunksize], Cs[i:i + chunksize], hprefix,
)
oys.append(ys) # 收集输出
hprefix = hs[-1] # 更新前一个状态
oys = torch.cat(oys, dim=0) # 合并输出
if has_D:
oys = oys + Ds * us # 添加 D 的贡献
oys = oys.permute(1, 2, 3, 0).view(B, -1, L) # 调整输出形状
return oys.to(inp_dtype) if not return_last_state else (oys.to(inp_dtype), hprefix.view(B, G * D, N).float())代码注释说明
函数参数:对每个参数进行了详细说明,包括其形状和作用。
核心逻辑:保留了选择性扫描的核心逻辑,包括状态更新和输出计算的过程。
内部函数:对内部函数 selective_scan_chunk 进行了详细注释,说明其计算步骤和返回值。
数据处理:注释了数据类型转换和形状调整的步骤,确保理解数据流动的过程。
这样处理后,代码更加简洁明了,同时保留了必要的功能和逻辑。
这个程序文件 test_selective_scan_easy.py 主要实现了一个选择性扫描(Selective Scan)算法,并通过测试用例验证其正确性。选择性扫描是一种用于处理序列数据的计算方法,广泛应用于深度学习中的时间序列建模和递归神经网络等领域。
程序的主要结构包括以下几个部分:
首先,导入了一些必要的库,包括 torch、pytest 和 einops。这些库提供了张量操作、自动求导和张量重排等功能。
接下来,定义了 selective_scan_easy 函数,这是选择性扫描的核心实现。该函数接受多个参数,包括输入张量 us、时间增量 dts、矩阵 As、Bs、Cs 和 Ds,以及一些可选参数如 delta_bias 和 delta_softplus。函数内部使用了一个嵌套的 selective_scan_chunk 函数来处理数据块的选择性扫描。
在 selective_scan_chunk 函数中,首先计算时间序列的累积和,并根据输入的矩阵计算中间结果。然后,使用张量运算来更新状态和输出,最后返回计算结果。
selective_scan_easy 函数还处理了输入数据的维度转换和类型转换,确保数据格式符合计算要求。计算完成后,函数返回最终的输出张量,可能还包括最后的状态。
接着,定义了 SelectiveScanEasy 类,它继承自 torch.autograd.Function,用于实现自定义的前向和反向传播。这个类的 forward 方法调用了 selective_scan_easy 函数,并保存了一些中间计算结果以供反向传播使用。backward 方法则实现了反向传播的逻辑,计算梯度并返回。
随后,定义了一些辅助函数,如 selective_scan_easy_fwdbwd 和 selective_scan_ref,用于执行前向和反向传播的计算,并提供与原始实现的参考比较。
最后,使用 pytest 框架定义了一系列测试用例,验证选择性扫描的实现是否正确。测试用例通过不同的参数组合,检查输出和梯度的准确性,确保算法在各种情况下都能正常工作。
总体而言,这个程序文件实现了一个高效的选择性扫描算法,并通过严格的测试确保其正确性和稳定性。
源码文件

源码获取
欢迎大家点赞、收藏、关注、评论 啦 、查看👇🏻获取联系方式👇🏻