前言
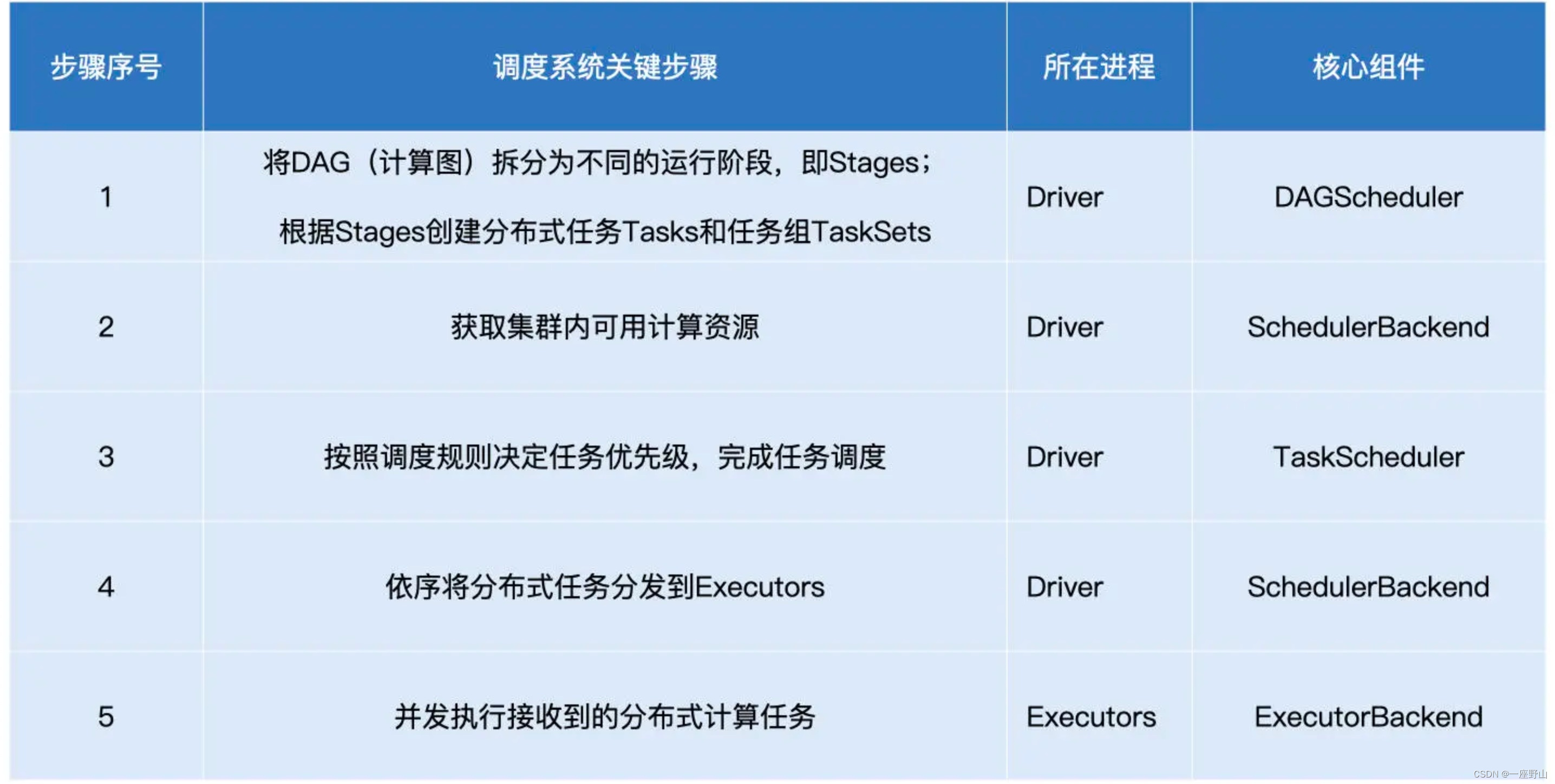
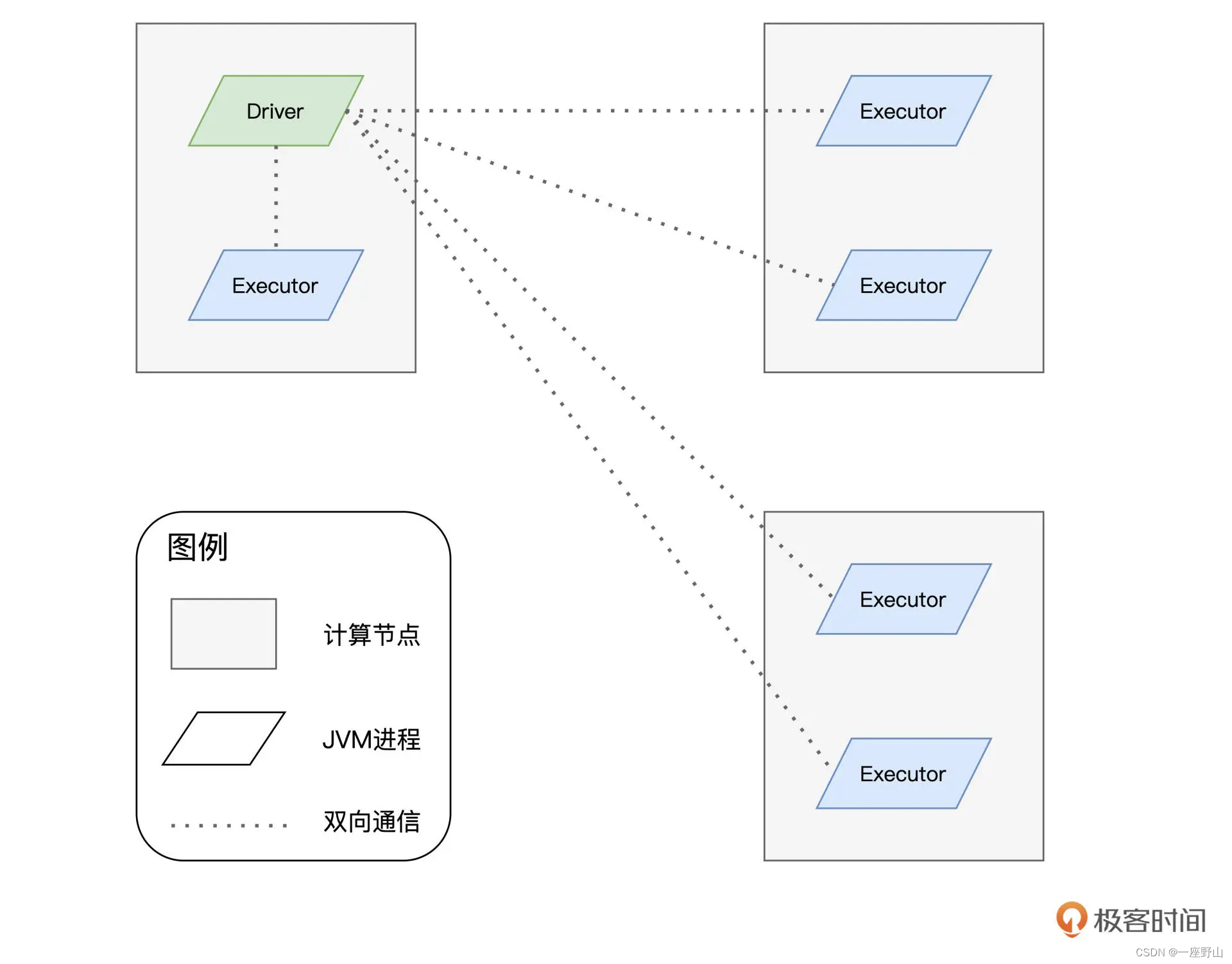
分布式计算的精髓,在于如何把抽象的计算流图,转化为实实在在的分布式计算任务,然后以并行计算的方式交付执行。今天这一讲,我们就来聊一聊,Spark 是如何实现分布式计算的。分布式计算的实现,离不开两个关键要素,一个是进程模型,另一个是分布式的环境部署。接下来,我们先去探讨 Spark 的进程模型,然后再来介绍 Spark 都有哪些分布式部署方式。
触发计算流程图

 函数
函数


Scala
##统计单词的次数
import org.apache.spark.rdd.RDD
// 这里的下划线"_"是占位符,代表数据文件的根目录,hdfs的目录地址
val rootPath: String = "/user/hadoop/wikiOfSpark.txt"
val file: String = s"${rootPath}"
// 读取文件内容
val lineRDD: RDD[String] = spark.sparkContext.textFile(file)
// 以行为单位做分词
val wordRDD: RDD[String] = lineRDD.flatMap(line => line.split(" "))
val cleanWordRDD: RDD[String] = wordRDD.filter(word => !word.equals(""))
// 把RDD元素转换为(Key,Value)的形式
val kvRDD: RDD[(String, Int)] = cleanWordRDD.map(word => (word, 1))
// 按照单词做分组计数
val wordCounts: RDD[(String, Int)] = kvRDD.reduceByKey((x, y) => x + y)
// 打印词频最高的5个词汇
wordCounts.map{case (k, v) => (v, k)}.sortByKey(false).take(5)
##########################
//统计相邻单词共现的次数
假设,我们再次改变 Word Count 的计算逻辑,由原来统计单词的计数,改为统计相邻单词共现的次数。
import org.apache.spark.rdd.RDD
// 这里的下划线"_"是占位符,代表数据文件的根目录,hdfs的目录地址
val rootPath: String = "/user/hadoop/wikiOfSpark.txt"
val file: String = s"${rootPath}"
// 读取文件内容
val lineRDD: RDD[String] = spark.sparkContext.textFile(file)
// 以行为单位提取相邻单词
val wordPairRDD: RDD[String] = lineRDD.flatMap( line => {
// 将行转换为单词数组
val words: Array[String] = line.split(" ")
// 将单个单词数组,转换为相邻单词数组
for (i <- 0 until words.length - 1) yield words(i) + "-" + words(i+1)
})
val cleanWordRDD: RDD[String] = wordPairRDD.filter(word => !word.equals(""))
// 把RDD元素转换为(Key,Value)的形式
val kvRDD: RDD[(String, Int)] = cleanWordRDD.map(word => (word, 1))
// 按照单词做分组计数
val wordCounts: RDD[(String, Int)] = kvRDD.reduceByKey((x, y) => x + y)
// 打印词频最高的5个词汇
wordCounts.map{case (k, v) => (v, k)}.sortByKey(false).take(5)
##对原来单词的计数,改为对单词的哈希值计数,在这种情况下。我们代码实现需要做哪些改动。
import org.apache.spark.rdd.RDD
import java.security.MessageDigest
// 这里的下划线"_"是占位符,代表数据文件的根目录,hdfs的目录地址
val rootPath: String = "/user/hadoop/wikiOfSpark.txt"
val file: String = s"${rootPath}"
// 读取文件内容
val lineRDD: RDD[String] = spark.sparkContext.textFile(file)
// 以行为单位做分词
val wordRDD: RDD[String] = lineRDD.flatMap(line => line.split(" "))
val cleanWordRDD: RDD[String] = wordRDD.filter(word => !word.equals(""))
// 把普通RDD转换为Paired RDD
val kvRDD: RDD[(String, Int)] = cleanWordRDD.map{ word =>
// 获取MD5对象实例
val md5 = MessageDigest.getInstance("MD5")
// 使用MD5计算哈希值
val hash = md5.digest(word.getBytes).mkString
// 返回哈希值与数字1的Pair
(hash, 1)
}
// 按照单词做分组计数
val wordCounts: RDD[(String, Int)] = kvRDD.reduceByKey((x, y) => x + y)
// 打印词频最高的5个词汇
wordCounts.map{case (k, v) => (v, k)}.sortByKey(false).take(5)
Scala
import org.apache.spark.sql.expressions.Window
import org.apache.spark.sql.functions._
// 创建表
case class SiteViews(site_id: String, date: String, page_view: Int)
val siteViews = Seq(
SiteViews("a", "2021-05-20", 10),
SiteViews("a", "2021-05-21", 11),
SiteViews("a", "2021-05-22", 12),
SiteViews("a", "2021-05-23", 12),
SiteViews("a", "2021-05-24", 13),
SiteViews("a", "2021-05-25", 14),
SiteViews("a", "2021-05-26", 15),
SiteViews("b", "2021-05-20", 21),
SiteViews("b", "2021-05-21", 22),
SiteViews("b", "2021-05-22", 22),
SiteViews("b", "2021-05-23", 22),
SiteViews("b", "2021-05-24", 23),
SiteViews("b", "2021-05-25", 23),
SiteViews("b", "2021-05-26", 25)
).toDF()
//
Window.partitionBy("column name"|column)
// orderBy的语法
Window.orderBy("column name"|column)